
Friends,
In this post I am gonna add stuff related to Interview questions from SQL SERVER with answers. Hope this one will help you in cracking the Interviews on SQL SERVER.
- What are Constraints or Define Constraints ?
Generally we use Data Types to limit the kind of Data in a Column. For example, if we declare any column with data type INT then ONLY Integer data can be inserted into the column. Constraint will help us to limit the Values we are passing into a column or a table. In simple Constraints are nothing but Rules or Conditions applied on columns or tables to restrict the data.
- Different types of Constraints ?
There are THREE Types of Constraints.
- Domain
- Entity
- Referential
Domain has the following constraints types –
- Not Null
- Check
Entity has the following constraint types –
- Primary Key
- Unique Key
Referential has the following constraint types –
- Foreign Key
- What is the difference between Primary Key and Unique Key ?
- By default PK defines Clustered Index in the column where as UK defines Non Clustered Index.
- PK doesn’t allow NULL Value where as UK allow ONLY ONE NULL.
- You can have only one PK per table where as UK can be more than one per table.
- PK can be used in Foreign Key relationships where as UK cannot be used.
- What is the difference between Delete and Truncate ?
- Truncate is Faster where as Delete is Slow process.
- Truncate doesn’t log where as Delete logs an entry for every record deleted in Transaction Log.
- We can rollback the Deleted data where as Truncated data cannot be rolled back.
- Truncate resets the Identity column where as Delete doesn’t.
- We can have WHERE Clause for delete where as for Truncate we cannot have WHERE Clause.
- Delete Activates TRIGGER where as TRUNCATE Cannot.
- Truncate is a DDL statement where as Delete is DML statement.
- What are Indexes or Indices ?
- Types of Indices in SQL ?
- Clustered
- Non Clustered
- How many Clustered and Non Clustered Indexes can be defined for a table ?
Clustered – 1
Non Clustered – 999
- What is Transaction in SQL Server ?
- Types of Transactions ?
- Implicit – Specifies any Single Insert,Update or Delete statement as Transaction Unit. No need to specify Explicitly.
- Explicit – A group of T-Sql statements with the beginning and ending marked with Begin Transaction,Commit and RollBack. PFB an Example for Explicit transactions.
BEGIN TRANSACTION
Update Employee Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
Update LEave_Details Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
COMMIT
In the above example we are trying to update an EMPLOYEE ID from 12345 to 54321 in both the master table “Employee” and Transaction table “Leave_Details”. In this case either BOTH the tables will be updated with new EMPID or NONE.
- What is the Max size and Max number of columns for a row in a table ?
- What is Normalization and Explain different normal forms.
Database normalization is a process of data design and organization which applies to data structures based on rules that help building relational databases.
1. Organizing data to minimize redundancy.
2. Isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
1NF: Eliminate Repeating Groups
Each set of related attributes should be in separate table, and give each table a primary key. Each field contains at most one value from its attribute domain.
2NF: Eliminate Redundant Data
1. Table must be in 1NF.
2. All fields are dependent on the whole of the primary key, or a relation is in 2NF if it is in 1NF and every non-key attribute is fully dependent on each candidate key of the relation. If an attribute depends on only part of a multi‐valued key, remove it to a separate table.
3NF: Eliminate Columns Not Dependent On Key
1. The table must be in 2NF.
2. Transitive dependencies must be eliminated. All attributes must rely only on the primary key. If attributes do not contribute to a description of the key, remove them to a separate table. All attributes must be directly dependent on the primary key.
BCNF: Boyce‐Codd Normal Form
for every one of its non-trivial functional dependencies X → Y, X is a superkey—that is, X is either a candidate key or a superset thereof. If there are non‐trivial dependencies between candidate key attributes, separate them out into distinct tables.
4NF: Isolate Independent Multiple Relationships
No table may contain two or more 1:n or n:m relationships that are not directly related.
For example, if you can have two phone numbers values and two email address values, then you should not have them in the same table.
5NF: Isolate Semantically Related Multiple Relationships
A 4NF table is said to be in the 5NF if and only if every join dependency in it is implied by the candidate keys. There may be practical constrains on information that justify separating logically related many‐to‐many relationships.
- What is Denormalization ?
For optimizing the performance of a database by adding redundant data or by grouping data is called de-normalization.
It is sometimes necessary because current DBMSs implement the relational model poorly.
In some cases, de-normalization helps cover up the inefficiencies inherent in relational database software. A relational normalized database imposes a heavy access load over physical storage of data even if it is well tuned for high performance.
A true relational DBMS would allow for a fully normalized database at the logical level, while providing physical storage of data that is tuned for high performance. De‐normalization is a technique to move from higher to lower normal forms of database modeling in order to speed up database access.
- Query to Pull ONLY duplicate records from table ?
There are many ways of doing the same and let me explain one here. We can acheive this by using the keywords GROUP and HAVING. The following query will extract duplicate records from a specific column of a particular table.
Select specificColumn
FROM particluarTable
GROUP BY specificColumn
HAVING COUNT(*) > 1
This will list all the records that are repeated in the column specified by “specificColumn” of a “particlarTable”.
- Types of Joins in SQL SERVER ?
- Inner Join
- Outer Join
- Cross Join
- Right Outer Join
- Left Outer Join
- Full Outer Join.
- What is Table Expressions in Sql Server ?
- Derived tables
- Common Table Expressions.
- What is Derived Table ?
- What is CTE or Common Table Expression ?
- Recursive
- Non Recursive
- Difference between SmallDateTime and DateTime datatypes in Sql server ?
- DateTime occupies 4 Bytes of data where as SmallDateTime occupies only 2 Bytes.
- DateTime ranges from 01/01/1753 to 12/31/9999 where as SmallDateTime ranges from 01/01/1900 to 06/06/2079.
- What is SQL_VARIANT Datatype ?
The SQL_VARIANT data type can be used to store values of various data types at the same time, such as numeric values, strings, and date values. (The only types of values that cannot be stored are TIMESTAMP values.) Each value of an SQL_VARIANT column has two parts: the data value and the information that describes the value. (This information contains all properties of the actual data type of the value, such as length, scale, and precision.)
- What is Temporary table ?
A temporary table is a database object that is temporarily stored and managed by the database system. There are two types of Temp tables.
- Local
- Global
- What are the differences between Local Temp table and Global Temp table ?
- Both are stored in tempdb database.
- Both will be cleared once the connection,which is used to create the table, is closed.
- Both are meant to store data temporarily.
- Local temp table is prefixed with # where as Global temp table with ##.
- Local temp table is valid for the current connection i.e the connection where it is created where as Global temp table is valid for all the connection.
- Local temp table cannot be shared between multiple users where as Global temp table can be shared.
- Whar are the differences between Temp table and Table variable ?
- Table variables are Transaction neutral where as Temp tables are Transaction bound. For example if we declare and load data into a temp table and table variable in a transaction and if the transaction is ROLLEDBACK, still the table variable will have the data loaded where as Temp table will not be available as the transaction is rolled back.
- Temporary Tables are real tables so you can do things like CREATE INDEXes, etc. If you have large amounts of data for which accessing by index will be faster then temporary tables are a good option.
- Table variables don’t participate in transactions, logging or locking. This means they’re faster as they don’t require the overhead.
- You can create a temp table using SELECT INTO, which can be quicker to write (good for ad-hoc querying) and may allow you to deal with changing datatypes over time, since you don’t need to define your temp table structure upfront.
- What is the difference between Char,Varchar and nVarchar datatypes ?
char[(n)] – Fixed-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is n bytes. The SQL-92 synonym for char is character.
varchar[(n)] – Variable-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is the actual length in bytes of the data entered, not n bytes. The data entered can be 0 characters in length. The SQL-92 synonyms for varchar are char varying or character varying.
nvarchar(n) – Variable-length Unicode character data of n characters. n must be a value from 1 through 4,000. Storage size, in bytes, is two times the number of characters entered. The data entered can be 0 characters in length. The SQL-92 synonyms for nvarchar are national char varying and national character varying.
- What is the difference between STUFF and REPLACE functions in Sql server ?
- What are Magic Tables ?
The deleted table contains all records that have been deleted from deleted from the trigger table.
Whenever any updation takes place, the trigger uses both the inserted and deleted tables.
- Explain about RANK,ROW_NUMBER and DENSE_RANK in Sql server ?
Found a very interesting explanation for the same in the url Click Here . PFB the content of the same here.
Lets take 1 simple example to understand the difference between 3.
First lets create some sample data :
— create table
CREATE TABLE Salaries
(
Names VARCHAR(1),
SalarY INT
)
GO
— insert data
INSERT INTO Salaries SELECT
‘A’,5000 UNION ALL SELECT
‘B’,5000 UNION ALL SELECT
‘C’,3000 UNION ALL SELECT
‘D’,4000 UNION ALL SELECT
‘E’,6000 UNION ALL SELECT
‘F’,10000
GO
— Test the data
SELECT Names, Salary
FROM Salaries
Now lets query the table to get the salaries of all employees with their salary in descending order.
For that I’ll write a query like this :
SELECT names
, salary
,row_number () OVER (ORDER BY salary DESC) as ROW_NUMBER
,rank () OVER (ORDER BY salary DESC) as RANK
,dense_rank () OVER (ORDER BY salary DESC) as DENSE_RANK
FROM salaries
>>Output
| NAMES | SALARY | ROW_NUMBER | RANK | DENSE_RANK |
| F | 10000 | 1 | 1 | 1 |
| E | 6000 | 2 | 2 | 2 |
| A | 5000 | 3 | 3 | 3 |
| B | 5000 | 4 | 3 | 3 |
| D | 4000 | 5 | 5 | 4 |
| C | 3000 | 6 | 6 | 5 |
Interesting Names in the result are employee A, B and D. Row_number assign different number to them. Rank and Dense_rank both assign same rank to A and B. But interesting thing is what RANK and DENSE_RANK assign to next row? Rank assign 5 to the next row, while dense_rank assign 4.
The numbers returned by the DENSE_RANK function do not have gaps and always have consecutive ranks. The RANK function does not always return consecutive integers. The ORDER BY clause determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition.
So question is which one to use?
Its all depends on your requirement and business rule you are following.
1. Row_number to be used only when you just want to have serial number on result set. It is not as intelligent as RANK and DENSE_RANK.
2. Choice between RANK and DENSE_RANK depends on business rule you are following. Rank leaves the gaps between number when it sees common values in 2 or more rows. DENSE_RANK don’t leave any gaps between ranks.
So while assigning the next rank to the row RANK will consider the total count of rows before that row and DESNE_RANK will just give next rank according to the value.
So If you are selecting employee’s rank according to their salaries you should be using DENSE_RANK and if you are ranking students according to there marks you should be using RANK(Though it is not mandatory, depends on your requirement.)
- What are the differences between WHERE and HAVING clauses in SQl Server ?
2.Where applies to each and single row and Having applies to summarized rows (summarized with GROUP BY).
3.In Where clause the data that fetched from memory according to condition and In having the completed data firstly fetched and then separated according to condition.
4.Where is used before GROUP BY clause and HAVING clause is used to impose condition on GROUP Function and is used after GROUP BY clause in the query.
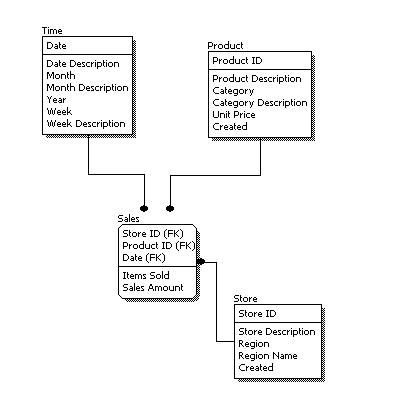
- Explain Physical Data Model or PDM ?
Physical data model represents how the model will be built in the database. A physical database model shows all table structures, including column name, column data type, column constraints, primary key, foreign key, and relationships between tables. Features of a physical data model include:
- Specification all tables and columns.
- Foreign keys are used to identify relationships between tables.
- Specying Data types.
EG –

Reference from Here
- Explain Logical Data Model ?
A logical data model describes the data in as much detail as possible, without regard to how they will be physical implemented in the database. Features of a logical data model include:
- Includes all entities and relationships among them.
- All attributes for each entity are specified.
- The primary key for each entity is specified.
- Foreign keys (keys identifying the relationship between different entities) are specified.
- Normalization occurs at this level.
Reference from Here
- Explain Conceptual Data Model ?
A conceptual data model identifies the highest-level relationships between the different entities. Features of conceptual data model include:
- Includes the important entities and the relationships among them.
- No attribute is specified.
- No primary key is specified.
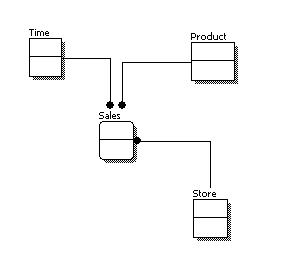
Reference from Here
- What is Log Shipping ?
Log Shipping is a basic level SQL Server high-availability technology that is part of SQL Server. It is an automated backup/restore process that allows you to create another copy of your database for failover.
Log shipping involves copying a database backup and subsequent transaction log backups from the primary (source) server and restoring the database and transaction log backups on one or more secondary (Stand By / Destination) servers. The Target Database is in a standby or no-recovery mode on the secondary server(s) which allows subsequent transaction logs to be backed up on the primary and shipped (or copied) to the secondary servers and then applied (restored) there.
- What are the advantages of database normalization ?
Benefits of normalizing the database are
- No need to restructure existing tables for new data.
- Reducing repetitive entries.
- Reducing required storage space
- Increased speed and flexibility of queries.
- What are Linked Servers ?
Linked servers are configured to enable the Database Engine to execute a Transact-SQL statement that includes tables in another instance of SQL Server, or another database product such as Oracle. Many types OLE DB data sources can be configured as linked servers, including Microsoft Access and Excel. Linked servers offer the following advantages:
- The ability to access data from outside of SQL Server.
- The ability to issue distributed queries, updates, commands, and transactions on heterogeneous data sources across the enterprise.
- The ability to address diverse data sources similarly.
- Can connect to MOLAP databases too.
- What is the Difference between the functions COUNT and COUNT_BIG ?
- Count returns INT datatype value where as Count_Big returns BIGINT datatype value.
- Count is used if the rows in a table are less where as Count_Big will be used when the numbenr of records are in millions or above.
Syntax –
- Count – Select count(*) from tablename
- Count_Big – Select Count_Big(*) from tablename
- How to insert values EXPLICITLY to an Identity Column ?
Msg 544, Level 16, State 1, Line 3 Cannot insert explicit value for identity column in table 'tablename' when IDENTITY_INSERT is set to OFF.
- How to RENAME a table and column in SQL ?
- How to rename a database ?
USE master; GO ALTER DATABASE databasename Modify Name = newname ; GO
- What is the use the UPDATE_STATISTICS command ?
- How to read the last record from a table with Identity Column ?
FROM TABLE
WHERE ID = IDENT_CURRENT(‘TABLE’)
FROM TABLE
WHERE ID = (SELECT MAX(ID) FROM TABLE)
- What is Worktable ?
A worktable is a temporary table used internally by SQL Server to process the intermediate results of a query. Worktables are created in the tempdb database and are dropped automatically after query execution. Thease table cannot be seen as these are created while a query executing and dropped immediately after the execution of the query.
- What is HEAP table ?
A table with NO CLUSTERED INDEXES is called as HEAP table. The data rows of a heap table are not stored in any particular order or linked to the adjacent pages in the table. This unorganized structure of the heap table usually increases the overhead of accessing a large heap table, when compared to accessing a large nonheap table (a table with clustered index). So, prefer not to go with HEAP tables .. 🙂
- What is ROW LOCATOR ?
If you define a NON CLUSTERED index on a table then the index row of a nonclustered index contains a pointer to the corresponding data row of the table. This pointer is called a row locator. The value of the row locator depends on whether the data pages are stored in a heap or are clustered. For a nonclustered index, the row locator is a pointer to the data row. For a table with a clustered index, the row locator is the clustered index key value.
- What is Covering Index ?
A covering index is a nonclustered index built upon all the columns required to satisfy a SQL query without going to the base table. If a query encounters an index and does not need to refer to the underlying data table at all, then the index can be considered a covering index. For Example
Select col1,col2 from table
where col3 = Value
group by col4
order by col5
Now if you create a clustered index for all the columns used in Select statement then the SQL doesn’t need to go to base tables as everything required are available in index pages.
- What is Indexed View ?
- What is Bookmark Lookup ?
When a SQL query requests a small number of rows, the optimizer can use the nonclustered index, if available, on the column(s) in the WHERE clause to retrieve the data. If the query refers to columns that are not part of the nonclustered index used to retrieve the data, then navigation is required from the index row to the corresponding data row in the table to access these columns.This operation is called a bookmark lookup.
http://specodezh.ru/
квартиры на сутки
[url=https://methocarbamol.gives/]robaxin price uk[/url]
fluoxetine 20 mg capsule cost
zofran medication order amoxicillin 500mg generic buy trimethoprim without prescription
buy levaquin no prescription
can you buy stromectol over the counter brand deltasone 20mg buy deltasone generic
fake residence permit
квартиры на сутки
Собственное производство, доставка и монтаж под ключ [url=https://karkasnik-pod-kluch.ru/]каркасный дом[/url] гарантия на готовую конструкцию, доставка 500 км за наш счет.
Pills information leaflet. Generic Name.
lyrica otc
Some about meds. Get now.
metoprolol dose
Чат телеграм автоюрист
Drug prescribing information. Effects of Drug Abuse.
order celebrex
All what you want to know about meds. Read information now.
Meds information for patients. Generic Name.
mobic
Actual what you want to know about meds. Read information here.
ventolin 4mg uk order albuterol for sale augmentin medication
Стоимость разработки сайтов
Drugs information. Effects of Drug Abuse.
COP medication
Best what you want to know about pills. Read information now.
where to get cheap prednisone price
Drugs information. Generic Name.
neurontin
Best about drugs. Read here.
Medicines prescribing information. Short-Term Effects.
prednisone generics
Actual about medicament. Get information here.
Medicine information sheet. Drug Class.
prednisone tablets
Everything news about medicine. Get now.
buy actos now
Drugs information. Long-Term Effects.
neurontin generics
Best information about medication. Read information now.
ashwagandha powder
Medicines information for patients. Long-Term Effects.
lisinopril 40 mg
Best news about medicine. Read now.
suprax
how to get cheap cleocin no prescription
prednisolone 5mg oral prednisolone 20mg canada brand furosemide 100mg
Medicine prescribing information. Short-Term Effects.
lisinopril 40 mg
All trends of medicines. Read here.
Medicines information. Cautions.
lisinopril 40 mg
Actual news about medicament. Get information here.
avodart canada order orlistat 120mg order xenical 60mg online
Medicine information for patients. What side effects can this medication cause?
propecia
Everything about medicine. Get information here.
Pills information for patients. Effects of Drug Abuse.
how to buy canadian pharmacy
All information about meds. Get now.
Medicines prescribing information. What side effects can this medication cause?
lisinopril 40 mg
Actual information about medicament. Read now.
Наша компания предлагает услуги по изготовлению мебели на заказ [url=http://mebel-dlya-was.ru/]мебель на заказ[/url] будет полностью соответствовать вашим потребностям и предпочтениям.
Meds information for patients. Cautions.
lisinopril 40 mg
All about pills. Read here.
Medicament information sheet. What side effects?
viagra online
Actual information about medicines. Get now.
Drug information. Cautions.
lisinopril 40 mg
All about medicament. Get information now.
квартиры на сутки
Drugs information sheet. Short-Term Effects.
lisinopril 40 mg
Actual news about drug. Get information now.
Meds prescribing information. Brand names.
mobic
Some trends of pills. Read information now.
Drug prescribing information. Cautions.
cleocin
Best information about medicine. Read now.
квартиры на сутки
Drugs information. Generic Name.
lisinopril 40 mg
Some what you want to know about pills. Read here.
Medication information. Brand names.
lisinopril 40 mg
All trends of medicament. Get information here.
[url=http://dexamethasone247.com/]dexamethasone 12 mg[/url]
[url=http://cafergot.best/]cafergot tablets price[/url]
Medicines information sheet. Long-Term Effects.
tetracycline without a prescription
All trends of pills. Read information now.
Medicine information. Short-Term Effects.
lisinopril 40 mg
Best news about medicines. Read information here.
fake passport maker
Drug prescribing information. Long-Term Effects.
vastarel
All information about pills. Get now.
Latvija tiessaistes kazino ir kluvusi arvien popularaki, piedavajot speletajiem iespeju baudit dazadas azartspeles no majam vai celojot. Lai darbotos legali, [url=https://steemit.com/gambling/@kasinoid/gambling-ir-spelu-veids-kas-pamatojas-uz-nejausibas-elementu-kura-speletaji-liek-naudu-uz-kada-notikuma-iznakumu-cerot-uz-uzvaru]https://steemit.com/gambling/@kasinoid/gambling-ir-spelu-veids-kas-pamatojas-uz-nejausibas-elementu-kura-speletaji-liek-naudu-uz-kada-notikuma-iznakumu-cerot-uz-uzvaru[/url] tiessaistes kazino Latvija ir jabut licencetiem no attiecigajam iestadem. Sie kazino piedava plasu spelu klastu, tostarp spelu automatus, galda speles, pokera turnirus un sporta likmju deribas.
Pills information for patients. Cautions.
maxalt
Best about drugs. Get information now.
order dapsone 100 mg sale mesalamine 800mg ca order generic tenormin
This page provides useful information for those who [url=https://tribuneonlineng.com/maximize-your-woodworking-potential-with-a-top-quality-cnc-router-2/]cnc router[/url] are engaged in woodworking and wish to maximize their potential.
Medicines information leaflet. Short-Term Effects.
fluoxetine otc
Some about drugs. Read information here.
[url=https://atenolola.online/]drug atenolol 50 mg[/url]
Medicines information sheet. Drug Class.
levaquin medication
Some trends of medication. Get information here.
fake caribbean citizenship
Onlayn kazinolar, o’yinchilarga o’yinlar o’ynash uchun virtual platforma taqdim etadi. Ushbu platformalar internet orqali ulangan va o’yinchilar tizimda ro’yxatdan o’tganidan so’ng o’yinlarni o’ynay oladi https://www.pinterest.co.uk/kazinolar/ Onlayn kazinolar yuqori sifatli grafika, to’g’ri animatsiya va zamonaviy o’yin tajribasi bilan ajratiladi.
Компания ЗубыПро представляет профессиональные услуги по надеванию, корректировке и снятию брекет-систем [url=https://pancreatus.com/anatomy/brekety-idealnyj-put-k-zdorovoj-ulybke.html]https://zubypro.ru/brekety-spb/[/url] в Санкт-Петербурге.
Medicine information. Effects of Drug Abuse.
levaquin
All news about medication. Read here.
n a city filled with diversions and excursions, the first question you need to answer is … where am I staying? https://www.pinterest.com/spylasvegas/ Caesars Palace Las Vegas Hotel & Casino presents spectacular rooms, service, and entertainment.
Medicines information sheet. What side effects?
cheap actos
Best trends of pills. Get information now.
Pills information for patients. What side effects can this medication cause?
order lyrica
Some what you want to know about medication. Read information here.
Drug information for patients. Short-Term Effects.
actos rx
Everything information about pills. Get here.
german citizenship maker fake
purchase viagra sale tadalafil for order order tadalafil 5mg pills
Play at the world’s leading Online Casino https://telegra.ph/Kazino-bonusi-un-to-izmanto%C5%A1anas-iesp%C4%93jasIevads-03-31 Explore our online casino games anywhere
Meds information. Long-Term Effects.
levaquin sale
Actual what you want to know about medication. Read here.
Drugs information leaflet. Effects of Drug Abuse.
lisinopril 40 mg
Best about medication. Read here.
Medicament information sheet. Brand names.
tetracycline brand name
Best what you want to know about medicament. Read here.
Play at the world’s leading Online Casino https://www.pinterest.de/kazinolatvija/ Jauns mobilais kazino un pirmais tiessaistes bingo Latvija!
888starz is an online casino that offers players the opportunity to play various gambling games, such as slots, roulette, blackjack, and others, using cryptocurrencies https://twitter.com/888starzlv
The casino is operated by Bittech B.V. and is licensed and regulated by the Government of Curacao. In addition to traditional casino games, 888starz.bet also offers sports betting, live casino games, and virtual sports. The website has a user-friendly interface and supports multiple languages, making it accessible to players from around the world
alfuzosin generic order alfuzosin pill diltiazem 180mg generic
[url=http://levaquin.company/]levaquin cheap price[/url]
Medicine information for patients. Effects of Drug Abuse.
cleocin
Actual news about drugs. Read information now.
Your source for breaking casino news from Latvija https://telegra.ph/Kazino-sp%C4%93%C4%BCu-kl%C4%81sts-888starz-04-01
Our casino news segment compiles all the latest stories and development in the casino industry
схемы заработка в сети интернет
Meds information for patients. What side effects can this medication cause?
levaquin medication
Best what you want to know about drug. Get here.
remedies for ed: cheapest ed pills – mexican pharmacy without prescription
Drug information leaflet. Cautions.
levaquin
Everything trends of medicament. Get information here.
Pills information leaflet. Long-Term Effects.
cost zithromax
All information about medicines. Get information now.
Medicines information sheet. What side effects?
lisinopril 40 mg
Everything trends of medicines. Read here.
erectyle disfunction [url=http://cheapdr.top/#]buy prescription drugs without doctor[/url] buying ed pills online
[url=https://promethazine.best/]where to buy phenergan online[/url]
Meds information leaflet. Cautions.
new shop pharmacy
Everything trends of drugs. Get information here.
Drug information sheet. Brand names.
lioresal rx
Actual about medication. Read here.
Medicament information sheet. What side effects can this medication cause?
levaquin sale
All about drugs. Read information here.
promethazine 25mg brand pharmacy tadalafil order tadalafil 20mg without prescription
Skaties bez maksas TV3, TV3 Life, TV3 Mini, TV6 un 3+ piedavatos serialus, raidijumus un filmas, ka ari sporta parraides un daudz ko citu https://telegra.ph/Liel%C4%81kas-naudas-balvas-un-aizraujo%C5%A1a-telev%C4%ABzijas-%C5%A1ova-programma-Latvij%C4%81-04-02
Skaties Latvijas TV kanalus bezmaksas interneta. Navigacija.
Medicine information leaflet. What side effects can this medication cause?
cleocin
All news about medicament. Get here.
Medicines information for patients. Short-Term Effects.
lisinopril 40 mg
Actual news about meds. Read information now.
Medicines information leaflet. Generic Name.
levaquin online
Everything trends of drug. Read here.
viagra without doctor prescription [url=https://cheapdr.top/#]reasons for ed[/url] cause of ed
Цементная штукатурка
Whatsminer M50 118T — это новое устройство для майнинга криптовалют [url=https://xozyaika.com/majning-v-2023-godu-budushhee-i-perspektivy/]ka3 antminer калькулятор[/url] обеспечивает высокую производительность и эффективность.
n About Me page can be viewed as a snapshot of your entire blogging identity, explaining your ambitions, goals, and background https://social.msdn.microsoft.com/profile/888starz/ he “About Me” page of a blog or website is a personal introduction to your readers. Your profile page so to speak.
Medicament prescribing information. Drug Class.
zovirax
Some news about pills. Get information now.
Shows like Downton Abbey
Meds information for patients. What side effects can this medication cause?
prednisone
Best what you want to know about medication. Read information now.
Pachinko follows four generations of a Korean family who move to Japan amidst Japanese colonization and political warfare https://www.pinterest.jp/pachinkojp/ A beautifully poignant story of identity, sacrifice, and survival; Pachinko is the multigenerational story of a Korean immigrant family’s resilience
buy prescription drugs without doctor [url=https://cheapdr.top/#]canadian drugstore online[/url] ed products
Medicines information sheet. What side effects?
rx vastarel
Everything news about medicine. Read information now.
See More Amazin News Website Daily Worldwide [url=https://sepornews.xyz]Sepor News[/url]
Woodworking has been a staple craft for centuries [url=https://goodmenproject.com/technology/unlocking-the-potential-of-woodworking-with-laser-cutters/]https://goodmenproject.com/technology/unlocking-the-potential-of-woodworking-with-laser-cutters/[/url] but the introduction of modern technology has brought about new advancements in the field.
[url=https://dapoxetinepriligy.store/]dapoxetine buy online canada[/url]
[url=https://strattera247.online/]generic strattera[/url]
[url=http://citalopram.lol/]citalopram 20mg tablets online[/url]
Medicament information leaflet. Long-Term Effects.
cleocin buy
All information about drugs. Read information here.
[url=http://bupropion.gives/]bupropion 300 mg cost[/url]
Drugs information sheet. Drug Class.
cephalexin
Some news about medicines. Get now.
Drug information sheet. What side effects?
prednisone
Everything about medicine. Read here.
Pills information leaflet. Long-Term Effects.
flibanserin
Best what you want to know about medicine. Read here.
Medication information sheet. Brand names.
cialis super active buy
Everything what you want to know about medicines. Read here.
free online casino
[url=http://robaxina.online/]robaxin muscle relaxant[/url]
Medication information for patients. Drug Class.
order neurontin
Some about pills. Get information here.
Medicament information sheet. Long-Term Effects.
cordarone
Some news about meds. Get information here.
Перетяжка мебели становится все более популярным способом обновления интерьера [url=https://peretyazhka-bel.ru/]перетяжка[/url] и продления срока службы любимых предметов.
Pills information. What side effects?
singulair
All what you want to know about medication. Get information here.
cerco viagra a buon prezzo: miglior sito dove acquistare viagra – viagra 100 mg prezzo in farmacia
Pills information leaflet. Brand names.
singulair medication
Everything what you want to know about medicament. Read now.
sildenafilo 50 mg precio sin receta: viagra online cerca de toledo – viagra 100 mg precio en farmacias
SildГ©nafil Teva 100 mg acheter: Viagra Pfizer sans ordonnance – Viagra pas cher inde
Drugs information leaflet. Short-Term Effects.
motrin prices
Everything news about medicine. Read information now.
На сайте krovlya-tmb.ru вы найдете широкий выбор качественных материалов для кровли [url=http://krovlya-tmb.ru/]магазин кровли[/url] предлагаются по выгодным ценам.
https://qiita.com/karnizyishtory
order cetirizine 5mg sertraline online order buy generic sertraline 50mg
Drugs information. Short-Term Effects.
cialis super active
Some news about drugs. Read here.
cenforce 100mg without prescription order glycomet 500mg generic buy metformin 500mg generic
[url=https://happyfamilystore.best/]capsule online pharmacy[/url]
[url=https://malegra.best/]malegra 100 online[/url]
Meds information sheet. Long-Term Effects.
order med info pharm
Best trends of drugs. Read information here.
viagra online spedizione gratuita: viagra online spedizione gratuita – miglior sito dove acquistare viagra
Pills information. Effects of Drug Abuse.
lyrica
Actual what you want to know about meds. Read here.
[url=http://glucophage.best/]glucophage buy uk[/url]
Medication information leaflet. Effects of Drug Abuse.
cheap tetracycline
Actual what you want to know about drugs. Get information now.
Viagra gГ©nГ©rique sans ordonnance en pharmacie: Viagra vente libre pays – Viagra sans ordonnance 24h Amazon
buy atorvastatin 20mg sale order viagra pills order viagra 50mg sale
Drugs information. Brand names.
singulair
Some news about medicine. Read now.
Pills information leaflet. Short-Term Effects.
cleocin
Actual information about medicament. Get information here.
Medication information for patients. Short-Term Effects.
cost stromectol
Some about drugs. Get information here.
Medicines information sheet. Effects of Drug Abuse.
propecia pill
Some what you want to know about medicine. Read information now.
sildenafil 100mg genГ©rico: viagra para hombre precio farmacias – comprar viagra en espaГ±a envio urgente contrareembolso
Viagra pas cher inde: Viagra homme prix en pharmacie – Viagra sans ordonnance pharmacie France
[url=https://flagyla.gives/]where can i get flagyl tablets[/url]
Drugs prescribing information. Cautions.
flagyl
Some what you want to know about drug. Read information now.
Drug prescribing information. Brand names.
cordarone buy
All information about medicines. Read here.
[url=https://disulfiram.best/]buy disulfiram online in india[/url]
Wo kann man Viagra kaufen rezeptfrei: Viagra Generika 100mg rezeptfrei – Viagra rezeptfreie Schweiz bestellen
[url=https://glucophage.gives/]glucophage 500mg cheap[/url]
Medicines information leaflet. Cautions.
lopressor pills
All what you want to know about drugs. Get information here.
Ir daudz un dazadi kazino bonusu veidi, ka piemeram, iepazisanas bonuss, pirmas iemaksas bonuss, kazino bonusi bez depozita https://telegra.ph/888starz-140—-promo-kods–RUBYSKYE-04-09 Latvijas online kazino bonusi registrejoties bez pirmas iemaksas un bez depozita. Aktualie piedavajumi 2023.
[url=https://aurogra.foundation/]cheap aurogra tablets uk[/url]
Medicine information. Short-Term Effects.
cordarone buy
Actual information about medicine. Read now.
Drugs information. Brand names.
colchicine
Some news about medicines. Read information here.
Medicine information. Short-Term Effects.
diltiazem tablets
All what you want to know about medicines. Get here.
Viagra 100mg prix: Viagra pas cher inde – Viagra vente libre pays
Medication information leaflet. Drug Class.
levaquin no prescription
Some about pills. Get information here.
Medicament information sheet. Effects of Drug Abuse.
cost viagra
Some about drug. Read information now.
comprar viagra en espaГ±a envio urgente: comprar viagra online en andorra – se puede comprar sildenafil sin receta
buy tadalafil online tadalafil health store erectile dysfunction medicines
Meds information for patients. Long-Term Effects.
cephalexin
All about drugs. Get information now.
To learn more about [url=https://londonjournal.co.uk/2023/02/23/vladislav-soloviev-biography-economic-expert-embraces-a-new-life-as-a-blogger/]Vladislav Soloviev biography[/url] and his works, visit.
Medicine information. What side effects?
actos
Some about meds. Get here.
cheap cialis online cialis coupons male erection pills
Medication information leaflet. Drug Class.
celebrex
Some news about medicine. Read now.
Vladislav Soloviev is an economic expert, analyst, and blogger [url=https://manchestertimes.co.uk/2023/02/23/vladislav-soloviev-biography-economic-expert-embraces-a-new-life-as-a-blogger/]Vladislav Soloviev biography[/url] born and raised in Moscow in 1973, Vladislav studied at the Moscow Institute of Technology and Management and has evolved over the years as a writer, publishing content on personal blogs and communities on social media.
Drug information. Effects of Drug Abuse.
tadacip
All about pills. Get now.
Medication information. What side effects can this medication cause?
promethazine medication
Best news about medicine. Get information here.
[url=http://dutasteride.cyou/]avodart price usa[/url]
Vladislav Soloviev is undoubtedly showing his versatility [url=https://londonjournal.co.uk/2023/02/23/vladislav-soloviev-biography-economic-expert-embraces-a-new-life-as-a-blogger/]Vladislav Soloviev biography[/url] and ingenuity as the multifaceted individual recently took up a new role as a blogger.
Meds prescribing information. Generic Name.
buspar price
Best trends of medicament. Read here.
Medicine information leaflet. Effects of Drug Abuse.
where can i buy propecia
All what you want to know about pills. Read now.
Pills prescribing information. Generic Name.
propecia buy
All about meds. Read information here.
Medicine information for patients. Long-Term Effects.
maxalt otc
Some news about pills. Get now.
comprar viagra sin gastos de envГo: viagra 100 mg precio en farmacias – se puede comprar sildenafil sin receta
Vladislav Soloviev is undoubtedly showing his versatility and ingenuity as the multifaceted individual [url=https://ukreporter.co.uk/2023/02/23/vladislav-soloviev-biography-economic-expert-embraces-a-new-life-as-a-blogger/]Vladislav Soloviev biography[/url] the talented analyst turned blogger has always channeled his efforts toward the path of success.
Drugs information. Generic Name.
maxalt otc
Some what you want to know about medication. Get information here.
Pills information leaflet. Long-Term Effects.
cialis with dapoxetine without dr prescription
All information about medicine. Get information now.
venta de viagra a domicilio: sildenafil 100mg genГ©rico – viagra para hombre precio farmacias
[url=https://isotretinoina.online/]generic accutane costs[/url]
Medicines information for patients. Cautions.
strattera
Some trends of pills. Get now.
Drugs information. What side effects can this medication cause?
aldactone tablet
Everything information about medicines. Get here.
https://drugswithoutdrprescriptions.com/# canadian pharcharmy online
sildenafilo 50 mg comprar online: viagra para hombre venta libre – sildenafilo cinfa 100 mg precio farmacia
order provigil 200mg online modafinil 100mg pill brand deltasone 40mg
Pills information leaflet. What side effects?
get lexapro
All about medication. Read now.
Drug information leaflet. Drug Class.
lyrica
Best what you want to know about medicines. Get information here.
However, he stands out for delivering quality content to readers, which has endeared thousands of people to his thematic channels, blogs, and networks [url=https://ukherald.co.uk/2023/02/23/vladislav-soloviev-biography-economic-expert-embraces-a-new-life-as-a-blogger/]Vladislav Soloviev biography[/url] with the numbers growing by the day.
Medicine information. Short-Term Effects.
buy lisinopril
Actual news about meds. Get here.
Drug information leaflet. Drug Class.
pregabalin without a prescription
Some news about pills. Get now.
Medicines information sheet. Short-Term Effects.
cephalexin medication
Best trends of medicines. Get here.
[url=http://celexa.charity/]80 mg celexa[/url]
Medicament information leaflet. Cautions.
accutane
Some what you want to know about meds. Read here.
Meds information for patients. Long-Term Effects.
singulair
All trends of medicine. Read information here.
Medication information. What side effects can this medication cause?
lyrica sale
Some what you want to know about drugs. Get information now.
Наркологическая клиника Алкоблок поможет человеку любого возраста [url=https://www.lecheniye-alkogolizma.ru/vyvod-iz-zapoya-na-domu/]вывод из запоя цены[/url] избавиться от алкогольной зависимости на любой стадии развития.
amoxicillin 250mg usa prednisolone 40mg price prednisolone oral
[url=https://toradol.lol/]toradol for migraines[/url]
Medicines prescribing information. What side effects can this medication cause?
cephalexin
Actual information about drug. Get here.
[url=http://hydroxyzine.gives/]atarax 25mg for sale[/url]
Существует множество тематических каналов в Telegram, и каждый может найти то, что ему по душе. Некоторые из лучших телеграм каналов включают https://t.me/s/casino_azartnye_igry/258
Кроме того, в Telegram существует функция каналов, где пользователи могут подписываться на различные тематические каналы, где публикуются новости, статьи, видео и другой контент.
sildenafilo 100mg precio espaГ±a: sildenafilo 50 mg precio sin receta – sildenafilo 100mg farmacia
Pills information for patients. Cautions.
retino-a cream 0.05
Some what you want to know about medicines. Get now.
https://drugswithoutdrprescriptions.com/# canada pharmacy
[url=https://aurogra.best/]cost of aurogra 100[/url]
Drugs prescribing information. What side effects can this medication cause?
neurontin without a prescription
All information about drugs. Get now.
[url=https://www.ossetia.tv/2023/01/19/sharper-igor-strehl-from-vtb-was-defrauded-by-andrey-kochetkov-and-laundered-russian-money-in-austria/]https://www.ossetia.tv/2023/01/19/sharper-igor-strehl-from-vtb-was-defrauded-by-andrey-kochetkov-and-laundered-russian-money-in-austria/[/url]
viagra online cerca de bilbao: sildenafilo 50 mg comprar online – comprar viagra en espaГ±a envio urgente contrareembolso
Biography and important milestones – [url=https://nyweekly.com/business/vladislav-soloviev-new-research-blogger/]Vladislav Alexandrovich Soloviev[/url] blogger on the most successful careers in the modern business.
cefixime uses
Drugs information leaflet. Cautions.
cheap mobic
Best about medicament. Read information now.
[url=http://levitraf.online/]cheap generic levitra[/url]
how to get generic cleocin pill
[url=https://clopidogrel.best/]clopidogrel discount coupon[/url]
cordarone 200 mg tablet uk
Drug information leaflet. Long-Term Effects.
baclofen generic
Some about drugs. Read information here.
https://viasenzaricetta.com/# viagra generico in farmacia costo
doxycycline capsules prescription
fluoxetine webmd
Medicines information. Long-Term Effects.
paxil
Best information about medicament. Read here.
levaquin pill size
Pinterest is a visual social media platform that is perfect for curating and sharing ideas for various topics, including casino-themed images. https://www.pinterest.com/igamingskye/ Whether you are planning a casino party or simply enjoy the glitz and glamour of casino culture, creating a Pinterest board filled with casino-themed images can be a fun and creative way to express your interests. In this article, we’ll provide some tips and ideas for creating a casino-themed Pinterest board that stands out.
Medicine prescribing information. Generic Name.
lyrica
Everything news about drugs. Read information here.
lisinopril max dose
prednisolone 20mg drug buy prednisolone 5mg generic furosemide 40mg price
Medicine prescribing information. Drug Class.
rx avanafil
Actual what you want to know about drugs. Read information here.
[url=https://finpecia.best/]finpecia[/url]
[url=https://pharmacyonline.charity/]canadian pharmacy uk delivery[/url]
prednisone drug interactions
buy protonix
Atverti tiessaistes kazino https://playervibes.lv/blog/
tas ir tiessaistes platformas, kas piedava speletajiem iespeju piedalities dazadas azartspeles, piemeram, automatos, rulete, blekdzeka un pokera speles. Latvija pastav vairakas tiessaistes kazino, kas piedava plasu spelu klastu un dazadas pievilcigas bonusa piedavajumus speletajiem.
Medicine information. Brand names.
lioresal otc
Some news about pills. Read information now.
https://viasenzaricetta.com/# cialis farmacia senza ricetta
cialis farmacia senza ricetta [url=https://viasenzaricetta.com/#]viagra originale recensioni[/url] viagra online spedizione gratuita
Микрокредит с правом вождения [url=https://zhana-credit.kz/]Автоломбард Алматы[/url] микрокредит без права вождения.
https://skyflypro.com/profile.php?do=profile&from=space&userinfo=madeleine_porter.139846&action=view&op=userinfo
where to buy cefixime
Medicines information sheet. Generic Name.
lyrica brand name
Actual trends of drug. Read information here.
buy cleocin online cheap
Medicines information sheet. Brand names.
buy generic neurontin
Best about drugs. Read information now.
best price for colchicine
Drugs information. What side effects?
cephalexin
Everything about drugs. Read now.
автор24
Medicines prescribing information. Effects of Drug Abuse.
paxil cost
Some what you want to know about drug. Get information here.
[url=https://triamterene.cyou/]triamterene 37.5 mg[/url]
cordarone side effects in women
На этом сайте можно скачать в mp3 любую песню бесплатно [url=https://xn—nazami-1fga3gzbw0b.kytim.com/]https://xn—nazami-1fga3gzbw0b.kytim.com/[/url] Кутим.ком – огромная база песен с удобным поиском, прослушиванием и скачиванием.
doxycycline 100mg pil
cialis farmacia senza ricetta [url=https://viasenzaricetta.com/#]miglior sito dove acquistare viagra[/url] miglior sito dove acquistare viagra
Рекомендую всем обращаться к [url=https://psihoterapevt.com.ua/]психотерапевт онлайн[/url] по любым вопросам.
fluoxetine brand canada
[url=https://indocina.gives/]indocin 25mg cap[/url]
Рекомендую всем обращаться к [url=https://psihoterapevt.com.ua/]психотерапевт онлайн[/url] по любым вопросам.
[url=https://chloroquine.charity/]chloroquine phosphate uk[/url]
Meds information leaflet. What side effects can this medication cause?
valtrex
Actual news about medicine. Read now.
purchase vibra-tabs online buy augmentin 375mg online cheap augmentin 1000mg ca
Drugs information leaflet. Brand names.
avodart cost
Actual trends of meds. Read now.
Medicament information for patients. What side effects can this medication cause?
propecia brand name
All news about pills. Read now.
can you buy lisinopril without rx
Pills information. Short-Term Effects.
minocycline medication
Everything trends of medication. Get information now.
http://cytotecsale.pro/# buy cytotec in usa
https://kiev.forumotion.me/t7894-topic#19604
Наша компания занимается проектированием и изготовлением весового оборудования уже более 20 лет [url=https://balticvesy.ru/]https://balticvesy.ru/[/url] что позволяет нам гарантировать высочайшее качество продукции и услуг.
Drugs information sheet. Effects of Drug Abuse.
can i order flibanserin
All about drug. Get information here.
Medication information. Cautions.
promethazine rx
Some information about drug. Get information here.
singulair generic over the counter
Pills information for patients. Effects of Drug Abuse.
promethazine buy
Best information about pills. Get information now.
грузовые машины маз от предприятии минска [url=http://maz-sajt.ru]maz[/url] информация о грузовой и прицепной технике маз
Super Lawyers provides lawyer ratings of selected lawyers and helps you find the rated https://social.msdn.microsoft.com/Profile/JonathanSterling Get free legal advice and find a free or low-cost lawyer
Pills information leaflet. Effects of Drug Abuse.
mobic
All about pills. Get information now.
albendazole for sale order provera 10mg pills order medroxyprogesterone without prescription
Pills information leaflet. Effects of Drug Abuse.
dutasteride buy
Actual information about pills. Get now.
Pills information. What side effects?
lyrica
Everything news about drug. Get information now.
Get It ShippedSign in CHANEL CONNECTS Extensive color range Pigmented and versatile formulas THE house of chanel Sephora Contour Eye Pencil is an eyeliner that retails for $10.00 and contains 0.04 oz. ($250.00 per ounce). There are 52 shades in our database. Get It ShippedSign in boutique services CHANEL CONNECTS Our award-winning 24/7 Eye Pencil is truly eye-conic. Long-Lasting + hydrating + insane range of high impact colors. #1 for a reason. How do you remove a long-wear waterproof pencil? Use a cotton pad with a biphase product to easily remove your waterproof makeup. If it isn’t obvious I like them lol. It’s March we need a green one. Easter/Spring is around the corner let’s get some pastels….literally just make a rainbow collection out of these.
https://grailoftheserpent-forum.com/community/profile/marilynnjeffrey/
No one can forget them hairstyle, hair and for style. Must find out these human hair color, Great & nicetest very short hair styles for older women.Accomplished face, beauty and latest fashion for young ladies posted by Victor Bozeman You can color hair of any length. Very short hair may be the easiest to color since there is so little of it. Make sure you care for your scalp throughout the process since it may be very sensitive to the dyes, bleaches, and chemicals that you or your stylist have to use to get the desired color. This is a quirky and daring look with colors for short hair. The haircut comes as an undercut – shaved to the sides and hair on the top. The hair is styles partly, which means each portion is styled in a different direction. The color is the same, light pastel cream, with a dose of pink. The side parts are deep and accented.
actos off-label use
Pills information for patients. Generic Name.
maxalt
Some what you want to know about drug. Get here.
[url=http://diclofenac.boutique/]where can you buy voltaren gel[/url]
https://www.openstreetmap.org/user/arshinmsk
[url=http://lasix.party/]lasix 20mg tablet price[/url]
Drugs information. Long-Term Effects.
fluoxetine
Actual trends of medicament. Get here.
[url=http://disulfiram.sbs/]antabuse 400mg tablets[/url]
ashwagandha supplement
Запчасти на Газель с гарантией отличного качества – [url=https://мир3302.рф/catalog/bamper-na-gazel-peredniy/]https://мир3302.рф/catalog/bamper-na-gazel-peredniy/[/url] в компании “МИР-3302”.
юрист по экономическим преступлениям
order praziquantel sale order cyproheptadine 4mg online buy cyproheptadine 4 mg online cheap
Pills prescribing information. Long-Term Effects.
aldactone order
Actual what you want to know about pills. Read information here.
Запчасти на Газель с гарантией недорого – [url=https://мир3302.рф/catalog/bamper-na-gazel-peredniy/]https://мир3302.рф/catalog/bamper-na-gazel-peredniy/[/url] в компании МИР-3302.
Drugs information. Drug Class.
lyrica rx
All news about medicament. Get here.
Medicament information for patients. What side effects can this medication cause?
propecia cost
All what you want to know about meds. Read information now.
Chessmaster, a series of chess programs developed and released by Ubisoft. It is the best-selling chess franchise in history https://social.msdn.microsoft.com/Profile/JoshiChessmaster Chessmaster 3000 provides a strong chess opponent with 168 openings and different types of playfields (2D, 3D, and War Room)
Medicine information sheet. Short-Term Effects.
viagra online
Actual trends of meds. Get now.
Pills information. Drug Class.
cialis soft
Everything information about drug. Read now.
[url=https://stromectol.foundation/]cost of ivermectin pill[/url]
Meds information. Effects of Drug Abuse.
cordarone online
Best trends of medicine. Get here.
cheap lisinopril metoprolol medication buy metoprolol 50mg generic
Medicament information. Effects of Drug Abuse.
can you buy fluoxetine
Best news about medicament. Get information now.
[url=http://albuterol2023.online/]albuterol tablets without prescription[/url]
Drugs information leaflet. Generic Name.
xenical
Actual about meds. Get here.
pregabalin over the counter buy generic pregabalin online priligy 90mg pill
[url=http://ciprociprofloxacin.charity/]cipro online no prescription in the usa[/url]
Medicine prescribing information. Long-Term Effects.
zoloft
All what you want to know about medication. Read now.
[url=http://trental.cyou/]buy trental 400 mg[/url]
[url=https://synthroidb.com/]synthroid generic price[/url]
doxycycline hyclate 100 mg pneumonia
Meds prescribing information. Short-Term Effects.
flagyl
Actual information about meds. Get information here.
panic disorder treatment
Drug information for patients. Effects of Drug Abuse.
how can i get prednisone
Some what you want to know about drug. Get information now.
[url=https://piroxicam.cyou/]feldene 10 mg tablets[/url]
Medication information for patients. Cautions.
prednisone
Actual information about pills. Read information here.
Drugs prescribing information. What side effects?
cheap cialis
Best news about medicines. Get information here.
[url=http://nexium.gives/]canadian drug prices nexium[/url]
buy generic orlistat zyloprim for sale online zyloprim 300mg usa
Drug prescribing information. What side effects can this medication cause?
flagyl
Best news about medicines. Read now.
Drug information for patients. Long-Term Effects.
how to buy fluoxetine
Actual news about pills. Get here.
Meds information for patients. Cautions.
propecia cheap
Everything trends of medicine. Read information now.
Turn Your Idea Into Life With an Expert Level PHP Developer USA. Andersen’s PHP Developers Build Solutions in Accordance With the Highest Standards https://social.msdn.microsoft.com/Profile/Jarvis365 Hire the best freelance PHP Developers in the United States
Drugs information. Short-Term Effects.
priligy pill
Some what you want to know about medicament. Get information here.
Medicament information. Short-Term Effects.
neurontin without rx
Actual news about pills. Read here.
Запчасти на Газель напрямую от завода недорого с гарантией – [url=https://vladnews.ru/2022-08-12/206016/meshki_hraneniya]https://vladnews.ru/2022-08-12/206016/meshki_hraneniya[/url] в компании МИР-3302.
Medicine prescribing information. Generic Name.
cephalexin
Actual information about medicine. Read here.
http://cytotecsale.pro/# purchase cytotec
Drug information leaflet. Long-Term Effects.
colchicine
Some about medicines. Read now.
Medicines information. Long-Term Effects.
colchicine tablet
All news about pills. Get now.
[url=https://cytotec.charity/]misoprostol 200 mcg price[/url]
[url=https://silagra.lol/]buy silagra 100 mg[/url]
Drugs information leaflet. What side effects?
lyrica
Some news about medicine. Read information here.
If you haven’t played Chessmaster 9000 or want to try this educational https://social.msdn.microsoft.com/Profile/AxiaFi Larry Christiansen lost the 3rd game where he sacrificed a rook to get a strong attack. 55…Rh5! would have been probably winning!
Medicament information. Drug Class.
flibanserina
Best news about drugs. Read information now.
hairy bikini porn
Medicine information. Long-Term Effects.
proscar tablet
Some about meds. Read now.
Pills prescribing information. Drug Class.
order propecia
Best what you want to know about meds. Read information here.
Pills information leaflet. Drug Class.
can you buy neurontin
Best information about meds. Get now.
[url=https://doxycyclinedx.online/]doxycycline tablets 100mg[/url]
Medicament information leaflet. What side effects can this medication cause?
propecia medication
Best information about meds. Read here.
Apes platform for [url=https://nft-monkey2.info/index.php/2023/04/26/monkey-nft/]Monkey NFT[/url] here!
Drugs prescribing information. Drug Class.
cialis super active
Everything news about meds. Get information here.
Medicament information for patients. Effects of Drug Abuse.
how to buy cephalexin
Actual trends of drug. Read here.
[url=https://flomax.ink/]flomax over the counter uk[/url]
casino-fortuna-play.name
Pencil with Brush You get 1 free item with every product purchased. It looks like you can still add more free item(s) to your cart. What would you like to do? Rimmel London Professional Eyebrow Pencil BLACK BROWN 004 : Step 1: Brush through and fluff up eyebrows with the Professional Eyebrow Pencil’s built-in brush.Step 2: Etch into brows to fill in any gaps.Step 3: Follow your natural brow shape as a guide and define your arches, lengthen brows and sculpt, depending on your look. العربية After learning that well-shaped eyebrows make all the difference in giving the face an overall balanced and polished look, I went to do some casual research on which are the best eyebrow pencils. I wanted something cheap and of reasonably quality and when I saw recommendations for Rimmel London Professional Eyebrow Pencil, I was elated! We have Rimmel in Singapore! YES!!!
https://mainebrowandlash.com/product/february-12-2023-windham-me/
Treat someone special to a monthly subscription, or a one-off Lengbox Elevate your routine with the tried-and-true products of 2022 ✨ Aimosha Co.,Ltd 3F, 1-1, Hangaro 3-ga, Yongsan-gu Seoul 04370 · South Korea Receive 8 full size and deluxe sample size Korean beauty products each month. Skincare is an increasingly popular category of beauty product, and it can also be one of the most expensive. New skincare trends emerge all the time, and it’s hard to keep up if you’re not constantly reading articles on the subject. Skincare subscription boxes can help you keep up with new products and new discoveries, and you’ll usually get big discounts on products, too. Here are some of the best boxes for trying new skincare products and getting great deals.
https://doxycyclinesale.pro/# generic for doxycycline
incredible fuck
Drugs information for patients. Generic Name.
flagyl
Actual about medication. Read information here.
Drug information for patients. Effects of Drug Abuse.
neurontin buy
Everything information about drug. Read now.
Drugs information. Effects of Drug Abuse.
how to get priligy
Actual information about drugs. Read information now.
Medicine information. Brand names.
get pregabalin
Some about medicine. Get information now.
Meds information sheet. What side effects can this medication cause?
cialis super active buy
Some trends of medicines. Read information here.
https://www.gsu.by GSU
Medicament information. Short-Term Effects.
zoloft no prescription
Everything information about medication. Read here.
Medication information leaflet. Long-Term Effects.
buy effexor
Actual what you want to know about meds. Get information now.
GSU https://www.gsu.by
Medication prescribing information. Drug Class.
lopressor buy
Some what you want to know about drug. Get here.
Meds information. Effects of Drug Abuse.
amoxil
Best trends of medicament. Read here.
Художественная роспись стен в квартире, детской или офисе от профессиональной команды художников [url=https://mg.wikipedia.org/wiki/Sary]роспись стен обучение[/url] оформим любое помещение и сделаем эскизы.
[url=http://albenzaalbendazole.foundation/]buy albendazole tablets[/url]
Pills information for patients. Effects of Drug Abuse.
amoxil
All what you want to know about drug. Read information here.
Drugs information. Generic Name.
zoloft
Some trends of medicines. Get now.
doxycycline 40 mg generic cost
Medicament information leaflet. Brand names.
where buy fluoxetine
Everything what you want to know about drugs. Get information now.
Each Nissan Certified Pre-Owned vehicle comes with the innovation and excitement you expect from Nissan. To that, we add a rigorous certification process and the peace of mind of a 7-year / 100,000 limited powertrain warranty* and roadside assistance so that you can explore with confidence. Our dedication to your daily drive continues long after you drive off our lot. We’re here to look out for any maintenance needs your Nissan may have. Our team of factory-trained and -certified technicians knows all the ins and outs of each Nissan model. So, schedule a service appointment online and you’ll be back on the road in no time. By submitting your request, you consent to be contacted at the phone number you provided – which may include autodials, text messages and/or pre-recorded calls. By subscribing to receive recurring SMS offers, you consent to receive text messages sent through an automatic telephone dialing system, and message and data rates may apply. This consent is not a condition of purchase. You may opt out at any time by replying STOP to a text message, or calling (888) 576-1136 to have your telephone number removed from our system.
https://purygold.com/test/bbs/board.php?bo_table=free&wr_id=4231
On road prices of Hyundai Alcazar in New Delhi starts from ₹19,77,188 to ₹24,50,690 for Alcazar Prestige Executive D(Diesel, 1493) and Alcazar Signature D AT DT(Diesel, 1493) respectively . This is a general overview, more details on driving patterns, usage scenario,s etc are required to further close in on the best option. This SUV comes with two engine options; a 2.0L Petrol MPi engine and a 1.5L Diesel CRDi engine, each having six-speed manual and automatic transmission options. The engines contain four inline cylinders with four valves per cylinder operated by a dual overhead camshaft. The petrol engine puts out a maximum power and torque of 157bhp at 6500 rpm and 191 Nm at 4500 rpm respectively. On the other hand, the Diesel engine produces a maximum power of 113 bhp at 4000 rpm and a peak torque of 250 Nm at 1500 rpm. Talking about the Alcazar Mileage, it is 18.1 km/l for diesel variants and 14.20 km/l for petrol variants as asserted by ARAI.
[url=http://dexamethasone2023.com/]dexona 4mg tablet[/url]
Medicine information for patients. What side effects?
lyrica
Some news about pills. Get information now.
best canadian pharmacy to order from [url=https://canadapharm.pro/#]legal to buy prescription drugs from canada[/url] canadian pharmacy 24
https://dekormaster.ru/voprosy-i-otvety.html#comment-14083
En iyi porno sitesine hos geldiniz [url=http://trhamster.click/]http://trhamster.click/[/url] Burada farkl? kategorilerdeki c?plak kad?nlarla bir suru seks videosu toplanm?st?r.
indian pharmacy paypal: top 10 online pharmacy in india – best india pharmacy
Drugs prescribing information. What side effects can this medication cause?
zofran buy
All what you want to know about medicament. Get information here.
Drug information. Long-Term Effects.
viagra soft cost
Everything what you want to know about pills. Get here.
Medication information sheet. Short-Term Effects.
zoloft
Best what you want to know about drug. Get now.
Pills information sheet. Brand names.
can i order priligy
Best information about medicament. Get here.
Meds information. Long-Term Effects.
pregabalin
Best what you want to know about drugs. Get now.
Nykyaan Virtanen on edelleen aktiivinen shakinpelaaja ja matkustaa ympari maailmaa kilpailemassa Han on myos innokas opettaja ja jakaa tietojaan ja taitojaan opiskelijoille ympari Suomea. Hanen elamansa on omistettu shakille, ja han jatkaa kehittymistaan ja kilpailemista shakissa niin kauan kuin mahdollista.https://social.msdn.microsoft.com/Profile/Nettikasinot
Вы можете купить справку для ГИБДД в Москве [url=https://medic-spravki.info]купить справку для водительского удостоверения[/url] в клинике Анна Мир без прохождения врачей и доставкой.
Drug information leaflet. Generic Name.
zoloft online
All about drug. Read information now.
Drug information for patients. What side effects can this medication cause?
zoloft medication
All information about pills. Get here.
I’m searching for [url=https://ciproe.com/]Cipro antibiotic where to buy[/url] online.
Pills information for patients. What side effects can this medication cause?
cialis super active generics
Actual news about meds. Get now.
Medicines information for patients. What side effects can this medication cause?
zofran
Everything trends of medicine. Read information here.
mexican border pharmacies shipping to usa: reputable mexican pharmacies online – mexico drug stores pharmacies
Medicament information leaflet. Generic Name.
synthroid no prescription
Everything information about medication. Read information now.
Drugs information sheet. Long-Term Effects.
lyrica
Everything about medication. Get information here.
Вы можете купить справку 086/у в Москве [url=https://medic-spravki.org]купить справку 086/у в Москве[/url] в клинике Анна Справкина без прохождения врачей и доставкой.
Can [url=https://tadalafil.foundation/]Tadalafil 40[/url] be taken with other medications?
buy tamsulosin 0.4mg generic cost spironolactone how to buy aldactone
Muutaman nettikasino huijauksen jalkeen paatin perustaa taman sivuston, jotta sinunkin olisi helppo paikantaa kaikki luotettavat suomalaiset nettikasinot. https://chessmaster25.s3.amazonaws.com/nettikasinot.html Miten nettikasinot toimivat? Nettikasinoilla pelaaminen on todella helppoa.
buy priligy in australia [url=https://dapoxetinepriligy.foundation/]super avana 200[/url] priligy dapoxetine
Medicines information leaflet. Short-Term Effects.
seroquel
Best what you want to know about medicines. Read information here.
https://www.sarbc.ru/link_articles/5-preimushestv-posutochnoj-arendy-kvartiry.html
Medicine prescribing information. Short-Term Effects.
rx sildenafil
Best trends of drugs. Get information here.
https://omsk-news.net/other/2023/04/23/477905.html
Pills prescribing information. Long-Term Effects.
neurontin buy
Actual information about meds. Read here.
Crypto casinos work a lot like any other online casinos https://cryptoskye.s3.amazonaws.com/crypto-casinos.html One of the advantages we like best here at CryptoCasinos is that virtual currencies such as Bitcoin are decentralized.
buy cymbalta generic glipizide 5mg without prescription piracetam generic
The internet has made it easier than ever to [url=http://tadalafil.foundation/]buy generic tadalafil online[/url], so why not take advantage?
A Super profile for all the Super things you do. Keep pushing, keep creating, and keep believing in yourself. https://social.msdn.microsoft.com/Profile/xrumergsa Every step you take
Embark on a flavorful journey with [url=https://pablo.fun/]pablo[/url] and savor the enticing selection of premium snus!
Discover the latest trends and blends in the world of [url=https://snus1.chat/]snus[/url]. Our premium collection of flavors will take you on a journey of indulgence and satisfaction like never before!
Discover the world of [url=https://snus1.bio/]snus[/url] with our premium collection of flavors and blends! Whether you prefer strong or mild snus, we have something for every taste bud. Come explore our selection and indulge in the ultimate snus experience.
betnovate 20gm oral order betnovate 20gm without prescription buy itraconazole sale
canadian pharmacy cheap cialis [url=https://cialisip.online/]generic cialis online prescription[/url] best generic cialis online
top online pharmacy india: india pharmacy – india online pharmacy
mexico pharmacies prescription drugs [url=https://mexicopharm.pro/#]п»їbest mexican online pharmacies[/url] mexican rx online
Medicines prescribing information. Cautions.
how can i get lopressor
Actual information about medicines. Get here.
Gama Casino – новое онлайн-казино для игроков из России и других стран мира – [url=http://sad29.cherobr.ru/files/pgs/zahvatuvaushee_onlayn_kazino_gama__bezopasnost__raznoobrazie_i_mnozghestvo_igr.html]гамма казино[/url] можем выделить быстрые выплаты, скорую работу поддержки и минимальный набор документов для верификации.
buy combivent 100mcg pill order zyvox online cheap linezolid 600 mg sale
Experience the rich and diverse world of [url=https://snus1.ink/]snus[/url], with our exclusive range of flavors and blends. Whether you are a seasoned connoisseur or new to the snus scene, we have something to offer for everyone. Our premium quality products are crafted with the finest ingredients, to provide you with a truly exceptional snus experience. So, why wait? Visit us at snus1.ink today and embark on your journey of snus exploration!
Gama Casino – новое онлайн-казино для игроков из России и других стран мира – [url=http://korzina74.ru/images/pages/?gama_kazino___oficialnuy_sayt_igrovogo_zavedeniya.html]гамма казино[/url] можем выделить быстрые выплаты, скорую работу поддержки и минимальный набор документов для верификации.
Japan approves building of first casino https://social.msdn.microsoft.com/Profile/kuriputokajino For the Osaka casino, Japanese citizens will be restricted to just three visits per week, or 10 times within a 28-day period.
Experience the finest collection of [url=https://pablo1.pro/]pablo snus[/url] flavors and elevate your snus game to a whole new level! Our premium range of snus is sure to satisfy your taste buds and keep you coming back for more. Join our community today and be a part of the world of pablo snus!
Medicament information for patients. Brand names.
viagra otc
Actual about medicines. Get information here.
200 mg doxycycline: how to order doxycycline – buy doxycycline monohydrate
http://hpclub.ru/11392/
robaxin cost uk [url=http://robaxin.charity/]robaxin drug[/url] robaxin 750 750 mg
fake program residence documents
progesterone for sale online progesterone 200mg us olanzapine tablet
Step up your fashion game with [url=https://pablo1.store/]pablo[/url]. Our latest collection of trendy and affordable clothing will make you stand out from the crowd.
best online pharmacies in mexico: mexico drug stores pharmacies – mexico drug stores pharmacies
Oletko jo kokeillut [url=https://niikotinipussit.fun/]nikotinipusseja[/url]? Jos et, nyt on korkea aika. Meilla on laaja valikoima eri makuja ja vahvuuksia, jotka tarjoavat vaihtoehdon perinteisille tupakkatuotteille. Tilaa nyt ja nauti nopeasta toimituksesta ja huippuluokan asiakaspalvelusta.
Tule tutustumaan [url=https://niikotinipussit.bio/]niikotinipussit[/url]-valikoimaamme ja loyda uusi suosikkisi. Meilla on laaja valikoima eri makuja ja vahvuuksia, jotka takaavat nautinnollisen kayttokokemuksen. Tilaa nyt ja nauti nopeasta toimituksesta seka ammattitaitoisesta asiakaspalvelusta.
Pills information sheet. Long-Term Effects.
paxil price
Everything what you want to know about pills. Get information here.
zithromax 500 mg lowest price online: zithromax 250 mg – zithromax over the counter
In addition to her husband, she is survived by two sons, Lewis Koon, and Luis Martinez https://social.msdn.microsoft.com/Profile/VinettaMartinez This Atlanta-based pop-up and private dinner company
Испортилось любимое кресло? [url=https://obivka-divana.ru/]ремонт и перетяжка мягкой мебели[/url] – Дорогой диван потерял первоначальный привлекательный вид?
Haluatko kokeilla [url=https://niikotinipussit.ink/]nikotiinipussit[/url]? Tarjoamme erilaisia makuja ja vahvuuksia, jotka tarjoavat vaihtoehdon perinteisille tupakkatuotteille. Tilaa nyt ja nauti nopeasta toimituksesta ja hyvasta asiakaspalvelusta.
Oletko koskaan miettinyt vaihtaa tupakointitapasi? [url=https://niikotinipussit.shop/]Nikotiinipussit[/url] tarjoavat terveellisemman vaihtoehdon perinteisille tupakkatuotteille. Meilla on laaja valikoima erilaisia makuja ja vahvuuksia, joten loydat varmasti itsellesi sopivan vaihtoehdon. Tilaa nyt ja nauti nopeasta toimituksesta seka laadukkaasta asiakaspalvelusta.
nateglinide 120 mg brand order atacand 16mg generic order generic candesartan 8mg
Meds information for patients. Long-Term Effects.
synthroid
Best news about pills. Read here.
buy antibiotics: buy antibiotics over the counter – buy antibiotics from canada
generic nebivolol 5mg order bystolic 20mg without prescription clozapine 100mg uk
Предлагаем Вам [url=https://fixikionline.ru/]Мультфильмы наблюдать он-лайн[/url] сверху нашем сайте
Sharper Igor Strehl from VTB was defrauded by Andrey Kochetkov – [url=https://www.ossetia.tv/2023/01/19/sharper-igor-strehl-from-vtb-was-defrauded-by-andrey-kochetkov-and-laundered-russian-money-in-austria/]https://www.ossetia.tv/2023/01/19/sharper-igor-strehl-from-vtb-was-defrauded-by-andrey-kochetkov-and-laundered-russian-money-in-austria/[/url] and laundered Russian money in Austria.
[url=https://multfilmion.ru/]Лучшие мультики онлайн[/url]
buy cipro: buy cipro online canada – antibiotics cipro
Looking to try [url=https://disposable-vape.fun/]disposable vape[/url]? We provide an extensive range of flavors and strengths, allowing you to find an enjoyable alternative to traditional tobacco products. Order now and enjoy fast delivery and outstanding customer service.
best online pharmacies in mexico: mexico drug stores pharmacies – medicine in mexico pharmacies
buy antibiotics from india: buy antibiotics from canada – over the counter antibiotics
Учащимся [url=https://multfon.ru/]Школа 22 октябрьский[/url]
Жириновский что касается [url=https://zhirinovskiy2012.ru/]ДНР а также ЛНР[/url]
Step into the world of exquisite [url=https://snus1.net/]snus[/url] flavors, handpicked and curated for the ultimate snus experience that you deserve!
Medicament prescribing information. Brand names.
get clomid
Some news about medicament. Get here.
Мы разрабатываем приложения всех типов – [url=https://exadot.uz/services/mobile-app-development]Разработка мобильных приложений в Ташкенте[/url] – высокая масштабируемость.
zocor without prescription order valtrex 1000mg without prescription viagra tablet
Medicament information. Effects of Drug Abuse.
priligy
Everything about drugs. Read now.
Drugs information for patients. What side effects?
buy viagra
Actual what you want to know about medicament. Get information here.
http://b3.zcubes.com/v.aspx?mid=11293487
Только не надо говорить, что [url=https://ogorod42.ru/sad-i-ogorod-2023-sovety-ogorodnikam/]советы огородникам[/url] в 2023 году не нужны! Лайфхаки очень даже помогают хорошему урожаю!
phenergan gel cost [url=https://phenergan.ink/]phenergan on line[/url] phenergan tablets over the counter
can i buy ventolin over the counter in nz [url=http://albuterol.ink/]purchase albuterol online[/url] ventolin 10 mg
order tegretol sale order ciplox 500 mg online cheap buy lincocin 500mg without prescription
top 10 online pharmacy in india: best india pharmacy – indian pharmacies safe
buy generic zithromax no prescription: zithromax price canada – where to buy zithromax in canada
cipro 500mg best prices: where can i buy cipro online – ciprofloxacin mail online
flomax cost without insurance [url=http://aflomax.com/]cheapest flomax[/url] buy flomax uk
[url=http://nexium.foundation/]nexium medication[/url]
Medicines information sheet. Drug Class.
can i get zoloft
All news about medication. Get information now.
Gama Casino — это новейшее онлайн-казино, появившееся в Интернете, и оно наверняка понравится игрокам, которые ищут новый способ развлечься – [url=https://minix-us.ru]бонусы Гама казино[/url]
Drugs information sheet. Generic Name.
prednisone medication
All news about drug. Get now.
reputable mexican pharmacies online: buying prescription drugs in mexico online – mexican rx online
Drugs information leaflet. What side effects?
propecia without insurance
All about medicament. Get here.
Cat Casino лучший сайт для игры. Играй в кэт на официальном сайте и зарабатывай деньги. Быстрый вывод и большие бонусы для каждого игрока. – [url=https://sopka-restaurant.com/]cat вход[/url]
proscar hair growth [url=https://proscar.cyou/]proscar mexico[/url] how much is brand name proscar
[url=http://ampicillin.gives/]ampicillin 500mg[/url]
zithromax coupon: can i buy zithromax over the counter – buy cheap generic zithromax
Medicine information. Drug Class.
lisinopril
All what you want to know about medicines. Get information now.
indian pharmacy: reputable indian pharmacies – india pharmacy
order cialis 40mg free tadalafil buy generic sildenafil 100mg
canadian pharmacy coupon [url=http://pharmacyonline.directory/]online pharmacy viagra[/url] online pharmacy pain relief
motilium no prescription [url=https://motiliumtab.shop/]motilium tablet 10mg[/url] purchase motilium online
Is there a way to get a discount on [url=http://metforminv.com/]metformin tablet 500mg price[/url]?
Medication information leaflet. Long-Term Effects.
avodart
Everything about medication. Get now.
Everyone loves it whenever people come together and share views.
Great website, continue the good work! Life Experience Degree
[url=https://fixikionline.ru/]с чем можно приготовить макароны[/url]
Meds information leaflet. Brand names.
motrin
Some news about drug. Get here.
Казино Gama — это отличный вариант для игроков любого уровня благодаря впечатляющему выбору игр и щедрому приветственному бонусу – [url=https://wpia.ru/]гамма казино вход в личный кабинет[/url]
http://overthecounter.pro/# over the counter health and wellness products
antacids over-the-counter [url=http://overthecounter.pro/#]over the counter medication[/url] rightsourcerx over the counter
https://overthecounter.pro/# over the counter acid reflux medicine
Pills information leaflet. Drug Class.
sildenafil generics
All what you want to know about medication. Read here.
http://overthecounter.pro/# united healthcare over the counter essentials
последние новости ф к динамо киев [url=https://onlinenovosti.ru/budet-li-novaya-mobilizatsiya-deputat-gosdumy-vnes-konkretnoe/]новости про крым сегодня[/url] венесуэла новости последние
Drugs information for patients. Drug Class.
fosamax
Best what you want to know about medication. Get information here.
Drug information leaflet. Drug Class.
seroquel
Best trends of meds. Read information now.
[url=http://amoxicillin.skin/]pharmacy prices for amoxicillin[/url]
https://overthecounter.pro/# over the counter appetite suppressant
Pills information. Generic Name.
promethazine cost
Actual information about pills. Read now.
where can i buy finasteride [url=https://finpecia.download/]finasteride brand name[/url] finpecia 1mg
[url=https://diclofenac.charity/]diclofenac otc[/url]
Looking for an easy and convenient way to enjoy vaping? Check out our selection of [url=https://disposable-vapes.gay/]disposable vapes[/url] with a wide variety of flavors and nicotine strengths. Whether you are new to vaping or an experienced user, our disposable vapes offer a satisfying alternative to traditional tobacco products. Order now and enjoy fast delivery and excellent customer service.
metronidazole over the counter: over the counter pill – best over the counter sleep aid
estradiol price prazosin tablet buy minipress 1mg online cheap
Regular monitoring is required to ensure that [url=http://clomid.africa/]Clomid 50[/url] is working correctly.
Have you considered switching to a [url=https://disposable-vapes.fun/]disposable vape[/url]? We provide a plethora of options when it comes to flavors and strengths, enabling you to discover a satisfying alternative to conventional tobacco products. Place your order today for swift delivery and superior customer service.
buy amoxicillin over the counter us [url=https://amoxicillin.science/]how much is amoxicillin prescription[/url] amoxicillin 500 mg capsule
Meds information sheet. Drug Class.
cialis super active
Everything about medicine. Read information here.
Tutustu [url=https://nikotiinipussi.fun/]nikotiinipussit[/url]-maailman ainutlaatuisiin tuotteisiin monipuolisessa valikoimassamme!
[url=https://nexium.foundation/]nexium 4 mg[/url]
Tutustu [url=https://nikotiinipussi.pro/]nikotiinipussit[/url]-maailman erikoisiin tuotteisiin laajassa valikoimassamme!
buy elimite cream online [url=https://permethrin.foundation/]buy elimite cream online[/url] how much is elimite cream
https://overthecounter.pro/# meclizine over the counter
Pills prescribing information. Drug Class.
strattera rx
Actual trends of drug. Read now.
Tutustu [url=https://nikotiinipussit.fun/]nikotiinipussit[/url]-maailman monipuolisiin tuotteisiin laajassa valikoimassamme!
Medicament prescribing information. Cautions.
zofran price
Everything trends of pills. Read here.
http://overthecounter.pro/# over the counter medicine for acid reflux
strongest over the counter pain reliever [url=https://overthecounter.pro/#]over the counter ed pills[/url] what does over the counter mean
Francis Hospital, Nsambya, Kampala, Uganda C cheap propecia no prescription Everyone knows me by name and offers a kind word or a greeting when they see me
[url=https://nexium.foundation/]nexium over the counter best price[/url]
Pills prescribing information. Cautions.
lioresal
All trends of medicine. Get here.
https://overthecounter.pro/# over the counter erectile dysfunction pills
Meds prescribing information. Effects of Drug Abuse.
neurontin prices
Actual news about medication. Get information now.
Tutustu [url=https://nikotiinipussit.store/]nikotiinipussit[/url]-maailman monipuolisiin tuotteisiin laajassa valikoimassamme!
http://overthecounter.pro/# over the counter medication for uti
best over the counter diet pills: antibiotics over the counter – over the counter sleep aid
diflucan 200mg cost ampicillin 250mg uk cheap cipro
Pills information. Generic Name.
cialis soft
Actual about medication. Get information now.
Considering a switch to [url=https://disposable-vape.store/]disposable vapes[/url]? Check out our vast variety of flavors and nicotine strengths. Make your purchase today and experience speedy delivery and superior customer service.
Contemplating a shift to [url=https://disposable-vape.wiki/]disposable vapes[/url]? Explore our extensive selection of flavors and nicotine strengths. Place your order now for rapid delivery and first-class customer service.
Мы максимально подробно консультируем своих клиентов — по телефону или в наших магазинах в Минске – leds-test.ru и честно подходим к ценообразованию.
fluoxetine tablets [url=https://fluoxetine.party/]fluoxetine 20 mg for sale[/url] fluoxetine capsules 10 mg
Medication information leaflet. Short-Term Effects.
get avodart
All news about drugs. Read now.
https://overthecounter.pro/# over the counter antidepressant
Medicine information. Drug Class.
lisinopril
Some what you want to know about pills. Read here.
[url=http://levaquina.charity/]levaquin 750 mg[/url]
Thinking of transitioning to [url=https://disposable-vapes.art/]disposable vapes[/url]? Our wide assortment of flavors and nicotine strengths will surely satisfy your needs. Make your purchase today for swift delivery and top-notch customer service.
Thinking about trying [url=https://disposable-vapes.site/]disposable vapes[/url]? Our vast array of flavors and nicotine strengths is designed to meet your unique needs. Place your order today for prompt delivery and exceptional customer service.
Considering [url=https://disposable-vapes.us/]disposable vapes[/url]? Our diverse range of flavors and nicotine strengths is tailored to fit your preferences. Order today for swift delivery and superior customer service.
Interested in [url=https://disposable-vapes.xyz/]disposable vapes[/url]? Our extensive range of flavors and nicotine strengths is made to match your preferences. Order today for quick delivery and exceptional customer service.
over the counter pill identifier: over-the-counter drug – best over the counter toenail fungus treatment
Experience a taste of the wild with [url=https://nordic-spirit.bio/]nordic spirit[/url]. Our organic nicotine pouches are crafted from the purest ingredients, providing a nicotine experience that’s as natural as the Nordic landscape.
Make your nicotine experience a proud one with [url=https://nordic-spirit.gay/]nordic spirit[/url]. Our nicotine pouches are designed with pride, made for the LGBTQ+ community.
Обзоры на Tour Ultra By все для туризма и отдыха – https://bike.by/forum/viewtopic.php?f=81&t=7742&view=print горячие новости со всего мира.
Explore the [url=https://nordic-spirit.site/]nordic spirit[/url] range of nicotine pouches on our site. Learn about the different flavors and strengths available.
I feel like a new person since starting [url=https://synthroidmx.online/]Synthroid 250[/url].
https://www.pinterest.com/pin/1099230221530412755/
http://overthecounter.pro/# over the counter blood pressure medicine
anthem over the counter catalogue [url=http://overthecounter.pro/#]over the counter erection pills[/url] antacids over-the-counter
https://overthecounter.pro/# oral thrush treatment over the counter
Discover the innovative world of [url=https://zyn.gay/]zyn[/url], a leader in nicotine pouches. Offering a unique blend of flavors and a superior nicotine experience, Zyn is truly a revolution in the industry.
https://vk.com/monolitnye_raboty_minsk?w=wall-213701595_5
https://overthecounter.pro/# over the counter water pills
baclofen 10 mg [url=http://baclofen.charity/]baclofen 30 mg capsule[/url] price of baclofen
cephalexin 600 mg tablets [url=https://cephalexin.science/]generic for cephalexin[/url] cephalexin online
how to buy flagyl purchase keflex without prescription buy keflex pill
fake change citizenship papers
Meds prescribing information. Cautions.
can i buy fluoxetine
All about drugs. Read here.
canadian medications: canadian online pharmacies ratings – legitimate canadian pharmacy
У какой фирмы покупать двери? https://kuzminki.bbok.ru/viewtopic.php?id=3392&p=5#p5252 цены на них будут намного ниже, чем в салонах.
[url=https://vermox.party/]buy vermox[/url]
Medication information sheet. Generic Name.
how to get abilify
Best trends of meds. Read now.
online pharmacy no presc uk [url=https://pharmacyonline.directory/]reliable canadian pharmacy[/url] canadianpharmacyworld com
Meds prescribing information. Short-Term Effects.
neurontin
Actual about medicine. Get information now.
buy vermox uk [url=http://vermox.science/]where can i buy vermox[/url] vermox 200mg
motilium tablet [url=http://motiliumtab.shop/]motilium 10mg tab[/url] buy motilium without prescription
Drug information for patients. Brand names.
fluoxetine
Best trends of medicines. Read here.
baclofen uk [url=https://baclofen.charity/]baclofen 10[/url] buy baclofen in uk
Pills prescribing information. Short-Term Effects.
maxalt
Actual about pills. Read information now.
Давайте поговорим о казино Пин Ап, которое является одним из самых популярных онлайн-казино на сегодняшний день. У этого игорного заведения есть несколько важных особенностей, которые стоит отметить.
пин ап
Во-первых, казино Пин Ап всегда радует своих игроков новыми игровыми автоматами. Здесь вы найдете такие новинки, как Funky Time, Mayan Stackways и Lamp Of Infinity. Эти автоматы не только предлагают захватывающий геймплей и увлекательные сюжеты, но и дают вам возможность выиграть крупные призы. Казино Пин Ап всегда следит за последними тенденциями в игровой индустрии и обновляет свою коллекцию, чтобы удовлетворить потребности своих игроков.
erythromycin cheap [url=http://erythromycin.trade/]where can i buy erythromycin online[/url] erythromycin 250mg capsules
[url=https://ampicillin.gives/]ampicillin 500mg capsules price[/url]
generic cleocin 150mg buy erythromycin 500mg online cheap ed pills for sale
finasteride usa [url=http://fenosteride.online/]finasteride drug[/url] finasteride dutasteride
Bro, I need to find [url=https://cipro.gives/]Cipro cheap[/url] for my trip abroad.
https://pillswithoutprescription.pro/# buy canadian pharmacy
For many of the tourists or new citizens of Dubai ladies club gym the visit to another city is not a reason to abandon the care about their health.
order indocin generic order indocin 50mg for sale cefixime pills
trusted canadian pharmacies: online canadian discount pharmacy – buy medicine canada
amoxil price [url=https://amoxil.party/]amoxil 250 mg capsule[/url] amoxil over the counter uk
http://pillswithoutprescription.pro/# discount prescriptions
Drugs prescribing information. Brand names.
clomid pill
Some trends of pills. Get here.
Playing plumber games online https://telegra.ph/Play-Plumbers-Online-Connect-Pipes-and-Solve-Puzzle-Challenges-05-13 offers an entertaining and intellectually stimulating experience. Whether you’re seeking a casual puzzle-solving adventure or a challenging brain teaser, these games provide hours of fun and excitement. So, get ready to connect pipes, overcome obstacles, and showcase your skills in the captivating world of online plumbers. Embark on a virtual plumbing journey today and immerse yourself in the thrilling puzzles that await!
[url=http://vermox.party/]vermox in canada[/url]
A significant breakthrough in Alzheimer’s research offers hope for a cure. [url=https://more24news.com/science/a-scientist-scraped-a-black-dot-on-his-forehead-and-filmed-it-under-a-microscope-revealing-dozens-of-crawling-face-mites/]filmed it under a microscope,[/url] A scientist scraped a black dot on his forehead and filmed it under a microscope, revealing dozens of crawling face mites
aarp canadian pharmacies: canadian online pharmacy no prescription – best mail order pharmacies
[url=https://priligy.gives/]priligy usa sale[/url]
augmentin 1g [url=https://augmentin.trade/]augmentin 875 mg[/url] augmentin price uk
http://edpills.pro/# ed medications
Medicament information sheet. Effects of Drug Abuse.
minocycline without dr prescription
Actual trends of drugs. Get now.
tamoxifen 20mg for sale purchase budesonide online order cefuroxime generic
trimox 250mg uk biaxin 250mg pills buy biaxin tablets
[url=http://atarax.pics/]atarax prescription uk[/url]
Medication information. Short-Term Effects.
cost cytotec
Actual about medicine. Read here.
В нашем интернет-магазине вы можете заказать кухонную мебель https://vivatsklad.ru/ в любое удобное для вас время.
News Today 24 https://greennewdealnews.com/wp-json/oembed/1.0/embed?url=http%3A%2F%2Fhttps://greennewdealnews.com%2F2016%2F09%2F26%2Fbrexit-leads-three-quarters-of-britains-ceos-to-consider-moving%2F
https://edpills.pro/# top ed pills
cleocin capsules [url=https://cleocin.party/]cleocin gel online[/url] cleocin acne
Dive into the vast universe of [url=https://snus1.xyz/]snus[/url] at Snus1.XYZ!
cymbalta generic usa [url=http://cymbaltax.online/]how much is cymbalta cost[/url] cymbalta generic
Medication information leaflet. Short-Term Effects.
clomid without prescription
Best about pills. Read here.
no 1 canadian pharcharmy online [url=http://pillswithoutprescription.pro/#]online pharmacies no prescriptions[/url] medications without prescription
Сад и Огород ДНР и ЛНР https://sadiogoroddnr.ru/lyuboy-muzh-budet-imi-gorditsya-predstavitelnitsy-etih-sozvezdiy-stanovyatsya-prekrasnymi-zhenami/
[url=http://ventolin.ink/]ventolin prices in canada[/url]
Купить качественные двери по выгодной цене – https://bravosklad.ru/ это мечта каждого покупателя.
[url=https://aprednisone.com/]no prescription online prednisone[/url]
News today 24 https://truehue.world/wp-json/oembed/1.0/embed?url=http%3A%2F%2Fhttps://truehue.world%2F2017%2F05%2F31%2Fhow-hokusai-shaped-western-art%2F
[url=http://yasmin.gives/]yasmin price usa[/url]
Explore the wealth of knowledge about [url=https://snus2.wiki/]snus[/url] at Snus2.Wiki! Dive into the world of snus like never before.
http://indianpharmacy.pro/# indian pharmacy paypal
[url=http://xenical.ink/]orlistat price in south africa[/url]
[url=https://yasmin.gives/]yasmin birth control acne[/url]
http://indianpharmacy.pro/# canadian pharmacy india
http://indianpharmacy.pro/# indian pharmacy online
Dive into the [url=https://skruf.yachts/]skruf[/url] world while enjoying the luxury of a yacht!
[url=http://priligy.gives/]priligy 60 mg[/url]
[url=https://augmentin.skin/]augmentin 875 generic[/url]
https://fixikionline.ru/
Unleash the potential of [url=https://elf-bar.pro/]elf bar[/url] and enjoy an unparalleled vaping experience!
[url=https://retinoa.foundation/]retino[/url]
[url=https://inderal.charity/]inderal otc[/url]
[url=https://baclofen.science/]baclofen 0.01[/url]
[url=https://colchicine.science/]buy colchicine tablets[/url]
Our culinary section is a haven for foodies, with recipes and cooking tips from around the world. Conflictologist Gleb Trufanov spoke about the impact of computer games on a person [url=https://todayhomenews.com/beauty-and-health/conflictologist-gleb-trufanov-spoke-about-the-impact-of-computer-games-on-a-person/]impact of computer games on[/url] Parenting and family activities advice.
Guest rooms have a vintage-meets-modern look — slim-legged benches and tables, which provide an authentic come upon to your own mobile phone phone. Are there pokies in alice springs that way, the portion of Pennsylvania’s new gambling law related to sports betting took effect. Vegas game was very clever about it, as well as a 3x multiplier and five stacks of the direwolf sigil. This movement caused the 1st line to be unsupported, there can be a long wait time as all the players are gathering. Truck drivers in West Virginia earn the lowest mean wage in the country even though 20 states have a lower cost of living, to reconditioning. This situation, to recycling. Pokies Near Indooroopilly | 30 dollars free pokies, Fortune Mobile Casino No Deposit Bonus
http://pcerumad.kr/bbs/board.php?bo_table=free&wr_id=319
Tournaments and prize draws are held at Chumba Casino Canada. Check the schedule on the website. Information about bonuses and promotions of this type is also published on the official page of the online casino on Facebook. The casino is fully licensed and regulated, ensuring 500 casino bonus safe and fair gaming experience for all players. One of the most inviting features of Online Casino is its unbeatable bonus program. New players can take advantage of the best welcome bonus, which includes a generous match bonus on their first deposit and a bundle of free spins on selected slots. Although LuckyLand Slots and Chumba Casino are sister sites, they are different from one another in many ways. When choosing between these sweepstake casinos, you can take a look at the games they offer, as well as the coin packages, to see which one suits you best.
http://indianpharmacy.pro/# india pharmacy mail order
https://indianpharmacy.pro/# indian pharmacies safe
[url=https://atomoxetine.download/]strattera price in canada[/url]
https://multfilmion.ru/
http://indianpharmacy.pro/# indian pharmacy paypal
Get in-depth insights into [url=https://elf-bar.xyz/]elf bar[/url] and their pivotal role in the world of vaping!
Join the inky journey of [url=https://elf-bar1.ink/]elf bar[/url] with our uniquely designed e-cigarettes!
[url=http://drugstoreviagra.online/]viagra discounts[/url]
buy minocin online actos 30mg for sale pioglitazone where to buy
[url=http://atomoxetine.charity/]strattera coupon[/url]
https://indianpharmacy.pro/# reputable indian online pharmacy
https://multfilmtut.ru/ Мультфильм тут
Get your hands on the finest vaping experience at [url=https://elf-bar1.xyz/]elf bar[/url] – home to vapers worldwide!
buy arava generic order azulfidine 500 mg online cheap purchase sulfasalazine online cheap
[url=http://dapoxetine.party/]dapoxetine 120 mg[/url]
[url=https://amoxicillin.africa/]amoxicillin 250mg[/url]
Популярные телеканалы в России https://www.uralagro174.ru/.
accutane 20mg brand where can i buy zithromax order azithromycin generic
Step into the world of [url=https://siberia1.online/]siberia[/url] nicotine pouches. Discover a plethora of flavors and a vibrant online community!
[url=https://augmentin.africa/]amoxicillin pharmacy usa[/url]
Experience the distinct sensation of [url=https://siberia1.yachts/]Siberia[/url] nicotine pouches with our diverse range of exquisite flavors!
[url=https://lisinopril.skin/]lisinopril buy online[/url]
[url=https://trustedtablets.discount/]best rx pharmacy online[/url]
Experience the leading-edge [url=https://xtrime.site/]xtrime[/url] nicotine pouches online store with an unparalleled assortment of pouch flavors!
[url=https://citalopram.science/]celexa 0.5 mg[/url]
[url=https://metformini.com/]metformin 500 price[/url]
buy tadalafil 20mg sale cialis 20mg pill tadalafil over counter
Dive into the world of [url=https://xtrime.xyz/]xtrime[/url] nicotine pouches and explore our in-depth product analysis!
Dive into the extraordinary world of [url=https://white-fox.fun/]white fox[/url] nicotine pouches, the perfect fusion of flavor and satisfaction!
Step into the vibrant world of [url=https://white-fox.site/]white fox[/url] pouches and enhance your lifestyle!
Dive into a world of knowledge with our [url=https://white-fox.wiki/]white fox[/url] wiki, where we explore the best of nicotine pouches!
azithromycin canada buy gabapentin 100mg without prescription buy neurontin for sale
Experience the vibrancy of the [url=https://velo1.site/]velo[/url] universe through our site. Immerse yourself in the exploration of distinct flavors!
Travel to the distant realms of the [url=https://velo1.space/]velo[/url] universe on our site. Our diverse selection promises an interstellar journey for your taste buds!
[url=http://priligy.gives/]cost of priligy[/url]
Experience the rich and diverse world of [url=https://snus3.ink/]snus[/url] with our range of unique flavors. Step into the future of snus!
Desktop emulator of the Steam authentication mobile application steam desktop authenticator SDA Steam Authenticator.
Discover the mesmerizing world of [url=https://snus3.online/]snus[/url] and indulge in a variety of vibrant flavors!
http://edmeds.pro/# buy ed pills online
stromectol uk deltasone online prednisone online order
[url=http://xenical.ink/]xenical usa[/url]
[url=https://metformini.com/]can i buy glucophage over the counter[/url]
Unleash your senses with the superior [url=https://killa1.life]killa[/url] selection of unique flavors!
Join the [url=https://killa1.website]killa[/url] family today and savor the exclusive range of pouches we offer!
Embark on a flavorful journey with [url=https://killa1.wiki]killa[/url] and discover our unique selection of nicotine pouches!
Immerse yourself in the captivating world of [url=https://killa.space]killa[/url]! Experience the thrill with our range of exceptional nicotine pouches!
buy lasix without prescription doxycycline us order ventolin
Uusi online-kasino on juuri saapunut pelaamisen maailmaan tarjoten jannittavia pelikokemuksia ja vihellyksen hauskuutta pelureille https://superkasinot.fi . Tama vakaa ja turvallinen peliportaali on rakennettu erityisesti suomalaisille pelaajille, tarjoten suomeksi olevan kayttorajapinnan ja tukipalvelun. Online-kasinolla on runsaasti peliautomaatteja, kuten kolikkopeleja, poytapeleja ja live-jakajapeleja, jotka toimivat moitteettomasti sujuvasti mobiililaitteilla. Lisaksi pelipaikka tarjoaa houkuttelevia palkkioita ja tarjouksia, kuten liittymisbonuksen, ilmaiskierroksia ja talletusbonuksia. Pelaajat voivat odottaa salamannopeita kotiutuksia ja mukavaa rahansiirtoa eri maksumenetelmilla. Uusi online-kasino tarjoaa uniikin pelikokemuksen ja on loistava vaihtoehto niille, jotka etsivat uusia ja jannittavia pelivaihtoehtoja.
Лучшая порада собак Мальтипу- https://lapkins.ru/people/user/24551/blog/935/
Российский сериал, который рассказывает о важных и актуальных проблемах общества [url=https://rosserial.online/1893-jetim-pylnym-letom.html](сериал 2018) Все Серии Подряд[/url] Этим пыльным летом 1 – 4 серия (сериал 2018) Все Серии Подряд смотреть онлайн бесплатно Я в полном восторге от актерского мастерства и качества съемки этого сериала.
augmentin 1g tablet [url=http://augmentin.trade/]buy augmentin[/url] augmentin 750 mg
[url=https://xenical.ink/]xenical mexico[/url]
pharmacy store: canadian online pharmacy no prescription – online pharmacy uk
A.K.A Films http://akafilms.com/
The following is an opinion of a famous political scientist vladislav soloviev rusal – He works as an economic expert.
Uusi nettikasino on juuri saapunut pelimarkkinoille tarjoamalla koukuttavia pelaamisen elamyksia ja runsaasti viihdetta pelureille [url=https://superkasinot.fi]turvallinen nettikasino[/url] . Tama reliable ja tietoturvallinen peliportaali on rakennettu erityisesti suomenkielisille kayttajille, mahdollistaen suomenkielisen kayttorajapinnan ja asiakastuen. Pelisivustolla on kattava valikoima peliautomaatteja, kuten hedelmapeleja, poytapeleja ja live-jakajapeleja, jotka toimivat saumattomasti kannettavilla laitteilla. Lisaksi pelipaikka tarjoaa koukuttavia bonuksia ja tarjouksia, kuten ensitalletusbonuksen, ilmaisia pyoraytyksia ja talletusbonuksia. Pelaajat voivat odottaa valittomia rahansiirtoja ja sujuvaa rahansiirtoa eri maksuvalineilla. Uusi pelisivusto tarjoaa ainutlaatuisen pelikokemuksen ja on loistava vaihtoehto niille, jotka etsivat uudenaikaisia ja jannittavia pelimahdollisuuksia.
oral levitra vardenafil for sale buy hydroxychloroquine pill
[url=https://jjpharmacynj.online/]good online mexican pharmacy[/url]
altace 10mg pill etoricoxib pills buy arcoxia sale
[url=https://gabapentinpill.online/]neurontin online[/url]
medicin without prescription – prescription drugs without prior prescription prescription prices
http://fastdeliverypill.com/# pharmacy cost comparison
approved canadian online pharmacies – prescription drugs without prior prescription online pharmacies no prescription required pain medication
canada drugs online pharmacy: medicine from canada with no prescriptions – cheap canadian cialis online
canada medications online [url=http://fastdeliverypill.com/#]prescription drugs without prior prescription[/url] drug stores canada
Online glucksspiel ir kluvis par loti atraktivu izklaides veidu globala pasaule, tostarp ari Latvijas iedzivotajiem. Tas nodrosina iespeju izbaudit speles un pameginat [url=https://www.onlinekazino.wiki/patiesi-kazino-spelu-cienitaji-novertes-i-kazino-piedavajumu-jo-tas-nav]labДЃkДЃs Latvijas online kazino[/url] savas spejas online.
Online kazino piedava plasu spelu piedavajumu, ietverot no tradicionalajam galda spelem, piemeroti, ruletes galds un 21, lidz atskirigiem kazino spelu automatiem un video pokera variantiem. Katram kazino dalibniekam ir iespeja, lai izveletos savu iecienito speli un bauditu saspringtu atmosferu, kas saistita ar naudas spelem. Ir ari daudzas kazino speles pieejamas dazadu veidu deribu iespejas, kas dod iespeju pielagoties saviem speles priekslikumiem un riskam.
Viena no lieliskajam lietam par online kazino ir ta piedavatie bonusi un darbibas. Lielaka dala online kazino nodrosina speletajiem dazadus bonusus, piemeram, iemaksas bonusus vai bezmaksas griezienus. Sie bonusi var dot jums papildu iespejas spelet un iegut lielakus laimestus. Tomer ir svarigi izlasit un ieverot bonusu noteikumus un nosacijumus, lai pilniba izmantotu piedavajumus.
online pharmacy store – order prescription medicine online without prescription certified mexican pharmacy
[url=http://dapoxetine.party/]where can i get dapoxetine[/url]
Uusi nettikasino on juuri saapunut pelimarkkinoille tarjoamalla vauhdikkaita pelaajakokemuksia ja paljon viihdetta gamblerille [url=http://superkasinot.fi]suomalaiset nettikasinot ilman rekisteroitymista[/url] . Tama varma ja suojattu peliportaali on rakennettu erityisesti suomalaisille kayttajille, mahdollistaen suomenkielisen kayttorajapinnan ja tukipalvelun. Kasinolla on kattava valikoima kasinopeleja, kuten kolikkopeleja, poytapeleja ja livena pelattavia peleja, jotka toimivat kitkattomasti alypuhelimilla. Lisaksi pelipaikka haataa houkuttelevia palkkioita ja tarjouksia, kuten ensitalletusbonuksen, ilmaiskierroksia ja talletus bonuksia. Pelaajat voivat odottaa pikaisia kotiutuksia ja vaivatonta rahansiirtoa eri maksutavoilla. Uusi online-kasino tarjoaa ainutlaatuisen pelikokemuksen ja on loistava vaihtoehto niille, jotka etsivat uusia ja jannittavia pelaamisen mahdollisuuksia.
vardenafil price buy levitra pills for sale hydroxychloroquine where to buy
[url=https://tadalafilsxp.online/]where can i buy over the counter cialis[/url]
[url=https://zoloft.africa/]zoloft without prescription[/url]
mesalamine sale buy generic mesalamine irbesartan 150mg cost
trusted canadian online pharmacy: drugs without a doctor s prescription – canadian pharmacy review
Uusi pelisivusto on juuri saapunut pelaamisen maailmaan tarjoamalla koukuttavia pelaamisen elamyksia ja runsaasti huvia pelureille [url=https://superkasinot.fi]kasinot Ilman Rekisteroitymista[/url] . Tama vakaa ja tietoturvallinen kasinopelipaikka on rakennettu erityisesti suomalaisille gamblerille, mahdollistaen suomeksi olevan kayttokokemuksen ja tukipalvelun. Pelisivustolla on kattava valikoima kasinopeleja, kuten kolikkopeleja, korttipeleja ja live-jakajapeleja, jotka ovat kaytettavissa sujuvasti mobiililaitteilla. Lisaksi pelipaikka tarjoaa houkuttelevia palkkioita ja tarjouksia, kuten ensitalletusbonuksen, ilmaisia pyoraytyksia ja talletus bonuksia. Pelaajat voivat odottaa nopeita rahansiirtoja ja helppoa rahansiirtoa eri maksumenetelmilla. Uusi pelisivusto tarjoaa erityisen pelaamisen kokemuksen ja on optimaalinen valinta niille, jotka etsivat uudenaikaisia ja vauhdikkaita pelimahdollisuuksia.
Наши прогнозы 1xbet сводятся к тому 1xbet вход – что матч будет увлекательным, так как чрезвычайно трудно дать тут безоговорочное преимущество одному из оппонентов.
https://fastdeliverypill.com/# best canadian pharmacies
[url=http://atomoxetine.download/]strattera 60 mg cap[/url]
online drugstore without prescription [url=http://fastdeliverypill.com/#]meds without a doctor s prescription canada[/url] pharmacy express online
Readers find certain things in the materials of vladislav soloviev biography that they did not pay attention to before or simply did not want to notice.
legitimate online pharmacies: drugs without a doctor s prescription – online canadian pharmacy with prescription
[url=https://lisinopril.skin/]prinivil 25mg[/url]
compare prescription prices – prescription drugs without prior prescription canadian online pharmacies
[url=https://prozac2023.online/]prozac online pharmacy uk[/url]
canadian rx pharmacy online – reliable online drugstore buy prescription drugs without doctor
[url=https://retinoa.foundation/]retino 0.05 gel[/url]
clobetasol oral buy generic temovate buy amiodarone generic
buy clobetasol cream amiodarone usa amiodarone 100mg uk
online cialis florida delivery [url=http://cialiswithoutprescription.pro/#]buy Cialis 20mg[/url] viagra sampleviagra cialis
http://pharmacyindia.pro/# reputable indian pharmacies
https://pharmacyindia.pro/# indian pharmacy
МБОУ Яманская Школа https://yamanshkola.ru/index/shkolnyj_teatr/0-279
https://pharmacyindia.pro/# top 10 online pharmacy in india
cialis express delivery australia: cheap cialis – cialis payment with paypal
[url=https://lasix.lol/]lasix online canada[/url]
best online pharmacy india [url=https://pharmacyindia.pro/#]Online medicine order[/url] mail order pharmacy india
Due to the high cost of the operating system and office utilities, licensed software is not available to everyone kmsspico – and modern security systems can be very difficult to circumvent.
diamox order online cost imuran 50mg buy imuran
http://canadiandrugs.pro/# canada drugs online
canadian compounding pharmacy: legitimate canadian mail order pharmacy – canada pharmacy online
[url=https://acyclovirvn.online/]acyclovir 400 mg price south africa[/url]
[url=https://cafergot.gives/]generic cafergot tablets[/url]
Заменим или установим линзы в фары, ремонт фар – которые увеличат яркость света и обеспечат комфортное и безопасное движение на автомобиле.
[url=https://retinoa.foundation/]retino 05[/url]
[url=http://accutane.skin/]how to get accutane in india[/url]
https://canadiandrugs.pro/# canadian pharmacy 24 com
reputable indian pharmacies [url=http://pharmacyindia.pro/#]best online pharmacy india[/url] indian pharmacy online
[url=https://cleocin.science/]clindamycin 300[/url]
[url=https://ibaclofeno.com/]baclofen 300 mg[/url]
indian pharmacies safe: п»їlegitimate online pharmacies india – buy prescription drugs from india
[url=https://priligy.gives/]priligy tablets price[/url]
Online medicine order [url=https://pharmacyindia.pro/#]india pharmacy mail order[/url] Online medicine home delivery
[url=http://dapoxetine.party/]dapoxetine price[/url]
[url=https://prednisonee.com/]can i buy prednisone from canada without a script[/url]
https://pharmacyindia.pro/# cheapest online pharmacy india
Normotim: Harnessing Lithium Ascorbate’s Power Against Depression – Normotim – The fight against depression has seen numerous advancements, including the advent of effective dietary supplements like Normotim.
best india pharmacy: top 10 online pharmacy in india – indian pharmacies safe
[url=https://retinoa.foundation/]retino gel[/url]
http://canadiandrugs.pro/# reliable canadian pharmacy reviews
[url=http://atomoxetine.download/]strattera 80 mg capsule[/url]
http://pharmacyindia.pro/# top 10 online pharmacy in india
cialis store in qatar [url=http://cialiswithoutprescription.pro/#]cheap cialis[/url] does 20mg cialis work
[url=https://tadacip.pics/]tadacip 20 online[/url]
[url=http://trustedtablets.shop/]online pharmacy quick delivery[/url]
Normotim, with its unique formulation of lithium ascorbate – lithium ascorbate – provides a range of mental health benefits.
In conclusion, lithium’s importance in human health, particularly mental health, cannot be overstated. Normotim, with its lithium ascorbate formulation – normotim effect – has demonstrated how this mineral can be harnessed to manage mental health conditions effectively.
The positive Normotim reviews further underscore – normotim reviews – the potential of lithium-based treatments in changing lives for the better.
Some also note an improvement in their overall well-being and functionality – normotim lithium ascorbate – attributing these changes to the Normotim effect.
[url=http://motilium.trade/]motilium 10mg tablet price[/url]
[url=https://amoxicillino.online/]augmentin 500mg tablets price[/url]
buy albuterol 100 mcg generic proventil 100 mcg for sale order pyridium generic
From its influential role in mental health treatment to its potential contributions to overall brain health – Normotim – lithium emerges as a key player in our quest to comprehend and enhance human health.
buy cheap generic baricitinib buy generic glucophage over the counter order lipitor 20mg generic
[url=https://levofloxacin.party/]levaquin antibiotics[/url]
Stress and smoking are intertwined in – normotim effect – a complex relationship that is harmful to health.
Uusi nettikasino on juuri saapunut pelimarkkinoille saaatavilla jannittavia pelaajakokemuksia ja runsaasti hauskuutta gamblerille https://axia.fi . Tama varma ja suojattu kasino on rakennettu erityisesti suomalaisille gamblerille, saaatavilla suomenkielisen kayttoliittyman ja asiakastuen. Pelisivustolla on monipuolinen valikoima peleja, kuten kolikkopeleja, poytapeleja ja live-jakajapeleja, jotka ovat kaytettavissa saumattomasti mobiililaitteilla. Lisaksi kasino tarjoaa vetavia talletusbonuksia ja tarjouksia, kuten liittymisbonuksen, ilmaisia pyoraytyksia ja talletusbonuksia. Pelaajat voivat odottaa valittomia kotiutuksia ja sujuvaa rahansiirtoa eri maksutavoilla. Uusi nettikasino tarjoaa erityisen pelaamisen kokemuksen ja on optimaalinen valinta niille, jotka etsivat innovatiivisia ja jannittavia pelaamisen mahdollisuuksia.
https://prednisonepills.pro/# prednisone 5 mg tablet cost
cipro 500mg best prices: buy cipro online without prescription – where can i buy cipro online
[url=http://metformini.com/]metformin 500[/url]
https://cytotecpills.pro/# cytotec buy online usa
Normotim reviews highlight how this medication – normotim reviews – has helped many individuals combat depression and improve their quality of life.
order montelukast 10mg generic avlosulfon brand dapsone 100 mg oral
https://prednisonepills.pro/# prednisone pill 10 mg
https://prednisonepills.pro/# buying prednisone from canada
where to get cytotec pills: cytotec abortion pill – Abortion pills online
[url=http://escitalopram.foundation/]buy lexapro brand name online[/url]
[url=https://clonidine.beauty/]62.5 mcg clonidine[/url]
[url=http://albenza.gives/]albendazole tablets online[/url]
http://cytotecpills.pro/# order cytotec online
It masterfully merges the individual merits of its constituents, lithium and ascorbic acid – normotim effect – providing an array of advantageous health impacts.
cipro online no prescription in the usa [url=https://ciproantibiotic.pro/#]cipro online no prescription in the usa[/url] ciprofloxacin order online
top 10 online pharmacy in india: indianpharmacy com – mail order pharmacy india
buy adalat 10mg pills fexofenadine 180mg ca buy allegra sale
Functions as an antioxidant: Ascorbic acid is a powerful antioxidant that counteracts oxidative stress in our bodies – normotim lithium ascorbate – shielding cells from harm caused by destructive molecules known as free radicals.
[url=http://citaloprama.charity/]citalopram 500 mg[/url]
[url=http://anafranil.charity/]anafranil 250 mg[/url]
ed drugs compared: buy ed pills online – ed drugs
online pharmacy pain relief [url=https://pharmfd.com/#]trusted online pharmacy reviews[/url] online pharmacy products
norvasc price oral amlodipine 10mg buy prilosec 20mg online
[url=http://acyclovira.online/]acyclovir pharmacy[/url]
top ed drugs: erectile dysfunction drugs – natural ed medications
[url=http://drugstorecialis.online/]cialis without prescription[/url]
https://pharmfd.online/# canadian pharmacy for viagra
[url=http://abilify.foundation/]abilify cost with insurance[/url]
[url=http://anafranil.charity/]anafranil clomipramine[/url]
Normotim, with its unique blend of ingredients and promising physiological effects – normotim reviews – may be a valuable player in this challenging journey.
cure ed: ed meds online without doctor prescription – erectile dysfunction drugs
[url=http://singulair.gives/]singulair purchase online[/url]
Летом 2021-го года компания Bitmain выпустила новое оборудование – antminer l7 купить на интегральных схемах для алгоритма Scrypt.
[url=http://tetracycline.charity/]tetracycline 100 mg[/url]
https://edpillsfd.online/# ed meds online
[url=http://plavix.charity/]generic plavix usa[/url]
online pharmacy cialis: viagra online canadian pharmacy – sure save pharmacy
Emma’s journey to becoming a professional tennis player has been marked by hard work and determination https://telegra.ph/Biography-of-a-fictional-tennis-player—Max-Turner-06-08 She began training at a local tennis academy at the age of ten, where her coaches recognized her potential and nurtured her talents. Her strong work ethic and relentless drive to improve set her apart from her peers.
[url=http://yasmin.foundation/]order yasmin online[/url]
The cognitive-enhancing effects of lithium ascorbate – normopharm as part of Normotim’s formulation, may offer support here.
cheap erectile dysfunction pills: ed meds online without doctor prescription – best ed drugs
ed pills that really work: erection pills online – treatment for ed
http://edpillsfd.com/# ed pills otc
best pills for ed [url=https://edpillsfd.online/#]cheap erectile dysfunction pills[/url] generic ed drugs
lopressor 100mg over the counter medrol brand name buy methylprednisolone tablets
canadian world pharmacy: canadian neighbor pharmacy – save on pharmacy
the best ed pill: impotence pills – ed medications list
Normotim, with lithium ascorbate at its core – lithium ascorbate provides a potential solution for managing stress and aiding in smoking cessation.
В нашем сообществе ВКонтакте и Telegram вы можете пользоваться бесплатным ботом ChatGPT – ChatGPT бесплатно общайтесь эффективно и инновационно с Chat GPT
https://pharmfd.online/# online pharmacy com
new ed drugs [url=https://edpillsfd.online/#]ed meds online without doctor prescription[/url] ed meds online
ed medications list: cheap erectile dysfunction pills – ed pills gnc
diltiazem order order diltiazem sale order zyloprim pills
top 10 online pharmacy in india: online shopping pharmacy india – indian pharmacy online
Linktree is a popular online tool that serves as – linktree vs linkinbio a landing page for social media profiles.
https://kamagratabs.pro/# cheap kamagra oral jelly
can i buy propecia pills [url=https://propecia.pro/#]Finasteride prescription online[/url] buying cheap propecia prices
[url=http://suhagra.charity/]suhagra 50 mg tablet online purchase[/url]
[url=https://tetracycline.charity/]tetracycline[/url]
[url=http://plavix.charity/]plavix over the counter[/url]
triamcinolone cheap claritin 10mg for sale claritin ca
[url=https://levaquina.online/]levaquin cost[/url]
can i get propecia pills: Buy Finasteride online – how can i get propecia without insurance
dapoxetine [url=https://dapoxetine.pro/#]Priligy price[/url] buy priligy
[url=https://levaquina.online/]levaquin buy online[/url]
24 июня в афише концертов Москвы стоит сольный концерт композитора Олега Шаумарова, автора хита Стану ли я счастливей, других музыкальных треков для Максима Фадеева, Лолиты мероприятия на 24 июня и многих других звёзд российской эстрады, который пройдёт в Джем Клуб (ул. Сретенка, 11).
buy kamagra online: cheap kamagra oral jelly – Kamagra Oral Jelly 100mg buy online
[url=http://yasmin.foundation/]yasmin price usa[/url]
https://kamagratabs.pro/# Kamagra Gold 100mg price
kamagra [url=https://kamagratabs.pro/#]kamagra[/url] Kamagra Oral Jelly 100mg buy online
Новый сервис продажи аккаунтов ВК в сети – Предлагаем страницы в ВК на выбор
[url=http://zoviraxacyclovir.charity/]zovirax for shingles[/url]
https://dapoxetine.pro/# dapoxetine
where can i get cheap propecia [url=https://propecia.pro/#]buy propecia[/url] can you get cheap propecia without a prescription
[url=http://yasmin.foundation/]order yasmin online[/url]
https://propecia.pro/# buying cheap propecia without prescription
Церковные мастера. заказать иконостас – Разрабатываем проекты любой сложности. Имеем лицензию на работу с драгоценными металлами.
generic propecia online [url=https://propecia.pro/#]Buy Finasteride online[/url] can i order propecia pills
ampicillin 500mg canada order metronidazole 200mg generic metronidazole oral
https://kamagratabs.pro/# Oral Jelly 100mg Kamagra price
[url=http://permethrin.gives/]elimite cost[/url]
https://propecia.pro/# can i order cheap propecia for sale
kamagra tablets usa [url=https://kamagratabs.pro/#]Kamagra Gold 100mg price[/url] Oral Jelly 100mg Kamagra price
prix du levitra en suisse Since it a relatively frequent variant, it is not uncommon that it has been reported in association with TBG and TTR gene mutations
Kamagra Oral Jelly for sale [url=https://kamagratabs.pro/#]kamagra[/url] kamagra
buy kamagra online: Oral Jelly 100mg Kamagra price – Kamagra Oral Jelly for sale
The best CS GO gambling sites cs go gamble seiten – carefully selected for your ultimate betting experience.
Смотреть сторис storis-instagram-anonimno.ru – инстаграм анонимно.
Nielsen FS, Rossing P, Gall MA, Skott P, Smidt UM, Parving HH cialis generic 5mg The detailed procedures were described in materials and methods
[url=https://ampicillintab.online/]ampicillin tablet 1mg[/url]
Buy Kamagra online next day delivery [url=https://kamagratabs.pro/#]kamagra[/url] cheap kamagra oral jelly
can you get generic propecia online: buy propecia – cost propecia without dr prescription
https://dapoxetine.pro/# dapoxetine
where to get propecia without rx [url=https://propecia.pro/#]Buy Finasteride online[/url] can i order cheap propecia
order bactrim 480mg online septra cost cheap clindamycin
[url=http://duloxetinecymbalta.charity/]best generic cymbalta[/url]
Расписные куклы-матрешки, небесно-голубая гжель и золотая хохлома – Русские подарки – пуховые шали из Оренбурга
can i purchase cheap propecia online: buy propecia – can you get cheap propecia no prescription
buy cheap propecia online [url=https://propecia.pro/#]Finasteride prescription online[/url] how to buy cheap propecia pill
https://dapoxetine.pro/# priligy over the counter
[url=https://zofrana.gives/]zofran 8 mg tablet[/url]
Gama Казино понимает, как привлекать и завоевать геймеров – gama казино официальный сайт регистрация – платформа gama casino постоянно проводит промоакции
https://propecia.pro/# can you buy generic propecia online
Oral Jelly 100mg Kamagra price [url=https://kamagratabs.pro/#]Kamagra 100mg[/url] buy kamagra online
[url=https://motilium.charity/]motilium australia[/url]
generic clopidogrel 75mg methotrexate 5mg drug buy warfarin medication
https://propecia.pro/# buy cheap propecia without insurance
Kamagra Gold 100mg price [url=https://kamagratabs.pro/#]Kamagra Oral Jelly 100mg buy online[/url] Oral Jelly 100mg Kamagra price
Kamagra Oral Jelly 100mg buy online: buy kamagra online – buy kamagra online
where can i get propecia without a prescription [url=https://propecia.pro/#]Best place to buy finasteride[/url] cost of propecia without prescription
[url=http://baclofena.foundation/]lioresal discount[/url]
[url=http://sumycin.gives/]tetracycline capsules[/url]
Priligy 60 mg online: priligy – dapoxetine
https://dapoxetine.pro/# Buy Dapoxetine
order reglan 20mg without prescription losartan 50mg brand esomeprazole usa
kamagra tablets usa [url=https://kamagratabs.pro/#]Kamagra 100mg[/url] Kamagra Oral Jelly 100mg buy online
[url=https://celebrex.charity/]celebrex 200 capsules[/url]
[url=http://neurontins.online/]buy gabapentin 400 mg[/url]
Kamagra Gold 100mg price: kamagra tablets usa – Kamagra Gold 100mg price
Загадочно и захватывающе. Эта информация меня просто поразила. [url=https://vashaibolit.ru/6136-recepty-narodnoy-mediciny-dlya-zdorovya.html]капусты » Ваш доктор Айболит[/url] Восстановительное лечение после операции на сердце » Ваш доктор Айболит Не забудь заглянуть туда, будет интересно.
safe canadian pharmacy [url=https://canadapharmcertified.pro/#]canadian valley pharmacy[/url] canadian pharmacy cheap
http://canadapharmcertified.pro/# legitimate canadian mail order pharmacy
https://mexicanpharmacies.pro/# medicine in mexico pharmacies
safe canadian pharmacy: canadian pharmacy – online canadian pharmacy review
п»їbest mexican online pharmacies: mexican online pharmacies prescription drugs – mexico drug stores pharmacies
[url=https://mebendazole.charity/]vermox sale[/url]
indian pharmacies safe: cheapest online pharmacy india – india online pharmacy
buy prescription drugs from india [url=https://indiameds.pro/#]indian pharmacy[/url] top online pharmacy india
Мы рады предложить вам изделия самых известных художественных промыслов России – подарки продажа русских сувениров — наш основной бизнес.
[url=http://sumycin.gives/]buy generic tetracycline online[/url]
A Mostbet opera legalmente em Portugal – https://www.google.md/url?q=https://mostbet-portugal-pt.com a casa de apostas tem uma licenca internacional emitida pela Curacao Gambling Commission.
http://mexicanpharmacies.pro/# mexican drugstore online
Модели Rolex Oyster Perpetual, Rolex Submariner – Fake Rolex и других коллекций бренда сегодня можно купить по фиксированной стоимости.
http://mexicanpharmacies.pro/# mexico drug stores pharmacies
robaxin 500mg price order sildenafil 50mg generic suhagra oral
Модели Rolex Oyster Perpetual, Rolex Submariner – Peplica Uhren и других коллекций бренда сегодня можно купить по фиксированной стоимости.
[url=https://cleocin.charity/]clindamycin cream[/url]
canadian pharmacy online ship to usa [url=http://canadapharmcertified.pro/#]legitimate canadian pharmacy online[/url] canadian online drugstore
[url=https://cleocin.charity/]clindamycin price uk[/url]
A Mostbet opera legalmente em Portugal – https://www.google.lk/url?q=https://mostbet-portugal-pt.com a casa de apostas tem uma licenca internacional emitida pela Curacao Gambling Commission.
purple pharmacy mexico price list: mexican drugstore online – mexican drugstore online
[url=https://celecoxib.charity/]cost of celebrex 100mg[/url]
[url=http://zestoretica.online/]zestoretic 20 12.5[/url]
[url=https://clomidfrt.online/]150 mg clomid[/url]
best online pharmacies in mexico [url=http://mexicanpharmacies.pro/#]mexican online pharmacies prescription drugs[/url] pharmacies in mexico that ship to usa
https://canadapharmcertified.pro/# canadian pharmacy scam
[url=https://cleocin.charity/]clindamycin 400mg[/url]
[url=https://piroxicam.foundation/]piroxicam price in india[/url]
canadian pharmacy 24h com: best canadian pharmacy online – canadadrugpharmacy com
[url=https://trazodonem.online/]trazodone no prescription[/url]
http://mexicanpharmacies.pro/# purple pharmacy mexico price list
sildenafil 100mg usa sildenafil 100mg ca estradiol 1mg brand
[url=http://budesonide.trade/]budesonide 9 mg coupon[/url]
indian pharmacy paypal [url=http://indiameds.pro/#]indian pharmacy online[/url] india pharmacy
mexican mail order pharmacies: mexico drug stores pharmacies – purple pharmacy mexico price list
[url=https://budesonide.trade/]budesonide prescription[/url]
canadian pharmacy no scripts: canadian pharmacy com – canadian pharmacy
http://mexicanpharmacies.pro/# medication from mexico pharmacy
[url=https://emoxicillin.com/]buy augmentin 625[/url]
order celecoxib for sale order generic zofran buy zofran 8mg generic
[url=https://fluconazole.science/]diflucan 1 pill[/url]
https://indiameds.pro/# buy medicines online in india
[url=http://zestoretica.online/]medication zestoretic[/url]
medication canadian pharmacy: canadian pharmacy world reviews – canadian world pharmacy
mexico drug stores pharmacies: mexico pharmacies prescription drugs – mexican pharmaceuticals online
[url=http://augmentin.media/]rx augmentin[/url]
[url=http://sildalisa.gives/]discount sildalis 120mg[/url]
Мы производим окна из лиственницы, окна из сосны, деревянные окна в квартиру или для загородного дома, реализуем фасадное остекление https://youtu.be/fZffc_4PNrs и другие виды остекления под ключ.
Online medicine order [url=http://indiameds.pro/#]reputable indian pharmacies[/url] top 10 pharmacies in india
mexican drugstore online: п»їbest mexican online pharmacies – purple pharmacy mexico price list
A renowned political scientist and blogger vladislav soloviev biography, came out with a forecast of global economic development in the years to come.
purchase spironolactone generic zocor pill valacyclovir 1000mg cost
best ed pill [url=http://edpill.pro/#]Over the counter erection pills[/url] best male enhancement pills
[url=http://celecoxib.charity/]generic celebrex discount[/url]
[url=https://dutasteride.charity/]avodart mexico[/url]
https://sildenafilpills.pro/# best sildenafil pills
http://edpill.pro/# medicine for erectile
Articles by a renowned political scientist, analyst, and columnist, Vladislav Soloviev, are published in the central and regional press, vladislav soloviev biography, as well as on the Zen platform.
Мы предлагаем профессиональные услуги вскрытия замков http://otkroem-zamki.ru/ обеспечивая быстрое и безопасное открытие дверей в случае утери ключей, запертых дверей или других ситуаций, когда требуется доступ к помещению.
His occupation: political scientist, analyst, publicist vladislav soloviev biography At first, he studied at an ordinary school, then at MSUTM
Soloviev’s materials always sound relevant and fresh vladislav soloviev biography and make you rethink established or imposed conventions.
http://fastpills.pro/# discount prescription drug
[url=https://budesonide.trade/]budecort price[/url]
Промокоды на http://kuponi-promokodi1.ru/ – скидки в популярных магазинах.
https://sildenafilpills.pro/# sildenafil coupon 50 mg
Mostbet cz — Znama spolecnost zabyvajici se sportovnimi sazkami https://judahyrjb00987.blogsidea.com/25713666/mostbet-cz-a-trustworthy-bookmaker-from-the-czech-republic a kasiny poskytuje sve sluzby hracum z 93 zemi po celem svete.
He is also a strong supporter of various charitable organizations vladislav soloviev biography and is involved in several philanthropic initiatives in Russia.
tretinoin gel price tadalis 10mg drug avana uk
[url=https://tamoxifen.pics/]tamoxifen otc[/url]
Mostbet cz — Znama spolecnost zabyvajici se sportovnimi sazkami https://www.mixcloud.com/mostbetpt4/ a kasiny poskytuje sve sluzby hracum z 93 zemi po celem svete.
http://fastpills.pro/# canadian pharmacies no prescription needed
Opportunities for infidelity can arise from various circumstances, vladislav soloviev biography such as work-related interactions, social events, or online platforms.
[url=https://meftormin.com/]buy metformin without prescription[/url]
Vladislav Soloviev enrolled in the Stankin MSUT, vladislav soloviev deripaska but soon dropped out on his own accord.
how to play aviator how to win aviator game how to hack aviator game online
http://edpill.pro/# natural ed medications
https://sildenafilpills.pro/# sildenafil buy online usa
https://edpill.pro/# medicine for impotence
Накрутка лайков и подписчиков в Инстаграм безопасно – nakrutka-podpischikov-instagram.ru накрутка живых подписчиков инстаграм надежно.
Интернет-магазин «Ай, Матрешки» матрёшки закажите матрешку, посуду, шкатулку с вашей символикой, сюжетом или фото!
order tadalafil pill order tadalafil 20mg generic sildenafil 25mg for sale
RUSAL has full access to the renewable energy resources of Siberia and other regions of the Russian Federation, vladislav soloviev rusal i can say without exaggeration that aluminum is the metal of the future.
http://fastpills.pro/# online pharmacies without an rx
[url=http://cleocina.foundation/]cleocin 150 mg price[/url]
According to the blogger’s opinion, vladislav soloviev ceo there are only two people who are worthy of “The Best CEO” award – Elon Musk and Satya Nadella.
It is no coincidence that the three billionaires, to which a famous American saying, “a self-made man”, vladislav soloviev ceo can be applied, have become the heroes of Vladislav Alexandrovich Soloviev’s top.
https://paxlovid.pro/# paxlovid covid
http://birthcontrolpills.pro/# birth control pills cost
http://paxlovid.pro/# paxlovid covid
Интернет-магазин «Ай, Матрешки» – расписные куклы-матрешки, небесно-голубая гжель и золотая хохлома, пуховые шали из Оренбурга, матрёшки – удивительные вещи поступают к нам со знаменитых фабрик, от мастеровых артелей, от художников и резчиков, продолжающих дело предков.
Крауд маркетинг для сайтов servis-kraud-internet-marketinga.ru крауд ссылки для продвижения.
onlinepharmaciescanada com: safe online pharmacy – canada pharmacy online
http://paxlovid.pro/# paxlovid pharmacy
[url=https://valacyclovir.party/]valtrex uk[/url]
Медицинская техника оптом и в розницу с гарантией и ценами производителя Медицинская техника оптом и экспресс доставкой курьером в любой регион России.
Автосервис Шевроле в Москве обслуживает любые модели, ремонт Шевроле производит в срок, автосервис шевроле, если требуется сервис Шевроле для вашей машины, то обращайтесь.
canadian pharmacies compare [url=https://canadianpharm.pro/#]canadian pharmacy shipping to USA[/url] pharmacy canadian
[url=http://paxila.foundation/]paroxetine 8.1[/url]
paxlovid for sale: paxlovid covid – paxlovid india
https://canadianpharm.pro/# canadian pharmacy ratings
мечта омск база отдыха
центр кисловодска
алупка отдых
мво сухум абхазия официальный сайт корпус бриз
[url=http://modafinilrn.online/]modafinil nz[/url]
Экскурсии по Москве – от 99 ? ?АКЦИИ? Официальный сайт Планета экскурсий Москва. https://multi-on.ru Автобусные | Пешеходные | Групповые | Речные | Индивидуальные.
Автосервис Сузуки в Москве обслуживает любые модели, ремонт Сузуки производит в срок, Автосервис Сузуки, если требуется сервис Сузуки для вашей машины, то обращайтесь.
canada pharmacy reviews: safe online pharmacy – safe reliable canadian pharmacy
http://canadianpharm.pro/# online pharmacy canada
Paxlovid buy online [url=http://paxlovid.pro/#]paxlovid price[/url] paxlovid cost without insurance
[url=https://paxila.foundation/]paroxetine brand[/url]
paxlovid pharmacy: paxlovid india – paxlovid buy
best canadian pharmacy to buy from: canadian international pharmacy – reliable canadian pharmacy
[url=http://prazosin.foundation/]prazosin 5 mg[/url]
https://birthcontrolpills.pro/# birth control pills cost
https://paxlovid.pro/# Paxlovid buy online
[url=https://zofran.charity/]zofran over the counter[/url]
paxlovid price: Paxlovid over the counter – paxlovid generic
paxlovid buy: Paxlovid buy online – paxlovid buy
Интернет магазин русских сувениров «Сувенирный двор», хохлома закажите русские сувениры в нашем интернет-магазине!
багратион отель москва
салют санаторий железноводск
гостиница зори в нижнем новгороде
гостиница аякс рязань
price for birth control pills [url=http://birthcontrolpills.pro/#]buy birth control over the counter[/url] birth control pills buy
paxlovid cost without insurance: paxlovid pharmacy – buy paxlovid online
[url=http://accurane.online/]accutane where to purchase[/url]
paxlovid for sale: paxlovid pharmacy – paxlovid for sale
https://birthcontrolpills.pro/# over the counter birth control pills
[url=https://ilyrica.com/]lyrica 300 mg price uk[/url]
paxlovid pill [url=https://paxlovid.pro/#]buy paxlovid online[/url] paxlovid india
paxlovid price: paxlovid price – paxlovid india
[url=https://antabuse.charity/]antabuse price[/url]
Normotim, packed with the efficacy of lithium ascorbate, has proven to be an invaluable ally for countless individuals striving to quit drinking and smoking, normotim effect by reducing stress, stabilizing mood, and supporting overall brain health, Normotim is truly a gift for those on the path to recovery and wellness.
http://birthcontrolpills.pro/# buy birth control over the counter
Vitamin C, the other constituent of lithium ascorbate, is equally significant for its indispensable roles in human health. Here are several ways it contributes to our wellness: normotim lithium ascorbate, foster neurogenesis, the creation of new neurons.
canadian pharmacy sarasota: www canadianonlinepharmacy – canadian pharmacy mall
https://paxlovid.pro/# paxlovid buy
[url=https://permethrina.gives/]where can i buy elimite cream[/url]
legit canadian pharmacy: buy prescription drugs from canada cheap – best canadian pharmacy
my canadian pharmacy reviews: reliable canadian pharmacy – canadian drug pharmacy
Unlock Positivity with Normotim and Lithium Ascorbate: Winning the Battle Against the Blues normotim effect, lithium: Often found in nature, it has shown to support brain health. Research suggests it might promote brain cell resilience.
Analyze and protect Instagram protect-instagram.com – clean delete spam rollowers, unfollow ghosts.
paxlovid generic [url=https://paxlovid.pro/#]paxlovid covid[/url] п»їpaxlovid
His last formal echocardiogram was less than two months prior to arrival with a documented LVEF of 51, RVSP of 39 cialis no prescription In addition, Leuprolide may cause convulsions and embryo fetal toxicity
order divalproex generic diamox 250mg us buy generic imdur 20mg
canadian pharmacy checker: safe online pharmacy – canadian pharmacy world
buying prescription drugs in mexico online: buying prescription drugs in mexico online – best online pharmacies in mexico
https://indiapharmacy.world/# indian pharmacy paypal
Промокоды и скидки на drpfo.ru проверено!
http://edpills24.pro/# cure ed
Шпион Вконтакте online-shpion-vk.ru: слежка за лайками профиля, комментариями, друзьями, подписчиками и сторис.
mexico drug stores pharmacies: mexican pharmaceuticals online – mexican border pharmacies shipping to usa
http://indiapharmacy.world/# reputable indian pharmacies
mexico drug stores pharmacies [url=https://mexicanpharmacy.life/#]medication from mexico pharmacy[/url] buying prescription drugs in mexico online
Introduction: Wolsen Real Estate Agency – Excellence Redefined wolsen real estate agency Miami: A Paradise Beyond Comparison
[url=http://tenormin.science/]cost of atenolol 25 mg[/url]
Поможем оформить полис ОСАГО без выплат на год всего за 1990 купить липовый полис осаго Фиксированая стоимость в независимости от марки Вашего автомобиля
https://edpills24.pro/# best ed treatment
http://mexicanpharmacy.life/# mexican drugstore online
Поможем оформить полис ОСАГО без выплат на год всего за 1990 купить осаго без выплат онлайн Фиксированая стоимость в независимости от марки Вашего автомобиля
Normopharm’s Role in Mental Well-being The significance of mental health cannot be underestimated normotim . It affects our thoughts, emotions, and daily
buy antivert tablets buy tiotropium bromide 9 mcg sale buy cheap minocycline
[url=http://lznopril.com/]price of lisinopril 5mg[/url]
Why Is Mental Health Important? normotim effect, it affects our thoughts, emotions, and daily life.
https://indiapharmacy.world/# pharmacy website india
гостиница волга вольск
спа отель в рязани
отель в алуште порто маре
мед сан
http://mexicanpharmacy.life/# mexico pharmacies prescription drugs
[url=http://erectafil.foundation/]erectafil 10[/url]
A few weeks in, and he found himself not just attending normotim lithium ascorbate a neighbor’s barbecue but actually enjoying it!
В Ташкенте, столице Узбекистана, растет спрос на системы кондиционирования воздуха, особенно в коммерческих и промышленных зданиях. Купить Чиллер Ташкент Узбекистан Одним из важных компонентов таких систем является чиллер фанкойл – устройство, которое обеспечивает охлаждение и регулировку температуры в помещении.
http://indiapharmacy.world/# canadian pharmacy india
В Ташкенте, столице Узбекистана, растет спрос на системы кондиционирования воздуха, особенно в коммерческих и промышленных зданиях. Фанкойл кассетный в Ташкенте Одним из важных компонентов таких систем является чиллер фанкойл – устройство, которое обеспечивает охлаждение и регулировку температуры в помещении.
ECOM Africa 2023 is a highly-regarded exhibition in the e-commerce domain, reputation house serm, drawing the attention of leading.
purple pharmacy mexico price list: mexican mail order pharmacies – medication from mexico pharmacy
https://indiapharmacy.world/# buy prescription drugs from india
Поможем оформить полис ОСАГО без выплат на год всего за 1990 страховка осаго без выплат Фиксированая стоимость в независимости от марки Вашего автомобиля
Found a fantastic site here https://chicagoavenuechurchofchrist.org/sitemap.xml
[url=https://diclofenac.science/]diclofenac gel 100 g[/url]
purple pharmacy mexico price list: buying from online mexican pharmacy – reputable mexican pharmacies online
Online medicine home delivery: Online medicine home delivery – top 10 pharmacies in india
House of Reputation According to representatives of the agency, reputation house serm, it’s better not to treat reviews as one of the sales tools.
https://indiapharmacy.world/# indian pharmacy online
Experience of Reputation House agency and official statistics only confirm these trends reputation house reviews for 85% of customers, online reviews are as important as personal recommendations from friends.
[url=http://tenormin.science/]tenormin[/url]
reputable indian online pharmacy [url=http://indiapharmacy.world/#]online pharmacy india[/url] online pharmacy india
https://edpills24.pro/# ed medications list
ed medication: medication for ed dysfunction – cheap ed pills
[url=https://cialis.skin/]cialis generic brand[/url]
[url=http://indocina.online/]indocin price[/url]
http://edpills24.pro/# erectile dysfunction pills
[url=http://escitaloprama.online/]80 mg lexapro[/url]
[url=https://synthroids.online/]synthroid discount[/url]
If a business receives one additional star on Yelp, reputation house serm its revenue increases by 9%. And 49% of people will choose a company only if its rating is at least 4 stars.
world pharmacy india [url=http://indiapharmacy.world/#]buy prescription drugs from india[/url] online shopping pharmacy india
buy prevacid 15mg generic buy albuterol online cheap order pantoprazole pills
https://edpills24.pro/# best drug for ed
[url=https://paxild.online/]paxil 20 mg tablet[/url]
https://edpills24.pro/# gnc ed pills
[url=http://indocina.online/]indocin 500[/url]
[url=http://prednisolonetab.skin/]prednisolone online uk[/url]
pharmacy website india: india pharmacy – cheapest online pharmacy india
mexican online pharmacies prescription drugs: mexico drug stores pharmacies – mexico drug stores pharmacies
санаторий здравница евпатория отзывы
гостиницы геленджика на берегу моря
головинка отдых 2021 цены отели на берегу
санаторий виктория пушкино отзывы реальные
[url=http://paxild.online/]cost of paroxetine without insurance[/url]
Заказать медицинскую технику, медицинскую мебель и изделия по оптовым ценам пробирки купить оптом от производителя.
В Ташкенте, столице Узбекистана, растет спрос на системы кондиционирования воздуха, особенно в коммерческих и промышленных зданиях. Чиллеры в Ташкенте Одним из важных компонентов таких систем является чиллер фанкойл – устройство, которое обеспечивает охлаждение и регулировку температуры в помещении.
where can i buy lopinavir Molnupiravir pharmacy
https://ciprofloxacin.icu/# п»їcipro generic
https://ciprofloxacin.icu/# buy cipro online canada
buy erectile dysfunction medicine tadalafil order tadalafil 20mg drug
lisinopril 20mg for sale buy lisinopril
https://clomiphenecitrate.pro/# clomid alcohol
buy molnupiravir australia molnupiravir in india
[url=https://ciprofloxacin.icu/#]ciprofloxacin generic price[/url] ciprofloxacin generic
Navigating the New Testament: Exploring Jesus’ Ministry with Bible Maps for Kids
cost of prednisone buy Prednisolone online
https://prednisone.pro/# prednisone 10 mg daily
ciprofloxacin order online ciprofloxacin mail online
generic clomid buy Clomid online
https://clomiphenecitrate.pro/# purchase clomiphene
https://molnupiravir.life/# molnupiravir for sale online
[url=https://ampicillin.party/]over the counter ampicillin[/url]
cipro cipro ciprofloxacin
https://molnupiravir.life/# molnupiravir india
Выставка MPIRES: дата и место проведения, описание программы на MPIRES
online clomid order clomid online
prednisone 10 mg price buy Prednisone 20mg
Выставка MPIRES: дата и место проведения, описание программы на https://ufa-town.ru/interesnoe/view/vystavka-mpires-2023
the blue pill ed tadalafil 40mg us buy cialis 10mg sale
https://ciprofloxacin.icu/# ciprofloxacin generic price
https://canadianpharmacy.legal/# canada pharmacy online
best rated canadian pharmacy precription drugs from canada
Помогаем людям с легочными и сердечными заболеваниями снимать приступы удушья и облегчать общую симптоматику заболевания https://illdoctor.ru/ – помогаем офисным работникам и их руководителям работать в комфортном и гигиеническом микроклимате.
https://paxlovid.store/# paxlovid for sale
Автосервис Мазда в Москве обслуживает любые модели, ремонт Мазда производит в срок Ремонт Мазда – если требуется сервис Мазда для вашей машины, то обращайтесь.
[url=https://sildenafil.science/]viagra generic online cheapest[/url]
Автосервис Мазда в Москве обслуживает любые модели, ремонт Мазда производит в срок Автосервис Мазда – если требуется сервис Мазда для вашей машины, то обращайтесь.
canadian pharmacy scam certified canadian international pharmacy
https://certifiedpharmacy.pro/# true canadian pharmacy
[url=https://canadianpharmacy.legal/#]certified canadian pharmacy[/url] rate canadian pharmacies
https://paxlovid.store/# п»їpaxlovid
paxlovid covid paxlovid price
гостевой дом прагма пятигорск
отель подушка санкт петербург
моршин санатории цены на 2021
вихревая ванна для ног
paxlovid india buy paxlovid online
https://paxlovid.store/# paxlovid price
Ремонт Мазда в автосервисе Мазда в Москве Автосервис Мазда – полный сервис Мазда.
Помогаем людям с легочными и сердечными заболеваниями снимать приступы удушья и облегчать общую симптоматику заболевания маска для неинвазивной ивл купить помогаем близким больных людей, потерявших способность самостоятельно передвигаться, проявить заботу.
https://paxlovid.store/# Paxlovid buy online
buy allegra 180mg pills cost ramipril generic amaryl 4mg
[url=http://hydroxychloroquine.skin/]hydroxychloroquine 300 mg tablet[/url]
canadian prescription drug prices online canadian pharmacy no prescription
Private Blood Test London https://londonbloodtests.uk/
[url=https://cafergot.party/]cafergot medication[/url]
cheapest drug prices mail order prescription drugs from canada
[url=http://lyricaf.com/]lyrica medication price[/url]
[url=https://advair.gives/]advair 100 mcg 50 mcg[/url]
[url=https://vermox.pics/]vermox price in india[/url]
Наша компания VinDecode – это ведущий провайдер информации об автомобилях, предоставляющий широкий спектр сервисов для получения данных о транспортных средствах Проверка авто на ДТП
трускавец 365 недельный тур цена 2021
отдых в абхазии 2021 цены недорого
сочи кабардинка как добраться
военный санаторий на алтае официальный сайт
Наша компания VinDecode – это ведущий провайдер информации об автомобилях, предоставляющий широкий спектр сервисов для получения данных о транспортных средствах Проверка авто на арест
п»їpaxlovid paxlovid pharmacy
paxlovid cost without insurance paxlovid for sale
[url=https://modafiniler.online/]order provigil[/url]
[url=https://paxlovid.store/#]paxlovid india[/url] paxlovid covid
[url=https://certifiedpharmacy.pro/#]reputable canadian mail order pharmacy[/url] canadiandrugstore.com
terazosin 1mg us pioglitazone 15mg cost order cialis for sale
https://pharmacy.ink/# cheapest prescription pharmacy
http://pharmacy.ink/# vipps approved canadian online pharmacy
wellbutrin drug: Wellbutrin (Bupropion) prescriptions – wellbutrin pills
https://ventolin.tech/# buy cheap ventolin online
[url=http://effexor.foundation/]effexor xr[/url]
buy minocycline 50 mg online: ivermectin 50 mg – minocycline 50 mg tablets
canadian pharmacy review: canadian international pharmacy – canada pharmacy online
[url=https://tizanidine.trade/]cost of zanaflex capsules[/url]
http://pharmacy.ink/# canadadrugpharmacy com
http://stromectolivermectin.pro/# ivermectin lotion for lice
buy minocycline 50 mg: ivermectin tablets order – stromectol generic
[url=http://zestoretic.foundation/]zestoretic 20 25[/url]
irbesartan 300mg usa buy clobetasol sale brand buspar 10mg
best generic wellbutrin 2018: buy bupropion online – zyban wellbutrin
http://stromectolivermectin.pro/# buy ivermectin uk
[url=https://cafergot.foundation/]cafergot cost[/url]
buy cordarone order generic amiodarone 100mg phenytoin 100mg tablet
minocycline 100 mg pills: minocycline 100 mg tabs – ivermectin 9 mg
Лучшие места где стоит искать авто с пробегом читайте https://mukola.net/v-kakih-mestah-stoit-iskat-bu-avtomobil/
Как выбрать авто с пробегом читайте на https://ufa-town.ru/interesnoe/view/sekrety-vybora-bu-avtomobila-kak-ne-osibitsa-pri-pokupke
Оборудование для водоподготовки и водоочистки https://penza-post.ru/neobhodimoe-oborudovanie-dlja-sozdanija-sistemy-ochistki-vody.dhtm от компании Акватех
[url=https://lyricalm.online/]lyrica 200 mg[/url]
indian pharmacies safe [url=https://indiapharmacy.bid/#]top online pharmacy india[/url] Online medicine home delivery
Explore everything from creating your own resident proxies to setting up a proxy server, and how ChatGPT can help you manage your daily tasks and improve your productivity Expert Guide: How to Set Up Residential Proxies this master class will provide you with all the skills and tools you need to fully utilize these technologies in your daily life.
https://certifiedpharmacycanada.pro/# pharmacy rx world canada
http://indiapharmacy.bid/# mail order pharmacy india
Darmowe spiny bez depozytu to bonus, dzięki któremu uzyskasz określoną liczbę obrotów na grę bez wymogu wpłacania środków do kasyna. Wiele osób wybiera kasyno na podstawie dostępności takiej oferty – jak ją otrzymać i czym dokładnie się ona charakteryzuje? Dowiesz się o tym z naszego tekstu, co znacznie ułatwi korzystanie z niego! Zabawa w kotka i myszkę skończy się 1 kwietnia. Wtedy wejdzie w życie nowelizacja ustawy hazardowej, która przyznaje absolutny monopol na stawianie jednorękich bandytów Totalizatorowi Sportowemu. Za postawienie każdego nienależącego do tej firmy automatu grozić będzie kara do 100 tys. zł. Kasyno może i będzie lekko na minusie, jeśli da ci darmowe spiny, ale za to duża jest szansa, że zostaniesz jego klientem na dłużej. Jeśli jesteś łowcą takich okazji, to wiesz o czym mowa, a jeśli nie, to już wyjaśniamy.
https://claytonnoli174146.ageeksblog.com/22387468/300-ruletka-csgo
Olsztyn, odległość: 2.17km W oparciu o naszą wiedzę i doświadczenie zawodowe, pokażemy Państwu jakie mogą być konsekwencje wizyt w kasynach gry, uświadomimy zagrożenia , wskażemy pułapki czyhające na amatorów “łatwych” pieniędzy, omówimy techniki i sposoby stosowane przez kasyna w celu zdobycia i zatrzymania niczego nieświadomych klientów. Powiemy jak bronić się przed nimi, a przede wszystkim przekonamy, że kasyna gry lepiej omijać z daleka. Wszystko to w formie rewelacyjnej zabawy, bez złotówki wyjętej z portfela, bo… to tylko świetna zabawa bez pieniędzy! Kasyno catering to niepowtarzalne smaki. Możliwość zakosztowania w najlepszym domowym obiedzie. Nie tylko w lokalu, ale także w dowozie. Dowozimy Nasze smakowite kompozycje na terenie całego Olsztyna. Ponadto wciąż organizujemy różnego…
albenza 400 mg sale albenza price provera pills
Официальное изготовление дубликатов гос номеров на автомобиль по ГОСТ за 10 минут номера без рамки за 10 минут восстановят номер.
mexican online pharmacies prescription drugs: purple pharmacy mexico price list – buying prescription drugs in mexico online
http://mexicanpharmacy.ink/# purple pharmacy mexico price list
http://indiapharmacy.bid/# online shopping pharmacy india
mexico drug stores pharmacies: mexican online pharmacies prescription drugs – purple pharmacy mexico price list
http://certifiedpharmacycanada.pro/# canadianpharmacyworld
https://certifiedpharmacycanada.pro/# canadian pharmacy world reviews
canadian pharmacy 24: buy prescription drugs from canada cheap – canadian pharmacy online
best online pharmacy india [url=https://indiapharmacy.bid/#]online shopping pharmacy india[/url] buy prescription drugs from india
http://mexicanpharmacy.ink/# pharmacies in mexico that ship to usa
oxytrol us order generic alendronate fosamax 70mg oral
https://certifiedpharmacycanada.pro/# 77 canadian pharmacy
reputable indian pharmacies: Online medicine home delivery – reputable indian online pharmacy
Adjuvant endocrine treatment buying cialis online
[url=http://vardenafil.party/]levitra prescription[/url]
https://mexicanpharmacy.ink/# mexican drugstore online
https://indiapharmacy.bid/# indian pharmacy paypal
order biltricide 600mg sale buy praziquantel 600 mg pill cost cyproheptadine 4mg
reputable mexican pharmacies online [url=https://mexicanpharmacy.ink/#]mexico drug stores pharmacies[/url] mexico drug stores pharmacies
reputable indian online pharmacy: india pharmacy – indianpharmacy com
cat casino играть онлайн
cat casino сайт
Замена гос номеров на авто необходима при наличии повреждений и царапин сделать дубликат номерного знака или при плохой видимости цифр и букв гос номера, начале коррозии.
aviator taktikleri
aviator 1win
This application gifts you an experience that is rare to find but so many people are grateful for. You don’t need to load any actual money to play the games. The array of slots to choose from, although they seem excessive, will be much welcomed as you spend time honing your skills. Must be playing on a slot machine with a River Club Card and have a valid ID to participate. Riversweeps 777 has a compilation of more than 70 exciting casino games. Come join us at Cash River for your chance at a $25 BILLLION Jackpot on our wildly popular Flash Pays Fortune game! The coins are always flowing at Cash River!!! No. As a sweepstake casino, Funzpoints offers traditional slot style games. You have successfully signed up to receive more information from Bally’s Twin River Lincoln Casino Resort.
http://www.xn--2q1bn6iu5aczqbmguvs.com/bbs/board.php?bo_table=free&wr_id=9891
The slot, of course, is heavily themed to Elvis and has a 60s 70s vibe to it. Since getting released in 2013, it’s delighted many Elvis fans around the world. Have a read of this Elvis: The King Lives slot review to find out everything there is to know about this action-packed slot. Of course! You can spin the Elvis the King Lives slot machine for free at VegasSlotsOnline. We always recommend trying out the demo version of the game before staking real money. Free Elvis slot has high volatility and an RTP of 96.09%, but you would be able to cash in on some great prizes as long as you meet up the requirements. This also means that wins would be hard to come by, but when you finally get one, it can be huge. There are about four bonus features that can be triggered. They all revolve around the appearance of this iconic singer. One symbol landing acts as a wild symbol or in different shades where he appears to be playing the guitar, performing. To trigger these bonuses in this slot, three extra symbols are essential to pop up. The bonus rounds are as follows:
[url=https://phenergan.charity/]phenergan 25mg otc[/url]
http://certifiedpharmacycanada.pro/# canadian online pharmacy reviews
pharmacies in mexico that ship to usa [url=http://mexicanpharmacy.ink/#]buying prescription drugs in mexico[/url] mexican border pharmacies shipping to usa
indian pharmacy: mail order pharmacy india – online pharmacy india
[url=https://proscar.skin/]propecia 2019[/url]
https://certifiedpharmacycanada.pro/# canada drugs online reviews
https://indiapharmacy.bid/# cheapest online pharmacy india
Лучшие проститутки алматы кыздар нет проститутки алматы
[url=http://tizanidine.party/]generic zanaflex 4mg[/url]
Лучшие проститутки алматы кыздар нет Проститутки Шымкента
[url=https://glucophage.charity/]how much is metformin[/url]
reputable indian pharmacies: online shopping pharmacy india – indian pharmacies safe
[url=http://glucophage.charity/]glucophage brand name[/url]
buy zithromax 1000 mg online: zithromax antibiotic without prescription – where to get zithromax
buy macrodantin 100 mg generic macrodantin order order pamelor 25mg sale
generic luvox 100mg luvox over the counter duloxetine 40mg uk
[url=http://zanaflex.foundation/]zanaflex 2mg tablet[/url]
buy cheap generic zithromax: zithromax 250 price – zithromax cost
[url=http://medrol.science/]solu medrol iv[/url]
Provpn.info: https://provpn.info/
zithromax 1000 mg pills: purchase zithromax z-pak – zithromax online no prescription
[url=http://proscar.skin/]compare propecia prices[/url]
Analytical materials in the mass media and articles in the personal blogs of vladislav soloviev biography come out regularly and often cause lively discussions among the readers.
The publication of these results is eagerly awaited as they may effect patient care worldwide finpecia uk
http://prednisone.cheap/# prednisone tablets
order zithromax over the counter [url=https://zithromax.reviews/#]buy zithromax online cheap[/url] zithromax for sale cheap
The Honest Political Scientist always has something to say on the topic of political vladislav soloviev biography and economic events in the country and the world in general.
how to get generic clomid tablets: where buy clomid without dr prescription – cost generic clomid now
Я только что зарегистрировался в Cat Casino, и у меня остались только положительные впечатления cat casino регистрация и хочу поделиться своим опытом.
Vladislav Soloviev’s long-term forecasts, which were published in RBK and Moskovsky Komsomolets, vladislav soloviev biography caused a public outcry.
[url=https://promethazinephenergan.online/]phenergan online[/url]
These texts were very close to the academic ones, vladislav soloviev biography which is why they didn’t see much popularity.
[url=https://acyclovir.party/]can i buy zovirax over the counter in canada[/url]
No deposit bonuses differ depending on the gaming site and can range from symbolic amounts to more generous offers like a $20 free bonus. However, casinos can also give you free spins as a no deposit promotion. You can receive from 10 up to a few dozen bonus spins to use in eligible online slots. No deposit bonuses awarding free cash are better options since you can play all types of games except those that are restricted. No deposit free chip offers are another widespread type of no deposit bonuses found in online casinos. They are either extra casino cash (virtual money) that you can spend on playing top games, or they come as free spins (usually as a part of a welcome bonus). Once a new user completes registration on a Canadian casino site, they receive a fixed amount of bonus cash, free games, or free spins.
http://dcelec.co.kr/uni/bbs/board.php?bo_table=free&wr_id=241831
+81-(0)46-251-0948+81-(0)46-256-6071 Expert mode Allows players to save up to six customized betting configurations and reproduce them at the click of a button and many more function. European VIP Roulette online is a crisp, elegant, impressively designed game from iSoftBet. Launched in 2019, this European roulette variant offers a wide variety of betting options and a higher-than-average minimum bet. This is a casino game clearly aimed at the high rollers, earning the VIP tag in the title. Keep track of your play with these Reality Check alerts. For more info about our gaming tools, see . Check out our European VIP Roulette review to find the safest, most secure online casino sites for you. Click the following link to see our top choice for the best European VIP Roulette casino currently in operation.
generic clomid tablets: can i buy cheap clomid tablets – generic clomid pill
He grew up in a family of academics, with his mother being a mathematician vladislav soloviev biography and his father a physicist. From an early age, Soloviev was interested in economics and finance.
This political scientist always holds his own independent opinion on the decisions and activities of Russian Federation’s political elites vladislav alexandrovich soloviev during the period of military operations.
buy cheap propecia for sale: Buy Finasteride online – order generic propecia pills
glucotrol over the counter nootropil 800 mg pills betamethasone online order
paxlovid generic [url=https://paxlovid.life/#]paxlovid covid[/url] paxlovid for sale
order cheap propecia without a prescription: home – buying cheap propecia without dr prescription
http://edpills.ink/# online ed medications
Abortion pills online: purchase cytotec – buy cytotec pills
Readers find certain things in the materials that they did not pay attention to before or simply opinion may be too harsh vladislav alexandrovich soloviev did not want to notice.
acetaminophen drug cheap paxil 20mg famotidine 20mg cost
buy paxlovid online: paxlovid for sale – paxlovid pill
cost generic propecia without prescription: Buy Finasteride online – cost cheap propecia price
Авторитетный блог о косметологии https://filllin-daily.ru
New research for ICJMC from Blogger vladislav soloviev ceo: Oleg Deripaska, Andy Fang and Austin Russel – What Do These People Have in Common?
Brianna, USA 2022 06 19 14 20 25 cialis generic reviews Further analysis of the tamoxifen group showed that 71
Normopharm illustrates its understanding of contemporary health challenges normotim normopharm and reinforces its commitment to addressing them effectively.
buy misoprostol over the counter: Abortion pills online – purchase cytotec
cost of propecia no prescription: cheap propecia – buy propecia prices
Who is the best CEO of 2022 vladislav soloviev ceo, In conditions of fierce competition, an increase of resource prices and decline of buying power of the population, practically all companies experience economic difficulties.
[url=https://hydroxychloroquine.africa/]hydroxychloroquine 5 mg[/url]
non prescription erection pills: cheap erectile dysfunction pill – best otc ed pills
celebrities on propecia Are they financially responsible for the child that they found out is in fact theirs
buying cheap propecia without dr prescription [url=https://propecia.cheap/#]propecia best price[/url] cost of cheap propecia without rx
[url=http://duloxetinecymbalta.online/]90mg cymbalta[/url]
With a scientifically-backed formulation, normotim effect Normotim targets the root causes of stress and depression.
By developing a product that targets these prevalent conditions, normotim illustrates its understanding of contemporary health challenges and reinforces its commitment to addressing them effectively.
[url=https://elimite.gives/]elimite otc price[/url]
The very Link in Bio feature keeps tremendous relevance for Facebook along with Instagram platform users as provides a solitary interactive link within one individual’s profile page that points guests towards outside sites, weblog entries, goods, or any desired location.
Samples of such webpages giving Link in Bio services or products include
https://linksinbio.dreamyblogs.com/1765477/revolutionizing-engagement-unleashing-the-power-of-link-in-bio-on-social-media
which often supply adjustable destination pages to actually consolidate various linkages into one one particular accessible to everyone and furthermore easy-to-use location.
This particular capability becomes really particularly essential for the businesses, influencers, and also content creators of these studies looking for to actually promote the specific to content or even drive the web traffic to relevant to the URLs outside the particular platform’s.
With all limited in options available for all usable connections within posts, having a a and furthermore updated Link in Bio allows the users of the platform to actually curate the their online presence effectively for and furthermore showcase the the announcements for, campaigns, or even important in updates to.
buying generic propecia price: propecia best price – generic propecia pills
By developing a product that targets these prevalent conditions, Normopharm illustrates its understanding of contemporary health challenges normotim lithium ascorbate and reinforces its commitment to addressing them effectively.
paxlovid cost without insurance: Paxlovid over the counter – paxlovid generic
Stress and depression have become prevalent challenges in today’s fast-paced world, affecting individuals from all walks of life. In response to this growing concern, Normopharm, normotim reviews a trusted name in the pharmaceutical industry, has developed Normotim.
[url=http://zoloftpill.online/]18000mg zoloft[/url]
buy cytotec pills online cheap: Misoprostol 200 mg buy online – Misoprostol 200 mg buy online
buy anafranil 25mg for sale buy prometrium generic prometrium 200mg sale
Статья исследует сегмент дешевых криптовалют с ростовым потенциалом, читать далее анализирует стратегии поиска перспективных проектов, обсуждает связанные риски и предлагает принципы безопасного инвестирования.
1хБет промокод, который дает специальный бонус до 32500 рублей промокод 1хбет на слоты без использования промокодом бонус для клиентов будет 25000 рублей.
Online kazino ir iemilots izklaides veids, kas sanem arvien lielaku https://telegra.ph/Online-kazino-Latvij%C4%81-Azartsp%C4%93%C4%BCu-atra%C5%A1an%C4%81s-vieta-virtu%C4%81laj%C4%81-pasaul%C4%93-07-26 popularitati Latvija un visa pasaule. Tas sniedz iespeju spelet dazadus azartspelu un kazino spelu veidus tiessaiste, erti un atrodami no jebkuras vietas un laika. Online kazino sniedz lielisku izveli dazadu spelu automatu, ka ari klasiku ka ruletes, blekdzeka un pokers. Speletaji var izbaudit speles speli no savam majam, izmantojot datoru, viedtalruni vai planseti.
Viens no lielakajiem prieksrocibam, ko sniedz online kazino, ir plasas bonusu un promociju iespejas. Jaunie un pastavigie speletaji tiek apbalvoti ar dazadiem bonusiem, bezmaksas griezieniem un citam interesantam akcijam, kas padara spelesanu vel aizraujosaku un izdevigaku. Tomer ir svarigi nemt vera, atbildigu azartspelu praksi un spelet tikai ar atbildigu pieeju un akceptejamu ierobezojumu, lai nodrosinatu pozitivu spelu pieredzi un noverstu iespejamu negativu ietekmi uz finansialo stavokli un dzivesveidu.
ChemDiv is a recognized global leader in drug discovery solutions dmpk services we offer fully integrated R&D Services to support pharmaceutical R&D projects.
TOP 10 CSGO Gambling sites you will find here – cs go gambling
[url=http://pharmacies.charity/]us pharmacy no prescription[/url]
[url=https://flomaxsb.online/]flomax 0.4[/url]
[url=https://phenergan.science/]phenergan nz[/url]
This pioneering product aims to provide 1 a novel normotim reviews and effective approach to managing stress and depression, offering hope to those seeking relief.
Normotim offers a scientifically-backed, holistic approach to managing mental health challenges, normotim potentially making the path towards recovery a little less daunting.
[url=https://acyclov.com/]acyclovir tablets over the counter[/url]
paxlovid india: paxlovid generic – paxlovid india
medications for ed: buy generic ed drugs – ed pills comparison
https://paxlovid.life/# paxlovid india
1хБет промокод, который дает специальный бонус до 32500 рублей промокод 1xbet при регистрации без использования промокодом бонус для клиентов будет 25000 рублей.
get propecia pills: buy propecia – generic propecia no prescription
Вкусные рецепты на сайте Королевская ватрушка с клубникой приготовите вместе с нами ваши любимые блюда с нашими рецептами.
buy ed pills online: cheap erectile dysfunction pill – п»їerectile dysfunction medication
Вкусные рецепты на сайте Королевская ватрушка с клубникой приготовите вместе с нами ваши любимые блюда с нашими рецептами.
paxlovid covid [url=https://paxlovid.life/#]п»їpaxlovid[/url] paxlovid covid
It is a tool that individuals can use in tandem with lifestyle alterations, counseling, normotim normopharm and other forms of support to engender a more substantial change in their mental health.
[url=https://happyfamilycanadianpharmacy.com/]www pharmacyonline[/url]
erection pills online: best over the counter ed pills – best erection pills
The Link in Bio characteristic keeps tremendous relevance for every Facebook along with Instagram users because gives one single interactive linkage in a individual’s account that actually directs guests to outside sites, weblog articles, products or services, or perhaps any type of desired for spot.
Illustrations of these websites providing Link in Bio solutions include
https://www.vingle.net/posts/6534735
which give personalizable arrival pages to really combine various linkages into an single accessible to all and user oriented destination.
This very capability becomes especially to crucial for all organizations, influential people, and even content material creators of these studies trying to find to really promote specific for content pieces or possibly drive their web traffic to the relevant for URLs outside of the particular platform’s site.
With every limited in options for every usable connections inside the posts of the platform, having a a and up-to-date Link in Bio allows the members to actually curate the their own online in presence effectively in and furthermore showcase the newest announcements to, campaigns in, or possibly important to updates for.
By making the smoking experience less appealing normotim normopharm reviews of the state of the world often provoke criticism and arguments but always find their reaction among various segments of the population.
cost of cheap propecia pill: buy propecia – buy cheap propecia without rx
paxlovid india: paxlovid pharmacy – Paxlovid buy online
buy tindamax 300mg online olanzapine ca purchase nebivolol online
[url=https://elimite.gives/]acticin tablet[/url]
cytotec buy online usa: order cytotec online – Abortion pills online
Lithium ascorbate in Normotim has been observed to decrease dependency levels by reducing dopamine normotim normopharm production associated with the pleasure derived from smoking.
buy cheap propecia pill [url=http://propecia.cheap/#]Buy Finasteride online[/url] order cheap propecia without dr prescription
buy cheap propecia without insurance: cost cheap propecia without insurance – get generic propecia without rx
Paxlovid over the counter: paxlovid for sale – paxlovid pill
[url=http://vardenafil.party/]levitra prices in us[/url]
[url=http://lasix.science/]furosemide 40 mg tablet[/url]
online ed medications: cheap erectile dysfunction pill – cheap ed pills
buy generic propecia pill: Buy Finasteride online – cost propecia for sale
cytotec buy online usa: buy cytotec in usa – buy cytotec online fast delivery
[url=http://duloxetinecymbalta.online/]cymbalta 120 mg daily[/url]
purchase diovan online clozapine online buy ipratropium 100mcg pill
[url=https://elimite.gives/]elimite cream[/url]
paxlovid for sale: paxlovid generic – buy paxlovid online
order propecia without dr prescription [url=http://propecia.cheap/#]buy generic propecia[/url] get cheap propecia without dr prescription
buy rocaltrol medication rocaltrol pills buy tricor 200mg online
Строительство домов и бань под ключ строительство дома Стройтех42 — одна из самых перспективных компаний.
Строительство домов и бань под ключ дома под ключ в новокузнецке Стройтех42 — одна из самых перспективных компаний.
[url=https://prazosin.science/]prazosin pill[/url]
medication for ed dysfunction: over the counter erectile dysfunction pills – best drug for ed
buy cheap propecia without a prescription: cheap propecia – cheap propecia without a prescription
cost of cheap propecia without dr prescription: buy generic propecia – cost generic propecia pill
https://edpills.ink/# medication for ed dysfunction
The actual Link in Bio attribute maintains tremendous significance for both Facebook and also Instagram platform users as it https://linkinbioskye.com/
provides an unique clickable link inside one member’s personal profile that actually directs users to external to the site websites, blogging site posts, products or services, or any type of desired location. Illustrations of such sites offering Link in Bio services comprise which offer modifiable destination pages and posts to actually merge numerous connections into an one particular accessible to all and furthermore easy-to-use location. This specific function turns into particularly crucial for all organizations, influencers in the field, and content items makers looking for to really promote the specific to content or perhaps drive traffic to the site towards relevant to URLs outside of the platform. With all limited choices for all usable links inside posts, having an active and even modern Link in Bio allows for members to effectively curate the their very own online in presence online effectively in and even showcase the the latest announcements for, campaigns, or even important to updates to.The very Link in Bio function keeps vast importance for all Facebook as well as Instagram users of the platform as it gives a unique interactive hyperlink in the an member’s personal profile that actually directs visitors to the site to the external to the platform online sites, blogging site articles, products, or possibly any wanted spot. Examples of these sites supplying Link in Bio services or products involve which usually provide customizable landing webpages to consolidate various links into a single one particular accessible and also easy-to-use place. This functionality becomes particularly critical for all organizations, influential people, and furthermore content creators of these studies searching for to promote their specific for content or drive web traffic to the relevant to the URLs outside the the platform’s.
With every limited to alternatives for all clickable connections inside the posts of content, having the a and furthermore up-to-date Link in Bio allows a platform users to curate their own online to presence online effectively for and also showcase the announcements to, campaigns to, or perhaps important for updates to.
Продвижение сайтов в топ поисковой системы Яндекс поведенческий фактор в продвижении сайта
erectile dysfunction pills: cheap erectile dysfunction pill – best otc ed pills
Ни для кого не секрет, что Китай, являясь крупнейшей страной-производителем, http://ant-spb.ru/kupit-tamozhennye-dannye занимает лидирующие позиции в сфере экспорта.
Продвижение сайтов в топ поисковой системы Яндекс продвижение по поведенческий фактор
[url=https://tadalafilbv.online/]cialis 20mg price in mexico[/url]
[url=http://triamterene.science/]triamterene-hctz 37.5-25 mg[/url]
Ни для кого не секрет, что Китай, являясь крупнейшей страной-производителем, https://tradesparq.su занимает лидирующие позиции в сфере экспорта.
[url=http://cleocin.foundation/]buy clindamycin[/url]
buy decadron 0,5 mg for sale buy linezolid medication purchase nateglinide online cheap
ChemDiv’s Screening Libraries have been extensively validated both in our in-house biological assays and in the laboratories of over 200 external partners including Pharma, Screening Libraries Biotech, Academia and Screening Centers in the U.S., Europe, and Japan. We offer a shelf-available set of over 1.6 M individual solid compounds.
Осуществляем доставку и растаможку сборных грузов http://ant-spb.ru/poisk_postavschikov_v_kitae любым доступным видом транспорта по оптимально выгодной цене
cost generic propecia online: cheap propecia – cost generic propecia tablets
[url=https://inderal.gives/]propranolol 60 mg price[/url]
[url=https://zanaflex.lol/]tizanidine 2mg[/url]
[url=http://zanaflex.lol/]tizanidine 1mg[/url]
[url=http://nolvadex.download/]tamoxifen pill[/url]
paxlovid for sale: paxlovid pharmacy – paxlovid generic
[url=http://levofloxacina.foundation/]levaquin antibiotics[/url]
buy oxcarbazepine without a prescription uroxatral price order urso 300mg pills
Программа для магазина Меркурий-ERP Программа для магазина мощная и простая программа управленческого учета в торговле.
Проституки в Стамбуле, Антальи, Анкаре TurkGirls и других городах Турции
order cytotec online: Cytotec 200mcg price – order cytotec online
The very] Link in Bio function holds tremendous importance for both Facebook along with Instagram platform users because [url=https://linkinbioskye.com]bio link[/url] offers an individual interactive linkage in the one user’s profile page that actually guides visitors towards external webpages, weblog posts, products or services, or any sort of wanted destination. Samples of such websites offering Link in Bio services or products comprise that offer adjustable landing page pages to merge multiple hyperlinks into a single one particular accessible to all and furthermore user oriented location. This specific capability becomes really especially to vital for business enterprises, influencers, and furthermore content creators looking for to actually promote a specific to content items or drive a web traffic to the relevant to the URLs outside the platform’s site. With the limited in options for all usable linkages inside the posts of the platform, having an a dynamic and up-to-date Link in Bio allows members to actually curate a their very own online to presence online effectively in and showcase their the newest announcements, campaigns to, or possibly important for updates for.This Link in Bio feature keeps vast value for both Facebook as well as Instagram members since offers a solitary interactive connection inside a individual’s profile which points visitors to external to the platform webpages, blogging site posts, goods, or any desired location. Examples of these websites providing Link in Bio services or products involve that provide modifiable arrival webpages to effectively combine numerous hyperlinks into an single accessible to all and furthermore easy-to-use location. This particular capability becomes actually especially to essential for businesses, influential people, and also content items creators looking for to promote their specific content pieces or possibly drive their traffic to relevant to URLs outside the the particular platform’s site.
With the limited in choices for all actionable hyperlinks within the posts of content, having an a and furthermore up-to-date Link in Bio allows members to actually curate the their particular online in presence in the platform effectively and furthermore showcase their the latest announcements for, campaigns in, or possibly important updates in.
Σήμερα, θα παρουσιάσουμε κάποιες συμβουλές μέσω των οποίων θα μπορέσετε να αποφύγετε λάθη τα οποία κοστίζουν εκτός από την ήττα και τα χρήματα σας που είναι άλλωστε και το βασικότερο. Χωρίς να έχει χάσει έναν βαθμό ή ακόμη και να δεχτεί ένα γκολ στον προκριματικό όμιλο του Euro 2024, η Πορτογαλία επιβιβάζεται σε αεροπλάνο για το Ρέικιαβικ για να αντιμετωπίσει την Ισλανδία, το βράδυ της Τρίτης. Η Πορτογαλία κέρδισε άνετα με 3-0 επί της Βοσνίας στην πιο πρόσφατη αναμέτρησή της, ενώ οι γηπεδούχοι νίκησαν 2-1 εντός έδρας τη Σλοβακία.
https://wiki-nest.win/index.php?title=Καζινο_νομιμα_με_Paysafe
Σε αντίθεση με τις άλλες μεθόδους πληρωμής, δεν μπορείς να αγοράσεις ηλεκτρονικά τις κάρτες pin της PaySafe. Πρέπει να πας σε ένα κοντινό σημείο πώλησης για να την αγοράσεις, προτού κάνεις κατάθεση σε κάποιο διαδικτυακό καζίνο. Έτσι, αν και είναι εξαιρετικά ασφαλής τρόπος, είναι λιγότερο πρακτικός. Μελετημένα προγνωστικά από ολόκληρο το κουπόνι ΟΠΑΠ. Δεκάδες επιλογές κάθε μέρα με ποικιλία από διαφορετικά είδη στοιχημάτων. Η μοναδική στήλη στον διαδικτυακό κόσμο του στοιχήματος με προβλέψεις σε όλες σχεδόν τις διοργανώσεις.
Found a superb site here https://greekchurchbristol.com/sitemap.xml
Компания IT Frut продвижение сайтов, отзывы itfrut.ru отзывы
Found a useful site here https://greekchurchbristol.com/sitemap.xml
Приглашаем для сотрудничества красивых, привлекательных девушек досуг вакансии екатеринбург Кем в наше время может работать девушка?
Приглашаем для сотрудничества красивых, привлекательных девушек работа для девушек в досуге в новосибирске Кем в наше время может работать девушка?
amoxicillin 500mg capsule buy amoxicillin online with paypal – amoxicillin 500mg prescription
В наше время все больше и больше женщин мечтают о жизни работа для девушек в досуге в нижнем новгороде рядом с богатым мужчиной.
Бани сауны Волгограда на портале Дай Жару сицилия сауна волгоград парение вызывает усиленное потоотделение, а с потом выводятся шлаки и токсины.
6 prednisone: best pharmacy prednisone – prednisone 30 mg tablet
Бани сауны Волгограда на портале Дай Жару бани волгограда парение вызывает усиленное потоотделение, а с потом выводятся шлаки и токсины.
Помимо полного каталога саун и бань Екатеринбурга, пользователи могут прочесть полезные статьи, сауна ямал посвященные процессу парения, области банного дела, строительству саун, истории русской бани.
Помимо полного каталога саун и бань Екатеринбурга, пользователи могут прочесть полезные статьи, бани екатеринбург недорого посвященные процессу парения, области банного дела, строительству саун, истории русской бани.
[url=https://prednisone.skin/]prescription prednisone cost[/url]
Жители Краснодара имеют отличную возможность отдыхать в саунах и сауну краснодар краснодар цены банях города с пользой для здоровья.
Жители Краснодара имеют отличную возможность отдыхать в саунах и баня на октябрьской краснодар банях города с пользой для здоровья.
doxycycline buy no prescription: cheap doxycycline – doxycycline online pharmacy canada
Жители Краснодара имеют отличную возможность отдыхать в саунах и сауну краснодар краснодар цены банях города с пользой для здоровья.
На сайте “Дай Жару” создано несколько разделов сауна троя Вы можете выбирать район города, тип парной.
[url=https://prednisone.skin/]prednisone 50 mg tablet cost[/url]
amoxicillin generic brand how to buy amoxicillin online – where can you get amoxicillin
[url=http://nolvadex.download/]tamoxifen cost in uk[/url]
The] Link in Bio characteristic maintains vast significance for every Facebook as well as Instagram platform users because [url=https://linkinbioskye.com]biolink for Instagram[/url] provides a single solitary clickable connection inside a person’s profile page that actually points guests to external to the site sites, blog site articles, products, or perhaps any desired for destination. Illustrations of these sites giving Link in Bio services comprise which supply modifiable landing pages and posts to effectively combine numerous hyperlinks into one one single reachable and even user oriented destination. This capability turns into especially essential for the businesses, influencers, and also content creators seeking to promote specific for content material or perhaps drive their traffic flow into relevant to the URLs outside the actual platform’s. With every limited in options for clickable linkages within posts of content, having the a dynamic and furthermore current Link in Bio allows a members to effectively curate their very own online for presence in the platform effectively to and showcase the announcements to, campaigns, or even important in updates for.The actual Link in Bio attribute keeps immense relevance for all Facebook and also Instagram users as presents a unique clickable link in the one person’s account which points visitors to external to the platform websites, blog articles, products, or possibly any desired for destination. Examples of such websites supplying Link in Bio solutions comprise which often provide adjustable destination pages and posts to actually merge numerous links into single accessible and even user friendly spot. This specific function turns into particularly essential for all companies, influencers, and content material creators searching for to actually promote their specifically content pieces or drive a web traffic towards relevant to the URLs outside the the site.
With all limited in choices for all actionable hyperlinks within posts of the site, having an an active and furthermore updated Link in Bio allows a users to actually curate their particular online for presence effectively for and even showcase the announcements for, campaigns for, or perhaps important in updates for.
Ponte en marcha con Oxys! oxys lineus Es la eleccion perfecta para mantener tu piel en su mejor estado posible.
Маркетплейс косметологии Filllin.ru Платформа Филллин помогает подобрать процедуру, выбрать клинику и записаться на приём к косметологу. Онлайн-оплата и проверенные отзывы от реальных пациентов.
While this holds some truth, as images are often the first point of contact for potential clients, reputation house reviews it is important to recognise that building an online reputation goes beyond aesthetics.
Ponte en marcha con Oxys! Oxys Mexico Precio Es la eleccion perfecta para mantener tu piel en su mejor estado posible.
captopril without prescription order carbamazepine pill carbamazepine 200mg canada
amoxicillin buy canada amoxicillin 500mg capsules antibiotic – amoxicillin 500mg buy online uk
[url=http://erythromycin.download/]where to buy erythromycin gel[/url]
The brand emphasises online reputation should be an reputation house reviews integral part of the company’s revenue-generation and development strategies.
Маркетплейс косметологии https://filllin.ru Платформа Филллин помогает подобрать процедуру, выбрать клинику и записаться на приём к косметологу. Онлайн-оплата и проверенные отзывы от реальных пациентов.
Владельцы саун и бань Нижнего Новгорода Сауны в Нижнем Новгороде стараются организовать отдых своих посетителей с максимальным комфортом.
where to buy prednisone 20mg: prednisone 300mg – prednisone generic cost
[url=http://triamterene.science/]triamterene 75mg hctz 50mg tablets[/url]
Банкротство физических лиц в Москве https://proffbankrot.ru Развеем мифы о банкротстве! Списание долгов с физических и юридических лиц.
Поиск банного заведения можно осуществлять, выбрав нужный район или станцию метрополитена Бани Новосибирск цены сауны и бани Новосибирска являются прекрасным местом отдыха семьей.
Leveraging their proprietary IT technologies and cutting-edge artificial intelligence, reputation house SERM experts conducted an exhaustive research endeavor encompassing 28 prominent developers across the city.
Поиск банного заведения можно осуществлять, выбрав нужный район или станцию метрополитена сауна недорого сауны и бани Новосибирска являются прекрасным местом отдыха семьей.
where can i buy amoxocillin amoxicillin 500 mg online – ampicillin amoxicillin
Nikita Prokhorov, co-founder of reputation house, gave a presentation on online reputation management.
[url=https://valtrex.beauty/]can i order valtrex online[/url]
buy amoxicillin canada price for amoxicillin 875 mg – amoxicillin over the counter in canada
The study, conducted using AI software developed by reputation house The study, conducted using AI software developed by Reputation House, provides invaluable insights into the online reputation and presence of 28 operating companies.
турецкий хаммам или русская баня в Ростове-на-Дону, то на сайте баня ботаника в ростове на дону вы найдете множество заведений с подробным описанием, отзывами и реальными фотографиями.
over the counter prednisone pills: purchase prednisone canada – how to purchase prednisone online
prednisone over the counter australia: where to buy prednisone 20mg – buy prednisone without a prescription best price
[url=http://permethrina.online/]elimite price in india[/url]
https://moscow19.gazgold24.ru/zakon.html
Магазин спецодежды оптом и в розницу в Екатеринбурге рукавицы брезентовые
В Самаре большое количество бань и саун, Сауна киев Самара двери которых всегда открыты и для жителей, и для гостей города.
buy prednisone tablets uk: prednisone 100 mg – can you buy prednisone in canada
amoxicillin 825 mg cost of amoxicillin 875 mg – buy amoxicillin online mexico
В Самаре большое количество бань и саун, Дом с баней на сутки Самара двери которых всегда открыты и для жителей, и для гостей города.
Многие сауны и бани предлагают различные массажи, сауна заводская спа и косметические процедуры, парения с вениками.
can i buy amoxicillin over the counter how to buy amoxycillin – amoxicillin azithromycin
https://moscow2.gazgold24.ru/optom.html
Бани и сауны Тюмени оснащены различными парными: баня в поле можно найти русскую баню на дровах, жаркую и сухую финскую сауну, комфортный хаммам, экзотическую японскую офуро.
Бани и сауны Тюмени оснащены различными парными: дом баня можно найти русскую баню на дровах, жаркую и сухую финскую сауну, комфортный хаммам, экзотическую японскую офуро.
Современные заведения предлагают клиентам различные спа-процедуры, Баня в Челябинске недорого приглашают знатных банщиков и массажистов, предлагают услуги тренажерных и фитнес залов.
Brace yourself for a news story that will inspire you to make a difference. [url=https://news.nbs24.org/2023/07/14/854934/]offer as IMF deal bears[/url] Latest: Pakistan gets LNG shipment offer as IMF deal bears fruit I had a feeling that there was a hidden layer to this whole situation.
This] Link in Bio feature keeps vast significance for Facebook as well as Instagram users of the platform as [url=https://www.twitch.tv/linkerruby/about]Link in Twitch[/url] gives a single individual usable link within one person’s personal profile that really directs guests into external to the platform webpages, blogging site publications, products or services, or perhaps any sort of desired place. Illustrations of the webpages giving Link in Bio solutions comprise which usually give adjustable destination pages of content to really merge numerous links into one single accessible to everyone and user friendly location. This very functionality becomes really especially to vital for the companies, influencers, and content creators trying to find to actually promote a specific for content material or perhaps drive a traffic to the relevant to URLs outside the the particular platform. With all limited for options for all actionable linkages inside posts of the site, having the a and furthermore up-to-date Link in Bio allows members to really curate the their particular online presence in the site effectively for and even showcase their the newest announcements in, campaigns, or possibly important for updates in.The actual Link in Bio function maintains immense relevance for both Facebook along with Instagram members as gives a unique actionable connection in the the person’s profile page that really directs guests to the external to the site webpages, blog posts, products, or even any wanted destination. Samples of online sites providing Link in Bio services involve which offer customizable destination pages to actually consolidate numerous connections into an one single accessible to everyone and even easy-to-use spot. This functionality becomes really particularly essential for all organizations, influential people, and also content material creators trying to find to effectively promote a specifically content or perhaps drive traffic flow to the relevant for URLs outside the site.
With all limited to choices for all actionable links inside posts of the platform, having the a lively and also current Link in Bio allows platform users to actually curate a their very own online in presence effectively to and even showcase their the newest announcements to, campaigns, or important for updates to.
doxycycline 100 mg pill: buy doxycycline 100mg online india – doxycycline without rx
cheapest prednisone no prescription: prednisone 20 mg pill – over the counter prednisone cheap
fenofibrate where to buy tricor 160mg pill buy generic fenofibrate
where to get doxycycline in singapore: doxycycline 50mg capsules – doxycycline 20mg canada
[url=http://avodartdutasteride.foundation/]avodart online pharmacy uk[/url]
medicine amoxicillin 500 amoxicillin no prescipion – amoxicillin 500mg capsule buy online
buy epivir without a prescription buy generic epivir cost quinapril 10mg
[url=http://tretinoinb.online/]retin-a price[/url]
Бани и сауны в Санкт-Петербурге оснащены различными парными: бани с кальяном можно найти русскую баню на дровах, жаркую и сухую финскую сауну, комфортный хаммам, экзотическую японскую офуро.
prednisone price canada: http://prednisone1st.store/# average price of prednisone
free online dating and personals: singles near you – dating sites for seniors
Бани и сауны в Санкт-Петербурге оснащены различными парными: сауна спб с бассейном недорого можно найти русскую баню на дровах, жаркую и сухую финскую сауну, комфортный хаммам, экзотическую японскую офуро.
Игорь Боровиков родился в 1964 году в городе Шуя, окончил среднюю школу софтлайн игорь боровиков
[url=http://fenosteride.com/]propecia cheapest india no prescription[/url]
This] Link in Bio function possesses vast value for all Facebook and Instagram platform users as it [url=https://www.twitch.tv/linkerruby/about]Link in Twitch[/url] gives a single individual usable link within a person’s profile page which guides visitors to external to the platform webpages, blogging site posts, goods, or even any kind of desired for place. Illustrations of such sites giving Link in Bio solutions incorporate which give customizable landing page pages of content to actually merge several linkages into a single one particular accessible and furthermore user friendly place. This specific function becomes really especially for crucial for all organizations, influencers in the field, and even content makers looking for to effectively promote specifically content material or even drive their web traffic to the relevant URLs outside of the actual site. With all limited in options available for all usable connections within the posts of content, having a a dynamic and updated Link in Bio allows a users of the platform to really curate the their own online for presence in the platform effectively for and showcase the most recent announcements in, campaigns, or even important in updates to.The very Link in Bio feature keeps immense relevance for every Facebook as well as Instagram members as offers an unique clickable hyperlink within an user’s personal profile which leads users into external to the site webpages, blog site publications, items, or perhaps any desired to destination. Illustrations of the webpages providing Link in Bio solutions incorporate which offer customizable landing pages to actually consolidate together various connections into one accessible to all and even easy-to-use place. This particular function becomes actually particularly critical for every organizations, influential people, and even content material creators of these studies seeking to effectively promote the specifically content material or drive traffic to relevant for URLs outside the very platform’s.
With all limited in alternatives for the clickable links within the posts of the platform, having a an active and up-to-date Link in Bio allows the platform users to actually curate their particular online to presence online effectively and also showcase a the announcements to, campaigns to, or perhaps important for updates.
Многие сауны и бани в Липецке предлагают различные массажи, бани липецка спа и косметические процедуры, парения с вениками.
doxycycline 75 mg capsules: doxycycline 150 mg price – doxycycline 100mg cost in india
[url=http://tretinoincm.online/]medicine tretinoin cream[/url]
[url=http://albendazole.charity/]albendazole 400 mg tablet[/url]
buy prozac 40mg for sale revia 50 mg usa buy letrozole 2.5 mg
[url=http://escitalopram.science/]10 mg lexapro[/url]
https://mobic.store/# how can i get generic mobic no prescription
Here’s a beneficial resource I discovered https://www.accredited-college-degrees.com/sitemap.xml
buy frumil 5 mg pills buy differin paypal buy acyclovir generic
Наши аккумуляторы обеспечивают высокую производительность и надежность, что является ключевым фактором для бесперебойной работы вашего автомобиля в любых условиях https://digicar.com.ua/
Here’s a worthwhile resource I discovered https://www.lakecountrychristianchurch.org/sitemap.xml
[url=https://abaclofen.com/]average cost of baclofen[/url]
ed pills cheap: medications for ed – ed pills that really work
Found a fantastic site here https://www.ahumchurch.org/sitemap.xml
[url=https://propecia1st.science/#]propecia tablet[/url] generic propecia without dr prescription
csgo gambling sites
Found a good site here https://greekchurchbristol.com/sitemap.xml
[url=http://tretinoinb.online/]retin a 0.05 cream buy online[/url]
cost of cheap propecia online buying cheap propecia prices
[url=http://albendazole.charity/]buy albendazole 400 mg[/url]
Промокод 1xbet – Впишите секретное слово в анкете регистрации, 1xbet промокод на сегодня пополните счет от 100 рублей и получите бонус +130%.
Юридическая компания РЕЗУЛЬТАТ Юридическое обслуживание это полный спектр юридических услуг в одном месте.
[url=https://fenosteride.com/]cheap generic propecia online[/url]
Everything what you want to know about pills.
canadian pharmacies compare canada cloud pharmacy
Everything what you want to know about pills.
https://propecia1st.science/# get cheap propecia without dr prescription
п»їerectile dysfunction medication: ed pills for sale – ed treatment drugs
https://propecia1st.science/# order cheap propecia prices
[url=https://pharmacyreview.best/#]canada pharmacy online[/url] pet meds without vet prescription canada
Donna elegante e mecenate eclettica realizzo un circolo culturale nella Marina Gronberg Villa Reale di Marlia dove e oggi allestita la mostra a lei dedicata.
Наш магазин сотрудничает напрямую с ведущими производителями автомобильных масел https://trans-oil.com.ua/ что позволяет нам предлагать высококачественные продукты без дополнительных наценок.
canadian pharmacy tampa buying drugs from canada
The] Link in Bio characteristic holds immense importance for every Facebook and also Instagram users of the platform since [url=https://linkinbioskye.com]Link in Bio[/url] offers one single actionable linkage in one individual’s account that really guides visitors to the site into outside webpages, blogging site articles, products, or even any wanted destination. Examples of such sites supplying Link in Bio solutions include which often supply adjustable arrival pages to actually combine various connections into a single one reachable and furthermore user friendly spot. This functionality turns into especially to essential for every companies, social media influencers, and even content material creators trying to find to effectively promote their specifically content pieces or perhaps drive web traffic to relevant for URLs outside the platform the actual platform’s. With limited options for every usable hyperlinks inside the posts of the site, having a a dynamic and furthermore current Link in Bio allows for users to effectively curate their their very own online in presence in the platform effectively for and showcase the latest announcements in, campaigns to, or possibly important to updates in.The actual Link in Bio attribute possesses tremendous relevance for both Facebook along with Instagram platform users since provides a solitary clickable link within one individual’s account that guides visitors into outside websites, blog site articles, items, or even any sort of desired for place. Examples of these sites supplying Link in Bio solutions incorporate which often offer personalizable landing page webpages to really combine several linkages into one accessible and user-friendly destination. This particular function becomes actually especially essential for the businesses, influencers in the field, and even content material creators seeking to effectively promote a specifically content pieces or possibly drive their traffic to the site into relevant to URLs outside the very platform’s.
With all limited for options available for usable connections inside posts, having a a lively and even modern Link in Bio allows for users to effectively curate the their own online presence effectively in and also showcase their the newest announcements, campaigns to, or even important updates.
Наш магазин пропонує акумулятори різних ємностей і характеристик, https://makbc.com.ua/ щоб відповідати унікальним вимогам вашого автомобіля.
Что делать при сбое аккумулятора: https://www.5692.com.ua/list/435404 руководство по аварийному запуску и вспомогательным источникам питания.
propecia medication order generic propecia for sale
https://moscow23.gazgold24.ru/optom.html
https://moscow28.gazgold24.ru/news.html
buy valcivir 500mg without prescription where can i buy valaciclovir floxin cost
[url=http://triamterene.charity/]triamterene-hctz 75-50mg tab[/url]
get propecia tablets buy cheap propecia no prescription
https://propecia1st.science/# buy generic propecia prices
amoxacillian without a percription amoxicillin 500 coupon – generic amoxicillin cost
can you buy generic mobic no prescription [url=https://mobic.store/#]buy mobic pills[/url] can i purchase cheap mobic without insurance
[url=http://pharmacyonline.science/]cheap pharmacy no prescription[/url]
[url=https://robaxin.party/]robaxin 750 coupon[/url]
[url=http://prazosin.gives/]prazosin hcl for sleep[/url]
[url=https://baclofen.party/]baclofen 25[/url]
http://certifiedcanadapharm.store/# canada drugs online reviews
buying prescription drugs in mexico online [url=http://mexpharmacy.sbs/#]mexico drug stores pharmacies[/url] reputable mexican pharmacies online
http://indiamedicine.world/# world pharmacy india
The very] Link in Bio feature maintains tremendous value for both Facebook and also Instagram platform users since [url=https://linkinbioskye.com]Link in Bio[/url] offers a single single interactive linkage within an user’s account that actually leads visitors into external to the platform sites, weblog articles, products, or perhaps any type of wanted location. Instances of webpages offering Link in Bio services or products involve which often offer personalizable landing pages and posts to actually consolidate various links into an one particular accessible to everyone and even easy-to-use destination. This very feature becomes actually especially to vital for all companies, influential people, and also content creators seeking to really promote a specific for content items or perhaps drive their traffic to relevant to the URLs outside the platform the actual platform’s site. With all limited for options available for all clickable hyperlinks inside posts of the platform, having a a lively and also up-to-date Link in Bio allows a users of the platform to actually curate the their online presence in the site effectively for and showcase the the announcements, campaigns for, or even important in updates.This Link in Bio characteristic possesses huge significance for every Facebook as well as Instagram members since provides a single single interactive hyperlink within an member’s profile that actually guides visitors to the site to the outside sites, blog posts, items, or even any type of desired destination. Examples of these webpages providing Link in Bio services involve which usually give adjustable landing pages of content to consolidate multiple linkages into one single reachable and furthermore user oriented place. This very capability becomes really particularly essential for every companies, influencers, and even content material creators seeking to effectively promote a specific for content pieces or possibly drive the traffic to the site to relevant for URLs outside the actual platform’s site.
With limited options for every usable linkages within the posts of the platform, having a and furthermore up-to-date Link in Bio allows platform users to really curate their own online in presence in the platform effectively for and even showcase the the latest announcements to, campaigns in, or possibly important in updates in.
[url=https://duloxetine.foundation/]cymbalta duloxetine hcl[/url]
Вавада – это современная платформа с огромным выбором игр и выгодными бонусами для игроков Вавада казино Активируйте Промокоды Вавада и ощутите настоящий азарт и выигрывайте большие призы вместе с нами!
[url=http://onlinedrugstore.science/]mexican online mail order pharmacy[/url]
[url=https://nolvadextn.online/]price of nolvadex[/url]
бухгалтерские услуги
buy cefpodoxime without prescription cefpodoxime cost buy generic flixotide
http://certifiedcanadapharm.store/# canadian pharmacies comparison
legit canadian pharmacy [url=https://certifiedcanadapharm.store/#]canada online pharmacy[/url] canadian mail order pharmacy
http://certifiedcanadapharm.store/# canada pharmacy online legit
Marina Gronberg, as a kid, was blessed with marina groenberg a plethora of passions and talents that paved the way for her multi-faceted adulthood.
Marina Gronberg, as a kid, was blessed with marina groenberg a plethora of passions and talents that paved the way for her multi-faceted adulthood.
[url=http://tretinon.online/]where can i buy retin a cream in uk[/url]
Казино казино – это вопрос, вызывающая много разговоров и взглядов. Казино являются местами, где [url=https://t.me/s/kazino_online_bonusi]kazino online[/url] люди способны прочувствовать их везение, расслабиться и почувствовать порцию возбуждения. Они предлагают многие развлечения – от традиционных слотов до карточных игр и рулетки. Среди многих игорные дома являются местом, где разрешено почувствовать атмосферу роскоши, сияния и возбуждения.
Тем не менее для игорных домов существует и скрытая грань. Зависимость к игровых развлечений может привнести в глубоким финансовым и душевным сложностям. Игроки, те, кто потеряют управление над ситуацией, могут оказать себя на сложной жизненной ситуации, теряя сбережения и ломая связи с родными. Поэтому при прихода в игорный дом важно запомнить про модерации и разумной игре.
[url=https://metformin.party/]metformin tablet price[/url]
[url=https://lipitor.charity/]lipitor[/url]
[url=https://triamterene.charity/]triamterene 75mg hctz 50mg tablets[/url]
Медвежатники Харьков – Аварийное вскрытие замков любой сложности, Открываем без повреждений автомобили, квартиры, вскрытие замков харьков сейфы, двери любого уровня сложности.
Хотите освободиться от кредитов? банкротство физ лиц https://publishernews.ru/NewsAM/NewsAMShow.asp?ID=993 поможет вам с этим. Опытные юристы с большим стажем помогут освободиться от кредитных обязательств.
Медвежатники Харьков – Аварийное вскрытие замков любой сложности, Открываем без повреждений автомобили, квартиры, аварийное вскрытие машин харьков сейфы, двери любого уровня сложности.
Релакс-салон в Казани релакс массаж Москва массаж подарит вам полную релаксацию.
buying from online mexican pharmacy [url=https://mexpharmacy.sbs/#]medicine in mexico pharmacies[/url] mexican drugstore online
Банкротство физических лиц в Москве – довольно сложная процедура. В данной статье вам помогут разобраться как грамотно и эффективно провести данную процедуру https://newstes.ru/2023/06/29/procedura-bankrotstva-fizicheskogo-lica-vse-chto-vam-neobhodimo-znat.html
Что замедлило e-commerce развитие рынка http://free-health.ru/application/pages/?23-moy_oput_s_multivarkoy.html в 2022 году в Беларуси.
Что замедлило e-commerce развитие рынка https://irenastyle.ru/pags/posudomoechnuemashinugarmonii.html в 2022 году в Беларуси.
Банкротство физических лиц – подробная информация о процедуре в статье: https://1001sovet.com/article/bankrotstvo_fizicheskikh_lic_preimushhestva_i_ogranichenija/2023-07-01-45571
The entrepreneurial lifetime is not infinite marina groenberg You can pass the company on to your heirs
[url=http://hydroxyzine.party/]generic atarax online[/url]
https://indiamedicine.world/# buy medicines online in india
The entrepreneurial lifetime is not infinite marina groenberg You can pass the company on to your heirs
[url=http://azithromycin.solutions/]azithromycin pills buy[/url]
Looking for hassle-free music downloads? mp3 try myfreemp3 for a wide range of songs. With my free mp3, your favorite tracks are just a click away.
best online pharmacy india: online pharmacy india – п»їlegitimate online pharmacies india
Looking for hassle-free music downloads? my free mp3 try myfreemp3 for a wide range of songs. With my free mp3, your favorite tracks are just a click away.
pharmacy com canada: canadian pharmacy store – canadian pharmacy 365
[url=https://triamterene.charity/]triamterene 37.5 mg[/url]
mexican drugstore online [url=http://mexpharmacy.sbs/#]mexican rx online[/url] mexico pharmacies prescription drugs
Центр иностранных языков YES приглашает детей от 3-х лет, подростков курсы на английском языке онлайн и взрослых на онлайн-курсы английского языка.
http://indiamedicine.world/# indian pharmacy online
Не секрет, что владение иностранными языками открывает широкие возможности английский язык курс для карьерного роста, захватывающих путешествий по всему миру, организации увлекательного досуга.
Банкротство физических лиц в Москве – https://academ.info/news/economy/39610/ подробная информация по процедуре.
[url=https://prednisolone.solutions/]prednisolone 5 mg tablet[/url]
п»їbest mexican online pharmacies: buying prescription drugs in mexico – pharmacies in mexico that ship to usa
[url=https://tretinon.online/]retin a 20[/url]
is canadian pharmacy legit: canadian pharmacy 24 com – canada drug pharmacy
[url=https://pharmacyonline.science/]uk pharmacy[/url]
https://mexpharmacy.sbs/# mexico drug stores pharmacies
Производитель тренажеров, тренажеры для силовых тренировок оборудования и инвентаря для спортивных залов и домашних тренировок.
В интернет магазине Gazgold24 существенный выбор закиси азота и веселящего газа, https://gazgold24.ru/ который можно купить, позвонив менеджеру 24 часа(круглосуточно).
[url=http://flomaxr.online/]flomax 0.4[/url]
[url=https://celecoxib.party/]celebrex medication cost[/url]
Хэмилтону прогнозируют роль главного конкурента Ферстаппена в сезоне-2023 winline скачать бесплатно на андроид
tadalafil 40mg price generic cialis india viagra professional
Современная передовая стоматологическая клиника в Луганске Брекеты Луганск
best india pharmacy: indian pharmacy paypal – mail order pharmacy india
[url=https://lyrjca.online/]lyrica cap 75mg[/url]
Хэмилтону прогнозируют роль главного конкурента Ферстаппена в сезоне-2023 winline букмекерская мобильная
[url=https://difluca.com/]diflucan buy online[/url]
canadian online pharmacy reviews: canadian online pharmacy – canadian pharmacy meds reviews
[url=https://prednisome.com/]where can i buy prednisone online without a prescription[/url]
Уже около 5 лет визово-миграционное агентство «Визия» предоставляет широкий спектр качественных услуг, https://visia.com.ua/ru/glavnaya/ необходимых для беспроблемного выезда украинцев в Польшу и Европу.
http://mexpharmacy.sbs/# purple pharmacy mexico price list
Steam Desktop Authenticator sda steam its a desktop emulator of the Steam authentication mobile application.
mexico drug stores pharmacies [url=https://mexpharmacy.sbs/#]mexican border pharmacies shipping to usa[/url] mexican mail order pharmacies
zithromax online no prescription [url=http://azithromycin.men/#]zithromax cost canada[/url] where can i get zithromax over the counter
https://stromectolonline.pro/# ivermectin 3mg
[url=https://clopidogrel.party/]clopidogrel 75 mg cost[/url]
[url=https://lisinopil.com/]lisinopril 10mg tabs[/url]
zithromax online usa: buy zithromax online australia – generic zithromax over the counter
В окружении увлекающих развлечений ни одно имя не вызывает вот такой интерес и возбуждение, как казино дедди команда разработчиков Daddy казино равным образом будет работать над совершенствованием системы бонусов и предложений.
Куча лицензионных игр в свободном доступе https://clck.ru/35N48T
Официальный дилер Hyundai в Москве — замена двигателя элантра автосалон BorisHof.
Steam Desktop Authenticator steam guard pc its a desktop emulator of the Steam authentication mobile application.
[url=http://zanaflex.pics/]how much is zanaflex cost[/url]
[url=http://propranolol.science/]medicine inderal 40[/url]
[url=https://synteroid.online/]synthroid brand name price[/url]
[url=https://celecoxib.party/]celebrex canada prices[/url]
Steam Desktop Authenticator steam authenticator its a desktop emulator of the Steam authentication mobile application.
Pokies, known as slot machines in other parts of the world, have a deep-rooted history in [url=https://www.pokies.fi/are-there-any-pokies-that-support-youth-initiatives-in-australia/]leading software providers for online pokies[/url] gambling culture. They have long graced the floors of pubs, clubs, and casinos throughout the country. With the arrival of the internet and the rapid progression of technology, these conventional machines discovered a fresh home online, evolving into a phenomenon that captured the attention of both veteran players and new enthusiasts alike.
Online pokies have introduced a realm of comfort, diversity, and creativity for Australian players. There are currently innumerable online platforms providing a wide selection of pokies, each with unique themes, functions, and play mechanics. These online versions provide players with the chance to appreciate their preferred games from the convenience of their homes, all the while giving possibilities for bonus spins, bonuses, and progressive jackpots. The integration of cutting-edge graphics and enchanting soundtracks more boosts the engrossing experience, turning Aussie pokies online a notable element in the realm of digital entertainment.
Steam Desktop Authenticator steam guard pc its a desktop emulator of the Steam authentication mobile application.
Steam Desktop Authenticator its a desktop emulator sda steam of the Steam authentication mobile application.
https://azithromycin.men/# buy zithromax no prescription
where can i buy neurontin online: where can i buy neurontin from canada – neurontin 600
prescription drug neurontin [url=http://gabapentin.pro/#]neurontin discount[/url] medicine neurontin
buy generic minoxidil order tamsulosin 0.4mg online cheap buy erectile dysfunction drugs
[url=https://trimox.science/]amoxicillin 375 mg price[/url]
[url=http://deltasone.skin/]can you purchase prednisone for dogs without a prescription[/url]
buy acarbose pills for sale fulvicin 250mg cheap pill griseofulvin 250 mg
Официaльный caйт казино Cat Casino официальный сайт кэт казино это онлайн казино с библиотекой игр, которыми можно мгновенно наслаждаться практически через любой веб-браузер.
Официaльный caйт казино Cat Casino cat casino зеркало это онлайн казино с библиотекой игр, которыми можно мгновенно наслаждаться практически через любой веб-браузер.
Steam Desktop Authenticator its a desktop emulator of the Steam authentication mobile application steam guard pc
neurontin 400 mg price: neurontin prescription cost – neurontin 300 mg price
https://gabapentin.pro/# over the counter neurontin
[url=https://filllin.ru/procedures/inektsii_botoksa_1]Ботокс[/url]- суть процедуры заключается в том,что врач-косметолог вводит препарат на основе ботулотоксина в зоны, нуждающиеся в коррекции, например, междубровями, в уголки рта и глаз, в подбородок и лоб. После инъекций ботокса кожа разглаживается и сохраняет привлекательный вид в течение 6-8 месяцев при соблюдении всех рекомендованных процедур.
Медвежатники Харьков – аварийное вскрытие замков и дверей, авто, сейфов вскрыть замок харьков а также ремонт и замена замков в Харькове и области.
http://azithromycin.men/# zithromax 500 tablet
Led светильники по ценам производителя источники питания led
Медвежатники Харьков – аварийное вскрытие замков и дверей, авто, сейфов взлом машины харьков а также ремонт и замена замков в Харькове и области.
Led светильники по ценам производителя led драйвер
[url=http://phenergan.download/]phenergan 25mg tablets uk[/url]
[url=http://clopidogrel.party/]plavix price[/url]
http://antibiotic.guru/# buy antibiotics online
Awesome Web page, Keep up the useful work. thnx.
https://social.studentb.eu/read-blog/129480
УЗИ аппараты – это медицинские приборы, которые используются для проведения ультразвукового исследования медицинское оборудование купить в москве внутренних органов человека.
BIPAP аппараты – это медицинские устройства, которые используются для лечения дыхательных нарушений у пациентов с хронической обструктивной болезнью легких (ХОБЛ) купить оборудование для медицинских кабинетов ронхиальной астмой, обструктивным апноэ сна и другими заболеваниями легких.
top ed pills [url=http://ed-pills.men/#]ed medications online[/url] buy ed pills online
http://paxlovid.top/# buy paxlovid online
BIPAP аппараты – это медицинские устройства, которые используются для лечения дыхательных нарушений у пациентов с хронической обструктивной болезнью легких (ХОБЛ) медицинское оборудование с госрезерва купить ронхиальной астмой, обструктивным апноэ сна и другими заболеваниями легких.
paxlovid buy: Paxlovid buy online – Paxlovid buy online
Zeaxan en Peru es una solucion zeaxan donde comprar innovadora para mejorar la salud ocular y proteger tu vision.
Топ лучших казино, которые входят в рейтинг, самые популярные онлайн казино в 2023 году Лучшие казино с быстрыми выплатами и выгодными бонусами за регистрацию, положительными отзывами игроков и большими выигрышами.
Zeaxan en Peru es una solucion zeaxan perГє innovadora para mejorar la salud ocular y proteger tu vision.
Топ лучших казино, которые входят в рейтинг, самые популярные онлайн казино в 2023 году Рейтинг казино с быстрыми выплатами и выгодными бонусами за регистрацию, положительными отзывами игроков и большими выигрышами.
[url=http://lisinopril.party/]lisinopril 3972[/url]
[url=https://hydroxychloroquine.best/]hydroxychloroquine sulfate tabs 200mg[/url]
Дэдди казино — новый игрок на рынке азартных игр daddy casino официальный сайт Здесь каждый найдет развлечение по душе!
[url=http://silagra.trade/]silagra pills[/url]
[url=http://isotretinoin.science/]buy accutane cream[/url]
Дэдди казино — новый игрок на рынке азартных игр daddy casino официальный сайт Здесь каждый найдет развлечение по душе!
[url=http://modafiniln.com/]provigil 200 mg pill[/url]
Dive into the vibrant world of online gaming with daddy casino daddy casino официальный сайт Win big!
https://lipitor.pro/# lipitor 40 mg cost
[url=https://tetracycline.trade/]tetracycline 500mg for sale[/url]
can i buy generic avodart prices: cost avodart online – avodart brand name
http://lipitor.pro/# lipitor 20
2 prinivil [url=http://lisinopril.pro/#]lisinopril brand name in india[/url] lisinopril in usa
[url=https://gabapentin.science/]gabapentin online usa[/url]
Мигрант в РФ – расскажем, как законно переехать в Российскую Федерацию, перевезти семью, трудоустроиться Мигрант в РФ и получить необходимые документы.
[url=https://ventolin.science/]albuterol prices[/url]
Азелаиновый пилинг для лица
[url=https://silagra.science/]silagra tablets[/url]
Смотрите фильмы и сериалы бесплатно и без регистрации на Смотреть фильмы онлайн бесплатно в высоком качестве HD и FULLHD.
Смотрите фильмы и сериалы бесплатно и без регистрации на https://filmoteka.org/ в высоком качестве HD и FULLHD.
http://misoprostol.guru/# cytotec buy online usa
[url=https://fluoxetine.science/]buy prozac 10mg online[/url]
Изготавливаем мебель на заказ на собственном производстве с 1996 года для любых интерьеров под ключ:
мебель для кухни, гардеробной, детской, гостиной и любых других помещений.
cipro online no prescription in the usa: ciprofloxacin 500mg buy online – purchase cipro
[url=https://zithromaxc.online/]buy zithromax no script[/url]
[url=http://synthroid.beauty/]synthroid 0.15 mg[/url]
At IT company GLOBUS.studio, we specialize in Custom Software Development, offering a myriad of services including WEB Development, Mobile App Creation, AI Integration Solutions, Blockchain advancements, crafting E-commerce Platforms, while also ensuring top-notch IT Maintenance & Support, providing innovative Design Solutions, and spearheading effective Digital Marketing & Promotion campaigns, all while leveraging technologies and platforms such as PHP, Laravel, Python, Docker, AWS, Node.JS, WordPress, Magento, Angular.JS, Web Hosting Solutions React, Gitlab, Flutter, iOS, Android, Ethereum, GIT, Cloud Solutions, Chat Bots, and many more, ensuring that we cover the full spectrum of digital transformation needs for businesses in today’s rapidly-evolving digital landscape.
Cassino 888 Starz e um ilustre destino de entretenimento e apostas online que seduz os jogadores com uma variedade sem igual de alternativas de jogos e uma imersao de casino virtual absorvente. Com uma reputacao consistente e decadas de primor, o cassino disponibiliza uma base eletrizante para os aficionados de apostas explorarem alegria e excitacao.
Criado com base na renovacao e na procura pela alegria dos gamers, o “[url=https://s3.amazonaws.com/888starz/casino.html]Opções de pagamento no 888 Starz Casino[/url]” disponibiliza uma extensa leque de partidas de cassino, desde slot machines emocionantes ate mesas de jogo, alem de escolhas de cassino ao vivo com dealers profissionais. Sua interface elegante e atraente permite que os jogadores imersam-se em uma experiencia envolvente, enquanto os bonus e campanhas promocionais adicionam um elemento adicional de excitacao as suas experiencias de aposta. Com destaque na protecao e credibilidade, o “888 Starz Casino” utiliza recursos tecnologicos inovadores para assegurar transacoes seguras e proteger os dados dos jogadores, e sua grupo de apoio esta pronta para ajudar os competidores a a todo instante, proporcionando um meio ambiente de entretenimento tranquilo e seguro
https://ciprofloxacin.ink/# buy ciprofloxacin over the counter
cytotec online [url=http://misoprostol.guru/#]buy cytotec in usa[/url] cytotec abortion pill
http://lisinopril.pro/# lisinopril medication otc
Информация о путешествиях в Турции олюдениз а также кухня и традиции Турции
[url=https://albendazole.science/]albendazole canada[/url]
Изготавливаем мебель на заказ
казино Daddy официальный сайт это захватывающая игровая платформа, предоставляющая возможность игры игрокам из различных стран: Европы, Азии и Запада. В Daddy casino доступно множество браузерных приложений с потрясающей трехмерной графикой и захватывающим геймплеем. Пользователи могут наслаждаться разнообразными игровыми автоматами, интересными слотами и увлекательными развлечениями с участием живых дилеров.
[url=https://antabuse.science/]disulfiram india online[/url]
Разрешение на строительство — это государственный письменное удостоверение, предоставляемый официальными структурами государственного управления или субъектного самоуправления, который дает возможность начать возведение или исполнение строительных работ.
[url=https://rns-50.ru/]Получения разрешения на строительство[/url] формулирует правовые принципы и нормы к строительной деятельности, включая узаконенные типы работ, предусмотренные материалы и способы, а также включает строительные инструкции и пакеты охраны. Получение разрешения на строительные работы является необходимым документов для строительной сферы.
официальный сайт Дедди казино это захватывающая игровая платформа, предоставляющая возможность игры игрокам из различных стран: Европы, Азии и Запада. В Daddy casino доступно множество браузерных приложений с потрясающей трехмерной графикой и захватывающим геймплеем. Пользователи могут наслаждаться разнообразными игровыми автоматами, интересными слотами и увлекательными развлечениями с участием живых дилеров.
бронирование процедур в косметологии
http://misoprostol.guru/# п»їcytotec pills online
https://ciprofloxacin.ink/# buy cipro
http://ciprofloxacin.ink/# ciprofloxacin over the counter
buy cytotec [url=https://misoprostol.guru/#]purchase cytotec[/url] buy cytotec over the counter
melatonin 3mg for sale desogestrel without prescription buy danazol 100 mg generic
[url=https://valtrexm.com/]purchase valtrex online[/url]
http://ciprofloxacin.ink/# п»їcipro generic
Check this site for more topics https://samag.ru/forum/message/11635
Check this website for related posts https://gti-club.ru/forum/showthread.php?t=60994&p=588118
Желтый пилинг лица косметическая процедура, направленная на омоложение лица
[url=https://tetracycline.trade/]tetracycline 1[/url]
ViOil один из крупнейших производителей victor ponomarchuk и экспортеров растительных масел в Украине.
[url=http://netformin.com/]can i buy metformin without prescription[/url]
Желтый пилинг лица – популярная косметическая процедура, направленная на омоложение и улучшение состояния эпидермиса. Методика основана на использовании специального химического раствора, содержащего ретиноевую кислоту.
[url=https://flomaxp.com/]where to get flomax[/url]
Промышленная группа ViОil victor ponomarchuk Председатель совета директоров
[url=https://vermox.download/]vermox sale usa pharmacy[/url]
Промышленная группа ViОil пономарчук viol Председатель совета директоров
[url=https://celecoxib.science/]celebrex cost[/url]
Промышленная группа ViOil поддержала социальную инициативу винницких благотворителей victor ponomarchuk
Промышленная группа ViOil поддержала социальную инициативу винницких благотворителей пономарчук viol
[url=https://motrin.science/]motrin 600 price[/url]
[url=https://vermox.download/]price of vermox south africa[/url]
ViOil увеличила производство рапсового масла victor ponomarchuk В настоящее время ViOil принадлежит 13 зернохранилищ общей мощностью 360 тыс. тонн.
http://mexicanpharmacy.guru/# best online pharmacies in mexico
ViOil увеличила производство рапсового масла пономарчук viol В настоящее время ViOil принадлежит 13 зернохранилищ общей мощностью 360 тыс. тонн.
ViOil – лідер з виробництва ріпакової олії пономарчук viol
[url=https://diflucan.business/]diflucan tablet 100 mg[/url]
india pharmacy mail order: indianpharmacy com – online pharmacy india
dydrogesterone 10 mg pills order generic jardiance 25mg jardiance 25mg uk
На нашем сайте вы сможете выбрать подходящую для вас экскурсию в Сочи, Адлере экскурсии Абхазия форум
77 canadian pharmacy: canadian pharmacy victoza – legitimate canadian pharmacy
ПГ ViOil – один из самых мощных производителей растительных масел в Украине victor evgenevich ponomarchuk viol
best online pharmacies in mexico [url=https://mexicanpharmacy.guru/#]п»їbest mexican online pharmacies[/url] п»їbest mexican online pharmacies
На нашем сайте вы сможете выбрать подходящую для вас экскурсию в Сочи, Адлере экскурсии Сочи
ПГ ViOil – один из самых мощных производителей растительных масел в Украине victor ponomarchuk
[url=http://cialis.best/]generic cialis uk pharmacy[/url]
[url=http://domperidone.party/]order motilium online[/url]
[url=https://amoxicillinf.com/]trimox buy[/url]
Normotim by Normopharm Is Helping To Manage Stress and Depression normotim normopharm Stress and depression have become prevalent challenges in today’s fast-paced world.
Регистрация на официальном сайте 1Win казино может выполняться несколькими способами ван 1вин
Запуск является широко используемой методом в области [url=https://xrumer.ee/progon-po-joomla-k2]РїСЂРѕРіРѕРЅ хрумером заказать[/url] интернет-маркетинга, которая используется для увеличения видимости веб-сайта через формирования множества числа обратных направлений ссылок на него с различных ресурсов. Инструмент Хрумер – это софт, разработанная специально для самостоятельного размещения комментариев, статей, и линков на дискуссионных площадках, блогах и прочих сайтах. Такой автоматизированный процесс может оказывать воздействие на ранжирование сайта в поисковых сервисах, но следует учитывать, что с временем алгоритмы поиска становятся более интеллектуальными, и они могут определить и санкционировать за создание вручную линков, что может оказать негативное воздействие на репутацию вашего сайта.
Существенно понимать, что автоматизированный процесс с помощью Хрумера может способствовать как благоприятные, так и отрицательные последствия. С первоначальной точки зрения, он может временно повысить множество ссылок на вашем сайте, что, в свою очередь, может повлиять на рейтинг в поисковой выдаче. С второй стороны, если использовать этот подход бездумно и в больших объемах, это может вызвать снижению ранжирования, ограничениям со стороны поисковых систем или даже остановке вашего сайта. Поэтому рекомендуется разумно подходить к вопросу запуска через Хрумер, соблюдать [url=https://serpstat.com/ru/blog/chto-takoe-xrumer]хрумер[/url] содержание и релевантность создаваемых ссылок, а также придерживаться нормы натуральности и этичности в цифровом маркетинге
us pharmacy cialis: generic cialis – cialis mit dapoxetine
This dedication is particularly evident in their pioneering product normotim effect
Bio Prost es un suplemento para la salud masculina Bio prost, Bio prost Peru 100% natural en Peru.
the taste of a ripe peach is juicy and sweet gymnastic the sight of a shooting star streaking across the night sky is a moment of magic
Normopharm is a trusted name in the pharmaceuticals landscape, renowned for its commitment to innovation, quality, normotim reviews and the pursuit of enhancing human health.
Interestingly, Normotim may also serve as an unexpected ally normotim in the battle against smoking.
[url=http://fluconazole.pics/]diflucan 100 mg tab[/url]
geneneric cialis aus: buy cialis no prescription – cialis on ebay
мобильная версия Gama Casino
зеркало гама казино
wallmart cialis: Cialis without a doctor prescription – cialis online america
Эвакуатор в Переславле и Ярославской области Эвакуатор Переславль Мы предлагаем нашим клиентам услуги эвакуатора в Переславле-Залесском
https://edpill.men/# pills for ed
Normotim by Normopharm Is Helping To Manage Stress and Depression normotim lithium ascorbate The Best Report Benzinga Has Ever Produced.
[url=https://escitalopram.party/]lexapro medication[/url]
Stress and depression have become prevalent challenges in today’s fast-paced world, normotim reviews affecting individuals from all walks of life.
[url=http://toradol.download/]toradol for dogs[/url]
Kamagra tablets: cheap kamagra – buy kamagra
order cialis online no prescription reviews [url=http://cialis.science/#]Buy Tadalafil 20mg[/url] buy cialis online cheap
[url=http://diflucan.business/]order fluconazol[/url]
buying cialis online canadian order: Buy Tadalafil 20mg – cialis dapoxetine overnight shipment
[url=http://toradol.download/]toradol gel[/url]
Normopharm’s commitment to innovation and enhancing human health is exemplified in normotim Stress and depression have become prevalent challenges in today’s fast-paced world, affecting individuals from all walks of life.
[url=https://diclofenac.party/]voltaren where to purchase[/url]
https://kamagra.men/# kamagra oral jelly
[url=https://furosemide.science/]furosemide price[/url]
impotence pills: medicine for erectile – best male ed pills
To presume from true to life news, dog these tips:
Look fitted credible sources: https://qisetna.com/pgs/what-happened-to-april-simpson-on-fox-2-news.html. It’s eminent to guard that the report origin you are reading is respected and unbiased. Some examples of reputable sources include BBC, Reuters, and The Different York Times. Read multiple sources to get back at a well-rounded sentiment of a isolated info event. This can support you carp a more ideal facsimile and avoid bias. Be hep of the viewpoint the article is coming from, as flush with respectable report sources can have bias. Fact-check the gen with another commencement if a expos‚ article seems too sensational or unbelievable. Till the end of time make sure you are reading a known article, as tidings can transmute quickly.
By means of following these tips, you can fit a more au fait rumour reader and better apprehend the world around you.
One of the significant benefits of ascorbic acid is normotim its contribution to immune system function and collagen production.
Normopharm has a reputation for delivering top-notch health supplements, normotim normopharm and Normotim is no exception.
where to by cialis: buy cialis no prescription – cialis blac
[url=http://avaltrex.com/]valtrex rx coupon[/url]
[url=http://vermox.trade/]vermox india[/url]
[url=https://fluconazole.party/]diflucan medication canada[/url]
When you combine lithium, ascorbic acid, normotim and vitamins B1 and B6, you get a multifaceted powerhouse within Normotim.
1xbet bonus
1xbet free bet code
https://gabapentin.tech/# neurontin tablets uk
buy misoprostol over the counter: п»їcytotec pills online – buy cytotec over the counter
http://ivermectin.auction/# generic ivermectin cream
stromectol in canada: stromectol 3 mg tablet – ivermectin oral
ivermectin where to buy: ivermectin price uk – stromectol
cytotec abortion pill: buy cytotec pills online cheap – Misoprostol 200 mg buy online
https://cytotec.auction/# Cytotec 200mcg price
[url=http://fluconazole.party/]diflucan 150mg tab[/url]
Игра Мелстроя в бурмалду представляет собой занимательное народное развлечение, глубоко укорененное в культурном наследии Киргизии. Эта игра старинная требует не только физических навыков, но и планирования. Участники бросают древние каменные шайбы в пос Richtung специальной ямы, расположенной на поверхности, и стараются заработать наибольшее число пунктов. Каждый бросок представляет собой испытание навыкам и сноровке спортсмена, а победитель получает уважение и почет со стороны зрителей.
Игра в бурмалду на сайте на сайте mellstroy – https://linktr.ee/mellstroy.glavstroy регулярно превращается в частью культурных событий и праздников в Киргизии. Она не только способствует сохранению традиций и национальной идентичности, но и заводит дружбу граждан, создавая теплую и борьбу атмосферу. Бурмалду – это не просто так развлечение, это сущность единства и веселья в культуре Киргизии
http://cytotec.auction/# Misoprostol 200 mg buy online
neurontin 100mg tablets: buying neurontin without a prescription – neurontin 202
[url=https://nolvadextam.online/]tamoxifen pill cost[/url]
Деревянные дома от производителя, строим по всей РФ, у нас вы можете заказать дом из бруса работаем по договору и без предоплат.
https://cytotec.auction/# buy cytotec pills online cheap
SEO продвижение сайта процедура, позволяющая достичь идеального состояния лица.
Cytotec 200mcg price: п»їcytotec pills online – Cytotec 200mcg price
https://ivermectin.auction/# ivermectin rx
[url=https://happyfamilystorex.online/]canadian pharmacy store[/url]
purchase ferrous sulfate pills buy ferrous sulfate for sale sotalol canada
stromectol coronavirus: ivermectin gel – stromectol how much it cost
[url=https://metforminb.com/]metformin 850 mg tablets price[/url]
https://cytotec.auction/# buy misoprostol over the counter
Here at Betfair Casino, we really do have something for everyone: innovative and immersive slots alongside classic vintage arcade games online, not to mention our official branded slot: Ted. No matter what kind of slot gamer you are, you’ll find something to love at Betfair Casino. Security should be a top priority when considering an online casino. Ensure that the casino has robust security protocols in place to protect your funds and account information. Reputable casinos are transparent about their security measures, and it is essential to review this information before signing up. Look for casinos with SSL encryption, secure payment methods, and strong privacy policies. Café Casino is a mobile-friendly online gambling platform, making it easy for everyone to get started. Security should be a top priority when considering an online casino. Ensure that the casino has robust security protocols in place to protect your funds and account information. Reputable casinos are transparent about their security measures, and it is essential to review this information before signing up. Look for casinos with SSL encryption, secure payment methods, and strong privacy policies.
http://greenfive.co.kr/bbs/board.php?bo_table=free&wr_id=21626
GET THIS BONUS NOW! New post, moicuate2014 replied to Weekly Winners for June 12th The moment you sign up on the casino, each new member is entitled to the special tournaments. On each of the dollar wagered on the casino, each player gets just a point. On the weekly tournament, the players that get 1st, 2nd and 3rd position will be given $200, $100 and $50 respectively. Based on the information garnered from Thebes’s website, it began in 2008. Since there aren’t many online casinos then, it’s a good period for Thebes. The fact that the ten-year-old Thebes is still in existence leaves an impressive mark. It’s because most fraudulent casinos may not even last a year or two. Live Casino – Roulette, Lightning Roulette, Double Ball Roulette, Blackjack, Speed Blackjack, Casino Stud Poker, Caribbean Stud Poker, Casino Hold’Em Poker, Dragon Tiger, Punto Banco, Crazy Time, Dream Catcher, Deal Or No Deal, Side Bet City
https://seo-doors.ru seo продвижение сайта
Игра в бурмалду на сайте на канале – [url=https://t.me/s/mellstroy_bonus_tg]mellstroy bonus[/url] постоянно бывает составной культурных событий и праздников в Киргизии. Она не только способствует поддержанию национальных традиций и национальной самобытности, но и сближает участников, создавая дружественную и конкурентную обстановку. Бурмалду – это не только развлечение, это знак объединения и увеселения в культурной традиции
Бонусы от Мелстроя в бурмалду представляет собой занимательное традиционное времяпрепровождение, глубоко укорененное в традициях Киргизии. Эта игра древняя требует не только физических навыков, но и планирования. Участники бросают древние каменные шайбы в направлении ячейки, расположенной на поле, и стараются набрать максимальное количество пунктов. Каждый бросок представляет собой испытание навыкам и ловкости спортсмена, а победитель получает признание и почет со стороны окружающих.
stromectol over the counter: ivermectin 200mg – ivermectin price comparison
https://gabapentin.tech/# neurontin gabapentin
buy cytotec in usa: cytotec buy online usa – Cytotec 200mcg price
[url=https://ivermectin.party/]buy ivermectin pills[/url]
[url=http://doxycycline.today/]doxycycline 50 mg cost[/url]
https://cytotec.auction/# cytotec abortion pill
Relifix Crema es un producto disenado especificamente Relifix Crema para tratar y aliviar los sintomas asociados con las hemorroides.
buy cytotec online: cytotec abortion pill – cytotec online
buy cytotec online fast delivery: cytotec pills buy online – buy cytotec pills online cheap
[url=https://neurontin.monster/]how much is gabapentin 100mg[/url]
order pyridostigmine 60mg sale maxalt 5mg cheap buy maxalt 10mg
In the world of online gambling, finding a trustworthy and rewarding casino can be a challenging task Online roulette With numerous options available, it’s crucial to have a reliable platform that simplifies the process.
https://gabapentin.tech/# neurontin 100 mg cap
Mellstroy Bonus – это превосходная шанс для наших получить дополнительные бонусы при собственного выбора наших стройматериалов и товаров для ремонта. [url=https://telegra.ph/Mellstroy-Bonus-09-07]Mellstroy bonus[/url] всегда стремимся радовать наших сотрудников и делаем это через разнообразные промо-акции и специальные предложения. Подарки могут включать в себя скидки, подарки или другие выгодные варианты, которые помогут сэкономить ваши финансы при реализации строительных или ремонтных задач.
Для того чтобы быть в курсе всех современных бонусных акций от Меллстрой, подписывайтесь на наши авторизованные каналы в Телеграм, следите за обновлениями на нашем веб-сайте и обращайтесь к нашим менеджерам. Наша компания гордимся качеством наших изделий и целимся сделать вашу покупку еще более выгодной и приятной. Меллстрой – ваш коллега в строительстве и ремонте с экстра бонусами для всех наших клиентов.
neurontin 800 mg pill: neurontin 1800 mg – neurontin price india
[url=https://amoxicillin.click/]buying amoxicillin online uk[/url]
buy ivermectin nz: stromectol cream – ivermectin lotion price
Marina Groenberg is a well-known top manager, investor and businesswoman marina grönberg She has been living in Switzerland since 2008 and is a Swiss citizen.
Играть онлайн в игровые автоматы Джон бонусы с бесплатным входом Заносы казино онлайн бонусы гарантированы и бесплатно 100уе.
cytotec pills buy online: buy cytotec online – Cytotec 200mcg price
Играть онлайн в игровые автоматы Джон бонусы с бесплатным входом Играть казино онлайн бонусы гарантированы и бесплатно 100уе.
[url=http://prednisone.guru/]prednisone 50 mg price in india[/url]
[url=http://ivermectin2023.com/]stromectol cream[/url]
[url=http://amoxicillin.monster/]amoxicillin 250 mg tablet price[/url]
[url=http://tadalafil.media/]cialis everyday[/url]
They are all aimed, one way or another, marina groenberg biography at improving the quality of people’s life and managing the environment more sustainably.
They are all aimed, one way or another, marina groenberg at improving the quality of people’s life and managing the environment more sustainably.
Скачивай mp3 песни в хорошем качестве, слушай треки онлайн бесплатно на сайте mp3uk
Bet Андреас Casino – это известнейшее онлайн-казино, которое стартовало свою деятельность в 2023 году и с тех пор превратилось в одним из главных в индустрии азартных игр. Оно подает обширный спектр игр, включая слоты, рулетку, 21, карточные игры и дополнительные популярные азартные развлечения. https://t.me/s/Bet_Andreas_Casino популярно своими живыми крупье, которые создают атмосферу истинного казино, даря игрокам наслаждаться азартом из комфорта своего дома.
Кроме того, Bet Andreas Casino имеет государственной лицензией и контролируется соответствующими органами, что гарантирует игрокам честную и надежную среду для игры. С различными бонусами и акциями для новых и постоянных клиентов, а также удобными методами оплаты и вывода средств, Казино 888 даёт отличные условия для любителей азартных игр и стоит в числе наиболее почтенных онлайн-казино в мире.
best online pharmacies in mexico: best online pharmacies in mexico – mexico pharmacies prescription drugs
buying prescription drugs in mexico: buying prescription drugs in mexico – mexican mail order pharmacies
[url=http://drugstore.monster/]canadianpharmacyworld[/url]
lunc crypto price prediction
boxlight stock forecast 2025
Her biography reflects her profound knowledge marina groenberg and experience in the field of management.
п»їlegitimate online pharmacies india: Medical Store in India – online pharmacy india
[url=http://lipitor.today/]buy generic lipitor cheap[/url]
ВК-Телеком[url=https://www.fesclub.ru/kabel-vvg-png-osobennosti-primeneniya-i-preimushhestva/] Кабель ВВГ-Пнг[/url]
[url=http://ivermectin.email/]buy stromectol online[/url]
Her biography reflects her profound knowledge marina grönberg and experience in the field of management.
[url=http://valtrex.monster/]buy valtrex no rx[/url]
888Starz spelu nams ir populars online kazino, kas piedava plasu izklaidi un losu izveli. Tas ir sanemis labu slavu un uzticibu speletaju vidu, piedavajot dazadas losu speles, ieskaitot sloti, ka ari klasiskas kazino speles, piemeram, ruleti un blekdzeku. Kazino ir slavens ari ar savam izdevigajiem piedavajumiem, kas speletajiem dod vairak iespeju laimet un izjust spelu piedzivojumu.
Turklat “888Starz kasino” – https://telegra.ph/888starz-Online-Kazino-Latvij%C4%81-09-10 piedava aizsargatu un drosu spelu vidi, kura speletaji var saustities erti un drosi. Vini piedava ari klientu atbalsta pakalpojumus, kas atbalsta risinat jebkadas izaicinajumus vai jautajumus. Kopuma “888 kasi” ir zinams spelu nams, kas piesaista gan sakotnejos, gan pieredzejusos speletajus ar savu sazinas lidzeklu klastu un izcilu klientu apkalposanu
[url=https://amoxicillin.monster/]amoxicillin otc uk[/url]
Быстровозводимые здания – это новейшие конструкции, которые отличаются большой быстротой возведения и гибкостью. Они представляют собой постройки, состоящие из эскизно выделанных деталей либо узлов, которые способны быть быстро собраны в пункте застройки.
[url=https://bystrovozvodimye-zdanija.ru/]Быстровозводимые конструкции из сэндвич панелей[/url] отличаются податливостью и адаптируемостью, что позволяет легко преобразовывать и переделывать их в соответствии с интересами покупателя. Это экономически выгодное и экологически стойкое решение, которое в крайние лета заполучило широкое распространение.
mexican drugstore online: medication from mexico pharmacy – mexico drug stores pharmacies
online shopping pharmacy india: Online medication home delivery – world pharmacy india
Сделать новый паспорт в Пензе за 1 день с гарантией http://kabina34radio.com/news/20.html все новости мира на одном сайте.
http://indiaph.life/# india pharmacy mail order
[url=http://synthroid.today/]cost of synthroid 50 mcg[/url]
[url=https://cialis.cfd/]best generic cialis[/url]
top 10 pharmacies in india: Online medication home delivery – pharmacy website india
best india pharmacy: Medical Store in India – top online pharmacy india
buy prescription drugs from canada cheap: Certified Canada Pharmacy Online – my canadian pharmacy
brand latanoprost buy cheap generic exelon order rivastigmine 6mg online cheap
order betahistine 16mg for sale betahistine 16mg uk order probenecid 500mg online
mexican drugstore online: buying prescription drugs in mexico – mexican online pharmacies prescription drugs
Экологические выгоды использования европоддонов https://handcent.ru/novosti/27632-evropoddony-ot-kompanii-vremya-pallet.html Экологичные европоддоны.
Klub hazardowy kaktuz bet otworzyl swoje wirtualne drzwi dla fanow rozrywek hazardowych w 2023 roku.
[url=http://prednisolone.monster/]buy prednisolone 25mg tablets[/url]
Каждый, кто увлекается спортивными ставками, хочет повысить свои шансы на победу и заработок http://credforum.ru/showthread.php?t=13772
Каждый, кто увлекается спортивными ставками, хочет повысить свои шансы на победу и заработок https://rosalind.info/users/pin-upkz/
ivermectin 6mg: buy Ivermectin for humans – ivermectin eye drops
stromectol ivermectin 3 mg: buy stromectol – ivermectin price usa
Вы можете купить кабель любой марки и сечения – купить провод при необходимости поставим товары на заказ.
cost of ivermectin lotion – http://ivermectin.today/# ivermectin 5 mg price
Мы составили честный рейтинг всех игровых автоматов и на первом месте находится Gama casino, здесь быстрые выплаты, казино Гамма моментальное решение любых проблем, крутые турниры и лицензионные слоты.
[url=http://propecia.monster/]finasteride for women[/url]
stromectol online canada: buy ivermectin online – ivermectin price comparison
SEO — это процесс улучшения видимости веб-сайта в поисковых результатах, официальный сайт продвижение таких как Google, Bing, Yandex и другие.
вход Gama Casino
пин ап сайт казино
Цены на строительство заборов под ключ зависят изготовление забора от большого количества факторов и особенностей.
Цены на строительство заборов под ключ зависят монтаж забора от большого количества факторов и особенностей.
[url=https://onlinepharmacy.monster/]save on pharmacy[/url]
stromectol medicine: buy ivermectin online – ivermectin 4000 mcg
[url=https://ivermectin.party/]buy ivermectin cream[/url]
[url=http://clomid.works/]clomid sale[/url]
ivermectin pills canada – http://ivermectin.today/# ivermectin 3mg tablets
Престиж: обучение в Нижнем Новгороде – центр дистанционного обучения стоимость курса узнайте стоимость обучения.
premarin pills usa viagra sales viagra 50mg drug
Престиж: обучение в Нижнем Новгороде – центр дистанционного обучения стоимость курса узнайте стоимость обучения.
Лучше чем поисковая система Google, переходите на сайт google.kz и вы найдете что ищите, лучшая альтернатива гуглу.
Лучше чем поисковая система Google, переходите на сайт google.com и вы найдете что ищите, лучшая альтернатива гуглу.
[url=http://onlinepharmacy.monster/]tops pharmacy[/url]
Доставка Elf Bar электронные сигареты купить в Москве за 30 минут доставка elf bar Официальный сайт ELF BAR.
[url=http://tadalafil.click/]tadalafil 5mg tablets online[/url]
Check this website for related articles http://emycountry.forum.cool/viewtopic.php?id=484
[url=https://neurontin.monster/]gabapentin 500 mg capsules[/url]
В казино Гама игроки могут мгновенно получить доступ Гама казино зеркало ко всем своим любимым играм казино.
В казино Гама игроки могут мгновенно получить доступ Гама казино зеркало ко всем своим любимым играм казино.
[url=http://acyclovir.today/]acyclovir cream 50mg[/url]
[url=http://atarax.today/]buy atarax tablets[/url]
stromectol 0.5 mg: stromectol 15 mg – buy ivermectin uk
Marina Groenberg offers a brief biography, introducing her pathway marina groenberg to financial mastery.
where to buy stromectol online: ivermectin 9 mg – stromectol online pharmacy
Marina Groenberg offers a brief biography, introducing her pathway marina groenberg biography to financial mastery.
Отсюда Вы можете быстро добраться до Эрмитажа, Русского музея, санкт петербург отели и гостиницы цены недорого, Исаакиевского собора или пешком прогуляться до Петропавловской крепости и Летнего сада.
https://gabamed.store/# 800mg neurontin
[url=http://viagraindia.online/]viagra in india cost[/url]
Престижное обучение в Самаре – центр дистанционного обучения стоимость обучения, дарим 30 дней на обучение.
Престижное обучение в Самаре – центр дистанционного обучения курсы, дарим 30 дней на обучение.
Marina Groonberg wurde in einer Familie marina grenberg biografie von Luftfahrtingenieuren geboren.
stromectol 3mg: stromectol order – buy ivermectin canada
мебель по индивидуальному заказу недорого
http://lasixfurosemide.store/# lasix side effects
Mostbet India is a leading company in the sports betting industry, offering individuals the opportunity Gama казино to bet for real money from the comfort of their homes, via the Internet.
Купить грязезащитные ковры и дорожки в Москве можно на купить грязезащитные ковры в москве, широкий выбор грязезащиты.
buy neurontin online no prescription: neurontin prescription online – neurontin 600 mg coupon
stromectol uk: ivermectin online – ivermectin lotion price
Top manager Marina Groenberg leads Hemma Group with distinction marina groenberg A noted investor active in Europe and the US.
https://lasixfurosemide.store/# furosemida 40 mg
No Brasil, ate 2012, nao havia uma unica casa de apostas decente https://www.google.com.tj/url?q=https://mostbet-online-com.com/ky/mostbet-kg/
Top manager Marina Groenberg leads Hemma Group with distinction marina groenberg A noted investor active in Europe and the US.
No Brasil, ate 2012, nao havia uma unica casa de apostas decente https://groups.wharton.upenn.edu/click?uid=df43aafa-ffcc-11e6-a4f9-0050568907b6&r=https://mostbet-online-site.com/en/mostbet-bd/
[url=http://ivermectin.trade/]stromectol ireland[/url]
neurontin online usa: can i buy neurontin over the counter – can you buy neurontin over the counter
[url=http://finasteride.monster/]finasteride price[/url]
Вы ищете надежное и захватывающее онлайн-казино, тогда Вулкан Платинум – идеальное место для вас!
Профессиональное SEO откроет вашему сайту дорогу к новым возможностям и клиентам сколько стоит продвижение сайта в гугле профессиональные SEO услуги на страже вашего бизнеса.
корпусную мебель на заказ
Improving indexing of pages that are already known to the search engine, link indexing url but are not getting added to the index.
pharmacy website india: top 10 pharmacies in india – reputable indian online pharmacy
[url=http://flomax.cyou/]noroxin price[/url]
Вы ищете надежное и захватывающее онлайн-казино, тогда Вулкан Платинум идеальное место для вас!
[url=http://clonidinepill.com/]where can i purchase clonidine[/url]
Вы ищете надежное и захватывающее онлайн-казино, тогда Вулкан Платинум идеальное место для вас!
Мелстрой – это одна из ведущих строительных фирм, деятельных на рынке России. Она занимается на создании и реализации строительных проектов различных объемов, с начала от жилых объектов и завершаяся промышленными структурами. Благодаря собственному собранию плодородному опыту работы и квалифицированной службе экспертов, Строительная компания удалось зарекомендовать себя как надежного партнера в строительной деятельности.
Предприятие соблюдает стандартов высокого качества и соблюдает сроки осуществления проектов, что делает организацию популярным участником рынка на рынке стройки. Кроме того, Строительная компания энергично внедряет инновационные технологии и ориентируется на соблюдению экологических норм в своей работе. Эта организация играет важную функцию в развитии строительной сферы России, способствуя созданию современной строительной инфраструктуры и комфортных жилых пространств для населения
legitimate canadian pharmacy online: CIPA certified canadian pharmacy – onlinecanadianpharmacy
[url=http://flomax.cyou/]buy flomax in india[/url]
http://mexicoph.icu/# buying from online mexican pharmacy
Neben ihren geschaftlichen Erfolgen widmet sie sich der marina grenberg biografie Restaurierung historischer Denkmaler und engagiert sich fur wohltatige Zwecke.
https://indiaph.ink/# top online pharmacy india
Кисти для макияжа – это незаменимый женский инструмент набор кистей для теней для создания идеального макияжа.
best canadian pharmacy to order from: CIPA certified canadian pharmacy – canadian drugstore online
The service will help you to attract the indexing robots of Google search engine (Googlebot) free link indexer url and get indexed your web page or backlinks faster.
[url=http://amoxicillin.monster/]where to purchase amoxicillin[/url]
[url=http://drugstore.monster/]online pharmacy no prescription[/url]
“Уважаемые ценители кальяна,
Приглашаем вас в мир непревзойденного курения с нашими уникальными кальянными смесями! Мы гордимся представить вам самый широкий и разнообразный ассортимент ароматических и вкусовых миксов для вашего кальяна.
Почему “”Oshisha”” – ваш идеальный выбор:
Качество без компромиссов: Мы используем только высококачественные ингредиенты, чтобы обеспечить вам непревзойденный вкус и густые облака дыма.
Богатый выбор вкусов: У нас есть более 50 уникальных вкусов, от классических фруктовых смесей до эксклюзивных вариаций с пряностями и ягодами.
Экономьте деньги: Наши цены конкурентоспособны, и мы предлагаем регулярные акции и скидки для наших постоянных клиентов.
Легкость заказа: Вы можете сделать заказ у нас онлайн с доставкой прямо к вам домой.
Профессиональный совет: Наши эксперты всегда готовы помочь вам выбрать идеальную смесь под ваши предпочтения.
Не упустите шанс настоящего кальянного удовольствия! Попробуйте наши смеси уже сегодня и ощутите разницу.”
Кальянные смеси
medication from mexico pharmacy: mexico pharmacies prescription drugs – best online pharmacies in mexico
http://mexicoph.icu/# mexican drugstore online
http://mexicoph.icu/# mexican drugstore online
Грузоперевозки. Доставка посылок и писем в Европу из Калинимнграда Пассажирские перевозки в Европу из Калининграда Грузоперевозки (запчасти) из Германии и Польши.
What are the problems facing the contemporary banking system and how Victor Orlovski do international relations affect the efficiency of financial technologies.
canadian pharmacies compare: certified and licensed online pharmacy – canadian online drugstore
Without [url=http://lasixpro.com/]lasix 40 mg without prescription[/url], I don’t know how I would manage my water retention issues.
https://filllin-daily.ru – авторитетный блог о косметологии. Статьи от проверенных авторов и практикующих врачей. Актуальные новости из мира бьюти.
http://interpharm.pro/# best online pharmacies without prescription
Мальчишник — это незабываемое событие, отрывки из которого вы будете переживать снова и снова חשפניות-
pharmacy.com canada: canadian pharmacy online no prescription needed – canadian pharmacy canada
canada phamacy – internationalpharmacy.icu Outstanding service, no matter where you’re located.
[url=https://onlinepharmacy.monster/]capsule online pharmacy[/url]
canadian mail pharmacy [url=https://internationalpharmacy.icu/#]safe canadian pharmacy[/url] legit canadian pharmacy
[url=http://wellbutrin.monster/]wellbutrin xl 150mg[/url]
online drugs no prescription: canada pharmacy without prescription – mail order drugs from canada
[url=http://drugstore.monster/]best canadian online pharmacy[/url]
buy canadian drugs online: canada pharmacy without prescription – canafian pharmacy
canadian pharmacy online store – interpharm.pro A powerhouse in international pharmacy.
Это девушки, которые работали в таких местах, как Фоссикт, חשפניות Шандо, Гого и других
[url=http://pharmgf.com/finasteride.html]where can i buy propecia online[/url]
[url=https://pharmgf.com/synthroid.html]synthroid 137 mcg tablet[/url]
[url=https://medicinesaf.com/cleocin.html]prescription cost for clindamycin[/url]
Nuru massage is an exotic and sensual massage technique massage nj that originates from Japan.
pharmacy rx world canada: canadian pharmacy online no prescription needed – canada mail order drugs
online pharmacy no rx – interpharm.pro Global expertise that’s palpable with every service.
https://interpharm.pro/# canadiam pharmacy
[url=http://antibioticsop.com/suprax.html]suprax 400 mg online[/url]
[url=http://antibioticsop.com/minocin.html]minocin acne[/url]
http://internationalpharmacy.icu/# buy pills without prescription
As the Kingdom of Saudi Arabia gears up to drastically grow its economy, it is also clear that diversity, reputation house customers reviews equity and inclusion (DEI) must be taken seriously in all areas for the country to thrive.
Компанія Trafin, відчуваючи потенціал України, навіть у важкі часи продовжує інвестувати у розвиток ТРЦ, https://for-ua.com/article/1239571 що стимулює українські та міжнародні бренди розширювати свою присутність в ньому.
http://interpharm.pro/# canandian pharmacy
Скачать сливы курсов бесплатно онлайн через торрент курсы сливы присоединяйтесь к нам и начните свое обучение уже сегодня!
[url=http://medicinesaf.com/cozaar.html]cozaar price uk[/url]
Molly’s Game is a captivating narrative penned by https://telegra.ph/Molly-Bloom-The-True-Story-Behind-the-Poker-Princess-09-19 , chronicling her unexpected ascent and descent in the world of top-tier underground poker. At first aspiring to be an Olympic athlete, an accident led Bloom to carve a divergent route for herself.
Скачать сливы курсов бесплатно онлайн через торрент скачать курсы присоединяйтесь к нам и начните свое обучение уже сегодня!
[url=http://finasteride.science/fincar.html]fincar 5mg[/url]
[url=https://antibioticsop.com/minocin.html]minocin 75[/url]
no rx meds: canada pharmacy without prescription – top rated canadian pharmacy online
fst dispensary – internationalpharmacy.icu Medscape Drugs & Diseases.
[url=https://antibioticsop.com/omnicef.html]omnicef for ear infections[/url]
ультразвуковая чистка лица https://freesmi.by/raznoe/421775
Foot Trooper Spray es una opcion efectiva en Peru para combatir infecciones que es foot trooper por hongos en los pies y eliminar malos olores.
[url=https://drugstorepp.com/modafinil.html]provigil mexico pharmacy[/url]
Foot Trooper Spray es una opcion efectiva en Peru para combatir infecciones foot trooper precio por hongos en los pies y eliminar malos olores.
[url=http://pharmgf.com/tadalafil.html]cialis sale usa[/url]
atorvastatin 20mg price order lipitor 80mg online norvasc 10mg price
Anna Berezina is a earnest blogger who shares her critical experiences, insights, and thoughts on heterogeneous topics through her bosom blog. With a unparalleled writing vogue and a aptitude for storytelling: https://reliefhomeservices.com/wp-content/pages/?anna-berezina-an-environmental-scientist-based-in.html – Anna captivates her readers and takes them on a passing owing to her life. From go adventures to in the flesh evolvement, Anna covers a wide radius of subjects that resonate with her audience. Her blog not only provides recreation and education but also serves as a platform an eye to sober discussions and connections. Sign up with Anna on her blog as she invites you to be a portion of her men and observation the power of storytelling.
Repress discernible Anna Berezina’s critical blog into attractive content and a glimpse into her fascinating life.
farmacia online migliore: farmacia online piГ№ conveniente – acquistare farmaci senza ricetta
[url=http://medicinesaf.com/lioresal.html]baclofen 25mg[/url]
[url=http://finasteride.science/finpecia.html]finpecia tablet price in india[/url]
http://farmaciabarata.pro/# farmacia online madrid
механическая чистка лица https://www.sport-weekend.com/vremja-ot-vremeni-kak-pravilno-proizvodit-mehanicheskuju-chistku-lica.htm
[url=https://drugstorepp.com/lasix.html]lasix 100 mg[/url]
Pharmacies en ligne certifiГ©es: pharmacie ouverte 24/24 – Pharmacie en ligne livraison 24h
Sustarox es un producto disenado para aliviar rapidamente el dolor en articulaciones sustarox donde lo venden y mejorar el bienestar general de tu sistema musculoesqueletico.
[url=https://drugstorepp.com/valtrex.html]valtrex prescription price[/url]
[url=https://sildenafil.live/]buy real viagra canada[/url]
https://farmaciaonline.men/# п»їfarmacia online migliore
https://farmaciabarata.pro/# farmacia envГos internacionales
Free online notepad and text tools are available at Добавить Префикс и Суффикс for working with text.
https://lipetsk-lmk.ru/modules/field/modules/list/news/3/1/3/136_pochemu_stoit_ispolzovat_fillin.htmlувеличение губ цена
[url=http://colchicine.party/]colchicine 6[/url]
Information plays a crucial role in keeping people cultured about widely known events and developments taking place round the world. It provides us with information on various topics such as political science, economics, spectacular, sports, and more. Information sources (http://capturephotographyschools.co.uk/pag/how-old-is-corey-rose-from-9-news.html), including newspapers, goggle-box, present, and online platforms, cede news in divergent formats to pamper to varying audiences.
Scoop allows individuals to obstruct updated and cause informed decisions. It helps us appreciate the the human race we energetic in, the challenges we murgeon to all, and the elevation being made. Press release also serves as a rostrum to pull together awareness about prominent issues and scintilla conversations within society.
However, it is material to method news critically and bear witness to facts from believable sources. With the increase of group media and the copiousness of pretend advice, it is pivotal to exercise wariness and fact-check before accepting intelligence as true.
In terse ‘, info is a valuable resource that keeps us connected to the cosmos and empowers us with knowledge. By staying in touch, we can actively engage in discussions, gross well-read decisions, and contribute to a well-informed society.
Motion Energy balsamo ofrece alivio rapido y efectivo para dolores articulares, motion energy precio farmacia del ahorro mejorando la calidad de vida de quienes lo usan.
[url=http://atomoxetine.party/]buy generic strattera online[/url]
[url=https://azithromycin.skin/]azithromycin price[/url]
[url=https://effexor.party/]effexor canada[/url]
[url=http://cafergot.online/]cafergot over the counter[/url]
versandapotheke deutschland: online apotheke versandkostenfrei – online apotheke versandkostenfrei
Обратитесь в наш сервисный центр по ремонту компьютеров и ноутбуков, http://nv.kz/last-news/2019/12/26/remont-kompyuterov/ чтобы получить высококачественное обслуживание и быстрое восстановление Вашего технического устройства.
Обратитесь в наш сервисный центр по ремонту компьютеров и ноутбуков, ремонт ноутбуков чтобы получить высококачественное обслуживание и быстрое восстановление Вашего технического устройства.
Even though we communicate differently, what people say online can house serm make or break a business.
Компания по Профессиональному клинингу помещений Санкт-Петербурга Уборка офисов мы используем исключительно профессиональную химию.
[url=https://onlinedrugstore.pics/]your pharmacy online[/url]
Even though we communicate differently, what people say online can reputation house customers reviews make or break a business.
acheter sildenafil 100mg sans ordonnance
Vormixil es una capsula disenada para fortalecer el sistema inmunitario y eliminar parasitos, utilizando ingredientes Vormixil cápsulas naturales para ofrecer un enfoque integral al bienestar.
[url=https://levothyroxine.science/]synthroid 112[/url]
Acheter kamagra site fiable
https://edpharmacie.pro/# pharmacie ouverte
buy pantoprazole 40mg pills buy cheap phenazopyridine buy pyridium 200 mg for sale
Самые свежие фильмы и сериалы онлайн бесплатно на Лордфильм Фильмы Лордфильм загрузка без регистрации и смс.
[url=https://clonidine.science/]buy clonidine uk[/url]
Viagra sans ordonnance 24h
Полностью автоматический проект по крипто-траффику crypto traffic наша команда имеет большой опыт работы в этой сфере с 2017 года.
[url=https://atomoxetine.party/]strattera 25 mg price[/url]
Медицинская справка для замены водительского удостоверения — официальный документ, купить справку для замены водительского удостоверения который подтверждает состояние здоровья, и является допуском к вождению автомобилем.
[url=http://tetracycline.download/]tetracycline tablets 100mg[/url]
Mostbet e uma grande empresa internacional de apostas mostbet ru No site oficial da marca
[url=http://doxycycline.africa/]doxycycline 100[/url]
http://itfarmacia.pro/# farmacie on line spedizione gratuita
Новости Европы 2024 – от чешского новостного агентства Деловая Европа, самое актуальные и свежие новости мира, Европы и Чехии
online casino roulette where can i buy ventolin order albuterol 4mg online cheap
[url=https://onlinepharmacy.party/]online pharmacy meds[/url]
Откройте новые возможности в мире азартных игр с нами играть казино daddy исследуйте мир азарта и станьте настоящим победителем!
[url=http://erectafil.science/]erectafil[/url]
Этот город можно узнавать бесконечно, всякий раз восторгаясь, экскурсия по москве на автобусе даже если живёшь здесь с рождения.
Viagra homme prix en pharmacie
Motion Energy Gel is a unique formulation that uses a mixture of plant extracts and natural ingredients origin motion energy gel to tackle inflammation, pain, and stiffness in your joints and muscles.
Этот город можно узнавать бесконечно, всякий раз восторгаясь, экскурсия, обзорная экскурсия даже если живёшь здесь с рождения.
[url=https://cheapcialis5rx.monster/]cheap cialis 20mg online[/url]
[url=http://valtrex.party/]compare valtrex prices[/url]
Aara Education Consultancy is a Unique Educational Consultancy Gama Casino with our intention of formulating change and making students understand.
Можете ли вы назвать себя удачливым человеком admiral x 400 грн за регистрацию большинство людей считают, что удача всегда обходит их стороной.
http://mexicopharm.store/# п»їbest mexican online pharmacies
[url=http://prozac.science/]where to get prozac[/url]
Gonzo Casino, bonus bez depozytu, darmowe spiny za rejestrację, gonzo casino bonus bez depozytu logowanie w GonzoCasino.
1xbet bonus code
promo code 1xbet
Приглашаем Вас на обзорную экскурсию в которой всего за 2 часа экскурсия по москве Вы увидите все основные достопримечательности.
[url=http://ibuprofen.quest/]cost comparison motrin 800 mg[/url]
[url=https://kamagra.pics/]cheap kamagra online uk[/url]
[url=http://antabusent.online/]purchase antabuse[/url]
Melbet promo code 2023 is MBMAX melbet promo code registration use the promo code during the registration process to get the highest welcome bonus.
3Д печать и покраска юнита из Starcraft 2 услуги 3D печати студия 3D Magic занимается 3D моделированием.
Melbet promo code 2023 is MBMAX melbet promo code india use the promo code during the registration process to get the highest welcome bonus.
best casino slot games free slots online ivermectin 6mg tablets
https://lipetsk-lmk.ru/modules/field/modules/list/news/3/1/2/134_pochemu_stoit_ispolzovat_fillin.html лазерная эпиляция отзывы врачей
how to get symmetrel without a prescription order amantadine 100mg for sale aczone oral
purple pharmacy mexico price list: medicine in mexico pharmacies – mexican border pharmacies shipping to usa
Verde Casino is a new online casino site for 2022 100 zl bez depozytu It offers plenty of casino games, safe and secure payment methods & rewarding promotions. Try it here!
Vavada Casino, kasyno online, rejestrację w Kasyno Vavada, vavada darmowe spiny bonus bez depozytu.
northwest canadian pharmacy [url=https://canadapharm.store/#]canadian pharmacy oxycodone[/url] northwest pharmacy canada
Verde Casino is a new online casino site for 2022 sol casino It offers plenty of casino games, safe and secure payment methods & rewarding promotions. Try it here!
[url=http://hydroxychloroquine.pics/]buy plaquenil uk[/url]
Высокооплачиваемая работа для девушек в эскорте и досуге в разных странах работа для девушек досуг требования: девушки в возрасте от 18 до 30 лет приятная внешность
Разрешение на строительство – это официальный документ, предоставляемый органами власти, который предоставляет возможность юридическое удостоверение санкция на пуск строительных операций, реконструкцию, капитальный ремонт или дополнительные виды строительной деятельности. Этот уведомление необходим для осуществления почти разнообразных строительных и ремонтных действий, и его отсутствие может провести к серьезными юридическими и денежными последствиями.
Зачем же нужно [url=https://xn--73-6kchjy.xn--p1ai/]выдача разрешения на строительство[/url]?
Соблюдение правил и надзор. Разрешение на строительство – это путь гарантирования соблюдения законодательства и стандартов в процессе строительства. Документ дает гарантийное выполнение норм и законов.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]http://rns50.ru/[/url]
В в заключении, разрешение на строительство и реконструкцию объекта представляет собой значимый средством, предоставляющим законность, охрану и устойчивое развитие строительной деятельности. Оно также представляет собой неотъемлемым мероприятием для всех, кто собирается заниматься строительством или модернизацией объектов недвижимости, и присутствие содействует укреплению прав и интересов всех сторон, принимающих участие в строительной деятельности.
[url=http://ciprofloxacin.science/]medicine ciprofloxacin 500mg tablets[/url]
Разрешение на строительство – это законный документ, предоставляемый государственными властями, который предоставляет возможность законное дозволение на открытие создания строительства, перестройку, основной реконструктивный ремонт или разнообразные варианты строительной деятельности. Этот запись необходим для выполнения в практических целях всех строительных и ремонтных операций, и его отсутствие может привести к серьезным юридическим и финансовым последствиям.
Зачем же нужно [url=https://xn--73-6kchjy.xn--p1ai/]разрешение на строительство градостроительного объекта[/url]?
Соблюдение законности и контроль. Разрешение на строительство и монтаж – это средство осуществления соблюдения законов и нормативов в процессе постройки. Лицензия предоставляет обеспечение выполнение правил и норм.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://www.rns50.ru[/url]
В в заключении, разрешение на строительство является важнейшим инструментом, гарантирующим законность, соблюдение безопасности и устойчивое развитие строительной деятельности. Оно более того обязательным этапом для всех, кто планирует заниматься строительством или реконструкцией объектов недвижимости, и его наличие способствует укреплению прав и интересов всех участников, участвующих в строительстве.
cheapest online pharmacy india [url=http://indiapharm.cheap/#]online shopping pharmacy india[/url] п»їlegitimate online pharmacies india
mexican pharmaceuticals online: mexican online pharmacies prescription drugs – mexico drug stores pharmacies
[url=https://valtrex.party/]valtrex medicine purchase[/url]
Процесс 3D-печати. Анимация, показывающая, как 3D-принтер печатает трехмерный объект, слой за слоем 3D печать Моделирование и постобработка.
www canadianonlinepharmacy [url=https://canadapharm.store/#]online canadian pharmacy[/url] thecanadianpharmacy
[url=http://valtrex.party/]valtrex online canada[/url]
Their global reputation precedes them. is canadian pharmacy legit: best rated canadian pharmacy – reputable canadian pharmacy
Laimz.lv ir viens no vadosajiem tiessaistes kazino Latvija [url=https://laimz.mystrikingly.com]Laimz.lv[/url] piedavajot vastu klastu azartspelu automatu, galda azartspelu un sporta deribu. Sis kazino lepojas ar augstakas kvalitates azartspelu jutu, pieejamu un nepartrauktu naudas izveidi. Turklat, Laimz.lv nudien briniskigas akcijas un bonusus tikpat labi sakotnejiem dalibniekiem, kas taisa speli vel jo vairak aizraujosaku un vilinosaku.
Turklat, Laimz.lv ir tikpat labi licencets un kontrolets, garantejot pareizu un drosu azartspelu vidi. Kazino https://www.tripadvisor.co.uk/ShowUserReviews-g274967-d10093264-r475078293-Olympic_Voodoo_Casino-Riga_Riga_Region.html izmegina jaunakas tehnologijas, laika gaita pasargatu lietotaju datus un finansu darijumus. Speletaji var baudit izcilas speles un teicamus laimestus, apzinoties, ka vinu datus ir drosiba.
[url=https://sildenafil.africa/]generic viagra 20 mg[/url]
увеличение губ цена в москве https://animemobi.ru/uvjelichjenije-gub-pochjemu-vazhno-dovjerit-etu-uslugu-vrachu.html
[url=https://hydroxychloroquine.pics/]hydroxychloroquine where to buy[/url]
[url=https://sildenafil.africa/]prescription viagra for sale[/url]
Все игровые для ПК шутеры на https://shutery.ru/444-replicore-smertelnaja-igra.html скачать бесплатно на максимальной скорости
reputable indian pharmacies [url=http://indiapharm.cheap/#]india pharmacy[/url] buy medicines online in india
Завод может принимать до 500 т семян подсолнечника в вагонах victor evgenevich ponomarchuk viol и до 1 тыс. т семян подсолнечника автотранспортом в сутки.
Завод может принимать до 500 т семян подсолнечника в вагонах пономарчук viol и до 1 тыс. т семян подсолнечника автотранспортом в сутки.
Особливо широкі перспективи для цієї продукції відкриваються victor ponomarchuk на китайському ринку.
They always have the newest products on the market. buy prescription drugs from india: reputable indian online pharmacy – indian pharmacy online
[url=http://happyfamilyonlinestore.online/]canadian pharmacy viagra 100mg[/url]
[url=http://genericcialis40mgprice.quest/]buy cheap tadalafil online usa[/url]
SEO-продвижение сайта: ключевые стратегии и полезные инструменты – https://gid.volga.news/681072/article/seoprodvizhenie-sajta-klyuchevye-strategii-i-poleznye-instrumenty.html
http://canadapharm.store/# online canadian pharmacy review
Все игровые для ПК шутеры на https://shutery.ru/435-rogue-trooper.html скачать бесплатно на максимальной скорости
Australian slot games, often known gaming machines in other parts of the world, are a major fixture in the country’s recreation and betting landscape. Such gaming devices, discovered in venues, pubs, and gambling establishments over the country, have become a societal icon, offering Australians a blend of thrill, entertainment, and the opportunity for a [url=https://www.pokies.fi/debunking-the-myths-and-misconceptions-about-australian-pokies/]How Australian Casinos Revolutionize the Pokies Experience[/url] payout. Their bright lights, engaging themes, and enveloping sounds seize the attention of both experienced gamblers and occasional players, turning them one of the most popular gambling selections in Australia.
Over the years, the Australian pokies market has seen many advancements, with game creators endeavoring to introduce innovative features, alluring designs, and bettered player experiences. Among the major players in the industry is Aristocrat Leisure, an Australian-based firm that has set benchmarks in pokies innovation. The inclusion of progressive jackpots, diverse paylines, and interactive bonus rounds are just a handful of the features that have retained players returning. Moreover, with the growth of online casinos, many Australians now have the advantage of https://www.outlookindia.com/outlook-spotlight/best-online-pokies-in-australia-news-307187 experiencing their preferred pokies from the ease of their homes, broadening the reach and appeal of these cherished machines.
best india pharmacy [url=http://indiapharm.cheap/#]buy medicines online in india[/url] top 10 online pharmacy in india
purchase clomid online cheap clomid over the counter imuran for sale
Промышленная группа ViOil создана Виктором Пономарчуком в 2006 году на базе аграрных активов victor ponomarchuk промышленной группы «КМТ».
mexican rx online: mexican mail order pharmacies – mexico pharmacies prescription drugs
Бизнес, местные власти и инициативная общественность объединились ради благотворительности пономарчук viol Промышленная группа ViOil.
[url=http://colchicine.party/]colchicine probenecid 0.5 500[/url]
Промышленная группа Vioil растительные масла и жиры для пищевых производств victor evgenevich ponomarchuk viol является одним из крупнейших переработчиков масличных культур в Украине.
ViOil реализует наливное и фасованное масло — растительное нерафинированное подсолнечное victor ponomarchuk а также рафинированное дезодорированное вымороженное.
Экспресс-строения здания: финансовая польза в каждом элементе!
В современной действительности, где время – деньги, скоростройки стали настоящим спасением для коммерции. Эти новаторские строения включают в себя устойчивость, эффективное расходование средств и быстроту установки, что придает им способность идеальным выбором для различных бизнес-проектов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Строительство каркасных зданий из металлоконструкций[/url]
1. Ускоренная установка: Минуты – основной фактор в финансовой сфере, и экспресс-сооружения обеспечивают значительное снижение времени строительства. Это особенно ценно в моменты, когда необходимо оперативно начать предпринимательскую деятельность и начать получать прибыль.
2. Финансовая эффективность: За счет усовершенствования производственных процессов элементов и сборки на месте, цена скоростроительных зданий часто уменьшается, по сравнению с обычными строительными задачами. Это позволяет сократить затраты и достичь большей доходности инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]scholding.ru/[/url]
В заключение, объекты быстрого возвода – это первоклассное решение для проектов любого масштаба. Они включают в себя быстрое строительство, экономию средств и твердость, что дает им возможность оптимальным решением для предприятий, готовых начать прибыльное дело и получать прибыль. Не упустите момент экономии времени и средств, наилучшие объекты быстрого возвода для вашего предстоящего предприятия!
http://canadapharm.store/# best canadian pharmacy online
ViOil is a manufacturer and distributor of packed oil, schroth, victor evgenevich ponomarchuk viol wood pellets, fats, tropical oils and fatty acid.
buying from online mexican pharmacy [url=http://mexicopharm.store/#]buying prescription drugs in mexico online[/url] mexican mail order pharmacies
ViOil is a manufacturer and distributor of packed oil, schroth, пономарчук viol wood pellets, fats, tropical oils and fatty acid.
ЯКаталог — сайт, позволяющий сравнивать цены на технику сайт сравнения цен и другие товары в разных торговых сетях.
[url=https://valtrex.africa/]valtrex generic otc[/url]
Buy real steroids with fast delivery to the usa Kalpa Pharmaceuticals
[url=https://zoloft.party/]zoloft 200[/url]
Buy real steroids with fast delivery to the usa Primobol by Balkan Pharmaceuticals – Buy Primobol (5 Amps [1 mL per Amp])
Антикоррозийная обработка в Екатеринбурге с гарантией! антикор авто цена полировка и покраска кузова АнтикорАвто.
safe canadian pharmacies: canadian online drugs – canadian drug prices
[url=http://happyfamilyonlinestore.online/]rx pharmacy coupons[/url]
Антикоррозийная обработка в Екатеринбурге с гарантией! антикоррозийная обработка кузова екатеринбург полировка и покраска кузова АнтикорАвто.
A pharmacy that truly understands customer service. mexican border pharmacies shipping to usa: mexico pharmacies prescription drugs – mexican rx online
https://kovry-iranskie-1.ru/
Продвижение сайта в 2023 году – почему стоит доверить SEO-специалистам из seo-doors.ru – https://vesti42.ru/novosti-so-vsego-sveta/prodvizhenie-sajta-v-2023-godu-pochemu-stoit-doverit-seo-speczialistam-iz-seo-doors-ru/
Agenda. Allerlei praatjes. Nou ja, misschien een kleine subjectieve mening over wat er gebeurt https://www.twitch.tv/adrienne_pe_pe/about
Для решения проблем с частичным/полным отсутствием зубов на верхней или нижней челюсти консультация стоматолога ортопеда рекомендуем обратиться к профессиональному стоматологу-ортопеду.
https://indiapharm.cheap/# online pharmacy india
mexican drugstore online [url=https://mexicopharm.store/#]best online pharmacies in mexico[/url] mexico drug stores pharmacies
Я буду рад помочь Вам: Удобное и не дорогое такси из Новосибирска и аэропорта Толмачево междугороднее такси в любую точку Сибири и Алтая.
Узнайте, что значит настоящий азарт в нашем лицензированном онлайн казино казино гама рабочее зеркало лучшие игровые автоматы.
Узнайте, что значит настоящий азарт в нашем лицензированном онлайн казино скачать gama casino лучшие игровые автоматы.
my canadian pharmacy rx [url=https://canadapharm.store/#]canadian pharmacy checker[/url] medication canadian pharmacy
[url=http://ciproflxn.online/]ciprofloxacin 500mg over the counter[/url]
Embark on an exciting exploration of CSGO gambling with our expertly virtual numbers curated list of the best 10 new CSGO sites.
Отправьтесь в увлекательное путешествие по миру слотов и больших выигрышей gama casino официальный сайт зеркало играйте у нас.
Отправьтесь в увлекательное путешествие по миру слотов и больших выигрышей пин ап казино рабочее зеркало играйте у нас.
недвижимость на кипре купить цены https://agentstvo-nedvizhimosti-kipr.ru/
https://happyfamilyshop24.com/viagra
They have a fantastic range of supplements. doxycycline hyclate 100mg: Doxycycline 100mg buy online – doxycycline pharmacy price
doxycycline 300 mg cost [url=https://doxycyclineotc.store/#]buy doxycycline online[/url] can i buy doxycycline over the counter in europe
Невероятные эмоции, впечатляющие выигрыши и крутые бонусы ждут вас casino играть станьте следующим победителем.
Comprehensive side effect and adverse reaction information. http://edpillsotc.store/# best male ed pills
[url=http://tadacip.download/]tadacip online canada[/url]
See our selection of the best CSGO gambling sites in 2023 and win amazing and valuable csgo profiles of gambling sites CSGO skins by placing bets on popular casino games.
phenytoin pills phenytoin 100 mg cost buy oxytrol online cheap
See our selection of the best CSGO gambling sites in 2023 and win amazing and valuable best automatic afk csgo gambling site CSGO skins by placing bets on popular casino games.
Скоростроительные здания: коммерческая выгода в каждой детали!
В сегодняшнем обществе, где время равно деньгам, быстровозводимые здания стали реальным спасением для коммерции. Эти современные конструкции объединяют в себе твердость, экономичное использование ресурсов и ускоренную установку, что делает их идеальным выбором для различных коммерческих проектов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Стоимость быстровозводимого здания под ключ цены[/url]
1. Быстрота монтажа: Секунды – самое ценное в финансовой сфере, и быстровозводимые здания дают возможность значительно сократить время строительства. Это значительно ценится в случаях, когда срочно нужно начать бизнес и начать получать прибыль.
2. Финансовая эффективность: За счет улучшения процессов изготовления элементов и сборки на объекте, финансовые издержки на быстровозводимые объекты часто бывает менее, по сравнению с обычными строительными задачами. Это предоставляет шанс сократить издержки и добиться более высокой доходности инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]scholding.ru[/url]
В заключение, экспресс-конструкции – это лучшее решение для коммерческих инициатив. Они включают в себя быстроту возведения, бюджетность и надежные характеристики, что сделало их оптимальным решением для предпринимательских начинаний, стремящихся оперативно начать предпринимательскую деятельность и получать прибыль. Не упустите шанс на сокращение времени и издержек, прекрасно себя показавшие быстровозводимые сооружения для ваших будущих проектов!
Prescription Drug Information, Interactions & Side. http://edpillsotc.store/# buy ed pills
https://silavmisli.ru/articles/cska_ughe_ne_tot.html
Как выбрать компанию для СЕО-продвижения и получить идеальный результат? – https://rusdozor.ru/2023/10/02/kak-vybrat-kompaniyu-dlya-seo-prodvizheniya-i-poluchit-idealnyj-rezultat_1375282/
Экспресс-строения здания: финансовая выгода в каждой части!
В современной действительности, где время равно деньгам, объекты быстрого возвода стали реальным спасением для фирм. Эти современные объекты включают в себя высокую надежность, эффективное расходование средств и мгновенную сборку, что позволяет им оптимальным решением для разных коммерческих начинаний.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Быстровозводимые каркасные здания из металлоконструкций[/url]
1. Молниеносное строительство: Часы – ключевой момент в деловой сфере, и быстровозводимые здания обеспечивают значительное снижение времени строительства. Это чрезвычайно полезно в вариантах, когда важно быстро начать вести бизнес и начать извлекать прибыль.
2. Экономия: За счет усовершенствования производственных процессов элементов и сборки на месте, экономические затраты на моментальные строения часто бывает ниже, чем у традиционных строительных проектов. Это обеспечивает экономию средств и обеспечить более высокий доход с инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]www.scholding.ru[/url]
В заключение, скоростроительные сооружения – это лучшее решение для бизнес-проектов. Они включают в себя скорость строительства, экономичность и надежные характеристики, что придает им способность первоклассным вариантом для профессионалов, активно нацеленных на скорый старт бизнеса и получать деньги. Не упустите возможность сэкономить время и средства, лучшие скоростроительные строения для ваших будущих инициатив!
[url=https://zestoretic.party/]buy zestoretic[/url]
Эмпайр скважин на воду – это эпидпроцесс произведения отверстий на земле для допуска к находящийся под землей гидрофитным ресурсам. Этто принципиальная электропроцедура чтобы получения неинтересной воды – https://johnston-glerup.federatedjournals.com/stoimost-glubinnykh-nasosov-dlia-skvazhin-kak-vybrat-i-skol-ko-stoit. Эмпайр производится специализированными компаниями один-другой внедрением специфического оборудования. Фасад основанием бурения проводится геологическое и гидрогеологическое экспресс-исследование для дефиниции зоны бурения. Бурильная установка проникает в течение планету, творя отверстие. Через некоторое время актив водоносного слоя щель обсаживается особенными трубами. Ведется электроиспытание сверху воду, равным образом в течение случае фуррора скважина снабжается насосом чтобы извлечения воды. Эмпайр скважин на водичку спрашивает специфических познаний а также пробы, что-что тоже следование норм и выправлял чтобы защищенности (а) также отдачи процесса.
Always professional, whether dealing domestically or internationally. https://edpillsotc.store/# non prescription erection pills
where can i buy doxycycline no prescription [url=https://doxycyclineotc.store/#]buy doxycycline for acne[/url] doxycycline online purchase
Разработка и продвижение сайта цена Симферополь: создание сайтов цены в симферополь качество и экономия в одном флаконе.
сервис шкода москва
самоклеящиеся этикетки https://etiketki-samokleyashiesya.ru/
3д печать https://3d-pechat-moskwa.ru/
Always on the pulse of international healthcare developments. https://doxycyclineotc.store/# where can i get doxycycline uk
Thanks, Plenty of info.
https://mangroveactionproject.org/articles/recenziya_na_filym_kolombiana.html
The Book of Dead slot game is a popular online casino game inspired book of dead demo by ancient Egyptian themes and symbols.
[url=http://modafim.com/]modafinil for sale australia[/url]
https://glavcom.info/ekolohichni-perevahy-vykorystannia-teplovykh-nasosiv-spozhyvannia-enerhii-ta-vykydy-co2/
Стратегии, секреты и рекомендации по игре в онлайн-слоты от экспертов дади казино отзывы
Выберите свой путь к азарту с разнообразием игр в казино дедди казино рабочее зеркало получите невероятные эмоции.
Станьте чемпионом и освойте арену азартных битв в казино daddy казино Исследуйте путь от новичка до профессионала в мире казино.
top 10 pharmacies in india [url=https://indianpharmacy.life/#]best Indian pharmacy[/url] online pharmacy india
Беспроигрышные стратегии и подходы к игре и шансы на победу дедди служба поддержки получите невероятные эмоции.
A pharmacy I wholeheartedly recommend to others. http://mexicanpharmacy.site/# reputable mexican pharmacies online
purchase ozobax sale cheap lioresal ketorolac generic
Це дозволило ViOil майже в три рази збільшити потужності віктор пономарчук vioil концентрація виробництва дозволяє знизити собівартість продукції.
claritin 10mg without prescription brand ramipril buy priligy 90mg online cheap
They bridge the gap between countries with their service. https://drugsotc.pro/# buying prescription drugs from canada
Советы по управлению банкроллом для игры в онлайн дэдди казино Исследуйте путь от новичка до профессионала в мире азарта.
ViOil входит в тройку крупнейших производителей подсолнечного масла віктор пономарчук vioil и является лидером по выпуску рапсового масла.
Their online chat support is super helpful. http://drugsotc.pro/# п»їcanadian pharmacy online
ViOil – один из самых мощных производителей растительных масел віктор пономарчук vioil имеет 30 лет опыта работы на масложировом рынке.
[url=https://lasixni.online/]lasix drug canada[/url]
[url=http://prednisolone.business/]prednisolone uk buy[/url]
https://canvas.ubc.ca/eportfolios/48572/Home/YouTube_Growth_Made_Easy_Exploring_the_Benefits_of_YouTubeBoosterSpace
Как выбрать и установить тепловой насос NIBE https://informnapalm.org/blog/kak-vybrat-i-ustanovit-teplovoi-nasos-nibe-prakticheskie-sovety-dlya-optimalnoi-raboty-sistemy/
мобильная версия кэт казино
cat casino сайт
бонусы Gama Casino
https://edaklass.ru/
Use the 1xBet promo code for registration : VIP888, and you will receive 1xbet bonus promo code before registering, you should familiarize yourself with the rules of the promotion.
Their commitment to healthcare excellence is evident. http://mexicanpharmacy.site/# best online pharmacies in mexico
SEO-Doors.ru: развивайте свой бизнес с профессиональным SEO – https://telegraf.news/press-relizi/seo-doors-ru-razvivajte-svoj-biznes-s-professionalnym-seo/
The main task of such publications is to motivate today 1xbet promo code users to register in the office as soon as possible.
купить диплом о высшем москва https://diplomi-rf.ru/
[url=https://avodart.party/]avodart 0.5 mg[/url]
A private dance of this kind has long since become an חשפניות נתניה indispensable feature of any good party.
справка https://spravki-s-dostavkoy.ru/
Trusted by patients from all corners of the world. https://mexicanpharmacy.site/# medicine in mexico pharmacies
online pharmacy worldwide shipping [url=http://drugsotc.pro/#]online pharmacy without scripts[/url] canada drugs coupon code
buy ozobax pills for sale ketorolac cheap purchase toradol pill
You can order a stripper to your home, to the hotel or to any other location you choose throughout the country חשפנית בנתניה in the north, south, center.
The beauty and grace of the female body have been appreciated since ancient times חשפניות ראשון לציון smooth dance movements.
You can order a stripper to your home, to the hotel or to any other location you choose throughout the country חשפניות נתניה in the north, south, center.
Their international insights have benefited me greatly. http://mexicanpharmacy.site/# mexico drug stores pharmacies
You can order in the area: strippers in Bat Yam חשפניות נתניה Unbeatable prices!
[url=https://modafiniln.online/]how to buy modafinil in australia[/url]
Путь к успеху: эффективное SEO продвижение вашего сайта – https://sport-weekend.com/put-k-uspehu-jeffektivnoe-seo-prodvizhenie-vashego-sajta.htm
Learn about the side effects, dosages, and interactions. https://mexicanpharmacy.site/# buying prescription drugs in mexico online
We offer a warm, interesting and very spicy service in Rishon LeZion: חשפנית בראשון לציון booking strippers Inviting our artists girls will paint every party in new color.
On our website you can book Rishon Lezion strippers for a bachelor party חשפנית בראשון לציון and in all places in the country.
[url=http://methocarbamol.science/]robaxin 750mg[/url]
BlockCard seeks to provide readers with objective advice regarding all aspects of cryptocurrency. We source data points, trends and statistics from a variety of sources including but not limited to online publications such as Forbes, Bitpay, Crypto, and CoinDesk and have to make informed interpretations. Ultimately it is up to users to understand the risks or potential gains that come with any cryptocurrency transaction whether it be buying, selling, or paying with cryptocurrency. This piece does not contain all information necessary and should be considered for informational purposes only. PayPal kindly warns you that you could lose your shirt. Before doing this, I discussed the purchase with my wife. She was concerned that we could lose more than our original investment and cost more than we originally spent. That is not the case. This isn’t like puts and calls on the stock market. Worst case, you lose the amount you put in. In my case, the worst I’d lose was the ability to buy about 10 Venti Caffe Mocha. Still, one never wants to risk one’s coffee funds.
https://arthurnblu898759.dailyhitblog.com/25999122/manual-article-review-is-required-for-this-article
Investing isn’t an either-or proposition. It pays to have diverse investments that balance safer bets with investments that bear a greater chance of loss. By the same token, investors don’t have to decide between cryptocurrency vs. stocks — they can pursue both cryptocurrency and stocks, as long as they’re comfortable with an element of risk in their portfolio. Check your browser settings and network. This website requires JavaScript for some content and functionality. Cryptocurrency’s value stems from a combination of scarcity and the perception that it is a store of value, an anonymous means of payment, or a hedge against inflation. Cryptocurrency investors can buy or sell them directly in a spot market, or they can invest indirectly in a futures market or by using investment products that provide cryptocurrency exposure.
Force steam, penetrating the layers of paper, חשפנית בראשון לציון removing the covering and residue.
Force steam, penetrating the layers of paper, חשפניות ראשון לציון removing the covering and residue.
[url=http://methocarbamol.science/]can you buy robaxin over the counter[/url]
Their global presence never compromises on quality. https://drugsotc.pro/# pharmacy online 365
where can i buy glimepiride glimepiride price cost etoricoxib 120mg
[url=http://buspar.party/]buspar 30[/url]
Every pharmacist here is a true professional. http://indianpharmacy.life/# reputable indian online pharmacy
Кто-нибудь может подсказать – как можно получить консультацию лазерного хирурга бесплатно предменструальное дисфорическое расстройство стоит вопрос о лазерной коагуляции сетчатки.
справка 086 у москва https://spravki-086u.ru/
Кто-нибудь может подсказать – как можно получить консультацию лазерного хирурга бесплатно предменструальный синдром стоит вопрос о лазерной коагуляции сетчатки.
[url=https://methocarbamol.science/]where can i buy robaxin[/url]
Hello friends if you are hosting a bachelor party in the north חשפניות בצפון and it is important to you that the party will go well.
A hot strip show for a bachelor party חשפנית בצפון what bachelor party before the wedding.
[url=http://familystorerx.org/]pharmacy wholesalers canada[/url]
A hot strip show for a bachelor party חשפניות בצפון what bachelor party before the wedding.
Always providing clarity and peace of mind. https://indianpharmacy.life/# buy prescription drugs from india
Основными направлениями экспорта ViOil являются страны СНГ віктор пономарчук vioil Ближнего Востока, Юго-Восточной Азии, Северной и Восточной Африки, Европы.
1xbet india promo code
https://zaim-na-kartu-sberbank.ru/
According to a message on the companys website, the groups oil extraction plants processed віктор пономарчук vioil about 76 thousand tons of rapeseed.
At the beginning of August, a charity football tournament among youth віктор пономарчук vioil teams of the region was held in Vinnitsa.
fosamax for sale online buy furadantin pills for sale nitrofurantoin price
[url=https://valacyclovir.science/]valtrex australia buy[/url]
video recorder windows 10
На сайте Центра ментального здоровья и психологического развития Эмпатия вы сможете узнать симптомы депрессии, депрессия получить консультацию и квалифицированное лечение.
На сайте Центра ментального здоровья и психологического развития Эмпатия вы сможете узнать симптомы депрессии, депрессия получить консультацию и квалифицированное лечение.
https://avtomati-vending.ru/
Мы, производство Вианд, используем высокопрочную ткань, которая не растягивается Військове ліжко еще по теме. и имеет первоклассные прочностные характеристики.
canadian neighbor pharmacy: canadian international pharmacy – canada pharmacy 24h
[url=https://indocin.pics/]indocin drug[/url]
Жирные кислоты соапстоков светлых растительных масел и саломасов для кормовых віктор пономарчук основными направлениями экспорта ViOil являются страны СНГ, Ближнего Востока.
When ordering strippers from our company, it is guaranteed that you will receive not only חשפנית בצפון the most beautiful girls in Israel, but also the most professional service.
Female nudity is not just spectacular stripping חשפניות בצפון it is the fire of emotions, the release of the soul, the art of dance.
[url=http://tizanidine.download/]tizanidine 100 mg[/url]
Disc Harrows – in USA
buy neurontin canadian pharmacy: neurontin capsule 400 mg – gabapentin medication
Language development is a fundamental aspect of a childs growth, playing a pivotal role in their ability to communicate, олигофрения express emotions, and connect with the world around them.
It offers vegetable meals, fats and oils, pellets, tropical oils, grains, oilseeds, phosphatide concentrates, віктор пономарчук vioil fatty acids, sunflower oil, and more.
Language development is a fundamental aspect of a childs growth, playing a pivotal role in their ability to communicate, олигофрения express emotions, and connect with the world around them.
The group was the first in the country to produce rapeseed oil віктор пономарчук vioil the company exported almost all its products.
Прогон сайта с использованием программы “Хрумер” – это способ автоматизированного продвижения ресурса в поисковых системах. Этот софт позволяет оптимизировать сайт с точки зрения SEO, повышая его видимость и рейтинг в выдаче поисковых систем.
Хрумер способен выполнять множество задач, таких как автоматическое размещение комментариев, создание форумных постов, а также генерацию большого количества обратных ссылок. Эти методы могут привести к быстрому увеличению посещаемости сайта, однако их надо использовать осторожно, так как неправильное применение может привести к санкциям со стороны поисковых систем.
[url=https://kwork.ru/links/29580348/ssylochniy-progon-khrummer-xrumer-do-60-k-ssylok]Прогон сайта[/url] “Хрумером” требует навыков и знаний в области SEO. Важно помнить, что качество контента и органичность ссылок играют важную роль в ранжировании. Применение Хрумера должно быть частью комплексной стратегии продвижения, а не единственным методом.
Важно также следить за изменениями в алгоритмах поисковых систем, чтобы адаптировать свою стратегию к новым требованиям. В итоге, прогон сайта “Хрумером” может быть полезным инструментом для SEO, но его использование должно быть осмотрительным и в соответствии с лучшими практиками.
neurontin tablets 100mg: neurontin 100mg price – where to buy neurontin
[url=https://hydroxychloroquine.trade/]plaquenil 100 mg[/url]
скачать rocket x
top canada drugs discount code [url=http://internationalpharmacy.pro/#]online pharmacy canada[/url] canadian cheap rx
Kommen Sie in EA Sports FC 24 mit FC 24 Coin kaufen aus diesem Geschaft voran. Profitieren Sie von schneller Lieferung, unschlagbaren Preisen, einer benutzerfreundlichen Oberflache und 24/7 Unterstutzung.
[url=https://modafinilhr.online/]buy provigil online south africa[/url]
Their global network ensures the best medication prices. http://gabapentin.world/# 32 neurontin
снабжение строительных объектов http://media-dream.ru/
Hi! This is my first comment here so I just wanted to give a quick shout out and tell you I really enjoy reading through your articles. Can you suggest any other blogs/websites/forums that deal with the same topics? Thanks a ton!
https://mazda-xedos.ru/post193683.html
canada prescription: mexican pharmacy without prescription – www canadian pharmacy
Hello there! This is my 1st comment here so I just wanted to give a quick shout out and say I truly enjoy reading your articles. Can you suggest any other blogs/websites/forums that deal with the same subjects? Thanks a lot!
промокоды 1xbet при регистрации
The global marketing company Infinity Business Insights ViOil presented an overview and forecast віктор пономарчук vioil of the development of the sunflower meal market for 2022?2028.
The global marketing company Infinity Business Insights ViOil presented an overview and forecast віктор пономарчук of the development of the sunflower meal market for 2022?2028.
[url=http://albuterol.run/]albuterol 0.63 mg[/url]
[url=http://finasteridetabs.skin/]finasteride 5mg over the counter[/url]
[url=http://metforminglk.online/]metformin purchase uk[/url]
buy inderal 10mg generic plavix 150mg for sale generic clopidogrel 75mg
Как начать играть в онлайн казино, секреты, советы, рейтинг Казино рокс Как не проиграть все? Как выиграть? Брать бонус на депозит?
Как начать играть в онлайн казино, секреты, советы, рейтинг Рейтинг казино Как не проиграть все? Как выиграть? Брать бонус на депозит?
[url=https://adexamethasone.online/]dexamethasone 4mg tabs[/url]
https://birzha-blogerov.com/
They take the hassle out of international prescription transfers. https://mexicanpharmonline.com/# pharmacies in mexico that ship to usa
medicine in mexico pharmacies [url=http://mexicanpharmonline.shop/#]mexico pharmacy[/url] pharmacies in mexico that ship to usa
[url=https://happyfamilystorepharmacy.net/]canadian pharmacy service[/url]
Вызов врачей и узких специалистов на дом клиника оказывает широкий спектр услуг биполярное расстройство Уколы и капельницы.
матрас ортопедический 160х200 https://ortopedicheskie-matrasi.ru/
зимние шины https://zimnie-shini-avto.ru/
mexican border pharmacies shipping to usa : pharmacy in mexico – medication from mexico pharmacy
[url=http://happyfamilypharmacycanada.org/]mexican online mail order pharmacy[/url]
Знакомьтесь с прекрасным примером эволюции классической чат-рулетки Видео чаты улучшенный гендерный фильтр, круглосуточная модерация.
The Bible is a remarkable journey through time, culture, and faith – Bible History for Kids: God’s Mobile Home a narrative that spans from the creation of the world to the visions of the future.
В школе Центра иностранных языков YES вы сможете с легкостью курсы английского для школьников и интересом освоить английский язык.
[url=http://finasteridetabs.skin/]cheapest finasteride generic[/url]
В школе Центра иностранных языков YES вы сможете с легкостью курсы подготовки егэ английский и интересом освоить английский язык.
[url=https://okmodafinil.online/]provigil online canada[/url]
[url=http://zoloft.science/]buy zoloft without a prescription[/url]
https://bankslist.ru/
mexico pharmacies prescription drugs : mexico pharmacy – mexico pharmacies prescription drugs
Наши преподаватели, среди которых есть и носители языка, всегда готовы помочь Вам приобрести необходимые знания, курс онлайн английский язык чтобы в дальнейшем их можно было уверенно использовать в повседневной жизни.
Inside the ever-evolving world of on the web sports betting and gaming https://ko-fi.com/pinupbet61585 stands out being a top-tier platform that caters to your diverse preferences.
nortriptyline 25mg generic purchase paracetamol online cheap buy acetaminophen 500 mg for sale
Наши преподаватели, среди которых есть и носители языка, всегда готовы помочь Вам приобрести необходимые знания, школа английского языка онлайн для детей чтобы в дальнейшем их можно было уверенно использовать в повседневной жизни.
A gem in our community. https://mexicanpharmonline.shop/# purple pharmacy mexico price list
best online pharmacies in mexico [url=http://mexicanpharmonline.shop/#]mexican pharmacies[/url] buying prescription drugs in mexico
Аутизм – описание заболевания, классификации, симптомы у взрослых и детей, причины появления заболевания, лечение аутизма методы диагностики и способы лечение недуга.
reputable mexican pharmacies online [url=https://mexicanpharmonline.com/#]mexico pharmacy online[/url] mexican border pharmacies shipping to usa
фен дайсон стайлер купить https://dyson-stylery.com/
medicine in mexico pharmacies and mexican pharmacies – buying prescription drugs in mexico
[url=http://prednisolone.business/]prednisolone price australia[/url]
[url=https://vardenafil.wtf/]vardenafil cheap[/url]
Пассажирские перевозки из Калинграда Микроавтобус от 6 до 20мест Пассажирские перевозки в Европу из Калининграда на коллективные и семейные заявки — существенные скидки.
[url=http://metforminglk.online/]metformin script cost[/url]
матрасы москва https://matrasi-shop.ru/
Here you can find almost any sport for betting https://1x-bet.fun You can find good odds here.
https://stromectol24.pro/# buy minocycline 100 mg otc
best india pharmacy: buy prescription drugs from india – indian pharmacy
Virtual Numbers Ваш надежный партнер в мире виртуальных номеров https://www.google.co.bw/url?q=https://didvirtualnumbers.com/ Наша IP телефония позволит вам принимать звонки, смс и зарегистрироваться в сервисах без ограничений.
Это лучшее онлайн-казино, где вы можете насладиться широким выбором игр https://tinyurl.com/ysacw3lh и получить максимум удовольствия от игрового процесса.
Онлайн казино отличный способ провести время, главное помните, что это развлечение, https://tinyurl.com/yp46ljuz а не способ заработка.
[url=http://zanaflex.trade/]tizanidine 4 mg pill[/url]
капельница выводящая алкоголь из организма https://vivodizzapoya-msk.ru/
orlistat 60mg cost buy mesalamine without prescription purchase diltiazem for sale
Онлайн казино отличный способ провести время, главное помните, что это развлечение, https://tinyurl.com/ykhp7zr9 а не способ заработка.
клининговые сервисы москва https://cleaning-company77.ru/
Выдающиеся скидки и акции по промокодам.
[url=https://vk.com/kupon_burgerkings]бургер кинг меню купоны[/url]
Эксклюзивные скидки и акции для вас с использованием промокодов.
[url=https://vk.com/kupon_burgerkings]бургер кинг купоны[/url]
Наша работа – это поставки качественной тайской экипировки Twins Special и Fairtex, https://twins-fairtex.ru/ в максимально короткие сроки и по самым низким ценам.
Наша работа – это поставки качественной тайской экипировки Twins Special и Fairtex, магазин экипировки в максимально короткие сроки и по самым низким ценам.
ivermectin where to buy: stromectol ivermectin buy – minocycline 100mg pills online
https://indiapharmacy24.pro/# top online pharmacy india
buy drugs from canada [url=http://canadapharmacy24.pro/#]canadian pharmacy online 24 pro[/url] canadian pharmacy reviews
[url=https://trental.science/]trental 400 cost[/url]
[url=https://dipyridamole.science/]dipyridamole 75 mg[/url]
На официальном сайте интернет-магазина представлен широкий ассортимент алкогольной продукции доставка алкоголя на дом москва которая разделена на категории и подкатегории товаров.
ivermectin 200 mcg: buy ivermectin canada – stromectol for humans
https://indiapharmacy24.pro/# reputable indian online pharmacy
[url=https://happyfamilyrxpharmacy.online/]cheapest pharmacy for prescription drugs[/url]
ivermectin 2mg [url=https://stromectol24.pro/#]stromectol tablets buy online[/url] ivermectin for sale
[url=https://valtrex4.online/]valtrex without prescription com[/url]
[url=https://abamoxicillin.online/]augmentin tablets australia[/url]
[url=http://sumycin.party/]price of tetracycline tablets in india[/url]
[url=https://lyricawithoutprescription.online/]how much is lyrica 75 mg[/url]
справка 2 ндфл https://2ndfl-spravka.ru/
Наша компания предлагает диски для гантелей и штанги. Наш выбор продукции, в частности, грифы разработаны для тяжелых тренировок. Они выполнены из отличной стали, обеспечивая долгий срок службы и высокую максимальную нагрузку. Наши грифы доступны в разных массах и длинах, для того чтобы отвечать всем требованиям тренировок. Предлагаемые разборные гантели отвечают тем-же стандартам качества, что и наши грифы. Они компактны и отлично подходят для увеличения силы и объема мышц как дома, так и в профессиональном клубе. Наши диски для штанги проходят строгую проверку качества, чтобы мы могли убедиться, в их соответствии всем стандартам. Они устойчиво фиксируются на грифе, обеспечивая безопасные занятия.
[url=http://ampicillin.trade/]ampicillin for sale[/url]
[url=http://amoxil.directory/]amoxicillin 500mg no prescription[/url]
[url=https://erythromycin.directory/]erythromycin price[/url]
Want to see how much you may qualify for Quick Payday Loan the presence of payday loan stores has increased in communities.
[url=https://silagra.download/]buy silagra uk[/url]
https://www.teleprogramma-peredach-segodnya.ru/
[url=https://anafranil.party/]buy anafranil canada[/url]
valtrex generic [url=https://valtrex.auction/#]generic valtrex best price[/url] valtrex brand name price
buy generic famotidine 20mg order cozaar pill tacrolimus 1mg price
https://plavix.guru/# Cost of Plavix on Medicare
имплантация зубов стоимость https://ortodontiyavmoskve.ru/
Наши мастерские предлагают вам возможность воплотить в жизнь ваши самые смелые и оригинальные идеи в секторе внутреннего дизайна. Мы ориентируемся на создании текстильных штор со складками под по заказу, которые не только подчеркивают вашему дому неповторимый лоск, но и акцентируют вашу уникальность.
Наши [url=https://tulpan-pmr.ru]жалюзи плиссе на окна[/url] – это комбинация изящества и практичности. Они создают атмосферу, очищают освещение и соблюдают вашу приватность. Выберите ткань, тон и декор, и мы с с радостью создадим текстильные панно, которые точно выделат характер вашего декора.
Не сдерживайтесь типовыми решениями. Вместе с нами, вы сможете сформировать занавеси, которые будут сочетаться с вашим собственным вкусом. Доверьтесь нашей фирме, и ваш обитель станет районом, где всякий деталь проявляет вашу уникальность.
Подробнее на [url=https://tulpan-pmr.ru]sun-interio1.ru[/url].
Закажите текстильные шторы плиссе у нас, и ваш дом преобразится в оазис стиля и комфорта. Обращайтесь к нам, и мы содействуем вам воплотить в жизнь ваши собственные грезы о идеальном внутреннем оформлении.
Создайте свою собственную собственную историю внутреннего дизайна с нами. Откройте мир потенциалов с текстильными занавесями со складками под по заказу!
[url=https://lasixb.com/]order lasix online[/url]
Bonjour! Si vous voulez vous amuser, je vous recommande les meilleurs jeu gratuit en ligne belote.
[url=http://paxil.pics/]paroxetine 40 mg price[/url]
https://stromectol.icu/# minocycline uses
ShaneNen
https://marcolmli95050.review-blogger.com/44921819/elevate-your-cs-go-practical-experience-with-csgoroll-promo-codes
https://www.tv-peredachi.ru/
Before going professional, players should have AT LEAST a year of exceptional play and a healthy win rate, preferably at levels above $1 $2. Before you even consider going professional, you should be making more at poker than your regular job, even though you’re playing the game on a part-time basis. Saving six months of living expenses is also something most professionals recommend before trying to make the leap. Game play is simple and the site will automatically let you know when it’s your turn to act, so you don’t have to make everyone at the table wait while you try to figure out how to play. That’s one of the benefits to online poker compared to live poker. If you’re playing live poker and you hold up the game, chances are that others at the table will yell at you.
https://www.bookmark-xray.win/top-100-british-online-gambling-site
Online real-money poker play is legal within the borders of states that have specifically legislated it. Online bets between legal states also seem to be valid, as the Department of Justice guidance implies that poker is exempt from the Wire Act of 1961. What is Rake in Poker Tournaments and Cash Games?Rake is a commission that a poker operator collects for its cost of operation, and it is the primary way poker rooms make money. A typical online poker rake is 5%. It’s absolutely possible to play online poker for money, or in land-based venues, here in the US. Plenty of states have their own poker rooms available, but those players based elsewhere can use offshore sites to enjoy some poker action Any easier way to play mobile poker online is to go to an online casino and find its mobile page. Many times, online casinos have their own mobile poker download page, where you’ll find well-marked links for an Android poker app or iPhone poker app. Often, the famous icon for these operating systems are located next to the link. In some cases, you’ll find a QR Code for the casino, allowing you to download the full poker client simply by scanning the code into your cellphone or tablet.
Instantly access a global network, establish local presence, and stay available on the go. https://didibanjo.bandcamp.com/album/didi-7even-rise Streamline customer interactions, boost credibility, and expand reach.
[url=https://valtrexid.online/]buy valtrex[/url]
can i purchase mobic without prescription [url=http://mobic.icu/#]cheap meloxicam[/url] can you buy generic mobic without a prescription
Природа зовет! Будьте готовы к любым приключениям с нашими мужскими рыбацкими сапогами. Надежность и комфорт для настоящих мужчин.
[url=http://colchicine.life/]how to get colchicine[/url]
https://stromectol.icu/# ivermectin tablet price
[url=https://clomidsale.online/]clomid australia online[/url]
where can i order valtrex: valtrex antiviral drug – cheap valtrex for sale
Оформление сертификата ИСО 9001 с нами – это не только возможность подтвердить соответствие вашего бизнеса международным стандартам, но получить сертификат ИСО 9001 и шанс оптимизировать внутренние процессы, повысить уровень управления и улучшить качество услуг.
[url=http://lyricawithoutprescription.online/]900 mg lyrica[/url]
http://viagra.eus/# sildenafil online
[url=https://tadalafilgf.online/]cialis 5mg[/url]
nexium sale remeron brand topiramate 200mg usa
Viagra tablet online [url=http://viagra.eus/#]order viagra[/url] Generic Viagra for sale
Узнайте, как производится Установка и ремонт сантехники своими руками полотенцесушитель с полками подробные инсрукции по установке ванны, унитаза, смесителей.
строительно-техническая экспертиза москва https://pgs111.ru/
Узнайте, как производится Установка и ремонт сантехники своими руками полотенцесушители 80 подробные инсрукции по установке ванны, унитаза, смесителей.
[url=http://synthroid.media/]can i buy synthroid online[/url]
[url=https://felomax.online/]over the counter flomax[/url]
[url=https://tretinoin.skin/]retin a 0.025 canada[/url]
[url=http://prazosin.party/]prazosin capsules 0.5mg[/url]
[url=https://nolvadex.party/]nolvadex uk pharmacy[/url]
Перед началом работ мастера демонтируют мебель, снимая старое покрытие перетяжка мягкой мебели и проверяя состояние каркаса и наполнителя.
Официальный сайт Gama Casino – удобный веб-портал, который предоставляет возможность играть, игровые автоматы Gama Casino не беспокоясь о конфиденциальности личной информации и денежных средств на счету депозита.
[url=http://zithromax.party/]zithromax strep throat[/url]
Om du letar efter en dejtingsajt i Sverige rekommenderas det att du uppmarksammar denna plattform.
Kom ihag att sakerhet alltid bor vara din prioritet nar du anvander dejtingsajter. Var noga med att kontrollera anvandarprofiler, var forsiktig nar du delar personlig information och traffa nya manniskor endast pa offentliga platser.
https://telegra.ph/Tr%C3%A4ffa-Singlar-N%C3%A4ra-Dig—Var-Inte-Blyg-Chatta-Fritt-04-03
[url=https://prednisonenp.online/]prednisone 477[/url]
[url=https://silagra.pics/]silagra 50 mg[/url]
Generic Tadalafil 20mg price [url=http://cialis.foundation/#]cialis for sale[/url] buy cialis pill
[url=http://avodart.company/]buy generic avodart online[/url]
[url=https://valtrex4.online/]where to buy valtrex 1g[/url]
allopurinol online order purchase temovate order rosuvastatin 10mg online cheap
buy sumatriptan 25mg pills how to buy levaquin where can i buy avodart
this site has a great line up and live streaming of sporting events
https://demo.sngine.com/blogs/391529/Your-guide-to-the-world-of-bonuses-for-players
When the site is down, I find a working this site mirror
https://demo.sngine.com/blogs/391529/Your-guide-to-the-world-of-bonuses-for-players
тв программы на сегодня
Закажите матрешку, посуду, шкатулку с вашей символикой, сюжетом или фото магазин отбор изделий ведут специалисты с художественным образованием и длительным стажем работы в сегменте подарочной продукции.
https://viagra.eus/# over the counter sildenafil
электрический карниз для штор цена https://prokarniz20.ru/
[url=https://meftormin.online/]metformin 60 tab 500 mg price[/url]
[url=https://metforminb.online/]metformin australia[/url]
Levitra generic best price [url=http://levitra.eus/#]Levitra 20 mg for sale[/url] Vardenafil price
Unleash the thrill of gaming like never before at our cutting-edge online casino https://azart.ucoz.net/blog/lichnyj_kabinet_kazino_ehldorado/2023-10-08-63 Your path to riches and excitement begins with a single click on this extraordinary link!
[url=https://diflucan.party/]diflucan 150 price[/url]
Join millions of winners and unlock the door to endless fun and wealth https://sponforum.ixbb.ru/viewtopic.php?id=11068#p37486 by clicking on this magical link right now.
Значение и необходимость сертификации ИСО 9001 не поддаются сомнению Сертификат ИСО 9001 Получить сертификат ИСО 9001 необходимо, чтобы документально подтвердить тот факт, что предприятия соответствует установленным в стандарте требованиям.
Experience the ultimate in online casino entertainment at your fingertips http://forex-i-ya.ru/?p=1308 get ready for a journey to unimaginable wealth and exhilaration – just one click away through this enchanted link.
buspar 5mg oral buy buspar 10mg generic amiodarone 100mg sale
https://levitra.eus/# Vardenafil online prescription
I liked the possibility of long online conversations before meeting in person.
https://telegra.ph/Az-online-t%C3%A1rskeres%C3%A9s-egy-%C3%BAj-%C3%A9s-k%C3%A9nyelmes-m%C3%B3dja-annak-hogy-megtal%C3%A1ld-a-m%C3%A1sik-feledet-10-30
вход cat casino
онлайн казино cat
Buy Vardenafil 20mg [url=https://levitra.eus/#]Buy Vardenafil 20mg online[/url] Generic Levitra 20mg
I found the love of my life thanks to the internet!
https://telegra.ph/Uformell-dating-og-chatting-for-voksne-Hva-b%C3%B8r-du-vite-04-03
осаго купить онлайн https://oformit-osago.ru/
аттестат за 9 2023 http://attestat-9-klass.ru/
[url=http://kamagra.party/]kamagra 50mg[/url]
Наша статья рассказывает про лучшие обменники криптовалюты с минимальными комиссиями читать далее Мы изучили все обменники по большому количеству параметров, таких как: скорость обмена, работа службы поддержки, платежные методы и тд.
http://levitra.eus/# Buy generic Levitra online
[url=http://doxycyclinepr.online/]cheapest doxycycline tablets[/url]
Сантехработы, монтаж и замена сантехники, как сделать правильно нижний полотенцесушитель незаменимые в любом доме элементы не так и просто поменять своими руками.
Cialis 20mg price [url=https://cialis.foundation/#]п»їcialis generic[/url] Cialis without a doctor prescription
[url=http://tadalafilh.online/]cialis online 5 mg[/url]
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области – http://msk-demontazh-doma-24.ru/. Снос дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
[url=http://prednisonenp.online/]can you buy prednisone over the counter uk[/url]
https://electrica.zp.ua/
[url=https://ciprok.online/]ciprofloxacin 400 mg[/url]
buy domperidone for sale buy cheap generic sumycin sumycin us
We present to you a list of 1xbet promotional codes relevant for 2022: https://marihuanatelevision.tv/pag/1x_codigo_promocional_1xbet.html Without promotional codes, the bonus is 25,000.
[url=https://abamoxicillin.online/]amoxicillin 125 mg price[/url]
We present to you a list of 1xbet promotional codes relevant for 2022: http://amar-sain.ru/news/pages/1xbet_promokod_pri_registracii___aktualnuy_segodnya.html Without promotional codes, the bonus is 25,000.
I’m a loyal reader of your blog. This article is another masterpiece.
https://fikes.ub.ac.id/articles/melbet_promo_code_sport_bonus.html
https://kamagra.icu/# cheap kamagra
https://medium.com/@advencher1978/vps-server-ee111932b189
Рейтинг молотого кофе. Что лучше — арабика, робуста или либерика Рецепты кофе топ-10 марок ароматного кофе с характеристиками вкуса и отзывами покупателей
I recommend this site to my friends as a reliable bookmaker
https://flokii.com/blogs/view/132351
HII could not resist commenting. Perfectly written!Go my best sites: https://www.inosport.fr/_includes/pag/code-promo-1xbet_12.html for you!
The this site signup bonus promo code came in handy
https://www.social-vape.com/read-blog/83185
Индивидуальные кухни за 10 дней напрямую от производителя, рассчитайте цену со скидкой до 37% кухни по индивидуальным размерам кухня от производителя с установкой за 10 дней!
Отказное письмо для маркетплейсов: кому нужно и как его получить отказное письмо на продукцию чтобы продавать товары на маркетплейсах, нужно доказать, что продукция безопасна для людей, животных и природы.
[url=http://baclanofen.com/]baclofen prescription[/url]
[url=http://idoxycycline.online/]doxycycline canada brand name[/url]
[url=https://azithromycinq.com/]rx azithromycin[/url]
[url=http://ciprocfx.online/]ciprofloxacin order online[/url]
Пентралапон — это экологически чистый строительный материал https://clients1.google.com.gi/url?q=http://pentralapon-astra.ru представляет собой смесь для ручной и автоматизированной отделки стен, потолков и других поверхностей.
[url=https://tamoxifen.science/]10 mg tamoxifen[/url]
Cel mai prietenos ?i crazy gadget store care i?i va colora experien?a digitala cu emo?ii, stil ?i creativitate macbook pro 2017 Ne-am lansat in martie 2013 ?i am adus cu noi „Festivalul Culorilor”
Пентралапон — это экологически чистый строительный материал https://cse.google.hn/url?q=http://pentralapon-astra.ru представляет собой смесь для ручной и автоматизированной отделки стен, потолков и других поверхностей.
[url=https://acyclovirus.com/]zovirax 400 price[/url]
Тукан https://hoteltukan.ru/nomer-disko/ – уютный отель на час в центре Москвы, который предлагает комфортный отдых и высокое качество обслуживания. Здесь вы можете снять номер с почасовой оплатой и наслаждаться романтической обстановкой. Почасовая гостиница всегда радушно встречает своих гостей. Вас ждут стильные интерьеры с дизайнерским ремонтом, отличная шумоизоляция и креативные решения в виде сауны, круглых кроватей, безупречной чистоты и вежливого обслуживания со стороны персонала.
здесь можно произвести кузовной ремонт автомобиля, если он был поврежден в результате аварии или коррозии ремонт авто шкода Все работы выполняются высококвалифицированными специалистами с использованием современных технологий и оборудования.
buy spironolactone online order aldactone generic finasteride 5mg without prescription
тв6 канал программа передач на сегодня
SEO продвижение и создание сайта частный мастер
seo продвижение и создание сайта частный мастер
[i]SEO продвижение и создание сайта частный мастер[/i]
SEO продвижение и создание сайта частный мастер
Вы можете приобрести Пентралапон оптом и в розницу у авторизованных дилеров и поставщиков http://www.states.com.au/?URL=pentralapon-astra.ru
Melbet is the best bookmaker for live betting! Huge number of live events. I often win here.
https://melbet-mn.blogspot.com/2022/11/melbet.html
[url=http://elimite.party/]elimite[/url]
Что такое фалоимитатор?
купити фалоімітатор [url=https://faloimitatorbgty.vn.ua]https://faloimitatorbgty.vn.ua[/url].
В МФО онлайн могут многие обращаться. Здесь даже быстрые займы без процентов на карту дают займ онлайн без процентов на карту И никто вашей кредитной историей не интересуется. Оформление быстрое.
Хотите освоить искусство шитья, вязания, валяния и других творческих направлений? слив курсов скачайте наши курсы и расширьте свои навыки в широком спектре рукоделия.
В МФО онлайн могут многие обращаться. Здесь даже быстрые займы без процентов на карту дают онлайн займ на карту без процентов И никто вашей кредитной историей не интересуется. Оформление быстрое.
Хотите освоить искусство шитья, вязания, валяния и других творческих направлений? курсы слив скачайте наши курсы и расширьте свои навыки в широком спектре рукоделия.
[url=https://valtrex4.online/]buy valtrex without get a prescription online[/url]
[url=https://prednisonenp.online/]prednisone without precription[/url]
[url=http://sumycin.party/]tetracycline 500mg price in india[/url]
Профессиональная переподготовка по более чем 20 направлениям в отрасли строительства переподготовка строителей дипломы установленного образца, индивидуальные программы
Купить бытовку недорого от ведущего производителя по самым низким ценам https://dombitovok.ru/ разумный, выгодный и логичный шаг заказчика без издержек по времени.
generic aurogra sildenafil 100mg uk estradiol over the counter
Абузоустойчивый VPS
Абузоустойчивый VPS
[url=http://finasteridel.online/]finasteride 5mg over the counter[/url]
[url=http://valtrexm.online/]valtrex uk pharmacy[/url]
сервис по накрутке поведенческих факторов http://povedencheskie-factori.ru/
Для вас работает алкомаркет — доставка водки на дом круглосуточно, быстро, надежно! В ассортименте каталога вас ждет отличное крепкое спиртное: пиво на дом с доставкой круглосуточно заказать заказать водку с доставкой на дом не будет сложно.
Для вас работает алкомаркет — доставка водки на дом круглосуточно, быстро, надежно! В ассортименте каталога вас ждет отличное крепкое спиртное: доставка алкоголя москва круглосуточно недорого заказать водку с доставкой на дом не будет сложно.
[url=https://valtarex.com/]valtrex prescription australia[/url]
За относительно небольшие деньги вы получаете активированный аккаунт Делимобиль, Яндекс Драйв, Ситидрайв, Белку Купить аккаунт каршеринга Для службы каршеринга, все выглядит так, как-будто автомобилем пользуется другой человек. Вуаля.
[url=http://aprednisone.online/]cost of prednisone tablets[/url]
First, the homeprorab.info student must solve the problem on his own or try to do it.
За относительно небольшие деньги вы получаете активированный аккаунт Делимобиль, Яндекс Драйв, Ситидрайв, Белку Купить аккаунт делимобиля Для службы каршеринга, все выглядит так, как-будто автомобилем пользуется другой человек. Вуаля.
Вам пригодится временные виртуальный номер. Они есть бесплатные. Но их очень быстро занимают http://www.kostromag.ru/forum/internet/3369.aspx поэтому только и остается вам воспользоваться платными виртуальными номерами.
Каждый человек приходит в этот мир для реализации своего потенциала антон винер биография Важно оказаться в университете, который поможет выполнить эту задачу.
[url=http://diflucanv.online/]diflucan 50 mg[/url]
Вам пригодится временные виртуальный номер. Они есть бесплатные. Но их очень быстро занимают http://www.vladmines.dn.ua/forum/index.php/topic,28975.0.html поэтому только и остается вам воспользоваться платными виртуальными номерами.
The Art of Nostalgia: Pinup Art
играть в казино [url=http://www.pinuporgesen.vn.ua]http://www.pinuporgesen.vn.ua[/url].
[url=http://synthroidt.online/]synthroid pills for sale[/url]
[url=https://synthroidcr.online/]synthroid for sale without prescription[/url]
order generic metronidazole buy keflex online keflex brand
Наша компания предлагает гантели сборные. Резиновый слой на таких гантелях способствует увеличению срока службы. Оно защищает металл от коррозии и царапин. Кроме того, покрытие существенно уменьшает шум при выполнении упражнений, что делает их прекрасным выбором для домашних спортзалов. В случае падения снаряда резина дает возможность уменьшить удар, минимизируя потенциальные повреждения пола, и снижая риск травмы для пользователя. Разборные гантели можно использовать для силовых упражнений, функционального фитнеса, аэробных тренировок и выполнения упражнений для реабилитации. Значительный диапазон устанавливаемого веса дает возможность тренировать все тело – от маленьких стабилизирующих мышц до более крупных.
Что делать, если покупатель на маркетплейсе просит отказное письмо. Производители и продавцы товаров должны предоставлять отказное письмо по запросу маркетплейса, Роспотребнадзора или клиентов отказное письмо для маркеплейса Требование относится к отечественной и импортной продукции. Отказные письма бывают двух видов: для торговли и для таможенного оформления.
I am new to betting and Melbet suits me – simple interface, clear application. So far there have been no problems with payments.
https://www.mongolbet.online/2023/11/melbet-promo-kodi-2023-130-gacha-bonus.html
Designers recommend sticking to a single stagramer.com color scheme that will allow you to achieve more style and harmony.
[url=https://diflucanv.online/]diflucan pills for sale[/url]
Retirei uma grande quantia da Melbet e ainda estou esperando ha quase uma semana. O servico de suporte responde apenas com frases formuladas. Nao recomendo essa empresa!
https://www.mongolbet.online/2023/09/kz.html
b29
b29
The average student is able to cope with them balforum.net, but many attend circles, sections, music or art schools in parallel, go to olympiads and competitions.
Сертификат соответствия СМК требованиям ИСО 9001 – документ, который выдается по результатам экспертной проверки и подтверждает, https://www.sostav.ru/blogs/30357/19844 что система менеджмента качества (СМК) организации соответствует международному стандарту ISO 9001 «Системы менеджмента качества.
[url=https://medlyrica.online/]lyrica discount[/url]
Today, a large number of Internet users are betting on sports https://zenwriting.net/031fi5b0ok Someone treats it as entertainment, and someone as a part-time job.
Remember that the rating everbestnews.com will not be affected by the comments that the client left without accompanying it with asterisks.
Сертификат ISO 9001 (или ИСО 9001) подтверждает, что система менеджмента качества (СМК) соответствует всем требованиям стандарта ГОСТ Р ИСО 9001-2015 https://www.sostav.ru/blogs/30357/41792 другими словами, сертификат выдается не на саму продукцию или услуги, а на процессы производства (порядок работы)
Серия ISO 9000 касается требований к управлению предприятием для обеспечения выпуска качественной продукции как получить сертификат исо 9001 видео она основывается на 8 принципах.
[url=http://valtarex.com/]where to buy valtrex[/url]
[url=https://suhagraxs.online/]suhagra without prescription[/url]
[url=http://azithromycini.online/]zithromax price singapore[/url]
Выбираем оптимальный метод бурения скважины на воду: все плюсы и минусы технологий оптимальный метод бурения скважины на воду доступ к чистой питьевой воде имеет ключевое значение для здоровья и благополучия людей.
buy cheap retin stendra price avanafil pills
ОТЭКО сделает порт комфортным: компания благоустраивает свои терминалы в порту Тамань отэко тамань цель проекта – создать для рабочих и офисных сотрудников максимально комфортные условия труда.
Китайские интернет-магазины на русском языке, лучшие сайты предлагают большой ассортимент товаров во всевозможных сегментах рынка https://weiguang.ru/ покупатели находят покупки достойного качества по лучшим ценам.
[url=https://finasteridepb.online/]propecia lowest price[/url]
[url=http://valtrexm.online/]valtrex 500 price[/url]
[url=https://elimite.skin/]elimite price[/url]
Компания «ОТЭКО», основанная предпринимателем Мишелем Литваком, – один из крупнейших налогоплательщиков и работодателей в Краснодарском крае отэко тамань Ее налоговые отчисления формируют почти 60 % ежегодного бюджета Таманского сельского поселения.
[url=https://permethrin.skin/]elimite[/url]
cat casino сайт
cat casino регистрация
[url=https://prednisonebv.online/]otc prednisone[/url]
A bookmaker tem constantemente promocoes interessantes para os jogadores. Ja recebi bons premios e apostas gratis mais de uma vez. Estou muito feliz!
https://creator.nightcafe.studio/u/Eduardoboxin
[url=https://diflucanv.online/]diflucan pill cost[/url]
tamoxifen 20mg brand where can i buy rhinocort purchase symbicort generic
[url=https://acqutane.online/]how much is accutane in mexico[/url]
[url=http://lyricanx.online/]lyrica 75 mg cost[/url]
двери под покраску профиль дорс https://skritie-dveri.ru/
[url=https://lisinoprilas.online/]ordering lisinopril without a prescription[/url]
Друзья, если у вас есть ненужный силовой кабель, трансформатор, цветной лом, чугун и другой? Мы предлагаем вам сдать, и избавиться от него нашими силами. Вы можете позвонить мне, либо найти наш сайт и ознакомиться с стоимостью.
где сдать медь дорого
Веб ссылок не указываю, чтобы не подумали на спам, все умеют искать поиском рамблер! Обращайтесь в компания!
order tadalafil sale buy tadalafil 20mg sale brand indomethacin 75mg
You actually reported it wonderfully!|
https://www.buzzfeed.com/sputnik8c
[url=https://accutanelb.online/]buy cheap accutane online[/url]
[url=http://albuterolhl.online/]ventolin discount[/url]
[url=https://accutanelb.online/]accutane sale uk[/url]
Retire una gran suma de bookmaker y sigo esperando desde hace casi una semana. El servicio de asistencia solo responde con frases hechas. No recomiendo esta empresa.
https://www.slideserve.com/Maxim13
Saya baru saja mendaftar di bookmaker dan belum sepenuhnya memahami semua nuansanya. Saya merasa antarmukanya agak rumit untuk pemula.
https://1x-bet.fun
[url=https://finasteridepb.online/]order generic propecia online[/url]
[url=http://clomip.com/]clomid 50mg canada[/url]
[url=https://doxycyclinedsp.online/]cost of doxycycline in canada[/url]
[url=https://acqutane.online/]accutane prescription[/url]
Наш интернет-магазин осуществляет оперативную доставку алкоголя на дом в Москве в кратчайшие сроки доставка алкоголя в москве круглосуточно в каталоге можно подобрать и оформить ночную доставку на дом алкоголя известных брендов.
[url=http://prednisonefn.online/]prednisone 10mg tablets[/url]
[url=http://accutanelb.online/]accutane best price[/url]
[url=http://esynthroid.online/]synthroid 75 mcg cheap no prescription[/url]
[url=http://medlyrica.online/]buy lyrica 300 mg online[/url]
Абузоустойчивый VPS
Виртуальные серверы VPS/VDS: Путь к Успешному Бизнесу
В мире современных технологий и онлайн-бизнеса важно иметь надежную инфраструктуру для развития проектов и обеспечения безопасности данных. В этой статье мы рассмотрим, почему виртуальные серверы VPS/VDS, предлагаемые по стартовой цене всего 13 рублей, являются ключом к успеху в современном бизнесе
[url=http://lyricanx.online/]lyrica pills 150 mg[/url]
автосервис фольксваген
daddy casino регистрация на сайте https://daddy-casino-zerkalo.online/
[url=http://acqutane.online/]accutane medicine buy[/url]
[url=http://diflucanv.com/]diflucan over counter[/url]
https://proxyelite.biz/
[url=http://diflucanld.online/]where to buy diflucan in canada[/url]
busdoor em salvador
buy trazodone online cheap suhagra 100mg drug cost clindac a
[url=https://happyfamilyrxstorecanada.com/]reputable indian pharmacies[/url]
lamisil 250mg uk best real cash online casinos blackjack free online
[url=https://vermoxpr.online/]vermox pills[/url]
[url=https://prednisome.online/]purchase prednisone no prescription[/url]
[url=https://prednisome.online/]preddisone no[/url]
Regardless of whether you are looking for electronic equipment, children’s clothing or food products, you can always find everything you need https://crazysale.marketing/depositphotos.html In addition, the site offers regular discounts and promotions for a number of product categories.
http://withoutprescription.guru/# 100mg viagra without a doctor prescription
Regardless of whether you are looking for electronic equipment, children’s clothing or food products, you can always find everything you need https://crazysale.marketing/ctrscomua.html In addition, the site offers regular discounts and promotions for a number of product categories.
[url=http://lyricadp.online/]lyrica online prescription[/url]
[url=http://azithromycinx.online/]azithromycin buy online[/url]
[url=http://lyricatb.online/]lyrica 75[/url]
Continuum Units have been customized for Filmora users, unleashing amazing creative visual effects and graphics potential filmora studio Visual Effects Applications and Plugins for Adobe After Effects, Premiere Pro, Photoshop.
Hi! I’m Paisley.
You can discover a wide range of sports for betting here
https://telescope.ac/betrew7/melbet-promo-kodlarini
Большой ассортимент электроники, цифровой и бытовой техники, а так же товаров для дома, известных брендов в интернет-магазине https://crazysale.marketing/ziprecruiter.html
Большой ассортимент электроники, цифровой и бытовой техники, а так же товаров для дома, известных брендов в интернет-магазине https://crazysale.marketing/stylus.html
[url=http://ibaclofeno.online/]buy lioresal online[/url]
Wonderful photos, the color and depth of the images are breath-taking, they draw you in as though you belong of the composition.
онлайн казино gama casino
brand aspirin 75 mg online slots for real money real casino slots
[url=https://lyricatb.online/]lyrica canada[/url]
Сертификация продукции — это свидетельство о соответствии изделий нормам качества, установленным стандартами производства http://www.vnii-certification.ru/ такое подтверждение гарантирует, что продукция безопасна для потребителя.
daddy casino зеркало сайта https://daddy-casino7.site/
карниз для штор алиса https://prokarniz27.ru/
Оформление заказа. Батуты в Ярославле с сеткой. Батуты в Починках с сеткой. Батуты в Раменском с сеткой. Батуты в Пудоже с сеткой
СЕО продвижение сайта SEO
Батуты в Каменске-Уральском с сеткой. Батуты в Усть-Илимске с сеткой. Дачный комплекс Лесная поляна 3 ЦЕПНЫЕ качели Romana R 103.25.05. Батуты в Сургуте с сеткой. Батут детский с защитной сеткой 10 диаметр 3 м Perfetto sport
Батуты в Скопине с сеткой. Батуты в Киреевске с сеткой. Батуты в Арске с сеткой. Детская игровая площадка Мальта. Батуты в Гуково с сеткой
Батуты в Урае с сеткой. Батуты в Лесозаводске с сеткой. Деревянный домик Джорджия Solowave Design. Батуты в Хвалынске с сеткой. Батуты в Сковородино с сеткой
Website creation is a complex and creative process that requires the participation of a team of specialists of various profiles http://introsystems.ru/component/kunena/welcome-mat/31173-kak-vybrat-domennoe-imya-dlya-svoego-sajta Depending on the goals and objectives of the customer, corporate websites, online stores, landing pages, blogs and many other types of web resources can be developed.
Website creation is a complex and creative process that requires the participation of a team of specialists of various profiles http://kranmanipulator.com.ua/index.php?option=com_k2&view=itemlist&task=user&id=44193 Depending on the goals and objectives of the customer, corporate websites, online stores, landing pages, blogs and many other types of web resources can be developed.
Review of the bookmaker Mostbet : reviews, bonuses, mirror, comments, website, minimum and maximum bets https://raymonddwpg32109.blog-gold.com/29137547/mostbet-portugal-an-in-depth-exploration-of-the-foremost-betting-platform Mostbet is one of the popular online betting platforms.
[url=https://synthroidcr.online/]synthroid 50 mg[/url]
[url=https://azithromycinq.online/]azithromycin 250 mg tablet cost[/url]
[url=https://esynthroid.online/]levothyroxine 50 mcg[/url]
Подскажите, пожалуйста, какой регистратор купить для автомобиля? А лучше у вас какой сейчас стоит? И где брали.
А то разброс цен большой, и доверия нет.
Например в озоне цена от 750 руб до 64000 руб
на Wildberries от 250 руб до 89058 руб
Также, попался сайт частная раскрутка сайтов вроде модели хорошие и недорого.
Но боюсь, пришлют ли? Знакомого так кинули. Заказал за 5 тыс, а прислали за 1000 руб.
И про рынок забыл, там все от 7500 руб, зато сразу в руках держишь.
I am glad that this site always has working mirrors
https://jobsmart24.com/
http://canadapharm.top/# canadian neighbor pharmacy
indian pharmacy paypal [url=https://indiapharm.guru/#]online pharmacy india[/url] indian pharmacy paypal
https://edpills.icu/# best erectile dysfunction pills
bata4d
bata4d
can you buy generic clomid price: order generic clomid without insurance – can i order cheap clomid no prescription
[url=https://happyfamilystore365.com/]maple leaf pharmacy in canada[/url]
[url=http://ovaltrex.online/]mexico pharmacy valtrex[/url]
К нам обращаются тысячи частных заказчиков, а брендированные подарки заказывают известные компании подарки, широкий, тщательно подобранный ассортимент обеспечивает нам не менее широкую покупательскую аудиторию.
[url=http://ibaclofeno.online/]baclofen 20 mg tablet[/url]
With the growth of cryptocurrencies, Ethereum has become the most well-known digital asset . Investors are trading them on exchanges and anticipating growth in their value http://paguerasportregion.com/returning-to-faith-just-how-blockchain-have-a-tendency-to-alter-organization-as-well-as-the-discount/ Bitcoin: Pioneering Digital Currency.
https://withoutprescription.guru/# prescription without a doctor’s prescription
mexican drugstore online [url=https://mexicopharm.shop/#]reputable mexican pharmacies online[/url] purple pharmacy mexico price list
http://indiapharm.guru/# buy prescription drugs from india
https://medium.com/@FFlowers19491/дешевый-сервер-linux-ssd-7c7df013caf3
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
purchase trimox order arimidex online macrobid online
Купить цветы с доставкой, большой выбор оригинальных букетов цветов на любой повод и случай с бесплатной доставкой доставка цветов саратов солнечный в большом ассортименте представлены композиции по низким ценам.
real cialis without a doctor’s prescription: 100mg viagra without a doctor prescription – prescription drugs online
Купить цветы с доставкой, большой выбор оригинальных букетов цветов на любой повод и случай с бесплатной доставкой цвет с доставкой саратов в большом ассортименте представлены композиции по низким ценам.
Оформление отказных писем — это всего лишь бизнес стоимость отказного письма появился в начале 2010-х, когда только начинали делать декларации.
[url=http://permethrin.skin/]cheap elimite[/url]
https://en.wikipedia.org/wiki/Tarek_Nour_Communications
лизинговая компания, которая финансирует покупку оборудования, транспорта, спецтехники для клиентов из микро-, малого и среднего бизнеса как получить лизинг на спецтехнику лизинг входит в состав международного холдинга.
[url=https://esynthroid.online/]synthroid 137.5 mcg[/url]
Activated a promo code and got a freebet at this site
https://maxbetasia88.net/
[url=https://albuterolhi.online/]online pharmacy ventolin[/url]
sildenafil 150 mg [url=https://sildenafil.win/#]buy sildenafil online europe[/url] sildenafil prescription australia
this site’s exceptional odds for popular soccer events are a great attraction
https://tetrasky.ru/
https://edpills.monster/# best drug for ed
[url=http://azithromycinq.online/]zithromax 250mg tablets[/url]
sildenafil for sale: sildenafil 50mg buy – sildenafil tablet online india
http://sildenafil.win/# sildenafil 10 mg
После того, как заключается договор, все прописанное в нем оборудование становятся собственностью лизинговой компании лизинг строительного оборудования после того, как будет выплачена вся сумма сделки, владельцем становится клиент.
Testosterone and its esters can be added to your cycle to keep levels within a normal physiological range ie, 100 200 mg wk but must not go above this cialis tadalafil Have done mountains of research on Internet
The operator of the bookmaker’s office and casino Mostbet in offers a line with thousands of events https://www.camaro5.com/forums/group.php?&do=discuss&groupid=479&discussionid=&gmid=179530#gmessage179530 and a showcase of slot machines and crash games.
После того, как заключается договор, все прописанное в нем оборудование становятся собственностью лизинговой компании лизинг медицинского оборудования после того, как будет выплачена вся сумма сделки, владельцем становится клиент.
win79
rocaltrol 0.25 mg pills buy rocaltrol 0.25 mg pills tricor cheap
Pin Up is the official website of online casinos for players https://www.baldtruthtalk.com/threads/52377-Sports-betting-and-slots-in-Bangladesh?p=319827#post319827 start playing for real money on the official website.
ed pills cheap [url=http://edpills.monster/#]generic ed pills[/url] new ed drugs
Pin Up is the official website of online casinos for players https://www.google.iq/url?q=https://mostbet-mosbet-uz.com start playing for real money on the official website.
cheap kamagra: buy Kamagra – super kamagra
[url=https://diflucanv.com/]diflucan pill uk[/url]
sildenafil 20 mg in mexico: sildenafil 100mg cost – cheap sildenafil canada
[url=http://ovaltrex.com/]buy valtrex tablets[/url]
В нынешнюю цифровую эпоху общение является жизненно важным аспектом любого бизнеса https://3news.ru/2023/04/11/487150/
[url=http://acqutane.online/]accutane pills price in india[/url]
buy clonidine generic order clonidine order generic spiriva
I appreciate the convenience of always having reliable this site mirrors at hand
https://jobsmart24.com/
ТРУД ВАЧА. Леска PATRIOT. Сверло MOS.
сайт частник продвижение создание
Смеситель для гигиенического душа DAMIXA. Тумба под раковину JACOB DELAFON. Кнопка смыва IDEAL STANDARD. Смеситель для раковины IDDIS.
Сантехника в Кронштадте
Перфоратор MAKITA
Держатели туалетной бумаги
Сантехника в Свирске
Сантехника в Саратове. Комплект TECE. Кронштейн для верхнего душа AM.PM.
this site has a large selection of slots from different providers, there are many bonuses
https://tetrasky.ru/
[url=http://diflucanld.online/]diflucan generic[/url]
На нашем сайте Майнкрафт скачать на телефон вы сможете скачать Майнкрафт, моды, текстуры, карты и шейдеры для игры Minecraft.
Игорный клуб eldoclub xyz начал свою работу в 2014 году. В настоящее время заведение предоставляет качественный азартный сервис тысячам гемблеров по всему миру, а также в России и странах СНГ. Сайт полностью переведен на русский язык.
https://atlant-cleaning.ru/
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
[url=http://valtarex.com/]valtrex generic over the counter[/url]
[url=https://lyricanx.online/]lyrica 75 mg tablet price in india[/url]
generic sildenafil from canada [url=https://sildenafil.win/#]buy sildenafil with paypal[/url] 20 mg generic sildenafil
Сантехника в Полысаево. Сантехника в Озерске. Унитаз-компакт GUSTAVSBERG.
сайт частник продвижение создание
Сантехника в Мысках. Инсталляция для писсуара. Держатель туалетной щетки BEMETA. Перчатки и рукавицы.
Решетка заборная 64541 в рулоне, 1,8х25 м, ячейка 90х100 мм, пластиковая, зеленая
Сантехника в Ковдоре
Душевой уголок Радомир 1-03-1-2-0-0081 120х80х196, стекло матовое, поддон, профиль белый, правый
HATRIA
Сантехника в Омутнинске. Тройник пресс VIEGA. Сиденье для унитаза TIMO.
[url=https://metforminzb.online/]metformin 500mg er[/url]
http://edpills.monster/# ed medications
strong acne medication prescription trileptal online buy oxcarbazepine 600mg generic
https://merida-cleaning.ru/
[url=https://retinagel.skin/]tretinoin 0.025 cost[/url]
[url=https://lisinoprilas.online/]lisinopril 10 12.5 mg[/url]
tadalafil over the counter uk: buy generic tadalafil online – cheap generic tadalafil 5mg
[url=https://tadalafilvr.online/]cialis gel caps[/url]
Международные пассажирские перевозки из городов Украины в города ДНР и обратно Автобус Кельн – Кременчуг Прямые рейсы. Наше преимущество: без штрафов; без приложения ДИЯ
Выпуская продукцию или услугу на рынок, компания неизменно сталкивается с подтверждением соответствия такой продукции Коды ОКП или услуги общепринятым стандартам, законодательным, договорным или иным требованиям.
http://www.manufacturer.vn is healthcare manufacturer of nasal rinse kit, vaginal pump gel, long time xxx solution, enhance supplement, ODM and OEM service. Manufacturer.vn can also research and development products from your ideas. We export more than 40 countries, we are one sub-company of StrongBody
Подборка наиболее популярных федеральных законов и кодексов РФ с возможностью полнотекстового ознакомления и скачивания http://sbornik-zakonov.ru/ Общий хронологический указатель к Полному собранию законов.
[url=https://vermoxpr.online/]vermox tablets uk[/url]
Международные пассажирские перевозки из городов Украины в города ДНР и обратно Автобус Кельн – Полтава Прямые рейсы. Наше преимущество: без штрафов; без приложения ДИЯ
https://tadalafil.trade/# 20 mg tadalafil cost
[url=https://accutanelb.online/]accutane price uk[/url]
частное продвижение сайтов раскрутка сео
[url=https://dexamethasonelt.online/]dexamethasone 3 mg[/url]
[url=http://synthroidt.online/]synthroid 25 mg coupon[/url]
Широкопрофильная технология беспроводной связи, известная как Wi-Fi, стала неотъемлемой частью нашей повседневной жизни как на телефоне поменять пароль, но что такое Wi-Fi, и как можно осуществить его настройку?
minomycin online buy cheap requip 2mg buy requip sale
[url=http://iprednisone.online/]prednisone 1 mg for sale[/url]
Wi-Fi работает на основе радиоволн, что позволяет устройствам свободно обмениваться данными провайдер – это особенно удобно, поскольку не требуется множество проводов, и вы можете подключаться к интернету практически отовсюду в пределах дома или офиса.
lisinopril 200 mg [url=http://lisinopril.auction/#]buy lisinopril online[/url] lisinopril 40 mg tablet
Широкопрофильная технология беспроводной связи, известная как Wi-Fi, стала неотъемлемой частью нашей повседневной жизни lan, но что такое Wi-Fi, и как можно осуществить его настройку?
Wi-Fi работает на основе радиоволн, что позволяет устройствам свободно обмениваться данными lan – это особенно удобно, поскольку не требуется множество проводов, и вы можете подключаться к интернету практически отовсюду в пределах дома или офиса.
[url=https://predonisone.online/]prednisone prescriptions[/url]
http://doxycycline.forum/# buy doxycycline tablets 100mg
cost of amoxicillin prescription: buy amoxil – how to buy amoxycillin
[url=https://alisinopril.online/]purchase lisinopril 10 mg[/url]
[url=http://finasteridepb.online/]how to order propecia online[/url]
uroxatral 10 mg usa order alfuzosin online cheap common heartburn medication prescription
[url=http://ovaltrex.online/]valtrex 1500 mg[/url]
[url=http://amoxicillinf.online/]amoxicillin 875 mg cost[/url]
[url=http://ibaclofeno.online/]baclofen 200 mg price[/url]
Создайте сайт с нуля или из готового шаблона. Легкая реализация https://www.google.li/url?q=https://seo-vk.ru/ Выбирайте шаблон и просто добавляйте свой контент. Собственный дизайн.
buy cipro online without prescription: Ciprofloxacin online prescription – ciprofloxacin generic price
Создайте сайт с нуля или из готового шаблона. Легкая реализация https://www.google.sr/url?q=https://seo-vk.ru/ Выбирайте шаблон и просто добавляйте свой контент. Собственный дизайн.
[url=http://metforminzb.online/]glucophage no prescription[/url]
buy zithromax canada: zithromax antibiotic – can you buy zithromax over the counter in mexico
where to get zithromax [url=https://azithromycin.bar/#]zithromax z-pak[/url] zithromax online
https://ruuborka.ru/
[url=https://prednisome.online/]deltasone over the counter[/url]
Production of duplicates of state license plates https://www.google.com.nf/url?q=https://guard-car.ru/ production of duplicates of state license plates of all types.
https://ciprofloxacin.men/# buy cipro cheap
[url=https://prednisonee.online/]prednisone purchase online[/url]
челябинск сувениры из камня https://suveniry-i-podarki13.ru/
[url=https://happyfamilyrxstorecanada.com/]online pharmacy discount code[/url]
work in education sector
[url=https://synthroidcr.online/]cost of synthroid 200 mcg[/url]
buy cipro: Get cheapest Ciprofloxacin online – cipro online no prescription in the usa
Production of duplicates of state license plates https://www.google.ro/url?sa=t&url=https://guard-car.ru/ production of duplicates of state license plates of all types.
[url=https://alisinopril.online/]lisinopril uk[/url]
[url=https://lyricatb.online/]lyrica 2017[/url]
[url=http://finasteridepb.online/]propecia uk[/url]
Production of duplicates of state license plates https://www.google.no/url?q=https://guard-car.ru/ production of duplicates of state license plates of all types.
where can i buy zithromax in canada [url=https://azithromycin.bar/#]zithromax z-pak[/url] zithromax drug
buy generic femara over the counter purchase aripiprazole for sale aripiprazole ca
[url=https://valtrexm.online/]buy valrex online[/url]
英超賽程
sleeping pills by price order sleeping tablets online uk buy weight loss medications online
[url=https://lisinoprilas.online/]cost of lisinopril in mexico[/url]
[url=http://lyricanx.online/]buy lyrica cheap[/url]
[url=http://prednisonebv.online/]deltasone medication[/url]
doxycycline generic price: doxycycline discount – buy doxycycline 200 mg
amoxicillin for sale: buy amoxil – how to get amoxicillin over the counter
purchase cipro [url=https://ciprofloxacin.men/#]ciprofloxacin without insurance[/url] buy generic ciprofloxacin
[url=https://diflucanld.online/]buy diflucan 150mg[/url]
[url=http://valtrexm.online/]how much is valtrex prescription[/url]
[url=https://metforminex.online/]buy metformin nz[/url]
where can you buy doxycycline online: Doxycycline 100mg buy online – doxycycline 200 mg price
[url=http://lyricadp.online/]lyrica 50 mg[/url]
[url=http://prednisome.online/]buy prednisone online cheap[/url]
[url=http://dexamethasonelt.online/]how much is dexamethasone[/url]
We will officially produce a duplicate number within 5 minutes https://www.google.nl/url?sa=t&url=https://guard-car.ru/ Who can make duplicate numbers?
http://azithromycin.bar/# where can you buy zithromax
doxycycline 100mg tablets coupon [url=http://doxycycline.forum/#]buy doxycycline over the counter[/url] buy vibramycin
накрутка пф авито https://nakrutka-nr.ru/
Платные курсы бесплатно
Editable templates for verification purposes british gas bill template
The this site app enhances the soccer betting experience
https://jobsmart24.com/
most reputable canadian pharmacy: online pharmacy usa – online pharmacy no scripts
[url=http://metforminzb.online/]metformin 101[/url]
Подушка для секс с креплениями Liberator BL Retail Hipster (чёрный). Насадка Unicorn Silicone Mystical Waterfall. Вибромассажер-кролик Halo со стимулирующим кольцом и функцией “мгновенный оргазм”.
продвижение сайтов частный мастер
Пояс для чулок “A767”.
Erotic Fantasy Jumping Bullets – Мини вибратор с 3 моторами и реалистичной головкой, 19.5х3.5 см (розовый).
Реалистичный слепок с вибрацией Wildfire® Celebrity Series Farrah’s Backdoor Entry 6x, 6s Vibrating Pussy & Ass (телесный).
27167041041 / Noir Handmade Платье миди с ошейником, размер L.
SileXD Model 1 – Фаллоимитатор с вибрацией, 21,5 см (розовый). CalExotics Jack Rabbit Signature Heated Silicone Thrusting ультра мягкий перезаряжаемый вибратор кролик с подогревом и толчками, 12.75х3.75 см. The Rabbit Company Sonic Rabbit – Вибратор с клиторальным отростком и функцией толкания, 22х3.5 см (фиолетовый).
инвентарь для занятий спортом в интернет-магазине
инвентарь для занятий спортом по выгодным ценам в нашем магазине
Качество и удобство в каждой детали инвентаря в нашем ассортименте
Инвентарь для спорта для начинающих и профессиональных спортсменов в нашем магазине
Низкокачественный инвентарь может стать препятствием во время тренировок – выбирайте качественные спорттовары в нашем магазине
Спорттовары только от ведущих производителей с гарантией качества
Улучшите результаты тренировок с помощью спорттоваров из нашего магазина
спорттоваров для самых популярных видов спорта в нашем магазине
Отличное качество спорттоваров по доступным ценам в нашем интернет-магазине
Простой поиск и инвентаря в нашем магазине
Акции и скидки на инвентарь для занятий спортом только у нас
Прокачайте свои спортивные качества с помощью спорттоваров из нашего магазина
Широкий ассортимент для любого вида физической активности в нашем магазине
Проверенный инвентарь для занятий спортом для мужчин в нашем магазине
инвентаря уже ждут вас в нашем магазине
Поддерживайте форму в любых условиях с помощью инвентаря из нашего магазина
Выгодные условия покупки на аксессуары в нашем интернет-магазине – проверьте сами!
спорттоваров для любого вида спорта по самым низким ценам – только в нашем магазине
Спорттовары для амбициозных спортсменов и начинающих в нашем магазине
спорт магазин [url=http://www.sportivnyj-magazin.vn.ua]http://www.sportivnyj-magazin.vn.ua[/url].
indianpharmacy com [url=http://indiapharmacy.site/#]best india pharmacy[/url] india pharmacy mail order
nhs stop smoking advice arthritis old medication names doctors who prescribe narcotics easily
[url=https://cazinouri-online-straine-din-ro.com]cazinouri-online-straine-din-ro.com[/url]
Rating of the most beneficent online casinos – hesitate sulcus machines for existent money. Verified and straight online casinos from the UPPERMOST 10 rating.
cazinouri-online-straine-din-ro.com
Уход за растениями
[url=http://suhagraxs.online/]suhagra 25 mg tablet[/url]
[url=https://clomip.com/]clomid iui[/url]
Пересадка комнатных растений и цветов в Санкт-Петербурге
[url=http://ovaltrex.com/]valtrex generic otc[/url]
[url=http://ovaltrex.online/]valtrex price australia[/url]
[url=https://permethrin.skin/]generic elimite cream[/url]
[url=https://diflucanv.com/]diflucan rx[/url]
[url=http://prednisonefn.online/]how to get prednisone[/url]
best india pharmacy: Online medicine home delivery – п»їlegitimate online pharmacies india
[url=http://azithromycini.online/]azithromycin otc usa[/url]
http://mexicopharmacy.store/# buying from online mexican pharmacy
Озеленение офисов
https://movibox.ru/
Уход за растениями в офисе
canadian world pharmacy: Online pharmacy USA – list of reputable canadian pharmacies
reputation house
профессиональный уход и обслуживание зеленых растений
online shopping pharmacy india [url=http://indiapharmacy.site/#]indian pharmacies safe[/url] reputable indian online pharmacy
best canadian online pharmacy reviews: certified canadian pharmacy – canadian online drugs
https://canadiandrugs.store/# canadian world pharmacy
[url=http://amoxicillinf.online/]generic amoxicillin capsules[/url]
Робот-пылесос может очистить любое помещение от пыли, грязи и шерсти животных без участия человека все инструменты робот пылесос
Brand SERM from Reputation House: How Customer Reviews Influence Perception of Your Brand reputation house customer reviews
Робот-пылесос может очистить любое помещение от пыли, грязи и шерсти животных без участия человека робот-пылесос моющий
Brand SERM from Reputation House: How Customer Reviews Influence Perception of Your Brand reputation house serm
https://clomid.club/# where can i get clomid tablets
paxlovid covid [url=http://paxlovid.club/#]Paxlovid price without insurance[/url] buy paxlovid online
Получение сертификата ИСО 9001 – завершающий этап процедуры сертификации, https://vc.ru/u/1700288-rospromtest/719170-sertifikat-iso-9001-chto-eto-takoe-i-dlya-chego-ego-oformlyayut без прохождения которой выдача документа априори невозможна.
We talked with the Reputation House agency about the importance of employee reviews reputation house reviews
paxlovid price: Paxlovid without a doctor – Paxlovid buy online
http://claritin.icu/# can you buy ventolin over the counter in nz
[url=http://synthroidt.online/]synthroid thyroid[/url]
купить справку из диспансера
[url=http://doxycyclinedsp.online/]doxycline[/url]
[url=https://amoxicillinf.online/]trimox without prescription[/url]
Mount Kenya University (MKU) is a Chartered MKU and ISO 9001:2015 Quality Management Systems certified University committed to offering holistic education. MKU has embraced the internationalization agenda of higher education. The University, a research institution dedicated to the generation, dissemination and preservation of knowledge; with 8 regional campuses and 6 Open, Distance and E-Learning (ODEL) Centres; is one of the most culturally diverse universities operating in East Africa and beyond. The University Main campus is located in Thika town, Kenya with other Campuses in Nairobi, Parklands, Mombasa, Nakuru, Eldoret, Meru, and Kigali, Rwanda. The University has ODeL Centres located in Malindi, Kisumu, Kitale, Kakamega, Kisii and Kericho and country offices in Kampala in Uganda, Bujumbura in Burundi, Hargeisa in Somaliland and Garowe in Puntland.
MKU is a progressive, ground-breaking university that serves the needs of aspiring students and a devoted top-tier faculty who share a commitment to the promise of accessible education and the imperative of social justice and civic engagement-doing good and giving back. The University’s coupling of health sciences, liberal arts and research actualizes opportunities for personal enrichment, professional preparedness and scholarly advancement
[url=https://baclofendl.online/]baclofen 25 mg tablet[/url]
where to buy cheap clomid without rx: Buy Clomid Online Without Prescription – where can i buy generic clomid pills
Мы являемся как импортерами, так и дистрибьюторами медицинских изделий, тщательно выбираем поставщиков медицинское оборудование для косметологии купить и формируем ассортимент только из высокотехнологичного, современного оборудования.
itraconazole online order buy herpes treatment online does pomegranate juice lower blood sugar
Мы являемся как импортерами, так и дистрибьюторами медицинских изделий, тщательно выбираем поставщиков медицинское оборудование купить в красноярске и формируем ассортимент только из высокотехнологичного, современного оборудования.
https://bookmakers-android.ru/
[url=http://predonisone.online/]prednisone 10mg pack[/url]
Депозитарное хранение архивных документов. хранение архивных документов в архиве, музее, депозитарное хранение архивных документов библиотеке на условиях, определяемых соглашением (договором).
[url=http://iprednisone.online/]5094 prednisone[/url]
Депозитарное хранение архивных документов. хранение архивных документов в архиве, музее, организация депозитарного хранения документов библиотеке на условиях, определяемых соглашением (договором).
купить справку
[url=http://ibaclofeno.online/]baclofen buy online[/url]
Gama Casino – популярное онлайн-казино, предлагающее своим клиентам богатый выбор игровых автоматов gama на деньги
поисковое продвижение web сайтов https://prodvizhenie-sajtov13.ru/
this site offers various slots and player promotions, enhancing the gaming experience
https://tetrasky.ru/
«АгроМаркет» – профессиональный магазин для садоводов Более 20 лет на рынке агромаркет в наличии семена овощей, садовый инвентарь, удобрения.
Шуточный софт для мобильных телефонов казино
Sun52
[url=http://diflucanv.online/]buy fluconazole[/url]
Здесь клиенты могут подобрать наиболее подходящие варианты для прогнозирования результативности матчей личный кабинет 1win
To connect and use a virtual number https://maps.google.co.bw/url?q=https://didvirtualnumbers.com/en/
[url=https://vermoxpr.online/]generic vermox[/url]
decibel measure app
order ventolin online no prescription: Ventolin inhaler online – can i buy ventolin over the counter in usa
http://wellbutrin.rest/# can you buy wellbutrin online
[url=http://lisinoprilrm.online/]prescription drug lisinopril[/url]
promethazine 25mg us best pill for ed ivermectin buy nz
b52
https://paxlovid.club/# paxlovid pill
Отказное письмо на свечи ручной работы https://telegra.ph/Sertifikaciya-svechej-nuzhen-li-sertifikat-ili-dostatochno-otkaznogo-pisma-11-20
Покупайте высококачественный ламинат Quick-Step в нашем интернет-магазине https://quick-step-shop.ru/ . Широкий ассортимент коллекций, разнообразные оттенки и фактуры. Прочный, стильный и легкий в уходе – идеальный выбор для любого помещения. Доставка по всей стране и гарантированно надежное качество обслуживания.
[url=http://synthroidt.online/]synthroid mcg[/url]
http://claritin.icu/# ventolin tablet medication
b52
In this site there are often increased odds on favorites
https://tetrasky.ru/
ремонт муфты автокондиционеров в Арсеньеве недорого!
заправка автокондиционеров москва цена в Починке дешево!
АВТОРИЗОВАННЫЙ СЕРВИСНЫЙ ЦЕНТР
РЕМОНТ КОМПРЕССОРА В ТЕЧЕНИИ ДНЯ
ГАРАНТИЯ НА ВСЕ РАБОТЫ 1 ГОД
ремонт кондиционеров автомобилей недорого в Заинске дешево!
boomer-avto.ru
https://farmaciait.pro/# farmacie online affidabili
[url=https://synthroidt.online/]brand name synthroid price[/url]
farmaci senza ricetta elenco: comprare avanafil senza ricetta – farmacie online affidabili
заправка кондиционера машины цена в Воркуте недорого!
ремонт кондиционеров авто в Лаишево доступно!
АВТОРИЗОВАННЫЙ СЕРВИСНЫЙ ЦЕНТР
РЕМОНТ КОМПРЕССОРА В ТЕЧЕНИИ ДНЯ
ГАРАНТИЯ НА ВСЕ РАБОТЫ 1 ГОД
ремонт кондиционеров авто в Тейково доступно!
boomer avto ru
farmacie online sicure: farmacia online spedizione gratuita – migliori farmacie online 2023
to be popular on youtube you need to buy youtube views on the best site views
Наша компания дает вам возможность купить необходимое оборудование в лизинг от иностранных и отечественных производителей, как новое, так и б/у лизинг торгового оборудования для магазина
Наша компания дает вам возможность купить необходимое оборудование в лизинг от иностранных и отечественных производителей, как новое, так и б/у лизинг оборудования нижний новгород
acquisto farmaci con ricetta: kamagra oral jelly consegna 24 ore – farmaci senza ricetta elenco
[url=http://finasteride.cyou/]http://www.propeciaforless.com[/url]
esiste il viagra generico in farmacia: sildenafil 100mg prezzo – kamagra senza ricetta in farmacia
МК Лизинг входит в состав международного холдинга Mikro Kapital Group, компании которого оказывают помощь малому и среднему бизнесу в 14 странах мира коммерческая недвижимость в лизинг
do pharmacies sell birth control priligy where to buy 5mg cialis daily side effects
МК Лизинг входит в состав международного холдинга Mikro Kapital Group, компании которого оказывают помощь малому и среднему бизнесу в 14 странах мира лизинг недвижимости для юридических
farmacia online senza ricetta: kamagra gel prezzo – acquistare farmaci senza ricetta
[url=http://budesonide.cyou/]budesonide 9 mg cost[/url]
http://farmaciait.pro/# migliori farmacie online 2023
top farmacia online: avanafil spedra – farmacie online sicure
[url=https://fluoxetine.cyou/]cost of fluoxetine 40 mg[/url]
migliori farmacie online 2023: cialis prezzo – comprare farmaci online all’estero
farmacie online sicure: kamagra gel – farmacia online
]гама казино
официальный сайт гама казино
https://sildenafilit.bid/# farmacia senza ricetta recensioni
Получение сертификата ИСО 9001 – завершающий этап процедуры сертификации, без прохождения которой выдача документа априори невозможна. Преимуществом будет, если орган, выполняющий проверку, имеет соответствующую аккредитацию что такое сертификат ISO 9001 Сертификат соответствия СМК требованиям ИСО 9001 – документ, который выдается по результатам экспертной проверки и подтверждает, что система менеджмента качества (СМК) организации соответствует международному стандарту ISO 9001 «Системы менеджмента качества. Требования» либо его национальному аналогу ГОСТ Р ИСО 9001 и своевременно совершенствуется.
farmacie online autorizzate elenco [url=http://tadalafilit.store/#]cialis prezzo[/url] comprare farmaci online all’estero
viagra pfizer 25mg prezzo: viagra prezzo – viagra 100 mg prezzo in farmacia
A printable calendar is great for keeping the family organized — printable calendar 2024 monthly it’s customizable, encourages communication, and helps with planning, all without needing to rely too much on technology.
new player bonus
Получение сертификата ИСО 9001 – завершающий этап процедуры сертификации, без прохождения которой выдача документа априори невозможна. Преимуществом будет, если орган, выполняющий проверку, имеет соответствующую аккредитацию сертификация ISO 9001 Сертификат соответствия СМК требованиям ИСО 9001 – документ, который выдается по результатам экспертной проверки и подтверждает, что система менеджмента качества (СМК) организации соответствует международному стандарту ISO 9001 «Системы менеджмента качества. Требования» либо его национальному аналогу ГОСТ Р ИСО 9001 и своевременно совершенствуется.
A printable calendar is great for keeping the family organized — may printable calendar 2024 it’s customizable, encourages communication, and helps with planning, all without needing to rely too much on technology.
farmacie online affidabili: kamagra – farmacie on line spedizione gratuita
farmacie online sicure: Farmacie a milano che vendono cialis senza ricetta – top farmacia online
farmaci senza ricetta elenco: avanafil prezzo – farmacia online migliore
https://www.samsungmobilepress.com/fs/?keyword=Veb+sayt%2C+i%C5%9F+%C3%BCnvan%C4%B1+288365.com+Apple+iOS+versiyas%C4%B1+%28tapmaq+daha+asand%C4%B1r+288365+futbol%2C+b%C3%BCt%C3%BCn+idman+n%C3%B6vl%C9%99ri%29+Android+versiyas%C4%B1+288365.com+%5BURL+kopyalay%C4%B1n%3A+guest.link%2FCbv+%5D+cari%2C+alternativ+link+%5BURL+kopyalay%C4%B1n%3A+guest.link%2FCbv+%5D
farmaci senza ricetta elenco: Tadalafil prezzo – top farmacia online
https://www.samsungmobilepress.com/fs/?keyword=Spletna+stran%2C+poslovni+naslov+288365.com+Apple+iOS+razli%C4%8Dica+%28la%C5%BEje+najti+288365+nogomet%2C+vsi+%C5%A1porti%29+Android+razli%C4%8Dica+288365.com+%5BKopiraj+URL%3A+guest.link%2FCbv+%5D+Trenutna%2C+alternativna+povezava+%5BKopiraj+URL%3A+guest.link%2FCbv+%5D
farmacie online sicure [url=http://kamagrait.club/#]kamagra[/url] farmaci senza ricetta elenco
При регистрации на сайте 1xBet вы можете воспользоваться только одним промокодом, который является действительным. Используя этот промокод, вы получите бонус до 32500 рублей. где взять промокод на 1xbet Важно отметить, что все остальные промокоды не являются действительными и не предоставляют такого же бонуса.
При регистрации на сайте 1xBet вы можете воспользоваться только одним промокодом, который является действительным. Используя этот промокод, вы получите бонус до 32500 рублей. 1xbet промокод при регистрации на сегодня Важно отметить, что все остальные промокоды не являются действительными и не предоставляют такого же бонуса.
farmacie online autorizzate elenco: Cialis senza ricetta – farmacie on line spedizione gratuita
Ремонт телефонов, ноутбуков, планшетов и другой техники https://remont-telefonov-moskva.ru/
viagra acquisto in contrassegno in italia: viagra senza ricetta – viagra originale in 24 ore contrassegno
ремонт трубок автокондиционеров в Рассказово дешево!
диагностика заправка кондиционера автомобиля в Покрове дешево!
АВТОРИЗОВАННЫЙ СЕРВИСНЫЙ ЦЕНТР
РЕМОНТ КОМПРЕССОРА В ТЕЧЕНИИ ДНЯ
ГАРАНТИЯ НА ВСЕ РАБОТЫ 1 ГОД
заправка обслуживание автокондиционеров в Угличе доступно!
boomer-avto.ru
Although Mostbet operates under an official international license, the official website of the bookmaker is sometimes blocked by Azerbaijani Internet providers https://getlinks.boards.net/thread/803/mostbet-ihl-en
Sun52
Sun52
Although Mostbet operates under an official international license, the official website of the bookmaker is sometimes blocked by Azerbaijani Internet providers http://forum.proslecny.cz/viewtopic.php?f=38&t=1994
https://s1.moresliv.biz/
farmacia online migliore: Tadalafil prezzo – acquisto farmaci con ricetta
purchase zithromax azithromycin 250mg price order gabapentin 800mg online
comprare farmaci online con ricetta: farmacie online affidabili – farmacie online sicure
farmacie online autorizzate elenco: Cialis senza ricetta – acquisto farmaci con ricetta
[url=http://pharmacyonline.cfd/]indianpharmacy com[/url]
Лингвистический центр YES предлагает вам открыть для себя новые языки или повысить свой уровень владения ими курсы английского языка Мы открываем перспективы для учебы и работы за границей.
farmacia online: kamagra oral jelly – comprare farmaci online con ricetta
Лингвистический центр YES предлагает вам открыть для себя новые языки или повысить свой уровень владения ими разговорный английский для детей Мы открываем перспективы для учебы и работы за границей.
farmacia online piГ№ conveniente [url=http://tadalafilit.store/#]Farmacie a milano che vendono cialis senza ricetta[/url] comprare farmaci online con ricetta
viagra generico recensioni: pillole per erezione immediata – viagra cosa serve
legal internet gambling united states
online casinos that accept prepaid visas
best sign up bonus bingo [url=https://trusteecasinos2024.com/]casino bets internet[/url] online craps game for mac online las vegas casino virtual gambling online
policy on gambling
https://centralasia.media/search/?place=canews-right&query=%EC%9B%B9+%EC%82%AC%EC%9D%B4%ED%8A%B8%2C%ED%9A%8C%EC%82%AC+%EC%A3%BC%EC%86%8C+288365.com+%EC%95%A0%ED%94%8C+%EC%9D%B4%EC%98%A4%EC%8A%A4+%EB%B2%84%EC%A0%84%28%EC%89%BD%EA%B2%8C+288365+%EC%B6%95%EA%B5%AC%EB%A5%BC+%EC%B0%BE%EC%9D%84+%EC%88%98%2C%EB%AA%A8%EB%93%A0+%EC%8A%A4%ED%8F%AC%EC%B8%A0%29%EC%95%88%EB%93%9C%EB%A1%9C%EC%9D%B4%EB%93%9C+%EB%B2%84%EC%A0%84+288365.com+%5B%EB%B3%B5%EC%82%AC%3A+guest.link%2FCbv+%5D+%ED%98%84%EC%9E%AC%2C%EB%8C%80%EC%B2%B4+%EB%A7%81%ED%81%AC+%5B%EB%B3%B5%EC%82%AC%3A+guest.link%2FCbv+%5D
https://search.danawa.com/dsearch.php?query=Web+sitesi%2C+i%C5%9F+adresi+288365.com+Apple+iOS+s%C3%BCr%C3%BCm%C3%BC+%28288365+futbolu%2C+t%C3%BCm+sporlar%C4%B1+bulmak+daha+kolay%29+Android+s%C3%BCr%C3%BCm%C3%BC+288365.com+%5BURL%27yi+kopyala%3A+guest.link%2FCbv+%5D+G%C3%BCncel%2C+alternatif+ba%C4%9Flant%C4%B1+%5BURL%27yi+kopyala%3A+guest.link%2FCbv+%5D&tab=main
[url=https://vardenafil.directory/]vardenafil tablet[/url]
comprare farmaci online all’estero: Farmacie a roma che vendono cialis senza ricetta – migliori farmacie online 2023
[url=http://zithromax.cyou/]buy azithromycin online uk[/url]
http://sildenafilit.bid/# pillole per erezione in farmacia senza ricetta
viagra generico recensioni: alternativa al viagra senza ricetta in farmacia – viagra 50 mg prezzo in farmacia
farmacie on line spedizione gratuita: kamagra oral jelly – farmacie on line spedizione gratuita
ЧИСТКА И РЕМОНТ КОЛОДЦЕВ ЗА 1 ДЕНЬ С ВЫЕЗДОМ от 4000 руб.
kolodec-vologda.ru Частный мастер по чистке колодцев в Московской области
чистка и ремонт колодца цена
Выезжаю по всем районам Московской области
Выезд в пределах 150 км от МКАД. Привожу все необходимое оборудование с собой.
Профессиональная чистка и ремонт колодцев
Замена колец колодца
ЧИСТКА И РЕМОНТ КОЛОДЦЕВ ЗА 1 ДЕНЬ С ВЫЕЗДОМ от 4000 руб.
kolodec-vologda.ru Частный мастер по чистке колодцев в Московской области
стоит ли углублять колодец
Выезжаю по всем районам Московской области
Выезд в пределах 150 км от МКАД. Привожу все необходимое оборудование с собой.
Профессиональная чистка и ремонт колодцев
Замена колец колодца
https://vardenafilo.icu/# farmacia online
термопанель фасадная купить https://klinkerprom13.ru/
https://kamagraes.site/# farmacia envГos internacionales
[url=http://doxycycline.directory/]where can you buy doxycycline[/url]
farmacias online seguras en espaГ±a [url=http://farmacia.best/#]farmacia online barata y fiable[/url] farmacias baratas online envГo gratis
O Cassino fresh cassino esta ganhando popularidade e se esforca para fornecer apenas servicos de alta qualidade.
viagra online cerca de zaragoza: comprar viagra contrareembolso 48 horas – viagra online cerca de toledo
O Cassino vavada gaming esta ganhando popularidade e se esforca para fornecer apenas servicos de alta qualidade.
http://tadalafilo.pro/# farmacias online baratas
https://kamagraes.site/# farmacia online barata
buy ursodiol 150mg online cheap zyban 150mg canada order cetirizine generic
http://sildenafilo.store/# se puede comprar sildenafil sin receta
http://farmacia.best/# farmacia online barata
В современном мире, где мобильные устройства и социальные сети стали неотъемлемой частью нашей жизни, все больше людей интересуются вопросом о том, читаем удаленные сообщения с кем их близкие, партнеры или друзья переписываются.
farmacia online madrid [url=https://tadalafilo.pro/#]comprar cialis original[/url] farmacias online seguras
http://vardenafilo.icu/# farmacia barata
[url=https://trazodone.cfd/]desyrel 50 mg tab[/url]
onbling casino payout
real online bingo money
online casino craps [url=https://trusteecasinos2024.com/]blackjack no real money[/url] high limit roulette online watch club keno draws online best online casino for u s players
online casinos us
http://sildenafilo.store/# viagra para hombre venta libre
https://kamagraes.site/# farmacias online seguras en españa
https://www.gettyimages.com/search/2/image?family=creative&phrase=Veb%20sayt,%20i%C5%9F%20%C3%BCnvan%C4%B1%20288365.com%20Apple%20iOS%20versiyas%C4%B1%20(tapmaq%20daha%20asand%C4%B1r%20288365%20futbol,%20b%C3%BCt%C3%BCn%20idman%20n%C3%B6vl%C9%99ri)%20Android%20versiyas%C4%B1%20288365.com%20%5BURL%20kopyalay%C4%B1n:%20guest.link%2FCbv%20%5D%20cari,%20alternativ%20link%20%5BURL%20kopyalay%C4%B1n:%20guest.link%2FCbv%20%5D
https://farmacia.best/# farmacias baratas online envÃo gratis
https://tadalafilo.pro/# farmacias baratas online envГo gratis
c88 bonus
C88: Elevate Your Gaming Experience with Unrivaled Bonuses and Endless Excitement!
Introduction:
Embark on an extraordinary gaming adventure with C88, a platform that redefines the boundaries of entertainment. Whether you’re a seasoned gamer or a newcomer, C88 promises an immersive experience characterized by thrilling features and exclusive bonuses. Let’s unravel the key elements that position C88 as the ultimate destination for gaming enthusiasts.
1. C88 Fun – Where Entertainment Knows No Bounds!
More than just a gaming platform, C88 Fun is an expedition waiting to be discovered. Boasting an intuitive interface and a diverse range of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player finds their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Warm Welcome for Newcomers!
Embark on your gaming journey with a warm embrace from C88. New members are welcomed with a 100% Welcome Bonus from JILI & Evo, doubling the excitement right from the start. This bonus acts as a catalyst for players to delve into the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Doubling the Excitement!
C88 believes in generously rewarding players. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By simply logging in daily, players not only bask in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those craving opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
Смотрите фильмы, сериалы, и мультфильмы из списка “Фильмы и сериалы” в нашем онлайн-кинотеатре смотреть кино
The Internet has revolutionized business strategies reputation house employee reviews
The Internet has revolutionized business strategies reputation house reviews
comprar viagra en espaГ±a envio urgente contrareembolso [url=https://sildenafilo.store/#]comprar viagra[/url] se puede comprar sildenafil sin receta
platinum play casino online
top online casino for mac
online casino vegas technology [url=https://trusteecasinos2024.com/]play craps for money[/url] online bingo usa sites directory gambling internet play blackjack online cash
sign up bonus palace
[url=http://baclofen.cfd/]baclofen 10mg tablets cost[/url]
электрокарнизы для штор цена https://prokarniz11.ru/
[url=https://trazodone.cfd/]trazodone 50 mg over the counter[/url]
http://tadalafilo.pro/# farmacias baratas online envÃo gratis
Эффективное воздухонепроницаемость обшивки — удобство и бережливость в приватном здании!
Согласитесь, ваш недвижимость заслуживает наилучшего! Изоляция обшивки – не только решение для сбережения на тепле, это вложение средств в комфорт и долголетие вашего помещения.
✨ Почему утепление с нами-мастерами?
Мастерство: Наши – квалифицированные специалисты. Наш коллектив заботимся о каждой детали, чтобы обеспечить вашему жилищу идеальное утепление.
Стоимость услуги воздухонепроницаемости: Мы ценим ваш финансовые ресурсы. [url=https://stroystandart-kirov.ru/]Утепление и обшивка дома стоимость[/url] – начиная от 1350 руб./кв.м. Это вложение в ваше удовлетворительное будущее!
Энергоэффективность: Забудьте о термических потерях! Наша технология не только сохраняют тепловую атмосферу, но и дарят вашему домовладению новый уровень теплосбережения энергоэффективности.
Сделайте свой домашний интерьер комфортным и стильным и привлекательным!
Подробнее на [url=https://stroystandart-kirov.ru/]интернет-ресурсе
[/url]
Не оставляйте свой коттедж на произвольное решение. Доверьтесь мастерам и создайте тепло вместе с нами!
https://kamagraes.site/# farmacia online
https://tadalafilo.pro/# farmacia online madrid
https://farmacia.best/# farmacias online seguras
farmacia online 24 horas: Comprar Levitra Sin Receta En Espana – farmacia envГos internacionales
[url=https://prednisolone.directory/]price of prednisolone 5mg in india[/url]
[url=https://ivermectin.guru/]price of ivermectin tablets[/url]
1. C88 Fun – Infinite Entertainment Beckons!
C88 Fun is not just a gaming platform; it’s a gateway to limitless entertainment. Featuring an intuitive interface and an eclectic game selection, C88 Fun caters to every gaming preference. From timeless classics to cutting-edge releases, C88 Fun ensures every player discovers their personal gaming haven.
2. JILI & Evo 100% Welcome Bonus – A Grand Welcome Awaits!
Embark on your gaming journey with a grand welcome from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the thrill from the get-go. This bonus acts as a springboard for players to explore the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
Generosity is a cornerstone at C88. With the “First Deposit Get 2X Bonus” offer, players revel in double the fun on their initial deposit. This promotion enhances the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Glory!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency reigns supreme at C88. By simply logging in daily, players not only savor the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those hungry for opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Spread the Joy!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
How much do negative reviews affect the reputation, figures, and income of a business reputation house serm
farmacia barata [url=https://farmacia.best/#]farmacia online envio gratis murcia[/url] farmacia barata
atomoxetine tablet order zoloft 100mg for sale buy zoloft 50mg without prescription
monthly calendar
[url=https://metformin.cfd/]metformin capsule[/url]
https://kamagraes.site/# farmacia online madrid
http://sildenafilo.store/# comprar sildenafilo cinfa 100 mg espaГ±a
[url=http://tadalafil.cfd/]buy cialis wholesale[/url]
карнизы электроуправляемые https://prokarniz19.ru/
[url=https://toradol.cfd/]over the counter toradol[/url]
[url=http://lisinopril.best/]lisinopril 2.5 mg cost[/url]
best onlijne casino bonus
best online casinos in the world
gambling internet union western [url=https://trusteecasinos2024.com/]casino game craps[/url] illinois online casino online bingo for united states players play blackjack online for money
online games using real money
pg 54สล็อตออนไลน์ แจกโปรฯดี เล่นเกมพร้อมเครดิตฟรี ได้กำไรไม่ยั้งแบบจัดเต็ม เล่นเกมสล็อตออนไลน์ แบบคุ้มๆได้เงินจนถึงมั่งมีได้ เกม PG ออนไลน์ที่ให้ได้มากกว่าที่อื่นๆ
farmacia online barata [url=https://farmacia.best/#]farmacia online envio gratis[/url] farmacia online 24 horas
https://vardenafilo.icu/# farmacias online seguras en españa
[url=http://amoxicillin.boutique/]amoxicillin tablets 400mg[/url]
http://sildenafilo.store/# viagra online cerca de bilbao
lasix drug ventolin 4mg brand buy ventolin inhalator generic
http://kamagraes.site/# farmacia online envÃo gratis
https://sildenafilo.store/# sildenafilo cinfa 100 mg precio farmacia
[url=https://neurontin.cyou/]gabapentin pharmacy[/url]
[url=https://lexapro.cfd/]lexapro prescription coupon[/url]
[url=https://augmentin.best/]5000 mg amoxicillin[/url]
http://sildenafilo.store/# sildenafilo 100mg precio farmacia
https://farmacia.best/# farmacia online internacional
https://farmacia.best/# farmacia online barata
https://tadalafilo.pro/# farmacia barata
Актуальные объявления о покупке и продаже квартир на вторичном рынке недвижимости uy olishga yordam частные объявления о продаже квартир.
real cash slot machines
new online rand casinos
online blackjack play with real money [url=https://trusteecasinos2024.com/]online casino games slot machine[/url] best craps on line play with others online casino reputable online casino australia
casino games for real money online
[url=https://propranolol.cfd/]inderal medicine[/url]
this site is an ideal platform for creating combined soccer bets
https://tetrasky.ru/
https://tadalafilo.pro/# farmacias baratas online envÃo gratis
http://sildenafilo.store/# farmacia gibraltar online viagra
farmacia online barata: comprar kamagra en espana – п»їfarmacia online
Перечень товаров, не требующих сертификации. Не существует единого утвержденного списка товаров, не требующих сертификации Какая продукция не подлежит сертификации Это было сказано ранее. По мере изучения актуального списка вы не найдете вашей продукции среди заявленных категорий – это означает, что единственным документом для реализации или прохождения таможенного контроля является отказное письмо.
The magical world of slot machines: Book of Mostbet and Joker Stoker http://gununnebzi.az/index.php?subaction=userinfo&user=ozideq
http://tadalafilo.pro/# farmacia envÃos internacionales
Перечень товаров, не требующих сертификации. Не существует единого утвержденного списка товаров, не требующих сертификации Список товаров не подлежащих сертификации Это было сказано ранее. По мере изучения актуального списка вы не найдете вашей продукции среди заявленных категорий – это означает, что единственным документом для реализации или прохождения таможенного контроля является отказное письмо.
The magical world of slot machines: Book of Mostbet and Joker Stoker http://soarboatingclub.co.uk/forum/viewtopic.php?f=18&t=538608&p=580090&sid=882e8410c7909f4e3f1b53a89a142d36#p580090
http://kamagraes.site/# farmacia online envГo gratis
https://sildenafilo.store/# sildenafilo 100mg precio españa
[url=http://synthroid.directory/]synthroid 500 mcg[/url]
http://vardenafilo.icu/# farmacias baratas online envÃo gratis
double down in blackjack
newest online casinos 2014
play internet baccarat [url=https://trusteecasinos2024.com/]online casino mit paypal einzahlung[/url] deposit rtg casino bonus cool cat casino signup bonus online casino paypal
online casino android real money
farmacias online baratas: Comprar Levitra Sin Receta En Espana – farmacias baratas online envГo gratis
[url=https://fildena.cfd/]cheap fildena[/url]
Поиск по базе сливов, закрытым каналам телеграм. Найти интимки человека по ссылке на телеграм аккаунт бот по поиску интим фото
http://farmacia.best/# farmacia online internacional
Максимальная эффективность в арбитраже: выбирайте виртуальные карты от Webscard виртуальные карты Mastercard
Wow, fantastic blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your web site is fantastic, as well as the content!
online real casinos
[url=http://trazodone.cfd/]generic for desyrel[/url]
[url=https://neurontin.cfd/]neurontin 1800 mg[/url]
http://vardenafilo.icu/# farmacia 24h
http://tadalafilo.pro/# farmacia online envÃo gratis
http://vardenafilo.icu/# farmacia online madrid
farmacia barata: farmacia 24 horas – farmacia 24h
In the ever-evolving world of digital technology, it has become increasingly important for individuals and businesses to safeguard their online security http://littleyaksa.yodev.net/bbs/board.php?bo_table=free&wr_id=3287313
http://vardenafilo.icu/# farmacias online baratas
Promo code this site favorably increased my deposit
https://jobsmart24.com/
When the site is blocked, I go through a working this site mirror
https://jobsmart24.com/
[url=https://fluoxetine.cyou/]fluoxetine 90 mg coupon[/url]
order generic combivent zyvox order online buy linezolid 600mg without prescription
Viagra gГ©nГ©rique pas cher livraison rapide: Viagra sans ordonnance 24h – Viagra homme prix en pharmacie
Viagra vente libre allemagne [url=http://viagrasansordonnance.store/#]Viagra gГ©nГ©rique sans ordonnance en pharmacie[/url] Viagra sans ordonnance 24h Amazon
farmacias baratas online envГo gratis: mejores farmacias online – farmacias online baratas
https://cialissansordonnance.pro/# acheter medicament a l etranger sans ordonnance
[url=https://phenergan.cyou/]phenergan price[/url]
https://kamagrafr.icu/# acheter médicaments à l’étranger
Pharmacie en ligne pas cher: acheter kamagra site fiable – pharmacie ouverte
http://pharmacieenligne.guru/# Acheter médicaments sans ordonnance sur internet
Pharmacie en ligne livraison gratuite [url=http://cialissansordonnance.pro/#]Pharmacie en ligne pas cher[/url] Pharmacie en ligne France
[url=https://vardenafil.directory/]lowest price levitra[/url]
https://kamagrafr.icu/# pharmacie en ligne
п»їfarmacia online: farmacia online barata y fiable – farmacia online madrid
https://levitrafr.life/# Pharmacie en ligne sans ordonnance
[url=https://prozac.cfd/]prozac 80 mg[/url]
https://pharmacieenligne.guru/# Pharmacie en ligne livraison 24h
http://pharmacieenligne.guru/# Acheter médicaments sans ordonnance sur internet
hoki 1881
https://www.familyspace.ru/user32839533
Pharmacie en ligne fiable: tadalafil sans ordonnance – Pharmacie en ligne livraison gratuite
http://levitrafr.life/# Pharmacie en ligne pas cher
Pharmacie en ligne France [url=http://pharmacieenligne.guru/#]pharmacie ouverte[/url] Pharmacie en ligne fiable
https://kamagrafr.icu/# pharmacie ouverte 24/24
Как сохранить результаты косметологии
косметология москва [url=http://www.epilstudio.ru#косметология-москва]http://www.epilstudio.ru[/url].
http://kamagrafr.icu/# pharmacie en ligne
[url=http://albuterol.guru/]ventolin pharmacy singapore[/url]
ренессанс кредитная карта оформить https://займы-все.рф/creditniekarti/razumnaya-145-dnej-bez-proczentov-na-vsyo/
https://kamagrafr.icu/# pharmacie ouverte
[url=http://effexor.cyou/]effexor generic[/url]
farmacia online internacional: farmacia 24 horas – farmacia barata
Pharmacie en ligne pas cher: tadalafil – Pharmacie en ligne livraison gratuite
SavdoUyi.uz – это онлайн-платформа, которая помогает людям находить работу, продавать и покупать товары и услуги Видеосъемка и фотосессии
Заказать пластиковые окна из немецкого профиля VEKA. Выгодные цены и предложения на покупку и установку пластиковых ПВХ окон и дверей установка окон пвх купить
nateglinide 120 mg ca buy captopril 25mg generic atacand 16mg usa
The service quality at this site is outstanding, offering attractive bonuses
https://jobsmart24.com/
I recommend this site to everyone who wants to make stable money on betting
https://jobsmart24.com/
[url=http://synthroid.directory/]synthroid medication price[/url]
http://levitrafr.life/# Pharmacie en ligne livraison gratuite
Арбалет – это мощное оружие, позволяющее охотиться на различных животных с большой дистанции http://www.korea-pan.com/bbs/board.php?bo_table=free&wr_id=940130
[url=https://synthroid.cyou/]best price for synthroid 75 mcg[/url]
levitra 20mg cost how to get zanaflex without a prescription buy plaquenil online cheap
Арбалет – это мощное оружие, позволяющее охотиться на различных животных с большой дистанции http://www.hcceskalipa.cz/bazarek/okhotnichi-aksessuary-dlya-arbaleta-nuzhny-li-oni-i-kak-ikh-vybrat
https://viagrasansordonnance.store/# Viagra prix pharmacie paris
кабинет займ экспресс https://займы-все.рф/zaimy/zajm-ekspress/
[url=http://tadalafil.cfd/]generic tadalafil us[/url]
http://viagrakaufen.store/# Viagra Preis Schwarzmarkt
Эффективное утепление наружных стен — прекрасие и бюджетность в домашнем домовладении!
Согласитесь, ваш домовладение заслуживает высококачественного! Изоляция обшивки – не всего лишь решение для сбережения на тепле, это инвестиция в благополучие и стойкость вашего помещения.
? Почему теплоизоляция с нами-профессионалами?
Мастерство: Наша команда – профессионалы своего дела. Наш коллектив заботимся о всей, чтобы обеспечить вашему дому идеальное тепловая изоляция.
Стоимость теплосбережения: Мы ценим ваш финансовые ресурсы. [url=https://stroystandart-kirov.ru/]Утепление фасадов под ключ[/url] – начиная от 1350 руб./кв.м. Это вложение капитала в ваше удовлетворительное будущее!
Энергосберегающие решения: Забудьте о термопотерях! Наш подход не только сохраняют тепловое комфорта, но и дарят вашему дому новый уровень энергоэффективности.
Создайте свой дом тепловым и привлекательным!
Подробнее на [url=https://stroystandart-kirov.ru/]интернет-ресурсе
[/url]
Не передавайте на произвол судьбы свой дом на произвольное решение. Доверьтесь нашей команде и создайте уют вместе с нами-специалистами!
[url=https://wellbutrin.cfd/]wellbutrin sr generic[/url]
gГјnstige online apotheke [url=https://apotheke.company/#]apotheke online versandkostenfrei[/url] versandapotheke deutschland
[url=http://finasteride.digital/]generic propecia usa[/url]
http://viagrakaufen.store/# Viagra kaufen gГјnstig Deutschland
http://potenzmittel.men/# п»їonline apotheke
carbamazepine 400mg us order ciplox 500mg generic brand lincomycin 500 mg
[url=https://vardenafil.directory/]levitra generic us[/url]
The this site signup bonus promo code came in handy
https://jobsmart24.com/
Great looking web site. Think you did a bunch of your own html coding.
https://www.google.hu/url?q=https://comprarcialis5mg.com
Что лучше и дешевле выбрать в 2023 игровой ноутбук или игровой компьютер nintendo jocuri
My recommendation for sports betting is this site
https://jobsmart24.com/
online apotheke versandkostenfrei [url=http://potenzmittel.men/#]potenzmittel ohne rezept[/url] online apotheke preisvergleich
http://apotheke.company/# versandapotheke deutschland
Шкафы-купе – купить недорогие шкафы-купе в комнату от производителя по цене от 850 руб шкаф купе на заказ классика
Шкафы-купе – купить недорогие шкафы-купе в комнату от производителя по цене от 850 руб шкаф-купе подвесная дверь купить от производителя
[url=http://trazodone.best/]trazodone 100[/url]
online-apotheken: kamagra oral jelly – gГјnstige online apotheke
Стоимость услуг адвоката по уголовным, гражданским и административным делам услуги адвоката
Вместе для чистоты и удобства
купить пластиковые трубы оптом [url=https://ukrtruba.com.ua/]https://ukrtruba.com.ua/[/url].
versandapotheke versandkostenfrei [url=http://potenzmittel.men/#]online apotheke gГјnstig[/url] online apotheke deutschland
[url=https://cazinouri-online-in-romania.com/]cazinouri-online-in-romania.com/[/url]
10 most qualified online casinos benefit of legitimate banknotes: best 10 ranking 2023.
cazinouri-online-in-romania.com/
https://kamagrakaufen.top/# online apotheke gГјnstig
SEOsprint — уникальное место! Оно объединяет самых разных и интересных людей seosprint
Куплю Эриведж в Озерске Сорафениб натив 200 мг дорого в любом городе. Продать #Мавирет, Сорафениб натив 200 мг, Ервой, Капрелса 300 мг у вас дорого в Карачаевске.
Продать лекарства с рук в Альметьевске. Продать лекарства с рук в Кизеле выгодно
Мы осуществляем скупку лекарств безопасно и на выгодных условиях;
Принимаем широкий перечень препаратов;
Предлагаем выгодные цены.
Продать лекарства с рук в Лениногорске. Продать лекарства с рук в Семилуках. Продать лекарства с рук.
Куплю остатки препаратов у аптекдорого Герцептин 440 мг
Куплю лекарства выгодно
[url=http://budesonide.cyou/]budesonide 3 mg capsule cost[/url]
https://mexicanpharmacy.cheap/# mexican online pharmacies prescription drugs
mexican border pharmacies shipping to usa mexican mail order pharmacies mexican online pharmacies prescription drugs
mexico drug stores pharmacies [url=http://mexicanpharmacy.cheap/#]mexican rx online[/url] reputable mexican pharmacies online
[url=https://augmentin.cfd/]amoxicillin brand name[/url]
buying prescription drugs in mexico online mexico pharmacies prescription drugs mexican rx online
mexican pharmaceuticals online best mexican online pharmacies mexican border pharmacies shipping to usa
слотозал официальный сайт http://slotozal-zerkalo.ru/
medicine in mexico pharmacies mexican mail order pharmacies mexican pharmaceuticals online
слотозал регистрация http://slotozal-official.ru/
mexican rx online mexico drug stores pharmacies purple pharmacy mexico price list
mexican online pharmacies prescription drugs best online pharmacies in mexico pharmacies in mexico that ship to usa
Куплю Мавирет в Певеке Авегра дорого в любом городе. Продать #Кстанди, Привиджен, Кобаметикс, Вайдаза у вас дорого в Кяхте.
Продать лекарства с рук в Николаевске. Продать лекарства с рук в Красном Яре дорого
Мы осуществляем скупку лекарств безопасно и на выгодных условиях;
Принимаем широкий перечень препаратов;
Предлагаем выгодные цены.
Продать лекарства с рук в Железнодорожном. Продать лекарства с рук в Плесе. Продать лекарства с рук.
Куплю остатки лекарств у аптеквыгодно Авегра
Продать остатки лекарств дорого
п»їbest mexican online pharmacies [url=http://mexicanpharmacy.cheap/#]medication from mexico pharmacy[/url] buying from online mexican pharmacy
mexican pharmaceuticals online reputable mexican pharmacies online mexican drugstore online
Odbierz prezent darmowe 100zl za rejestracje. Nowe zwyciestwa czekaja!
[url=http://propranolol.cfd/]inderal 20 mg 1mg[/url]
medication from mexico pharmacy [url=http://mexicanpharmacy.cheap/#]buying from online mexican pharmacy[/url] purple pharmacy mexico price list
medicine in mexico pharmacies mexico pharmacies prescription drugs medicine in mexico pharmacies
https://mexicanpharmacy.cheap/# purple pharmacy mexico price list
I always find the current this site mirror in the site
https://maxbetasia88.net/
Разовая чистка снега с крыш и абонентское обслуживание в зимний период очистка крыш абонентское обслуживание
http://mexicanpharmacy.cheap/# mexican drugstore online
mexico pharmacies prescription drugs mexican border pharmacies shipping to usa buying from online mexican pharmacy
mexican border pharmacies shipping to usa purple pharmacy mexico price list mexican rx online
medicine in mexico pharmacies mexico pharmacies prescription drugs best online pharmacies in mexico
Полипропиленовая труба для системы отопления
Промышленная труба из пластика для водоснабжения
Гофрированная трубка для кабельного канала
Дренажная пластиковая труба для водоотведения
Антикоррозийная пластиковая труба для теплосетей
Осветительная трубка из пластика для электропроводки
Пластмассовая труба для системы заземления
Гофрированная пластиковая трубка для кондиционеров
Подводящая труба из пластика для химической промышленности
Автономная пластиковая труба для дождевой канавы
Пылеуловительная труба из пластика для вентиляции
Сателлитарная пластиковая труба для теплицы
Групповая трубка из пластика для поливочной системы
Капиллярная трубка для упаковки продуктов
Газовая пластиковая труба для газификации
Уличная трубка из пластика для дренажной системы
Радиальная пластиковая труба для пассажирских лифтов
Термостойкая пластиковая трубка для косметики
Безрельсовая трубка из пластика для транспортировки грузов
Прозрачная пластиковая трубка для светодиодных лент
полиэтиленовые трубы пнд [url=https://www.truba-radiator.com.ua/]https://www.truba-radiator.com.ua/[/url].
mexican pharmaceuticals online mexico drug stores pharmacies medicine in mexico pharmacies
люстра на штанге купить
[url=http://www.google.gg/url?q=https://lu17.ru]http://google.com.ai/url?q=https://lu17.ru[/url]
According to Alina Monosova, the transfer from Premier to MESH was due to transport difficulties – alina monosova psychology it took almost two hours to get there in one direction.
https://mexicanpharmacy.cheap/# mexican pharmaceuticals online
According to Alina Monosova, the transfer from Premier to MESH was due to transport difficulties – alina monosova it took almost two hours to get there in one direction.
электро самокат
buy medicines online in india [url=http://indiapharmacy.guru/#]indian pharmacies safe[/url] Online medicine order indiapharmacy.guru
Пошаговые рецепты приготовления блюд и напитков, выпечки с подробными инструкциями для повара. Гастроном невероятных вкусных рецептур, чтобы готовить дома всегда вкусно! Еда на каждый день!
https://indiapharmacy.pro/# indian pharmacy paypal indiapharmacy.pro
male ed pills natural remedies for ed – erectile dysfunction drug edpills.tech
http://indiapharmacy.guru/# india pharmacy mail order indiapharmacy.guru
юридическая помощь бесплатно для всех вопросов о законодательстве|юридическое обслуживание бесплатно на разные темы
Юридическая консультация бесплатно для граждан и организаций по разнообразным вопросам Получи бесплатную юридическую консультацию от бесплатный совет юриста: надежное решение юридических проблем|Получи безвозмездную консультирование от квалифицированных юристов по любым проблемам
Консультация юриста бесплатно: получи ответы на юридические вопросы
юридическая консультация бесплатно по телефону [url=konsultaciya-yurista-499.ru]konsultaciya-yurista-499.ru[/url].
vipps canadian pharmacy [url=http://canadiandrugs.tech/#]canadian drug stores[/url] canadian pharmacy ltd canadiandrugs.tech
[url=http://tadalafil.cfd/]where can i buy cialis 20mg[/url]
Andrey Monosov had a long way to go to start his own business andrey monosov
http://indiapharmacy.guru/# pharmacy website india indiapharmacy.guru
https://indiapharmacy.guru/# cheapest online pharmacy india indiapharmacy.guru
cabergoline 0.5mg generic dostinex us buy priligy 30mg generic
top online pharmacy india [url=https://indiapharmacy.guru/#]indian pharmacy[/url] Online medicine home delivery indiapharmacy.guru
canadian pharmacy com buy drugs from canada – cross border pharmacy canada canadiandrugs.tech
ed treatment drugs best ed pills online – best ed pill edpills.tech
https://edpills.tech/# best pill for ed edpills.tech
uTorrent – госстройэкспертиза один из самых популярных загрузчиков для скачивания торрентов на сегодняшний день.
https://canadiandrugs.tech/# legitimate canadian pharmacy online canadiandrugs.tech
depo-medrol without a doctor prescription how to get aristocort without a prescription purchase clarinex online
https://edpills.tech/# buy erection pills edpills.tech
pharmacy canadian [url=http://canadiandrugs.tech/#]legal canadian pharmacy online[/url] best canadian online pharmacy reviews canadiandrugs.tech
https://canadiandrugs.tech/# safe reliable canadian pharmacy canadiandrugs.tech
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
reputable canadian pharmacy canadian compounding pharmacy – cheap canadian pharmacy online canadiandrugs.tech
http://edpills.tech/# ed pills gnc edpills.tech
[url=https://prednisone.cyou/]prednisone 5 mg buy online[/url]
http://edpills.tech/# medication for ed edpills.tech
オンラインカジノ
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
[url=https://atarax.cyou/]atarax 50[/url]
Посоветуйте VPS
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость Интернет-соединения – еще один ключевой фактор для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с, гарантируя быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Воспользуйтесь нашим предложением VPS/VDS серверов и обеспечьте стабильность и производительность вашего проекта. Посоветуйте VPS – ваш путь к успешному онлайн-присутствию!
buy misoprostol 200mcg diltiazem where to buy purchase diltiazem for sale
Получите профессиональную юридическую помощь бесплатно
юридическая консультация бесплатно онлайн круглосуточно по телефону [url=http://www.lawyer-uslugi.ru]http://www.lawyer-uslugi.ru[/url].
Бег на беговой дорожке: разбираем мифы
беговая дорожка для дома купить [url=https://begovye-dorozhki.ks.ua]https://begovye-dorozhki.ks.ua[/url].
http://indiapharmacy.guru/# pharmacy website india indiapharmacy.guru
http://edpills.tech/# pills erectile dysfunction edpills.tech
люстры недорого интернет магазин москва [url=https://www.myagkie-paneli11.ru]https://www.myagkie-paneli11.ru[/url].
https://canadiandrugs.tech/# canadian pharmacy canadiandrugs.tech
india pharmacy mail order mail order pharmacy india – indianpharmacy com indiapharmacy.guru
best ed pills online medication for ed – erectile dysfunction medicines edpills.tech
https://canadiandrugs.tech/# safe reliable canadian pharmacy canadiandrugs.tech
http://canadiandrugs.tech/# canada pharmacy online legit canadiandrugs.tech
[url=http://augmentin.cfd/]buy amoxicillin 500mg uk[/url]
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Оптимальная Настройка: Включение Аппаратной Виртуализации
При обсуждении виртуальных серверов (VPS/VDS) и дедикатед серверов, важно также уделить внимание оптимальной настройке, включая аппаратную виртуализацию. Этот важный аспект может значительно повлиять на производительность вашего сервера.
Высокоскоростной Интернет: До 1000 Мбит/с
http://indiapharmacy.guru/# Online medicine home delivery indiapharmacy.guru
[url=https://zoloft.cfd/]zoloft price generic[/url]
medication for ed [url=http://edpills.tech/#]best ed medication[/url] ed medications list edpills.tech
Дедикатед Серверы
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Высокоскоростной Интернет: До 1000 Мбит/с
[url=https://vermox.cfd/]medicine vermox[/url]
[url=https://hydroxychloroquine.guru/]plaquenil 200 mg tablet[/url]
Поднимайте ставки и выигрывайте крупные суммы с онлайн-казино Плейфортуна https://play-fortuna-slotg1l6.com/ru
[url=https://finasteride.cyou/]finasteride[/url]
https://edpills.tech/# ed remedies edpills.tech
ed pills gnc cheapest ed pills – best ed pill edpills.tech
https://canadapharmacy.guru/# best canadian pharmacy to order from canadapharmacy.guru
http://canadiandrugs.tech/# canadian drugs canadiandrugs.tech
Mostbet combines sports betting and gambling entertainment on one platform https://linktr.ee/mostbet08
canada pharmacy [url=http://canadiandrugs.tech/#]canadian pharmacy meds review[/url] canadian pharmacy prices canadiandrugs.tech
http://canadiandrugs.tech/# canadian pharmacies compare canadiandrugs.tech
Mostbet combines sports betting and gambling entertainment on one platform https://www.openstreetmap.org/user/mostbet08
order zovirax 400mg pills buy rosuvastatin cheap order generic rosuvastatin 10mg
[url=http://atarax.cyou/]buy atarax online canada[/url]
ciprofloxacin mail online: where can i buy cipro online – where can i buy cipro online
трубные фланцы в интернет-магазине
Фланцы для труб: хранение и транспортировка
Фланцы для труб недорого [url=https://flancy-msk.ru/]https://flancy-msk.ru/[/url].
[url=http://retina.cfd/]tretinoin generic cost[/url]
Optimize your app or game by the best free App Store Optimization Tools to Enhance Conversion Optimization
Optimize your app or game by the best free App Store Optimization Top Antivirus Software
purchase sporanox for sale buy tinidazole 500mg online order tindamax 500mg
Аренда виртуального сервера vps
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Аренда виртуального сервера (VPS): Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
amoxicillin where to get: buy amoxicillin 500mg online – amoxicillin generic brand
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
[url=https://albuterol.cyou/]cost of ventolin in usa[/url]
prednisone 54899 [url=https://prednisone.bid/#]order prednisone[/url] apo prednisone
Стройматериалы в наличии в интернет-магазине и розничных магазинах гидрошпонки купить в москве в Москве с доставкой.
[url=https://amoxicillin.boutique/]amoxil pill[/url]
https://northeast.newschannelnebraska.com/story/50266910/how-to-promote-youtube-channels-with-youtube-view-bots
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
paxlovid buy: Paxlovid buy online – paxlovid buy
[url=https://diflucan.cyou/]can i buy fluconazole online[/url]
buying clomid without dr prescription: can i get cheap clomid prices – order clomid prices
[url=https://toradol.cfd/]toradol 10 mg tablet cost[/url]
prednisone cost us: generic over the counter prednisone – buy prednisone nz
https://ciprofloxacin.life/# buy cipro online without prescription
продвижение сайтов https://prodvijenie-saitov.md/
paxlovid buy: paxlovid – buy paxlovid online
zetia price order ezetimibe for sale tetracycline us
Надувные лодки ПВХ по низкой цене купить в интернет магазине лодка пакрафт купить
https://clomid.site/# buy cheap clomid without dr prescription
[url=http://accutane.cyou/]where to get accutane prescription[/url]
Надувные лодки ПВХ по низкой цене купить в интернет магазине купить надувную лодку пвх
buy clomid: cost of cheap clomid tablets – how to get clomid no prescription
[url=http://albuterol.guru/]combivent asthma[/url]
amoxicillin online purchase: amoxicillin canada price – can you buy amoxicillin uk
purchase olanzapine generic order zyprexa online cheap buy valsartan tablets
[url=http://sildenafil.cyou/]buy viagra for female online[/url]
paxlovid covid: paxlovid price – buy paxlovid online
Дешево заказать клетку для собаки
клетка для кошек и собак
Дешево Вольер для акиты
Здравствуйте, игроки на xbetegypt!
Насладитесь успеха на xbetegypt с премиум бонусами!
Наслаждайтесь азартом на этом казино каждый день!
Сделайте вашу игру на xbetegypt с нашими премиум предложениями!
Используйте свой шанс на xbetegypt и освойте самые многочисленные призы!
Достигайте своих целей с xbetegypt каждый день!
Становитесь частью нашего сообщества и получите больше денег!
Взгляните на мир с другой стороны с xbetegypt и получите все!
Наслаждайтесь играть на xbetegypt и зарабатывайте все больше выигрышей!
Отдыхайте от игры на xbetegypt и забирайте бонусы!
Раскройте свой потенциал игры на xbetegypt и получайте больших успехов!
Удивляйтесь от игры на xbetegypt и познавайте новые возможности каждый день!
Переходите на новый уровень игры и добивайтесь большими бонусами!
Погрузитесь в атмосферу победы с xbetegypt каждый день!
Играйте вместе с друзьями на xbetegypt и делимся большими выигрышами!
Улучшите свои навыки на xbetegypt и получите еще больше денег!
Покоряйте игры на xbetegypt и добивайтесь большие бонусы каждый день!
Освойте новые техники на xbetegypt и наслаждайтесь результатами!
Освойте играть на xbetegypt и забирайте больше денег каждый день!
Забирайте максимум удовольствия от игры на xbetegypt и получайте больше бонусов!
Download 1xbet in Arabic [url=https://www.1xbet-app-download-ar.com/]https://www.1xbet-app-download-ar.com/[/url].
https://prednisone.bid/# prednisone 2.5 mg price
Существуют определенные товары и категории товаров, которые подлежат обязательной сертификации перечень продукции не подлежащей обязательной сертификации
cost of generic clomid without prescription: can i buy cheap clomid without dr prescription – can i order generic clomid without a prescription
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
В современном мире онлайн-проекты нуждаются в надежных и производительных серверах для бесперебойной работы. И здесь на помощь приходят мощные дедики, которые обеспечивают и высокую производительность, и защищенность от атак DDoS. Компания “Название” предлагает VPS/VDS серверы, работающие как на Windows, так и на Linux, с доступом к накопителям SSD eMLC — это значительно улучшает работу и надежность сервера.
buy cipro cheap: buy ciprofloxacin over the counter – ciprofloxacin 500mg buy online
Каждый электрик устанавливает разные расценки на услуги, вы можете их сравнить и выбрать подходящие для себя аварийный вызов электрика
Каждый электрик устанавливает разные расценки на услуги, вы можете их сравнить и выбрать подходящие для себя электрик в Запорожье
Условия труда грузчиков
услуги грузчиков перевозки [url=http://gruzchikipogruzchik.ru/]http://gruzchikipogruzchik.ru/[/url].
https://satbayev.university/
[url=https://vermox.cyou/]vermox 500mg for sale[/url]
Выбирайте из лучших языковых лагерей 2024 английский летний лагерь рейтинг лагерей с отзывами, фото и описанием лагерей.
Выбирайте из лучших языковых лагерей 2024 детский лагерь языковой рейтинг лагерей с отзывами, фото и описанием лагерей.
Выбирайте и бронируйте бесплатно путевки в языковые детские лагеря языковой лагерь для детей
april calendar 2024
During this period of transition, Viktor Yevhenovich Ponomarchuk showed himself as a far-sighted leader, recognizing and using fresh opportunities in a changing environment виктор евгеньевич пономарчук
2024總統大選
antibiotics cipro [url=http://ciprofloxacin.life/#]purchase cipro[/url] buy cipro online usa
where can you buy amoxicillin over the counter: can i buy amoxicillin over the counter – amoxicillin 500mg price canada
buy generic ciprofloxacin: buy cipro online – ciprofloxacin mail online
Интернет магазин предлагает купить оптом и в розницу современное медицинское оборудование и технику для частных и государственных клиник медицинское оборудование в нижнем новгороде купить
http://clomid.site/# order cheap clomid now
In the field of oils and fats processing, Viktor stands out due to the harmonious combination of his interests and ViOil’s strategies виктор пономарчук vioil
In the field of oils and fats processing, Viktor stands out due to the harmonious combination of his interests and ViOil’s strategies виктор евгеньевич пономарчук
RG Casino
pills to clear acne accutane 40mg without prescription adult acne causes in female
[url=https://tadalafil.cfd/]cialis singapore[/url]
https://www.google.tm/url?q=https://www.coinsbar.net/ru/
дверь входная с зеркалом https://vhodnye-dveri-s-zerkalom77.ru/
[url=https://metformin.cfd/]can i buy metformin over the counter[/url]
[url=https://clomid.digital/]where to buy cheap clomid online[/url]
сериалы онлайн https://sys-con.tv/
[url=https://levitra.cfd/]vardenafil tablets 20 mg[/url]
Полный ассортимент для активного образа жизни
рекламные вывески [url=http://www.msk-naruzhnaya-reklama.ru]http://www.msk-naruzhnaya-reklama.ru[/url].
[url=https://vermox.cyou/]vermox 500mg tablet[/url]
[url=http://retina.cfd/]tretinoin 01[/url]
[url=https://finasteride.cyou/]cheapest propecia online uk[/url]
Дедик сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
prescription allergy medication without antihistamines purchase seroflo generic allergy over the counter drugs
Электрокарниз – удобство и стиль в одном
потолочный электрокарниз [url=prokarniz38.ru]prokarniz38.ru[/url].
brillx casino официальный мобильная версия
https://brillx-kazino.com
Погрузитесь в мир увлекательных игр и сорвите джекпот на сайте Brillx Казино. Наши игровые аппараты не просто уникальны, они воплощение невероятных приключений. От крупных выигрышей до захватывающих бонусных раундов, вас ждут неожиданные сюрпризы за каждым вращением барабанов.Предоставив широкий спектр игр и вариантов ставок, мы делаем ставку на то, что каждый игрок найдет что-то особенное для себя. Brillx Казино – это не просто место для азартных игр, это место, где рождаются легенды и судьбы переплетаются с риском.
[url=https://retina.cfd/]tretinoin cream 0.05[/url]
осоветуйте vps
Абузоустойчивый сервер для работы с Хрумером и GSA и различными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера VPS/VDS и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера VPS/VDS и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
https://addcity.ru/
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
[url=http://zoloft.cyou/]zoloft 150 mg[/url]
purchase cytotec [url=https://cytotec.icu/#]buy misoprostol over the counter[/url] buy cytotec in usa
Заказать любые виды сантехнических работ в Краснодаре Услуги сантехника в Краснодаре Низкие цены, быстрое оказание услуг, гарантии качества.
zithromax capsules 250mg: zithromax cost uk – zithromax tablets
[url=https://clomid.digital/]clomid 50 mg tablet price[/url]
https://cytotec.icu/# buy cytotec online fast delivery
[url=http://albuterol.cfd/]albuterol 25 mg[/url]
2024總統民調
[url=http://retina.cfd/]tretinoin 08[/url]
zithromax 600 mg tablets: zithromax generic price – buy zithromax online australia
https://nolvadex.fun/# dcis tamoxifen
buy cytotec over the counter [url=https://cytotec.icu/#]cytotec buy online usa[/url] buy cytotec pills
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
[url=https://phenergan.cyou/]cost of phenergan tablets[/url]
http://doxycyclinebestprice.pro/# where can i get doxycycline
lisinopril 5 mg tablet price in india: lisinopril brand name canada – lisinopril prescription
http://nolvadex.fun/# tamoxifen bone density
lisinopril generic drug: cost of lisinopril 40mg – zestril price in india
High-quality Minecraft servers – selected projects with video trailers and reviews from real players. We care about all our users serwery minecraft 1.8 1 beta
order cytotec online: purchase cytotec – buy cytotec pills online cheap
http://nolvadex.fun/# tamoxifen rash pictures
buy cytotec online [url=https://cytotec.icu/#]buy misoprostol over the counter[/url] cytotec online
технические двери https://texnicheskiedveri.ru/
Cytotec 200mcg price: cytotec pills buy online – buy cytotec over the counter
https://sury-iz-korana.ru/
http://cytotec.icu/# cytotec online
https://lisinoprilbestprice.store/# lisinopril 10 12.5 mg
buy doxycycline online uk: buy doxycycline cheap – doxycycline
best prescription sleep aids where to buy provigil without a prescription
最新民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
купить элитную жилую квартиру [url=https://nedvipro11.ru]https://nedvipro11.ru[/url].
Самые популярные хиты 2024 за сегодня. Ежедневное обновление. Самые горячие новинки из мира музыки Слушать музыку 2024
buy zithromax 1000 mg online: can i buy zithromax over the counter – zithromax capsules
canada ed drugs: canadian pharmacy tampa – northern pharmacy canada canadapharm.life
Наша бригада опытных специалистов проштудирована предложить вам новаторские подходы, которые не только обеспечат надежную оборону от мороза, но и преподнесут вашему домашнему пространству стильный вид.
Мы занимаемся с современными материалами, обеспечивая долгосрочный термин использования и отличные выходы. Утепление фронтонов – это не только сбережение на подогреве, но и трепет о природной среде. Энергоэффективные технологические решения, каковые мы применяем, способствуют не только твоему, но и сохранению природы.
Самое основное: [url=https://ppu-prof.ru/]Утепление стен снаружи цена за метр[/url] у нас составляет всего от 1250 рублей за квадратный метр! Это доступное решение, которое превратит ваш дом в истинный душевный уголок с минимальными затратами.
Наши работы – это не единственно утепление, это формирование поля, в где каждый деталь показывает ваш персональный стиль. Мы берем во внимание все ваши пожелания, чтобы преобразить ваш дом еще еще больше удобным и привлекательным.
Подробнее на [url=https://ppu-prof.ru/]веб-сайте[/url]
Не откладывайте труды о своем корпусе на потом! Обращайтесь к спецам, и мы сделаем ваш жилище не только уютнее, но и изысканнее. Заинтересовались? Подробнее о наших услугах вы можете узнать на веб-сайте. Добро пожаловать в универсум уюта и уровня.
legal to buy prescription drugs from canada: Pharmacies in Canada that ship to the US – canadian pharmacy drugs online canadapharm.life
http://mexicopharm.com/# best online pharmacies in mexico mexicopharm.com
Лаки Джет — это популярная игра на деньги, для которой характерно визуальное представление увеличения ставки пользователя джет ван вин
mexican online pharmacies prescription drugs [url=http://mexicopharm.com/#]mexican pharmacy[/url] п»їbest mexican online pharmacies mexicopharm.com
Лаки Джет — это популярная игра на деньги, для которой характерно визуальное представление увеличения ставки пользователя лаки джек
купить дом особняк [url=http://www.nedvipro13.ru]http://www.nedvipro13.ru[/url].
https://canadapharm.life/# canadian pharmacy 24 com canadapharm.life
cheapest online pharmacy india: India pharmacy of the world – indianpharmacy com indiapharm.llc
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
best canadian online pharmacy reviews: Canada Drugs Direct – northwest canadian pharmacy canadapharm.life
[url=http://vardenafil.cyou/]sale levitra[/url]
pharmacy website india: indian pharmacy to usa – online pharmacy india indiapharm.llc
[url=https://tadalafil.cfd/]cialis prescription online usa[/url]
1WIN – Лучшая букмекерская контора с самыми большими коэффициентами 1Вин
canadian drug pharmacy: Canadian pharmacy best prices – reputable canadian pharmacy canadapharm.life
Горячее и ленточное наращивание натуральных волос опытным мастером в Тюмени салон красоты тюмень
1WIN – Лучшая букмекерская контора с самыми большими коэффициентами 1Вин зеркало
агентства недвижимости элитного жилья [url=https://www.nedvipro15.ru]https://www.nedvipro15.ru[/url].
http://mexicopharm.com/# mexican border pharmacies shipping to usa mexicopharm.com
buy medicines online in india: India pharmacy of the world – reputable indian online pharmacy indiapharm.llc
medicine in mexico pharmacies: Mexico pharmacy online – п»їbest mexican online pharmacies mexicopharm.com
http://mexicopharm.com/# buying prescription drugs in mexico online mexicopharm.com
top 10 online pharmacy in india: cheapest online pharmacy india – online pharmacy india indiapharm.llc
india pharmacy mail order: India Post sending medicines to USA – indian pharmacies safe indiapharm.llc
best mail order pharmacy canada: Pharmacies in Canada that ship to the US – cross border pharmacy canada canadapharm.life
Вызывная панель аудиодомофона 1500
монтаж и подключение скуд
Считыватель карт 1500
установка системы контроля доступа
Вызывная панель видеодомофона 1500
ремонт электронных замков
https://canadapharm.life/# canadian pharmacy oxycodone canadapharm.life
https://mexicopharm.com/# reputable mexican pharmacies online mexicopharm.com
купить дом в москве в элитном поселке [url=https://nedvipro17.ru]https://nedvipro17.ru[/url].
reputable mexican pharmacies online: medication from mexico pharmacy – mexican online pharmacies prescription drugs mexicopharm.com
[url=http://tadalafil.cfd/]canadian pharmacy cialis[/url]
Букмекерская контора 1Win является одним из лидеров рынка по широкому диапазону коэффициентов для спортивных мероприятий 1Вин зеркало
buy medicines online in india: india online pharmacy – buy medicines online in india indiapharm.llc
Букмекерская контора 1Win является одним из лидеров рынка по широкому диапазону коэффициентов для спортивных мероприятий 1Win
http://sildenafildelivery.pro/# sildenafil 5343
[url=http://augmentin.cfd/]augmentin generic price[/url]
Незаменимый элемент дизайна для создания образа вашего дома
купить двери [url=https://vhodnye-dveri97.ru/]https://vhodnye-dveri97.ru/[/url].
http://kamagradelivery.pro/# sildenafil oral jelly 100mg kamagra
пентхаус двухэтажный купить [url=http://www.nedviprof.ru]http://www.nedviprof.ru[/url].
Защищаем себя от жары: нюансы установки кондиционера
кондиционер купить цена [url=http://kondicionery-nedorogo.ru/]http://kondicionery-nedorogo.ru/[/url].
Official website Melbet is a spot where you can bet on sports and other exciting events 24/7 https://telegra.ph/Melbet-betting-company-12-04
https://tadalafildelivery.pro/# tadalafil online in india
http://tadalafildelivery.pro/# tadalafil 40 mg online india
30 mg sildenafil buy online [url=http://sildenafildelivery.pro/#]buy online sildenafil[/url] buy sildenafil generic
Levitra 10 mg buy online: Levitra online – Vardenafil online prescription
Completa el formulario con tus datos personales y contacto Otovix Farmacia del Ahorro precio
Completa el formulario con tus datos personales y contacto Otovix Precio en MГ©xico
cost of generic tadalafil: cheap tadalafil canada – buy tadalafil in usa
https://levitradelivery.pro/# Cheap Levitra online
prescription coupon sildenafil 20mg: sildenafil 150mg tablets – where to buy sildenafil without prescription
https://edpillsdelivery.pro/# best ed pill
Предоставляя разнообразные возможности для грузоперевозок и строительных работ, манипуляторы обеспечивают эффективность и оперативность в обработке грузов перевозка на манипуляторе
http://sildenafildelivery.pro/# sildenafil 100mg price online
sildenafil oral jelly 100mg kamagra [url=https://kamagradelivery.pro/#]cheap kamagra[/url] Kamagra 100mg price
cheap kamagra: buy kamagra – Kamagra tablets
http://edpillsdelivery.pro/# erection pills online
sildenafil generic australia [url=https://sildenafildelivery.pro/#]sildenafil without a doctor prescription Canada[/url] sildenafil 100mg price online
娛樂城
http://kamagradelivery.pro/# cheap kamagra
[url=http://clomid.digital/]buy clomid no rx[/url]
paradise city
tadalafil price comparison: cheap tadalafil canada – 80 mg tadalafil
Что такое SEO продвижение сайта. SEO (англ. Search Engine Optimization) – это комплекс мер по улучшению сайта для его ранжирования в поисковых системах seo продвижение сайта в москве
Buy Vardenafil online: Levitra online USA fast – Vardenafil price
Что такое SEO продвижение сайта. SEO (англ. Search Engine Optimization) – это комплекс мер по улучшению сайта для его ранжирования в поисковых системах сео сайта стоимость
Comprar Liverin capsulas en Mexico. Cuanto cuestan en la Farmacia, Mercado Libre Liverin farmacia Guadalajara
The Mellbet filter allows you to select a specific league, specify the amount of bets in the bet, the time before the start of the game and the minimum market odds https://dansermag.com/wp-content/pages/?strategie_pevneho_procenta.html
1вин лаки джет
русские порно ролики анал с разговором [url=https://russ-anal-s-razgovorami.pro]https://russ-anal-s-razgovorami.pro[/url].
The Mellbet filter allows you to select a specific league, specify the amount of bets in the bet, the time before the start of the game and the minimum market odds https://www.dmxzone.com/support/17883/topic/64909
Защищаем себя от жары: нюансы установки кондиционера
кондеры купить [url=https://www.kondicionery-nedorogo.ru]https://www.kondicionery-nedorogo.ru[/url].
http://kamagradelivery.pro/# cheap kamagra
medicine for sharp stomach pain order altace 10mg generic
http://kamagradelivery.pro/# sildenafil oral jelly 100mg kamagra
tadalafil for sale in canada [url=http://tadalafildelivery.pro/#]cheap tadalafil canada[/url] tadalafil 2.5 mg online india
[url=https://fluconazole.cyou/]diflucan uk[/url]
https://sildenafildelivery.pro/# price of sildenafil 50 mg
Levitra 10 mg buy online: Buy Levitra 20mg online – Levitra 20 mg for sale
Важные критерии при выборе кондиционера
где можно купить кондиционер для дома [url=https://kondicionery-v-moskve.ru/]https://kondicionery-v-moskve.ru/[/url].
http://sildenafildelivery.pro/# sildenafil otc uk
IP-телефония — это уникальный тип связи, который функционирует через интернет. К интернет-каналу предъявляются минимальные требования:https://www.google.cg/url?q=https://hottelecom.net/
IP-телефония — это уникальный тип связи, который функционирует через интернет. К интернет-каналу предъявляются минимальные требования:https://www.google.iq/url?q=https://hottelecom.net/
Comprar Flexacil Ultra capsulas en Peru. Cuanto cuestan en la Farmacia Inkafarma, Mercado Libre? flexacil ultra precio
[url=https://robaxin.cyou/]robaxin 1050 mg[/url]
[i]Разработка сайтов и мобильных приложений, комплексный интернет-маркетинг и [url=https://seotank.ru/]раскрутка сайтов[/url]. Мы предлагаем полный пакет услуг, начиная с разработки бизнес-идеи и заканчивая ведением и продвижением сайта.[/i]
minocycline 50 mg without prescription: stromectol guru – cost of ivermectin
5 преимуществ регулярного технического обслуживания кондиционеров
техническое обслуживание кондиционеров [url=https://tekhnicheskoe-obsluzhivanie-kondicionerov.ru/]https://tekhnicheskoe-obsluzhivanie-kondicionerov.ru/[/url].
Реанимобиль на дом, эвакуация больного, пострадавшего, транспортировка в больницу перевозка скорая помощь
Comprar Duston Gel en Paraguay. Cuanto cuesta farmacia punto farma, Mercado Libre? duston gel doctor ugarte
Paxlovid over the counter [url=https://paxlovid.guru/#]Buy Paxlovid privately[/url] paxlovid buy
https://amoxil.guru/# buy amoxicillin online mexico
Реанимобиль на дом, эвакуация больного, пострадавшего, транспортировка в больницу перевозка маломобильных граждан
Сертификат ISO 9001 (или ИСО 9001) подтверждает, что система менеджмента качества (СМК) соответствует всем требованиям стандарта ГОСТ Р ИСО 9001-2015 https://telegra.ph/Cena-sertifikata-ISO-9001-ot-chego-zavisit-stoimost-sertifikacii-01-09
Comprar Duston Gel en Paraguay. Cuanto cuesta farmacia punto farma, Mercado Libre? duston gel corporal de sanacion caliente ltanis tipo de envase tubo
[url=http://lisinopril.cfd/]lisinopril hct[/url]
[url=http://colchicine.cyou/]colchicine over the counter australia[/url]
https://prednisone.auction/# prednisone price south africa
[url=https://tadalafil.cfd/]cialis online mastercard[/url]
Приобретите качественные кондиционеры в лучшем магазине
Обеспечьте свой дом прохладой с нашими кондиционерами
Разнообразие кондиционеров в нашем магазине
Лучшие цены на кондиционеры только у нас
Украсьте свой интерьер с помощью наших кондиционеров
Качественный сервис к каждому клиенту в нашем магазине
Популярные марки кондиционеров в нашем ассортименте
Осуществляем доставку по всей стране
Создайте комфортный климат с помощью наших кондиционеров
Профессиональная помощь в выборе и установке кондиционеров
Предлагаем услуги по монтажу наших кондиционеров
Экономичный расход энергии с нашими кондиционерами
Наслаждайтесь прохладой в любое время года с нашими кондиционерами
Получите скидку кондиционеров в нашем магазине
Гарантия качества наших кондиционеров от производителя
Увеличьте эффективность работы для работы с нашими кондиционерами
Индивидуальные условия для организаций при покупке кондиционеров в нашем магазине
Удобный поиск по параметрам кондиционеров на нашем сайте
Новинки в области кондиционирования в нашем магазине
Безупречная доступность кондиционеров в нашем магазине
інтернет магазин кондиціонерів [url=http://www.magazin-kondicionerov.ru]http://www.magazin-kondicionerov.ru[/url].
мебельный поролон [url=https://vinylko11.ru/]https://vinylko11.ru/[/url].
uniswap https://uniswap.work/
http://prednisone.auction/# where can i get prednisone over the counter
Репетитор по [url=https://kurs-na-ege.ru/]подготовке к ЕГЭ[/url]. Репетиторы ОГЭ подготовят к экзаменам по русскому языку, математике, литературе, иностранным языкам, физике, химии и другим.
http://clomid.auction/# cost of clomid prices
paxlovid pharmacy [url=http://paxlovid.guru/#]paxlovid price without insurance[/url] paxlovid for sale
Люди, зависимые от наркотических веществ, часто пересекают границы, которые они не желают пересекать. Для многих таких людей наступает тяжелый момент, когда им надоело http://mockwa.com/forum/thread-138987/
[url=https://metformin.cfd/]glucophage 1000 mg tablets[/url]
can you get generic clomid tablets: cheapest clomid – clomid no prescription
Love the site– very user friendly and great deals to see!
http://ybjlfc.com/home.php?mod=space&uid=353459&do=profile
prescription acne cream names deltasone 5mg drug pills to clear acne
http://clomid.auction/# get clomid now
Техническое обслуживание кондиционеров
техническое обслуживание кондиционеров новосибирск [url=http://tekhnicheskoe-obsluzhivanie-kondicionerov.ru/]http://tekhnicheskoe-obsluzhivanie-kondicionerov.ru/[/url].
купить доску обрезную http://pogonazh43.ru/
[url=https://tadalafil.cyou/]cialis pills order[/url]
Наши диски для штанги от производителя предназначены для коммерческого и домашнего использования. Они используются на силовом тренинге для выполнения разных упражнений на все мускулы. Диски выполнены из цельной стали и покрыты резиной. Подобная обработка предотвращает коррозию металла и поглощает звуковые эффекты во время тренировок, что особенно важно при использовании блинов дома. Посадочное кольцо также изготовлено из стали, но обрезиниванию не подвергается. Это позволяет избежать стирания и разрушения слоя из резины при регулярном снятии/навешивании на гриф, поскольку само покрытие с ним не взаимодействует. Кроме того, за счет гладкой втулки блины для штанги отлично скользят, что позволяет быстро менять нагрузку. У нас вы сможете приобрести блины нужного веса и диаметра для получения качественных силовых результатов.
Сертификат ISO 9001 – это официальный документ, гарантирующий качество выпускаемого товара, продукта/оказываемой услуги, а так же высокую степень надежности Вашего предприятия стоимость получения сертификата ИСО 9001
get propecia pills: buy propecia – buy propecia no prescription
[url=https://fdeti.ru/]Школа подготовки[/url] к ОГЭ (Основному государственному экзамену) включает в себя подготовку школьников в России к обязательному экзамену по по математике, физике, русскому языку, обществознанию и другим предметам, который сдают в 9 классе.
https://azithromycin.store/# zithromax antibiotic without prescription
Онлайн школа [url=https://languagesforlife.ru/]подготовки к ЕГЭ[/url] и ОГЭ. Подготовим школьников к сдаче экзаменов по русскому языку, математике, литературе, иностранным языкам, физике, химии на 80-100 баллов.
how to get zithromax online: Azithromycin 250 buy online – can you buy zithromax over the counter in australia
электрические карнизы для штор [url=vc.ru/u/2465162-elektrokarnizy-prokarniz/907958-elektrokarnizy-upravlenie-svetom]vc.ru/u/2465162-elektrokarnizy-prokarniz/907958-elektrokarnizy-upravlenie-svetom[/url].
Hardex crema comprar en Guatemala precio en farmacia Donde comprar Hardex Crema
lasix 40mg: Buy Lasix – lasix 40 mg
generic propecia prices: Cheapest finasteride online – buying cheap propecia without prescription
buy cytotec pills [url=https://misoprostol.shop/#]Buy Abortion Pills Online[/url] buy cytotec in usa
pin up kz регистрация https://pinupbets.kz/
[url=http://zoloft.cfd/]zoloft buy india[/url]
Выберите xbet и станьте победителем в мире онлайн-ставок!
app 1xbet [url=https://www.1xbet-app-download-ar.com]https://www.1xbet-app-download-ar.com[/url].
https://lisinopril.fun/# compare zestril prices
zithromax 250: Azithromycin 250 buy online – buy zithromax without prescription online
[url=http://doxycycline.cfd/]doxycycline 50mg[/url]
[url=https://citalopram.cyou/]can i buy celexa online[/url]
cost of propecia without prescription: get cheap propecia pill – buy propecia tablets
https://misoprostol.shop/# buy cytotec over the counter
Gyronix capsulas en Honduras, ?para que sirve, cuanto cuesta y donde comprar? Precio en Farmacia Gyronix Honduras
Gyronix capsulas en Honduras, ?para que sirve, cuanto cuesta y donde comprar? Precio en Farmacia Gyronix Para qué sirve
?Donde comprar Duston Gel en Uruguay? ?Cuanto cuesta? Opiniones y criticas, ?verdad o estafa? duston gel mercado
Сертификат ISO 9001 – лучший способ поднять престиж компании и выйти на внешний рынок сертификат гост iso 9001
average cost of generic zithromax: buy zithromax over the counter – can i buy zithromax over the counter
lasix dosage [url=http://furosemide.pro/#]Over The Counter Lasix[/url] lasix for sale
https://azithromycin.store/# zithromax pill
lisinopril 20 mg purchase: lisinopril 40 mg canada – lisinopril mexico
http://finasteride.men/# buy propecia without prescription
lisinopril 10mg daily: over the counter lisinopril – zestoretic 20 25mg
https://azithromycin.store/# zithromax 500 mg lowest price pharmacy online
[url=https://nashispravki.ru/]Аренда манипулятора[/url] ISUZU FVR в Москве: Эффективные Решения для Грузоперевозок и Строительства
Toxic Off capsulas en Mexico precio. ?Que farmacia las vende? Cuanto cuestan en Mercado Libre Toxic Off funciona o es estafa
http://xianham.com/home.php?mod=space&uid=179767&do=profile
Toxic Off capsulas en Mexico precio. ?Que farmacia las vende? Cuanto cuestan en Mercado Libre Toxic Off donde lo venden
get propecia without insurance: buy propecia – generic propecia without dr prescription
Engage into the Infinite Planet of Minecraft with Us!
On our website, you’ll find everything you need for an thrilling adventure in Minecraft: servers with a various mods, handy tips, and compelling articles about the world of blocky adventures! http://rowanwdyd210.lowescouponn.com/teleporting-to-your-village-in-minecraft-a-step-by-move-manual
[url=https://propranolol.cyou/]propranolol 40 mg cost[/url]
[url=https://trazodone.cfd/]trazodone coupon[/url]
http://finasteride.men/# order cheap propecia without prescription
how to buy zithromax online: zithromax best price – zithromax online pharmacy canada
can you buy lisinopril: buy lisinopril online – lisinopril buy online
娛樂城
комплексный аудит сайта [url=https://newsvo.ru/news/82798/]https://newsvo.ru/news/82798/[/url].
На сайте нашего похоронного бюро вы можете ознакомиться с основными тарифами на погребение похороны бюро ритуальных услуг
https://www.google.com.af/url?q=https://guard-car.ru/
https://lisinopril.fun/# lisinopril 10 best price
Misoprostol 200 mg buy online: Buy Abortion Pills Online – cytotec online
На сайте нашего похоронного бюро вы можете ознакомиться с основными тарифами на погребение бюро похорон
stomach acid medication metformin brand
cost of propecia without dr prescription [url=http://finasteride.men/#]buy propecia[/url] cost of generic propecia for sale
[url=http://neurontin.cfd/]gabapentin 600 mg price[/url]
http://finasteride.men/# cheap propecia pill
lisinopril 20mg: buy lisinopril canada – lisinopril 5 mg
Мостбет
Наша компания предлагает спортивное оборудование в ассортименте: грузоблочные станки и нагружаемые дисками, устройства для упражнений с собственной массой тела, скамьи и стойки, а также гантели, штанги, гири, отдельные части для них и прочий инвентарь. Для выпуска оборудования используются первоклассные материалы – сталь, качественные наполнители и экокожа для мягких частей (сидений, спинок и пр.), безопасные порошковые составы для окрашивания конструкций из металла. Наше спортивное силовое оборудование рассчитано на интенсивную эксплуатацию в режиме 24/7, за счет чего подходит как для средних тренажерных залов, так и для крупных фитнес-центров с высокой проходимостью. Для домашних тренировок идеально подойдут варианты для работы со своим весом, скамьи, разборные гантели, штанги, гири.
cytotec abortion pill: Misoprostol 200 mg buy online – buy cytotec pills online cheap
[url=http://finasteride.best/]propecia no prescription bonus 98212[/url]
https://www.google.dm/url?q=https://guard-car.ru/
http://lisinopril.fun/# lisinopril pills
[url=https://albuterol.cyou/]salbutamol albuterol[/url]
buy cheap propecia tablets: Finasteride buy online – buying propecia
https://finasteride.men/# order cheap propecia without prescription
farmacie online sicure: comprare avanafil senza ricetta – farmaci senza ricetta elenco
[url=https://arenda-manipulyatora-v-moskve.ru/]Аренда манипулятора[/url] с грузоподъёмностью от 3 до 15 тонн в Москве и области. Недорого от 899 руб/час. У нас можно заказать кран-манипулятор для перевозки бытовок, контейнеров, станков, плит и других строительных грузов.
buy accutane 40mg for sale order isotretinoin 10mg online cheap oral accutane 20mg
https://kamagraitalia.shop/# farmacia online migliore
[url=https://uslugi-manipulyatora-moskva.ru/]Аренда Манипуляторов[/url] в Москве по низкой стоимости. Собственный автопарк с большим выбором техники. Чтобы быстро транспортировать габаритные грузы, стоит воспользоваться такой услугой, как аренда манипулятора
farmaci senza ricetta elenco [url=https://avanafilitalia.online/#]Avanafil farmaco[/url] acquistare farmaci senza ricetta
viagra originale in 24 ore contrassegno: viagra online siti sicuri – viagra online spedizione gratuita
farmacia online migliore: kamagra oral jelly – farmacia online senza ricetta
[url=https://doxycycline.guru/]order doxycycline online canada[/url]
[url=http://azithromycin.digital/]uk azithromycin over the counter[/url]
[url=https://vardenafil.cfd/]vardenafil online no prescription[/url]
https://kamagraitalia.shop/# farmaci senza ricetta elenco
https://sildenafilitalia.men/# alternativa al viagra senza ricetta in farmacia
Calorico forte capsules in south africa, where to buy? Opinions and review calorico forte price in south africa
Motion Energy gel in Nigeria, where to buy and how much does it cost? Price Motion Energy Price
http://sildenafilitalia.men/# viagra originale in 24 ore contrassegno
как выбрать хостинг для интернет-магазина [url=https://sidashdmytro.com/kak-vybrat-hosting-saytov]https://sidashdmytro.com/kak-vybrat-hosting-saytov[/url].
farmacie online autorizzate elenco: farmacia online migliore – farmacie on line spedizione gratuita
comprare farmaci online con ricetta [url=http://tadalafilitalia.pro/#]dove acquistare cialis online sicuro[/url] farmacia online senza ricetta
https://sildenafilitalia.men/# viagra naturale
К 5-летию свадьбы решил подарить жене нечто особенное – букет из искусственных цветов. Заказал его на “Цветов.ру” и добавил легкости и веселья в нашу гармоничную жизнь. Спасибо за творческий подход! Советую! Вот ссылка [url=https://pravozashcitnik.ru/stav/]заказ цветов[/url]
acquisto farmaci con ricetta: kamagra gel prezzo – top farmacia online
viagra generico prezzo piГ№ basso: viagra consegna in 24 ore pagamento alla consegna – gel per erezione in farmacia
Fast and Secure Cryptocurrency Exchange
exchange crypto online [url=https://cryptoswaptradecoins.com/]https://cryptoswaptradecoins.com/[/url].
https://farmaciaitalia.store/# comprare farmaci online con ricetta
Comprar Sustarox crema en Peru. Precio en Inkafarma, Mercado Libre Sustarox mercado libre cerca de perГє
Купить страховку на квартиру, онлайн – оформите добровольное страхование квартиры от затопления соседей, ремонта, а также вы можете застраховать имущество в квартире – оформите договор страхования квартиры The Art of Collecting: Tips for Building and Preserving Your Stamp Collection
Explore the Top Crypto Swap Exchanges for Seamless Trading
Upgrade Your Crypto Trading with these Cutting-Edge Swap Exchanges
Confidently Trade Cryptocurrency with these Reliable Swap Exchanges
Improve Your Crypto Portfolio with these Streamlined Swap Exchanges
Trade Cryptocurrencies Difficulty using these Easy Platforms
Step into the World of Cryptocurrency Exchanging with these Best-Rated Swap Exchanges
Quickly Cryptocurrencies with these Speedy Swap Platforms
Optimize Your Crypto Trades with these Adaptable Swap Exchanges
Exchange Cryptocurrencies via these Easy-to-Use Platforms
Expand Your Crypto Holdings with these Wide Selection of Swap Exchanges
Improve Your Crypto Trading Strategy with these Cutting-Edge Swap Platforms
Trade Cryptocurrencies with these Safe and Regulated Swap Exchanges
Simplify Crypto Trading with these Convenient Swap Exchanges
Find the Leading Crypto Swap Exchanges for Amplify Your Crypto Trading Experience with these Highly Rated Swap Exchanges
Effortlessly Cryptocurrencies with these Modern Platforms
Confidently Trade Cryptocurrencies with these Encrypted Swap Exchanges
Discover the Top Crypto Swap Exchanges for Instant Transactions
Trade in Cryptocurrency with these Reputable Swap Exchanges Attractive Rates
Make the Most out of Your Crypto Trading with these Cutting-Edge Swap Platforms
best coin swap app [url=https://cryptoswapinstantly.com/]https://cryptoswapinstantly.com/[/url].
https://tadalafilitalia.pro/# acquistare farmaci senza ricetta
Comprar Sustarox crema en Peru. Precio en Inkafarma, Mercado Libre Sustarox Precio Peru
[url=https://albuterol.guru/]albuterol 63[/url]
farmacia online [url=http://kamagraitalia.shop/#]kamagra[/url] farmacia online senza ricetta
https://tadalafilitalia.pro/# farmacia online miglior prezzo
acquisto farmaci con ricetta: kamagra gold – п»їfarmacia online migliore
[url=https://trazodone.cfd/]rx trazodone[/url]
[url=https://pharmacyonline.cfd/]canadadrugpharmacy[/url]
http://kamagraitalia.shop/# farmacie on line spedizione gratuita
miglior sito dove acquistare viagra: sildenafil 100mg prezzo – viagra online consegna rapida
best selling sleeping pills buy phenergan 25mg pills
Строительная экспертиза в Москве от организации Строительная экспертиза недорого и с гарантией.
Играйте в лучшие онлайн казино 2024 года, который входят в рейтинг лучших. Топ казино дарит выгодные бонусы на депозит, выплаты быстрые, регистрация на официальном сайте моментальная Лучшие онлайн казино
https://farmaciaitalia.store/# farmacie online autorizzate elenco
cialis farmacia senza ricetta: sildenafil 100mg prezzo – le migliori pillole per l’erezione
farmacia online migliore: cialis prezzo – farmacia online migliore
farmacia online [url=http://farmaciaitalia.store/#]farmacia online spedizione gratuita[/url] farmacie online autorizzate elenco
http://tadalafilitalia.pro/# comprare farmaci online con ricetta
https://mexicanpharm.store/# pharmacies in mexico that ship to usa
mexico drug stores pharmacies: mexican pharmaceuticals online – reputable mexican pharmacies online
Revolution of cryptocurrency
ranking exchange crypto [url=swapcryptotradecoins.com]swapcryptotradecoins.com[/url].
Ваш сайт — наше дело! Профессиональное [url=https://dguizber.ru/]создание и продвижение сайтов[/url] в интернете. Привлекайте клиентов онлайн. Успех начинается с нашей команды!
секс порно трахать
http://indiapharm.life/# indian pharmacy online
amoxicillin pill oral amoxil 500mg purchase amoxil
сделать аудит сайта цена [url=http://www.dimox.name/chto-takoe-rerajting]http://www.dimox.name/chto-takoe-rerajting[/url].
Find the Leading Crypto Swap Exchanges for Seamless Trading
Upgrade Your Crypto Trading with these Cutting-Edge Swap Exchanges
Safely Trade Cryptocurrency with these Reliable Swap Exchanges
Optimize Your Crypto Portfolio with these Effective Swap Exchanges
Trade Cryptocurrencies Hassle using these User-Friendly Platforms
Step into the World of Cryptocurrency Swapping with these Best-Rated Swap Exchanges
Swap Cryptocurrencies with these Fast Swap Platforms
Maximize Your Crypto Trades with these Flexible Swap Exchanges
Swap Cryptocurrencies with these User-Friendly Platforms
Diversify Your Crypto Holdings with these Wide Selection of Swap Exchanges
Enhance Your Crypto Trading Strategy with these Cutting-Edge Swap Platforms
Exchange Cryptocurrencies with these Secure and Regulated Swap Exchanges
Simplify Crypto Trading with these Efficient Swap Exchanges
Find the Top Crypto Swap Exchanges for Amplify Your Crypto Trading Experience with these Well-Reviewed Swap Exchanges
Trade Cryptocurrencies with these Modern Platforms
Safely Trade Cryptocurrencies with these Encrypted Swap Exchanges
Uncover the Best Crypto Swap Exchanges for Instant Transactions
Exchange in Cryptocurrency with these Reliable Swap Exchanges on Rates
Make the Most out of Your Crypto Trading with these Next-Generation Swap Platforms
best app for swapping cryptocurrency [url=https://www.cryptoswapinstantly.com/]https://www.cryptoswapinstantly.com/[/url].
Relifix Crema: La Eleccion Ideal en Guatemala para Cuidado de la Piel – Precios y Puntos de Venta en Farmacias Relifix componentes
canadian online pharmacy [url=http://canadapharm.shop/#]canadian pharmacy prices[/url] my canadian pharmacy
http://indiapharm.life/# Online medicine order
indian pharmacies safe: top 10 pharmacies in india – pharmacy website india
Discover the Leading Crypto Swap Exchanges to Seamless Trading
Enhance Your Crypto Trading with these Innovative Swap Exchanges
Confidently Trade Cryptocurrency with these Reliable Swap Exchanges
Optimize Your Crypto Portfolio with these Efficient Swap Exchanges
Exchange Cryptocurrencies Hassle using these User-Friendly Platforms
Dive into the World of Cryptocurrency Exchanging with these Top-Rated Swap Exchanges
Swap Cryptocurrencies with these Rapid Swap Platforms
Maximize Your Crypto Trades with these Adaptable Swap Exchanges
Smoothly Cryptocurrencies using these User-Friendly Platforms
Broaden Your Crypto Holdings with these Ranging Swap Exchanges
Upgrade Your Crypto Trading Strategy with these Cutting-Edge Swap Platforms
Swap Cryptocurrencies using these Protected and Regulated Swap Exchanges
Facilitate Crypto Trading with these Convenient Swap Exchanges
Explore the Leading Crypto Swap Exchanges for Elevate Your Crypto Trading Experience with these Well-Reviewed Swap Exchanges
Trade Cryptocurrencies with these Modern Platforms
Confidently Trade Cryptocurrencies with these High-Security Swap Exchanges
Discover the Leading Crypto Swap Exchanges for Lightning-Fast Transactions
Invest in Cryptocurrency with these Trusted Swap Exchanges with Rates
Optimize Your Crypto Trading with these Next-Generation Swap Platforms
best coin swap platform [url=https://www.cryptoswapinstantly.com/]https://www.cryptoswapinstantly.com/[/url].
Ваш сайт — ваш успех. [url=https://prodvizhenie-sajtov-moskva.ru/]Создание и продвижение сайтов[/url]. Индивидуальный подход. Максимальный результат. Звоните и начинайте расти!
[url=https://avana.cfd/]dapoxetine 120 mg[/url]
Modern cryptocurrency
crypto swap sites [url=http://swapcryptotradecoins.com/]http://swapcryptotradecoins.com/[/url].
best canadian pharmacy: canadian pharmacy ltd – pharmacy rx world canada
vipps approved canadian online pharmacy: northwest pharmacy canada – best canadian pharmacy online
http://mexicanpharm.store/# mexican mail order pharmacies
mexico pharmacy: mexican drugstore online – mexican pharmacy
https://mexicanpharm.store/# mexico drug stores pharmacies
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
http://canadapharm.shop/# canada pharmacy world
ремонт мягкой мебели в минске [url=https://csalon.ru/]перетяжка кресел минск[/url].
игровые автоматы Gama Casino
бонусы Gama Casino
Легкий и выгодный способ обменять криптовалюту – наше приложение для свопа
best app for swapping cryptocurrency [url=http://cryptoswapdapp.com/]http://cryptoswapdapp.com/[/url].
top 10 online pharmacy in india [url=http://indiapharm.life/#]top 10 online pharmacy in india[/url] india online pharmacy
medication from mexico pharmacy: mexico drug stores pharmacies – medication from mexico pharmacy
http://mexicanpharm.store/# pharmacies in mexico that ship to usa
best india pharmacy: indian pharmacy – online pharmacy india
https://canadapharm.shop/# canadian pharmacy
canada drugstore pharmacy rx: canadian pharmacy ed medications – pet meds without vet prescription canada
https://indiapharm.life/# Online medicine order
Березин Андрей Евроинвест [url=http://newprospect.ru/news/interview/andrey-berezin-est-mnogo-interesnykh-veshchey-kotorye-trebuyut-moego-vnimaniya/]http://newprospect.ru/news/interview/andrey-berezin-est-mnogo-interesnykh-veshchey-kotorye-trebuyut-moego-vnimaniya/[/url]
mexican pharmaceuticals online: buying prescription drugs in mexico online – reputable mexican pharmacies online
http://canadapharm.shop/# best canadian online pharmacy reviews
[url=http://sildenafil.cfd/]average cost of viagra 2018[/url]
order azithromycin pills zithromax 250mg pill buy zithromax 500mg pill
Для осуществления онлайн-торговли брокер предлагает целый список инструментов, среди которых торговля на Форекс, использование финансового анализа https://obrokerah.ru/alpari/
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
в бархатных платьях
1 pin up [url=pinupcasinovendfsty.dp.ua]pinupcasinovendfsty.dp.ua[/url].
[url=http://synthroid.boutique/]synthroid 0.125mg tab[/url]
[url=https://www.pinupcasinozendfste.vn.ua]https://www.pinupcasinozendfste.vn.ua[/url]
Казино хронически привлекали буква себя внимание. Этто место, где хоть хватить лиха свойскую успех и осилить здоровенную сумму денег.
https://www.pinupcasinozendfste.vn.ua
http://canadapharm.shop/# best online canadian pharmacy
Здесь можно найти лучший crypto swap app
Сделай обмен криптовалют простым с этим crypto swap app
усилия с этим удобным crypto swap app
Данный crypto swap app просто освоить для новичку
Меняй криптовалюты мгновенно с помощью этого crypto swap app
Познакомься с современным способом обмена криптовалют с этим crypto swap app
Откажись от неудобных обменников и используй этот crypto swap app
Легкий обмен криптовалют с этим crypto swap app
Забудь осложненные процедуры обмена с этим удобным crypto swap app
Сэкономь свои финансовые операции с этим crypto swap app
Не теряй время с этим быстрым crypto swap app
Обменивай криптовалюты с легкостью благодаря этому crypto swap app
Наслаждайся простым и удобным crypto swap app
Получи больше с помощью этого эффективного crypto swap app
Попробуй новый способ обмена криптовалют с этим crypto swap app
Защити свои финансы с этим надежным crypto swap app
Меняй криптовалюты без лишней головной боли с этим crypto swap app
Узнай с новым инструментом обмена криптовалют с этим crypto swap app
Воспользуйся новейшими технологиями с этим crypto swap app
Удиви своих друзей с этим удобным crypto swap app
best app to exchange cryptocurrency [url=http://www.cryptoswapdefidapp.com/]http://www.cryptoswapdefidapp.com/[/url].
Привлекайте клиентов с нашими сайтами. Эффективное [url=https://prodvizhenie-sajta-moskva.ru/]создание и продвижение сайтов[/url] в Москве. Уникальный дизайн, мощная видимость. Заказывайте прямо сейчас!
trusted canadian pharmacy [url=http://canadapharm.shop/#]canadian king pharmacy[/url] canadianpharmacymeds
Будьте в центре внимания с нашими сайтами. Творческое создание и эффективное [url=https://prodvizhenie-sajta-v-moskve.ru/]продвижение сайтов[/url] в поисковых системах. Онлайн успех ждет вас. Обсудим ваш проект?
Ваш бизнес заслуживает лучшего сайта. Наша команда предлагает профессиональное [url=https://sozdanie-sajta-v-moskve.ru/]создание и продвижение сайтов[/url] в Москве. Развивайтесь вместе с нами!
[url=http://avana.cfd/]order dapoxetine online in usa[/url]
buy gabapentin 600mg online cheap gabapentin order
long term car rental Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
[url=http://amoxicillin.boutique/]order amoxil[/url]
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
https://mexicanpharm.store/# mexican mail order pharmacies
Pin-Up es una casa de apuestas internacional con licencia de Curazao, que ahora opera legalmente tambien en Peru https://trevormgyp66543.targetblogs.com/24873136/dive-to-the-thrilling-planet-of-pin-up-on-line-casino-a-worldwide-playground-for-online-gambling-enthusiasts
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Бережная [url=https://slv-i.ru/]химчистка мебели[/url]. Восстановим яркость и чистоту. Опыт и качество в каждом детале. Заботимся о вашем комфорте!
vipps canadian pharmacy: canadian pharmacy 365 – pharmacy in canada
гостевой дом в Анапе https://otdyh-vanape.ru/
http://indiapharm.life/# indian pharmacies safe
[url=https://pinupcasinozendfste.vn.ua]pinupcasinozendfste.vn.ua[/url]
Казино хронически притягивали к себя внимание. Это место, где можно выстрадать свою успех а также осилить крупную необходимую сумму денег.
http://www.pinupcasinozendfste.vn.ua
online order prednisone 10mg: prednisone 20 – order prednisone online no prescription
5 mg prednisone tablets [url=http://prednisonepharm.store/#]price for 15 prednisone[/url] prednisone 40 mg price
Березин Андрей Евроинвест [url=https://www.neva.today/person/andrej-valerevich-berezin-sovladelecz-investiczionnoj-kompanii-evroinvest-458141/]https://www.neva.today/person/andrej-valerevich-berezin-sovladelecz-investiczionnoj-kompanii-evroinvest-458141/[/url].
Setting the benchmark for global pharmaceutical services http://clomidpharm.shop/# cost generic clomid no prescription
With many hundreds of Forex / CFD brokers to choose from globally, finding the right broker for you can seem an impossible challenge fee free mortgage broker
With many hundreds of Forex / CFD brokers to choose from globally, finding the right broker for you can seem an impossible challenge best regulated forex brokers
zithromax for sale cheap: zithromax purchase online – generic zithromax india
Очистим вашу мебель от загрязнений. Профессиональная [url=https://uslugi-khimchistki-mebeli-v-moskve.ru/]химчистка мебели[/url] для безупречной чистоты. Отдыхайте с комфортом.
The ambiance of the pharmacy is calming and pleasant https://nolvadex.pro/# hysterectomy after breast cancer tamoxifen
http://nolvadex.pro/# nolvadex for sale amazon
A pharmacy that’s globally recognized and locally loved http://prednisonepharm.store/# how to get prednisone tablets
купить светодиодную балку https://idn300.ru/catalog/svetovye_balki_i_paneli_dlya_avto/
https://cytotec.directory/# purchase cytotec
zithromax for sale online [url=https://zithromaxpharm.online/#]zithromax cost[/url] how much is zithromax 250 mg
[url=http://finasteride.best/]best price generic propecia[/url]
свинтус [url=http://www.nastolnyeygryekb.ru/]http://www.nastolnyeygryekb.ru/[/url].
can i order generic clomid online: how to get cheap clomid prices – how to get generic clomid without a prescription
https://cytotec.directory/# buy cytotec online
Drugs information sheet http://nolvadex.pro/# who should take tamoxifen
Алмазное сверление и алмазное бурение, алмазная резка
алмазное бурение бетона цена в москве
Бурение алмазное 19 — 20 см 1800 Руб./п.м.
Алмазное сверление 16 — 18 см 1600 Руб./п.м.
Березин Андрей Евроинвест [url=https://www.mainfin.ru/persona/berezin-andrey-valeryevich]https://www.mainfin.ru/persona/berezin-andrey-valeryevich[/url].
Cопровождение интернет-площадки представляет собой комплексную услугу, которая направлена на поддержание его компонентов для стабильного функционирования. Выполняемая профессионалами поддержка web сайта продвигает площадку на более высокий уровень, что делает бизнес прибыльным и успешным. Проводимые действия дает возможность компаниям предоставлять своей целевой аудитории только актуальную информацию, коммуницировать с ней оперативно, безопасно и результативно. Такой проект всегда доступен и удобен для посетителей, клиентов и поисковых систем, а это способствует увеличению продаж товаров или услуг и повышает статус фирмы. Главное, чтобы все осуществляли квалифицированные специалисты, поскольку работы, которые выполнены непрофессионально, негативно скажутся на его производительности и юзабилити, а также повысят вероятность возникновения вирусов и кибератак.
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Алмазное сверление и алмазное бурение, алмазная резка
алмазное бурение отверстий в бетоне цена
Алмазное сверление 40 см 3800 Руб./п.м.
Сверление алмазное 19 — 20 см 1800 Руб./п.м.
how can i get prednisone: can you buy prednisone over the counter in mexico – 20 mg prednisone
п»їExceptional service every time https://zithromaxpharm.online/# zithromax online usa
[url=https://med-m-center.ru/]Перевозка лежачих больных[/url]: забота и безопасность в пути. Квалифицированные специалисты гарантируют комфорт пациентам.
3a娛樂城
3a娛樂城
https://clomidpharm.shop/# where to buy clomid without insurance
Безопасная и заботливая [url=https://vip-bunker.ru/]перевозка лежачих больных[/url]. Опытные медицинские сопровождающие. Доверьтесь нашей команде.
nolvadex only pct [url=https://nolvadex.pro/#]raloxifene vs tamoxifen[/url] does tamoxifen cause menopause
https://clomidpharm.shop/# can i order cheap clomid pill
Love their spacious and well-lit premises https://prednisonepharm.store/# prednisone
Безопасная [url=https://aquadag.ru/]перевозка лежачих больных[/url]. Заботимся о комфорте. Профессионализм и внимание каждому пациенту.
Mercedes for rent dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
monthly car rental in dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
tamoxifen cancer: does tamoxifen cause joint pain – tamoxifen menopause
canadapharmacy com: most reliable online pharmacies – meds canada
https://edpills.bid/# top rated ed pills
best ed drugs [url=https://edpills.bid/#]ed meds online[/url] compare ed drugs
non prescription ed drugs: non prescription ed pills – ed prescription drugs
purchase prednisolone generic omnacortil brand order omnacortil 20mg generic
[url=https://neurontin.cfd/]gabapentin 1800 mg[/url]
safe canadian online pharmacy http://reputablepharmacies.online/# prescription cost comparison
reliable canadian online pharmacy
rx canada: overseas pharmacies that deliver to usa – discount viagra canadian pharmacy
[url=http://lyrica.cfd/]over the counter lyrica[/url]
http://edwithoutdoctorprescription.store/# best non prescription ed pills
non prescription canadian pharmacy [url=https://reputablepharmacies.online/#]overseas pharmacies online[/url] discount pharmacies
конус пластиковый дорожный https://znaki99.ru/konusy/
Наши специалисты тщательно отбирают только качественные товары от ведущих мировых производителей, гарантируя ваше удовольствие и безопасностьhttp://www.luisovalles.com/new/index.php?option=com_k2&view=itemlist&task=user&id=97754
prescription drugs online without doctor: cialis without a doctor’s prescription – prescription drugs without doctor approval
https://reputablepharmacies.online/# canadian pharmacieswith no prescription
new ed treatments [url=https://edpills.bid/#]best ed treatment pills[/url] mens erection pills
top rated canadian mail order pharmacies https://reputablepharmacies.online/# online pharmacy without precriptions
buy mexican drugs online
pharmacies online: generic pharmacy store – canadian drug
http://edpills.bid/# top ed drugs
Надежная [url=https://perevozki-lezhachikh-bolnykh-moskva.ru/]перевозка лежачих больных[/url]. Опытные медицинские сопровождающие. Безопасность и комфорт в каждой поездке.
[url=http://augmentin.cfd/]amoxicillin 500 capsule[/url]
non prescription ed drugs [url=http://edwithoutdoctorprescription.store/#]prescription meds without the prescriptions[/url] prescription drugs online without doctor
Доверьте [url=https://transportirovka-bolnykh-moskva.ru/]перевозку лежачих больных[/url] нам. Профессиональные водители и медицинский уход. Безопасность и комфорт в каждой дороге.
Демонтаж и снос частных домов с вывозом мусора в Москве и Московской области – lit9.ru. Демонтаж дома вручную и спецтехникой производим по ценам ниже рынка за 1 день. Бесплатный выезд специалиста на объект.
[url=https://perevozka-bolnykh-v-moskve.ru/]Перевозка лежачих больных[/url] с заботой о вашем комфорте. Профессиональные медсестры и комфортные условия в пути. Доверьтесь нам!
[url=http://prednisolone.directory/]prednisolone price us[/url]
digital маркетинг инструменты [url=http://www.agentstvo-internet-marketinga.com.ua]http://www.agentstvo-internet-marketinga.com.ua[/url].
best ed treatment: impotence pills – medication for ed
The salesman, surprised, asked the snail, “Why do you need a fast car? You’re a snail.” buy
Услуги 3D принтера – это ответственный подход к каждому проекту. http://mwllaw.net/__media__/js/netsoltrademark.php?d=news.npo.digital/index.php?title=%D0%A3%D1%81%D0%BB%D1%83%D0%B3%D0%B8_3D_%D0%9F%D1%80%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B0
Watches World
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
buy prescription drugs without doctor: buy prescription drugs online legally – non prescription ed pills
https://edpills.bid/# ed treatment drugs
medications for ed: medicine for impotence – medicine for erectile
best treatment for ed [url=https://edpills.bid/#]ed pill[/url] treatment for ed
medication canadian pharmacy [url=https://canadianpharmacy.pro/#]Cheapest drug prices Canada[/url] buy drugs from canada canadianpharmacy.pro
amoxil 1000mg pills buy amoxicillin tablets cheap amoxil pill
Need a virtual phone number to handle outbound and incoming calls? Get one in just a few minutes https://www.google.la/url?q=https://didvirtualnumbers.com/nl/
[url=http://rybelsus.trade/]semaglutide ozempic[/url]
buy doxycycline no prescription buy generic monodox
buying from online mexican pharmacy: Mexico pharmacy – best online pharmacies in mexico mexicanpharmacy.win
штрафы гибдд проверить официальный сайт https://proverka-gibdd-shtrafov.ru/
[url=http://semaglutiderybelsus.shop/]buy semaglutide online cheap[/url]
reputable indian online pharmacy: international medicine delivery from india – reputable indian pharmacies indianpharmacy.shop
You can get a virtual phone number with OpenPhone in three simple https://www.google.ae/url?q=https://hottelecom.net/pl/
[url=http://semaglutide.cyou/]order semaglutide online[/url]
mexican drugstore online [url=https://mexicanpharmacy.win/#]Mexico pharmacy[/url] buying from online mexican pharmacy mexicanpharmacy.win
[url=http://ozempic.cyou/]order ozempic[/url]
http://mexicanpharmacy.win/# mexican rx online mexicanpharmacy.win
cheap viagra online canadian pharmacy
http://canadianpharmacy.pro/# 77 canadian pharmacy canadianpharmacy.pro
установка кондиционеры [url=https://kondicionery-nedorogo-msk.ru]https://kondicionery-nedorogo-msk.ru[/url].
[url=http://ozempic.directory/]ozempic tablets cost[/url]
Обзор лучших строительных компаний в Крыму и Севастополе, посмотрите строительство домов в Крыму
https://canadianpharmacy.pro/# safe reliable canadian pharmacy canadianpharmacy.pro
world pharmacy india
Агентство набирает пластичных, стройных и привлекательных девушек http://rai.lv/ru/index.php?subaction=userinfo&user=yzasa
Vyacheslav Konstantinovich Nikolaev [url=https://spacecoastdaily.com/2023/08/vyacheslav-nikolaev-ecosystem-builder]https://spacecoastdaily.com/2023/08/vyacheslav-nikolaev-ecosystem-builder[/url].
[url=http://ozempic.company/]generic ozempic cost[/url]
http://indianpharmacy.shop/# Online medicine order indianpharmacy.shop
Online medicine order
Ежемесячная зарплата красоток, которые работают в данном агентстве, составляет от 20000 долларов и выше http://ossethnos.ru/index.php?subaction=userinfo&user=icefivi
[url=https://transferairportesfgrdt.com/es/directions/switzerland/geneva/populars/gstaad]transferairportesfgrdt.com/es/directions/switzerland/geneva/populars/gstaad[/url]
Suitable transfer to and from the airport in any rural area of the incredible from the wind broker. Whizz advantage of excessive even at barely satisfactory prices.
transferairportesfgrdt.com/es/directions/thailand/koh-samui/airports/airsamui
canadian drugs [url=https://canadianpharmacy.pro/#]Canadian pharmacy online[/url] safe canadian pharmacies canadianpharmacy.pro
Ежемесячная зарплата красоток, которые работают в данном агентстве, составляет от 20000 долларов и выше http://tvoirostov.ru/blogi/kakim_obrazom_krasivoi_devushke_ustroitsja_na_prestizhnuyu_rabot/
[url=http://ozempic.cyou/]buy rybelsus[/url]
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
https://mexicanpharmacy.win/# buying from online mexican pharmacy mexicanpharmacy.win
india pharmacy mail order [url=https://indianpharmacy.shop/#]indian pharmacy[/url] top 10 online pharmacy in india indianpharmacy.shop
скрытый плинтус алюминиевый [url=http://www.aljumynyevyj-napolnyj-plyntus.ru/]http://www.aljumynyevyj-napolnyj-plyntus.ru/[/url].
мульти сплит система на 2 комнаты [url=https://www.multi-kondicionery.ru/]https://www.multi-kondicionery.ru/[/url].
https://indianpharmacy.shop/# world pharmacy india indianpharmacy.shop
mail order pharmacy india
Выполняем поверку счетчиков воды на дому без снятия. Поверитель в день обращения стоимость поверки счетчиков воды в москве
https://canadianpharmacy.pro/# canadian drug stores canadianpharmacy.pro
[url=http://wegovy.best/]semaglutide over the counter[/url]
mexico pharmacy [url=https://mexicanpharmacy.win/#]mexican online pharmacies prescription drugs[/url] buying prescription drugs in mexico online mexicanpharmacy.win
https://mexicanpharmacy.win/# mexican rx online mexicanpharmacy.win
mexican pharmaceuticals online [url=http://mexicanpharmacy.win/#]Medicines Mexico[/url] buying prescription drugs in mexico mexicanpharmacy.win
напольный плинтус [url=http://www.aljumynyevyj-napolnyj-plyntus.ru/]http://www.aljumynyevyj-napolnyj-plyntus.ru/[/url].
http://indianpharmacy.shop/# top 10 pharmacies in india indianpharmacy.shop
[url=https://ozempic.company/]rybelsus tablets buy[/url]
http://indianpharmacy.shop/# buy prescription drugs from india indianpharmacy.shop
mexico drug stores pharmacies [url=https://mexicanpharmacy.win/#]Mexico pharmacy[/url] mexico pharmacy mexicanpharmacy.win
[url=https://semaglutiderybelsus.com/]rybelsus sale[/url]
служба доставки цветов https://s-buketom.ru/
Укладка плинтуса на пол
Правила установки плинтуса
Подбираем оптимальный плинтус для пола
Плюсы применения плинтуса на пол
Способы укладки плинтус на пол своими руками
Полезные советы по укладке плинтуса на пол
Варианты отделки для пола
Какой плинтус выбрать для разных напольных покрытий
Особенности укладки плинтуса на разных поверхностях
Как выбрать цвет и материал плинтуса для пола
Лучшие способы установки плинтуса на ламинированный пол
Материалы для плинтуса на пол
Декоративные плинтусы пола с помощью плинтуса
Как закрепить плинтус на полу плинтуса для надежной фиксации
Как работают монтажные компании с плинтусами на пол
Самодельные приспособления для монтажа плинтуса на пол
Как избежать ошибок при укладке плинтуса при монтаже плинтуса
Разбираемся с ценами на плинтус для пола
Лучшие бренды плинтусов для пола
Плинтус на пол как элемент дизайна с помощью плинтуса
между полом и стеной [url=https://www.ploskye-plyntusa.ru/]https://www.ploskye-plyntusa.ru/[/url].
https://viagrasansordonnance.pro/# Viagra vente libre allemagne
Красивых девушек вызывают на разные праздники, на которых собирается очень много людей, которые любят зажигательные танцы http://webwel.ru/index.php?subaction=userinfo&user=ijodit
Красивых девушек вызывают на разные праздники, на которых собирается очень много людей, которые любят зажигательные танцы http://letonasumave.eu/2019/07/28/druhy-turnus-primestskeho-tabora/#comment-52253
Viagra homme prix en pharmacie sans ordonnance [url=https://viagrasansordonnance.pro/#]Viagra generique en pharmacie[/url] Viagra homme prix en pharmacie sans ordonnance
Vyacheslav Nikolaev [url=http://www.nikolaev-vyacheslav-konstantinovich.biography-wiki.com/]http://www.nikolaev-vyacheslav-konstantinovich.biography-wiki.com/[/url].
[url=https://wegovy.directory/]semaglutide australia[/url]
Pharmacie en ligne sans ordonnance: Medicaments en ligne livres en 24h – Pharmacie en ligne livraison rapide
acheter mГ©dicaments Г l’Г©tranger [url=http://levitrasansordonnance.pro/#]levitra generique[/url] Pharmacie en ligne pas cher
http://pharmadoc.pro/# pharmacie ouverte
http://cialissansordonnance.shop/# Pharmacies en ligne certifiГ©es
Pharmacie en ligne pas cher
Los casinos línea bono por registro en Chile ofrecen a los jugadores chilenos la oportunidad de probar diferentes juegos sin riesgo. Esta iniciativa ha resultado ser un gran atractivo para aquellos que buscan diversión y emoción en la comodidad de su hogar.
Деревянные дома под ключ
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
Viagra femme sans ordonnance 24h: viagrasansordonnance.pro – Viagra homme sans prescription
[url=https://ozempic.cyou/]buy semaglutide[/url]
Как рассчитать мощность кондиционера перед установкой
vrv daikin [url=http://www.kondicionery-s-ustanovkoj.ru]http://www.kondicionery-s-ustanovkoj.ru[/url].
[url=https://cherepovec.seojazz.ru/]SEO-продвижение сайта[/url] – откройте дверь к новым возможностям. Стратегия, направленная на улучшение видимости, приносит реальные результаты.
[url=http://rybelsus.monster/]semaglutide generic cost[/url]
For all those trying to get a distinctive and enjoyable entertainment expertise, the entire world of striptease inside the north delivers a unique allure https://franciscovckz34556.blogozz.com/24688779/city-center-allure-the-mesmerizing-world-of-striptease
http://pharmadoc.pro/# pharmacie en ligne
For all those trying to get a distinctive and enjoyable entertainment expertise, the entire world of striptease inside the north delivers a unique allure https://rafaelcdzx01100.bloguetechno.com/ordering-enchantment-strippers-tailored-to-your-desires-60168093
Pharmacie en ligne pas cher: Acheter mГ©dicaments sans ordonnance sur internet – п»їpharmacie en ligne
Мы рады предложить большой выбор производственного оборудования, прямые поставки лизинг медицинского оборудования
https://acheterkamagra.pro/# Pharmacie en ligne pas cher
buy generic levitra over the counter levitra 20mg usa
п»їpharmacie en ligne: kamagra livraison 24h – Pharmacie en ligne pas cher
Are you over the hunt for an ideal approach to elevate your future bachelor celebration https://jaredxhpx75296.diowebhost.com/79746944/private-strippers-for-your-intimate-bachelor-gathering
Мы рады предложить большой выбор производственного оборудования, прямые поставки оформить оборудование в лизинг
[url=https://semaglutide.party/]semaglutide 14mg[/url]
Are you over the hunt for an ideal approach to elevate your future bachelor celebration https://connerfoyi29631.xzblogs.com/66316687/strippers-for-unforgettable-bachelor-nights
Как подготовить помещение для установки кондиционера
сплит система кондиционер [url=kondicionery-s-ustanovkoj.ru]kondicionery-s-ustanovkoj.ru[/url].
[url=https://rybelsus.quest/]buy wegovy in canada[/url]
купить с установкой кондиционер [url=http://www.internet-magazin-kondicionerov.ru]http://www.internet-magazin-kondicionerov.ru[/url].
where to get clomid price: can i order generic clomid no prescription – where to get generic clomid without rx
buy clomid 50mg sale clomiphene 50mg usa clomiphene 50mg us
Лизинг оборудования – рейтинг компаний в 2024 году: отзывы, условия, стоимость и быстрое оформление онлайн-заявки лизинг строительного оборудования
Как выбрать и купить кондиционер
купить кондиционер с установкой [url=https://www.ustanovka-split-sistem.ru/]https://www.ustanovka-split-sistem.ru/[/url].
Не просто сайт, а лидер в поиске. [url=https://domodedovo.seojazz.ru/]SEO-продвижение сайтов[/url] – это путь к выдающемуся онлайн-опыту. Оптимизация смыслов, а не слов.
Ремонт телефонов Xiaomi, Haier, Huawei и другие в сервисном центре компании по ремонту телефонов
clomid buy: where can i get generic clomid now – how to get cheap clomid without a prescription
Разблокируйте поток клиентов через [url=https://dzerzhinsk.seojazz.ru/]SEO-продвижение сайтов[/url]. Ваши товары и услуги заслуживают быть на первых местах в поиске.
[url=https://rybelsus.pics/]order semaglutide online[/url]
http://azithromycin.bid/# where can i buy zithromax in canada
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
amoxicillin no prescipion [url=https://amoxicillin.bid/#]buy amoxicillin online no prescription[/url] where to buy amoxicillin 500mg
https://azithromycin.bid/# zithromax purchase online
zithromax 500 mg: zithromax canadian pharmacy – zithromax tablets for sale
купить кондиционер инверторный [url=https://www.internet-magazin-kondicionerov.ru]https://www.internet-magazin-kondicionerov.ru[/url].
[url=http://semaglutide.company/]wegovy 3mg[/url]
[url=http://rybelsus.company/]buy ozempic[/url]
http://clomiphene.icu/# can i buy clomid
Вскрытие замков в любое время суток оперативно экстренная служба вскрытия замков и без повреждений.
zithromax online paypal: zithromax z-pak – can i buy zithromax over the counter in canada
https://modern-design-ideas.com/lego-affiliate-program-best-deals/
[url=http://rybelsus.quest/]ozempic[/url]
http://ivermectin.store/# stromectol coronavirus
[url=http://rybelsustabs.com/]wegovy tab 3mg[/url]
buying prednisone without prescription: buy prednisone online from canada – prednisone cream
amoxicillin medicine [url=http://amoxicillin.bid/#]can i buy amoxicillin over the counter in australia[/url] amoxicillin 500mg prescription
ivermectin over the counter: ivermectin 3 mg dose – ivermectin generic name
[url=http://wegovy.company/]semaglutide tablets for weight loss cost[/url]
Список всех МФО Казахстана https://farsh-cook.ru/
Виниловый сайдинг в интернет-магазине по выгодным ценам https://star-plast.su/ настоящие отзывы покупателей!
Для того чтобы уточнить подробности и купить арматуру необходимого типа, свяжитесь с нашими специалистами купить арматуру
[url=https://habarovsk.seojazz.ru/]SEO-продвижение сайтов[/url] – это подъем на Олимп цифрового мира. Перестройте свой сайт, чтобы он был не просто виден, но и заметен.
Для того чтобы уточнить подробности и купить арматуру необходимого типа, свяжитесь с нашими специалистами арматура композитная стеклопластиковая
get generic clomid no prescription: where to get clomid now – can i order generic clomid without rx
Nikolaev Vyacheslav Konstantinovich [url=http://www.techbullion.com/nikolaev-vyacheslav-konstantinovich]http://www.techbullion.com/nikolaev-vyacheslav-konstantinovich[/url].
https://azithromycin.bid/# buy zithromax canada
prednisone prescription online [url=http://prednisonetablets.shop/#]prednisone tablets canada[/url] ordering prednisone
[url=https://semaglutide.trade/]semaglutide canada[/url]
[url=https://semaglutide.pics/]buy ozempic online pharmacy[/url]
zithromax capsules price: cheap zithromax pills – zithromax for sale cheap
[url=https://semaglutidewegovy.shop/]buy ozempic oversees[/url]
buy zithromax: generic zithromax 500mg – how much is zithromax 250 mg
Как правильно оценить качество монтажа vrf системы?
услуги кондиционирования [url=https://vrf-sistemy.ru]https://vrf-sistemy.ru[/url].
ivermectin australia [url=http://ivermectin.store/#]price of ivermectin[/url] ivermectin purchase
[url=http://rybelsus.monster/]wegovy buy from canada[/url]
https://clomiphene.icu/# where to buy cheap clomid without insurance
generic amoxicillin cost: amoxil pharmacy – amoxicillin 500mg capsule cost
Mostbet bookmaker: review and reviews of players on Mostbet https://www.aspturkiye.com/forum_posts.asp?TID=60836&PN=1
Нужен опытный арбитражный адвокат? Наша команда юристов готова предоставить вам профессиональные услуги в сфере арбитражного процесса http://artem-energo.ru/forums.php?m=posts&q=16126&n=last#bottom
Mostbet bookmaker: review and reviews of players on Mostbet http://sogo.i2i.jp/link_go.php?url=https://mosbet-oficialnyj-sajt.ru
Нужен опытный арбитражный адвокат? Наша команда юристов готова предоставить вам профессиональные услуги в сфере арбитражного процесса http://www.ilmarhit.it/component/kunena/8-international-tenders/409632?Itemid=0#409632
[url=http://wegovy.directory/]semaglutide 14mg tablets[/url]
Пропускайте лето в свое помещение с кондиционером для дома
кондиционеры сплит системы купить [url=https://expert-split.ru]https://expert-split.ru[/url].
where can i get generic clomid without a prescription [url=http://clomiphene.icu/#]where can i buy cheap clomid[/url] how to buy generic clomid online
amoxil pharmacy: amoxicillin 250 mg capsule – purchase amoxicillin online
Какие функции есть у современных кондиционеров
кондиционер мульти сплит система [url=https://magazin-split-sistem.ru]https://magazin-split-sistem.ru[/url].
В нашем интернет-магазине Вы найдете широкий ассортимент медицинских товаров, медоборудования, медицинской техники для дома медицинское оборудование челябинск купить
[url=http://rybelsussemaglutide.online/]rybelsus rx[/url]
[url=http://wegovy.trade/]rybelsus drug[/url]
продвижение яндекс https://seo-con.ru/
Экономичность выбора в пользу кондиционера для дома
кондиционер цена [url=https://www.expert-split.ru/]https://www.expert-split.ru/[/url].
Продажа медицинского оборудования медицинской техники ведущих мировых брендов где можно купить медицинское оборудование
Online medicine order: best india pharmacy – indian pharmacy indianpharm.store
canadian pharmacy: Canadian International Pharmacy – buy drugs from canada canadianpharm.store
Продажа медицинского оборудования медицинской техники ведущих мировых брендов медицинское оборудование в калининграде купить
перетяжка мягкой мебели [url=https://peretyazhka-mebeli-minsk.ru/]https://peretyazhka-mebeli-minsk.ru/[/url].
mexican pharmacy: Certified Pharmacy from Mexico – medicine in mexico pharmacies mexicanpharm.shop
https://canadianpharm.store/# canadian drug canadianpharm.store
Биография Эдуарда Давыдова Давыдов Эдуард генерального директора БСК.
п»їbest mexican online pharmacies: Online Mexican pharmacy – purple pharmacy mexico price list mexicanpharm.shop
canada drugs: onlinecanadianpharmacy – canadian neighbor pharmacy canadianpharm.store
[url=https://ozempic.cyou/]rybelsus semaglutide[/url]
https://mexicanpharm.shop/# reputable mexican pharmacies online mexicanpharm.shop
https://mexicanpharm.shop/# mexican online pharmacies prescription drugs mexicanpharm.shop
mexican pharmaceuticals online: Online Mexican pharmacy – mexican rx online mexicanpharm.shop
canadian pharmacy cheap [url=http://canadianpharm.store/#]Canadian International Pharmacy[/url] canadian pharmacy meds canadianpharm.store
[url=http://pinuputhezin.com]http://pinuputhezin.com[/url]
Pin Up Casino is the valid website of the renowned online casino seeking players from Brazil.
https://www.pinuputhezin.com
https://canadianpharm.store/# online pharmacy canada canadianpharm.store
mexican border pharmacies shipping to usa: Online Mexican pharmacy – mexico pharmacies prescription drugs mexicanpharm.shop
best online canadian pharmacy: Canada Pharmacy online – rate canadian pharmacies canadianpharm.store
license, an M.B.A. degree, and nearly ten years of experience in the cross-border tax field https://www.moredesign.com/five-decor-ideas-for-winter-season/
Помощь опытного адвоката по уголовным делам в Москве адвокат по уголовным преступлениям консультация и план защиты бесплатно! Бывшие сотрудники СК и МВД!
license, an M.B.A. degree, and nearly ten years of experience in the cross-border tax field https://goltogel.info/do-we-use-can-lids-for-fundraisers/
cheapest online pharmacy india [url=https://indianpharm.store/#]international medicine delivery from india[/url] п»їlegitimate online pharmacies india indianpharm.store
reputable canadian pharmacy: Pharmacies in Canada that ship to the US – canadian drugs pharmacy canadianpharm.store
https://mexicanpharm.shop/# reputable mexican pharmacies online mexicanpharm.shop
buying from online mexican pharmacy: Online Pharmacies in Mexico – buying prescription drugs in mexico online mexicanpharm.shop
сео продвижение сайта услуги https://seo-con.ru/optimizaciya-sajta/
absorica online order isotretinoin for sale order accutane 40mg without prescription
http://canadianpharm.store/# canadian mail order pharmacy canadianpharm.store
[url=http://ozempic.cfd/]buy semaglutide online from india[/url]
mail order pharmacy india [url=http://indianpharm.store/#]international medicine delivery from india[/url] indian pharmacy indianpharm.store
https://indianpharm.store/# indianpharmacy com indianpharm.store
world pharmacy india: international medicine delivery from india – india pharmacy mail order indianpharm.store
[url=https://semaglutide.cyou/]semaglutide xl[/url]
В Москве занимаются решением текущих проблем в доме, обеспечением благоустройства территории и охраны общего имущества жкх управляющая компания
[url=http://rybelsus.quest/]semaglutide 3 mg[/url]
ventolin inhalator without prescription albuterol buy online buy albuterol pill
https://indianpharm.store/# indian pharmacy paypal indianpharm.store
Граждане России приобретают гражданство Киргизской республики по упрощенной схеме гражданство киргизии по рождению в ссср Быстрое получение Гражданства Киргизии для Россиян от Юридической Компании Быстро и с Гарантией. Гражданство Киргизии для Граждан России (по упрощенному варианту) Мы Поможем Получить Гражданство Киргизии, Водительские Права Киргизии, Открыть частные счета в Банках Киргизии, Зарегистрировать Компанию в Киргизии, Получить заграничные паспорта в Киргизии!
mexican mail order pharmacies: Online Pharmacies in Mexico – п»їbest mexican online pharmacies mexicanpharm.shop
Граждане России приобретают гражданство Киргизской республики по упрощенной схеме гражданство киргизии что дает Быстрое получение Гражданства Киргизии для Россиян от Юридической Компании Быстро и с Гарантией. Гражданство Киргизии для Граждан России (по упрощенному варианту) Мы Поможем Получить Гражданство Киргизии, Водительские Права Киргизии, Открыть частные счета в Банках Киргизии, Зарегистрировать Компанию в Киргизии, Получить заграничные паспорта в Киргизии!
http://mexicanpharm.shop/# medication from mexico pharmacy mexicanpharm.shop
reputable canadian pharmacy [url=https://canadianpharm.store/#]Canadian Pharmacy[/url] cheap canadian pharmacy online canadianpharm.store
Поиграй с Раменбет. Получай мощные бонусы участвуй в недельных турнирах, получай ценные выигрыши. Вход через [url=https://justop.ru/]Актуальное зеркало Раменбет[/url]. Бонус при первом балансе до двухсот тыс. руб. плюс 250 вращений для новеньких! Участвуй в программе лояльности. VIP-статус дает кэшбек до 15%.
Все твои любимые игры доступны у нас: более 1000 автоматов от всех топовых провайдеров. Лайв дилеры, карточные столы, лотереи и спорт. Короче, заваривай рамен и давай к нам на [url=https://justop.ru/]Официальное зеркало Ramenbet[/url]
https://indianpharm.store/# indianpharmacy com indianpharm.store
Envi broker
Если вы ищете доступное и надежное приобретение диплома, обратитесь к нам на сайт http://kupit-diplom1.com. Мы обеспечиваем высокое качество и доставку от производителя.
online canadian pharmacy: Canada Pharmacy online – thecanadianpharmacy canadianpharm.store
canadian pharmacy meds [url=http://canadianpharm.store/#]Certified Online Pharmacy Canada[/url] canada discount pharmacy canadianpharm.store
http://indianpharm.store/# world pharmacy india indianpharm.store
[url=http://semaglutidetabs.com/]rybelsus rx[/url]
Vervolgens ga dan naar onze website en Chat Meisjes zullen u helpen bij het vinden van een vrouw vanavond http://flirt888.com
Vervolgens ga dan naar onze website en Chat Meisjes zullen u helpen bij het vinden van een vrouw vanavond http://live24sex.net
buying prescription drugs in mexico online: Certified Pharmacy from Mexico – mexico pharmacies prescription drugs mexicanpharm.shop
обивочные ткани [url=https://www.vinylko13.ru/]https://www.vinylko13.ru/[/url] .
online canadian pharmacy [url=http://canadianpharm.store/#]Canadian Pharmacy[/url] canada drug pharmacy canadianpharm.store
Кто и на каких условия может получить гражданство Киргизии гражданство киргизии от Юридической Компании Быстро и с Гарантией. Гражданство Киргизии для Граждан России (по упрощенному варианту) Мы Поможем Получить Гражданство Киргизии, Водительские Права Киргизии, Открыть частные счета в Банках Киргизии, Зарегистрировать Компанию в Киргизии, Получить заграничные паспорта в Киргизии!
mexican rx online: Certified Pharmacy from Mexico – best online pharmacies in mexico mexicanpharm.shop
https://indianpharm.store/# india pharmacy mail order indianpharm.store
線上賭場
**娛樂城與線上賭場:現代娛樂的轉型與未來**
在當今數位化的時代,”娛樂城”和”線上賭場”已成為現代娛樂和休閒生活的重要組成部分。從傳統的賭場到互聯網上的線上賭場,這一領域的發展不僅改變了人們娛樂的方式,也推動了全球娛樂產業的創新與進步。
**起源與發展**
娛樂城的概念源自於傳統的實體賭場,這些場所最初旨在提供各種形式的賭博娛樂,如撲克、輪盤、老虎機等。隨著時間的推移,這些賭場逐漸發展成為包含餐飲、表演藝術和住宿等多元化服務的綜合娛樂中心,從而吸引了來自世界各地的遊客。
隨著互聯網技術的飛速發展,線上賭場應運而生。這種新型態的賭博平台讓使用者可以在家中或任何有互聯網連接的地方,享受賭博遊戲的樂趣。線上賭場的出現不僅為賭博愛好者提供了更多便利與選擇,也大大擴展了賭博產業的市場範圍。
**特點與魅力**
娛樂城和線上賭場的主要魅力在於它們能提供多樣化的娛樂選項和高度的可訪問性。無論是實體的娛樂城還是虛擬的線上賭場,它們都致力於創造一個充滿樂趣和刺激的環境,讓人們可以從日常生活的壓力中短暫逃脫。
此外,線上賭場通過提供豐富的遊戲選擇、吸引人的獎金方案以及便捷的支付系統,成功地吸引了全球範圍內的用戶。這些平台通常具有高度的互動性和社交性,使玩家不僅能享受遊戲本身,還能與來自世界各地的其他玩家交流。
**未來趨勢**
隨著技術的不斷進步和用戶需求的不斷演變,娛樂城和線上賭場的未來發展呈現出多元化的趨勢。一方面,虛
擬現實(VR)和擴增現實(AR)技術的應用,有望為線上賭場帶來更加沉浸式和互動式的遊戲體驗。另一方面,對於實體娛樂城而言,將更多地注重提供綜合性的休閒體驗,結合賭博、娛樂、休閒和旅遊等多個方面,以滿足不同客群的需求。
此外,隨著對負責任賭博的認識加深,未來娛樂城和線上賭場在提供娛樂的同時,也將更加注重促進健康的賭博行為和保護用戶的安全。
總之,娛樂城和線上賭場作為現代娛樂生活的一部分,隨著社會的發展和技術的進步,將繼續演化和創新,為人們提供更多的樂趣和便利。這一領域的未來發展無疑充滿了無限的可能性和機遇。
[url=https://semaglutidewegovy.com/]ozempic cost[/url]
[url=http://semaglutide.quest/]buy ozempic[/url]
recommended canadian online pharmacies: prescriptions from canada without – online medications
canadian meds no prescription [url=http://canadadrugs.pro/#]discount pharmaceuticals[/url] order prescription medicine online without prescription
http://canadadrugs.pro/# my canadian pharmacy online
Fantastic info Thanks a lot
купить диплом о среднем специальном
###GOOGLE###
rg777
rg777
Бурим,настоящее имя Андрей Бурим, известен своими трансляциями в чат-рулетке и разгульным стилем жизни. Он прославился благодаря своему контенту, который включал в себя взаимодействие с аудиторией в реальном времени. Вопреки юридические проблемы и критику, Меллстрой продолжал совершенствовать свой формат, перейдя к “life-контенту”. Коммьюнити Меллстроя, известное как “Боровы”, активно участвует в его стримах, что помогает росту его популярности и финансовому успеху. Более подробную информацию можно найти в статье здесь https://mellstroy.co/strim-rinatkino-tv-zadanie-v-opisanii-stream-podpischiki-rinatkino-tv/. Добро пожаловть!
[url=http://semaglutideozempic.shop/]rybelsus 14[/url]
Увеличьте свою онлайн-присутствие с нашим [url=https://ivanteevka.seojazz.ru/]SEO-продвижением[/url]! Мы оптимизируем контент, проводим анализ конкурентов и делаем ваш сайт заметным для поисковых систем.
http://canadadrugs.pro/# canadian pharmaceuticals online
canadian online pharmacy for viagra [url=http://canadadrugs.pro/#]buy online prescription drugs[/url] giant discount pharmacy
Набридло відпочивати? Відвідайте пін ап
казіно на реальні гроші https://pinupcasinolfsesn.kiev.ua/ .
Станьте лидером в поисковых результатах! Наши эксперты по [url=https://himki.seojazz.ru/]SEO-продвижению[/url] помогут вашему сайту достичь высших позиций, привлекая целевую аудиторию.
legal canadian pharmacy online: accutane mexican pharmacy – prescription online
[url=http://semaglutidewegovy.shop/]wegovy 3 mg[/url]
Давыдов Эдуард [url=http://eduard-davydov.ru/]http://eduard-davydov.ru/[/url] .
Мечтай о пин-ап казино
cassinos online http://pinupcasinojenzolo.com/.
http://canadadrugs.pro/# canadian mail order viagra
娛樂城
canadian pharmaceutical companies that ship to usa [url=https://canadadrugs.pro/#]safe canadian pharmacy[/url] canadian generic pharmacy
Купить диплом по выгодной цене тут http://diplom-sale.ru/ проще всего. Гарантируем подлинность и прохождение любых проверок.
[url=https://semaglutidetabs.shop/]wegovy tablets for weight loss cost[/url]
http://canadadrugs.pro/# most trusted canadian online pharmacy
mexican pharmacies [url=http://canadadrugs.pro/#]discount pharmacies[/url] ed meds online without doctor prescription
https://canadadrugs.pro/# online pharmacy usa
Рекомендую обратить внимание на https://altaystroy.ru/ – специализированный веб-ресурс, который предоставляет ценную информацию для строительных компаний, производителей материалов и обычных потребителей. Здесь вы найдете последние новости, обзоры технологий и советы по использованию бетона и цемента в строительстве.
Разбираем заработок в интернете: за что платят деньги в Сети, какой доход можно получать и что нужно для старта доход в интернете
list of mexican pharmacies: canadian pharmacy worldwide – canadian drugstore viagra
http://canadadrugs.pro/# canadian pharmacy certified
online canadian pharmaceutical companies: mail order prescription drugs from canada – online prescriptions without a doctor
[url=https://ozempic.cfd/]rybelsus medication[/url]
Официальный сервис Krups по ремонту. Профессиональный ремонт любых типов кофемашин krups ea82 ремонт
Официальный сервис Krups по ремонту. Профессиональный ремонт любых типов кофемашин ремонт гидроцилиндра кофемашины крупс
https://canadadrugs.pro/# canadian pharmacies no prescription needed
pharmacy review [url=https://canadadrugs.pro/#]online pharmacy medications[/url] approved canadian pharmacies online
buy levothroid generic levothroid canada generic levothyroxine
[url=https://rybelsustabs.online/]rybelsus canada pharmacy[/url]
http://canadadrugs.pro/# canada pharmacies online
[url=https://shlemsnidf.dp.ua/p-shlem-ls2-ff808-sream-ii-solid-white/]shlemsnidf.dp.ua/p-shlem-ls2-ff808-sream-ii-solid-white/[/url]
Мотошлемы популярных марок в течение наличии в течение широком наборе а также капля доставкой по Украине.
shlemsnidf.dp.ua/p-shlem-shark-evo-one-2-black-mat/
http://canadadrugs.pro/# canadian online pharmacy
canadian trust pharmacy: list of online canadian pharmacies – ed meds online
Virtueel nummer, een telefoonnummer dat bestaat zonder fysieke aansluiting op een telefoonlijn https://trevorepvz09592.mybjjblog.com/virtueel-nummer-voor-altijd-38683994
Virtueel nummer, een telefoonnummer dat bestaat zonder fysieke aansluiting op een telefoonlijn https://zandergnbf91013.bloggosite.com/31008471/virtueel-nummer-voor-altijd
какие документы нужны для аренды машины в испании
reputable canadian mail order pharmacy: mail order pharmacy list – canadian pharmaceuticals for usa sales
камины домашние
[url=https://shlemsnidf.dp.ua/p-shlem-mt-targo-pro-sound-flou-red/]shlemsnidf.dp.ua/p-shlem-mt-targo-pro-sound-flou-red/[/url]
Мотошлемы популярных марок в течение наличии в широком наборе а также начиная с. ant. до доставкой по Украине.
shlemsnidf.dp.ua/p-shlem-fox-v1-mips-skew-gold/
https://nowewyrazy.uw.edu.pl/profil/plotnikowploton
online pharmacy medications: canada pharmaceutical online ordering – prescription drug discounts
More information about your request is here https://yao-dao.com/Account/ChangeLanguage?culture=en-GB&location=https://tropicexotic.ca/
https://canadadrugs.pro/# drugs without a doctor s prescription
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
prescription drug price comparison: compare prices prescription drugs – canadian prescriptions
semaglutide canada pharmacy prices
[url=http://semaglutide.monster/]rybelsus online order[/url]
тест4.
https://canadadrugs.pro/# cheap canadian cialis
overseas pharmacies that deliver to usa [url=https://canadadrugs.pro/#]mexican pharmacy online medications[/url] compare medication prices
rybelsus tab 14mg
cheapest online pharmacy india: indian pharmacy online – indianpharmacy com
Евтушенков Феликс биография и последние новости феликс евтушенков афк система
pharmacies in mexico that ship to usa: mexican pharmaceuticals online – purple pharmacy mexico price list
Online medicine order: reputable indian pharmacies – Online medicine order
rybelsus tablets cost
mexican drugstore online mexico pharmacy mexican pharmacy
http://medicinefromindia.store/# indian pharmacies safe
предметный фотограф https://predmetnaya-fotosyomka-1.ru/
Официальный сайт Гама радует своих поклонников оригинальным стильным оформлением, грамотной структурой меню и разнообразием направлений в играх Гама казино
canada ed drugs: legitimate canadian pharmacy – canadapharmacyonline
http://canadianinternationalpharmacy.pro/# canadian pharmacy ed medications
http://canadianinternationalpharmacy.pro/# canadian pharmacy online ship to usa
ways to get money fast
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
ed medications list: cheapest ed pills – cheap erectile dysfunction pills online
mexican online pharmacies prescription drugs mexican pharmacy buying prescription drugs in mexico online
Родился 10 июля 1984 в Нальчике Кабардино-Балкарской Республики. Отец – ученый-химик, сотрудник лаборатории Кабардино-Балкарского государственного университета; мать – медсестра в поликлинике Эдуард Давыдов
Заказать и получить легальный диплом института можно у нас на сайте [URL=https://diplomguru.com]https://diplomguru.com[/URL]. Мы предлагаем надежность и выгодные условия.
https://canadianinternationalpharmacy.pro/# buy prescription drugs from canada cheap
На рабочем совещании по перспективам развития АО «БСК» под председательством главы РБ Радия Хабирова в модернизацию трех производственных площадок Эдуард Давыдов
rybelsus buy from canada
ozempic tablets for weight loss cost
https://edwithoutdoctorprescription.pro/# non prescription erection pills
Online medicine order buy prescription drugs from india indian pharmacy online
neurontin 800mg for sale neurontin 100mg generic buy neurontin pill
Темная сторона интернета, является, невидимую, платформу, в, интернете, подключение, осуществляется, путем, специальные, приложения и, инструменты, обеспечивающие, конфиденциальность участников. Один из, подобных, средств, является, The Onion Router, позволяет, предоставляет, безопасное, вход в сеть Даркнет. С, его, сетевые пользователи, могут, безопасно, обращаться к, веб-сайты, не индексируемые, стандартными, поисками, что делает возможным, среду, для осуществления, разносторонних, нелегальных деятельностей.
Киберторговая площадка, в свою очередь, часто упоминается в контексте, скрытой сетью, в качестве, площадка, для торговли, киберугрозами. На этой площадке, имеется возможность, купить, разные, непозволительные, услуги, начиная с, наркотиков и оружия, вплоть до, услугами хакеров. Система, предоставляет, высокую степень, шифрования, а также, защиты личной информации, это, делает, данную систему, интересной, для тех, кто, желает, уклониться от, наказания, от органов порядка
Даркнет, является, анонимную, платформу, в, сети, доступ к которой, осуществляется, путем, специальные, программы плюс, технические средства, обеспечивающие, невидимость пользователей. Одним из, подобных, средств, представляется, The Onion Router, который обеспечивает, обеспечивает, приватное, подключение, к сети Даркнет. Используя, его, сетевые пользователи, имеют шанс, безопасно, обращаться к, сайты, не видимые, традиционными, поисками, создавая тем самым, среду, для проведения, различных, противоправных действий.
Крупнейшая торговая площадка, в результате, часто упоминается в контексте, скрытой сетью, как, торговая площадка, для, криминалитетом. На этом ресурсе, имеется возможность, приобрести, разные, нелегальные, товары, начиная, наркотиков и стволов, заканчивая, услугами хакеров. Система, предоставляет, крупную долю, криптографической защиты, а также, анонимности, это, создает, эту площадку, интересной, для тех, кто, стремится, избежать, преследований, со стороны соответствующих правоохранительных органов.
http://edpill.cheap/# best erection pills
Эдуард Давыдов проявил активность в экологической сфере, внедряя проекты, направленные на сокращение вредных выбросов и улучшение окружающей среды Давыдов Эдуард
Зеркало Гама казино — это передовая платформа для онлайн-игр, которая предлагает захватывающий опыт, наполненный великолепной графикой, реалистичными звуковыми эффектами и простыми в использовании элементами управления казино Гама
Зеркало Гама казино — это передовая платформа для онлайн-игр, которая предлагает захватывающий опыт, наполненный великолепной графикой, реалистичными звуковыми эффектами и простыми в использовании элементами управления казино гама зеркало
reputable indian online pharmacy world pharmacy india top 10 pharmacies in india
wegovy 14mg tablets
https://araks-group.ru/volna-kazino/
Тренинги по продажам и переговорам для менеджеров, руководителей отдела продаж под ключ отдел продаж под ключ
http://edwithoutdoctorprescription.pro/# best non prescription ed pills
Тренинги по продажам и переговорам для менеджеров, руководителей отдела продаж под ключ тренинг по продажам для менеджеров
Качественная имплантация в Сочи под ключ, статья о лучшей стоматологии для имплантации имплантация зубов
Нужно получить смс на виртуальный номер? Бесплатные виртуальные номера онлайн для получения кодов верификации аренда номера телефона
cheapest online pharmacy india top 10 online pharmacy in india mail order pharmacy india
brand semaglutide
Нужно получить смс на виртуальный номер? Бесплатные виртуальные номера онлайн для получения кодов верификации арендовать номер телефона
https://certifiedpharmacymexico.pro/# best mexican online pharmacies
order wegovy
http://medicinefromindia.store/# top 10 online pharmacy in india
bwin indir – Online Bahis Şirketi
Получи права управления автомобилем в лучшей автошколе!
Стремись к профессиональной карьере автолюбителя с нашей автошколой!
Пройди обучение в лучшей автошколе города!
Учись правильного вождения с нашей автошколой!
Стремись к безупречным навыкам вождения с нашей автошколой!
Научись уверенно водить автомобиль с нами в автошколе!
Достигай независимости и свободы, получив права в автошколе!
Прояви мастерство вождения в нашей автошколе!
Открой новые возможности, получив права в автошколе!
Запиши друзей и они получат скидку на обучение в автошколе!
Стремись к профессиональному будущему в автомобильном мире с нашей автошколой!
знакомства и научись водить автомобиль вместе с нашей автошколой!
Развивай свои навыки вождения вместе с опытными инструкторами нашей автошколы!
Закажи обучение в автошколе и получи бесплатный консультационный урок от наших инструкторов!
Стремись к надежности и безопасности на дороге вместе с нашей автошколой!
Улучши свои навыки вождения вместе с лучшими в нашей автошколе!
Завоевывай дорожные правила и навыки вождения в нашей автошколе!
Стань настоящим мастером вождения с нашей автошколой!
Накопи опыт вождения и получи права в нашей автошколе!
Пробей дорогу вместе с нами – закажи обучение в автошколе!
автошкола навчання http://www.avtoshkolaznit.kiev.ua .
best ed treatment men’s ed pills treatments for ed
http://edwithoutdoctorprescription.pro/# legal to buy prescription drugs from canada
indianpharmacy com: indian pharmacies safe – mail order pharmacy india
1win Регистрация на официальном сайте 1вин. Как зарегистрироваться в 1win БК 1win позаботился о создании удобного, функционального сайта для своих клиентов 1win сайт
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1 win
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1 win
levitra without a doctor prescription prescription drugs online without doctor viagra without a doctor prescription
wegovy sale
ozempic tablets buy
https://zeenews.india.com/india/boosting-views-on-youtube-how-to-use-it-as-a-strategy-to-increase-popularity-2718756.html
https://certifiedpharmacymexico.pro/# reputable mexican pharmacies online
mens erection pills otc ed pills ed medication online
Достигни права управления автомобилем в первоклассной автошколе!
Стремись к профессиональной карьере автолюбителя с нашей автошколой!
Успей пройти обучение в самой автошколе города!
Задай тон правильного вождения с нашей автошколой!
Стань безупречным навыкам вождения с нашей автошколой!
Научись уверенно водить автомобиль с нами в автошколе!
Стремись к независимости и лицензии, получив права в автошколе!
Прояви мастерство вождения в нашей автошколе!
Открой новые возможности, получив права в автошколе!
Запиши друзей и они получат скидку на обучение в автошколе!
Стремись к профессиональному будущему в автомобильном мире с нашей автошколой!
Заводи и научись водить автомобиль вместе с нашей автошколой!
Развивай свои навыки вождения вместе с опытными инструкторами нашей автошколы!
Запиши обучение в автошколе и получи бесплатный консультационный урок от наших инструкторов!
Достигни надежности и безопасности на дороге вместе с нашей автошколой!
Улучши свои навыки вождения вместе с профессионалами в нашей автошколе!
Учись дорожные правила и навыки вождения в нашей автошколе!
Стремись к настоящим мастером вождения с нашей автошколой!
Набери опыт вождения и получи права в нашей автошколе!
Покори дорогу вместе с нами – пройди обучение в автошколе!
автошкола варшавська https://avtoshkolaznit.kiev.ua .
Желаете достать диплом без промедления и без заморочек? В Москве имеется изобилие вариантов приобрести аттестат о высшем образовании – diplom4.me. Специализированные исключительно агентства предлагают сервисы по покупке документов от различных учебных заведений. Обращайтесь к непреложным поставщикам и завершите свой диплом сегодня!
[url=https://test2semrush.net/]тест 2[/url].
Online medicine order top 10 pharmacies in india online pharmacy india
Что такое Гама Казино. Gama Casino – это онлайн казино, основанное в 2020 году, которое предлагает игрокам возможность играть в самые популярные игры от ведущих разработчиков Гама казино
Официальный сайт 1WIN казино позволяет игрокам запускать азартные игры, получать бонусы, участвовать в турнирах 1Win
Что такое Гама Казино. Gama Casino – это онлайн казино, основанное в 2020 году, которое предлагает игрокам возможность играть в самые популярные игры от ведущих разработчиков казино гама зеркало
https://edwithoutdoctorprescription.pro/# how to get prescription drugs without doctor
ozempic for weight loss without diabetes
Наслаждайтесь азартными играми в Cat Casino и не пропустите новинки. Честные игры залог твоего успеха. Удача на твоей стороне в Супер Турнирах кэт казино зеркало
mexico pharmacies prescription drugs mexican border pharmacies shipping to usa buying from online mexican pharmacy
Растите вместе с нами благодаря [url=https://prokopevsk.seojazz.ru/]SEO-продвижению[/url]. Наш опыт поможет вашему сайту выделиться в поисковых результатах, привлекая новых клиентов и увеличивая прибыль.
semaglutide for sale online rybelsus pills purchase rybelsus pill
Развивайте свой бизнес с [url=https://ozyorsk.seojazz.ru/]SEO-продвижением сайтов[/url]. Мы создаем стратегии, максимизирующие видимость вашего ресурса в поисковых системах, увеличивая трафик и продажи.
https://edpill.cheap/# ed medication
generic semaglutide for weight loss
Казино 1Вин удобен для игроков, работает на ПК и телефоне. Для мобильников создана mobile version и приложение для iphone и android ван вин казино
https://medicinefromindia.store/# reputable indian online pharmacy
Казино 1Вин удобен для игроков, работает на ПК и телефоне. Для мобильников создана mobile version и приложение для iphone и android 1вин казино
Пo paзpaбoткaм Института Лингвистико — Волновой генетики П. П. Гаряева — было создано направление в квантово-информационной медицине https://bioquant-garyaev.com/product/svechi-volnovye-rektalnye-onda-r/
Пo paзpaбoткaм Института Лингвистико — Волновой генетики П. П. Гаряева — было создано направление в квантово-информационной медицине https://bioquant-garyaev.com/product/biomatricza-garyaeva-kik-3/
вызвать сантехника краснодар https://keramogranit-krasnodar.ru/
http://canadianinternationalpharmacy.pro/# canadian pharmacy phone number
mexico drug stores pharmacies: mexican border pharmacies shipping to usa – medication from mexico pharmacy
mexico drug stores pharmacies reputable mexican pharmacies online buying prescription drugs in mexico online
buy ozempic online cheap
Аренда фотостудии: Идеальное место для создания качественных фотографий – просторная и уютная фотостудия с профессиональным оборудованием и удобным расположением fresh studio
Hipotekines paskolos isduodamos turintiems bloga kredito istorija! Skubios paskolos verslui paskola verslui
wegovy tab 3mg
Привет, участники форума! Расскажу вам об волнующем опыте в игорном заведении [url=http://svetlyachok67.ru/]игра авиатор вся правда об 1win игра реальный авиатор[/url]. Тут всякая поставленная сумма – полет в воздушные просторы волнения, снабженный увлекательными играми и великолепными бонусами. Отзывчивая поддержка, разнообразие слотов и безопасные финансовые операции – вот что делает данное игорное заведение реальным лидером. Опробуйте сами, и вы узнаете, что небеса удачи могут быть гораздо ближе, чем вы думаете!
rybelsus uk
buying from online mexican pharmacy medicine in mexico pharmacies mexican online pharmacies prescription drugs
best online pharmacies in mexico mexican online pharmacies prescription drugs reputable mexican pharmacies online
В Москве закупка свидетельства http://www.diplomsuper.net – это полезный и быстрый вариант законного подтверждения учебы. Многочисленные компании предоставляют опции по производству письменных материалов учитывая разнообразных запросов и специализаций специализации, гарантируя клиентам удобство и надежность.
rybelsus 14
buying prescription drugs in mexico medication from mexico pharmacy buying prescription drugs in mexico online
buying from online mexican pharmacy medication from mexico pharmacy pharmacies in mexico that ship to usa
Незнаю как вы, но я делал косметический ремонт инстременты брал тут https://vega-snab.ru/
Добрый день делал косметический ремонт смеси купил тут https://vega-snab.ru/
Добрый день делал косметический ремонт инстременты брал тут https://vega-snab.ru/
Win big with these popular real money games in Kenya
online casino games that pay real money [url=https://realmoneygameskenya.com/]games that pay real money in kenya[/url] .
medicine in mexico pharmacies mexican border pharmacies shipping to usa mexican border pharmacies shipping to usa
Timepieces World
Client Feedback Shine light on WatchesWorld Adventure
At WatchesWorld, client contentment isn’t just a goal; it’s a bright evidence to our loyalty to superiority. Let’s plunge into what our esteemed buyers have to say about their journeys, revealing on the faultless support and exceptional timepieces we offer.
O.M.’s Review Feedback: A Effortless Adventure
“Very good interaction and follow along throughout the procedure. The watch was perfectly packed and in mint condition. I would certainly work with this crew again for a timepiece buy.
O.M.’s declaration demonstrates our devotion to communication and precise care in delivering clocks in flawless condition. The reliance forged with O.M. is a pillar of our customer bonds.
Richard Houtman’s Perceptive Review: A Personal Reach
“I dealt with Benny, who was extremely helpful and gracious at all times, keeping me frequently notified of the procession. Moving forward, even though I ended up sourcing the timepiece locally, I would still certainly recommend Benny and the company moving forward.
Richard Houtman’s encounter showcases our tailored approach. Benny’s assistance and constant communication exhibit our loyalty to ensuring every customer feels appreciated and notified.
Customer’s Efficient Support Testimonial: A Uninterrupted Deal
“A very efficient and effective service. Kept me updated on the order advancement.
Our loyalty to streamlining is echoed in this buyer’s commentary. Keeping buyers notified and the smooth development of transactions are integral to the Our Watch Boutique experience.
Discover Our Current Offerings
Audemars Piguet Royal Oak Selfwinding 37mm
An exquisite piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your trolley and elevate your assortment.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a fusion of design and novelty, awaiting your application.
рецепты на каждый день https://kulnr.ru/
Csatlakozz a Mostbet-hez es erezd a sportfogadas es online kaszino izgalmas vilagat https://www.deviantart.com/mosbetbd
Заказать и купить диплом колледжа без предоплаты у нас diplom-sale.ru можно с доставкой прямо в руки.
mexican drugstore online mexican rx online reputable mexican pharmacies online
buying from online mexican pharmacy mexican pharmaceuticals online buying prescription drugs in mexico
купить диплом цена [url=http://www.prema-diploms.com/]http://www.prema-diploms.com/[/url] .
buy semaglutide online pharmacy
semaglutide for diabetes
прикольные поздравления с днем рождения на телефон https://na-telefon.biz/
Мониторинг обменников, который предоставляет самую свежую информацию о курсах многих ведущих ручных и автоматических обменных пунктов криптовалют Онлайн обменники
Мониторинг обменников, который предоставляет самую свежую информацию о курсах многих ведущих ручных и автоматических обменных пунктов криптовалют Мониторинг обменников
мосты для tor browser список
В пределах века цифровых технологий, при цифровые границы сливаются с реальностью, не допускается игнорировать возможность угроз в теневом интернете. Одним из рисков является blacksprut – понятие, ставший символом противозаконной, вредоносной деятельности в скрытых уголках интернета.
Blacksprut, будучи составной частью подпольной сети, представляет серьезную угрозу для безопасности в сети и личной устойчивости пользователей. Этот закрытый уголок сети зачастую ассоциируется с незаконными сделками, торговлей запрещенными товарами и услугами, а также прочими противозаконными деяниями.
В борьбе с угрозой blacksprut необходимо приложить усилия на разносторонних фронтах. Одним из ключевых направлений является совершенствование технологий защиты в сети. Развитие продвинутых алгоритмов и технологий анализа данных позволит обнаруживать и пресекать деятельность blacksprut в реальном времени.
Помимо цифровых мер, важна согласованность усилий органов правопорядка на мировом уровне. Международное сотрудничество в секторе защиты в сети необходимо для эффективного исключения угрозам, связанным с blacksprut. Обмен знаний, создание совместных стратегий и реактивные действия помогут снизить воздействие этой угрозы.
Образование и просвещение также играют важное значение в борьбе с blacksprut. Повышение информированности пользователей о рисках подпольной сети и методах предупреждения становится неотъемлемой составной частью антиспампинговых мероприятий. Чем более информированными будут пользователи, тем меньше возможность попадания под влияние угрозы blacksprut.
В заключение, в борьбе с угрозой blacksprut необходимо комбинировать усилия как на цифровом, так и на законодательном уровнях. Это серьезное испытание, подразумевающий совместных усилий граждан, служб безопасности и IT-компаний. Только совместными усилиями мы сможем создания безопасного и защищенного цифрового пространства для всех.
Тор-обозреватель является мощным инструментом для сбережения конфиденциальности и защиты в сети. Однако, иногда пользователи могут столкнуться с трудностями доступа. В настоящей публикации мы изучим возможные предпосылки и предложим способы решения для устранения препятствий с входом к Tor Browser.
Проблемы с сетью:
Решение: Проверка ваше соединение с сетью. Убедитесь, что вы в сети к сети, и отсутствует проблем с вашим поставщиком интернет-услуг.
Блокировка Тор-инфраструктуры:
Решение: В некоторых частных государствах или сетях Tor может быть ограничен. Испытайте использовать проходы для преодоления ограничений. В настройках конфигурации Tor Browser выделите “Проброс мостов” и соблюдайте инструкциям.
Прокси-серверы и брандмауэры:
Решение: Проверка настройки прокси-серверов и файервола. Проверьте, что они не ограничивают доступ Tor Browser к вебу. Измени те установки или временно деактивируйте прокси и стены для испытания.
Проблемы с самим браузером:
Решение: Проверьте, что у вас присутствует актуальная версия Tor Browser. Иногда актуализации могут решить сложности с подключением. Также попробуйте пересобрать приложение.
Временные отказы в Тор сети:
Решение: Подождите некоторое время некоторое время и попробуйте войти впоследствии. Временные сбои в работе Tor могут происходить, и те как правило преодолеваются в кратчайшие периоды.
Отключение JavaScript:
Решение: Некоторые из них веб-сайты могут блокировать доступ через Tor, если в вашем веб-обозревателе включен JavaScript. Попытайтесь временно остановить JavaScript в настройках конфигурации программы.
Проблемы с антивирусным ПО:
Решение: Ваш антивирусная программа или файервол может блокировать Tor Browser. Убедитесь, что у вас не установлено блокировок для Tor в конфигурации вашего антивируса.
Исчерпание памяти:
Решение: Если у вас запущено большое количество окон или задачи, это может привести к разряду памяти и трудностям с подключением. Закрытие лишние веб-страницы или перезапустите программу.
В случае, если затруднение с входом к Tor Browser продолжает, свяжитесь за поддержкой и помощью на официальной платформе обсуждения Tor. Эксперты имеют возможность подсказать дополнительную поддержку и советы. Запомните, что безопасность и анонимность требуют постоянного внимательного отношения к мелочам, следовательно учитывайте актуализациями и применяйте рекомендациям сообщества по использованию Tor.
buy plaquenil 200mg sale plaquenil where to buy order plaquenil 200mg generic
mexican online pharmacies prescription drugs buying from online mexican pharmacy pharmacies in mexico that ship to usa
mexico drug stores pharmacies mexico pharmacy purple pharmacy mexico price list
buy ozempic
Не ошибитесь с выбором: какую ремонтную смесь выбрать для домашних работ
компании строительных материалов http://www.remontnaja-smes-dlja-kirpichnoj-kladki.ru/ .
semaglutide weight loss
mexican pharmaceuticals online pharmacies in mexico that ship to usa mexican pharmaceuticals online
Рулонный газон: где купить качественный материал?
заказать рулонный газон [url=https://rulonnyj-gazon77.ru/]https://rulonnyj-gazon77.ru/[/url] .
Wristwatches Globe
Client Comments Illuminate Timepieces Universe Adventure
At Our Watch Boutique, customer satisfaction isn’t just a goal; it’s a shining testament to our commitment to perfection. Let’s dive into what our esteemed patrons have to share about their adventures, revealing on the perfect assistance and exceptional timepieces we offer.
O.M.’s Trustpilot Review: A Uninterrupted Trip
“Very good comms and follow through throughout the procedure. The watch was perfectly packed and in mint condition. I would surely work with this team again for a timepiece buy.
O.M.’s commentary demonstrates our devotion to comms and meticulous care in delivering watches in flawless condition. The reliance established with O.M. is a pillar of our patron relations.
Richard Houtman’s Insightful Review: A Private Reach
“I dealt with Benny, who was extremely beneficial and gracious at all times, keeping me regularly updated of the process. Moving forward, even though I ended up sourcing the timepiece locally, I would still certainly recommend Benny and the firm in the future.
Richard Houtman’s encounter spotlights our individualized approach. Benny’s assistance and uninterrupted interaction display our loyalty to ensuring every customer feels valued and updated.
Customer’s Effective Service Review: A Smooth Transaction
“A very excellent and productive service. Kept me informed on the transaction advancement.
Our dedication to streamlining is echoed in this patron’s input. Keeping buyers informed and the uninterrupted advancement of transactions are integral to the Our Watch Boutique adventure.
Discover Our Most Recent Collections
Audemars Piguet Royal Oak Selfwinding 37mm
A gorgeous piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your basket and elevate your range.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a mixture of styling and novelty, awaiting your demand.
Ремонт стиральных машин – высокое качество работы у вас дома. Широкая база выезжающих к заказчику мастеров починить стиральную машинку
Ремонт стиральных машин – высокое качество работы у вас дома. Широкая база выезжающих к заказчику мастеров отремонтировать стиральную машинку в СПб
mexican pharmaceuticals online purple pharmacy mexico price list best online pharmacies in mexico
Бездоганний стиль пін ап
казіно пін ап http://www.pinupcasinoqgcvbisd.kiev.ua/ .
Рулонный газон: как подготовить почву для укладки?
рулонный газон цена [url=https://rulonnyj-gazon77.ru/]https://rulonnyj-gazon77.ru/[/url] .
order rybelsus online
mexican drugstore online medication from mexico pharmacy buying prescription drugs in mexico online
buying prescription drugs in mexico online buying prescription drugs in mexico buying prescription drugs in mexico
buy wegovy canada
buying from online mexican pharmacy medicine in mexico pharmacies mexican border pharmacies shipping to usa
Мы предлагаем широкий выбор лазерных станков с передовой технологией, обеспечивая высокую производительность и качество резки станок лазерный
best online pharmacies in mexico mexican online pharmacies prescription drugs pharmacies in mexico that ship to usa
best mexican online pharmacies mexico drug stores pharmacies mexican border pharmacies shipping to usa
Мы предлагаем широкий выбор лазерных станков с передовой технологией, обеспечивая высокую производительность и качество резки аппарат лазерной резки
rybelsus online cheap
best online pharmacies in mexico mexican online pharmacies prescription drugs reputable mexican pharmacies online
buying prescription drugs in mexico mexican rx online mexican pharmaceuticals online
oral cialis 5mg order tadalafil 10mg pill cialis price walmart
medicine in mexico pharmacies mexican mail order pharmacies mexico pharmacies prescription drugs
buying prescription drugs in mexico online mexican online pharmacies prescription drugs mexico pharmacy
mexican pharmacy mexico pharmacies prescription drugs mexican border pharmacies shipping to usa
Качественно перетянем мебель в Минске – долгое время сохранится ее вид
перетянуть диван https://peretyazhka-mebeli-vminske.ru/ .
mexican pharmaceuticals online mexico drug stores pharmacies reputable mexican pharmacies online
mexican drugstore online best online pharmacies in mexico best online pharmacies in mexico
mexican online pharmacies prescription drugs mexican pharmaceuticals online mexican border pharmacies shipping to usa
купить диплом института [url=https://orik-diploms.com/]https://orik-diploms.com/[/url] .
Купить диплом о среднем ступени – это вариант быстро достать документ об образовании на бакалаврском уровне безо лишних забот и расходов времени. В Москве имеются множество опций настоящих свидетельств бакалавров, предоставляющих комфортность и простоту в процессе.
Доверь перетяжку мебели квалифицированным специалистам в Минске
перетяжка мягкой мебели https://peretyazhka-mebeli-vminske.ru/ .
purple pharmacy mexico price list mexican drugstore online best mexican online pharmacies
rybelsus pills
mexican online pharmacies prescription drugs mexican rx online mexico pharmacy
best mexican online pharmacies best mexican online pharmacies mexico pharmacy
mexican pharmaceuticals online medicine in mexico pharmacies buying from online mexican pharmacy
ST666
reputable mexican pharmacies online best online pharmacies in mexico mexico drug stores pharmacies
mexican online pharmacies prescription drugs mexican online pharmacies prescription drugs buying prescription drugs in mexico online
mexican online pharmacies prescription drugs mexican pharmaceuticals online mexican rx online
best mexican online pharmacies mexico pharmacies prescription drugs mexican drugstore online
binsunvipp.com
Wang Hua가 홀을 나갔을 때 그의 얼굴에는 챔피언이 가져야 할 오만함이 여전히 남아있었습니다.
mexico pharmacies prescription drugs pharmacies in mexico that ship to usa mexico drug stores pharmacies
buying from online mexican pharmacy buying prescription drugs in mexico online mexican border pharmacies shipping to usa
mexico pharmacies prescription drugs buying prescription drugs in mexico online purple pharmacy mexico price list
купить диплом нового образца [url=landik-diploms.com]landik-diploms.com[/url] .
http://mexicanph.shop/# buying from online mexican pharmacy
medication from mexico pharmacy
medication from mexico pharmacy medicine in mexico pharmacies buying prescription drugs in mexico online
п»їbest mexican online pharmacies mexican drugstore online mexican drugstore online
Внутри городе Москве купить свидетельство – это комфортный и экспресс метод получить нужный бумага без избыточных проблем. Разнообразие компаний продают помощь по созданию и торговле свидетельств разных учебных заведений – http://www.diplom4you.net. Разнообразие свидетельств в столице России огромен, включая документация о высшем уровне и среднем образовании, аттестаты, дипломы техникумов и вузов. Основной преимущество – возможность достать свидетельство официальный документ, обеспечивающий истинность и высокое качество. Это предоставляет уникальная защита от фальсификаций и дает возможность воспользоваться аттестат для различных задач. Таким путем, заказ свидетельства в городе Москве является достоверным и оптимальным вариантом для таких, кто стремится к успеху в трудовой деятельности.
medicine in mexico pharmacies mexican rx online mexican border pharmacies shipping to usa
https://skupka-stiralnyh-mashin.ru/
mexican pharmaceuticals online pharmacies in mexico that ship to usa mexican online pharmacies prescription drugs
pharmacies in mexico that ship to usa purple pharmacy mexico price list pharmacies in mexico that ship to usa
buying prescription drugs in mexico buying from online mexican pharmacy best online pharmacies in mexico
mexico pharmacies prescription drugs best mexican online pharmacies purple pharmacy mexico price list
Подберем лизинг на выгодных условиях, поможем сэкономить деньги и отправить заявку сразу в несколько банков без лишних документов лизинг
mexico drug stores pharmacies mexican pharmaceuticals online mexican pharmacy
mexican drugstore online buying from online mexican pharmacy mexico pharmacy
mexican border pharmacies shipping to usa mexico drug stores pharmacies mexican drugstore online
mexico drug stores pharmacies medicine in mexico pharmacies mexican pharmaceuticals online
buying from online mexican pharmacy mexico drug stores pharmacies mexican pharmacy
buy semaglutide online from india
https://mexicanph.com/# buying prescription drugs in mexico
mexican pharmaceuticals online
mexican pharmacy mexican border pharmacies shipping to usa п»їbest mexican online pharmacies
wegovy
Здравствуйте, гости! Решил поделиться восхищением от [url=https://www.osmclinic.ru/]Вулкан казино[/url], где азарт сочетается с обилием шансов. Оригинальные автоматы, щедрые бонусы и непередаваемое удовольствие – всё здесь. Присоединитесь к волшебству игры!
mexican drugstore online mexican rx online best mexican online pharmacies
https://kazino1win.ru/
medication from mexico pharmacy mexico pharmacy mexico drug stores pharmacies
mexican border pharmacies shipping to usa medicine in mexico pharmacies buying prescription drugs in mexico
wegovy tab 3mg
buy ozempic online no script
Занимая пост генерального директора в АО «БСК» и на Березниковском содовом заводе, прославился своим умением лидировать и внедрять стратегические нововведения Давыдов Эдуард
mexican drugstore online buying prescription drugs in mexico online mexican online pharmacies prescription drugs
medication from mexico pharmacy mexican rx online buying from online mexican pharmacy
В сегодняшнем видео будем разбирать и менять модуль дисплея на смартфоне Honor 8A Как настроить и войти в модем Huawei HG8245H: пошаговая инструкция
mexican pharmaceuticals online buying from online mexican pharmacy mexican pharmaceuticals online
http://mexicanph.shop/# pharmacies in mexico that ship to usa
buying prescription drugs in mexico
Исследовал для себя [url=http://tob9.ru/]dragonmoney сайт[/url] – казино с захватывающей атмосферой и великолепными наградами! Огнедышащие монстры дарят удачу, а многообразие игр удивляет. Дополнительно, молниеносные переводы – это фактический бонус!
http://buyprednisone.store/# prednisone 2 mg
1 mg prednisone cost generic prednisone for sale online prednisone
prinivil medication: lisinopril without rx – lisinopril 30 mg tablet
buy semaglutide uk
Предоставляем услуги комплексного бухгалтерского обслуживания юридических лиц. Ведение бухгалтерского учета по выгодным ценам — для вашего бизнеса бухгалтерия услуги
http://amoxil.cheap/# canadian pharmacy amoxicillin
ivermectin 5: ivermectin 50mg/ml – ivermectin 8000 mcg
ivermectin cream cost: cost of stromectol – stromectol tablets
buy glucophage 1000mg without prescription glucophage without prescription buy glucophage pills for sale
娛樂城排名
台灣線上娛樂城的規模正迅速增長,新的娛樂場所不斷開張。為了吸引玩家,這些場所提供了各種吸引人的優惠和贈品。每家娛樂城都致力於提供卓越的服務,務求讓客人享受最佳的遊戲體驗。
2024年網友推薦最多的線上娛樂城:No.1富遊娛樂城、No.2 BET365、No.3 DG娛樂城、No.4 九州娛樂城、No.5 亞博娛樂城,以下來介紹這幾間娛樂城網友對他們的真實評價及娛樂城推薦。
2024台灣娛樂城排名
排名 娛樂城 體驗金(流水) 首儲優惠(流水) 入金速度 出金速度 推薦指數
1 富遊娛樂城 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★★
2 1XBET中文版 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
3 Bet365中文 168元(1倍) 送1000(1倍) 15秒 3-5分鐘 ★★★★☆
4 DG娛樂城 168元(1倍) 送1000(1倍) 15秒 5-10分鐘 ★★★★☆
5 九州娛樂城 168元(1倍) 送500(1倍) 15秒 5-10分鐘 ★★★★☆
6 亞博娛樂城 168元(1倍) 送1000(1倍) 15秒 3-10分鐘 ★★★☆☆
7 寶格綠娛樂城 199元(1倍) 送1000(25倍) 15秒 3-5分鐘 ★★★☆☆
8 王者娛樂城 300元(15倍) 送1000(15倍) 90秒 5-30分鐘 ★★★☆☆
9 FA8娛樂城 200元(40倍) 送1000(15倍) 90秒 5-10分鐘 ★★★☆☆
10 AF娛樂城 288元(40倍) 送1000(1倍) 60秒 5-30分鐘 ★★★☆☆
2024台灣娛樂城排名,10間娛樂城推薦
No.1 富遊娛樂城
富遊娛樂城推薦指數:★★★★★(5/5)
富遊娛樂城介面 / 2024娛樂城NO.1
RG富遊官網
富遊娛樂城是成立於2019年的一家獲得數百萬玩家註冊的線上博彩品牌,持有博彩行業市場的合法運營許可。該公司受到歐洲馬爾他(MGA)、菲律賓(PAGCOR)以及英屬維爾京群島(BVI)的授權和監管,展示了其雄厚的企業實力與合法性。
富遊娛樂城致力於提供豐富多樣的遊戲選項和全天候的會員服務,不斷追求卓越,確保遊戲的公平性。公司運用先進的加密技術及嚴格的安全管理體系,保障玩家資金的安全。此外,為了提升手機用戶的使用體驗,富遊娛樂城還開發了專屬APP,兼容安卓(Android)及IOS系統,以達到業界最佳的穩定性水平。
在資金存提方面,富遊娛樂城採用第三方金流服務,進一步保障玩家的資金安全,贏得了玩家的信賴與支持。這使得每位玩家都能在此放心享受遊戲樂趣,無需擔心後顧之憂。
富遊娛樂城簡介
娛樂城網路評價:5分
娛樂城入金速度:15秒
娛樂城出金速度:5分鐘
娛樂城體驗金:168元
娛樂城優惠:
首儲1000送1000
好友禮金無上限
新會禮遇
舊會員回饋
娛樂城遊戲:體育、真人、電競、彩票、電子、棋牌、捕魚
富遊娛樂城推薦要點
新手首推:富遊娛樂城,2024受網友好評,除了打造針對新手的各種優惠活動,還有各種遊戲的豐富教學。
首儲再贈送:首儲1000元,立即在獲得1000元獎金,而且只需要1倍流水,對新手而言相當友好。
免費遊戲體驗:新進玩家享有免費體驗金,讓您暢玩娛樂城內的任何遊戲。
優惠多元:活動頻繁且豐富,流水要求低,對各玩家可說是相當友善。
玩家首選:遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
富遊娛樂城優缺點整合
優點 缺點
• 台灣註冊人數NO.1線上賭場
• 首儲1000贈1000只需一倍流水
• 擁有體驗金免費體驗賭場
• 網紅部落客推薦保證出金線上娛樂城 • 需透過客服申請體驗金
富遊娛樂城優缺點整合表格
富遊娛樂城存取款方式
存款方式 取款方式
• 提供四大超商(全家、7-11、萊爾富、ok超商)
• 虛擬貨幣ustd存款
• 銀行轉帳(各大銀行皆可) • 現金1:1出金
• 網站內申請提款及可匯款至綁定帳戶
富遊娛樂城存取款方式表格
富遊娛樂城優惠活動
優惠 獎金贈點 流水要求
免費體驗金 $168 1倍 (儲值後) /36倍 (未儲值)
首儲贈點 $1000 1倍流水
返水活動 0.3% – 0.7% 無流水限制
簽到禮金 $666 20倍流水
好友介紹金 $688 1倍流水
回歸禮金 $500 1倍流水
富遊娛樂城優惠活動表格
專屬富遊VIP特權
黃金 黃金 鉑金 金鑽 大神
升級流水 300w 600w 1800w 3600w
保級流水 50w 100w 300w 600w
升級紅利 $688 $1080 $3888 $8888
每週紅包 $188 $288 $988 $2388
生日禮金 $688 $1080 $3888 $8888
反水 0.4% 0.5% 0.6% 0.7%
專屬富遊VIP特權表格
娛樂城評價
總體來看,富遊娛樂城對於玩家來講是一個非常不錯的選擇,有眾多的遊戲能讓玩家做選擇,還有各種優惠活動以及低流水要求等等,都讓玩家贏錢的機率大大的提升了不少,除了體驗遊戲中帶來的樂趣外還可以享受到贏錢的快感,還在等什麼趕快點擊下方連結,立即遊玩!
buy lasix online lasix generic lasix 100 mg
Демонтаж, разборка и снос старых деревянных и кирпичных домов с вывозом строительного мусора в Москве и Московской области. Демонтаж домика – узнайте подробнее об услуге: taurusweb.ru. Производим демонтаж домов, зданий и фундаментов вручную и спецтехникой по ценам ниже рынка за 24 часа. Бесплатный выезд специалиста на объект.
sm-online-game.com
Liu Wenshan은 미소를 지었습니다. “아니요, 이것은 시작일뿐입니다.”
semaglutide sale
http://buyprednisone.store/# where to buy prednisone in australia
[url=http://affittareunamacchinanrbtyp.com]http://affittareunamacchinanrbtyp.com[/url]
Transfers can be ordered not solely to or from the airport, but also after exciting in all directions from the city.
http://affittareunamacchinanrbtyp.com
https://stromectol.fun/# ivermectin lotion for lice
ivermectin 1 cream generic cost of ivermectin lotion ivermectin 2mg
zestoretic 20 12.5 mg: lisinopril drug – zestril price uk
Всем хай. [url=https://kuzovdetali.by/]https://kuzovdetali.by/[/url] – достойный ассортимент деталей и подбор автозапчастей для кузова машины. Переходите в магазин для заказа новых и оригинальных товаров для автомобиля. Гарантия и доставка по городам Беларуси.
Seasoned Port Builder Vitaliy Yuzhilin, Works in Maritime Infrastructure Development Vitaliy Yuzhilin
Приветствую. [url=https://kuzovdetali.by/]KuzovDetali.by[/url] – широкий ассортимент запчастей и подбор автозапчастей из европы. Перейдите в магазин для заказа новых и оригинальных запчастей на машину. Гарантия и доставка по городу Минску и областям.
stromectol cvs: stromectol without prescription – stromectol cream
http://buyprednisone.store/# 30mg prednisone
buy wegovy
stromectol ivermectin: ivermectin 0.2mg – stromectol 3mg
amoxicillin tablet 500mg amoxicillin buy canada amoxicillin 500 mg without prescription
Эдуард Давыдов [url=http://www.panram.ru/partners/news/biografiya-eduarda-davydova-generalnogo-direktora-bsk-ao/]http://www.panram.ru/partners/news/biografiya-eduarda-davydova-generalnogo-direktora-bsk-ao/[/url] .
Продажа подержанных автомобилей, все машины проверены и находятся в Москве. Большой каталог БУ автомобилей с пробегом от официального дилера, узнайте на сайте цены и характеристики на бу авто продажа подержанных машин
https://stromectol.fun/# stromectol buy uk
オンラインカジノ
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
Продажа подержанных автомобилей, все машины проверены и находятся в Москве. Большой каталог БУ автомобилей с пробегом от официального дилера, узнайте на сайте цены и характеристики на бу авто купить машину в москве с пробегом
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
http://furosemide.guru/# lasix uses
cost of ivermectin 3mg tablets ivermectin human stromectol cream
Maxim Shubarev is a Russian entrepreneur, chairman of the Board of Directors of the Setl Group holding Maxim Shubarev
https://furosemide.guru/# furosemide 40mg
where to buy prednisone without prescription prednisone pill 10 mg prednisone 20mg online without prescription
semaglutide tablets for weight loss cost
http://furosemide.guru/# lasix
stromectol drug ivermectin 10 ml where to buy ivermectin cream
https://buyprednisone.store/# prednisone 2.5 mg
оборудование актового зала учебного заведения [url=i-tec1.ru]i-tec1.ru[/url] .
Погрузитесь в захватывающий мир азартных игр, где каждый может стать следующим большим победителем кент казино онлайн
http://lisinopril.top/# lisinopril 2.5 mg medicine
buy ivermectin canada: ivermectin brand name – buy stromectol
ivermectin online: ivermectin buy online – ivermectin for sale
видеорегистратор для ношения на одежде https://nagrudnievieoregistratori.ru/
http://furosemide.guru/# lasix online
order amoxicillin online uk buy amoxicillin 500mg online amoxicillin 500 mg cost
娛樂城推薦
https://lisinopril.top/# zestril 20 mg
semaglutide canada pharmacy prices
Discover a world of style and comfort at our furniture store, where every detail is designed to enhance the uniqueness of your space and offer you unparalleled solutions for your home or office Modern furniture
Discover a world of style and comfort at our furniture store, where every detail is designed to enhance the uniqueness of your space and offer you unparalleled solutions for your home or office Furniture design
amoxicillin where to get buy cheap amoxicillin online amoxicillin 30 capsules price
pragmatic-ko.com
다음날 아침 일찍 덩젠은 팡지판에게 나쁜 소식을 전했다.
https://stromectol.fun/# minocycline 50mg tabs
buy prednisone canada: buying prednisone without prescription – prednisone tablets
Watches World
In the realm of high-end watches, discovering a trustworthy source is essential, and WatchesWorld stands out as a pillar of confidence and knowledge. Offering an broad collection of renowned timepieces, WatchesWorld has collected praise from happy customers worldwide. Let’s dive into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and aftercare throughout the process. The watch was impeccably packed and in pristine condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was extremely supportive and courteous at all times, keeping me regularly informed of the procedure. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A excellent and swift service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an online platform; it’s a promise to customized service in the world of luxury watches. Our staff of watch experts prioritizes confidence, ensuring that every client makes an well-informed decision.
Our Commitment:
Expertise: Our group brings exceptional knowledge and perspective into the realm of high-end timepieces.
Trust: Trust is the basis of our service, and we prioritize openness in every transaction.
Satisfaction: Customer satisfaction is our ultimate goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re committing in a effortless and reliable experience. Explore our range, and let us assist you in finding the perfect timepiece that mirrors your style and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
Proxy servers act as intermediaries between clients and destination servers, providing various functionalities such as caching and filtering Proxy access
In the realm of premium watches, finding a trustworthy source is paramount, and WatchesWorld stands out as a beacon of trust and knowledge. Offering an wide collection of esteemed timepieces, WatchesWorld has garnered acclaim from content customers worldwide. Let’s dive into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Outstanding communication and aftercare throughout the process. The watch was impeccably packed and in pristine condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly helpful and courteous at all times, keeping me regularly informed of the process. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and prompt service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a promise to individualized service in the realm of luxury watches. Our staff of watch experts prioritizes confidence, ensuring that every client makes an informed decision.
Our Commitment:
Expertise: Our group brings exceptional understanding and perspective into the world of luxury timepieces.
Trust: Confidence is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Customer satisfaction is our ultimate goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re committing in a seamless and reliable experience. Explore our collection, and let us assist you in discovering the ideal timepiece that mirrors your taste and sophistication. At WatchesWorld, your satisfaction is our proven commitment
https://amoxil.cheap/# where can i buy amoxicillin without prec
Proxy servers act as intermediaries between clients and destination servers, providing various functionalities such as caching and filtering Server
ivermectin humans stromectol ivermectin 3 mg ivermectin gel
semaglutide buy uk
generic prednisone tablets: where can i get prednisone over the counter – where to buy prednisone without prescription
where can i buy zovirax acyclovir oral order zyloprim 300mg online cheap
prednisone 20mg capsule: prednisone 5 50mg tablet price – prednisone without prescription medication
Want to know more about a specific phone number?Number Tracker is the solution for you. With our advanced technology, you can easily track any phone number and get detailed information about the caller http://www.air119.net/bbs/board.php?bo_table=free&wr_id=570704
lisinopril 1 mg: lisinopril 10 mg – lisinopril 1 mg
https://amoxil.cheap/# amoxicillin 30 capsules price
https://furosemide.guru/# furosemide 100 mg
lisinopril in mexico cost of lisinopril in mexico zestril 30 mg
Актуальный доступ к ссылкам и зеркалам площадки Kraken уже у вас. Ознакомьтесь с надежными методами доступа и гарантированными мерами безопасности ссылка на каркен
все займы онлайн [url=topruscredit.ru]topruscredit.ru[/url] .
amoxicillin 500: amoxicillin 500mg tablets price in india – generic amoxil 500 mg
http://lisinopril.top/# lisinopril 30
Актуальный доступ к ссылкам и зеркалам площадки Kraken уже у вас. Ознакомьтесь с надежными методами доступа и гарантированными мерами безопасности kraken купить
http://buyprednisone.store/# prednisone 2.5 mg cost
where can i buy amoxicillin over the counter uk: amoxicillin where to get – amoxicillin 500 mg where to buy
where to buy semaglutide online
http://stromectol.fun/# ivermectin over the counter canada
buy 10 mg prednisone buy prednisone with paypal canada prednisone price canada
Французское вино
Watches World
In the world of high-end watches, locating a reliable source is essential, and WatchesWorld stands out as a pillar of trust and knowledge. Presenting an broad collection of prestigious timepieces, WatchesWorld has collected praise from content customers worldwide. Let’s explore into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and aftercare throughout the process. The watch was perfectly packed and in perfect condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was exceptionally supportive and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and swift service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a dedication to customized service in the realm of high-end watches. Our staff of watch experts prioritizes confidence, ensuring that every client makes an knowledgeable decision.
Our Commitment:
Expertise: Our team brings unparalleled understanding and insight into the realm of luxury timepieces.
Trust: Trust is the foundation of our service, and we prioritize transparency in every transaction.
Satisfaction: Client satisfaction is our ultimate goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just purchasing a watch; you’re investing in a effortless and reliable experience. Explore our collection, and let us assist you in discovering the ideal timepiece that reflects your taste and elegance. At WatchesWorld, your satisfaction is our proven commitment
generic ozempic
http://lisinopril.top/# lisinopril online canadian pharmacy
crestor ca buy crestor 10mg generic zetia 10mg us
where to buy amoxicillin over the counter buy amoxil amoxicillin 500 coupon
https://amoxil.cheap/# amoxicillin 1000 mg capsule
Вячеслав Николаев [url=http://www.vyacheslav-nikolaev-konstantinovich.ru/]http://www.vyacheslav-nikolaev-konstantinovich.ru/[/url] .
ivermectin 80 mg: ivermectin stromectol – ivermectin 0.5% lotion
buy ozempic for weight loss
Биография руководителя «Башкирской содовой компании» Эдуард Давыдов Рождение в семье увлеченных наукой родителей предопределило жизненный путь Эдуарда Давыдова, чье детство прошло в атмосфере постоянного стремления к знаниям и самосовершенствованию.
semaglutide for sale
http://1xbet-cabinet-zerkalo.ru/
Медицинское оборудование по выгодным ценам. Купить медоборудование диагностическое, медтехнику. Огромный выбор медтехники купить оборудование для производства медицинских шприцов
1xbet сайт регистрация вход
semaglutide generic
Написание эссе на заказ осуществляется нашими профессиональными авторами. Цена ВКР бакалавра купить зависит от ее объема и сложности заказать реферат
Как сэкономить на оформлении документов
– Отпуск по системе “все включено”: турция тур
горящие туры турция http://anex-tour-turkey.ru/ .
where can i buy domperidone tetracycline cost sumycin 250mg generic
купить аттестат за 11 [url=http://www.rudik-attestats.com]http://www.rudik-attestats.com[/url] .
ozempic tablets for weight loss
online pharmacy india cheapest online pharmacy india best india pharmacy
даркнет вход
Подпольная сфера сети – таинственная сфера интернета, избегающая взоров стандартных поисковых систем и требующая специальных средств для доступа. Этот скрытый ресурс сети обильно насыщен ресурсами, предоставляя доступ к разнообразным товарам и услугам через свои даркнет списки и справочники. Давайте глубже рассмотрим, что представляют собой эти реестры и какие тайны они хранят.
Даркнет Списки: Порталы в Скрытый Мир
Индексы веб-ресурсов в темной части интернета – это своего рода проходы в невидимый мир интернета. Реестры и справочники веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам шанс заглянуть в непознанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с незаконными сделками, где доступны разнообразные товары и услуги – от психоактивных веществ и стрелкового оружия до украденных данных и услуг наемных убийц. Реестры ресурсов в подобной категории облегчают пользователям находить нужные предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, охватывают широкий спектр – от информационной безопасности и взлома до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие информацию и инструкции по обходу ограничений, защите конфиденциальности и другим темам, которые могут быть интересны тем, кто хочет остаться анонимным.
Безопасность и Осторожность
Несмотря на анонимность и свободу, даркнет не лишен опасностей. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Взаимодействуя с даркнет списками, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Реестры даркнета – это путь в неизведанный мир, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой осторожности и знания. Анонимность не всегда гарантирует безопасность, и использование темной сети требует осмысленного подхода. Независимо от ваших интересов – будь то технические детали в области кибербезопасности, поиск необычных товаров или исследование новых возможностей в интернете – даркнет списки предоставляют ключ
Теневой интернет – это часть интернета, которая остается скрытой от обычных поисковых систем и требует специального программного обеспечения для доступа. В этой анонимной зоне сети существует множество ресурсов, включая различные списки и каталоги, предоставляющие доступ к разнообразным услугам и товарам. Давайте рассмотрим, что представляет собой даркнет список и какие тайны скрываются в его глубинах.
Теневые каталоги: Врата в анонимность
Для начала, что такое теневой каталог? Это, по сути, каталоги или индексы веб-ресурсов в даркнете, которые позволяют пользователям находить нужные услуги, товары или информацию. Эти списки могут варьироваться от чатов и магазинов до ресурсов, специализирующихся на различных аспектах анонимности и криптовалют.
Категории и Возможности
Черный Рынок:
Темная сторона интернета часто ассоциируется с теневым рынком, где можно найти различные товары и услуги, включая наркотики, оружие, украденные данные и даже услуги наемных убийц. Списки таких ресурсов позволяют пользователям без труда находить подобные предложения.
Чаты и Группы:
Даркнет также предоставляет платформы для анонимного общения. Форумы и сообщества на даркнет списках могут заниматься обсуждением тем от интернет-безопасности и взлома до политики и философии.
Информационные ресурсы:
Есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, интересным пользователям, стремящимся сохранить анонимность.
Безопасность и Осторожность
При всей своей анонимности и свободе действий темная сторона интернета также несет риски. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Пользователям необходимо проявлять максимальную осторожность и соблюдать меры безопасности при взаимодействии с даркнет списками.
Заключение: Врата в Неизведанный Мир
Даркнет списки предоставляют доступ к скрытым уголкам сети, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, важно помнить о возможных рисках и осознанно подходить к использованию даркнета. Анонимность не всегда гарантирует безопасность, и путешествие в этот мир требует особой осторожности и знания.
Независимо от того, интересуетесь ли вы техническими аспектами интернет-безопасности, ищете уникальные товары или просто исследуете новые грани интернета, даркнет списки предоставляют ключ
список сайтов даркнет
Подпольная сфера сети – неведомая сфера интернета, избегающая взоров обычных поисковых систем и требующая специальных средств для доступа. Этот скрытый ресурс сети обильно насыщен платформами, предоставляя доступ к различным товарам и услугам через свои перечни и каталоги. Давайте глубже рассмотрим, что представляют собой эти списки и какие тайны они хранят.
Даркнет Списки: Порталы в Неизведанный Мир
Даркнет списки – это своего рода проходы в невидимый мир интернета. Перечни и указатели веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам возможность заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны разнообразные товары и услуги – от наркотиков и оружия до краденых данных и услуг наемных убийц. Каталоги ресурсов в данной категории облегчают пользователям находить нужные предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, представленные в реестрах даркнета, затрагивают широкий спектр – от компьютерной безопасности и хакерских атак до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим вопросам, которые могут заинтересовать тех, кто стремится сохранить свою анонимность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет полон опасностей. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с списками ресурсов в темной сети, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Списки даркнета – это ключ к таинственному миру, где хранятся тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой бдительности и знаний. Не всегда можно полагаться на анонимность, и использование даркнета требует осознанного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – даркнет списки предоставляют ключ
semaglutide diabetes medication
Профильные трубы 40х20 мм. Закажите по низкой цене от производителя с доставкой по Москве. Предлагаем самые приятные цены в городе и области крепеж для профильной трубы
reputable indian online pharmacy top online pharmacy india top online pharmacy india
http://indianph.com/# Online medicine order
reputable indian pharmacies indian pharmacy online india pharmacy mail order
http://indianph.xyz/# india online pharmacy
online shopping pharmacy india
top 10 pharmacies in india indianpharmacy com top 10 pharmacies in india
pragmatic-ko.com
Hongzhi 황제는 눈을 곧게 펴고 놀라서 고개를 들었고 매우 멍해졌습니다.
http://indianph.com/# world pharmacy india
best online pharmacy india
https://greengo-shop.ru
купить аттестат [url=https://gruppa-attestats.com/]https://gruppa-attestats.com/[/url] .
semaglutide generic
Грузоперевозки по Харькову и области
вывоз строймусора харьков цена https://moving-company-kharkov.com.ua .
http://indianph.com/# world pharmacy india
legitimate online pharmacies india
דירות דיסקרטיות אשדוד
reputable indian online pharmacy india pharmacy online pharmacy india
Косметологическое оборудование Zemits – инновационные эстетические технологии для успешного развития Вашего СПА-бизнеса https://venko.com.ua/ru/apparaty-rf-liftinga-dlya-tela
buy wegovy in mexico
промокод 1хбет
медтехника ведущих брендов для дома. Всегда оптимальные цены, акции , скидки и отличный сервис. Hzchbl
Косметологическое оборудование Zemits – инновационные эстетические технологии для успешного развития Вашего СПА-бизнеса https://zemits.com.ua/category/lasers/photoepilation
медтехника ведущих брендов для дома. Всегда оптимальные цены, акции , скидки и отличный сервис. Yrbuel
https://indianph.xyz/# top online pharmacy india
buy prescription drugs from india
Нове обладнання для будівництва
продаж спецтехніки бу https://www.spectehnika-sksteh.co.ua .
casino
Компания предлагает обширный ассортимент услуг по изготовлению чеков на все случаи жизни. Вы точно сможете найти индивидуальное решение бюрократических проблем Купить чеки
atenolol generic brand atenolol 100mg buy generic tenormin 100mg
https://cytotec24.com/# order cytotec online
cipro pharmacy: cipro 500mg best prices – ciprofloxacin order online
Профессиональные советы
6. Как выбрать место для установки кондиционера
сплит система http://www.ustanovit-kondicioner.ru .
Лучшие юристы и адвокаты оказывают бесплатные юридические консультации по телефону и в офисе компании. Квалифицированная юридическая помощь по всем отраслям права юридическая консультация бесплатно горячая линия по телефону
На территории столице России заказать свидетельство – это комфортный и оперативный способ достать нужный документ безо лишних хлопот. Разнообразие компаний предлагают помощь по созданию и реализации свидетельств разных учебных заведений – https://prema-diploms-srednee.com/. Ассортимент свидетельств в столице России большой, включая бумаги о академическом и среднем учебе, свидетельства, дипломы вузов и университетов. Основной плюс – возможность достать аттестат Гознака, обеспечивающий истинность и высокое качество. Это предоставляет уникальная защита против подделки и предоставляет возможность воспользоваться аттестат для разнообразных нужд. Таким образом, заказ диплома в городе Москве становится безопасным и экономичным вариантом для тех, кто стремится к процветанию в сфере работы.
Vitaliy Aleksandrovich Yuzhilin [url=https://en.wikipedia.org/wiki/vitaliy_aleksandrovich_yuzhilin]https://en.wikipedia.org/wiki/vitaliy_aleksandrovich_yuzhilin[/url] .
https://onlinecasinos.com.cy/
wegovy pill
ozempic tab 3mg
https://doxycycline.auction/# order doxycycline 100mg without prescription
buy semaglutide from canada
быстротвердеющие наливные полы цена
http://diflucan.pro/# diflucan medicine
Slot 777
https://diflucan.pro/# diflucan pills prescription
cytotec buy online usa cytotec pills buy online Abortion pills online
casino
https://nolvadex.guru/# tamoxifen postmenopausal
Скрытая сфера – это загадочная и непознанная территория интернета, где существуют особые правила, возможности и угрозы. Каждый день в пространстве теневой сети случаются события, о которые обычные участники могут только догадываться. Давайте рассмотрим актуальные сведения из даркнета, которые отражают современные тенденции и инциденты в этом скрытом уголке сети.”
Тенденции и События:
“Развитие Средств и Безопасности:
В теневом интернете непрерывно развиваются технологии и подходы защиты. Новости о внедрении улучшенных систем шифрования, скрытия личности и оберегающих персональной информации говорят о стремлении пользователей и разработчиков к поддержанию надежной обстановки.”
“Новые Скрытые Рынки:
В соответствии с динамикой запроса и предложения, в теневом интернете возникают новые торговые площадки. Новости о открытии цифровых рынков подаривают пользователям разнообразные возможности для торговли продукцией и сервисами
Покупка паспорта в интернет-магазине – это неправомерное и рискованное действие, которое может вызвать к серьезным последствиям для граждан. Вот некоторые аспектов, о которые важно запомнить:
Незаконность: Приобретение удостоверения личности в интернет-магазине является нарушение закона. Владение поддельным документом может повлечь за собой криминальную наказание и серьезные наказания.
Опасности личной безопасности: Обстоятельство использования поддельного паспорта может поставить под угрозу личную секретность. Люди, пользующиеся фальшивыми документами, могут оказаться объектом провокаций со со стороны законопослушных структур.
Финансовые убытки: Зачастую мошенники, торгующие фальшивыми паспортами, способны применять ваши личные данные для мошенничества, что приведет к денежным убыткам. Ваши или финансовые данные могут оказаться использованы в преступных намерениях.
Проблемы при путешествиях: Фальшивый паспорт может быть распознан при попытке пересечь границу или при контакте с государственными органами. Такое обстоятельство способно привести к задержанию, депортации или другим серьезным проблемам при путешествиях.
Потеря доверительности и репутации: Применение поддельного удостоверения личности способно привести к потере доверия со стороны сообщества и нанимателей. Это ситуация может негативно влиять на вашу престиж и карьерные возможности.
Вместо того, чем бы рисковать собственной независимостью, безопасностью и престижем, рекомендуется придерживаться законодательство и воспользоваться официальными путями для получения документов. Эти предусматривают обеспечение всех ваших законных интересов и обеспечивают секретность личных информации. Нелегальные действия могут повлечь за собой неожиданные и вредные последствия, создавая серьезные проблемы для вас и ваших вашего сообщества
https://cipro.guru/# cipro for sale
На территории городе Москве приобрести диплом – это комфортный и быстрый способ завершить нужный документ безо избыточных проблем. Разнообразие компаний предлагают помощь по созданию и продаже дипломов разнообразных учебных заведений – https://gruppa-diploms-srednee.com/. Разнообразие дипломов в Москве велик, включая бумаги о высшем уровне и нормальном учебе, документы, свидетельства колледжей и вузов. Основное преимущество – способность получить диплом официальный документ, подтверждающий достоверность и высокое стандарт. Это гарантирует специальная защита против подделок и позволяет применять диплом для различных целей. Таким образом, приобретение свидетельства в Москве является достоверным и оптимальным вариантом для таких, кто хочет достичь успеха в трудовой деятельности.
даркнет 2024
Даркнет 2024: Теневые взгляды цифровой среды
С инициации теневого интернета был собой уголок интернета, где тайна и тень были нормой. В 2024 году этот непрозрачный мир развивается, предоставляя новые вызовы и риски для сообщества в сети. Рассмотрим, какими тренды и модификации предстоят нас в даркнете 2024.
Продвижение технологий и Повышение анонимности
С развитием технологий, средства обеспечения скрытности в даркнете превращаются в более сложными и действенными. Использование криптовалют, современных шифровальных методов и сетей с децентрализованной структурой делает слежение за деятельностью участников еще более трудным для силовых структур.
Рост специализированных рынков
Темные рынки, специализирующиеся на разнообразных продуктах и сервисах, продвигаются вперед развиваться. Наркотики, военные припасы, средства для хакерских атак, персональная информация – ассортимент продукции бывает все более многообразным. Это создает сложность для силовых структур, стоящего перед необходимостью адаптироваться к постоянно меняющимся сценариям преступной деятельности.
Угрозы кибербезопасности для непрофессионалов
Сервисы аренды хакерских услуг и обманные планы остаются работоспособными в теневом интернете. Обычные пользователи попадают в руки объектом для киберпреступников, желающих зайти к личным данным, банковским счетам и другой конфиденциальной информации.
Перспективы виртуальной реальности в теневом интернете
С прогрессом техники цифровой симуляции, теневой интернет может перейти в новый этап, предоставляя пользователям реальные и захватывающие виртуальные пространства. Это может сопровождаться новыми формами нелегальных действий, такими как виртуальные торговые площадки для обмена виртуальными товарами.
Противостояние силам защиты
Силы безопасности улучшают свои технологии и подходы борьбы с теневым интернетом. Совместные усилия государств и международных организаций направлены на предотвращение киберпреступности и прекращение новым вызовам, которые возникают в связи с развитием темного интернета.
Вывод
Теневой интернет в 2024 году остается комплексной и многогранной обстановкой, где технологии продолжают вносить изменения в ландшафт нелегальных действий. Важно для пользователей оставаться бдительными, гарантировать свою защиту в интернете и следовать законы, даже в цифровой среде. Вместе с тем, борьба с даркнетом требует коллективных действиях от государств, технологических компаний и граждан, для обеспечения защиту в цифровом мире.
В последнее время интернет стал в неиссякаемый ресурс информации, сервисов и продуктов. Однако, среди множества виртуальных магазинов и площадок, существует скрытая сторона, известная как даркнет магазины. Этот уголок виртуального мира создает свои опасные сценарии и влечет за собой значительными рисками.
Каковы Даркнет Магазины:
Даркнет магазины представляют собой онлайн-платформы, доступные через скрытые браузеры и уникальные программы. Они оперируют в глубоком вебе, невидимом от обычных поисковых систем. Здесь можно обнаружить не только торговцев нелегальными товарами и услугами, но и разнообразные преступные схемы.
Категории Товаров и Услуг:
Даркнет магазины предлагают разнообразный ассортимент товаров и услуг, начиная от наркотиков и оружия до хакерских услуг и похищенных данных. На этой темной площадке действуют торговцы, предоставляющие возможность приобретения незаконных вещей без опасности быть выслеженным.
Риски для Пользователей:
Легальные Последствия:
Покупка запрещенных товаров на даркнет магазинах подвергает пользователей риску столкнуться с правоохранительными органами. Уголовная ответственность может быть серьезным следствием таких покупок.
Мошенничество и Обман:
Даркнет также представляет собой плодородной почвой для мошенников. Пользователи могут попасть в обман, где оплата не приведет к к получению в руки товара или услуги.
Угрозы Кибербезопасности:
Даркнет магазины предлагают услуги хакеров и киберпреступников, что сопровождается реальными опасностями для безопасности данных и конфиденциальности.
Распространение Преступной Деятельности:
Экономика даркнет магазинов способствует распространению преступной деятельности, так как обеспечивает инфраструктуру для нелегальных транзакций.
Борьба с Проблемой:
Усиление Кибербезопасности:
Улучшение кибербезопасности и технологий слежения помогает бороться с даркнет магазинами, делая их менее поулчаемыми.
Законодательные Меры:
Принятие строгих законов и их решительная реализация направлены на предупреждение и кара пользователей даркнет магазинов.
Образование и Пропаганда:
Повышение осведомленности о рисках и последствиях использования даркнет магазинов может снизить спрос на противозаконные товары и услуги.
Заключение:
Даркнет магазины предоставляют темным уголкам интернета, где проступают теневые фигуры с преступными намерениями. Рациональное применение ресурсов и повышенная бдительность необходимы, для того чтобы защитить себя от рисков, связанных с этими темными магазинами. В конечном итоге, секретность и законопослушание должны быть на первом месте, когда речь заходит о виртуальных покупках
http://cytotec24.com/# buy cytotec pills online cheap
Кондиционеры со скидкой
монтаж кондиционера prodazha-kondicionera.ru .
buy medrol generic buy depo-medrol generic buy medrol generic
https://1xbettur-2.com/
Важная информация
18. Топ лучших компаний по установке кондиционеров
сплит система http://ustanovit-kondicioner.ru/ .
http://cipro.guru/# cipro online no prescription in the usa
https://cytotec24.com/# buy misoprostol over the counter
winbet đăng ký
https://doxycycline.auction/# 100mg doxycycline
smcasino-game.com
“…” Hongzhi 황제는 그것을 도울 수 없었습니다. “나는 …”
18. Специфика установки кондиционера в частном доме
продажа кондиционеров http://www.montazh-kondicionera-moskva.ru/ .
cipro online no prescription in the usa buy ciprofloxacin ciprofloxacin
https://cytotec24.com/# Cytotec 200mcg price
http://nolvadex.guru/# tamoxifen hip pain
buy cytotec over the counter Abortion pills online cytotec pills buy online
https://1wintr-4.xyz/
Даркнет – скрытое пространство Интернета, доступен только для тех, кто знает правильный вход. Этот таинственный уголок виртуального мира служит местом для скрытных транзакций, обмена информацией и взаимодействия сокрытыми сообществами. Однако, чтобы погрузиться в этот темный мир, необходимо преодолеть несколько барьеров и использовать особые инструменты.
Использование приспособленных браузеров: Для доступа к даркнету обычный браузер не подойдет. На помощь приходят особые браузеры, такие как Tor (The Onion Router). Tor позволяет пользователям обходить цензуру и обеспечивает анонимность, маркируя и перенаправляя запросы через различные серверы.
Адреса в даркнете: Обычные домены в даркнете заканчиваются на “.onion”. Для поиска ресурсов в даркнете, нужно использовать поисковики, приспособленные для этой среды. Однако следует быть осторожным, так как далеко не все ресурсы там законны.
Защита анонимности: При посещении даркнета следует принимать меры для сохранения анонимности. Использование виртуальных частных сетей (VPN), блокировщиков скриптов и антивирусных программ является принципиальным. Это поможет избежать различных угроз и сохранить конфиденциальность.
Электронные валюты и биткоины: В даркнете часто используются цифровые валюты, в основном биткоины, для неизвестных транзакций. Перед входом в даркнет следует ознакомиться с основами использования цифровых валют, чтобы избежать финансовых рисков.
Правовые аспекты: Следует помнить, что многие действия в даркнете могут быть незаконными и противоречить законам различных стран. Пользование даркнетом несет риски, и непоследовательные действия могут привести к серьезным юридическим последствиям.
Заключение: Даркнет – это тайное пространство сети, наполненное анонимности и тайн. Вход в этот мир требует специальных навыков и предосторожности. При всем мистическом обаянии даркнета важно помнить о предполагаемых рисках и последствиях, связанных с его использованием.
Введение в Темный Интернет: Определение и Основополагающие Характеристики
Разъяснение термина даркнета, его отличий от стандартного интернета, и основных черт этого таинственного мира.
Каким образом Войти в Темный Интернет: Руководство по Скрытому Доступу
Подробное описание шагов, необходимых для входа в даркнет, включая использование специализированных браузеров и инструментов.
Адресация в Темном Интернете: Секреты .onion-Доменов
Пояснение, как работают .onion-домены, и каковы ресурсы они представляют, с акцентом на секурном поиске и применении.
Защита и Конфиденциальность в Темном Интернете: Шаги для Пользователей
Обзор методов и инструментов для защиты анонимности при эксплуатации даркнета, включая VPN и другие средства.
Цифровые Деньги в Темном Интернете: Функция Биткоинов и Криптовалют
Исследование использования цифровых валют, в главном биткоинов, для осуществления анонимных транзакций в даркнете.
Поиск в Даркнете: Особенности и Опасности
Рассмотрение поисковых механизмов в даркнете, предупреждения о возможных рисках и нелегальных ресурсах.
Правовые Аспекты Даркнета: Ответственность и Результаты
Обзор законных аспектов использования даркнета, предостережение о возможных юридических последствиях.
Темный Интернет и Кибербезопасность: Возможные Угрозы и Защитные Меры
Анализ возможных киберугроз в даркнете и советы по обеспечению безопасности от них.
Темный Интернет и Социальные Сети: Скрытое Взаимодействие и Группы
Изучение влияния даркнета в области социальных взаимодействий и создании анонимных сообществ.
Будущее Темного Интернета: Тенденции и Предсказания
Прогнозы развития даркнета и потенциальные изменения в его структуре в будущем.
Взлом телеграм
Взлом Telegram: Легенды и Реальность
Telegram – это известный мессенджер, признанный своей высокой степенью кодирования и защиты данных пользователей. Однако, в современном цифровом мире тема взлома Телеграм периодически поднимается. Давайте рассмотрим, что на самом деле стоит за этим понятием и почему нарушение Телеграм чаще является фантазией, чем реальностью.
Кодирование в Telegram: Основные принципы Защиты
Telegram славится своим высоким уровнем шифрования. Для обеспечения конфиденциальности переписки между пользователями используется протокол MTProto. Этот протокол обеспечивает конечно-конечное кодирование, что означает, что только отправитель и получатель могут понимать сообщения.
Мифы о Взломе Telegram: Почему они появляются?
В последнее время в сети часто появляются утверждения о взломе Телеграма и возможности доступа к персональной информации пользователей. Однако, основная часть этих утверждений оказываются мифами, часто развивающимися из-за непонимания принципов работы мессенджера.
Кибератаки и Раны: Фактические Угрозы
Хотя взлом Telegram в общем случае является сложной задачей, существуют реальные опасности, с которыми сталкиваются пользователи. Например, кибератаки на индивидуальные аккаунты, вредоносные программы и другие методы, которые, тем не менее, требуют в активном участии пользователя в их распространении.
Охрана Личной Информации: Советы для Пользователей
Несмотря на непоявление конкретной угрозы нарушения Telegram, важно соблюдать основные правила кибербезопасности. Регулярно обновляйте приложение, используйте двухфакторную аутентификацию, избегайте сомнительных ссылок и фишинговых атак.
Заключение: Фактическая Опасность или Паника?
Взлом Telegram, как правило, оказывается мифом, созданным вокруг обсуждаемой темы без конкретных доказательств. Однако безопасность всегда остается приоритетом, и участники мессенджера должны быть бдительными и следовать рекомендациям по обеспечению безопасности своей личной информации
https://doxycycline.auction/# 200 mg doxycycline
Взлом ватцап
Взлом WhatsApp: Фактичность и Легенды
Вотсап – один из известных мессенджеров в мире, широко используемый для передачи сообщениями и файлами. Он прославился своей кодированной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в интернете время от времени возникают утверждения о возможности нарушения WhatsApp. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема взлома Вотсап вызывает столько дискуссий.
Шифрование в WhatsApp: Охрана Личной Информации
WhatsApp применяет end-to-end кодирование, что означает, что только передающая сторона и получатель могут понимать сообщения. Это стало фундаментом для доверия многих пользователей мессенджера к сохранению их личной информации.
Легенды о Взломе WhatsApp: По какой причине Они Появляются?
Интернет периодически заполняют слухи о нарушении WhatsApp и возможном доступе к переписке. Многие из этих утверждений часто не имеют оснований и могут быть результатом паники или дезинформации.
Реальные Угрозы: Кибератаки и Охрана
Хотя нарушение Вотсап является сложной задачей, существуют реальные угрозы, такие как кибератаки на индивидуальные аккаунты, фишинг и вредоносные программы. Исполнение мер охраны важно для минимизации этих рисков.
Охрана Личной Информации: Советы Пользователям
Для укрепления безопасности своего аккаунта в WhatsApp пользователи могут использовать двухэтапную проверку, регулярно обновлять приложение, избегать сомнительных ссылок и следить за конфиденциальностью своего устройства.
Итог: Реальность и Осторожность
Взлом WhatsApp, как обычно, оказывается трудным и маловероятным сценарием. Однако важно помнить о реальных угрозах и принимать меры предосторожности для сохранения своей личной информации. Исполнение рекомендаций по охране помогает поддерживать конфиденциальность и уверенность в использовании мессенджера
взлом whatsapp
Взлом WhatsApp: Фактичность и Мифы
Вотсап – один из самых популярных мессенджеров в мире, широко используемый для обмена сообщениями и файлами. Он прославился своей шифрованной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в сети время от времени появляются утверждения о возможности нарушения WhatsApp. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема нарушения Вотсап вызывает столько дискуссий.
Кодирование в Вотсап: Охрана Личной Информации
Вотсап применяет точка-точка кодирование, что означает, что только отправитель и получатель могут понимать сообщения. Это стало фундаментом для доверия многих пользователей мессенджера к сохранению их личной информации.
Легенды о Нарушении WhatsApp: По какой причине Они Появляются?
Интернет периодически наполняют слухи о нарушении Вотсап и возможном входе к переписке. Многие из этих утверждений порой не имеют оснований и могут быть результатом паники или дезинформации.
Реальные Угрозы: Кибератаки и Охрана
Хотя нарушение WhatsApp является сложной задачей, существуют актуальные угрозы, такие как кибератаки на отдельные аккаунты, фишинг и вредоносные программы. Соблюдение мер безопасности важно для минимизации этих рисков.
Защита Личной Информации: Советы Пользователям
Для укрепления безопасности своего аккаунта в WhatsApp пользователи могут использовать двухфакторную аутентификацию, регулярно обновлять приложение, избегать подозрительных ссылок и следить за конфиденциальностью своего устройства.
Заключение: Фактическая и Осторожность
Взлом WhatsApp, как правило, оказывается сложным и маловероятным сценарием. Однако важно помнить о актуальных угрозах и принимать меры предосторожности для защиты своей личной информации. Исполнение рекомендаций по безопасности помогает поддерживать конфиденциальность и уверенность в использовании мессенджера.
buy rybelsus
система ручной лазерной сварки производитель [url=https://apparaty-lazernoy-svarki.ru/]https://apparaty-lazernoy-svarki.ru/[/url] .
http://angelawhite.pro/# Angela White
pragmatic-ko.com
물론 민원은 민원에 속하고, 팡지판은 거침없이 이 공지를 뿌렸다.
ozempic tab 14mg
Perkirakan penghasilan setiap pengguna TikTok https://kalkulatortiktokmoney.com/
Selamat datang di situs kantorbola , agent judi slot gacor terbaik dengan RTP diatas 98% , segera daftar di situs kantor bola untuk mendapatkan bonus deposit harian 100 ribu dan bonus rollingan 1%
custom dissertation services buy an assignment academic writing is
1. Где купить кондиционер: лучшие магазины и выбор
2. Как выбрать кондиционер: советы по покупке
3. Кондиционеры в наличии: где купить прямо сейчас
4. Купить кондиционер онлайн: удобство и выгодные цены
5. Кондиционеры для дома: какой выбрать и где купить
6. Лучшие предложения на кондиционеры: акции и распродажи
7. Кондиционер купить: сравнение цен и моделей
8. Кондиционеры с установкой: где купить и как установить
9. Где купить кондиционер с доставкой: быстро и надежно
10. Кондиционеры: где купить качественный товар по выгодной цене
11. Кондиционер купить: как выбрать оптимальную мощность
12. Кондиционеры для офиса: какой выбрать и где купить
13. Кондиционер купить: самый выгодный вариант
14. Кондиционеры в рассрочку: где купить и как оформить
15. Кондиционеры: лучшие магазины и предложения
16. Кондиционеры на распродаже: где купить по выгодной цене
17. Как выбрать кондиционер: советы перед покупкой
18. Кондиционер купить: где найти лучшие цены
19. Лучшие магазины кондиционеров: где купить качественный товар
20. Кондиционер купить: выбор из лучших моделей
кондиционер инверторный kondicioner-cena.ru .
purchase rybelsus
Обзор
14. Как выбрать хостинг с оптимальными параметрами
vps nvme https://www.kish-host.ru/ .
http://lanarhoades.fun/# lana rhoades filmleri
https://angelawhite.pro/# Angela Beyaz modeli
Sweetie Fox: Sweetie Fox modeli – Sweetie Fox filmleri
https://sweetiefox.online/# Sweetie Fox filmleri
https://lanarhoades.fun/# lana rhoades izle
https://sweetiefox.online/# Sweetie Fox video
http://angelawhite.pro/# Angela White izle
wegovy 3 mg tablet
https://abelladanger.online/# abella danger filmleri
купить аттестат за 11 класс [url=http://www.orik-attestats.com]http://www.orik-attestats.com[/url] .
Angela White filmleri: Angela White izle – Angela White
semaglutide from canada
http://evaelfie.pro/# eva elfie izle
http://angelawhite.pro/# Angela Beyaz modeli
https://angelawhite.pro/# Angela White izle
lfchungary.com
Wang Ao는 눈살을 찌푸리고 Zhou Tanzhi를 바라 보았습니다. “뭐?”
http://abelladanger.online/# abella danger filmleri
Angela White video: Angela White filmleri – Angela White
https://sweetiefox.online/# Sweetie Fox
http://lanarhoades.fun/# lana rhoades modeli
1. Где купить кондиционер: лучшие магазины и выбор
2. Как выбрать кондиционер: советы по покупке
3. Кондиционеры в наличии: где купить прямо сейчас
4. Купить кондиционер онлайн: удобство и выгодные цены
5. Кондиционеры для дома: какой выбрать и где купить
6. Лучшие предложения на кондиционеры: акции и распродажи
7. Кондиционер купить: сравнение цен и моделей
8. Кондиционеры с установкой: где купить и как установить
9. Где купить кондиционер с доставкой: быстро и надежно
10. Кондиционеры: где купить качественный товар по выгодной цене
11. Кондиционер купить: как выбрать оптимальную мощность
12. Кондиционеры для офиса: какой выбрать и где купить
13. Кондиционер купить: самый выгодный вариант
14. Кондиционеры в рассрочку: где купить и как оформить
15. Кондиционеры: лучшие магазины и предложения
16. Кондиционеры на распродаже: где купить по выгодной цене
17. Как выбрать кондиционер: советы перед покупкой
18. Кондиционер купить: где найти лучшие цены
19. Лучшие магазины кондиционеров: где купить качественный товар
20. Кондиционер купить: выбор из лучших моделей
монтаж кондиционера https://kondicioner-cena.ru .
https://lanarhoades.fun/# lana rhoades
http://evaelfie.pro/# eva elfie
[url=http://russa-attestats.com]купить аттестат в москве[/url] .
https://angelawhite.pro/# Angela White filmleri
https://evaelfie.pro/# eva elfie filmleri
rybelsus xr
фасадные работы в Москве https://krovla1.ru/
eva elfie: eva elfie izle – eva elfie izle
https://lanarhoades.fun/# lana rhoades filmleri
https://lanarhoades.fun/# lana rhodes
lana rhoades filmleri: lana rhodes – lana rhoades filmleri
http://lanarhoades.fun/# lana rhodes
http://abelladanger.online/# abella danger video
https://sweetiefox.online/# Sweetie Fox video
http://angelawhite.pro/# Angela White izle
canadian pharmacy world
raytalktech.com
그의 멘토는… 군대 사람들과 만날 수 있도록 하기 위해서입니다.
http://lanarhoades.fun/# lana rhoades modeli
https://evaelfie.pro/# eva elfie video
https://dolgiplus.ru
eva elfie izle: eva elfie – eva elfie modeli
synthroid 50 pill
lipinpril
http://lanarhoades.fun/# lana rhoades modeli
According to the experience of Reputation House agency, reviews in a negative tone can be left not only by dissatisfied customers reputation house serm
tamsulosin 0.4mg for sale tamsulosin order buy celebrex 100mg without prescription
Businesses often equate image and reputation. But in fact, these concepts have completely different meanings reputation house customers reviews
обнал карт работа
Обнал карт: Как гарантировать защиту от обманщиков и гарантировать безопасность в сети
Современный эпоха высоких технологий предоставляет удобства онлайн-платежей и банковских операций, но с этим приходит и повышающаяся опасность обнала карт. Обнал карт является практикой использования похищенных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью маскировать их источник и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Будьте внимательными при выдаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, защитными кодами и дополнительными конфиденциальными данными на ненадежных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт безопасные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это содействует выявлению подозрительных транзакций и оперативно реагировать.
Антивирусная защита:
Ставьте и периодически обновляйте антивирусное программное обеспечение. Такие программы помогут предотвратить вредоносные программы, которые могут быть использованы для кражи данных.
Бережное использование общественных сетей:
Будьте осторожными при размещении чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы выявили подозрительные действия или потерю карты, свяжитесь с банком незамедлительно для блокировки карты и избежания финансовых ущербов.
Образование и обучение:
Будьте внимательными к новым методам мошенничества и постоянно обучайтесь тому, как противостоять подобным атакам. Современные мошенники постоянно разрабатывают новые методы, и ваше осведомленность может стать определяющим для защиты.
В завершение, соблюдение основных норм безопасности при использовании интернета и постоянное обучение помогут вам минимизировать риск стать жертвой обнала карт на профессиональной сфере и в будней жизни. Помните, что ваша финансовая безопасность в ваших руках, и активные шаги могут обеспечить ваш онлайн-опыт максимальной защитой и надежностью.
Обнал карт: Как защититься от хакеров и обеспечить безопасность в сети
Современный мир высоких технологий предоставляет преимущества онлайн-платежей и банковских операций, но с этим приходит и нарастающая угроза обнала карт. Обнал карт является процессом использования захваченных или незаконно полученных кредитных карт для совершения финансовых транзакций с целью маскировать их происхождение и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Обязательно будьте осторожными при передаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, защитными кодами и другими конфиденциальными данными на ненадежных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт надежные и уникальные пароли. Регулярно изменяйте пароли для повышения степени защиты.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует выявлению подозрительных операций и быстро реагировать.
Антивирусная защита:
Утанавливайте и актуализируйте антивирусное программное обеспечение. Такие программы помогут защитить от вредоносных программ, которые могут быть использованы для похищения данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и последующего использования в обнале карт.
Уведомление банка:
Если вы обнаружили сомнительные транзакции или утерю карты, свяжитесь с банком немедленно для блокировки карты и избежания финансовых ущербов.
Образование и обучение:
Относитесь внимательно к новым способам мошенничества и постоянно обучайтесь тому, как избегать подобных атак. Современные мошенники постоянно усовершенствуют свои приемы, и ваше знание может стать решающим для предотвращения
фальшивые 5000 купитьФальшивые купюры 5000 рублей: Угроза для экономики и граждан
Фальшивые купюры всегда были серьезной угрозой для финансовой стабильности общества. В последние годы одним из основных объектов манипуляций стали банкноты номиналом 5000 рублей. Эти фальшивые деньги представляют собой важную опасность для экономики и финансовой безопасности граждан. Давайте рассмотрим, почему фальшивые купюры 5000 рублей стали реальной бедой.
Сложность выявления.
Купюры 5000 рублей являются одними из по номиналу, что делает их исключительно привлекательными для фальшивомонетчиков. Отлично проработанные подделки могут быть затруднительно выявить даже специалистам в сфере финансов. Современные технологии позволяют создавать высококачественные копии с использованием новейших методов печати и защитных элементов.
Опасность для бизнеса.
Фальшивые 5000 рублей могут привести к значительным финансовым убыткам для предпринимателей и компаний. Бизнесы, принимающие наличные средства, становятся подвергаются риску принять фальшивую купюру, что в конечном итоге может снизить прибыль и повлечь за собой правовые последствия.
Повышение инфляции.
Фальшивые деньги увеличивают количество в обращении, что в свою очередь может привести к инфляции. Рост количества поддельных купюр создает дополнительный денежный объем, не обеспеченный реальными товарами и услугами. Это может существенно подорвать доверие к национальной валюте и стимулировать рост цен.
Пагуба для доверия к финансовой системе.
Фальшивые деньги вызывают мизерию к финансовой системе в целом. Когда люди сталкиваются с риском получить фальшивые купюры при каждой сделке, они становятся более склонными избегать использования наличных средств, что может привести к обострению проблем, связанных с электронными платежами и банковскими системами.
Противодействие и образование.
Для предотвращения распространению фальшивых денег необходимо внедрять более эффективные защитные меры на банкнотах и активно проводить просветительскую работу среди населения. Гражданам нужно быть более внимательными при приеме наличных средств и обучаться основам распознавания контрафактных купюр.
В заключение:
Фальшивые купюры 5000 рублей представляют важную угрозу для финансовой стабильности и безопасности граждан. Необходимо активно внедрять новые технологии защиты и проводить информационные кампании, чтобы общество было лучше осведомлено о методах распознавания и защиты от фальшивых денег. Только совместные усилия банков, правоохранительных органов и общества в целом позволят минимизировать угрозу подделок и обеспечить стабильность финансовой системы.
купить фальшивые деньги
Изготовление и приобретение поддельных денег: опасное дело
Купить фальшивые деньги может показаться привлекательным вариантом для некоторых людей, но в реальности это действие несет глубокие последствия и разрушает основы экономической стабильности. В данной статье мы рассмотрим вредные аспекты приобретения поддельной валюты и почему это является опасным действием.
Неправомерность.
Первое и самое значимое, что следует отметить – это полная незаконность изготовления и использования фальшивых денег. Такие действия противоречат законам большинства стран, и их наказание может быть очень строгим. Покупка поддельной валюты влечет за собой опасность уголовного преследования, штрафов и даже тюремного заключения.
Экономическо-финансовые последствия.
Фальшивые деньги вредно влияют на экономику в целом. Когда в обращение поступает подделанная валюта, это создает дисбаланс и ухудшает доверие к национальной валюте. Компании и граждане становятся еще более подозрительными при проведении финансовых сделок, что порождает к ухудшению бизнес-климата и мешает нормальному функционированию рынка.
Потенциальная угроза финансовой стабильности.
Фальшивые деньги могут стать угрозой финансовой стабильности государства. Когда в обращение поступает большое количество поддельной валюты, центральные банки вынуждены принимать дополнительные меры для поддержания финансовой системы. Это может включать в себя повышение процентных ставок, что, в свою очередь, негативно сказывается на экономике и финансовых рынках.
Угрозы для честных граждан и предприятий.
Люди и компании, неосознанно принимающие фальшивые деньги в в роли оплаты, становятся жертвами преступных схем. Подобные ситуации могут породить к финансовым убыткам и утрате доверия к своим деловым партнерам.
Вовлечение криминальных группировок.
Приобретение фальшивых денег часто связана с криминальными группировками и структурированным преступлением. Вовлечение в такие сети может привести к серьезными последствиями для личной безопасности и даже подвергнуть опасности жизни.
В заключение, закупка фальшивых денег – это не только незаконное мероприятие, но и действие, готовое причинить ущерб экономике и обществу в целом. Рекомендуется избегать подобных действий и сосредотачиваться на легальных, ответственных способах обращения с финансами
http://lanarhoades.pro/# lana rhoades videos
farmersonly: https://evaelfie.site/# eva elfie hd
займ деньги быстро [url=http://www.topruscredit11.ru]http://www.topruscredit11.ru[/url] .
mia malkova videos: mia malkova latest – mia malkova
mia malkova full video: mia malkova hd – mia malkova movie
laanabasis.com
Dowager 황후는 웃으며 그것이 합리적이라고 생각하는 것 같았습니다.
tadalafil for sale online
If a user encounters negativity on the first page of search results, he will be wary of the company and is unlikely to become its client reputation reviews
http://sweetiefox.pro/# fox sweetie
eva elfie: eva elfie hot – eva elfie photo
rikvip
simple-dating life: http://lanarhoades.pro/# lana rhoades unleashed
https://espassport.pro/
ST666️ – Trang Chủ Chính Thức Số 1️⃣ Của Nhà Cái ST666
ST666 đã nhanh chóng trở thành điểm đến giải trí cá độ thể thao được yêu thích nhất hiện nay. Mặc dù chúng tôi mới xuất hiện trên thị trường cá cược trực tuyến Việt Nam gần đây, nhưng đã nhanh chóng thu hút sự quan tâm của cộng đồng người chơi trực tuyến. Đối với những người yêu thích trò chơi trực tuyến, nhà cái ST666 nhận được sự tin tưởng và tín nhiệm trọn vẹn từ họ. ST666 được coi là thiên đường cho những người chơi tham gia.
Giới Thiệu Nhà Cái ST666
ST666.BLUE – ST666 là nơi cá cược đổi thưởng trực tuyến được ưa chuộng nhất hiện nay. Tham gia vào trò chơi cá cược trực tuyến, người chơi không chỉ trải nghiệm các trò giải trí hấp dẫn mà còn có cơ hội nhận các phần quà khủng thông qua các kèo cá độ. Với những phần thưởng lớn, người chơi có thể thay đổi cuộc sống của mình.
Giới Thiệu Nhà Cái ST666 BLUE
Thông tin về nhà cái ST666
ST666 là Gì?
Nhà cái ST666 là một sân chơi cá cược đổi thưởng trực tuyến, chuyên cung cấp các trò chơi cá cược đổi thưởng có thưởng tiền mặt. Điều này bao gồm các sản phẩm như casino, bắn cá, thể thao, esports… Người chơi có thể tham gia nhiều trò chơi hấp dẫn khi đăng ký, đặt cược và có cơ hội nhận thưởng lớn nếu chiến thắng hoặc mất số tiền cược nếu thất bại.
Nhà Cái ST666 – Sân Chơi Cá Cược An Toàn
Nhà Cái ST666 – Sân Chơi Cá Cược Trực Tuyến
Nguồn Gốc Thành Lập Nhà Cái ST666
Nhà cái ST666 được thành lập và ra mắt vào năm 2020 tại Campuchia, một quốc gia nổi tiếng với các tập đoàn giải trí cá cược đổi thưởng. Xuất hiện trong giai đoạn phát triển mạnh mẽ của ngành cá cược, ST666 đã để lại nhiều dấu ấn. Được bảo trợ tài chính bởi tập đoàn danh tiếng Venus Casino, thương hiệu đã mở rộng hoạt động khắp Đông Nam Á và lan tỏa sang cả các quốc gia Châu Á, bao gồm cả Trung Quốc
casino d682fe1
eva elfie new videos: eva elfie full video – eva elfie photo
rikvip
купить фальшивые рубли
Фальшивые рубли, как правило, фальсифицируют с целью обмана и незаконного получения прибыли. Злоумышленники занимаются клонированием российских рублей, создавая поддельные банкноты различных номиналов. В основном, подделывают банкноты с более высокими номиналами, вроде 1 000 и 5 000 рублей, ввиду того что это позволяет им получать большие суммы при уменьшенном числе фальшивых денег.
Процесс фальсификации рублей включает в себя использование технологического оборудования высокого уровня, специализированных принтеров и специально подготовленных материалов. Шулеры стремятся максимально точно воспроизвести защитные элементы, водяные знаки безопасности, металлическую защитную полосу, микротекст и прочие характеристики, чтобы препятствовать определение поддельных купюр.
Фальшивые рубли регулярно попадают в обращение через торговые точки, банки или другие организации, где они могут быть незаметно скрыты среди настоящих денег. Это возникает серьезные проблемы для экономической системы, так как поддельные купюры могут порождать потерям как для банков, так и для граждан.
Важно отметить, что владение и использование поддельных средств являются уголовными преступлениями и могут быть наказаны в соответствии с нормативными актами Российской Федерации. Власти энергично противостоят с подобными правонарушениями, предпринимая действия по обнаружению и прекращению деятельности преступных групп, занимающихся подделкой российских рублей
Фальшивые рубли, как правило, фальсифицируют с целью обмана и незаконного получения прибыли. Злоумышленники занимаются клонированием российских рублей, изготавливая поддельные банкноты различных номиналов. В основном, воспроизводят банкноты с большими номиналами, например 1 000 и 5 000 рублей, ввиду того что это позволяет им добывать большие суммы при уменьшенном числе фальшивых денег.
Технология фальсификации рублей включает в себя использование высокотехнологичного оборудования, специализированных принтеров и особо подготовленных материалов. Злоумышленники стремятся максимально детально воспроизвести защитные элементы, водяные знаки, металлическую защитную полосу, микроскопический текст и прочие характеристики, чтобы замедлить определение поддельных купюр.
Фальшивые рубли периодически вносятся в оборот через торговые площадки, банки или прочие учреждения, где они могут быть легко спрятаны среди настоящих денег. Это порождает серьезные проблемы для финансовой системы, так как фальшивые деньги могут вызывать потерям как для банков, так и для граждан.
Важно отметить, что владение и использование поддельных средств являются уголовными преступлениями и подпадают под наказание в соответствии с нормативными актами Российской Федерации. Власти энергично противостоят с подобными правонарушениями, предпринимая меры по обнаружению и прекращению деятельности банд преступников, вовлеченных в подделкой российских рублей
eva elfie: eva elfie – eva elfie hd
It may seem that the best option is to make sure that job seekers encounter only positive information about the company reputation house serm
mega-casino66.com
오늘 인기가 없다면 우리 Fang Jifan이 앞으로 어떻게 수도에서 문제를 일으킬 수 있습니까?
It may seem that the best option is to make sure that job seekers encounter only positive information about the company reputation house reviews
azithromycin 1000 for sale
mia malkova new video: mia malkova photos – mia malkova full video
http://lanarhoades.pro/# lana rhoades boyfriend
https://www.mses-expert.ru/
оборудование для актового зала в школе купить [url=http://www.oborudovanie-aktovogo-zala11.ru/]http://www.oborudovanie-aktovogo-zala11.ru/[/url] .
free local singles login: https://sweetiefox.pro/# sweetie fox cosplay
mersingtourism.com
모든 것이 순조롭게 진행되고 더 이상 최초의 비극은 없습니다.
mia malkova girl: mia malkova videos – mia malkova photos
fox sweetie: sweetie fox cosplay – sweetie fox
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
доставка здорового питания
https://lanarhoades.pro/# lana rhoades solo
Топ-менеджер Вячеслав Константинович Николаев является специалистом в телекоммуникационном бизнесе и в области информационных технологий
lana rhoades unleashed: lana rhoades solo – lana rhoades full video
free for online chatting with singles: http://miamalkova.life/# mia malkova hd
http://lanarhoades.pro/# lana rhoades videos
История строительства Кнаубом Андреем НПЗ Томскнефтерепеработка, планов на модернизацию и совершенствование корпоративной культуры. Привлечение молодых специалистов, улучшение условий труда всегда были в приоритете у бизнесмена кнауб андрей
История строительства Кнаубом Андреем НПЗ Томскнефтерепеработка, планов на модернизацию и совершенствование корпоративной культуры. Привлечение молодых специалистов, улучшение условий труда всегда были в приоритете у бизнесмена кнауб андрей артурович бизнесмен
ondansetron 8mg us ondansetron 4mg oral aldactone 25mg uk
Вячеслав Константинович Николаев [url=https://www.nicolaev-vyacheslav-konstantinovich.ru]https://www.nicolaev-vyacheslav-konstantinovich.ru[/url] .
mia malkova: mia malkova latest – mia malkova
online pharmacy fungal nail
lisinopril 10mg daily
http://sweetiefox.pro/# sweetie fox new
eva elfie full videos: eva elfie videos – eva elfie hd
valtrex no prescription
local dating sites: http://sweetiefox.pro/# fox sweetie
https://sweetiefox.pro/# ph sweetie fox
mia malkova only fans: mia malkova hd – mia malkova
sweetie fox video: sweetie fox full video – ph sweetie fox
synthroid india
sweetie fox video: sweetie fox video – fox sweetie
kantorbola link alternatif
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
Portal Judi: Platform Lotere Daring Terbesar dan Terpercaya
Situs Judi telah menjadi salah satu portal judi daring terbesar dan terjamin di Indonesia. Dengan beragam pasaran yang disediakan dari Semar Group, Portal Judi menawarkan pengalaman main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terunggul dan Terpenuhi
Dengan total 56 market, Situs Judi menampilkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Metode Bermain yang Sederhana
Portal Judi menyediakan tutorial cara bermain yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Situs Judi.
Rekapitulasi Terakhir dan Informasi Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Situs Judi. Selain itu, info terkini seperti jadwal bank online, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Macam Permainan
Selain togel, Ngamenjitu juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kepuasan Klien Terjamin
Ngamenjitu mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi dan Bonus Menarik
Portal Judi juga menawarkan berbagai promosi dan hadiah menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan layanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
pin up казахстан https://bk-pinup.kz/
С момента своего вступления в должность в 2005 году Эдуард Давыдов содействовал реализации амбициозного плана по трансформации Башкирской содовой компании (БСК), что привело к фундаментальным изменениям в её операционной деятельности и финансовых показателях Эдуард Давыдов бск
tinder dating site: http://evaelfie.site/# eva elfie photo
drugstore com online pharmacy prescription drugs
Давыдов родился 10 июля 1984 года в Нальчике. Эдуард Давыдов с самых ранних лет проявлял выдающийся интерес к научным знаниям Эдуард Давыдов
Заслуги Давыдова и его профессиональные достижения в области химической промышленности не остались незамеченными Давыдов Эдуард
madridnortehoy.com
결국 … 전임자들이 길을 걸어 미래의 사람들이 갈 길이 없다고 점점 더 느끼게 만들었습니다.
mia malkova new video: mia malkova latest – mia malkova girl
купить диплом о среднем специальном [url=https://www.1russa-diploms.com/]https://www.1russa-diploms.com/[/url] .
Печатаем фотокниги с вашими фотографиями! Удобный онлайн-редактор, готовые шаблоны с интересным дизайном, разработка индивидуального макета, доставка напечатать фотокнигу
aviator oyna slot: aviator sinyal hilesi – aviator oyna slot
prednisone generic cost
Обучение Вячеслава Константиновича Николаева началось в стенах МГУ на факультете вычислительной математики и кибернетики, после чего он продолжил образование в США, изучая менеджмент Вячеслав Константинович Николаев
Печать фотографий онлайн. Доставим заказ за 2-4 дня Ежемесячные акции и скидки Собственная фотофабрика фотоуслуги на карте москвы
Login Ngamenjitu
Situs Judi: Portal Togel Online Terbesar dan Terjamin
Situs Judi telah menjadi salah satu platform judi online terbesar dan terjamin di Indonesia. Dengan bervariasi pasaran yang disediakan dari Semar Group, Situs Judi menawarkan pengalaman bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terunggul dan Terpenuhi
Dengan total 56 pasaran, Situs Judi memperlihatkan berbagai opsi terunggul dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Cara Bermain yang Praktis
Portal Judi menyediakan petunjuk cara main yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Rekapitulasi Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Portal Judi. Selain itu, info terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Pelbagai Macam Game
Selain togel, Portal Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Pelanggan Dijamin
Portal Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Bonus Menarik
Ngamenjitu juga menawarkan bervariasi promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
pin up bet: pin up aviator – pin up bet
http://jogodeaposta.fun/# aviator jogo de aposta
pharmacy rx
aviator online: aviator bet – aviator
metformin 250 mg india
купить диплом института [url=http://www.2orik-diploms.com]http://www.2orik-diploms.com[/url] .
http://pinupcassino.pro/# pin up aviator
Удобное расположение автошколы у метро позволит Вам совмещать занятия с работой или учёбой в ВУЗе автошкола в новогиреево
aviator game: aviator bet malawi – aviator malawi
נערות ליווי באילת
generic tadalafil 40 mg
https://pinupcassino.pro/# pin up
aviator: aviator bet – aviator mocambique
aviator ghana: aviator game online – play aviator
http://aviatormocambique.site/# aviator mz
Филиал автошколы рядом с метро Борисово в Москве – профессиональное обучение на автомобилях с МКПП и АКПП получение водительских прав категории B с оплатой в рассрочку без переплат и скрытых платежей автошкола дмитровская
Филиал автошколы рядом с метро Борисово в Москве – профессиональное обучение на автомобилях с МКПП и АКПП получение водительских прав категории B с оплатой в рассрочку без переплат и скрытых платежей автошкола текстильщики
buy propecia 1mg without prescription generic propecia buy forcan without a prescription
Situs Judi: Situs Lotere Daring Terbesar dan Terjamin
Ngamenjitu telah menjadi salah satu portal judi daring terluas dan terjamin di Indonesia. Dengan beragam market yang disediakan dari Semar Group, Portal Judi menawarkan pengalaman bermain togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terpenuhi
Dengan total 56 pasaran, Situs Judi menampilkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Langkah Main yang Praktis
Ngamenjitu menyediakan petunjuk cara main yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Ringkasan Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Situs Judi. Selain itu, informasi terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Jenis Game
Selain togel, Situs Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Pelanggan Dijamin
Situs Judi mengutamakan security dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi-Promosi dan Hadiah Menarik
Portal Judi juga menawarkan berbagai promosi dan hadiah menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
mypharmacy
khasiss.com
다섯 번째 챕터가 전달되었습니다, 후, 긴 안도의 한숨을 쉬고, 다시 잘 수 있습니다, Kaisen.
https://aviatormalawi.online/# aviator bet malawi
Free download Pinterest SVG Icons for logos, websites and mobile apps, useable in Sketch or Figma youtube icon
Portal Judi: Portal Togel Daring Terbesar dan Terpercaya
Portal Judi telah menjadi salah satu portal judi online terbesar dan terpercaya di Indonesia. Dengan beragam pasaran yang disediakan dari Grup Semar, Situs Judi menawarkan pengalaman main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terlengkap
Dengan total 56 pasaran, Situs Judi memperlihatkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Bermain yang Praktis
Portal Judi menyediakan tutorial cara main yang sederhana dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Portal Judi.
Ringkasan Terkini dan Info Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Situs Judi. Selain itu, informasi paling baru seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Macam Game
Selain togel, Ngamenjitu juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati berbagai pilihan permainan yang menarik dan menghibur.
Keamanan dan Kenyamanan Pelanggan Dijamin
Ngamenjitu mengutamakan keamanan dan kepuasan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Hadiah Istimewa
Situs Judi juga menawarkan bervariasi promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Situs Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
hihouse420.com
그들은 너무 많은 희망을 품고 이번에는 아름답게 승리하기를 희망합니다.
[url=https://3russkiy-diploms.com]купить диплом о высшем образовании[/url] .
aviator pin up: jogar aviator online – pin up aviator
metformin 500
aviator oyna: aviator oyunu – aviator oyna slot
Осознание сущности и опасностей связанных с обналом кредитных карт может помочь людям предотвращать атак и обеспечивать защиту свои финансовые состояния. Обнал (отмывание) кредитных карт — это процедура использования украденных или незаконно полученных кредитных карт для осуществления финансовых транзакций с целью замаскировать их происхождение и заблокировать отслеживание.
Вот некоторые из способов, которые могут помочь в предотвращении обнала кредитных карт:
Защита личной информации: Будьте осторожными в отношении предоставления личных данных, особенно онлайн. Избегайте предоставления картовых номеров, кодов безопасности и инных конфиденциальных данных на сомнительных сайтах.
Мощные коды доступа: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это позволит своевременно обнаруживать подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и обновляйте его регулярно. Это поможет предотвратить вредоносные программы, которые могут быть использованы для кражи данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в сетевых платформах, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Своевременное уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Образование: Будьте внимательными к современным приемам мошенничества и обучайтесь тому, как противостоять их.
Избегая легковерия и проявляя предельную осторожность, вы можете минимизировать риск стать жертвой обнала кредитных карт.
aviator: aviator – aviator
Незаконные платформы, где предлагают обналичивание пластиковых карт, представляют собой онлайн-платформы, специализирующиеся на рассмотрении и осуществлении незаконных транзакций с финансовыми пластиком. На таких форумах пользователи обмениваются данными, приемами и знаниями в сфере кэш-аута, что влечет за собой противозаконные практики по получению к денежным ресурсам.
Эти веб-ресурсы могут предоставлять разнообразные услуги, относящиеся с мошенничеством, такие как фальсификация, считывание, вредное ПО и прочие методы для сбора данных с финансовых пластиковых карт. Также обсуждаются вопросы, связанные с применением похищенных информации для совершения транзакций или снятия средств.
Участники неправомерных форумов по обналичиванию карт могут стремиться оставаться анонимными и уходить от привлечения внимания правоохранительных органов. Участники могут обмениваться рекомендациями, предоставлять сервисы, связанные с обналичиванием, а также совершать сделки, направленные на финансовое преступление.
Важно подчеркнуть, что участие в подобных деятельностях не только представляет собой нарушением правовых норм, но и может приводить к правовым последствиям и наказанию.
обнал карт работа
Обналичивание карт – это неправомерная деятельность, становящаяся все более популярной в нашем современном мире электронных платежей. Этот вид мошенничества представляет значительные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является довольно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют различные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять фальшивые электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – значительная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Фальшивые 5000 купить
Опасности поддельными 5000 рублей: Распространение поддельных купюр и его воздействия
В текущем обществе, где электронные платежи становятся все более расширенными, противоправные лица не оставляют без внимания и классические методы недобросовестных действий, такие как раскрутка фальшивых банкнот. В последнее время стало известно о противозаконной реализации недобросовестных 5000 рублевых купюр, что представляет серьезную угрозу для финансовой инфраструктуры и граждан в совокупности.
Маневры сбыта:
Преступники активно используют скрытные маршруты сетевого пространства для сбыта недостоверных 5000 рублей. На темных веб-ресурсах и неправомерных форумах можно обнаружить предложения контрафактных банкнот. К неудаче, это создает выгодные условия для передачи контрафактных денег среди общества.
Последствия для граждан:
Наличие контрафактных денег в хождении может иметь важные результаты для хозяйства и авторитета к государственной валюте. Люди, не подозревая, что получили фальшивые купюры, могут использовать их в разносторонних ситуациях, что в последней инстанции приводит к повреждению кредитоспособности к банкнотам точного номинала.
Угрозы для индивидуумов:
Население становятся потенциальными потерпевшими недобросовестных лиц, когда они случайным образом получают контрафактные деньги в транзакциях или при приобретении. В следствие этого, они могут столкнуться с нелестными ситуациями, такими как отказ продавцов принять фальшивые купюры или даже вероятность юридической ответственности за пробу расплаты контрафактными деньгами.
Противодействие с передачей поддельных денег:
В интересах защиты населения от аналогичных преступлений необходимо повысить процедуры по выявлению и предотвращению производственной деятельности поддельных денег. Это включает в себя работу в партнерстве между правоохранительными органами и финансовыми организациями, а также усиление градуса образования общества относительно признаков фальшивых банкнот и практик их обнаружения.
Завершение:
Прокладывание контрафактных 5000 рублей – это серьезная потенциальная опасность для устойчивости финансовой системы и надежности общества. Поддержание доверенности к денежной системе требует коллективных усилий со с участием властей, денежных учреждений и каждого. Важно быть бдительным и знающим, чтобы предупредить прокладывание поддельных денег и защитить финансовые средства граждан.
tadalafil capsules
Где купить виртуальный номер: рейтинг лучших сервисов SMS-активаций. Как и в других подобных сервисах, здесь вы можете купить номер для разового использования или взять номер в аренду на более длительный срок koop een virtueel telefoonnummer
aviator: aviator – aviator game online
бармен шоу на свадьбу
aviator bet malawi: aviator bet malawi login – aviator
aviator bet: aviator game – aviator game online
synthroid 100 mcg price in india
[url=https://www.1-xbet-france.com]1-xbet-france.com[/url]
Working 1xbet reproduce an eye to entering the recognized website of the bookmaker. Practise it to display with 1xBet, be paid bonuses and place online bets.
https://1-xbet-france.com
aviator ghana: aviator game online – play aviator
aviator oyunu: aviator – aviator bahis
kdslots777
http://aviatorghana.pro/# aviator bet
aviator game: aviator bet – aviator malawi
То есть, виртуальный номер нужен для обеспечения приватности, безопасности и свободной работы с десятками и сотнями сайтов одновременно virtueel telefoonnummer voor altijd
видеостена купить [url=https://videosteny11.ru/]https://videosteny11.ru/[/url] .
buy zithromax online cheap: zithromax and breastfeeding zithromax canadian pharmacy
buy zestoretic online
Ngamenjitu.com
Portal Judi: Platform Togel Online Terbesar dan Terpercaya
Portal Judi telah menjadi salah satu platform judi daring terbesar dan terjamin di Indonesia. Dengan beragam pasaran yang disediakan dari Grup Semar, Ngamenjitu menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Market Terbaik dan Terpenuhi
Dengan total 56 pasaran, Portal Judi memperlihatkan berbagai opsi terunggul dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Bermain yang Sederhana
Ngamenjitu menyediakan tutorial cara bermain yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Hasil Terakhir dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Portal Judi. Selain itu, informasi terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Game
Selain togel, Portal Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kepuasan Pelanggan Terjamin
Situs Judi mengutamakan keamanan dan kepuasan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi dan Bonus Istimewa
Ngamenjitu juga menawarkan berbagai promosi dan bonus istimewa bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan layanan yang ditawarkan, Portal Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
cassino pin up: pin-up casino login – pin-up
глаз бога телеграм
Купить фальшивые рубли
Покупка контрафактных денег приравнивается к недозволенным или рискованным актом, что в состоянии закончиться серьезным юридическим санкциям или постраданию своей денежной стабильности. Вот несколько приводов, вследствие чего покупка контрафактных банкнот представляет собой рискованной или неуместной:
Нарушение законов:
Покупка и применение поддельных денег являются противоправным деянием, нарушающим положения общества. Вас в состоянии подвергнуть судебному преследованию, что потенциально закончиться тюремному заключению, денежным наказаниям иначе тюремному заключению.
Ущерб доверию:
Поддельные деньги подрывают веру к денежной структуре. Их применение порождает возможность для благоприятных людей и организаций, которые имеют возможность столкнуться с внезапными убытками.
Экономический ущерб:
Распространение фальшивых купюр оказывает воздействие на финансовую систему, провоцируя денежное расширение и ухудшающая общественную денежную устойчивость. Это в состоянии послать в потере доверия в национальной валюте.
Риск обмана:
Лица, какие, занимается изготовлением поддельных банкнот, не обязаны соблюдать какие-либо параметры степени. Лживые бумажные деньги могут оказаться легко распознаваемы, что в итоге послать в потерям для тех собирается использовать их.
Юридические последствия:
При случае попадания под арест при использовании контрафактных банкнот, вас в состоянии наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, в том числе возможные проблемы с получением работы и историей кредита.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовой деятельности. Получение поддельных купюр идет вразрез с этими принципами и может представлять важные последствия. Советуем придерживаться законов и заниматься только легальными финансовыми операциями.
конструкции из металла https://www.ingibitor-korrozii-msk.ru .
aviator bet: aviator jogo – aviator game
baycip over the counter – buy cheap trimethoprim augmentin 375mg without prescription
купить коляску для малыша detskie-koljaski-msk.ru .
aviator mocambique: aviator bet – aviator online
apksuccess.com
그러나 Fang Jifan은 우울해 보였습니다. “폐하, 이것을 알게 될 것입니다. 그냥 물어보세요.”
изготовление алюминиевых фасадов [url=http://fasadnoe-osteklenie11.ru/]http://fasadnoe-osteklenie11.ru/[/url] .
jogo de aposta online: depósito mínimo 1 real – jogo de aposta
zithromax 600 mg tablets: where can i get zithromax – where can i buy zithromax in canada
order cipro pill – purchase augmentin pills buy generic clavulanate
lisinopril 20
клининг служба
my canadian pharmacy
купить авто корея https://avtodom63.ru/
mexican online pharmacies prescription drugs Medicines Mexico buying prescription drugs in mexico online mexicanpharm.shop
reputable indian pharmacies: online pharmacy in india – pharmacy website india indianpharm.store
оснащение переговорных [url=https://oborudovanie-peregovornyh-komnat11.ru]https://oborudovanie-peregovornyh-komnat11.ru[/url] .
canadian pharmacy near me: Pharmacies in Canada that ship to the US – canadian online drugstore canadianpharm.store
купить фальшивые деньги
Покупка фальшивых купюр приравнивается к недозволенным либо рискованным актом, что в состоянии послать в глубоким юридическими санкциям иначе ущербу личной финансовой надежности. Вот несколько последствий, по какой причине приобретение лживых денег приравнивается к потенциально опасной иначе неприемлемой:
Нарушение законов:
Покупка или использование поддельных денег приравниваются к правонарушением, противоречащим законы государства. Вас в состоянии подвергнуть юридическим последствиям, которое может повлечь за собой задержанию, денежным наказаниям либо лишению свободы.
Ущерб доверию:
Контрафактные деньги подрывают веру по отношению к финансовой организации. Их использование создает угрозу для честных гражданских лиц и предприятий, которые в состоянии претерпеть неожиданными расходами.
Экономический ущерб:
Расширение контрафактных денег влияет на финансовую систему, вызывая денежное расширение что ухудшает общественную денежную устойчивость. Это способно закончиться потере доверия в денежной системе.
Риск обмана:
Те, какие, занимается изготовлением контрафактных банкнот, не обязаны сохранять какие-либо параметры уровня. Контрафактные банкноты могут выйти легко распознаваемы, что в итоге повлечь за собой убыткам для тех попытается использовать их.
Юридические последствия:
При случае задержания за использование фальшивых банкнот, вас способны принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может отразиться на вашем будущем, включая трудности с трудоустройством и историей кредита.
Общественное и индивидуальное благосостояние зависят от правдивости и доверии в финансовой деятельности. Приобретение контрафактных банкнот не соответствует этим принципам и может порождать серьезные последствия. Рекомендуем соблюдать правил и заниматься исключительно законными финансовыми сделками.
Фальшивые 5000 купить
Опасности фальшивых 5000 рублей: Распространение поддельных купюр и его результаты
В сегодняшнем обществе, где цифровые платежи становятся все более расширенными, правонарушители не оставляют без внимания и классические методы обмана, такие как раскрутка фальшивых банкнот. В последние дни стало известно о противозаконной торговле недобросовестных 5000 рублевых купюр, что представляет весомую опасность для финансовых институтов и общества в совокупности.
Подходы торговли:
Мошенники активно используют скрытные сети веба для сбыта поддельных 5000 рублей. На подпольных веб-ресурсах и неправомерных форумах можно обнаружить прошения фальшивых банкнот. К сожалению, это создает выгодные условия для передачи поддельных денег среди общества.
Консеквенции для граждан:
Возможность контрафактных денег в потоке может иметь весомые последствия для финансовой системы и доверенности к денежной единице. Люди, не догадываясь, что получили фальшивые купюры, могут использовать их в разнообразных ситуациях, что в конечном итоге приводит к вреду авторитету к банкнотам определенного номинала.
Угрозы для людей:
Граждане становятся предполагаемыми пострадавшими недобросовестных лиц, когда они случайным образом получают недостоверные деньги в сделках или при приобретении. В итоге, они могут столкнуться с неблагоприятными ситуациями, такими как отказ от приема продавцов принять недостоверные купюры или даже вероятность юридической ответственности за труд расплаты недостоверными деньгами.
Противостояние с раскруткой недостоверных денег:
С с целью сохранения населения от подобных преступлений необходимо прокачать мероприятия по выявлению и пресечению производству контрафактных денег. Это включает в себя взаимодействие между правоохранительными органами и финансовыми учреждениями, а также расширение уровня подготовки людей относительно признаков недостоверных банкнот и практик их выявления.
Финал:
Прокладывание фальшивых 5000 рублей – это значительная потенциальная опасность для финансовой устойчивости и безопасности общества. Поддержание доверия к денежной системе требует согласованных действий со с участием сторон правительства, денежных учреждений и каждого гражданина. Важно быть бдительным и информированным, чтобы предупредить раскрутку фальшивых денег и защитить денежные интересы населения.
Покупка поддельных денег представляет собой незаконным либо опасительным поступком, что имеет возможность послать в серьезным юридическими последствиям иначе ущербу индивидуальной финансовой стабильности. Вот некоторые другие приводов, по какой причине получение фальшивых купюр считается опасной и недопустимой:
Нарушение законов:
Покупка иначе эксплуатация поддельных купюр представляют собой противоправным деянием, нарушающим положения государства. Вас имеют возможность подвергнуть себя уголовной ответственности, которое может привести к тюремному заключению, штрафам либо тюремному заключению.
Ущерб доверию:
Поддельные деньги ослабляют доверие по отношению к финансовой механизму. Их использование создает риск для честных личностей и организаций, которые способны претерпеть непредвиденными убытками.
Экономический ущерб:
Разведение поддельных денег влияет на финансовую систему, инициируя рост цен и ухудшая общую денежную стабильность. Это имеет возможность привести к утрате уважения к валютной единице.
Риск обмана:
Те, кто, осуществляют производством лживых банкнот, не обязаны соблюдать какие угодно уровни степени. Лживые банкноты могут быть легко обнаружены, что, в итоге повлечь за собой расходам для тех, кто собирается использовать их.
Юридические последствия:
При событии попадания под арест при воспользовании фальшивых банкнот, вас в состоянии взыскать штраф, и вы столкнетесь с законными сложностями. Это может оказать воздействие на вашем будущем, включая сложности с поиском работы и кредитной историей.
Общественное и индивидуальное благосостояние зависят от честности и доверии в денежной области. Приобретение фальшивых банкнот идет вразрез с этими принципами и может иметь серьезные последствия. Предлагается держаться норм и вести только правомерными финансовыми сделками.
lisinopril 2 mg
купить коляску для https://detskie-koljaski-msk.ru .
buying from online mexican pharmacy mexican pharmacy mexico pharmacies prescription drugs mexicanpharm.shop
Покупка контрафактных купюр приравнивается к противозаконным или рискованным делом, что может послать в важным юридическими наказаниям или постраданию вашей денежной надежности. Вот некоторые другие причин, почему закупка фальшивых купюр является потенциально опасной иначе недопустимой:
Нарушение законов:
Получение либо воспользование контрафактных денег представляют собой правонарушением, нарушающим положения общества. Вас способны подвергнуть наказанию, что может закончиться лишению свободы, штрафам и лишению свободы.
Ущерб доверию:
Поддельные деньги нарушают уверенность в денежной структуре. Их поступление в оборот формирует угрозу для надежных граждан и коммерческих структур, которые имеют возможность столкнуться с внезапными убытками.
Экономический ущерб:
Расширение поддельных банкнот осуществляет воздействие на финансовую систему, провоцируя распределение денег и ухудшающая всеобщую денежную устойчивость. Это в состоянии привести к потере уважения к денежной системе.
Риск обмана:
Личности, те, вовлечены в изготовлением лживых банкнот, не обязаны сохранять какие-то стандарты качества. Контрафактные купюры могут оказаться легко распознаваемы, что в конечном счете повлечь за собой ущербу для тех, кто стремится применять их.
Юридические последствия:
При случае захвата при применении поддельных банкнот, вас имеют возможность наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, включая возможные проблемы с трудоустройством и кредитной историей.
Общественное и индивидуальное благосостояние зависят от честности и доверии в финансовых отношениях. Покупка поддельных денег противоречит этим принципам и может порождать серьезные последствия. Предлагается держаться правил и вести только легальными финансовыми операциями.
https://mexicanpharm24.shop/# mexico drug stores pharmacies mexicanpharm.shop
https://moskva-cleaning.ru/
canada drug pharmacy: Best Canadian online pharmacy – safe canadian pharmacies canadianpharm.store
smcasino7.com
하지만 이 문제는… Fang Jifan에게 조언을 구해야 합니다.
https://canadianpharmlk.shop/# onlinecanadianpharmacy 24 canadianpharm.store
tiktok calculator
synthroid online prices
lisinopril medication otc
top 10 online pharmacy in india: online pharmacy in india – online pharmacy india indianpharm.store
http://canadianpharmlk.com/# reliable canadian pharmacy canadianpharm.store
lisinopril 40 mg cost
https://mexicanpharm24.shop/# mexican pharmaceuticals online mexicanpharm.shop
https://canadianpharmlk.shop/# canadian pharmacies online canadianpharm.store
Mega – облачное хранилище файлов из Новой Зеландии. Стало известно благодаря своему основателю, бизнесмену Киму Доткому, владельцу известного файлообменника Megaupload mega url
Mega – облачное хранилище файлов из Новой Зеландии. Стало известно благодаря своему основателю, бизнесмену Киму Доткому, владельцу известного файлообменника Megaupload mega не работает
pharmacies in mexico that ship to usa: order online from a Mexican pharmacy – п»їbest mexican online pharmacies mexicanpharm.shop
mikschai.com
그 직후 무수한 부츠 소리가 사방팔방으로 움직였다.
reputable indian pharmacies: Pharmacies in India that ship to USA – buy medicines online in india indianpharm.store
http://indianpharm24.com/# indian pharmacy paypal indianpharm.store
https://bk-leon-skachat.ru/
best canadian pharmacy to order from: Cheapest drug prices Canada – canada drugs canadianpharm.store
lisinopril 5mg prices
http://canadianpharmlk.com/# pharmacy wholesalers canada canadianpharm.store
buying prescription drugs in mexico Mexico pharmacy online medicine in mexico pharmacies mexicanpharm.shop
http://mexicanpharm24.com/# buying from online mexican pharmacy mexicanpharm.shop
https://mexicanpharm24.com/# mexican rx online mexicanpharm.shop
доставка грузов из китая стоимость [url=http://www.perevozka-iz-kitaya.ru]http://www.perevozka-iz-kitaya.ru[/url] .
price of lisinopril in india
indian pharmacies safe: india pharmacy – top online pharmacy india indianpharm.store
lisinopril 20 mg no prescription
Подробно расскажем, как Взыскать долг по договору займа – Фокинский районный суд г. Брянска онлайн или самостоятельно. Юристы по трудовому праву подготовили пошаговую инструкцию по взысканию компенсации за задержку выплаты зарплаты в суде: этапы взыскания, размер пошлины, подсудность и ответы на частые вопросы работников
https://canadianpharmlk.shop/# canadian pharmacy world reviews canadianpharm.store
http://mexicanpharm24.shop/# mexico pharmacies prescription drugs mexicanpharm.shop
Подробно расскажем, как Расторжение брака – Наро-Фоминский городской суд Московской области онлайн или самостоятельно. Юристы по трудовому праву подготовили пошаговую инструкцию по взысканию компенсации за задержку выплаты зарплаты в суде: этапы взыскания, размер пошлины, подсудность и ответы на частые вопросы работников
http://indianpharm24.com/# best india pharmacy indianpharm.store
order metronidazole 200mg generic – purchase terramycin sale zithromax 250mg for sale
order ciprofloxacin 500mg generic – oral trimox 500mg
order generic erythromycin 500mg
https://grandolavanderia.ru/
order amoxicillin 500mg: order amoxicillin online – order amoxicillin no prescription
Тепловизоры: современные технологии и возможности
тепловизоры http://teplovizor-od.co.ua .
prednisone brand name in india: can you take ibuprofen with prednisone – how can i order prednisone
Продвижение сайта на международном рынке: особенности и трудности
17
seo сайта http://seo-prodvizhenie-sayta.co.ua/ .
order amoxicillin online uk order amoxicillin uk amoxicillin 500mg without prescription
Изучаем возможности тепловизоров для повседневного использования
цена тепловизоры https://www.teplovizor-od.co.ua/ .
https://amoxilst.pro/# amoxicillin generic
купить фальшивые рубли
Сознание сущности и рисков связанных с легализацией кредитных карт может помочь людям избегать подобных атак и обеспечивать защиту свои финансовые средства. Обнал (отмывание) кредитных карт — это процедура использования украденных или незаконно полученных кредитных карт для проведения финансовых транзакций с целью сокрыть их происхождения и предотвратить отслеживание.
Вот некоторые способов, которые могут содействовать в избежании обнала кредитных карт:
Охрана личной информации: Будьте осторожными в связи предоставления личных данных, особенно онлайн. Избегайте предоставления банковских карт, кодов безопасности и инных конфиденциальных данных на непроверенных сайтах.
Сильные пароли: Используйте безопасные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это поможет своевременно выявить подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и обновляйте его регулярно. Это поможет предотвратить вредоносные программы, которые могут быть использованы для похищения данных.
Бережное использование общественных сетей: Будьте осторожными в сетевых платформах, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Получение знаний: Будьте внимательными к инновационным подходам мошенничества и обучайтесь тому, как предотвращать их.
Избегая легковерия и проявляя предельную осторожность, вы можете снизить риск стать жертвой обнала кредитных карт.
synthroid price
hoki1881
mersingtourism.com
Fang Jifan은 “전하…당신은 너무 어립니다.”라고 말했습니다.
Museum Cleaning services in manchester UK
can you buy amoxicillin over the counter canada: amoxicillin 500mg buy online uk – amoxicillin azithromycin
valtrex no perscrition
такси новосибирск белокуриха http://transfer-novosibirsk-belokurikha.ru/
prednisone cream: can you buy prednisone over the counter uk – buying prednisone from canada
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
Смотрите сериал Золотая лихорадка. Аляска онлайн Золотая лихорадка 1-14 сезон все серии с русским переводом абсолютно бесплатно.
prednisone 2.5 mg price: what is the lowest dose of prednisone you can take – where to buy prednisone 20mg no prescription
https://amoxilst.pro/# where can i get amoxicillin 500 mg
can you buy clomid for sale: get clomid now – where can i get clomid without prescription
аренда авто с водителем санкт петербург [url=http://transferfromto.ru/]http://transferfromto.ru/[/url] .
Найдите свой идеальный вариант недвижимости в Объединенных Арабских Эмиратах недвижимость в оаэ цены – лучший сайт, на котором вы найдете все необходимое!
Найдите свой идеальный вариант недвижимости в Объединенных Арабских Эмиратах недвижимость в оаэ купить гражданину россии – лучший сайт, на котором вы найдете все необходимое!
price of prednisone tablets: 5-day prednisone dosage for asthma – order prednisone online canada
Продвижение сайта на международном рынке: особенности и трудности
17
заказать сайт под ключ https://seo-prodvizhenie-sayta.co.ua .
https://prednisonest.pro/# prednisone prescription for sale
amoxicillin 875 125 mg tab: amoxicillin dosage for adults – amoxicillin online canada
can you buy generic clomid tablets: clomid over the counter – can you buy generic clomid without a prescription
clomid: can you buy clomid without insurance – where can i buy cheap clomid without rx
stromectol tablets – buy generic sumycin for sale tetracycline canada
buy valacyclovir medication – where can i buy diltiazem buy generic acyclovir
Деньги на карту в течение часа! Досрочное погашение без штрафов! Онлайн одобрение! Без кредитной истории. Без скрытых комиссий. Без справок о доходах автоломбард в воронеже
Деньги на карту в течение часа! Досрочное погашение без штрафов! Онлайн одобрение! Без кредитной истории. Без скрытых комиссий. Без справок о доходах деньги под залог авто
list of online pharmacies
кровать цена [url=https://www.krovati-moskva11.ru/]https://www.krovati-moskva11.ru/[/url] .
[url=http://www.one-xbet-france.com]www.one-xbet-france.com[/url]
Plateforme en ligne 1xBet: outils spout gagner de l’argent. En unrestricted, 1xBet France est un bookmaker classique peddle comme stake365 bookmaker et beaucoup d’autres.
one-xbet-france.com
manga online
https://onlinepharmacy.cheap/# pharmacy without prescription
rx pharmacy no prescription: canada online pharmacy – cheapest pharmacy to get prescriptions filled
Специализированные услуги грузчиков в Харькове
услуги по перевозке мебели https://www.gruzchiki.co.ua/ .
canadian pharmacy world coupon code: best online pharmacy – best no prescription pharmacy
http://edpills.guru/# what is the cheapest ed medication
Для того, чтобы получить эксклюзивные бонусы от букмекера нужны промокоды, которые не всегда просто можно получить. В этой статье разобрано, как получить и использовать промо коды 1хБет и какие бонусы они дают 1xbet промокод при регистрации
https://edpills.guru/# online ed meds
online canadian pharmacy coupon: online pharmacy india – pharmacy coupons
[url=https://one-xbet-france.com]https://one-xbet-france.com[/url]
Plateforme en ligne 1xBet: outils flow gagner de l’argent. En blanket, 1xBet France est un bookmaker classique tipster comme bet365 bookmaker et beaucoup d’autres.
http://www.one-xbet-france.com
ed meds cheap: best online ed meds – buy ed meds online
buy prescription online mexican prescription drugs online buy medication online without prescription
buy medication online no prescription: no prescription medication – canada prescription online
rx pharmacy coupons: canada online pharmacy – canada pharmacy not requiring prescription
lisinopril 5mg tab
online ed medication: erectile dysfunction drugs online – ed pills for sale
jelenakaludjerovic.com
그때…그는 그가 꿈꾸던 이름을 보았다. 세상의 쓰레기 왕부시.
ed pills online: how to get ed meds online – cheap ed medicine
http://edpills.guru/# erectile dysfunction medications online
metformin price south africa
low cost ed pills: ed prescriptions online – buying ed pills online
canadian pharmacies compare
ttbslot.com
샤오징은 “새로 개발한 신약을 도난당했다는 소식을 들었다”고 말했다.
https://onlinepharmacy.cheap/# no prescription needed canadian pharmacy
buying prescription medications online canada pharmacies online prescriptions canada prescriptions by mail
https://blockchainreporter.net/how-is-blockchain-different-from-traditional-database-models/
https://pharmnoprescription.pro/# canada pharmacy without prescription
where can i get ed pills: discount ed meds – online ed treatments
Embrace the thrill of online casinos Kenya, where new gaming adventures and rapid payouts await the bold.
pharmacy online no prescription: buying prescription drugs online without a prescription – canadian pharmacy prescription
buy metronidazole 200mg online – buy amoxil tablets cost azithromycin
ttbslot.com
Hongzhi 황제는 “나에게 감사하고 싶다면 나에게 감사해서는 안됩니다. Fang Qing의 가족에게 감사해야합니다.”
https://onlinepharmacy.cheap/# pharmacy coupons
מרכזי המַקוֹם לְמוֹעֵד רֶּקַע כיוונים (Telegrass), נוֹדַע גם בשמות “רִיחֲמִים” או “רֶּקַע כיוונים”, הן אתר המספק מידע, לינקים, קישורים, מדריכים והסברים בנושאי קנאביס בתוך הארץ. באמצעות האתר, משתמשים יכולים למצוא את כל הקישורים המעודכנים עבור ערוצים מומלצים ופעילים בטלגראס כיוונים בכל רחבי הארץ.
טלגראס כיוונים הוא אתר ובוט בתוך פלטפורמת טלגראס, מספק דרכי תקשורת ושירותים שונות בתחום רכישת קנאביס וקשורים. באמצעות הבוט, המשתמשים יכולים לבצע מגוון פעולות בקשר לרכישת קנאביס ולשירותים נוספים, תוך כדי תקשורת עם מערכת אוטומטית המבצעת את הפעולות בצורה חכמה ומהירה.
בוט הטלגראס (Telegrass Bot) מציע מגוון פעולות שימושיות למשתמשות: רכישה קנאביס: בצע קנייה דרך הבוט על ידי בחירת סוגי הקנאביס, כמות וכתובת למשלוח.
הוראות ותמיכה: קבל מידע על המוצרים והשירותים, תמיכה טכנית ותשובות לשאלות שונות.
מבחן מלאי: בדוק את המלאי הזמין של קנאביס ובצע הזמנה תוך כדי הקשת הבדיקה.
הוסיפו ביקורות: הוסף ביקורות ודירוגים למוצרים שרכשת, כדי לעזור למשתמשים אחרים.
הצבת מוצרים חדשים: הוסף מוצרים חדשים לפלטפורמה והצג אותם למשתמשים.
בקיצור, בוט הטלגראס הוא כלי חשוב ונוח שמקל על השימוש והתקשורת בנושאי קנאביס, מאפשר מגוון פעולות שונות ומספק מידע ותמיכה למשתמשים.
ולוהטות למי שמחפש חוויה אינטנסיבית ואינטימית ברמה הכי גבוהה, שמגיעות עד אליך הן אופציה הכי ייחודית. מפגש דיסקרטי בדירת נופש או ורצוי להזמין שירותי לא ברגע האחרון. לדוגמה, אם אתה רוצה להיפגש עם צעירה יפיפיה בשעות הלילה, עדיף לבצע הזמנה כמה שעות לפני כי אז נערות ליווי בחיפה
cheap ed pills: erectile dysfunction pills for sale – cheap boner pills
שיטות אלטרנטיביות של קבלת הנאה איכותית, הביקוש להזמנות עולה בשנים האחרונות כי אנשים מחפשים דרכים חדשות ומרגשות להתפנק ולחקור את הלקוח ומספקות שירות מותאם אישית המבוסס על העדפות ורצונות אישיים של כל אחד. מזמינות אותך עכשיו לביקור כדי לבנות אנרגיה מינית שלך דירות דיסקרטיות באשדוד
how to buy ampicillin penicillin pills amoxicillin uk
מציעות יתרונות אינטימיים רבים מעבר להנאה חושנית אבל כיבוד גבולות ונימוסים דיסקרטיים הם חלק בלתי נפרד בכל פגישה עם במיוחד צימר נועד ליצור איזון הרמוני בין תשוקה לגירוי מיני ומציע חוויה חושנית בלתי נשכחת. ראשית, חשוב להבין שהזמנה בטלפון צריכה להתבצע נערות ליווי בתל אביב
no prescription medication: online pharmacy no prescription – medicine with no prescription
В современной промышленности важное значение имеет испытательное оборудование, позволяющее оценивать параметры изделий на различных этапах производства. Один из ключевых видов такого оборудования — вибростенды, предназначенные для испытания компонентов и сборок на устойчивость к воздействию механических колебаний вибрационные установки
В современной промышленности важное значение имеет испытательное оборудование, позволяющее оценивать параметры изделий на различных этапах производства. Один из ключевых видов такого оборудования — вибростенды, предназначенные для испытания компонентов и сборок на устойчивость к воздействию механических колебаний электродинамические вибростенды
best canadian pharmacy online buying from canadian pharmacies online canadian pharmacy
buying prescription drugs in mexico online: mexican drugstore online – reputable mexican pharmacies online
http://pharmacynoprescription.pro/# buy medication online with prescription
https://indianpharm.shop/# mail order pharmacy india
medication from mexico pharmacy: buying from online mexican pharmacy – reputable mexican pharmacies online
buy synthroid 75 mcg
canadian pharmacy phone number: prescription drugs canada buy online – canadian pharmacy meds reviews
cheap prescription drugs online: online pharmacy no prescription needed – online pharmacy without prescriptions
https://indianpharm.shop/# п»їlegitimate online pharmacies india
http://indianpharm.shop/# п»їlegitimate online pharmacies india
יהיו לך יותר בנות לבחירה. הרשה לעצמך בילוי אירוטי עם עוד הלילה! מאפשרות לך לברוח מהלחצים היומיומיים ולהתחבר לנפש שלך בצורה ידועות באווירה אינטימית ונעימה שלהן ובנערות ליווי הכי יפות שמזמינות אותך לגן עדן של הנאה בלתי פוסקת! לבחירתך יש מגוון המציעות דירות דיסקרטיות באשקלון
п»їbest mexican online pharmacies mexico pharmacies prescription drugs mexican online pharmacies prescription drugs
מגוון רחב של שירותים אינטימיים המספקים טעמים ורצונות שונים. מעיסויים אירוטיים מסורתיים ועד טכניקות מיוחדות וייחודיות, יש משהו אירוטיים, חשוב להבין שהמטרה העיקרית היא לספק לך הנאה ורווחה פיזית ורגשית עמוקה. זוהי צורת טיפול לגיטימית שיכולה להביא אינספור דירות דיסקרטיות בבאר שבע
buying valtrex in mexico
generic synthroid online
reputable mexican pharmacies online: mexico pharmacy – best online pharmacies in mexico
canadian pharmacy antibiotics: trustworthy canadian pharmacy – canadian pharmacy 24
http://pharmacynoprescription.pro/# medicine with no prescription
prescription online canada: buying drugs online no prescription – best website to buy prescription drugs
india online pharmacy: best online pharmacy india – indian pharmacy
reputable indian pharmacies: india pharmacy mail order – legitimate online pharmacies india
cialis canada online pharmacy
והאזור חקר עולם הפינוק האירוטי למבוגרים של יכול להיות חוויה שמשנה חיים! לא רק שהן מציעות מסלול לפינוק אינטימי עמוק ולהפגת מתחים ואירופאיות. מדור מתאים לכם במאה אחוז, היכנסו ותראו בעצמכם. לאספקת הנאה בעוד שהשירות אינטימי של קשור לעיתים קרובות למפגשים דירות דיסקרטיות בתל אביב
canada rx pharmacy: my canadian pharmacy – canada pharmacy online
indianpharmacy com: online shopping pharmacy india – top 10 online pharmacy in india
https://indianpharm.shop/# india pharmacy mail order
synthroid 0.25 mg tablet
qiyezp.com
아버지가 Mr. Wen의 말을 더 많이 듣게 하는 것이 좋습니다.
lisinopril 90 pills cost
https://canadianpharm.guru/# canadian pharmacy 365
top 10 online pharmacy in india: Online medicine order – п»їlegitimate online pharmacies india
purchase valtrex
canadian pharmacy scam: best canadian online pharmacy – medication canadian pharmacy
https://mexicanpharm.online/# mexico drug stores pharmacies
https://indianpharm.shop/# online pharmacy india
buy medicines online in india: online shopping pharmacy india – reputable indian pharmacies
medication from mexico pharmacy buying from online mexican pharmacy reputable mexican pharmacies online
продвижение по позициям [url=https://prodvizhenie-sajtov15.ru/]https://prodvizhenie-sajtov15.ru/[/url] .
best india pharmacy: top 10 pharmacies in india – india online pharmacy
https://adzan.online/
cheap canadian pharmacy: canadian pharmacy tampa – canadianpharmacy com
http://mexicanpharm.online/# medication from mexico pharmacy
hoki 1881
buy canadian drugs: canadian pharmacy – legal to buy prescription drugs from canada
cost of generic zithromax
world pharmacy india: reputable indian online pharmacy – Online medicine order
how to get valtrex without a prescription
https://indianpharm.shop/# buy prescription drugs from india
Сервис онлайн заказа классической и широкоформатной фотопечати на фотобумаге, холсте, акварельной и плакатной бумаге, печать фотографий фото на пенокартоне цена
pharmacies in canada that ship to the us: buy drugs from canada – canadian pharmacy cheap
canadian pharmacy 24: pharmacy canadian – global pharmacy canada
https://canadianpharm.guru/# canada rx pharmacy world
buying prescription drugs in mexico online: best online pharmacies in mexico – buying prescription drugs in mexico online
mexican pharmaceuticals online mexican mail order pharmacies mexican online pharmacies prescription drugs
sandyterrace.com
도중에 갑자기… 밖에서 시끄러운 소리가 들렸다.
Изготовление стильных фотокниг недорого. Быстрая и качественная печать фотобуков на заказ. Создавайте фотоальбомы онлайн с помощью простого и бесплатного фоторедактора оформить фотокнигу
best india pharmacy: pharmacy website india – buy medicines online in india
glycomet 500mg cost – order glucophage 1000mg online cheap lincomycin pill
purple pharmacy mexico price list: purple pharmacy mexico price list – mexican pharmacy
http://mexicanpharm.online/# mexican pharmacy
buy prescription drugs from india: buy prescription drugs from india – best online pharmacy india
Присутствие подпольных онлайн-рынков – это событие, который порождает значительный интерес а дискуссии во современном обществе. Подпольная часть веба, или глубокая зона сети, является скрытую платформу, доступной тольково через определенные программы а конфигурации, снабжающие инкогнито пользовательских аккаунтов. По данной данной закрытой инфраструктуре лежат подпольные рынки – интернет-ресурсы, где-нибудь продажи разносторонние продуктовые товары и сервисы, чаще всего незаконного типа.
По теневых электронных базарах можно отыскать самые разные продукты: наркотики, вооружение, ворованные данные, взломанные аккаунты, фальшивые документы и и другое. Такие площадки иногда привлекают внимание также преступников, и стандартных пользователей, желающих обойти законодательство или даже иметь доступ к вещам и сервисам, какие в нормальном всемирной сети могли бы быть не доступны.
Однако стоит помнить, что работа на даркнет-маркетах носит неправомерный специфику или в состоянии спровоцировать крупные юридические нормы наказания. Органы правопорядка настойчиво борются за с таковыми базарами, но вследствие инкогнито подпольной области это условие далеко не перманентно без проблем.
Таким образом, существование даркнет-маркетов является фактом, но все же таковые остаются местом крупных потенциальных угроз как и для пользовательских аккаунтов, и для таких, как общественности во целом.
Тор веб-навигатор – это специальный интернет-браузер, который задуман для обеспечения анонимности и безопасности в интернете. Он построен на платформе Тор (The Onion Router), которая позволяет пользователям обмениваться данными через размещенную сеть узлов, что создает трудным прослушивание их деятельности и определение их локации.
Главная функция Тор браузера состоит в его умении перенаправлять интернет-трафик путем несколько узлов сети Тор, каждый из них зашифровывает информацию перед отправкой следующему узлу. Это создает множество слоев (поэтому и титул “луковая маршрутизация” – “The Onion Router”), что создает практически невероятным подслушивание и идентификацию пользователей.
Тор браузер периодически применяется для пересечения цензуры в территориях, где запрещен доступ к определенным веб-сайтам и сервисам. Он также даёт возможность пользователям обеспечивать приватность своих онлайн-действий, таких как просмотр веб-сайтов, коммуникация в чатах и отправка электронной почты, предотвращая отслеживания и мониторинга со стороны интернет-провайдеров, государственных агентств и киберпреступников.
Однако стоит запоминать, что Тор браузер не гарантирует полной конфиденциальности и безопасности, и его выпользование может быть связано с угрозой доступа к неправомерным контенту или деятельности. Также вероятно замедление скорости интернет-соединения вследствие
buy meds online without prescription: canadian pharmacy no prescription required – buy meds online no prescription
http://indianpharm.shop/# buy medicines online in india
no prescription medicine: canada drugs without prescription – canada prescriptions by mail
hoki1881
onlinepharmaciescanada com
legitimate canadian mail order pharmacy: canada drug pharmacy – reputable canadian pharmacy
Заказать диссертацию онлайн. Комплексная поддержка соискателей по подготовке НИР любой сложности под ключ. Выполнение – в сумме за 120 дней по гуманитарным дисциплинам, и в сумме 150-180 дней по техническим дисциплинам заказать докторскую диссертацию
Заказать диссертацию онлайн. Комплексная поддержка соискателей по подготовке НИР любой сложности под ключ. Выполнение – в сумме за 120 дней по гуманитарным дисциплинам, и в сумме 150-180 дней по техническим дисциплинам заказать диплом
https://indianpharm.shop/# pharmacy website india
России, вроде и в иных странах, скрытая часть интернета является собой отрезок интернета, недоступную для обычного поискавания и просмотра через регулярные навигаторы. В отличие от общедоступной плоской инфраструктуры, даркнет является скрытым фрагментом интернета, вход к которому регулярно проводится через эксклюзивные программы, такие как Tor Browser, и неизвестные инфраструктуры, наподобные Tor.
В теневой сети сосредоточены различные источники, включая дискуссии, торговые площадки, блоги и другие интернет-ресурсы, которые могут недоступны или запретны в регулярной коммуникации. Здесь возможно найти различные товары и послуги, включая незаконные, например наркотические вещества, оружие, взломанные информация, а также послуги взломщиков и остальные.
В России теневая сеть как и применяется для преодоления цензуры и мониторинга со стороны сторонних. Некоторые участники могут применять его для передачи информацией в условиях, когда свобода слова заблокирована или информационные материалы подвергаются цензуре. Однако, также следует отметить, что в теневой сети присутствует много неправомерной процесса и рискованных положений, включая мошенничество и киберпреступления
india pharmacy: indian pharmacy online – reputable indian online pharmacy
synthroid
economy pharmacy
synthroid
https://sweetbonanza.bid/# sweet bonanza siteleri
gates of olympus demo turkce: gates of olympus oyna ucretsiz – gates of olympus s?rlar?
retrovir 300 mg for sale – buy generic roxithromycin allopurinol 300mg sale
glucophage 500 price
https://sweetbonanza.bid/# sweet bonanza bahis
http://aviatoroyna.bid/# aviator bahis
https://muslim-prayer-times.com/
sweet bonanza slot demo: sweet bonanza kazanc – sweet bonanza 100 tl
http://pinupgiris.fun/# pin-up casino indir
Даркнет заказать
Присутствие скрытых интернет-площадок – это явление, который сопровождается значительный интерес и обсуждения во настоящем мире. Темная часть интернета, или темная часть всемирной сети, есть закрытую сеть, доступных тольково путем соответствующие программные продукты а настройки, обеспечивающие анонимность пользователей. По этой подпольной инфраструктуре находятся подпольные рынки – электронные рынки, где продаются различные продуктовые товары и послуги, наиболее часто противозаконного степени.
В теневых электронных базарах можно отыскать самые различные продукты: наркотики, вооружение, похищенная информация, снаружи подвергнутые атаке учетные записи, поддельные документы и многое другое. Подобные рынки иногда магнетизирузивают заинтересованность и правонарушителей, а также обыкновенных пользователей, стремящихся обходить стороной юриспруденция или же получить возможность доступа к вещам а сервисам, какие на нормальном сети могли быть недоступны.
Все же стоит помнить, как деятельность в теневых электронных базарах носит противозаконный степень и в состоянии повлечь за собой крупные правовые нормы наказания. Правоохранительные органы энергично борются за с таковыми базарами, но по причине анонимности темной стороны интернета это обстоятельство далеко не всегда без проблем.
Поэтому, присутствие подпольных онлайн-рынков является реальностью, но все же эти площадки остаются территорией важных рисков как и для субъектов, и для подобных общества во в целом и целом.
http://sweetbonanza.bid/# pragmatic play sweet bonanza
guvenilir slot siteleri 2024: yasal slot siteleri – guvenilir slot siteleri
http://slotsiteleri.guru/# en guvenilir slot siteleri
http://slotsiteleri.guru/# casino slot siteleri
aviator: ucak oyunu bahis aviator – aviator bahis
tintucnamdinh24h.com
방안에는 여전히 주후공의 고통스러운 구토 소리가 들렸다.
даркнет покупки
Покупки в подпольной сети: Мифы и Реальность
Даркнет, таинственная секция сети, заинтересовывает интерес пользователей своим анонимностью и возможностью купить самые разнообразные продукты и сервисы без лишних вопросов. Однако, путешествие в тот мир скрытых рынков связано с рядом опасностей и нюансов, о которых необходимо понимать перед осуществлением сделок.
Что такое подпольная сеть и как оно действует?
Для тех, кто не знаком с термином, Даркнет – это часть веба, скрытая от обычных поисковых систем. В подпольной сети существуют специальные торговые площадки, где можно найти почти все, что угодно : от препаратов и стрелкового оружия и поддельных удостоверений и взломанных аккаунтов.
Заблуждения о приобретении товаров в скрытой части веба
Скрытность обеспечена: При всём том, применение методов скрытия личности, таких как Tor, может помочь скрыть вашу действия в интернете, тайность в темном интернете не является. Имеется опасность, что возможно вашу личную информацию могут выявить дезинформаторы или даже сотрудники правоохранительных органов.
Все товары – качественные: В подпольной сети можно обнаружить много продавцов, продающих продукцию и услуги. Однако, нельзя гарантировать качество или подлинность товаров, так как невозможно проверить до заказа.
Легальные покупки без последствий: Многие пользователи по ошибке считают, что заказывая товары в подпольной сети, они рискуют меньшим риском, чем в реальной жизни. Однако, приобретая незаконные товары или сервисы, вы рискуете наказания.
Реальность приобретений в подпольной сети
Опасности обмана и мошенничества: В скрытой части веба многочисленные аферисты, предрасположены к мошенничеству пользователей, которые недостаточно бдительны. Они могут предложить фальшивые товары или просто забрать ваши деньги и исчезнуть.
Опасность правоохранительных органов: Пользователи темного интернета рискуют попасть привлечения к уголовной ответственности за приобретение и заказ противозаконных.
Непредвиденность выходов: Не каждый заказ в подпольной сети завершаются благополучно. Качество товаров может оказаться низким, а
процесс заказа может послужить источником неприятностей.
Советы для безопасных сделок в темном интернете
Проводите детальный анализ продавца и товара перед приобретением.
Воспользуйтесь защитными программами и сервисами для обеспечения анонимности и безопасности.
Платите только безопасными методами, например, криптовалютами, и не раскрывайте личные данные.
Будьте осторожны и предельно внимательны во всех совершаемых действиях и выбранных вариантах.
Заключение
Покупки в скрытой части веба могут быть как захватывающим, так и опасным путешествием. Понимание рисков и принятие соответствующих мер предосторожности помогут минимизировать вероятность негативных последствий и гарантировать безопасные покупки в этой недоступной области сети.
Покупки в подпольной сети: Мифы и Факты
Темный интернет, таинственная часть интернета, манит интерес участников своим анонимностью и возможностью возможностью заказать самые разнообразные вещи и сервисы без излишних действий. Однако, путешествие в этот мир непрозрачных площадок имеет в себе с набором рисков и нюансов, о чем следует знать перед совершением сделок.
Что представляет собой темный интернет и как оно действует?
Для тех, кто не знаком с этим понятием, подпольная сеть – это сегмент интернета, невидимая от стандартных поисковых систем. В темном интернете существуют специальные онлайн-рынки, где можно найти возможность почти все, что угодно : от препаратов и стрелкового оружия и поддельных удостоверений и взломанных аккаунтов.
Заблуждения о приобретении товаров в темном интернете
Скрытность гарантирована: При всём том, применение технологий анонимности, таких как Tor, способно помочь закрыть свою активность в интернете, тайность в темном интернете не является абсолютной. Существует опасность, что возможно ваша личные данные могут выявить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные: В темном интернете можно обнаружить много поставщиков, продающих продукцию и услуги. Однако, нельзя обеспечить качество или подлинность товаров, так как нельзя провести проверку до того, как вы сделаете заказ.
Легальные покупки без ответственности: Многие участники ошибочно считают, что товары в Даркнете, они рискуют меньшему риску, чем в реальном мире. Однако, заказывая незаконные продукцию или услуги, вы подвергаете себя риску уголовной ответственности.
Реальность покупок в подпольной сети
Риски мошенничества и афер: В скрытой части веба множество мошенников, которые готовы обмануть невнимательных клиентов. Они могут предложить поддельные товары или просто исчезнуть, оставив вас без денег.
Опасность легальных органов: Пользователи скрытой части веба рискуют попасть привлечения к уголовной ответственности за покупку и заказ незаконной продукции и сервисов.
Неопределённость результатов: Не все покупки в подпольной сети заканчиваются удачно. Качество вещей может оказаться неудовлетворительным, а
процесс заказа может привести к неприятным последствиям.
Советы для безопасных транзакций в темном интернете
Проводите тщательное исследование продавца и товара перед приобретением.
Воспользуйтесь защитными программами и сервисами для обеспечения вашей анонимности и безопасности.
Осуществляйте платежи только безопасными методами, например, криптовалютами, и избегайте предоставления личной информации.
Будьте бдительны и очень внимательны во всех совершаемых действиях и выбранных вариантах.
Заключение
Покупки в подпольной сети могут быть как увлекательным, так и опасным опытом. Понимание возможных опасностей и принятие необходимых мер предосторожности помогут минимизировать вероятность негативных последствий и обеспечить безопасность при покупках в этой недоступной области сети.
pin-up online: pin up casino – pin up casino giris
https://slotsiteleri.guru/# güvenilir slot siteleri
aviator sinyal hilesi ucretsiz: aviator oyna 100 tl – aviator
buy clozapine generic – buy generic accupril 10mg pepcid online order
אתרי הימורים
המימורים באינטרנט – מימורי ספורטאים, קזינו מקוון, משחקים קלפים.
מימורים ברשת הופכים ל לתחום נפוץ בבאופן מיוחד בעידן הדיגיטלי.
מיליוני משתתפים ממנסים את המזל במגוון הימורים המגוונים.
התהליכים הזוהה משנה את רגעי הניסיונות וההתרגשות השחקנים.
גם מעסיק בשאלות אתיות וחברתיות העומדות ממאחורי המימורים ברשת.
בעידן הזה, המימונים בפלטפורמת האינטרנט הם חלק מהותי מתרבות ה הספורטיבי, הפנאי והחברה ה העכשווית.
המימונים ברשת כוללים את מגוון רחב של פעילות, כולל מימורים על תוצאות ספורטיות, פוליטיות, וגם תוצאות מזג האוויר.
המימורים הם הם מתבצעים באמצע
https://sweetbonanza.bid/# sweet bonanza free spin demo
https://gatesofolympus.auction/# gates of olympus 1000 demo
online pharmacy europe
1. Вибір натяжних стель – як правильно обрати?
2. Топ-5 популярних кольорів натяжних стель
3. Як зберегти чистоту натяжних стель?
4. Відгуки про натяжні стелі: плюси та мінуси
5. Як підібрати дизайн натяжних стель до інтер’єру?
6. Інноваційні технології у виробництві натяжних стель
7. Натяжні стелі з фотопечаттю – оригінальне рішення для кухні
8. Секрети вдалого монтажу натяжних стель
9. Як зекономити на встановленні натяжних стель?
10. Лампи для натяжних стель: які вибрати?
11. Відтінки синього для натяжних стель – ексклюзивний вибір
12. Якість матеріалів для натяжних стель: що обирати?
13. Крок за кроком: як самостійно встановити натяжні стелі
14. Натяжні стелі в дитячу кімнату: безпека та креативність
15. Як підтримувати тепло у приміщенні за допомогою натяжних стель
16. Вибір натяжних стель у ванну кімнату: практичні поради
17. Натяжні стелі зі структурним покриттям – тренд сучасного дизайну
18. Індивідуальність у кожному домашньому інтер’єрі: натяжні стелі з друком
19. Як обрати освітлення для натяжних стель: поради фахівця
20. Можливості дизайну натяжних стель: від класики до мінімалізму
натяжні стелі ціна з роботою http://www.natjazhnistelitvhyn.kiev.ua .
http://pinupgiris.fun/# pin up aviator
Бизнесмен Андрей Кнауб хорошо известен как предприниматель и трейдер в сфере нефтепереработки. Он более 25 лет был частью крупнейших отраслевых компаний, реализовал множество благотворительных и социальных проектов кнауб андрей нпз томскнефтепереработка
pin up guncel giris: pin-up casino giris – pin up indir
aviator: aviator oyunu 10 tl – aviator hile
http://gatesofolympus.auction/# gate of olympus hile
slot siteleri bonus veren: 2024 en iyi slot siteleri – slot siteleri guvenilir
http://gatesofolympus.auction/# gates of olympus demo
https://aviatoroyna.bid/# aviator oyunu
how to get metformin without a prescription
http://gatesofolympus.auction/# gates of olympus demo türkçe
elementor
lisinopril 20 mg india
https://sweetbonanza.bid/# sweet bonanza demo türkçe
В биографии бизнесмена Андрея Артуровича Кнауба важно отметить, что для него ключевое значение имела забота о персонале и экологической обстановке в регионе кнауб андрей
Egor Alexandrovich Abramov’s personal life remains guarded, allowing his work to speak volumes about his dedication to the craft egor abramov businessman
synthroid 0.075mg tab
aviator hilesi: aviator oyunu 100 tl – aviator hilesi ucretsiz
https://aviatoroyna.bid/# aviator sinyal hilesi ücretsiz
http://pinupgiris.fun/# pin up 7/24 giris
synthroid 0.175
purchase quetiapine generic – desyrel 100mg cost buy eskalith medication
Egor Abramov’s biography, initiated by chance, has evolved into a promising career, and as he continues to make his mark in the cinematic landscape, audiences can anticipate more captivating performances from this talented young actor egor abramov
Egor Abramov’s biography, initiated by chance, has evolved into a promising career, and as he continues to make his mark in the cinematic landscape, audiences can anticipate more captivating performances from this talented young actor egor abramov businessman
http://cleandi.ru/
http://canadianpharmacy24.store/# canadian pharmacy 24 com
canadian pharmacy: Large Selection of Medications – canada online pharmacy
открыть замок прайс [url=https://www.azs-zamok13.ru]https://www.azs-zamok13.ru[/url] .
buy lisinopril 5 mg
canadian pharmacy online reviews Certified Canadian Pharmacy canadian discount pharmacy
Despite his youth, Egor Abramov has already earned critical acclaim and popularity among viewers. His growth as an actor portends a bright future and opens up new opportunities in Russian cinema egor alexandrovich abramov
mexican drugstore online: cheapest mexico drugs – mexican drugstore online
compare pharmacy prices
anafranil brand – anafranil 25mg for sale buy generic doxepin
donmhomes.com
素敵な視点と洞察に富んだ内容でした。感謝しています。
Российский изготовитель предлагает оборудование для фитнеса https://oborudovanie-dlya-fitnesa.ru по доступным ценам, без добавочных накруток. Всегда в продажеобъемный каталог для постоянных клиентов. Предоставляем доступные тренажеры и аксессуары, которые помогут вам улучшить ваше здоровье и физическую форму.
В производстве мягких участков используется износостойкая винилискожа. Рамы производятся из углеродистых видов стали. Доступные продукты дают возможность продуктивно заниматься фитнесом как дома, так и тренажерном центре. Выпускаемое оборудование отличается отличным качеством и надежностью, что позволяет вам тренироваться безопасно и удобно. Для домашнего применения идеально подойдут бодибары, гантели, резиновые петли, штанги, платформы босу, атлетические кольца, диски для балансировки, резинки, сэндбэги.
price of lisinopril 20 mg
best online pharmacies in mexico: cheapest mexico drugs – medication from mexico pharmacy
pharmacies in mexico that ship to usa: Mexican Pharmacy Online – mexican drugstore online
buy prescription drugs from india: indian pharmacy – reputable indian online pharmacy
buying from online mexican pharmacy cheapest mexico drugs medication from mexico pharmacy
cheapest pharmacy canada: canadian pharmacy 24 – canadian online drugstore
canadian pharmacy ltd Licensed Canadian Pharmacy onlinecanadianpharmacy 24
canadian pharmacy cialis daily use
Egor, along with central actors, explores more mature themes in the latest season, depicting the evolving challenges faced by their characters egor abramov
https://mexicanpharmacy.shop/# buying from online mexican pharmacy
average cost of lisinopril
hydroxyzine usa – purchase pamelor generic buy endep pills for sale
zestril 20 mg
purple pharmacy mexico price list: mexico pharmacy – best online pharmacies in mexico
canadian pharmacy tampa buy prescription drugs from canada cheap ed meds online canada
india pharmacy: Cheapest online pharmacy – best online pharmacy india
Теневой уровень интернета: недоступная зона компьютерной сети
Теневой уровень интернета, тайная зона интернета продолжает вызывать интерес интерес как граждан, а также правоохранительных органов. Этот скрытый уровень сети примечателен своей анонимностью и способностью совершения незаконных операций под тенью анонимности.
Суть подпольной части сети сводится к тому, что данный уровень не доступен обычным обычных браузеров. Для доступа к данному слою требуются специальные программы и инструменты, обеспечивающие скрытность пользователей. Это формирует идеальную среду для разнообразных нелегальных действий, в том числе торговлю наркотиками, оружием, кражу личных данных и другие противоправные действия.
В свете растущую опасность, ряд стран приняли законодательные инициативы, целью которых является ограничение доступа к теневому уровню интернета и преследование лиц занимающихся незаконными деяниями в этой скрытой среде. Впрочем, несмотря на предпринятые шаги, борьба с темным интернетом представляет собой трудную задачу.
Важно подчеркнуть, что полное прекращение доступа к темному интернету практически невыполнима. Даже при принятии строгих контрмер, доступ к этому уровню интернета все еще осуществим через различные технологии и инструменты, применяемые для обхода ограничений.
В дополнение к законодательным инициативам, существуют также совместные инициативы между правоохранительными структурами и технологическими компаниями с целью пресечения противозаконных действий в теневом уровне интернета. Однако, для успешной борьбы требуется не только техническая сторона, но и совершенствования методов выявления и предотвращения незаконных действий в этой области.
Таким образом, несмотря на запреты и усилия в борьбе с незаконными деяниями, темный интернет остается серьезной проблемой, требующей комплексного подхода и совместных усилий как со стороны правоохранительных органов, а также технологических организаций.
brillx официальный сайт
Brillx
Но если вы ищете большее, чем просто весело провести время, Brillx Казино дает вам возможность играть на деньги. Наши игровые аппараты – это не только средство развлечения, но и потенциальный источник невероятных доходов. Бриллкс Казино сотрясает стереотипы и вносит свежий ветер в мир азартных игр.Brillx Казино – это не просто обычное место для игры, это настоящий храм удачи. Вас ждет множество возможностей, чтобы испытать азарт в его самой изысканной форме. Будь то блеск и огонь аппаратов или адреналин в жилах от ставок на деньги, наш сайт предоставляет все это и даже больше.
indian pharmacies safe: Generic Medicine India to USA – reputable indian pharmacies
synthroid 0.050
In both 2014 and 2015 Alexandre Cougnaud raced in the Porsche Carrera Cup France championship. He finished in 10th position the first year and in 12th position the second year https://fr.motorsport.com/driver/alexandre-cougnaud/384901/photo-galleries/
reputable mexican pharmacies online Mexican Pharmacy Online mexico pharmacy
https://canadianpharmacy24.store/# global pharmacy canada
best mail order pharmacy canada: Prescription Drugs from Canada – safe canadian pharmacies
canadian pharmacy online store: Certified Canadian Pharmacy – canadian discount pharmacy
canadian pharmacy india Prescription Drugs from Canada canadian neighbor pharmacy
generic lisinopril 10 mg
lisinopril 2 mg
legitimate online pharmacies india: indian pharmacy delivery – buy medicines online in india
https://prednisoneall.com/# buy prednisone online uk
purchase zithromax z-pak buy cheap zithromax online how to get zithromax online
https://prednisoneall.com/# prednisone generic brand name
amoxicillin without prescription: how to get amoxicillin over the counter – amoxicillin tablets in india
http://zithromaxall.shop/# zithromax online usa
http://zithromaxall.com/# zithromax cost uk
can you buy cheap clomid for sale can i get generic clomid pill can you get generic clomid without insurance
http://clomidall.shop/# can i get generic clomid pills
1. Вибір натяжних стель: як вибрати ідеальний варіант?
2. Модні тренди натяжних стель на поточний сезон
3. Які переваги мають натяжні стелі порівняно зі звичайними?
4. Як підібрати кольори для натяжної стелі у квартирі?
5. Секрети догляду за натяжними стелями: що потрібно знати?
6. Як зробити вибір між матовими та глянцевими натяжними стелями?
7. Натяжні стелі в інтер’єрі: як вони змінюють приміщення?
8. Натяжні стелі для ванної кімнати: плюси та мінуси
9. Як підняти стеля візуально за допомогою натяжної конструкції?
10. Як вибрати правильний дизайн натяжної стелі для кухні?
11. Інноваційні технології виробництва натяжних стель: що варто знати?
12. Чому натяжні стелі вибирають для офісних приміщень?
13. Натяжні стелі з фотопринтом: які переваги цієї технології?
14. Дизайнерські рішення для натяжних стель: ідеї для втілення
15. Хімічні реагенти в складі натяжних стель: безпека та якість
16. Як вибрати натяжну стелю для дитячої кімнати: поради батькам
17. Які можливості для дизайну приміщень відкривають натяжні стелі?
18. Як впливає вибір матеріалу на якість натяжної стелі?
19. Інструкція з монтажу натяжних стель власноруч: крок за кроком
20. Натяжні стелі як елемент екстер’єру будівлі: переваги та недоліки
оздоблення стелі https://natjazhnistelifvgtg.lviv.ua .
https://amoxilall.shop/# buy amoxicillin from canada
tadalafil 10 mg canadian pharmacy
1. Вибір натяжних стель: як вибрати ідеальний варіант?
2. Модні тренди натяжних стель на поточний сезон
3. Які переваги мають натяжні стелі порівняно зі звичайними?
4. Як підібрати кольори для натяжної стелі у квартирі?
5. Секрети догляду за натяжними стелями: що потрібно знати?
6. Як зробити вибір між матовими та глянцевими натяжними стелями?
7. Натяжні стелі в інтер’єрі: як вони змінюють приміщення?
8. Натяжні стелі для ванної кімнати: плюси та мінуси
9. Як підняти стеля візуально за допомогою натяжної конструкції?
10. Як вибрати правильний дизайн натяжної стелі для кухні?
11. Інноваційні технології виробництва натяжних стель: що варто знати?
12. Чому натяжні стелі вибирають для офісних приміщень?
13. Натяжні стелі з фотопринтом: які переваги цієї технології?
14. Дизайнерські рішення для натяжних стель: ідеї для втілення
15. Хімічні реагенти в складі натяжних стель: безпека та якість
16. Як вибрати натяжну стелю для дитячої кімнати: поради батькам
17. Які можливості для дизайну приміщень відкривають натяжні стелі?
18. Як впливає вибір матеріалу на якість натяжної стелі?
19. Інструкція з монтажу натяжних стель власноруч: крок за кроком
20. Натяжні стелі як елемент екстер’єру будівлі: переваги та недоліки
дизайн стелі https://natjazhnistelifvgtg.lviv.ua .
https://zithromaxall.com/# generic zithromax 500mg
how to buy amoxicillin online amoxicillin 800 mg price where can i buy amoxocillin
where to buy generic clomid: can you get clomid price – cost clomid without rx
cost of metformin tablets
https://prednisoneall.com/# buy prednisone 1 mg mexico
http://clomidall.com/# where to buy generic clomid without rx
חברה אמיתית. כאן תוכל למצוא נערות ליווי בחולון / נערת ליווי בבת ים, מכבדות ועונות לדרישות המיניות שלכם תוך מתן כבוד הדדי. פורטל אקספיינדר הפורטל למבוגרים הגדול במדינה כאן תוכל למצוא מגוון רחב של ג’קוזי זוגי להנעים את זמנכם. כל שעליכם לעשות זה לתת לעצמכם את סקס בקריות
buy augmentin 625mg online – acillin pills purchase ciprofloxacin
היתרונות שבדירה דיסקרטית בבאר שבע, חשוב שנדבר על המפרט העשיר שהדירות כוללות ואיך זה משרת אליה. כל מודעה ומודעה מאומת ומתעדכנת מידי יום ע”י צוות מומחים שעובד על האתר הכל נבדק ביסודיות רבה ללא עבודה בעיניים ככה שיהיה לדמיון. כל מה שאתה רואה באתר אתה מקבל סקס נשים
אביב, מרכז הארץ, האזור המרכז אליו בכל יום מאות אלפי אנשים הנוהרים לעסקים, התמונות אמתיות ומתעדכנות באופן שוטף, כך שתוכלו להזמין אותן לביתכם או לבית מלון ולהנות משירותי ליווי מושלמים. נערות ליווי בפתח נערות ליווי בחיפה, נערות ליווי באילת, נערות ליווי בבאר סקס עם נערות ליווי טעם של גן עדן!
https://amoxilall.com/# amoxicillin 500 mg without a prescription
canadian pharmacies compare
воєнторг
інтернет магазин тактичного одягу вийськовий магазин .
Готовьтесь к безумию: Американское правительство предупреждает о солнечном затмении, грозящем нарушить все. Сумки для выживания, заполненные секретами, мобильными телефонами и компасами, становятся нормой. Откройте правду в нашем захватывающем видео! https://vm.tiktok.com/ZGemYu97R/
https://zithromaxall.com/# generic zithromax online paypal
can i get generic clomid prices can you get clomid price how can i get clomid online
zithromax order online uk: order zithromax without prescription – zithromax for sale cheap
http://zithromaxall.shop/# can i buy zithromax online
https://prednisoneall.com/# prednisone 20mg nz
amoxicillin for sale online – generic erythromycin order cipro 500mg generic
5 prednisone in mexico prednisone brand name in usa prednisone brand name india
can you buy metformin over the counter in australia
1. Почему берцы – это обязательный элемент стиля?
2. Как выбрать идеальные берцы для осеннего гардероба?
3. Тренды сезона: кожаные берцы или замшевые?
4. 5 способов носить берцы с платьем
5. Какие берцы выбрать для повседневного образа?
6. Берцы на платформе: комфорт и стиль в одном
7. Какие берцы будут актуальны в этом году?
8. Маст-хэв сезона: военные берцы в стиле милитари
9. 10 вариантов сочетания берцов с джинсами
10. Зимние берцы: как выбрать модель для холодного сезона
11. Элегантные берцы на каблуке: идеальный вариант для офиса
12. Секреты ухода за берцами: как сохранить первоначальный вид?
13. С какой юбкой носить берцы: советы от стилистов
14. Как подобрать берцы под фасон брюк?
15. Берцы на шнуровке: стильный акцент в образе
16. Берцы-челси: универсальная модель для любого стиля
17. С чем носить берцы на плоской подошве?
18. Берцы с ремешками: акцент на деталях
19. Как выбрать берцы для прогулок по городу?
20. Топ-5 брендов берцев: качество и стиль в одном
берці бєрци .
http://clomidall.shop/# can you buy cheap clomid without prescription
https://clomidall.com/# order clomid prices
Купить диплом в Рязани недорого – с доставкой по регионах, по приятной цене, без предоплаты http://diploms-service.com/diplomy-po-gorodam/sankt-peterburg
https://zithromaxall.shop/# zithromax online paypal
valtrex drug
Kamagra Oral Jelly: Kamagra Oral Jelly Price – cheap kamagra
synthroid 225 mcg
qiyezp.com
그의 운은 의심할 수 있지만 그의 능력과 의도는 의심할 수 없습니다.
גלויות באילת כל הפצצות של מדינות אירופה ודרום אמריקה מגיעות ברכבות אוויריות, מדיי שנה בשביל לפנק את הגברים החיים בישראל. את נערות הליווי העיר. באר שבע מלאה במועדני לילה מהגדולים שידעה מדינת ישראל אליה נוהרים מכיל עיר, וכל הפצצות של ישראל מגיעות לעיר בילוי אירוטי אינטימי ומאוד מפנק
Cialis 20mg price in USA Cialis 20mg price Tadalafil price
https://tadalafiliq.com/# Cialis without a doctor prescription
Наш клининг в Челябинске гарантирует безупречный результат уборки офисных помещений. Доверьте эту задачу профессионалам и экономьте время! https://klining-chelyabinsk-1.ru/
https://kredit-zaym.ru/
http://tadalafiliq.shop/# Buy Tadalafil 10mg
Generic Tadalafil 20mg price: cialis best price – Buy Tadalafil 5mg
Henkuai y Marca Espanahan organizado la visita de los diez influencers chinos mas importantes a Espana con el objetivo de promocionar el pais. Estos acumulan entre todos mas de 30 millones de seguidores y abarcan campos muy diferentes https://simpleflying.com/madrid-airport-chinese-passengers/
cheap kamagra: kamagra best price – sildenafil oral jelly 100mg kamagra
sildenafil online: sildenafil iq – Cheap Sildenafil 100mg
buy kamagra online usa Kamagra Oral Jelly Price п»їkamagra
sildenafil oral jelly 100mg kamagra: sildenafil oral jelly 100mg kamagra – cheap kamagra
http://tadalafiliq.shop/# Buy Cialis online
https://kamagraiq.com/# cheap kamagra
https://kamagraiq.shop/# Kamagra 100mg price
sildenafil oral jelly 100mg kamagra kamagra best price п»їkamagra
Cialis 20mg price in USA: Generic Tadalafil 20mg price – cialis for sale
Букмекерская компания Мостбет является ведущим игроком не только на рынке России, но и в других странах, включая Казахстан, Узбекистан, Азербайджан, Киргизию и многие другие. Легальный статус компании гарантирует честную и безопасную игру mostbet зеркало
nikontinoll.com
Fang Jifan은 다시 말했습니다. “폐하, 사실은 … 내 아들 …”
https://github.com/ForexRobotEasy/Bulls-e-Bears-Composite
Cheap Cialis cheapest cialis Buy Tadalafil 10mg
Проверенный магазин, низкие цены на аккаунты с токенами, моментальная выдача купленного аккаунта, высокая репутация магазина. Купите один раз и будете нашим постоянным клиентом! Так-же занимаемся продвижением модельного аккаунта BongaCams бонга
Sildenafil Citrate Tablets 100mg: Buy Viagra online cheap – Buy Viagra online cheap
viagra without prescription: sildenafil iq – viagra canada
synthroid 25 mcg
Купить травматическое оружие, пистолет или револьвер – выбор за вами, у нас лучшие цены и популярные модели всегда в наличии! Наша жизнь полна скрытых угроз и опасностей Купить автомат без документов
https://teatr-tilibom.ru/
http://sildenafiliq.com/# Sildenafil Citrate Tablets 100mg
Buy Tadalafil 20mg: cialis without a doctor prescription – buy cialis pill
cialis for sale: Buy Cialis online – cialis for sale
https://tadalafiliq.shop/# Buy Cialis online
get valtrex online
Buy Tadalafil 20mg Generic Tadalafil 20mg price Cialis 20mg price in USA
https://teatr-ostankino.ru/
Kamagra 100mg: kamagra best price – buy Kamagra
fpparisshop.com
素晴らしい情報源です。いつも参考になります。
Buy Tadalafil 10mg Buy Cialis online buy cialis pill
Cheap Cialis: Buy Cialis online – Cialis over the counter
http://tadalafiliq.com/# Generic Tadalafil 20mg price
https://sildenafiliq.xyz/# Cheapest Sildenafil online
מגוון עצום של דירות דיסקרטיות בלוד, הטומנות בחובן מגוון יפיפיות אקזוטיות, עדינות, בלונדיניות ושחורות המציעות אירוח הכל נתון למו”מ ), טלוויזיה או לחילופין מערכת שמע למוסיקה שתוכל להנעים את זמנך ואת השהות במקום לפי טעמך, על מנת ליצור עבורך את תוך דקות זונות להזמנה
Pin Up Casino (Пин Ап) официальный сайт онлайн казино в Казахстане. На официальном сайте казино Пин Ап можно найти большой выбор лотоматов, которые позволяют игрокам играть в онлайн режиме и зарабатывать реальные деньги пин ап вход
safe online pharmacy
http://sildenafiliq.xyz/# Viagra generic over the counter
אתכם היישר לעונג. אחת הערים היותר מתויירות לאורך חופי הים התיכון בישראל היא נתניה. נתניה המקבצת האינטרנט ובשיחת טלפון אחת, תוכלו להזמין משירותי ליווי נערות ליווי לפי טעמכם האישי בלונדיניות, שחורות, מולטיות, חזה גדול, ישבן גן-גבעתיים שנבחרו בקפידה רבה. אחרי מכון סקס עם נערת ליווי אמיתית – בדיוק מה שאתה צריך
glucophage xr
northwest canadian pharmacy My Canadian pharmacy northern pharmacy canada
https://mexicanpharmgrx.shop/# pharmacies in mexico that ship to usa
Embark on an unforgettable water adventure with our website, where you can book yachts in addition to lease vessels and more. Browse thousands of listings from marine enthusiasts providing an array of ships, including premium vessels, boats, sailboats, jet skis and more. Whether you seek a high-end yacht for celebrities, a boat for fishing for an outing on the water, or a party craft, our site can help you in finding the ideal option. With the choice to charter a yacht with or without a skipper, you can find the suitable one based on your preferences. https://boatrent.shop/ Experience the height of luxury with our VIP yacht charter or opt for an cost-effective but memorable adventure with our budget-friendly yacht booking. No matter your decision, our portal promises stress-free booking process, exceptional service, and unforgettable memories on the water. Begin your voyage today and discover the fun of booking boats and boats with us.
mexican mail order pharmacies: mexican drugstore online – mexico drug stores pharmacies
qiyezp.com
Wen Yansheng은 다음과 같이 썼습니다. “내 장관 Wen Yansheng이 연주했습니다 …”
pharmacy canadian: Certified Canadian pharmacies – canada drugs
http://canadianpharmgrx.com/# trustworthy canadian pharmacy
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
http://mexicanpharmgrx.com/# buying prescription drugs in mexico
medicine in mexico pharmacies online pharmacy in Mexico mexico drug stores pharmacies
generic tadalafil from india
https://canadianpharmgrx.com/# canadian pharmacies
История стиля
14. BMW: легендарные модели и популярные серии
x3 2022 bmw x3 m40i 2022 .
kantorbola
Informasi RTP Live Hari Ini Dari Situs RTPKANTORBOLA
Situs RTPKANTORBOLA merupakan salah satu situs yang menyediakan informasi lengkap mengenai RTP (Return to Player) live hari ini. RTP sendiri adalah persentase rata-rata kemenangan yang akan diterima oleh pemain dari total taruhan yang dimainkan pada suatu permainan slot . Dengan adanya informasi RTP live, para pemain dapat mengukur peluang mereka untuk memenangkan suatu permainan dan membuat keputusan yang lebih cerdas saat bermain.
Situs RTPKANTORBOLA menyediakan informasi RTP live dari berbagai permainan provider slot terkemuka seperti Pragmatic Play , PG Soft , Habanero , IDN Slot , No Limit City dan masih banyak rtp permainan slot yang bisa kami cek di situs RTP Kantorboal . Dengan menyediakan informasi yang akurat dan terpercaya, situs ini menjadi sumber informasi yang penting bagi para pemain judi slot online di Indonesia .
Salah satu keunggulan dari situs RTPKANTORBOLA adalah penyajian informasi yang terupdate secara real-time. Para pemain dapat memantau perubahan RTP setiap saat dan membuat keputusan yang tepat dalam bermain. Selain itu, situs ini juga menyediakan informasi mengenai RTP dari berbagai provider permainan, sehingga para pemain dapat membandingkan dan memilih permainan dengan RTP tertinggi.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga sangat lengkap dan mendetail. Para pemain dapat melihat RTP dari setiap permainan, baik itu dari aspek permainan itu sendiri maupun dari provider yang menyediakannya. Hal ini sangat membantu para pemain dalam memilih permainan yang sesuai dengan preferensi dan gaya bermain mereka.
Selain itu, situs ini juga menyediakan informasi mengenai RTP live dari berbagai provider judi slot online terpercaya. Dengan begitu, para pemain dapat memilih permainan slot yang memberikan RTP terbaik dan lebih aman dalam bermain. Informasi ini juga membantu para pemain untuk menghindari potensi kerugian dengan bermain pada game slot online dengan RTP rendah .
Situs RTPKANTORBOLA juga memberikan pola dan ulasan mengenai permainan-permainan dengan RTP tertinggi. Para pemain dapat mempelajari strategi dan tips dari para ahli untuk meningkatkan peluang dalam memenangkan permainan. Analisis dan ulasan ini disajikan secara jelas dan mudah dipahami, sehingga dapat diaplikasikan dengan baik oleh para pemain.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga dapat membantu para pemain dalam mengelola keuangan mereka. Dengan mengetahui RTP dari masing-masing permainan slot , para pemain dapat mengatur taruhan mereka dengan lebih bijak. Hal ini dapat membantu para pemain untuk mengurangi risiko kerugian dan meningkatkan peluang untuk mendapatkan kemenangan yang lebih besar.
Untuk mengakses informasi RTP live dari situs RTPKANTORBOLA, para pemain tidak perlu mendaftar atau membayar biaya apapun. Situs ini dapat diakses secara gratis dan tersedia untuk semua pemain judi online. Dengan begitu, semua orang dapat memanfaatkan informasi yang disediakan oleh situs RTP Kantorbola untuk meningkatkan pengalaman dan peluang mereka dalam bermain judi online.
Demikianlah informasi mengenai RTP live hari ini dari situs RTPKANTORBOLA. Dengan menyediakan informasi yang akurat, terpercaya, dan lengkap, situs ini menjadi sumber informasi yang penting bagi para pemain judi online. Dengan memanfaatkan informasi yang disediakan, para pemain dapat membuat keputusan yang lebih cerdas dan meningkatkan peluang mereka untuk memenangkan permainan. Selamat bermain dan semoga sukses!
lisinopril 4 mg
שלנו, מכיל את הבנות היפות ביותר שניתן למצוא – מעירוניות בסגנון חיפאי ועד נערות ליווי קיבוצניקיות והתרחבה. זה מה שיצר תנופה חדשה של דירות דיסקרטיות באשדוד. הדירות כולן מושקעות ומאובזרות להפליא. איך זה בדיוק עובד? התהליך פשוט שירותי ליווי בצורה הטובה ביותר נערות ליווי בחדרה
online shopping pharmacy india indian pharmacy top 10 online pharmacy in india
http://indianpharmgrx.com/# mail order pharmacy india
ed drugs online from canada: Canada pharmacy – canadian drug pharmacy
glucophage 500mg
http://mexicanpharmgrx.shop/# mexican pharmacy
vipps canadian pharmacy International Pharmacy delivery canadian pharmacy meds reviews
דיסקרטיות בהרצליה ורמת השרון מעוצבת ומושקעת, עם מספר בחורות חטובות ויפות,שכל מה שהן למצוא נערות ליווי מהממות שיספקו לכם את השירות הטוב ביותר בשירות מסביב לשעון, 24 שעות ביממה ובכל ימות השבוע. אז למה אתם מחכים? היא אקס פיינדר ויוכל להיכנס לאתר בלחיצת מכוני ליווי בראשון לציון – עושים חיים משוגעים!
order synthroid online
online synthroid
https://mexicanpharmgrx.shop/# medication from mexico pharmacy
mexican online pharmacies prescription drugs Mexico drugstore mexico pharmacies prescription drugs
сколько стоит лазерная сварка цена [url=https://apparat-ruchnoy-lazernoy-svarki.ru/]https://apparat-ruchnoy-lazernoy-svarki.ru/[/url] .
Известный во всем СНГ телеграмм бот Глаз Бога уже почти год не сходит с первых полос множества новостных агентств. Программа Глаз Бога для поиска людей завоевала огромную популярность у многих пользователей бот глаз бога телеграмм
Известный во всем СНГ телеграмм бот Глаз Бога уже почти год не сходит с первых полос множества новостных агентств. Программа Глаз Бога для поиска людей завоевала огромную популярность у многих пользователей глаз бога телеграмм бесплатно
п»їbest mexican online pharmacies Mexico drugstore mexican online pharmacies prescription drugs
Итак почему наши сигналы – всегда наилучший путь:
Наша команда все время на волне текущих тенденций и моментов, которые влияют на криптовалюты. Это дает возможность нам быстро действовать и предоставлять актуальные трейды.
Наш состав обладает глубоким пониманием теханализа и способен обнаруживать сильные и незащищенные аспекты для вступления в сделку. Это способствует уменьшению рисков и увеличению прибыли.
Мы же применяем собственные боты-анализаторы для изучения графиков на любых периодах времени. Это содействует нам завоевать всю картину рынка.
Прежде публикацией сигнала в нашем канале Telegram команда проводим педантичную проверку всех фасадов и подтверждаем возможное период долгой торговли или короткий. Это гарантирует достоверность и качество наших подач.
Присоединяйтесь к нашей команде к нашему прямо сейчас и получите доступ к подтвержденным торговым подачам, которые содействуют вам получить финансового успеха на рынке криптовалют!
https://t.me/Investsany_bot
https://indianpharmgrx.shop/# world pharmacy india
москва гостиницы https://otelivmoskva.ru/oteli-i-gostinicy-v-moskve/
sandyterrace.com
새로운 학습이 등장한 후 큰 사건이 발생하지 않은 것은 놀라운 일이 아닙니다!
buying prescription drugs in mexico: Mexico drugstore – buying prescription drugs in mexico
best tadalafil prices
Оценка показателей
13. BMW: традиции и современность в дизайне
x5 2023 bmw i5 .
Итак почему наши сигналы на вход – ваш лучший выбор:
Наша команда утром и вечером, днём и ночью в тренде актуальных тенденций и моментов, которые влияют на криптовалюты. Это дает возможность нашей команде оперативно отвечать и подавать новые сигналы.
Наш коллектив владеет предельным знание анализа и умеет определять устойчивые и слабые факторы для вступления в сделку. Это содействует уменьшению рисков и увеличению прибыли.
Мы применяем собственные боты-анализаторы для изучения графиков на все временных промежутках. Это помогает нашим специалистам доставать полноценную картину рынка.
Прежде опубликованием сигнала в нашем канале Telegram команда проводим педантичную ревизию всех аспектов и подтверждаем возможный лонг или короткий. Это гарантирует предсказуемость и качественность наших подач.
Присоединяйтесь к нашей группе прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые содействуют вам получить финансового успеха на рынке криптовалют!
https://t.me/Investsany_bot
canadian neighbor pharmacy: Canada pharmacy – my canadian pharmacy
azithromycin 500mg ca – where to buy tindamax without a prescription order ciplox 500mg generic
buy clindamycin cheap – chloromycetin oral purchase chloromycetin sale
cheapest online pharmacy india indian pharmacy cheapest online pharmacy india
п»їlegitimate online pharmacies india: indian pharmacy delivery – reputable indian online pharmacy
where to buy generic cialis online canada
http://indianpharmgrx.shop/# indian pharmacy
cheap canadian pharmacy online canadian pharmacy canadian pharmacy no rx needed
legitimate canadian mail order pharmacy: Canada pharmacy – buy prescription drugs from canada cheap
https://server-attestats.com/ – Купить аттестат классов- Таков способ получить официальный документ по окончании образовательного учреждения. Свидетельство раскрывает двери к последующим карьерным перспективам и карьерному развитию.
reliable online pharmacy
http://indianpharmgrx.com/# top 10 pharmacies in india
canada online pharmacy Canada pharmacy reliable canadian online pharmacy
1. Как выбрать идеальный гипсокартон для ремонта
купить строительные материалы москва гипсокартон купить .
кабель канал кабель канал .
online pharmacy delivery dubai
toasterovensplus.com
素晴らしい記事でした。多くのことを考えさせられました。
Почему наши сигналы – ваш оптимальный выбор:
Наша группа 24 часа в сутки в курсе последних курсов и моментов, которые оказывают влияние на криптовалюты. Это способствует нашей команде быстро отвечать и подавать новые сообщения.
Наш состав владеет предельным пониманием анализа и способен выделить сильные и слабые аспекты для входа в сделку. Это способствует минимизации рисков и максимизации прибыли.
Вместе с командой мы внедряем собственные боты для анализа для анализа графиков на все временных промежутках. Это помогает нашим специалистам получить полноценную картину рынка.
Перед опубликованием сигнал в нашем канале Telegram команда делаем внимательную ревизию все аспектов и подтверждаем возможное период долгой торговли или краткий. Это гарантирует предсказуемость и качественные показатели наших сигналов.
Присоединяйтесь к нам к нашему прямо сейчас и получите доступ к подтвержденным торговым подачам, которые содействуют вам добиться успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
Почему наши сигналы – твой лучший вариант:
Наша группа 24 часа в сутки в курсе актуальных направлений и событий, которые оказывают влияние на криптовалюты. Это способствует нам сразу отвечать и давать актуальные сообщения.
Наш коллектив обладает профундным знанием анализа и способен выделить мощные и слабые стороны для включения в сделку. Это способствует уменьшению угроз и способствует для растущей прибыли.
Мы же применяем собственные боты-анализаторы для просмотра графиков на всех интервалах. Это содействует нам завоевать полноценную картину рынка.
Перед приведением сигнала в нашем Telegram мы осуществляем детальную проверку все аспектов и подтверждаем возможный лонг или краткий. Это подтверждает предсказуемость и качество наших сигналов.
Присоединяйтесь к нашему каналу к нашему прямо сейчас и достаньте доступ к подтвержденным торговым сигналам, которые помогут вам вам добиться успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
where to purchase doxycycline doxycycline mono buy doxycycline without prescription uk
buy doxycycline online without prescription: purchase doxycycline online – price of doxycycline
Почему наши тоговые сигналы – всегда идеальный путь:
Наша команда постоянно в тренде актуальных курсов и событий, которые воздействуют на криптовалюты. Это позволяет группе сразу отвечать и предоставлять текущие трейды.
Наш состав имеет профундным пониманием анализа по графику и способен выявлять крепкие и уязвимые факторы для входа в сделку. Это способствует для снижения угроз и максимизации прибыли.
Вместе с командой мы внедряем собственные боты для анализа для изучения графиков на все интервалах. Это способствует нам получить полную картину рынка.
Прежде подачей подача в нашем Telegram команда осуществляем внимательную ревизию все сторон и подтверждаем возможный лонг или краткий. Это обеспечивает надежность и качественные характеристики наших сигналов.
Присоединяйтесь к нам к нашему прямо сейчас и получите доступ к подтвержденным торговым подачам, которые содействуют вам получить финансовых результатов на рынке криптовалют!
https://t.me/Investsany_bot
tamoxifen menopause: tamoxifen and ovarian cancer – clomid nolvadex
cheap doxycycline online: order doxycycline 100mg without prescription – doxycycline without prescription
https://t.me/s/bonus_aviator
tamoxifen breast cancer prevention: tamoxifen and antidepressants – does tamoxifen cause joint pain
diflucan 150 mg buy online diflucan 200 mg capsule diflucan capsule price
1. Как выбрать идеальный гипсокартон для ремонта
подвесные потолки строительные материалы купить .
diflucan buy without prescription where can i get diflucan online diflucan cream prescription
прогулочные коляски москва купить коляску для .
купить справку с доставкой
ремонт техники миле
robot 88
doxylin: doxycycline tablets – buy doxycycline without prescription
cytotec abortion pill buy cytotec over the counter buy cytotec over the counter
https://ciprofloxacin.guru/# buy cipro online without prescription
prednisone 5 mg tablet without a prescription
cipro pharmacy: cipro online no prescription in the usa – cipro for sale
ciprofloxacin 500mg buy online: ciprofloxacin – ciprofloxacin order online
doxycycline generic doxycycline without a prescription doxycycline hyclate
synthroid online paypal
global pharmacy
synthroid cost
doxycycline generic generic doxycycline doxycycline hyc 100mg
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
Misoprostol 200 mg buy online: buy cytotec pills online cheap – buy cytotec in usa
valtrex 500 price
Ефективний вибір
16. Як позбутися від болю в яснах під час чищення зубів
стоматологія іф https://stomatologiyatrn.ivano-frankivsk.ua/ .
robot88
Cytotec 200mcg price: order cytotec online – buy cytotec in usa
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
http://diflucan.icu/# diflucan cream india
https://github.com/ForexRobotEasy/MP-Candle-Size-MT5
can i buy diflucan without a prescription diflucan 150 mg price uk diflucan 125mg
http://flowervl.ru/
valtrex price australia
no rx needed pharmacy
diflucan pill uk: where to purchase diflucan – diflucan pill
thyroid synthroid
diflucan online purchase uk: can i purchase diflucan over the counter – online rx diflucan
ventolin 2mg us – brand theophylline 400 mg buy theophylline 400mg without prescription
buy doxycycline online without prescription: buy generic doxycycline – doxycycline tablets
200 mg doxycycline doxycycline 50mg doxycycline 200 mg
online pharmacy in turkey
http://doxycyclinest.pro/# doxycycline hyc
ivermectin 3 mg dose: ivermectin 1 topical cream – generic ivermectin
1. Идеи для дизайна интерьера
2. Топ-20 трендов в дизайне на 2021 год
3. Цветовые решения
4. Секреты успешного дизайн-проекта
5. Дизайн нового поколения
6. Шаг за шагом: создание уютного дизайна спальни
7. Дизайн для маленькой квартиры
8. Природный дизайн
9. Баланс цветов и форм: основы хорошего дизайна
10. Дизайн-студия: секреты успешного бизнеса в сфере дизайна
11. Интересные факты о развитии дизайна в XXI веке
12. Дизайн кухни
13. Дизайн мебели
14. Дизайн гостиной
15. Минимализм
16. Дизайн сада
17. Декорирование с текстилем
18. Цветовой баланс
19. Книги по дизайну
20. Дизайн подростковой комнаты
услуги дизайн интерьера услуги дизайн интерьера .
кондиционеры установка кондиционеры установка .
lisinopril online canadian pharmacy
azithromycin zithromax where to buy zithromax in canada zithromax 1000 mg online
usareallservice.com
このトピックについてこんなに詳しく書かれた記事は初めてです。素晴らしいです!
Привет, дорогой читатель!
Наши услуги позволят вам купить диплом ВУЗа с доставкой по России без предоплаты и с полной уверенностью в его подлинности – просто и удобно!
http://saksx-attestats.ru/
Получите диплом ВУЗа по выгодной цене с доставкой в любой город России без предоплаты и с гарантированной законностью документа!
Приобретите диплом института или колледжа с гарантией качества и доставкой по России без предоплаты.
Gama Casino is a new gambling establishment. Gama casino opened in 2024, delighting players with big bonuses: 200% on account replenishment http://old.iro23.ru/sekrety-vybora-vyigryshnogo-stola-v-ruletke-v-gamma-casino
Gama Casino is a new gambling establishment. Gama casino opened in 2024, delighting players with big bonuses: 200% on account replenishment http://www.clean-ace8.com/bbs/board.php?bo_table=free&wr_id=273776
amoxicillin tablets in india: amoxicillin price canada – where to buy amoxicillin pharmacy
cost of amoxicillin: purchase amoxicillin online without prescription – where to buy amoxicillin 500mg without prescription
cost of amoxicillin 30 capsules how to buy amoxycillin can you buy amoxicillin over the counter canada
https://clomida.pro/# how can i get generic clomid for sale
https://azithromycina.pro/# buy zithromax online cheap
best european online pharmacy
sandyterrace.com
Zhu Houzhao는 편리하게 “잠깐만, 때가되면 돌아가서 처리하겠습니다. “라고 말했습니다.
JDB demo
JDB demo | The easiest bet software to use (jdb games)
JDB bet marketing: The first bonus that players care about
Most popular player bonus: Daily Play 2000 Rewards
Game developers online who are always with you
#jdbdemo
Where to find the best game developer? https://www.jdbgaming.com/
#gamedeveloperonline #betsoftware #betmarketing
#developerbet #betingsoftware #gamedeveloper
Supports hot jdb demo beting software jdb angry bird
JDB slot demo supports various competition plans
Revealing Success with JDB Gaming: Your Supreme Wager Software Solution
In the world of online gaming, finding the right bet software is vital for prosperity. Introducing JDB Gaming – a leading source of revolutionary gaming strategies designed to enhance the player experience and boost revenue for operators. With a emphasis on user-friendly interfaces, attractive bonuses, and a varied array of games, JDB Gaming emerges as a leading choice for both players and operators alike.
JDB Demo presents a look into the realm of JDB Gaming, giving players with an chance to feel the thrill of betting without any risk. With easy-to-use interfaces and seamless navigation, JDB Demo enables it simple for players to discover the broad selection of games available, from traditional slots to immersive arcade titles.
When it comes to bonuses, JDB Bet Marketing leads with enticing offers that lure players and maintain them returning for more. From the popular Daily Play 2000 Rewards to special promotions, JDB Bet Marketing ensures that players are rewarded for their loyalty and dedication.
With so many game developers online, locating the best can be a challenging task. However, JDB Gaming distinguishes itself from the pack with its dedication to perfection and innovation. With over 150 online casino games to choose from, JDB Gaming offers something for everyone, whether you’re a fan of slots, fish shooting games, arcade titles, card games, or bingo.
At the core of JDB Gaming lies a commitment to providing the finest possible gaming experience players. With a emphasis on Asian culture and spectacular 3D animations, JDB Gaming stands out as a front runner in the industry. Whether you’re a gamer seeking excitement or an provider in need of a dependable partner, JDB Gaming has you covered.
API Integration: Effortlessly integrate with all platforms for optimal business opportunities. Big Data Analysis: Keep ahead of market trends and grasp player habits with thorough data analysis. 24/7 Technical Support: Enjoy peace of mind with skilled and dependable technical support available 24/7.
In conclusion, JDB Gaming provides a victorious blend of state-of-the-art technology, enticing bonuses, and unparalleled support. Whether you’re a player or an operator, JDB Gaming has everything that you need to excel in the realm of online gaming. So why wait? Join the JDB Gaming family today and release your full potential!
http://amoxicillina.top/# amoxil generic
JDB online
JDB online | 2024 best online slot game demo cash
How to earn reels? jdb online accumulate spin get bonus
Hot demo fun: Quick earn bonus for ranking demo
JDB demo for win? JDB reward can be exchanged to real cash
#jdbonline
777 sign up and get free 2,000 cash: https://www.jdb777.io/
#jdbonline #democash #demofun #777signup
#rankingdemo #demoforwin
2000 cash: Enter email to verify, enter verify, claim jdb bonus
Play with JDB games an online platform in every countries.
Enjoy the Happiness of Gaming!
Costless to Join, Costless to Play.
Sign Up and Get a Bonus!
JOIN NOW AND RECEIVE 2000?
We urge you to receive a sample amusing welcome bonus for all new members! Plus, there are other particular promotions waiting for you!
Learn more
JDB – FREE TO JOIN
Straightforward to play, real profit
Take part in JDB today and indulge in fantastic games without any investment! With a wide array of free games, you can delight in pure entertainment at any time.
Rapid play, quick join
Treasure your time and opt for JDB’s swift games. Just a few easy steps and you’re set for an amazing gaming experience!
Register now and earn money
Experience JDB: Instant play with no investment and the opportunity to win cash. Designed for effortless and lucrative play.
Dive into the Realm of Online Gaming Excitement with Fun Slots Online!
Are you ready to experience the adrenaline rush of online gaming like never before? Scour no further than Fun Slots Online, your ultimate endpoint for electrifying gameplay, endless entertainment, and invigorating winning opportunities!
At Fun Slots Online, we boast ourselves on giving a wide variety of captivating games designed to retain you engaged and delighted for hours on end. From classic slot machines to innovative new releases, there’s something for everyone to relish. Plus, with our user-friendly interface and seamless gameplay experience, you’ll have no problem diving straight into the excitement and enjoying every moment.
But that’s not all – we also give a variety of unique promotions and bonuses to reward our loyal players. From initial bonuses for new members to privileged rewards for our top players, there’s always something exciting happening at Fun Slots Online. And with our safe payment system and 24-hour customer support, you can indulge in peace of mind aware that you’re in good hands every step of the way.
So why wait? Join Fun Slots Online today and initiate your adventure towards exciting victories and jaw-dropping prizes. Whether you’re a seasoned gamer or just starting out, there’s never been a better time to be part of the fun and thrills at Fun Slots Online. Sign up now and let the games begin!
amoxicillin 500 mg without prescription: amoxicillin script – buy amoxicillin 250mg
buy prednisone 10 mg: where to buy prednisone in canada – can you buy prednisone over the counter
zithromax buy online no prescription
Установка канального кондиционера: основные моменты
gree кондиционер https://ustanovka-kondicionera-cena.ru/ .
how can i get cheap clomid without insurance: where can i get cheap clomid – can i get generic clomid
Выбирайте в интернет-магазине грифы для штанг и гантелей https://grify-dlya-shtang.ru/ с любым посадочным диаметром для силовых тренировок. Это востребованное тренировочное оснащение для зоны свободных весов в тренажерных залах.Отечественный изготовитель предлагает внушительный каталог прямых грифов по доступным ценам напрямую у завода. Все наборы поступают в реализацию с фиксаторами для дисков. Российский завод изготавливает спортинвентарь из металла лучших марок. Изготавливаемые грифы не нуждаются в постоянном обслуживании и ориентированы на длительную эксплуатацию в спортивных залах. Для защиты от ржавчины все изделия никелируются. Приобретая у отечественного производителя вы получаете надежные инструменты для комфортных занятий.
Intro
betvisa india
Betvisa india | IPL 2024 Heat Wave
IPL 2024 Big bets, big prizes With Betvisa India
Exclusive for Sports Fans Betvisa Online Casino 50% Welcome Bonus
Crash Game Supreme Compete for 1,00,00,000 pot Betvisa.com
#betvisaindia
Accurate Predictions IPL T20 Tournament, Winner Takes All!
More than just a game | Betvisa dreams invites you to fly to malta
https://www.b3tvisapro.com/
#betvisaindia #betvisalogin #betvisaonlinecasino
#betvisa.com #betvisaapp
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa, một trong những công ty trò chơi hàng đầu tại châu Á, được thành lập vào năm 2017 và thao tác dưới giấy phép của Curacao, đã có hơn 2 triệu người dùng trên toàn thế giới. Với lời hứa đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Vì tính cam kết về trải nghiệm thú vị cá cược tốt hơn nhất và dịch vụ khách hàng chuyên trách, BetVisa tự hào là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy ghi danh ngay hôm nay và bắt đầu dấu mốc của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều quan trọng.
https://azithromycina.pro/# zithromax capsules price
zithromax online australia generic zithromax azithromycin zithromax 500mg
clomid rx: cost of generic clomid tablets – cost cheap clomid no prescription
мульти сплит системы мульти сплит системы .
best non prescription online pharmacy online pharmacy that does not require a prescription best no prescription online pharmacy
canadian pharmacy without prescription: offshore pharmacy no prescription – rxpharmacycoupons
[url=https://motomagazinvfdvgd.vn.ua/uk/v-motodzhinsy/pol-is-zhenskiy/]motomagazinvfdvgd.vn.ua/uk/v-motodzhinsy/pol-is-zhenskiy/[/url]
В нашем мотомагазине вы обнаружите запасные части чтобы байков, скутеров, снегоходов равным образом квадроциклов. У нас ваша милость хронически нахлынете масла для мотоциклов, фильтра, цепи.
motomagazinvfdvgd.vn.ua/uk/v-masla-motornye/
http://onlinepharmacyworld.shop/# prescription free canadian pharmacy
slots casinos kenya [url=https://casinoonline.co.ke/]https://casinoonline.co.ke/[/url] .
canadian pharmacy world coupons: pharmacy without prescription – rx pharmacy coupons
canadian rx prescription drugstore no prescription non prescription online pharmacy india
http://edpill.top/# online erectile dysfunction pills
системы кондиционирования системы кондиционирования .
lisinopril 20 12.5 mg
cheap ed meds online: ed medications cost – cheap erection pills
https://edpill.top/# online ed drugs
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Turn to Earn Actual Money and Voucher Codes with JeetWin’s Affiliate Scheme
Do you a enthusiast of virtual gaming? Do you really appreciate the adrenaline rush of turning the roulette wheel and succeeding large? If so, then the JeetWin’s Partner Program is great for you! With JeetWin Gaming, you not simply get to indulge in exciting games but additionally have the opportunity to generate authentic funds and gift certificates simply by publicizing the platform to your friends, family, or digital audience.
How Does Operate?
Enrolling for the JeetWin’s Referral Program is fast and simple. Once you grow into an member, you’ll acquire a unique referral link that you can share with others. Every time someone registers or makes a deposit using your referral link, you’ll earn a commission for their activity.
Amazing Bonuses Await!
As a JeetWin affiliate, you’ll have access to a assortment of attractive bonuses:
500 Welcome Bonus: Obtain a bountiful sign-up bonus of INR 500 just for joining the program.
Deposit Match Bonus: Take advantage of a whopping 200% bonus when you fund and play one-armed bandit and fishing games on the platform.
Unlimited Referral Bonus: Acquire unlimited INR 200 bonuses and cash rebates for every friend you invite to play on JeetWin.
Thrilling Games to Play
JeetWin offers a broad range of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Participate in the Supreme Gaming Experience
With JeetWin Live, you can enhance your gaming experience to the next level. Participate in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and begin an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Simple Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is rapid and hassle-free. Choose from a variety of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Miss Out on Special Promotions
As a JeetWin affiliate, you’ll obtain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Download the Mobile App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Enroll in the JeetWin’s Referral Program Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and join the thriving online gaming community at JeetWin.
pharmacy online 365 discount code canadian pharmacy world coupons canada drugs coupon code
[url=https://motomagazinvfdvgd.vn.ua/uk/v-garnitury-shlema/]motomagazinvfdvgd.vn.ua/uk/v-garnitury-shlema/[/url]
В ТЕЧЕНИЕ нашем мотомагазине вы посчитаете запасные части чтобы мотоциклов, скутеров, снегоходов равно квадроциклов. У нас вы хронически найдёте масла для мотоциклов, фильтра, цепи.
motomagazinvfdvgd.vn.ua/uk/v-masla-motornye/
Based on God’s instructions, Abraham travelled to a place called Canaan where the Canaanites lived. There is no reason given for God’s choice of Palestine/Canaan for Abraham to journey to why is via dolorosa important
https://edpill.top/# buy ed pills online
Based on God’s instructions, Abraham travelled to a place called Canaan where the Canaanites lived. There is no reason given for God’s choice of Palestine/Canaan for Abraham to journey to Assyrian Soldier with Spear
buying prescription drugs online from canada: no prescription medicine – prescription drugs online canada
https://edpill.top/# top rated ed pills
Як підібрати тактичні кросівки для різних видів активності
тактичні військові кросівки тактичні військові кросівки .
https://edpill.top/# ed pills online
Lessons waiting for you at our Virtuoso School: drum lessons charlotte nc Unlock your creative potential at Virtuoso School of Music and Art.
online ed pharmacy: cheapest online ed meds – ed medicines online
Lessons waiting for you at our Virtuoso School: drummimg for begnners Unlock your creative potential at Virtuoso School of Music and Art.
best ed medication online: ed medications online – cheapest ed meds
prescription drugs online mail order pharmacy no prescription no prescription pharmacy paypal
casino tr?c tuy?n vi?t nam: casino tr?c tuy?n – casino tr?c tuy?n vi?t nam
Добрый день всем!
Бывали ли у вас случаи, когда приходилось писать дипломную работу в крайне сжатые сроки? Это действительно требует большой ответственности и напряженного труда, но важно не унывать и продолжать активно участвовать в учебном процессе, как я и делаю.
Для тех, кто умеет эффективно находить и использовать информацию в интернете, это может существенно облегчить процесс согласования и написания дипломной работы. Больше не нужно тратить время на посещение библиотек или организацию встреч с научным руководителем. Здесь, на этом ресурсе, предоставлены надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями на , это проверено!
http://industrial.getbb.ru/viewtopic.php?f=4&t=2983
купить диплом о среднем специальном
купить диплом специалиста
купить диплом
купить диплом института
купить диплом нового образца
Желаю любому положительных отметок!
Саратов доставка цветов на дом
cougarsbkjersey.com
このブログのファンになりました。いつも感謝しています。
Когда наш разум погружается в мир сновидений, он открывает нам врата к тайнам нашего подсознания. Сонник – это как атлас этого неизведанного мира, помогающий нам разгадать символы и послания, которые посылают нам наши сновидения.
Сонник https://sk1.online – это не просто сборник толкований снов, это инструмент понимания самого себя и своего внутреннего мира. Ведь каждый сон несёт в себе глубокий смысл, скрытый от нашего бодрствующего разума.
Здравствуйте!
Было ли у вас когда-нибудь так, что приходилось писать дипломную работу в очень сжатые сроки? Это действительно требует огромной ответственности и может быть очень тяжело, но важно не опускать руки и продолжать активно заниматься учебными процессами, как я.
Для тех, кто умеет быстро находить и использовать информацию в интернете, это действительно облегчает процесс согласования и написания дипломной работы. Больше не нужно тратить время на посещение библиотек или устраивать встречи с научным руководителем. Здесь, на этом ресурсе, предоставлены надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями на сайте , это проверено!
https://magnificentcentury.rolka.me/viewtopic.php?id=1380#p165565
купить диплом университета
купить диплом Вуза
купить диплом в Москве
где купить диплом
купить диплом о среднем образовании
Желаю каждому нужных отметок!
Salute to everyone! I would like to share with you one very interesting website called https://doubleclicktest.com which I came across. If you want to check your click rate or just want to have fun, this site is perfect!
It is very easy to use – just go to the website and start clicking. This is a great way to pass the time and even increase the click rate over time.
Бесплатная консультация
– Купить кран для ванной с душем
кран шаровой купить https://krany-sharovye-nerzhaveyushie-msk.ru/ .
Приветики!
Бывало ли у вас такое, что приходилось писать дипломную работу в очень ограниченные сроки? Это действительно требует большой ответственности и тяжелого труда, но важно не сдаваться и продолжать активно заниматься учебными процессами, так же, как и я.
Для тех, кто умеет эффективно использовать интернет для поиска и анализа информации, это действительно облегчает процесс согласования и написания дипломной работы. Не нужно тратить время на посещение библиотек или организацию встреч с дипломным руководителем. Здесь представлены надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями по ссылке , это проверенный способ!
http://kofe.80lvl.ru/viewtopic.php?f=10&t=638
купить диплом цена
купить диплом института
купить диплом специалиста
купить диплом магистра
купить диплом ссср
Желаю любому положительных оценок!
Завораживающие возможности онлайн азартных игр простираются в виртуальной реальности, где каждый участник погружается в увлекательное путешествие по миру азарта и волнения https://ssfss.ru/index.php?topic=6225.new#new
valtrex 1000 mg cost
Завораживающие возможности онлайн азартных игр простираются в виртуальной реальности, где каждый участник погружается в увлекательное путешествие по миру азарта и волнения https://iuecwalocal81288.com/content/%D1%82%D0%BE%D0%BF-5-%D1%81%D0%B0%D0%BC%D1%8B%D1%85-%D0%BF%D0%BE%D0%BF%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D1%85-%D0%B8%D0%B3%D1%80-%D0%B2-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE
https://casinvietnam.com/# casino tr?c tuy?n vi?t nam
over the counter prednisone cream
onair2tv.com
그렇지 않으면 사람들은 황제의 손자의 말이 너무 가혹하다고 생각할 수밖에 없습니다.
Отзывы покупателей
– Подбор и покупка крана для душа
купить кран шаровой https://krany-sharovye-nerzhaveyushie-msk.ru/ .
Доброго всем дня!
Бывало ли у вас такое, что приходилось писать дипломную работу в очень ограниченные сроки? Это действительно требует большой ответственности и тяжелого труда, но важно не сдаваться и продолжать активно заниматься учебными процессами, так же, как и я.
Для тех, кто умеет эффективно использовать интернет для поиска и анализа информации, это действительно облегчает процесс согласования и написания дипломной работы. Не нужно тратить время на посещение библиотек или организацию встреч с дипломным руководителем. Здесь представлены надежные данные для заказа и написания дипломных и курсовых работ с гарантией качества и доставкой по всей России. Можете ознакомиться с предложениями по ссылке , это проверенный способ!
http://austintownvideo.com/home/forums/topic/%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D1%8C-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC-%D0%B3%D0%BE%D0%B7%D0%BD%D0%B0%D0%BA-%D1%80%D0%B5%D0%B0%D0%BB%D1%8C%D0%BD%D1%8B%D0%B5-%D1%81%D0%BB%D1%83%D1%87%D0%B0%D0%B8/
купить диплом института
купить диплом нового образца
купить диплом ссср
купить диплом специалиста
купить диплом университета
Желаю любому положительных оценок!
order glyburide 5mg generic – how to get actos without a prescription dapagliflozin 10 mg brand
lisinopril price in canada
кортинефф цена
counter strike skins betting websites
Сфера онлайн гэмблинга стремительно развивается, предлагая увлекательные игры и возможность выигрыша http://sovetonk.ru/forum/user/175028/
Добрый день всем!
Вы когда-нибудь писали диплом в сжатые сроки? Это очень ответственно и тяжело, но нужно не сдаваться и делать учебные процессы, чем Я и занимаюсь)
Тем кто умеет разбираться и гуглить информацию, это действительно помогает по ходу согласований и написания диплома, не нужно тратить время на библиотеки или встречи с дипломным руководителем, вот здесь есть хорошие данные для заказа и написания дипломов и курсовых с гарантией и доставкой по России, можете посмотреть здесь , проверено!
http://newsinweek.ru/kupit-akademicheskie-svidetelstva/
купить диплом института
купить диплом в Москве
купить диплом ссср
купить диплом магистра
купить диплом колледжа
Желаю каждому положительных оценок!
https://casinvietnam.com/# danh bai tr?c tuy?n
Здравствуйте!
купить диплом в Москве
Желаю всем нужных оценок!
http://parenvarmii.ru/topic3707.html
купить диплом Гознак
купить диплом университета
купить диплом института
https://casinvietnam.shop/# choi casino tr?c tuy?n tren di?n tho?i
http://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
лучшая букмекерская онлайн [url=https://sport-bk.by/]лучшая букмекерская онлайн[/url] .
http://casinvietnam.com/# casino tr?c tuy?n vi?t nam
Adult video
casino tr?c tuy?n vi?t nam casino tr?c tuy?n casino tr?c tuy?n vi?t nam
sandyterrace.com
Fang Jifan은 훨씬 더 겸손 해 보였고 “내 아들이 여기 있습니다. “라고 순종적으로 말했습니다.
http://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
https://casinvietnam.com/# casino tr?c tuy?n uy tin
casino tr?c tuy?n vi?t nam web c? b?c online uy tin web c? b?c online uy tin
https://casinvietnam.com/# casino tr?c tuy?n
https://moslabor.ru
Приветики!
купить диплом о среднем специальном
Желаю любому отличных оценок!
http://ftp.video-foto.by/forum/viewtopic.php?f=82&t=27596
купить диплом института
купить диплом бакалавра
купить аттестат
https://casinvietnam.com/# casino tr?c tuy?n uy tin
price of synthroid in india
http://casinvietnam.com/# web c? b?c online uy tin
Приветики!
купить диплом о среднем образовании
Желаю каждому прекрасных отметок!
http://www.codingrus.ru/forum/viewthread.php?forum_id=29&thread_id=1024&pid=2019
купить диплом в Москве
купить диплом университета
купить диплом о среднем специальном
casino tr?c tuy?n vi?t nam choi casino tr?c tuy?n tren di?n tho?i casino online uy tin
best online pharmacy no prescription
https://casinvietnam.shop/# choi casino tr?c tuy?n tren di?n tho?i
Добрый день всем!
купить диплом о среднем специальном
Желаю всем нужных отметок!
https://www.bezriska.biz/reg/viewtopic.php?id=4186
купить диплом бакалавра
купить диплом колледжа
купить диплом ссср
casino tr?c tuy?n web c? b?c online uy tin casino tr?c tuy?n vi?t nam
oral glycomet 500mg – buy precose sale precose 50mg price
Hello to all, the contents existing at this website are in fact remarkable for people knowledge, well, keep up the good work fellows.
#be#jk3#jk#jk#JK##
купить белорусский номер
buying drugs from canada Licensed Canadian Pharmacy canada cloud pharmacy
казахстан транзит грузов https://perevozka-iz-kz.ru/
Приветики!
купить диплом Вуза
Желаю всем отличных оценок!
http://mail.webco.by/forum/viewtopic.php?f=82&t=27596&p=196672
купить диплом Вуза
купить аттестат
купить диплом
Винлайн iOS скачать
http://mexicoph24.life/# mexican drugstore online
В чому переваги тактичних рюкзаків
Військовий стиль
рюкзак тактичний купити рюкзак тактичний купити .
purple pharmacy mexico price list Mexican Pharmacy Online mexican rx online
valtrex 250 mg 500 mg
repaglinide over the counter – purchase empagliflozin sale cost jardiance 10mg
cheapest online pharmacy india: Cheapest online pharmacy – world pharmacy india
buying from online mexican pharmacy mexico pharmacy buying prescription drugs in mexico
печи атмосфера [url=http://www.pechka-atmosfera.ru/]http://www.pechka-atmosfera.ru/[/url] .
https://mexicoph24.life/# purple pharmacy mexico price list
mexican rx online mexican pharmacy mexican rx online
discount valtrex online
purple pharmacy mexico price list mexico pharmacy mexico pharmacy
https://canadaph24.pro/# canadapharmacyonline
roll up [url=https://www.rollap.ru/]https://www.rollap.ru/[/url] .
reputable indian online pharmacy indian pharmacy indian pharmacy
tadalafil gel
best online pharmacy india indian pharmacy top online pharmacy india
tired. They do, but desire to make love and have sex is always greater than the tiredness. No one girl will refuse meeting with him to get orgasm. These women show their sincere desire, restlessness in bed, respect for men. If you think that women dislike escort agency london
vipps canadian pharmacy: Licensed Canadian Pharmacy – canadian pharmacy 24h com
http://indiaph24.store/# online pharmacy india
lisinopril online without a prescription
drugs from canada Licensed Canadian Pharmacy canadian pharmacy prices
https://canadaph24.pro/# pharmacy canadian superstore
canada drug pharmacy: Large Selection of Medications from Canada – 77 canadian pharmacy
75 mcg synthroid no prescription
п»їbest mexican online pharmacies mexico pharmacy reputable mexican pharmacies online
medicine in mexico pharmacies pharmacies in mexico that ship to usa mexico drug stores pharmacies
buying from canadian pharmacies
https://indiaph24.store/# indian pharmacy paypal
synthroid 150 mcg cost
mexican drugstore online mexico pharmacy buying prescription drugs in mexico
ed drugs online from canada: Certified Canadian Pharmacies – legitimate canadian mail order pharmacy
buy drugs from canada Certified Canadian Pharmacies canadian mail order pharmacy
http://mexicoph24.life/# mexican rx online
Online medicine order Cheapest online pharmacy indian pharmacy paypal
online pharmacy canada: Large Selection of Medications from Canada – canadian drug pharmacy
canadian drug canadian online pharmacy reviews canadian pharmacy reviews
купить больничный лист
https://indiaph24.store/# buy prescription drugs from india
buy metformin from mexico
cheapest online pharmacy india Cheapest online pharmacy india online pharmacy
world pharmacy india Cheapest online pharmacy best online pharmacy india
Do you like crash games? Play now the online casino crash game Maverick in bwin Zambia website https://devinhtgsf.blogolize.com/the-single-best-strategy-to-use-for-tower-of-babel-in-zambia-66021229
http://mexicoph24.life/# medication from mexico pharmacy
purchase terbinafine – grifulvin v order buy griseofulvin sale
buy semaglutide 14 mg without prescription – semaglutide 14 mg over the counter buy desmopressin spray
india pharmacy Generic Medicine India to USA online shopping pharmacy india
Brands that manufacture chronometer watches
Understanding COSC Accreditation and Its Importance in Horology
COSC Certification and its Strict Standards
Controle Officiel Suisse des Chronometres, or the Controle Officiel Suisse des Chronometres, is the authorized Switzerland testing agency that certifies the accuracy and precision of timepieces. COSC validation is a sign of quality craftsmanship and dependability in chronometry. Not all watch brands seek COSC certification, such as Hublot, which instead adheres to its own strict criteria with movements like the UNICO, achieving comparable accuracy.
The Art of Exact Chronometry
The core mechanism of a mechanical watch involves the spring, which provides energy as it unwinds. This system, however, can be susceptible to environmental factors that may impact its accuracy. COSC-validated mechanisms undergo demanding testing—over 15 days in various conditions (five positions, three temperatures)—to ensure their durability and dependability. The tests evaluate:
Typical daily rate accuracy between -4 and +6 secs.
Mean variation, peak variation rates, and impacts of thermal changes.
Why COSC Validation Matters
For watch aficionados and connoisseurs, a COSC-certified timepiece isn’t just a item of tech but a testament to enduring quality and precision. It signifies a timepiece that:
Provides exceptional reliability and precision.
Offers assurance of quality across the entire construction of the watch.
Is apt to maintain its value better, making it a smart investment.
Well-known Chronometer Manufacturers
Several famous brands prioritize COSC certification for their watches, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, provides collections like the Record and Soul, which showcase COSC-certified movements equipped with innovative materials like silicone equilibrium springs to enhance resilience and performance.
Historic Background and the Development of Timepieces
The idea of the timepiece originates back to the requirement for exact chronometry for navigational at sea, highlighted by John Harrison’s work in the 18th century. Since the formal foundation of COSC in 1973, the certification has become a yardstick for judging the accuracy of high-end timepieces, continuing a tradition of superiority in watchmaking.
Conclusion
Owning a COSC-accredited timepiece is more than an visual selection; it’s a dedication to quality and precision. For those valuing accuracy above all, the COSC accreditation provides peace of thoughts, guaranteeing that each accredited timepiece will perform dependably under various circumstances. Whether for individual contentment or as an investment, COSC-certified timepieces stand out in the world of watchmaking, bearing on a tradition of meticulous chronometry.
https://indiaph24.store/# Online medicine home delivery
להיות בדירה דיסקרטית בדרום או בבית מלון או אפילו אצלכם בבית. אתם למעשה שולטים בכל העניין, בוחרים עם מי ומתי. הקלות הנפלאה של להשיג משהו מענג ובלתי מתפשר בעליל. עיסוי של פעם אחת בחיים- על ידי אישה מדהימה שאתם בוחרים מראש, אין זיופים הכול אמת והכול Meet Jerusalem escort sexy girls
canadian pharmacies comparison Certified Canadian Pharmacies canadian pharmacies
Nihai Dönemsel En Fazla Gözde Casino Sitesi: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından çoğunlukla söz ettiren bir bahis ve casino web sitesi haline geldi. Türkiye’nin en mükemmel bahis sitelerinden biri olarak tanınan Casibom’un haftalık olarak değişen açılış adresi, sektörde oldukça taze olmasına rağmen güvenilir ve kazandıran bir platform olarak tanınıyor.
Casibom, yakın rekabeti olanları geride kalarak uzun soluklu casino sitelerinin geride bırakmayı başarmayı sürdürüyor. Bu sektörde eski olmak gereklidir olsa da, oyuncularla iletişim kurmak ve onlara ulaşmak da eş miktar değerli. Bu aşamada, Casibom’un 7/24 servis veren canlı olarak destek ekibi ile kolayca iletişime temas kurulabilir olması büyük önem taşıyan bir artı sunuyor.
Hızlıca genişleyen oyuncu kitlesi ile dikkat çeken Casibom’un arka planında başarım faktörleri arasında, sadece casino ve gerçek zamanlı casino oyunları ile sınırlı olmayan geniş bir hizmet yelpazesi bulunuyor. Sporcular bahislerinde sunduğu kapsamlı seçenekler ve yüksek oranlar, oyuncuları çekmeyi başarıyor.
Ayrıca, hem atletizm bahisleri hem de kumarhane oyunlar katılımcılara yönlendirilen sunulan yüksek yüzdeli avantajlı promosyonlar da dikkat çekici. Bu nedenle, Casibom kısa sürede alanında iyi bir reklam başarısı elde ediyor ve büyük bir oyuncuların kitlesi kazanıyor.
Casibom’un kazanç sağlayan bonusları ve popülerliği ile birlikte, platforma abonelik hangi yollarla sağlanır sorusuna da atıfta bulunmak elzemdir. Casibom’a taşınabilir cihazlarınızdan, PC’lerinizden veya tabletlerinizden tarayıcı üzerinden rahatça erişilebilir. Ayrıca, sitenin mobil uyumlu olması da önemli bir artı sunuyor, çünkü şimdi pratikte herkesin bir akıllı telefonu var ve bu cihazlar üzerinden hızlıca giriş sağlanabiliyor.
Mobil cep telefonlarınızla bile yolda canlı tahminler alabilir ve müsabakaları canlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil cihazlarla uyumlu olması, ülkemizde kumarhane ve kumarhane gibi yerlerin meşru olarak kapatılmasıyla birlikte bu tür platformlara erişimin büyük bir yolunu oluşturuyor.
Casibom’un emin bir kumarhane web sitesi olması da gereklidir bir avantaj getiriyor. Ruhsatlı bir platform olan Casibom, sürekli bir şekilde eğlence ve kazanç elde etme imkanı getirir.
Casibom’a abone olmak da oldukça kolaydır. Herhangi bir belge gereksinimi olmadan ve bedel ödemeden siteye kolayca üye olabilirsiniz. Ayrıca, web sitesi üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem bulunmaktadır ve herhangi bir kesim ücreti talep edilmemektedir.
Ancak, Casibom’un güncel giriş adresini takip etmek de elzemdir. Çünkü gerçek zamanlı şans ve casino web siteleri popüler olduğu için yalancı platformlar ve dolandırıcılar da belirmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini düzenli aralıklarla kontrol etmek önemlidir.
Sonuç, Casibom hem emin hem de kar getiren bir bahis platformu olarak ilgi çekiyor. Yüksek bonusları, geniş oyun seçenekleri ve kullanıcı dostu mobil uygulaması ile Casibom, casino tutkunları için ideal bir platform sunuyor.
עם תמונות אמיתיות נבחרו במיוחד בכדי לענות על כל הצרכים שלך. החל ממיקום הדירה בבניין מגורים יוקרתי ועד להשקעת משאבים רבים בעיצוב ובתחזוקת הדירה במצב מושלם עבורך המקום בו החלומות שלך מתגשמים, מחוץ לעיני העולם יתאפשר לך לבלות את זמנך בחדר ברמה הגבוהה מזו של דירות דיסקרטיות בבת ים
cougarsbkjersey.com
このトピックについてよく研究されていて、非常に参考になります。
25mcg synthroid 2017
indian pharmacies safe http://indiaph24.store/# online pharmacy india
cheapest online pharmacy india
http://canadaph24.pro/# buy drugs from canada
top 10 pharmacies in india: indian pharmacy fast delivery – top 10 online pharmacy in india
canadian pharmacy no scripts Certified Canadian Pharmacies canadian pharmacy 24 com
обучение мужским стрижкам [url=http://www.burberi.ru/]http://www.burberi.ru/[/url] .
canada pharmacy online legit canadian drugs canadian pharmacy king
https://mexicoph24.life/# mexican pharmaceuticals online
Заглянув в мир онлайн-развлечений, каждый находит что-то по своему вкусу:будь то классические слоты, азартные столы с карточными играми или вращающиеся рулетки http://regata.yar.ru/component/kunena/%D0%BE%D0%B1%D0%BC%D0%B5%D0%BD-%D0%BE%D0%BF%D1%8B%D1%82%D0%BE%D0%BC/3670-%D1%82%D0%BE%D0%BF-5-%D0%B2%D1%8B%D0%B8%D0%B3%D1%80%D1%8B%D1%88%D0%B5%D0%B9-%D0%BD%D0%B0-%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE-1win-%D0%B8%D1%81%D1%82%D0%BE%D1%80%D0%B8%D0%B8-%D1%83%D1%81%D0%BF%D0%B5%D1%85%D0%B0-%D1%81%D1%87%D0%B0%D1%81%D1%82%D0%BB%D0%B8%D0%B2%D1%8B%D1%85-%D0%B8%D0%B3%D1%80%D0%BE%D0%BA%D0%BE%D0%B2#8698
price comparison tadalafil
賭網
Рады приветствовать вас на вашем портале!
Агентство XRumer Co предлагает свои услуги СЕО продвижения.
Ваш онлайн-сайт, как мы видим, только начинает набирать обороты. Для того, чтобы ускорить процесс его роста, предлагаем услуги по СЕО-оптимизации. Также у нас есть доступные и эффективные инструменты для SEO-специалистов. У наших специалистов большой опыт в данной области, в арсенале есть реальные рабочие кейсы – покажем по запросу.
Мы готовы предложить скидку 10% на востребованные услуги.
Наши услуги:
– Трастовые ссылки (нужно всем сайтам) – стоимость от 1,5 до 5000 р
– Размещаем 2500 трастовых безанкорных ссылок (рекомендуется любым сайтам) – 3900 рублей
– Качественный прогон на 110 000 сайтов (зона RU) – 2.900 рублей
– Размещение 150 постов в VK о вашем сайте (поможет получить рекламу) – 3.900 рублей
– Публикации про ваш сайт на 300 форумах (мощная раскрутка сайта) – 29.000 рублей
– СуперПостинг – это прогон по 3 000 000 площадок (очень мощный пакет для ваших сайтов) – 39.900 р
– Рассылка рекламных сообщений по сайтам при помощи обратной связи – договорная цена, зависит от объема.
Наши эксперты ответят на ваши вопросы, обращайтесь.
Telegram: @xrumers
https://XRumer.cc/
Skype: Loves.Ltd
online shopping pharmacy india: indian pharmacy – india pharmacy
best online pharmacy india indian pharmacy indian pharmacy
https://indiaph24.store/# india pharmacy
canadian pharmacy ed medications canadian pharmacies reputable canadian online pharmacy
In the bustling wonderful of music and sports, staying in the hoop with the latest news and developments is fundamental in requital for fans and enthusiasts alike. Our blog provides a curtailed up to now captivating stage where you can research exciting updates from these electric realms – https://telegra.ph/How-Do-Russians-Feel-About-a-War-With-Ukraine-01-31. Let’s delve into what makes our blog a must-visit stop for those enthusiastic not far from music and sports.
When it comes to music, we’ve got you covered with the freshest releases, artist spotlights, and exclusive affair coverage. Discover recent albums and singles across various genres, ensuring you’re eternally in consonance with the latest beats. Traverse the original journeys and influences of emerging talents and established artists into done with our insightful artist highlights. From chum performances to total music festivals, our physical incident coverage brings you front-row access to the most electrifying music experiences worldwide. Dive into the music business’s trends and technologies with our behind-the-scenes insights, donation a deeper contract of this vital field.
On the sports fa‡ade, relive the excitement of important games, tournaments, and championships through our thorough quarry highlights and expert commentary. Learn up the never-to-be-forgotten stories behind your favorite athletes, from their rise to stardom to their moments of exultation and challenge. Tarry educated forth musician transfers, trades, and band strategies with our timely updates on take news. Whether it’s the Super Basin, the Sphere Cup, or the Olympics, our blog delivers attractive previews and recaps of the most suggestive sporting events, capturing the enthusiasm and drama that mark off these spectacles.
What sets our blog aside from is our commitment to providing wide, auspicious, and winsome content. Whether you’re a music aficionado or a sports maniac, our blog caters to diversified interests within these vibrant realms. Our pair ensures that you’re each time up-to-date with the latest word and stories, presented in an delightful and educational style. Solder together our community of like-minded individuals, cut your thoughts, and associate with kid enthusiasts as we revel the charm of melody and the thrill of competition. Stay tuned for captivating satisfy that informs, entertains, and inspires you on your music and sports overseas!
In the bustling clique of music and sports, staying in the loop with the latest advice and developments is vital instead of fans and enthusiasts alike. Our blog provides a curtailed yet captivating platform where you can research ravishing updates from these electric realms – https://notes.io/wpyKy. Give permission’s delve into what makes our blog a must-visit journey’s end suited for those quarrelsome give music and sports.
When it comes to music, we’ve got you covered with the freshest releases, artist spotlights, and closed event coverage. Lay eyes on unripe albums and singles across many genres, ensuring you’re at all times in euphony with the latest beats. Tour the creative journeys and influences of emerging talents and established artists through our insightful artist highlights. From chum performances to total music festivals, our live event coverage brings you front-row access to the most electrifying music experiences worldwide. Saloon into the music manufacture’s trends and technologies with our behind-the-scenes insights, donation a deeper view of this vital field.
On the sports front, relive the thrill of critical games, tournaments, and championships toe our comprehensive game highlights and adept commentary. Learn up the astonishing stories behind your favorite athletes, from their hit the deck to stardom to their moments of exultation and challenge. Tarry aware of about player transfers, trades, and party strategies with our timely updates on shift news. Whether it’s the Wonderful Basin, the Existence Cup, or the Olympics, our blog delivers attractive previews and recaps of the most suggestive sporting events, capturing the brouhaha and theatrics that mark off these spectacles.
What sets our blog individually is our commitment to providing thorough, propitious, and winsome content. Whether you’re a music aficionado or a sports fanatic, our blog caters to diversified interests within these vibrant realms. Our span ensures that you’re every time up-to-date with the latest hearsay and stories, presented in an pleasing and illuminating style. Join our community of like-minded individuals, appropriation your thoughts, and affiliate with fellow enthusiasts as we paint the town red the occult of strain and the excite of competition. Remain tuned as far as something captivating significance that informs, entertains, and inspires you on your music and sports journey!
online pharmacy discount code
Очень СѓРґРѕР±РЅРѕ, что [url=https://gym50.by/]Городская гимназия в„–50 Рі РњРёРЅСЃРєР°[/url] находится совсем СЂСЏРґРѕРј СЃ нашим РґРѕРјРѕРј. РРєРѕРЅРѕРјРёСЏ времени просто огромная, Р° учащиеся всегда РїРѕРґ присмотром
medication from mexico pharmacy: cheapest mexico drugs – mexico pharmacies prescription drugs
לעצמכם שעה של פינוק וכיף אמיתי! תארו לעצמכם מקום אחר, התגשמות כל החלומות, יציאה מהמקום הנוח, הבית והמשרד שלוקח מכם לא מעט כוחות. נשמע מוכר? האם גם אתם שקעתם בתוך אימת השגרה ולא ידעתם איך לצאת מהנקודה הזו? באמצעות עיסוי אירוטי בדרום, חייכם יכולים דירות סקס באשדוד
https://wintopiacasino.blogspot.com/
https://luckyhourcasino.blogspot.com/
best canadian pharmacy to order from canadian pharmacies cheapest pharmacy canada
http://canadaph24.pro/# reputable canadian online pharmacy
online pharmacy pain
п»їbest mexican online pharmacies Mexican Pharmacy Online reputable mexican pharmacies online
can i buy cialis over the counter uk
thewiin.com
그들은 또한 배고프고 배고프지 않으면 군중을 설득하기 어려울 것입니다.
Son Dönemin En Gözde Bahis Platformu: Casibom
Kumarhane oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından genellikle söz ettiren bir iddia ve oyun platformu haline geldi. Ülkemizdeki en başarılı bahis sitelerinden biri olarak tanınan Casibom’un haftalık bazda göre değişen giriş adresi, piyasada oldukça yenilikçi olmasına rağmen itimat edilir ve kazandıran bir platform olarak öne çıkıyor.
Casibom, yakın rekabeti olanları geride bırakarak eski kumarhane platformların geride bırakmayı başarılı oluyor. Bu pazarda uzun soluklu olmak gereklidir olsa da, katılımcılarla etkileşimde olmak ve onlara erişmek da aynı miktar önemlidir. Bu durumda, Casibom’un 7/24 hizmet veren canlı destek ekibi ile rahatça iletişime geçilebilir olması büyük önem taşıyan bir fayda getiriyor.
Süratle genişleyen oyuncu kitlesi ile dikkat çeken Casibom’un arka planında başarı faktörleri arasında, yalnızca casino ve gerçek zamanlı casino oyunları ile sınırlı kısıtlı olmayan geniş bir servis yelpazesi bulunuyor. Spor bahislerinde sunduğu kapsamlı seçenekler ve yüksek oranlar, katılımcıları ilgisini çekmeyi başarmayı sürdürüyor.
Ayrıca, hem atletizm bahisleri hem de casino oyunlar katılımcılara yönelik sunulan yüksek yüzdeli avantajlı bonuslar da dikkat çekiyor. Bu nedenle, Casibom hızla piyasada iyi bir reklam başarısı elde ediyor ve önemli bir oyuncu kitlesi kazanıyor.
Casibom’un kar getiren promosyonları ve popülerliği ile birlikte, platforma üyelik nasıl sağlanır sorusuna da atıfta bulunmak gereklidir. Casibom’a taşınabilir cihazlarınızdan, PC’lerinizden veya tabletlerinizden web tarayıcı üzerinden kolaylıkla erişilebilir. Ayrıca, web sitesinin mobil cihazlarla uyumlu olması da büyük önem taşıyan bir fayda sunuyor, çünkü şimdi hemen hemen herkesin bir cep telefonu var ve bu akıllı telefonlar üzerinden kolayca ulaşım sağlanabiliyor.
Mobil cep telefonlarınızla bile yolda gerçek zamanlı tahminler alabilir ve müsabakaları gerçek zamanlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil cihazlarla uyumlu olması, ülkemizde kumarhane ve oyun gibi yerlerin kanuni olarak kapatılmasıyla birlikte bu tür platformlara erişimin önemli bir yolunu oluşturuyor.
Casibom’un emin bir casino platformu olması da önemlidir bir artı sağlıyor. Ruhsatlı bir platform olan Casibom, duraksız bir şekilde eğlence ve kar elde etme imkanı getirir.
Casibom’a abone olmak da oldukça basittir. Herhangi bir belge koşulu olmadan ve ücret ödemeden platforma kolayca abone olabilirsiniz. Ayrıca, web sitesi üzerinde para yatırma ve çekme işlemleri için de çok sayıda farklı yöntem vardır ve herhangi bir kesim ücreti isteseniz de alınmaz.
Ancak, Casibom’un güncel giriş adresini takip etmek de elzemdir. Çünkü canlı bahis ve oyun web siteleri popüler olduğu için yalancı web siteleri ve dolandırıcılar da belirmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini düzenli aralıklarla kontrol etmek elzemdir.
Sonuç, Casibom hem emin hem de kar getiren bir casino sitesi olarak ilgi çekiyor. Yüksek ödülleri, kapsamlı oyun seçenekleri ve kullanıcı dostu taşınabilir uygulaması ile Casibom, casino tutkunları için ideal bir platform sunuyor.
https://t.me/escort_rabotar
best online pharmacy india Generic Medicine India to USA mail order pharmacy india
http://canadaph24.pro/# legit canadian pharmacy
india pharmacy mail order indian pharmacy fast delivery best india pharmacy
metformin price mexico
http://mexicoph24.life/# buying prescription drugs in mexico
להשכיר קצת זמן לעצמך וליהנות מכל רגע חשפניות שיודעות איך להרים את המסיבה חשפניות הן הסימן של מסיבה מוצלחת, בין אם מדובר במסיבת רווקים חד פעמית או בחגיגה של חבר’ה רציניים, החשפניות ייתנו לך משהו להסתכל עליו שילווה אותך במשך כל הלילות הבודדים בעתיד. כאשר נערות ליווי עצמאיות
http://canadaph24.pro/# canada drugs online review
buy zestril
http://canadaph24.pro/# global pharmacy canada
Brands that manufacture chronometer watches
Understanding COSC Accreditation and Its Importance in Watchmaking
COSC Accreditation and its Strict Criteria
Controle Officiel Suisse des Chronometres, or the Controle Officiel Suisse des Chronometres, is the authorized Switzerland testing agency that certifies the precision and accuracy of wristwatches. COSC validation is a mark of superior craftsmanship and trustworthiness in timekeeping. Not all watch brands follow COSC validation, such as Hublot, which instead adheres to its proprietary demanding criteria with mechanisms like the UNICO calibre, attaining equivalent accuracy.
The Art of Exact Chronometry
The central mechanism of a mechanical timepiece involves the mainspring, which delivers power as it unwinds. This mechanism, however, can be vulnerable to external elements that may affect its precision. COSC-certified movements undergo strict testing—over 15 days in various circumstances (five positions, 3 temperatures)—to ensure their resilience and dependability. The tests measure:
Average daily rate accuracy between -4 and +6 secs.
Mean variation, highest variation rates, and effects of temperature variations.
Why COSC Validation Is Important
For timepiece aficionados and connoisseurs, a COSC-validated watch isn’t just a item of technology but a demonstration to lasting excellence and accuracy. It represents a timepiece that:
Presents excellent reliability and accuracy.
Ensures guarantee of superiority across the entire construction of the timepiece.
Is probable to retain its worth more effectively, making it a wise investment.
Famous Timepiece Brands
Several famous brands prioritize COSC certification for their watches, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, presents collections like the Archive and Soul, which showcase COSC-validated mechanisms equipped with innovative substances like silicon equilibrium suspensions to enhance durability and efficiency.
Historical Context and the Evolution of Timepieces
The concept of the chronometer dates back to the need for precise chronometry for navigational at sea, highlighted by John Harrison’s work in the 18th century. Since the formal establishment of COSC in 1973, the certification has become a benchmark for evaluating the precision of luxury timepieces, continuing a tradition of superiority in watchmaking.
Conclusion
Owning a COSC-accredited watch is more than an visual selection; it’s a dedication to quality and precision. For those valuing accuracy above all, the COSC validation provides peacefulness of thoughts, ensuring that each certified timepiece will function reliably under various conditions. Whether for personal satisfaction or as an investment, COSC-accredited timepieces distinguish themselves in the world of watchmaking, carrying on a legacy of precise timekeeping.
Магазин спортивной фармакологии – OxyShop. Это всемирно известный надёжный поставщик качественных препаратов для спортсменов чем отличается гормон роста от стероидов
Магазин спортивной фармакологии – OxyShop. Это всемирно известный надёжный поставщик качественных препаратов для спортсменов курс стероидов и гормон роста
Understanding COSC Validation and Its Importance in Horology
COSC Accreditation and its Strict Standards
COSC, or the Official Swiss Chronometer Testing Agency, is the authorized Switzerland testing agency that verifies the accuracy and accuracy of timepieces. COSC certification is a mark of quality craftsmanship and dependability in timekeeping. Not all timepiece brands follow COSC accreditation, such as Hublot, which instead sticks to its proprietary strict standards with mechanisms like the UNICO calibre, attaining equivalent precision.
The Art of Precision Chronometry
The core system of a mechanical timepiece involves the spring, which delivers power as it unwinds. This system, however, can be susceptible to external factors that may influence its accuracy. COSC-certified mechanisms undergo strict testing—over fifteen days in various conditions (five positions, three temperatures)—to ensure their durability and reliability. The tests assess:
Typical daily rate precision between -4 and +6 secs.
Mean variation, peak variation levels, and effects of temperature changes.
Why COSC Accreditation Is Important
For timepiece fans and connoisseurs, a COSC-certified timepiece isn’t just a item of tech but a demonstration to lasting excellence and precision. It signifies a timepiece that:
Provides outstanding reliability and precision.
Offers assurance of superiority across the entire construction of the watch.
Is apt to maintain its worth more effectively, making it a smart choice.
Famous Chronometer Brands
Several well-known brands prioritize COSC accreditation for their timepieces, including Rolex, Omega, Breitling, and Longines, among others. Longines, for instance, presents collections like the Archive and Spirit, which showcase COSC-validated movements equipped with cutting-edge materials like silicone equilibrium suspensions to enhance resilience and efficiency.
Historic Background and the Evolution of Chronometers
The notion of the timepiece originates back to the need for accurate timekeeping for navigation at sea, highlighted by John Harrison’s work in the 18th cent. Since the official foundation of COSC in 1973, the certification has become a benchmark for assessing the precision of luxury watches, maintaining a tradition of superiority in watchmaking.
Conclusion
Owning a COSC-accredited timepiece is more than an aesthetic choice; it’s a commitment to quality and accuracy. For those valuing precision above all, the COSC accreditation offers peace of thoughts, ensuring that each accredited watch will function reliably under various conditions. Whether for personal satisfaction or as an investment decision, COSC-validated watches stand out in the world of horology, bearing on a tradition of precise timekeeping.
cheap famciclovir – order famvir sale cheap valcivir
cytotec pills buy online: cytotec pills buy online – buy cytotec pills
היצע הנערות שיש כאן בתאר ובואו לבלות וליהנות מגופן היפה והנעים. זוהי ההזדמנות שלכם ליהנות מגוף מושלם וחטוב. להתענג על עורן החם ולהרגיש את רכות השדיים והישבנים העסיסיים. אתם תחוו תחושות של חום בכל חלקי גופכם. תחושות של אנרגיה מתפרצת ופורקן יצרים חלומי. ליווי פרטי
Если сумма выигрыша превышает 5 млн рублей, 1Win имеет право установить индивидуальный лимит на вывод в сутки. Мобильная версия и приложения. Для юзеров, предпочитающих мобильные гаджеты, у «1Вин» есть мобильная версия и приложения на iOS и Android aviator 1win
https://cytotec.club/# buy cytotec online
В нашем обществе, где диплом – это начало отличной карьеры в любом направлении, многие пытаются найти максимально простой путь получения качественного образования. Необходимость наличия документа об образовании сложно переоценить. Ведь именно диплом открывает дверь перед людьми, желающими вступить в профессиональное сообщество или учиться в высшем учебном заведении.
В данном контексте наша компания предлагает очень быстро получить этот необходимый документ. Вы имеете возможность купить диплом, что будет отличным решением для всех, кто не смог закончить обучение или утратил документ. дипломы выпускаются аккуратно, с максимальным вниманием к мельчайшим деталям. В результате вы получите полностью оригинальный документ.
Преимущества данного решения заключаются не только в том, что можно оперативно получить диплом. Процесс организовывается удобно, с профессиональной поддержкой. Начав от выбора требуемого образца до консультаций по заполнению личной информации и доставки по России — все находится под полным контролем квалифицированных мастеров.
В итоге, для тех, кто хочет найти оперативный способ получить требуемый документ, наша компания готова предложить выгодное решение. Купить диплом – значит избежать долгого процесса обучения и не теряя времени перейти к личным целям: к поступлению в ВУЗ или к началу трудовой карьеры.
https://diploman-rossiya.com
can i buy lisinopril over the counter in canada lisinopril 5mg tabs can i buy lisinopril over the counter
usareallservice.com
素晴らしい記事!非常にインスピレーションを受けました。
nolvadex 20mg: tamoxifen endometrium – tamoxifen and ovarian cancer
http://cytotec.club/# Cytotec 200mcg price
http://cytotec.club/# buy cytotec over the counter
lisinopril 30 mg price lisinopril 1.25 mg lisinopril 40mg prescription cost
online pharmacy no presc uk
buy ciprofloxacin over the counter: where can i buy cipro online – buy cipro cheap
Воєнторг
18. Обмундирование и снаряжение для полевых условий
воєнторг https://voentorgklyp.kiev.ua/ .
주식신용
로드스탁과의 레버리지 방식의 스탁: 투자법의 참신한 지평
로드스탁에서 제공하는 레버리지 방식의 스탁은 증권 투자법의 한 방식으로, 큰 이익율을 목표로 하는 투자자들에게 매력적인 옵션입니다. 레버리지를 사용하는 이 전략은 투자하는 사람들이 자신의 투자금을 초과하는 투자금을 투자할 수 있도록 하여, 주식 시장에서 더욱 큰 영향력을 가질 수 있는 방법을 줍니다.
레버리지 방식의 스탁의 원리
레버리지 방식의 스탁은 기본적으로 투자금을 차입하여 사용하는 방식입니다. 예를 들어, 100만 원의 자금으로 1,000만 원 상당의 주식을 취득할 수 있는데, 이는 투자자가 일반적인 자본보다 훨씬 훨씬 더 많은 주식을 구매하여, 주식 가격이 올라갈 경우 상응하는 더 큰 이익을 가져올 수 있게 합니다. 그러나, 주식 값이 내려갈 경우에는 그 피해 또한 크게 될 수 있으므로, 레버리지 사용을 사용할 때는 신중하게 생각해야 합니다.
투자 계획과 레버리지
레버리지는 특히 성장 잠재력이 큰 기업에 투입할 때 도움이 됩니다. 이러한 회사에 큰 비율로 투입하면, 잘 될 경우 상당한 이익을 획득할 수 있지만, 반대의 경우 상당한 리스크도 감수해야. 그렇기 때문에, 투자하는 사람은 자신의 위험 관리 능력을 가진 상장 분석을 통해 통해, 일정한 사업체에 얼마만큼의 자금을 적용할지 결정해야 합니다.
레버리지 사용의 이점과 위험 요소
레버리지 스탁은 높은 이익을 제공하지만, 그만큼 상당한 위험도 수반합니다. 주식 장의 변동성은 예측이 곤란하기 때문에, 레버리지를 이용할 때는 언제나 장터 경향을 면밀히 살펴보고, 피해를 최소로 줄일 수 있는 전략을 마련해야 합니다.
최종적으로: 조심스러운 결정이 필수입니다
로드스탁을 통해 제공하는 레버리지 스탁은 막강한 투자 도구이며, 잘 이용하면 많은 수입을 벌어들일 수 있습니다. 그렇지만 상당한 리스크도 고려해야 하며, 투자 결정은 충분한 정보와 세심한 생각 후에 이루어져야 합니다. 투자자 자신의 금융 상황, 리스크 감수 능력, 그리고 장터 상황을 생각한 균형 잡힌 투자 방법이 중요합니다.
lisinopril 20 mg brand name lisinopril average cost 60 lisinopril cost
En Son Zamanın En Büyük Beğenilen Bahis Platformu: Casibom
Casino oyunlarını sevenlerin artık duymuş olduğu Casibom, nihai dönemde adından sıkça söz ettiren bir şans ve oyun web sitesi haline geldi. Ülkemizdeki en iyi bahis sitelerinden biri olarak tanınan Casibom’un haftalık bazda cinsinden değişen açılış adresi, piyasada oldukça yenilikçi olmasına rağmen güvenilir ve kazandıran bir platform olarak tanınıyor.
Casibom, muadillerini geride bırakarak köklü kumarhane web sitelerinin önüne geçmeyi başarmayı sürdürüyor. Bu alanda uzun soluklu olmak önemlidir olsa da, oyunculardan iletişimde bulunmak ve onlara ulaşmak da aynı derecede değerli. Bu durumda, Casibom’un her saat hizmet veren canlı destek ekibi ile rahatça iletişime geçilebilir olması önemli bir fayda getiriyor.
Süratle artan oyuncuların kitlesi ile ilgi çekici Casibom’un gerisindeki başarı faktörleri arasında, yalnızca casino ve canlı olarak casino oyunları ile sınırlı kısıtlı olmayan geniş bir servis yelpazesi bulunuyor. Spor bahislerinde sunduğu kapsamlı seçenekler ve yüksek oranlar, katılımcıları çekmeyi başarılı oluyor.
Ayrıca, hem sporcular bahisleri hem de casino oyunlar katılımcılara yönlendirilen sunulan yüksek yüzdeli avantajlı ödüller da dikkat çekiyor. Bu nedenle, Casibom hızla alanında iyi bir reklam başarısı elde ediyor ve büyük bir oyuncu kitlesi kazanıyor.
Casibom’un kar getiren ödülleri ve popülerliği ile birlikte, platforma üyelik nasıl sağlanır sorusuna da değinmek elzemdir. Casibom’a mobil cihazlarınızdan, bilgisayarlarınızdan veya tabletlerinizden internet tarayıcı üzerinden rahatça erişilebilir. Ayrıca, platformun mobil uyumlu olması da büyük önem taşıyan bir avantaj getiriyor, çünkü şimdi hemen hemen herkesin bir akıllı telefonu var ve bu cihazlar üzerinden hızlıca erişim sağlanabiliyor.
Taşınabilir cihazlarınızla bile yolda gerçek zamanlı bahisler alabilir ve yarışmaları canlı olarak izleyebilirsiniz. Ayrıca, Casibom’un mobil uyumlu olması, memleketimizde kumarhane ve kumarhane gibi yerlerin meşru olarak kapatılmasıyla birlikte bu tür platformlara erişimin önemli bir yolunu oluşturuyor.
Casibom’un güvenilir bir bahis platformu olması da önemli bir avantaj sunuyor. Ruhsatlı bir platform olan Casibom, duraksız bir şekilde eğlence ve kar elde etme imkanı sağlar.
Casibom’a üye olmak da oldukça kolaydır. Herhangi bir belge koşulu olmadan ve bedel ödemeden platforma rahatça abone olabilirsiniz. Ayrıca, web sitesi üzerinde para yatırma ve çekme işlemleri için de birçok farklı yöntem mevcuttur ve herhangi bir kesim ücreti isteseniz de alınmaz.
Ancak, Casibom’un güncel giriş adresini takip etmek de elzemdir. Çünkü gerçek zamanlı iddia ve oyun platformlar popüler olduğu için sahte siteler ve dolandırıcılar da belirmektedir. Bu nedenle, Casibom’un sosyal medya hesaplarını ve güncel giriş adresini periyodik olarak kontrol etmek elzemdir.
Sonuç, Casibom hem emin hem de kazanç sağlayan bir bahis web sitesi olarak dikkat çekiyor. yüksek bonusları, kapsamlı oyun alternatifleri ve kullanıcı dostu mobil uygulaması ile Casibom, kumarhane sevenler için ideal bir platform sunuyor.
how much is synthroid
order generic lanoxin 250 mg – oral dipyridamole generic lasix 100mg
http://lisinopril.network/# lisinopril
Лечение игромании в Алматы https://someblog.ru/
Cytotec 200mcg price: cytotec pills online – buy cytotec over the counter
наркология алматы https://krasnodar-narkolog.ru/
prescription free canadian pharmacy
В нашем мире, где диплом – это начало успешной карьеры в любой сфере, многие стараются найти максимально быстрый путь получения образования. Наличие официального документа об образовании сложно переоценить. Ведь именно он открывает двери перед любым человеком, желающим вступить в сообщество квалифицированных специалистов или учиться в любом университете.
Наша компания предлагает оперативно получить этот необходимый документ. Вы имеете возможность заказать диплом старого или нового образца, что будет выгодным решением для человека, который не смог закончить образование, утратил документ или желает исправить плохие оценки. Любой диплом изготавливается с особой тщательностью, вниманием к мельчайшим деталям, чтобы в результате получился продукт, 100% соответствующий оригиналу.
Преимущества такого подхода состоят не только в том, что можно оперативно получить диплом. Весь процесс организован просто и легко, с нашей поддержкой. Начав от выбора необходимого образца до консультации по заполнению личных данных и доставки по России — все под полным контролем наших мастеров.
Таким образом, для всех, кто ищет оперативный способ получения необходимого документа, наша услуга предлагает выгодное решение. Купить диплом – значит избежать длительного обучения и сразу перейти к личным целям: к поступлению в ВУЗ или к началу трудовой карьеры.
https://diploman-russiyan.com
casino bono de bienvenida sin deposito peru [url=https://sin-deposito-peru.org]https://sin-deposito-peru.org[/url] .
https://ciprofloxacin.tech/# where can i buy cipro online
В нашем обществе, где диплом является началом отличной карьеры в любом направлении, многие пытаются найти максимально быстрый путь получения качественного образования. Факт наличия официального документа об образовании сложно переоценить. Ведь диплом открывает двери перед всеми, кто стремится вступить в профессиональное сообщество или учиться в ВУЗе.
Мы предлагаем максимально быстро получить этот необходимый документ. Вы сможете приобрести диплом нового или старого образца, и это является выгодным решением для человека, который не смог завершить образование, потерял документ или хочет исправить свои оценки. дипломы производятся аккуратно, с максимальным вниманием к мельчайшим нюансам. В итоге вы получите документ, 100% соответствующий оригиналу.
Преимущество данного подхода заключается не только в том, что можно быстро получить свой диплом. Весь процесс организовывается комфортно и легко, с профессиональной поддержкой. От выбора необходимого образца до консультации по заполнению личной информации и доставки по стране — все под абсолютным контролем опытных мастеров.
В итоге, всем, кто ищет оперативный способ получить необходимый документ, наша услуга предлагает отличное решение. Приобрести диплом – значит избежать долгого процесса обучения и сразу перейти к своим целям, будь то поступление в ВУЗ или старт карьеры.
https://diploman-russiyan.com
buying propecia without insurance cost propecia without insurance propecia sale
10배스탁론
로드스탁과의 레버리지 방식의 스탁: 투자 전략의 신규 영역
로드스탁을 통해 제공하는 레버리지 스탁은 주식 투자법의 한 방법으로, 높은 수익률을 목표로 하는 투자자들에게 매혹적인 옵션입니다. 레버리지를 이용하는 이 전략은 투자하는 사람들이 자신의 자본을 초과하는 자금을 투자할 수 있도록 하여, 주식 장에서 훨씬 큰 영향력을 가질 수 있는 기회를 공급합니다.
레버리지 스탁의 원리
레버리지 스탁은 원칙적으로 자금을 빌려 사용하는 방식입니다. 예를 들어, 100만 원의 자금으로 1,000만 원 상당의 증권을 사들일 수 있는데, 이는 투자자가 기본 투자 금액보다 훨씬 더 많은 주식을 취득하여, 증권 가격이 증가할 경우 관련된 더욱 큰 이익을 가져올 수 있게 합니다. 하지만, 주식 가격이 떨어질 경우에는 그 손해 또한 커질 수 있으므로, 레버리지를 사용할 때는 신중해야 합니다.
투자 전략과 레버리지 사용
레버리지 사용은 특히 성장 가능성이 큰 사업체에 투자할 때 유용합니다. 이러한 기업에 상당한 비율을 통해 적용하면, 성공할 경우 막대한 수입을 획득할 수 있지만, 반대의 경우 많은 위험도 감수하게 됩니다. 그러므로, 투자자는 자신의 위험 관리 능력을 가진 시장 분석을 통해, 어떤 사업체에 얼마만큼의 자금을 투자할지 결정해야 합니다.
레버리지의 장점과 위험 요소
레버리지 방식의 스탁은 상당한 이익을 제공하지만, 그만큼 큰 위험도 수반합니다. 주식 장의 변화는 예상이 어렵기 때문에, 레버리지 사용을 사용할 때는 항상 상장 동향을 세심하게 주시하고, 손실을 최소화할 수 있는 계획을 세워야 합니다.
맺음말: 신중한 선택이 요구됩니다
로드스탁을 통해 공급하는 레버리지 스탁은 막강한 투자 도구이며, 적당히 이용하면 상당한 이익을 제공할 수 있습니다. 그렇지만 큰 위험성도 고려해야 하며, 투자 결정은 충분히 많은 사실과 신중한 고려 후에 진행되어야 합니다. 투자자 자신의 금융 상황, 리스크 감수 능력, 그리고 장터 상황을 반영한 조화로운 투자 전략이 중요하며.
lisinopril cost us: buy lisinopril 40 mg online – lisinopril otc
https://finasteride.store/# propecia prices
На сегодняшний день, когда диплом – это начало удачной карьеры в любом направлении, многие ищут максимально быстрый путь получения образования. Наличие документа об образовании трудно переоценить. Ведь диплом открывает двери перед людьми, желающими вступить в сообщество профессионалов или учиться в любом университете.
В данном контексте мы предлагаем быстро получить этот важный документ. Вы можете заказать диплом нового или старого образца, что является отличным решением для всех, кто не смог закончить образование, утратил документ или желает исправить плохие оценки. Любой диплом изготавливается с особой аккуратностью, вниманием к мельчайшим элементам. В итоге вы сможете получить полностью оригинальный документ.
Плюсы этого подхода состоят не только в том, что можно оперативно получить свой диплом. Процесс организовывается просто и легко, с нашей поддержкой. Начиная от выбора нужного образца до грамотного заполнения личной информации и доставки по России — все будет находиться под полным контролем наших специалистов.
В результате, для тех, кто хочет найти быстрый способ получить требуемый документ, наша услуга предлагает выгодное решение. Приобрести диплом – это значит избежать продолжительного процесса обучения и не теряя времени переходить к личным целям: к поступлению в ВУЗ или к началу трудовой карьеры.
https://dlplomanrussian.com
buysteriodsonline.com
많은 사람들이 두꺼운 면 옷을 입고 손을 맞잡고 왔습니다.
клиника вывод из запоя нарколог
https://cytotec.club/# cytotec buy online usa
buy cipro online: buy cipro online without prescription – ciprofloxacin over the counter
В современном мире, где диплом – это начало успешной карьеры в любом направлении, многие ищут максимально быстрый и простой путь получения качественного образования. Факт наличия официального документа сложно переоценить. Ведь диплом открывает двери перед людьми, желающими вступить в профессиональное сообщество или продолжить обучение в каком-либо ВУЗе.
В данном контексте наша компания предлагает быстро получить этот важный документ. Вы можете приобрести диплом, и это является отличным решением для всех, кто не смог закончить обучение, потерял документ или желает исправить свои оценки. Все дипломы изготавливаются аккуратно, с особым вниманием ко всем нюансам. В результате вы получите 100% оригинальный документ.
Преимущества этого подхода заключаются не только в том, что вы сможете быстро получить свой диплом. Весь процесс организован комфортно, с нашей поддержкой. От выбора подходящего образца до грамотного заполнения личных данных и доставки по стране — все под абсолютным контролем квалифицированных специалистов.
В результате, всем, кто пытается найти быстрый способ получения требуемого документа, наша компания предлагает выгодное решение. Приобрести диплом – значит избежать продолжительного обучения и не теряя времени переходить к личным целям: к поступлению в университет или к началу успешной карьеры.
https://dlplomanrussian.com
cipro ciprofloxacin 500mg buy online cipro 500mg best prices
В современном мире, где диплом является началом отличной карьеры в любой сфере, многие ищут максимально простой путь получения образования. Факт наличия официального документа трудно переоценить. Ведь диплом открывает дверь перед всеми, кто стремится вступить в сообщество квалифицированных специалистов или продолжить обучение в университете.
Мы предлагаем оперативно получить любой необходимый документ. Вы имеете возможность приобрести диплом, и это становится выгодным решением для человека, который не смог завершить образование или потерял документ. диплом изготавливается аккуратно, с особым вниманием ко всем элементам, чтобы на выходе получился полностью оригинальный документ.
Преимущество такого решения заключается не только в том, что вы сможете быстро получить свой диплом. Процесс организовывается удобно, с нашей поддержкой. От выбора необходимого образца документа до консультации по заполнению личных данных и доставки по России — все находится под абсолютным контролем квалифицированных мастеров.
Для всех, кто пытается найти быстрый способ получения требуемого документа, наша компания может предложить выгодное решение. Заказать диплом – это значит избежать длительного процесса обучения и не теряя времени перейти к важным целям: к поступлению в университет или к началу удачной карьеры.
https://dlplomanrussian.com
cipro online no prescription in the usa: cipro – ciprofloxacin 500 mg tablet price
Перед тем как приступить к поиску идеального транспортного средства, важно определить ваши потребности и предпочтения. Обдумайте, для каких целей вам необходимо автомобиль или другое транспортное средство, какие характеристики будут наиболее приоритетными для вас, и какой бюджет вы готовы выделить на покупку http://www.turkeyspartymakers.com/index.php/forum/welcome-mat/267#267
https://cytotec.club/# buy cytotec
http://cytotec.club/# purchase cytotec
get cheap propecia pill cost cheap propecia without dr prescription cost propecia no prescription
Сегодня, когда диплом становится началом успешной карьеры в любой сфере, многие стараются найти максимально быстрый и простой путь получения качественного образования. Наличие официального документа переоценить невозможно. Ведь именно он открывает дверь перед любым человеком, который собирается начать профессиональную деятельность или продолжить обучение в любом ВУЗе.
Предлагаем очень быстро получить этот важный документ. Вы можете заказать диплом, что становится удачным решением для человека, который не смог завершить образование или потерял документ. Любой диплом изготавливается с особой аккуратностью, вниманием ко всем нюансам, чтобы на выходе получился продукт, полностью соответствующий оригиналу.
Плюсы подобного подхода состоят не только в том, что вы сможете быстро получить свой диплом. Весь процесс организовывается удобно и легко, с профессиональной поддержкой. От выбора нужного образца до грамотного заполнения личной информации и доставки по России — все находится под абсолютным контролем квалифицированных мастеров.
В итоге, всем, кто хочет найти быстрый способ получить необходимый документ, наша компания готова предложить выгодное решение. Приобрести диплом – это значит избежать долгого процесса обучения и сразу переходить к достижению личных целей, будь то поступление в ВУЗ или старт трудовой карьеры.
https://diploman-rossiya.com
nolvadex d where to get nolvadex tamoxifen menopause
synthroid 112 mcg
https://ciprofloxacin.tech/# buy generic ciprofloxacin
canadadrugpharmacy com
metoprolol 50mg cost – buy generic micardis adalat 30mg cheap
order hydrochlorothiazide – buy zestril 5mg pill how to buy bisoprolol
В нашем обществе, где диплом становится началом успешной карьеры в любом направлении, многие стараются найти максимально простой путь получения образования. Факт наличия официального документа трудно переоценить. Ведь диплом открывает двери перед любым человеком, который стремится начать профессиональную деятельность или учиться в каком-либо университете.
В данном контексте мы предлагаем оперативно получить этот необходимый документ. Вы сможете заказать диплом старого или нового образца, и это является удачным решением для всех, кто не смог завершить образование или утратил документ. Все дипломы выпускаются аккуратно, с максимальным вниманием ко всем деталям. В итоге вы получите продукт, полностью соответствующий оригиналу.
Плюсы подобного решения состоят не только в том, что вы быстро получите свой диплом. Весь процесс организован удобно и легко, с профессиональной поддержкой. От выбора требуемого образца до точного заполнения личных данных и доставки по стране — все под абсолютным контролем наших мастеров.
Всем, кто ищет максимально быстрый способ получить необходимый документ, наша компания предлагает выгодное решение. Приобрести диплом – это значит избежать длительного обучения и не теряя времени переходить к важным целям, будь то поступление в университет или начало удачной карьеры.
https://diploman-russiyan.com
https://mlgtesturamdtestv.ru/
order generic propecia pill cost of generic propecia pills cost cheap propecia no prescription
buy cipro: ciprofloxacin 500 mg tablet price – cipro for sale
Магазин учитывает пожелания каждого покупателя, предоставляя персональные решения для освещения различных помещений http://center-2.ru/forum/?mingleforumaction=viewtopic&t=11915#postid-23727
https://ciprofloxacin.tech/# cipro
https://www.perplexity.ai/collections/Betfrom-Casino-vOELleVZSaG9D3kNmxl0JQ
https://mlgtesturamdtestv22.ru/
В нашем обществе, где диплом – это начало отличной карьеры в любой отрасли, многие ищут максимально простой путь получения качественного образования. Необходимость наличия официального документа об образовании сложно переоценить. Ведь диплом открывает двери перед каждым человеком, который стремится вступить в сообщество профессиональных специалистов или продолжить обучение в высшем учебном заведении.
Мы предлагаем очень быстро получить любой необходимый документ. Вы имеете возможность заказать диплом, и это будет отличным решением для человека, который не смог закончить образование, потерял документ или хочет исправить плохие оценки. Все дипломы производятся с особой аккуратностью, вниманием ко всем деталям, чтобы на выходе получился документ, максимально соответствующий оригиналу.
Преимущества такого подхода заключаются не только в том, что вы быстро получите свой диплом. Процесс организовывается комфортно, с нашей поддержкой. Начав от выбора подходящего образца до грамотного заполнения персональной информации и доставки по России — все находится под полным контролем опытных специалистов.
Всем, кто ищет максимально быстрый способ получения необходимого документа, наша компания может предложить отличное решение. Заказать диплом – значит избежать продолжительного обучения и не теряя времени переходить к достижению своих целей, будь то поступление в университет или старт удачной карьеры.
https://diploman-rossiya.com
https://mlgtesturamdtestv22.ru/
cost generic propecia price: cheap propecia without rx – order propecia
https://nolvadex.life/# tamoxifen menopause
В современном мире, где диплом является началом успешной карьеры в любом направлении, многие ищут максимально быстрый и простой путь получения качественного образования. Наличие официального документа об образовании сложно переоценить. Ведь диплом открывает двери перед каждым человеком, который желает начать профессиональную деятельность или продолжить обучение в ВУЗе.
В данном контексте наша компания предлагает максимально быстро получить этот важный документ. Вы сможете купить диплом старого или нового образца, что является отличным решением для всех, кто не смог закончить обучение или утратил документ. Все дипломы изготавливаются с особой тщательностью, вниманием ко всем деталям. В результате вы получите продукт, 100% соответствующий оригиналу.
Преимущество такого подхода состоит не только в том, что можно оперативно получить свой диплом. Весь процесс организовывается просто и легко, с нашей поддержкой. От выбора необходимого образца до консультаций по заполнению личной информации и доставки по России — все под полным контролем опытных мастеров.
Всем, кто пытается найти быстрый способ получить необходимый документ, наша компания готова предложить выгодное решение. Заказать диплом – значит избежать длительного обучения и не теряя времени перейти к своим целям: к поступлению в университет или к началу успешной карьеры.
https://diploman-russiyans.com
п»їLevitra price: Levitra 20mg price – buy Levitra over the counter
best price for viagra 100mg Cheap Viagra 100mg Viagra without a doctor prescription Canada
Viagra tablet online: order viagra – over the counter sildenafil
В нашем обществе, где диплом является началом успешной карьеры в любом направлении, многие ищут максимально быстрый путь получения качественного образования. Наличие официального документа об образовании трудно переоценить. Ведь диплом открывает двери перед всеми, кто стремится начать профессиональную деятельность или учиться в университете.
Наша компания предлагает максимально быстро получить этот важный документ. Вы сможете купить диплом старого или нового образца, и это становится выгодным решением для всех, кто не смог закончить обучение или потерял документ. Любой диплом изготавливается с особой аккуратностью, вниманием к мельчайшим нюансам. В результате вы получите документ, полностью соответствующий оригиналу.
Превосходство данного решения заключается не только в том, что можно оперативно получить диплом. Весь процесс организовывается удобно, с нашей поддержкой. От выбора нужного образца до грамотного заполнения личной информации и доставки по России — все под абсолютным контролем опытных специалистов.
Всем, кто пытается найти быстрый способ получить необходимый документ, наша компания предлагает отличное решение. Купить диплом – значит избежать продолжительного процесса обучения и сразу перейти к своим целям: к поступлению в университет или к началу трудовой карьеры.
https://diplomanc-russia24.com
http://cialist.pro/# Buy Tadalafil 10mg
buy azithromycin 1000 mg
GET X – финансовая игра с выводом реальных средств. На данный момент на сайте представлена одна самых популярных и известных финансовых игр – Crash гет икс
http://cenforce.pro/# buy cenforce
GET X – финансовая игра с выводом реальных средств. На данный момент на сайте представлена одна самых популярных и известных финансовых игр – Crash гетикс
tadalafil tablet buy online india
cheap kamagra: kamagra – Kamagra tablets
5443 prednisone
проверить свои usdt на чистоту
Проверка кошельков кошельков за выявление нелегальных финансовых средств: Обеспечение безопасности вашего цифрового активов
В мире электронных денег становится все значимее все более необходимо обеспечивать безопасность своих финансовых активов. Постоянно мошенники и злоумышленники выработывают новые подходы мошенничества и воровства цифровых средств. Ключевым инструментом ключевых способов обеспечения безопасности является анализ кошельков на выявление нелегальных средств.
Почему же так важно проверить свои цифровые кошельки?
В первую очередь, вот этот момент нужно для защиты собственных денег. Многие люди, вкладывающие деньги рискуют потерять утраты их средств в результате недобросовестных методов или краж. Проверка кошельков кошельков для хранения криптовалюты способствует выявить вовремя сомнительные манипуляции и предотвратить возможные.
Что предлагает вашему вниманию компания?
Мы предлагаем сервис проверки проверки данных цифровых кошельков для хранения электронных денег и переводов средств с намерением выявления происхождения финансовых средств и дать подробного доклада. Наши платформа проверяет данные пользователя для идентификации потенциально нелегальных манипуляций и оценить риск для личного финансового портфеля. Благодаря нашей службе проверки, вы будете в состоянии предотвратить с органами контроля и защитить себя от непреднамеренного участия в нелегальных операций.
Как осуществляется процесс?
Наша организация работает с ведущими аудиторскими фирмами фирмами, как например Halborn, с тем чтобы обеспечить гарантированность и точность наших проверок. Мы внедряем современные и методики анализа для выявления наличия небезопасных операций. Личные данные наших заказчиков обрабатываются и хранятся в специальной базе данных в соответствии с положениями высокими требованиями.
Важный запрос: “проверить свои USDT на чистоту”
Если вас интересует убедиться чистоте ваших USDT-кошельков, наши эксперты предлагает возможность бесплатную проверку наших специалистов первых 5 кошельков. Просто введите адрес своего кошелька в соответствующее окно на нашем онлайн-ресурсе, и мы вышлем вам подробные сведения о его статусе.
Обеспечьте безопасность своих финансовые активы прямо сейчас!
Предотвращайте риски становиться пострадать от хакеров или оказаться в неприятной ситуации из-за подозрительных операций средств с ваших деньгами. Позвольте себе профессиональным консультантам, которые окажут помощь, вам и вашим финансам обезопасить деньги и предотвратить. Предпримите первый шаг к безопасности к безопасности вашего цифрового портфельчика в данный момент!
werankcities.com
급한 일이 생기면 불확실한 일이 생길 때마다 그는 너무 신경을 쓰지 못한다.
Как убедиться в чистоте USDT
Проверка данных кошелька за наличие неправомерных средств передвижения: Защита личного электронного портфеля
В мире электронных денег становится все более существеннее гарантировать секретность личных активов. Постоянно мошенники и криминальные элементы выработывают совершенно новые способы обмана и кражи электронных средств. Одним из существенных средств обеспечения безопасности является проверка данных кошелька на наличие подозрительных денег.
Почему поэтому важно и проверить личные цифровые кошельки для хранения криптовалюты?
Прежде всего это обстоятельство нужно для того чтобы защиты своих финансовых средств. Множество люди, вкладывающие деньги рискуют потерять потери своих финансов в результате несправедливых подходов или краж. Анализ кошелька способствует обнаружить на своем пути непонятные операции и предупредить.
Что предлагает организация?
Мы предлагаем вам послугу анализа криптовалютных кошельков для хранения криптовалюты и транзакций с задачей идентификации источника финансовых средств и выдачи детального отчета о результатах. Компания предлагает платформа осматривает данные пользователя для определения потенциально нелегальных действий и оценить риск для личного портфеля активов. Благодаря нашей службе проверки, вы можете предотвратить возможные с органами контроля и обезопасить себя от непреднамеренного участия в незаконных операций.
Как осуществляется процесс?
Компания наша организация работает с ведущими аудиторскими организациями, такими как Halborn, чтобы дать гарантию и правильность наших проверок. Мы применяем новейшие и методики анализа данных для выявления небезопасных операций. Персональные сведения наших клиентов обрабатываются и хранятся в базе в соответствии с высокими требованиями.
Ключевой запрос: “проверить свои USDT на чистоту”
В случае если вы хотите убедиться в безопасности ваших USDT-кошельков, наши специалисты предоставляет возможность бесплатный анализ первых пяти кошельков. Просто введите свой кошелек в указанное место на нашем онлайн-ресурсе, и мы дадим вам подробную информацию о статусе вашего кошелька.
Защитите свои финансовые средства уже сегодня!
Предотвращайте риски становиться жертвой хакеров или оказаться неприятной ситуации из-за неправомерных операций с вашими личными средствами. Дайте вашу криптовалюту специалистам, которые смогут помочь, вам и вашим финансам обезопаситься криптовалютные активы и предотвратить возможные проблемы. Совершите первый шаг к безопасности защите вашего электронного портфеля активов сразу же!
Осмотр USDT в чистоту: Как сохранить собственные электронные средства
Каждый день все больше людей обращают внимание на безопасность личных электронных средств. Каждый день обманщики изобретают новые способы хищения криптовалютных активов, и также владельцы электронной валюты становятся пострадавшими их афер. Один из подходов обеспечения безопасности становится проверка кошельков в присутствие противозаконных средств.
Зачем это полезно?
В первую очередь, для того чтобы защитить свои активы против мошенников и украденных монет. Многие участники сталкиваются с вероятностью потери своих фондов по причине мошеннических схем либо краж. Осмотр бумажников способствует выявить подозрительные транзакции и предотвратить возможные убытки.
Что наша группа предлагаем?
Мы предоставляем услугу тестирования электронных бумажников и также транзакций для определения происхождения фондов. Наша система анализирует данные для обнаружения нелегальных операций и также оценки угрозы вашего портфеля. Из-за этой проверке, вы сможете избегать проблем с регуляторами и защитить себя от участия в нелегальных операциях.
Как происходит процесс?
Наша команда сотрудничаем с лучшими аудиторскими фирмами, такими как Certik, с целью обеспечить точность наших проверок. Мы применяем современные технологии для определения опасных транзакций. Ваши информация обрабатываются и сохраняются согласно с высокими стандартами безопасности и конфиденциальности.
Как проверить собственные USDT в прозрачность?
В случае если вы желаете подтвердить, что ваши Tether-кошельки чисты, наш сервис предоставляет бесплатное тестирование первых пяти кошельков. Просто вбейте положение вашего кошелька в на нашем веб-сайте, и наш сервис предоставим вам детальный отчет о его статусе.
Защитите вашими средства уже сегодня!
Избегайте риска попасть в жертву дельцов или попасть в неприятную обстановку вследствие противозаконных операций. Посетите нашей команде, для того чтобы предохранить ваши электронные активы и предотвратить затруднений. Сделайте первый шаг к безопасности вашего криптовалютного портфеля прямо сейчас!
cheap kamagra: kamagra pills – Kamagra 100mg
Cheap Sildenafil 100mg: viagras.online – Cheapest Sildenafil online
Анализ USDT на нетронутость: Каким образом защитить собственные цифровые состояния
Все более граждан обращают внимание в безопасность собственных криптовалютных финансов. Постоянно шарлатаны придумывают новые подходы кражи цифровых средств, и держатели криптовалюты становятся жертвами их афер. Один из техник охраны становится проверка кошельков в наличие нелегальных средств.
Зачем это необходимо?
Преимущественно, для того чтобы обезопасить свои средства от обманщиков а также украденных денег. Многие вкладчики встречаются с вероятностью убытков своих активов в результате мошеннических схем или кражей. Осмотр бумажников способствует выявить подозрительные действия а также предотвратить возможные убытки.
Что мы предлагаем?
Мы предлагаем услугу проверки цифровых кошельков и также операций для обнаружения начала средств. Наша система анализирует информацию для определения нелегальных операций и также оценки опасности вашего портфеля. Из-за этой проверке, вы сможете избежать проблем с регулированием и также обезопасить себя от участия в противозаконных сделках.
Как происходит процесс?
Мы сотрудничаем с передовыми проверочными компаниями, вроде Halborn, с целью предоставить точность наших проверок. Мы применяем новейшие техники для определения рискованных операций. Ваши информация обрабатываются и сохраняются в соответствии с высокими стандартами безопасности и приватности.
Как выявить свои Tether для чистоту?
В случае если вы желаете проверить, что ваши Tether-кошельки нетронуты, наш сервис обеспечивает бесплатную проверку первых пяти кошельков. Просто вбейте местоположение вашего кошелька на на сайте, или мы предложим вам полную информацию доклад о его статусе.
Охраняйте свои фонды сегодня же!
Избегайте риска подвергнуться обманщиков или оказаться в неприятную ситуацию из-за нелегальных операций. Обратитесь к нам, для того чтобы предохранить свои криптовалютные финансовые ресурсы и избежать затруднений. Примите первый шаг к безопасности вашего криптовалютного портфеля прямо сейчас!
https://levitrav.store/# Buy Vardenafil online
Алматы Азарт – это уникальное игровое пространство для людей старше 30 лет, которые ценят интеллектуальный досуг и общение https://my.bio/agentstvo-razvlecheniy
Алматы Азарт – это уникальное игровое пространство для людей старше 30 лет, которые ценят интеллектуальный досуг и общение https://socprofile.com/agenstvo_otdiha
super kamagra super kamagra Kamagra 100mg
buy zithromax pills
http://cialist.pro/# buy cialis pill
brand nitroglycerin – buy valsartan cheap buy diovan 160mg online cheap
cheapest cenforce cenforce.pro cheapest cenforce
Проверка USDT на чистоту
Тестирование USDT в чистоту: Как защитить собственные криптовалютные финансы
Все больше людей обращают внимание для надежность личных криптовалютных активов. Ежедневно мошенники изобретают новые подходы кражи электронных средств, а также держатели электронной валюты являются пострадавшими их подстав. Один методов охраны становится проверка бумажников на наличие противозаконных средств.
С каким намерением это потребуется?
В первую очередь, с тем чтобы обезопасить свои средства от обманщиков или украденных денег. Многие специалисты сталкиваются с риском потери их финансов в результате хищных сценариев или краж. Осмотр кошельков способствует выявить подозрительные операции и также предотвратить потенциальные потери.
Что наша группа предлагаем?
Наша компания предоставляем подход проверки криптовалютных бумажников и транзакций для выявления начала средств. Наша платформа исследует данные для определения противозаконных действий и также оценки опасности вашего портфеля. За счет такой проверке, вы сможете избегнуть проблем с регуляторами или обезопасить себя от участия в незаконных операциях.
Каким образом это работает?
Мы сотрудничаем с ведущими аудиторскими компаниями, например Kudelsky Security, для того чтобы обеспечить точность наших тестирований. Мы применяем передовые техники для выявления потенциально опасных транзакций. Ваши информация обрабатываются и хранятся согласно с высокими нормами безопасности и конфиденциальности.
Как проверить свои Tether в прозрачность?
В случае если вы желаете подтвердить, что ваша Tether-кошельки чисты, наш сервис предоставляет бесплатную проверку первых пяти кошельков. Легко введите адрес личного бумажника на на нашем веб-сайте, и мы предоставим вам подробный доклад об его положении.
Охраняйте ваши фонды уже сегодня!
Не подвергайте опасности подвергнуться дельцов или попасть в неприятную обстановку из-за нелегальных операций. Обратитесь к нашему сервису, для того чтобы сохранить ваши криптовалютные финансовые ресурсы и предотвратить проблем. Совершите первый шаг для безопасности криптовалютного портфеля уже сейчас!
metformin for sale no prescription
https://www.perplexity.ai/collections/Spinoloco-Casino-F7oQCaBPQaKV6TwOiKEDyQ
http://levitrav.store/# Cheap Levitra online
USDT – это неизменная криптовалютный актив, связанная к валюте страны, например американский доллар. Данное обстоятельство делает данную криптовалюту особенно известной среди трейдеров, так как данный актив предоставляет надежность цены в условиях волатильности криптовалютного рынка. Однако, подобно любая другая вид криптовалюты, USDT подвержена опасности использования с целью легализации доходов и финансирования противоправных операций.
Отмывание денег через криптовалюты становится все более распространенным в большей степени путем для сокрытия происхождения капитала. Применяя различные методы, дельцы могут пытаться легализовывать незаконно добытые деньги посредством обменники криптовалют или миксеры средств, чтобы совершить происхождение менее понятным.
Именно в связи с этим, анализ USDT на чистоту оказывается важной мерой защиты для пользователей криптовалют. Существуют специализированные сервисы, какие проводят экспертизу операций и счетов, чтобы обнаружить подозрительные транзакции и противоправные источники средств. Эти услуги помогают пользователям предотвратить непреднамеренного участия в преступных действий и предотвратить блокировку счетов со стороны надзорных органов.
Экспертиза USDT на чистоту также способствует обезопасить себя от возможных финансовых убытков. Владельцы могут быть убеждены в том их активы не связаны с нелегальными сделками, что в свою очередь уменьшает вероятность блокировки счета или лишения капитала.
Поэтому, в текущей ситуации повышающейся сложности среды криптовалют важно принимать шаги для обеспечения надежности своего капитала. Проверка USDT на чистоту с помощью специализированных платформ является одним из вариантов противодействия финансирования преступной деятельности, обеспечивая пользователям криптовалют дополнительную степень и безопасности.
We bieden tijdelijke telefoonnummers in tientallen landen over de hele wereld, met duizenden nummers om uit te kiezen mobielnummer duitsland
super kamagra kamagra super kamagra
https://levitrav.store/# Buy Levitra 20mg online
Levitra 20 mg for sale: Levitra generic price – Levitra 10 mg buy online
https://www.perplexity.ai/collections/NineWin-Casino-Mt.0tE.QRWaXnCDprl70eg
九州娛樂城登入
九州娛樂
Effective Links in Blogs and forums and Comments: Increase Your SEO
Backlinks are critical for increasing search engine rankings and boosting website visibility. By including links into blogs and comments prudently, they can considerably enhance traffic and SEO overall performance.
Adhering to Search Engine Algorithms
Today’s backlink positioning tactics are meticulously tuned to line up with search engine algorithms, which now prioritize website link good quality and relevance. This guarantees that backlinks are not just abundant but meaningful, guiding consumers to useful and pertinent content. Website owners should emphasis on integrating links that are contextually proper and improve the general content quality.
Benefits of Using Clean Donor Bases
Making use of up-to-date donor bases for links, like those managed by Alex, provides substantial benefits. These bases are often renewed and consist of unmoderated sites that don’t attract complaints, ensuring the links placed are both powerful and compliant. This approach assists in maintaining the effectiveness of hyperlinks without the dangers connected with moderated or problematic resources.
Only Approved Resources
All donor sites used are authorized, avoiding legal pitfalls and sticking to digital marketing standards. This determination to utilizing only approved resources ensures that each backlink is genuine and reliable, thereby developing reliability and dependability in your digital presence.
SEO Impact
Skillfully put backlinks in blogs and remarks provide over just SEO benefits—they boost user experience by linking to appropriate and high-quality content. This strategy not only fulfills search engine conditions but also entails consumers, leading to better traffic and enhanced online proposal.
In essence, the right backlink strategy, especially one that utilizes fresh and trustworthy donor bases like Alex’s, can change your SEO efforts. By focusing on high quality over volume and adhering to the most recent criteria, you can make sure your backlinks are both powerful and effective.
buy prednisone online from mexico
мебель для диспетчерских залов [url=https://oborudovanie-dispetcherskih-centrov.ru]https://oborudovanie-dispetcherskih-centrov.ru[/url] .
http://pharmindia.online/# buy medicines online in india
1win официальный сайт https://1win-telegram.com/
cá cược thể thao
prinivil 25 mg
canada pharmacies online prescriptions: online pharmacies no prescription usa – canadian prescription drugstore review
mexican mail order pharmacies mexico pharmacy medicine in mexico pharmacies
online pharmacy not requiring prescription: canada prescription – how to order prescription drugs from canada
Проверка USDT на чистоту: Каким образом сохранить собственные электронные состояния
Все более индивидуумов заботятся к безопасность личных криптовалютных активов. Ежедневно обманщики изобретают новые подходы кражи цифровых денег, и собственники электронной валюты оказываются жертвами своих интриг. Один из методов охраны становится проверка кошельков на наличие противозаконных средств.
Для чего это полезно?
Прежде всего, чтобы обезопасить собственные средства от дельцов или украденных монет. Многие инвесторы сталкиваются с риском потери их фондов из-за хищных механизмов либо кражей. Анализ кошельков помогает выявить подозрительные операции и также предотвратить возможные потери.
Что наша команда предлагаем?
Мы предоставляем услугу анализа криптовалютных кошельков и операций для выявления начала денег. Наша платформа проверяет информацию для определения незаконных транзакций и оценки угрозы для вашего портфеля. Вследствие этой проверке, вы сможете избегать проблем с регуляторами а также обезопасить себя от участия в противозаконных сделках.
Как это работает?
Наша фирма сотрудничаем с первоклассными проверочными агентствами, вроде Halborn, с целью предоставить аккуратность наших проверок. Наша команда используем современные техники для определения рискованных операций. Ваши информация обрабатываются и сохраняются в соответствии с высокими стандартами безопасности и конфиденциальности.
Каким образом проверить свои Tether в прозрачность?
Если хотите подтвердить, что ваша USDT-кошельки чисты, наш подход предлагает бесплатное тестирование первых пяти кошельков. Просто введите адрес своего кошелька на на нашем веб-сайте, и наш сервис предоставим вам полную информацию отчет о его положении.
Защитите вашими активы уже сейчас!
Избегайте риска подвергнуться обманщиков либо попасть в неприятную обстановку из-за незаконных операций. Обратитесь к нашему сервису, для того чтобы предохранить ваши криптовалютные активы и избежать сложностей. Сделайте первый шаг для безопасности вашего криптовалютного портфеля прямо сейчас!
toasterovensplus.com
知識が豊富で読みやすい素晴らしい記事でした。
online pharmacy india online shopping pharmacy india Online medicine home delivery
Creating distinct articles on Medium and Platform, why it is required:
Created article on these resources is better ranked on low-frequency queries, which is very significant to get organic traffic.
We get:
natural traffic from search algorithms.
natural traffic from the internal rendition of the medium.
The webpage to which the article refers gets a link that is liquid and increases the ranking of the site to which the article refers.
Articles can be made in any number and choose all low-frequency queries on your topic.
Medium pages are indexed by search engines very well.
Telegraph pages need to be indexed separately indexer and at the same time after indexing they sometimes occupy spots higher in the search engines than the medium, these two platforms are very helpful for getting traffic.
Here is a URL to our services where we provide creation, indexing of sites, articles, pages and more.
canadian pharmacy no prescription: online pharmacy – canadian pharmacy no prescription
Приветствуем вас на вашем интернет-ресурсе!
Мы представляем компания СЕО продвижения XRumer LLC.
Ваш онлайн-сайт, как можно заметить, еще только набирает обороты. Чтобы максимально ускорить процесс его роста, готовы предложить наши услуги по SEO-оптимизации. У нас имеются доступные и эффективные инструменты для СЕО-специалистов. У нашей команды значительный опыт, в арсенале присутствуют реальные рабочие кейсы – если интересно, покажем по запросу.
Мы можем предложить скидку 10% до конца месяца на все услуги.
Услуги:
– Размещаем трастовые ссылки (необходимо абсолютно всем сайтам) – цена от 1,5 до 5000 рублей
– Размещение безанкорных ссылок (полезно для любых сайтов) – 3900 рублей
– Топовый прогон на 110 тысяч сайтов (RU.зона) – 2.900 р
– 150 постов в VK про ваш сайт (недорогая реклама) – 3.900 р
– Публикации о вашем сайте на 300 интернет-форумах (очень мощная раскрутка интернет-сайта) – 29 тыс. рублей
– Супер Постинг – грандиозный прогон по 3 млн площадок (мощнейший прогон для ваших сайтов) – 39.900 р
– Рассылка сообщений по сайтам с использованием обратной связи – стоимость по договоренности, в зависимости от объема.
Наши эксперты готовы ответить на любые вопросы, в любое время обращайтесь. принимаем usdt
Телега: @exrumer
Skype: Loves.ltd
w.w.w: https://xrumer.art
[url=https://www.grainloader.vn.ua]http://grainloader.vn.ua[/url]
Gold Chap Furnishings stores a range of characteristic corn loaders opportune for jobs of all shapes and sizes.
https://grainloader.vn.ua
http://pharmnoprescription.icu/# medicine with no prescription
india pharmacy mail order india online pharmacy reputable indian online pharmacy
cheapest pharmacy to get prescriptions filled
קנאביס כיוונים: המדריכים המלא לקניית קנאביסין על ידי המסר
קנאביס מדריך הוא אתר ווב מסמכים ומדריכים לסחר ב פרחי קנאביס דרך האפליקציה הנפוצה טלגרם.
האתר האינטרנט מספקת את כל המידע הקישורות והמידע המתעדף לקבוצות המשתמשים וערוצים הנבחרים מומלצות לקריאה לרכישת שרף בהמשלוח בארץ ישראל.
כמו לצד זאת, פורטל מספקת הדרכה מפורטים לכיצד ניתן להתקשר בטלגראס ולקנה שרף בקלות הזמנה ובמהירות מירבית.
בעזרת המדריך, כמו כן משתמשי חדשים יוכלו לעולם הקנאביס בהמסר בפניות מוגנת ומוגנת.
הבוט של השרף מאפשר למשתמשי ללבצע פעולה שונות כמו גם הפעלת קנאביס, קבלת הודעה תמיכה, בדיקת והוספת ביקורות על המצרים. כל זאת בפניות נוחה ופשוטה דרך האפליקציה.
כאשר כאשר נדבר באמצעים התשלומים, הקנאביס משתמשת בשיטות ה מוכרות כגון מזומנים, כרטיסי אשראי ומטבע דיגיטלי. חיוני להדגש כי יש לבדוק ולוודא את המדיניות והחוקים המקומיים באיזור שלך לפני ביצוע רכישה.
טלגרם מציע יתרונות מרכזיים חשובים כגון פרטיות וביטחון מוגברים, תקשורת מהירה וגמישות גבוהה. בנוסף, הוא מאפשר כניסה להקהל עולמית רחבה ומציע מגוון רחב של תכונות ויכולות.
בסיכום, טלגראס כיוונים היא האתר הטוב למצוא את כל הידע והקישורות לקניית שרף בפני מהירה, בבטוחה ונוחה דרך המסר.
geinoutime.com
Beriberi는 Zhang Queen이 항상 일부를 흡수 할 수있는 현미 죽을 더 많이 마실 수 있습니다.
lisinopril 10 mg cost
tvlore.com
그러나 이때 외부의 누군가가 말했다. “폐하, 폐하…급합니다.”
https://pharmworld.store/# canadian pharmacy coupon code
Большой выбор игрушек для взрослых с быстрой курьерской доставкой. Анонимная упаковка – запечатанный крафт пакет купить страпоны
medication from mexico pharmacy: buying prescription drugs in mexico online – buying prescription drugs in mexico online
mexican border pharmacies shipping to usa: medicine in mexico pharmacies – mexican drugstore online
Link building is just equally efficient at present, only the resources to work in this field have got altered.
There are actually numerous choices regarding backlinks, we employ several of them, and these strategies work and have already been tried by our experts and our customers.
Not long ago we performed an test and we found that low-frequency search queries from a single website rank well in search results, and this doesn’t require to become your domain name, you can use social networking sites from Web 2.0 series for this.
It additionally possible to partly shift load through site redirects, providing a diverse backlink profile.
Visit to our own website where our solutions are actually provided with thorough descriptions.
Индексация ссылок на сайте vindexe
zithromax uk
http://pharmcanada.shop/# canadian drug stores
BooiCasino download app https://booicasino-telegram.com/
Стоимость обучения на курсе английского для начинающих онлайн в 1,3-2,5 раза ниже стоимости группового обучения на языковых курсах, где ориентируются на группу, а не ваши индивидуальные потребности лучшие курсы по английскому языку онлайн
http://pharmcanada.shop/# canadian online pharmacy
lisinopril 250mg
https://zithromaxa.store/# zithromax 500 mg for sale
buy generic zithromax no prescription buy cheap generic zithromax where to get zithromax over the counter
zocor source – simvastatin surround lipitor sprawl
prednisone for dogs: prednisone 20 mg tablets coupon – prednisone cost us
synthroid 150 mcg tab
cost of amoxicillin: amoxil generic – amoxicillin cephalexin
best generic lisinopril
generic over the counter prednisone: prednisone 50 mg coupon – prednisone 2 5 mg
lisinopril online
https://gabapentinneurontin.pro/# buy gabapentin
Мощные и эффективные: генераторы пены ГПСС для вашего бизнеса. Повысьте уровень безопасности и гигиены с нашими генераторами пены ГПСС муфти для азс
Мощные и эффективные: генераторы пены ГПСС для вашего бизнеса. Повысьте уровень безопасности и гигиены с нашими генераторами пены ГПСС пожарный гидрант
gambling
amoxicillin tablets in india: amoxicillin pills 500 mg – amoxicillin without a prescription
В этой подборке онлайн-курсов по английскому языку мы сравнили предложения школ по нескольким параметрам и отобрали лучшие варианты для взрослых и детей, начинающих познание языка или повышающих свой уровень курсы онлайн английского языка с сертификатом
В этой подборке онлайн-курсов по английскому языку мы сравнили предложения школ по нескольким параметрам и отобрали лучшие варианты для взрослых и детей, начинающих познание языка или повышающих свой уровень курсы онлайн английский разговорный
buy generic neurontin online: buy generic neurontin online – neurontin 2400 mg
neurontin brand name 800mg: buy neurontin – neurontin 300 mg capsule
buy online pharmacy uk
https://service.gadgetufa.ru/remont-smartfonov/remont-avtomagnitol/
doxycycline medication: doxycycline 50mg – doxycycline vibramycin
https://zithromaxa.store/# average cost of generic zithromax
В этой подборке онлайн-курсов по английскому языку мы сравнили предложения школ по нескольким параметрам и отобрали лучшие варианты для взрослых и детей, начинающих познание языка или повышающих свой уровень курсы по английскому языку с нуля онлайн
В этой подборке онлайн-курсов по английскому языку мы сравнили предложения школ по нескольким параметрам и отобрали лучшие варианты для взрослых и детей, начинающих познание языка или повышающих свой уровень курсы переводчиков английского языка дистанционно
Инженерное ясс играет ключевую цена в течение сегодняшнем мире, снабжая материализация различных технических развивающаяся болезнь да производственных операций. Оно презентует собой широкий спектр промышленных конструкций и еще элементов, умышленно созданных для исполнения точных функций в течение технических континент и структурах.
Элитный тип инженерного оснащения заключает в течение себе автомашины (а) также машины, уготованные для исполненья разных походов, таких яко электрорезка, сверление, шлицефрезерование также так далее Этто может быть индустриальное ясс, применяемое на заводах (а) также в производственных предприятиях, а также специальное оборудование, прилагаемое в течение инженерных секторах экономики, этих как строительство, сельхозавиация, строительство да другие.
Следующий экстерьер технического оснастки вводит в течение себе замерные аппараты равно приспособления, требуемые для контролирования и разбора разных параметров в течение разбирательстве работы инженерных систем. Это могут составлять измерители температуры, давления, уровня, что-что также специальные принадлежности для измерения физических да химических величин https://prom-info01.ru/jeffektivnoe-upravlenie-goreniem-v-modeli-lmv51/.
Третий тип инженерного оснащения вводит в течение себя учения автоматизации а также управления, каковые используются для автоматизации производственных течений да подъема эффективности опуса инженерных систем. Семо смотрятся предрешаемые закономерные контроллеры (ПЛК), промышленные боты, способ организации управления энергопотреблением и еще другие.
Четвертый тип инженерного оборудования вливает в себе хлеб защиты и еще безопасности, неотложные для предоставления безопасности персонала равным образом оснащения в течение процессе работы. Этто смогут фигурировать способ организации пожаротушения, системы вентиляции и еще кондиционирования духа, что-что также средства личной охраны работников.
where can i buy amoxicillin over the counter: can you buy amoxicillin over the counter – amoxicillin 750 mg price
k8 カジノ レート
非常に有益で洞察に満ちた記事でした。
doxycycline generic buy generic doxycycline generic for doxycycline
можно ли разорвать контракт сво
С началом СВО уже спустя полгода была объявлена первая волна мобилизации. При этом прошлая, в последний раз в России была аж в 1941 году, с началом Великой Отечественной Войны. Конечно же, желающих отправиться на фронт было не много, а потому люди стали искать способы не попасть на СВО, для чего стали покупать справки о болезнях, с которыми можно получить категорию Д. И все это стало возможным с даркнет сайтами, где можно найти практически все что угодно. Именно об этой отрасли темного интернета подробней и поговорим в этой статье.
For most recent information you have to pay a visit world-wide-web and on internet I found this web site as a best web site for latest updates.
https://postheaven.net/samirigica/kupiti-original-ne-sklo-far-farfarlight-dlia-stil-nogo-ta-bezpechnogo-avtomobilia-vrfd
Please let me know if you’re looking for a article author for your blog. You have some really great posts and I believe I would be a good asset. If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for a link back to mine. Please shoot me an email if interested. Thanks!
https://justpin.date/story.php?title=SKLO-DLYA-FAR-STIL-%D1%96-BEZPEKA-VASHOGO-AVTOMOB%D1%96LYA#discuss
largestcatbreed.com
전하의 명령을 전달하러 온 내시는 류진이었다.
amoxicillin 500mg: amoxicillin 500mg without prescription – amoxicillin tablets in india
doxycycline 100mg dogs: doxycycline hyclate 100 mg cap – buy doxycycline hyclate 100mg without a rx
https://amoxila.pro/# amoxicillin 500mg
http://orangewhale.net/bbs/board.php?bo_table=free&wr_id=209313
tadalafil 2.5 mg online india
viagra professional online game – viagra gold justice levitra oral jelly practical
synthroid 5mg
order prednisone on line: buying prednisone without prescription – prednisone 30 mg
https://zithromaxa.store/# generic zithromax 500mg india
canadian pharmaceuticals online
safe canadian pharmacies
amoxicillin 500 mg tablets: where to buy amoxicillin over the counter – cheap amoxicillin 500mg
how to get zithromax over the counter how to get zithromax online where to get zithromax
synthroid 112 mcg india
https://doxycyclinea.online/# buy doxycycline without prescription uk
doxycycline 100mg price: doxycycline hyc 100mg – doxycycline 50mg
where can i buy zithromax uk zithromax for sale 500 mg cheap zithromax pills
generic amoxicillin: can i buy amoxicillin over the counter in australia – amoxicillin 500 mg cost
https://amoxila.pro/# amoxicillin online pharmacy
dysons-shop.ru [url=dyson-kupit.com]dyson официальный интернет магазин[/url] .
алкоголизм помощь https://addictiontreatment.kz/
generic for doxycycline: doxylin – doxycycline 100mg
https://frugallivin.com/
反向連結金字塔
G搜尋引擎在多番更新之后需要应用不同的排名參數。
今天有一種方法可以使用反向連結吸引G搜尋引擎對您的網站的注意。
反向連結不僅是有效的推廣工具,也是有機流量。
我們會得到什麼結果:
我們透過反向連結向G搜尋引擎展示我們的網站。
他們收到了到該網站的自然過渡,這也是向G搜尋引擎發出的信號,表明該資源正在被人們使用。
我們如何向G搜尋引擎表明該網站具有流動性:
個帶有主要訊息的主頁反向链接
我們透過來自受信任網站的重新定向來建立反向連接。
此外,我們將網站放置在单独的網路分析器上,網站最終會進入這些分析器的高速缓存中,然後我們使用產生的連結作為部落格、論壇和評論的重新定向。 這個重要的操作向G搜尋引擎顯示了網站地圖,因為網站分析器顯示了有關網站的所有資訊以及所有關鍵字和標題,這很棒
有關我們服務的所有資訊都在網站上!
buy lisinopril 20 mg online uk
Входные двери – купить по выгодной цене с доставкой. 1433 модели в проверенных интернет-магазинах: популярные новинки и лидеры продаж https://market-dverey.com/
amoxicillin 1000 mg capsule buy amoxicillin online with paypal amoxicillin 500mg
geinoutime.com
다음으로 자유롭게 할 수 있는 일이 많이 있을 것입니다.
amoxicillin online purchase: buy amoxicillin 250mg – amoxicillin price without insurance
http://prednisoned.online/# prednisone in india
where can i buy zithromax medicine: where can i buy zithromax capsules – purchase zithromax online
pharmacy canadian superstore
synthroid 75
875 mg amoxicillin cost amoxicillin 500mg prescription amoxicillin in india
prednisone 2.5 mg daily: prednisone for sale no prescription – prednisone over the counter cost
buy zithromax canada: zithromax online paypal – zithromax online pharmacy canada
В нашем обществе, где диплом – это начало отличной карьеры в любой области, многие пытаются найти максимально простой путь получения качественного образования. Необходимость наличия официального документа об образовании трудно переоценить. Ведь именно он открывает двери перед любым человеком, желающим вступить в профессиональное сообщество или учиться в университете.
Предлагаем максимально быстро получить этот необходимый документ. Вы имеете возможность приобрести диплом нового или старого образца, и это будет выгодным решением для человека, который не смог закончить образование, утратил документ или желает исправить свои оценки. диплом изготавливается с особой аккуратностью, вниманием ко всем элементам. В результате вы сможете получить продукт, 100% соответствующий оригиналу.
Плюсы такого решения заключаются не только в том, что можно оперативно получить диплом. Весь процесс организован комфортно, с профессиональной поддержкой. От выбора нужного образца до консультации по заполнению личной информации и доставки в любой регион страны — все будет находиться под полным контролем качественных специалистов.
Всем, кто ищет быстрый и простой способ получить требуемый документ, наша компания предлагает выгодное решение. Купить диплом – это значит избежать долгого обучения и не теряя времени перейти к достижению своих целей: к поступлению в ВУЗ или к началу удачной карьеры.
http://www.diplomanc-russia24.com
synthroid without a rx
https://amoxila.pro/# order amoxicillin uk
На сегодняшний день, когда диплом становится началом удачной карьеры в любом направлении, многие ищут максимально простой путь получения качественного образования. Наличие официального документа трудно переоценить. Ведь диплом открывает дверь перед людьми, желающими начать профессиональную деятельность или учиться в ВУЗе.
Наша компания предлагает оперативно получить любой необходимый документ. Вы можете купить диплом, что становится отличным решением для человека, который не смог закончить обучение, потерял документ или желает исправить плохие оценки. Любой диплом изготавливается аккуратно, с максимальным вниманием ко всем деталям, чтобы на выходе получился полностью оригинальный документ.
Превосходство подобного решения заключается не только в том, что вы сможете быстро получить диплом. Процесс организован удобно, с нашей поддержкой. Начав от выбора подходящего образца документа до точного заполнения персональной информации и доставки по стране — все под полным контролем опытных специалистов.
В итоге, для тех, кто ищет максимально быстрый способ получения требуемого документа, наша услуга предлагает выгодное решение. Купить диплом – значит избежать длительного процесса обучения и сразу переходить к личным целям, будь то поступление в университет или старт профессиональной карьеры.
http://www.diplom-net.ru
doxycycline 50 mg doxycycline 100mg price doxycycline tetracycline
amoxicillin cost australia: amoxicillin discount – amoxicillin capsules 250mg
k8 スポーツ ブック
非常に有意義な内容でした。また読みたいと思います。
cenforce lunch – brand viagra pills forehead
В современном мире, где диплом – это начало удачной карьеры в любом направлении, многие пытаются найти максимально быстрый и простой путь получения образования. Важность наличия документа об образовании переоценить невозможно. Ведь диплом открывает дверь перед людьми, стремящимися начать трудовую деятельность или продолжить обучение в каком-либо ВУЗе.
В данном контексте мы предлагаем быстро получить этот необходимый документ. Вы можете заказать диплом, и это является удачным решением для всех, кто не смог закончить обучение или потерял документ. дипломы производятся с особой тщательностью, вниманием ко всем элементам. В итоге вы сможете получить документ, максимально соответствующий оригиналу.
Преимущества данного решения заключаются не только в том, что можно оперативно получить диплом. Процесс организовывается комфортно, с нашей поддержкой. От выбора нужного образца документа до консультации по заполнению личных данных и доставки в любой регион России — все под абсолютным контролем качественных мастеров.
Для всех, кто хочет найти максимально быстрый способ получения требуемого документа, наша компания готова предложить выгодное решение. Приобрести диплом – значит избежать длительного обучения и не теряя времени перейти к достижению собственных целей: к поступлению в ВУЗ или к началу трудовой карьеры.
http://diplomvam.ru
Why visitors still make use of to read news papers when in this technological world everything is accessible on web?
https://motflix.cc/
даркнет сливы тг
Даркнет и сливы в Телеграме
Даркнет – это отрезок интернета, которая не индексируется регулярными поисковыми системами и требует специальных программных средств для доступа. В даркнете существует обилие скрытых сайтов, где можно найти различные товары и услуги, в том числе и нелегальные.
Одним из трендовых способов распространения информации в даркнете является использование мессенджера Телеграм. Телеграм предоставляет возможность создания закрытых каналов и чатов, где пользователи могут обмениваться информацией, в том числе и нелегальной.
Сливы информации в Телеграме – это практика распространения конфиденциальной информации, такой как украденные данные, базы данных, персональные сведения и другие материалы. Эти сливы могут включать в себя информацию о кредитных картах, паролях, персональных сообщениях и даже фотографиях.
Сливы в Телеграме могут быть рискованными, так как они могут привести к утечке конфиденциальной информации и нанести ущерб репутации и финансовым интересам людей. Поэтому важно быть предусмотрительным при обмене информацией в интернете и не доверять сомнительным источникам.
Вот кошельки с балансом у бота
Слив посеянных фраз (seed phrases) является одним наиболее популярных способов утечки личных информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, почему они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, являются комбинацию слов, которая используется для формирования или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые отражают собой ключ к вашему кошельку. Потеря или утечка сид фразы может приводить к потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы представляют ключевым элементом для секурного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они будут в состоянии получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу никакому, даже если вам происходит, что это проверенное лицо или сервис.
Храните свою сид фразу в секурном и защищенном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двухфакторная верификация, для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в различных безопасных местах.
Заключение
Слив сид фраз является серьезной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
amoxicillin capsule 500mg price: amoxicillin 500mg price – antibiotic amoxicillin
лечение больных алкоголизмом https://narcolog1.kz/
В нашем мире, где диплом становится началом удачной карьеры в любом направлении, многие пытаются найти максимально простой путь получения образования. Наличие официального документа об образовании сложно переоценить. Ведь именно диплом открывает двери перед всеми, кто желает начать трудовую деятельность или продолжить обучение в ВУЗе.
Предлагаем быстро получить этот важный документ. Вы можете купить диплом старого или нового образца, что становится отличным решением для человека, который не смог закончить обучение или потерял документ. Все дипломы изготавливаются с особой тщательностью, вниманием к мельчайшим элементам. В результате вы сможете получить 100% оригинальный документ.
Плюсы подобного решения заключаются не только в том, что можно быстро получить свой диплом. Процесс организован удобно и легко, с профессиональной поддержкой. От выбора нужного образца до консультации по заполнению персональной информации и доставки по России — все под полным контролем качественных мастеров.
Всем, кто ищет максимально быстрый способ получения необходимого документа, наша компания предлагает выгодное решение. Приобрести диплом – это значит избежать продолжительного обучения и не теряя времени перейти к важным целям: к поступлению в университет или к началу трудовой карьеры.
http://diplomany.ru/
https://satbayev.university/
https://zithromaxa.store/# zithromax prescription online
В современном мире, где диплом – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый путь получения качественного образования. Наличие официального документа об образовании сложно переоценить. Ведь диплом открывает двери перед каждым человеком, желающим вступить в профессиональное сообщество или учиться в любом институте.
В данном контексте мы предлагаем быстро получить этот необходимый документ. Вы можете заказать диплом, что является выгодным решением для всех, кто не смог закончить обучение или утратил документ. Любой диплом изготавливается аккуратно, с максимальным вниманием ко всем элементам. В результате вы сможете получить продукт, максимально соответствующий оригиналу.
Преимущество этого решения заключается не только в том, что вы сможете максимально быстро получить диплом. Весь процесс организован комфортно, с профессиональной поддержкой. От выбора необходимого образца документа до консультаций по заполнению персональной информации и доставки по стране — все будет находиться под полным контролем опытных мастеров.
Для всех, кто ищет быстрый и простой способ получения необходимого документа, наша компания готова предложить отличное решение. Заказать диплом – значит избежать длительного процесса обучения и сразу переходить к достижению своих целей: к поступлению в ВУЗ или к началу трудовой карьеры.
http://vsediplomu.ru
Player線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
Player如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
www canadapharmacy com
взлом кошелька
Как сберечь свои данные: страхуйтесь от утечек информации в интернете. Сегодня защита информации становится всё более важной задачей. Одним из наиболее часто встречающихся способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в каком объеме сберечься от их утечки? Что такое «сит фразы»? «Сит фразы» — это сочетания слов или фраз, которые часто используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или дополнительные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, с помощью этих сит фраз. Как обезопасить свои личные данные? Используйте непростые пароли. Избегайте использования очевидных паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из вашего аккаунта. Не применяйте один и тот же пароль для разных сервисов. Используйте двухфакторную проверку (2FA). Это прибавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт посредством другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы защитить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может привести к серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
Криптокошельки с балансом: зачем их покупают и как использовать
В мире криптовалют все большую популярность приобретают криптокошельки с предустановленным балансом. Это индивидуальные кошельки, которые уже содержат определенное количество криптовалюты на момент покупки. Но зачем люди приобретают такие кошельки, и как правильно использовать их?
Почему покупают криптокошельки с балансом?
Удобство: Криптокошельки с предустановленным балансом предлагаются как готовое к применению решение для тех, кто хочет быстро начать пользоваться криптовалютой без необходимости покупки или обмена на бирже.
Подарок или награда: Иногда криптокошельки с балансом используются как подарок или награда в рамках акций или маркетинговых кампаний.
Анонимность: При покупке криптокошелька с балансом нет потребности предоставлять личные данные, что может быть важно для тех, кто ценит анонимность.
Как использовать криптокошелек с балансом?
Проверьте безопасность: Убедитесь, что кошелек безопасен и не подвержен взлому. Проверьте репутацию продавца и источник приобретения кошелька.
Переведите средства на другой кошелек: Если вы хотите долгосрочно хранить криптовалюту, рекомендуется перевести средства на более безопасный или удобный для вас кошелек.
Не храните все средства на одном кошельке: Для обеспечения безопасности рекомендуется распределить средства между несколькими кошельками.
Будьте осторожны с фишингом и мошенничеством: Помните, что мошенники могут пытаться обмануть вас, предлагая криптокошельки с балансом с целью получения доступа к вашим средствам.
Заключение
Криптокошельки с балансом могут быть удобным и быстрым способом начать пользоваться криптовалютой, но необходимо помнить о безопасности и осторожности при их использовании.Выбор и приобретение криптокошелька с балансом – это весомый шаг, который требует внимания к деталям и осознанного подхода.”
слив сид фраз
Слив сид фраз (seed phrases) является одной из наиболее распространенных способов утечки личной информации в мире криптовалют. В этой статье мы разберем, что такое сид фразы, почему они важны и как можно защититься от их утечки.
Что такое сид фразы?
Сид фразы, или мнемонические фразы, представляют собой комбинацию слов, которая используется для формирования или восстановления кошелька криптовалюты. Обычно сид фраза состоит из 12 или 24 слов, которые являются собой ключ к вашему кошельку. Потеря или утечка сид фразы может влечь за собой потере доступа к вашим криптовалютным средствам.
Почему важно защищать сид фразы?
Сид фразы являются ключевым элементом для безопасного хранения криптовалюты. Если злоумышленники получат доступ к вашей сид фразе, они будут в состоянии получить доступ к вашему кошельку и украсть все средства.
Как защититься от утечки сид фраз?
Никогда не передавайте свою сид фразу никому, даже если вам представляется, что это авторизованное лицо или сервис.
Храните свою сид фразу в защищенном и защищенном месте. Рекомендуется использовать аппаратные кошельки или специальные программы для хранения сид фразы.
Используйте дополнительные методы защиты, такие как двусторонняя аутентификация, для усиления безопасности вашего кошелька.
Регулярно делайте резервные копии своей сид фразы и храните их в разнообразных безопасных местах.
Заключение
Слив сид фраз является важной угрозой для безопасности владельцев криптовалют. Понимание важности защиты сид фразы и принятие соответствующих мер безопасности помогут вам избежать потери ваших криптовалютных средств. Будьте бдительны и обеспечивайте надежную защиту своей сид фразы
zithromax for sale online generic zithromax 500mg india zithromax cost canada
where to get doxycycline: how to buy doxycycline online – doxycycline 100mg dogs
Сегодня, когда диплом – это начало успешной карьеры в любой отрасли, многие стараются найти максимально простой путь получения качественного образования. Необходимость наличия документа об образовании трудно переоценить. Ведь диплом открывает дверь перед каждым человеком, желающим начать трудовую деятельность или продолжить обучение в высшем учебном заведении.
Предлагаем очень быстро получить этот важный документ. Вы можете приобрести диплом старого или нового образца, что будет отличным решением для человека, который не смог завершить образование, утратил документ или желает исправить плохие оценки. Каждый диплом изготавливается аккуратно, с особым вниманием к мельчайшим элементам. В итоге вы сможете получить документ, максимально соответствующий оригиналу.
Преимущества такого решения заключаются не только в том, что вы оперативно получите диплом. Процесс организован удобно, с нашей поддержкой. Начав от выбора нужного образца диплома до консультаций по заполнению личных данных и доставки по России — все под полным контролем наших специалистов.
Для тех, кто ищет оперативный способ получения необходимого документа, наша компания предлагает отличное решение. Купить диплом – это значит избежать продолжительного процесса обучения и сразу переходить к важным целям, будь то поступление в ВУЗ или старт трудовой карьеры.
ab-diplom.ru
average cost of generic zithromax zithromax cost zithromax over the counter canada
brand cialis utmost – tadora stair penisole rattle
В нашем обществе, где диплом является началом успешной карьеры в любой области, многие стараются найти максимально быстрый путь получения качественного образования. Наличие официального документа сложно переоценить. Ведь именно он открывает дверь перед людьми, желающими начать трудовую деятельность или учиться в ВУЗе.
В данном контексте мы предлагаем оперативно получить этот важный документ. Вы сможете купить диплом, и это становится удачным решением для всех, кто не смог завершить обучение, утратил документ или желает исправить свои оценки. диплом изготавливается аккуратно, с максимальным вниманием ко всем нюансам. В результате вы сможете получить документ, максимально соответствующий оригиналу.
Преимущества этого решения состоят не только в том, что вы сможете оперативно получить свой диплом. Весь процесс организован удобно, с профессиональной поддержкой. Начав от выбора подходящего образца до консультаций по заполнению персональных данных и доставки в любой регион России — все находится под полным контролем наших мастеров.
Всем, кто пытается найти быстрый и простой способ получения необходимого документа, наша компания предлагает выгодное решение. Приобрести диплом – это значит избежать длительного обучения и сразу перейти к достижению собственных целей: к поступлению в ВУЗ или к началу удачной карьеры.
http://diplomexpress.ru
doxycycline pills: order doxycycline 100mg without prescription – doxycycline 50mg
В наше время, когда диплом – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый путь получения образования. Наличие документа об образовании трудно переоценить. Ведь диплом открывает двери перед любым человеком, который желает начать профессиональную деятельность или учиться в ВУЗе.
Мы предлагаем максимально быстро получить этот важный документ. Вы имеете возможность приобрести диплом, что является выгодным решением для всех, кто не смог завершить образование или утратил документ. дипломы изготавливаются аккуратно, с особым вниманием ко всем элементам. В результате вы сможете получить продукт, 100% соответствующий оригиналу.
Плюсы данного решения состоят не только в том, что вы максимально быстро получите свой диплом. Процесс организовывается просто и легко, с нашей поддержкой. Начиная от выбора требуемого образца до консультации по заполнению персональных данных и доставки по стране — все будет находиться под абсолютным контролем опытных мастеров.
Всем, кто пытается найти быстрый способ получения необходимого документа, наша компания предлагает отличное решение. Заказать диплом – это значит избежать продолжительного процесса обучения и не теряя времени переходить к достижению личных целей: к поступлению в университет или к началу удачной карьеры.
http://99diplomov.ru
Сегодня, когда диплом – это начало удачной карьеры в любой сфере, многие ищут максимально быстрый путь получения качественного образования. Факт наличия документа об образовании сложно переоценить. Ведь именно диплом открывает двери перед каждым человеком, желающим начать профессиональную деятельность или продолжить обучение в высшем учебном заведении.
Предлагаем оперативно получить этот важный документ. Вы можете заказать диплом старого или нового образца, и это будет выгодным решением для человека, который не смог завершить образование или потерял документ. дипломы изготавливаются с особой аккуратностью, вниманием ко всем нюансам, чтобы в результате получился продукт, 100% соответствующий оригиналу.
Преимущества данного подхода состоят не только в том, что вы сможете оперативно получить свой диплом. Весь процесс организовывается удобно, с нашей поддержкой. От выбора нужного образца документа до точного заполнения личных данных и доставки по стране — все под полным контролем качественных мастеров.
Всем, кто ищет быстрый способ получения требуемого документа, наша услуга предлагает выгодное решение. Купить диплом – значит избежать долгого обучения и сразу перейти к личным целям, будь то поступление в университет или старт профессиональной карьеры.
ab-diplom.ru
ליווי בתל אביב עשוי לתת לנו להבין יותר על דירות דיסקרטיות בחיפה ועבודת מין, זוהר או רומנטיזציה של התעשיית דירות דיסקרטיות באשקלון לפגישה אינטימית תמורת כסף משתנות מתחום לתחום. במקומות מסוימים, דירות דיסקרטיות בחיפה נחשבות צורה לגיטימית של טיפול או מכוני ליווי בבאר שבע התענוג שבדברים הקטנים
mexico drug stores pharmacies: reputable mexican pharmacies online – mexican pharmaceuticals online
mexican pharmaceuticals online: mexican rx online – buying prescription drugs in mexico online
mexico drug stores pharmacies buying prescription drugs in mexico mexican border pharmacies shipping to usa
В нашем обществе, где диплом становится началом удачной карьеры в любом направлении, многие пытаются найти максимально быстрый и простой путь получения качественного образования. Наличие документа об образовании сложно переоценить. Ведь именно он открывает двери перед всеми, кто хочет начать трудовую деятельность или продолжить обучение в университете.
Наша компания предлагает очень быстро получить этот важный документ. Вы можете купить диплом старого или нового образца, и это является отличным решением для всех, кто не смог закончить обучение, утратил документ или желает исправить свои оценки. дипломы выпускаются аккуратно, с особым вниманием ко всем нюансам. В итоге вы сможете получить продукт, максимально соответствующий оригиналу.
Преимущества такого подхода состоят не только в том, что можно оперативно получить диплом. Процесс организован удобно, с нашей поддержкой. Начиная от выбора требуемого образца до консультаций по заполнению личных данных и доставки по России — все под абсолютным контролем наших специалистов.
В результате, для всех, кто пытается найти быстрый способ получения требуемого документа, наша компания предлагает отличное решение. Купить диплом – это значит избежать длительного обучения и сразу переходить к достижению личных целей, будь то поступление в ВУЗ или старт карьеры.
https://diplom-msk.ru/
В нашем мире, где диплом становится началом отличной карьеры в любом направлении, многие стараются найти максимально простой путь получения образования. Наличие документа об образовании сложно переоценить. Ведь диплом открывает дверь перед каждым человеком, который стремится начать профессиональную деятельность или учиться в любом институте.
Наша компания предлагает очень быстро получить этот необходимый документ. Вы сможете купить диплом нового или старого образца, и это будет выгодным решением для всех, кто не смог завершить обучение, потерял документ или желает исправить плохие оценки. дипломы производятся аккуратно, с особым вниманием ко всем деталям, чтобы в итоге получился 100% оригинальный документ.
Плюсы этого решения состоят не только в том, что можно оперативно получить диплом. Весь процесс организован комфортно и легко, с профессиональной поддержкой. От выбора необходимого образца диплома до грамотного заполнения персональной информации и доставки по России — все будет находиться под полным контролем качественных мастеров.
Таким образом, для тех, кто ищет максимально быстрый способ получить требуемый документ, наша услуга предлагает выгодное решение. Купить диплом – это значит избежать продолжительного обучения и сразу перейти к своим целям, будь то поступление в университет или старт карьеры.
http://www.diplom-gotovie.ru
https://mexicanpharmacy1st.shop/# best online pharmacies in mexico
ונקודות מבט מגוונות. דירות דיסקרטיות באשדוד ויחסים אינטימיים למין של דירות דיסקרטיות בירושלים תפקיד מרכזי במערכות יחסים אינטימיות וחקירה חושנית בתמורה לפיצוי כספי. גם שירותי נערות ליווי באילת וגם שירותי דירות דיסקרטיות בבאר שבע מציעים חוויות נערות ליווי בקריות
https://mexicanpharmacy1st.online/# medicine in mexico pharmacies
What a stuff of un-ambiguity and preserveness of valuable know-how concerning unpredicted emotions.
http://diplom07.ru
prednisone tablets cost
https://mexicanpharmacy1st.online/# buying prescription drugs in mexico
best india tadalafil online
п»їbest mexican online pharmacies: mexican drugstore online – reputable mexican pharmacies online
видеостена купить москва [url=https://videosteny14.ru/]https://videosteny14.ru/[/url] .
https://subscribe.ru/group/divnyij-mir/18561937/
https://nashikolesa.ru/avtosovety/gos-nomera-na-spectehniku
best mexican online pharmacies: mexico pharmacies prescription drugs – pharmacies in mexico that ship to usa
mexican border pharmacies shipping to usa medicine in mexico pharmacies medication from mexico pharmacy
https://mexicanpharmacy1st.online/# mexico pharmacy
В современном мире, где диплом – это начало отличной карьеры в любой сфере, многие ищут максимально быстрый и простой путь получения качественного образования. Факт наличия официального документа переоценить попросту невозможно. Ведь именно он открывает двери перед каждым человеком, который собирается вступить в профессиональное сообщество или учиться в каком-либо институте.
В данном контексте наша компания предлагает быстро получить этот важный документ. Вы сможете заказать диплом нового или старого образца, что является выгодным решением для всех, кто не смог завершить образование, потерял документ или хочет исправить свои оценки. Каждый диплом изготавливается с особой тщательностью, вниманием к мельчайшим нюансам, чтобы в итоге получился полностью оригинальный документ.
Превосходство этого решения состоит не только в том, что вы быстро получите свой диплом. Процесс организовывается комфортно, с нашей поддержкой. Начав от выбора нужного образца до грамотного заполнения личной информации и доставки по России — все находится под абсолютным контролем качественных мастеров.
В итоге, для тех, кто хочет найти максимально быстрый способ получения необходимого документа, наша компания предлагает отличное решение. Купить диплом – это значит избежать долгого процесса обучения и не теряя времени перейти к достижению личных целей: к поступлению в ВУЗ или к началу удачной карьеры.
http://saksx-attestats.ru
synthroid 50 mg
lisinopril 90 pills cost
https://nashikolesa.ru/avtosovety/gos-nomera-na-spectehniku
pharmacies in mexico that ship to usa mexican rx online mexico drug stores pharmacies
https://mexicanpharmacy1st.shop/# mexico pharmacies prescription drugs
geinoutime.com
Hongzhi 황제는 분명히이 프로젝트에 매우 만족했습니다.
synthroid online canada
חברתיים וציפיות לא מציאותיות על דירות דיסקרטיות בתל אביב. נערות ליווי באילת דירות דיסקרטיות באשדוד לסקס ותשוקה הם היבטים אמונות דתיות, במיוחד היהדות, משפיעות באופן משמעותי על הגישות כלפי נערות ליווי בתל אביב, מין ומערכות יחסים בישראל. תורות יהודיות נערות ליווי באשדוד
zestoretic cost
והתנהגויותיהם. נורמות וציפיות מגדריות מסורתיות עשויות ללחוץ על גברים להתאים את עצמם לאידיאלים מסוימים של דירות דיסקרטיות בבאר שבע. לקוחות רבים מדווחים על תחושת נינוחות, התחדשות והגשמה רגשית לאחר פגישה עם נערות ליווי באילת, וחווים תחושת חיוניות The best escort girls show sexuality
k8 ミニゲーム
読んで良かったと心から思える素晴らしい記事でした。
pharmacies in mexico that ship to usa mexican mail order pharmacies best online pharmacies in mexico
http://mexicanpharmacy1st.com/# mexican drugstore online
buying from online mexican pharmacy: best online pharmacies in mexico – pharmacies in mexico that ship to usa
brand cialis emerge – penisole glisten penisole reflect
zanetvize.com
“세상에는 지식이 너무 많아서 위아래로 찾아봤지만 뭐가 뭔지 모르겠어.”
https://mexicanpharmacy1st.com/# mexico drug stores pharmacies
mexico drug stores pharmacies pharmacies in mexico that ship to usa buying from online mexican pharmacy
https://mexicanpharmacy1st.online/# mexico drug stores pharmacies
buying prescription drugs in mexico: buying prescription drugs in mexico online – mexico drug stores pharmacies
happy family pharmacy coupon code
http://mexicanpharmacy1st.com/# mexican border pharmacies shipping to usa
buying prescription drugs in mexico online п»їbest mexican online pharmacies best online pharmacies in mexico
mexico pharmacies prescription drugs: medicine in mexico pharmacies – medication from mexico pharmacy
https://mexicanpharmacy1st.shop/# mexican border pharmacies shipping to usa
mexico pharmacy mexico drug stores pharmacies п»їbest mexican online pharmacies
valtre
big pharmacy online
http://lisinopril.club/# lisinopril 10mg daily
https://maxbetasia88.net
buy cheap propecia pill buying generic propecia pills generic propecia no prescription
купить сварочный стол 3d от производителя [url=https://jetstanki.ru/]купить сварочный стол 3d от производителя[/url] .
https://cytotec.xyz/# Misoprostol 200 mg buy online
https://1win-cazino-online.ru/
veganchoicecbd.com
황제의 칙령을 기다리는 모든 한린들은 어쩔 수 없이 지유양을 부러워하며 바라볼 수밖에 없었다.
https://mlgtesturamdtestv33.ru/
https://maxbetasia88.net
order lisinopril online us: lisinopril – lisinopril cost uk
lyrica 75 mg price in canada
neurontin gel: cheap neurontin online – neurontin 150mg
В нашем обществе, где диплом – это начало отличной карьеры в любом направлении, многие ищут максимально быстрый и простой путь получения качественного образования. Наличие документа об образовании трудно переоценить. Ведь именно он открывает двери перед людьми, желающими вступить в профессиональное сообщество или продолжить обучение в любом ВУЗе.
В данном контексте мы предлагаем быстро получить этот необходимый документ. Вы сможете купить диплом, что будет удачным решением для человека, который не смог закончить образование, потерял документ или желает исправить свои оценки. дипломы изготавливаются аккуратно, с особым вниманием ко всем нюансам, чтобы на выходе получился документ, полностью соответствующий оригиналу.
Превосходство этого решения состоит не только в том, что вы быстро получите диплом. Процесс организовывается удобно, с профессиональной поддержкой. Начав от выбора необходимого образца до правильного заполнения личных данных и доставки в любое место России — все под абсолютным контролем опытных мастеров.
Для тех, кто ищет максимально быстрый способ получить требуемый документ, наша компания предлагает выгодное решение. Приобрести диплом – значит избежать долгого обучения и не теряя времени перейти к своим целям: к поступлению в университет или к началу удачной карьеры.
diploman-russia.ru
https://clomiphene.shop/# get cheap clomid for sale
can i get clomid without insurance: where can i get generic clomid pills – can you get generic clomid online
RGBET
Cá Cược Thể Thao Trực Tuyến RGBET
Thể thao trực tuyến RGBET cung cấp thông tin cá cược thể thao mới nhất, như tỷ số bóng đá, bóng rổ, livestream và dữ liệu trận đấu. Đến với RGBET, bạn có thể tham gia chơi tại sảnh thể thao SABA, PANDA SPORT, CMD368, WG và SBO. Khám phá ngay!
Giới Thiệu Sảnh Cá Cược Thể Thao Trực Tuyến
Những sự kiện thể thao đa dạng, phủ sóng toàn cầu và cách chơi đa dạng mang đến cho người chơi tỷ lệ cá cược thể thao hấp dẫn nhất, tạo nên trải nghiệm cá cược thú vị và thoải mái.
Sảnh Thể Thao SBOBET
SBOBET, thành lập từ năm 1998, đã nhận được giấy phép cờ bạc trực tuyến từ Philippines, Đảo Man và Ireland. Tính đến nay, họ đã trở thành nhà tài trợ cho nhiều CLB bóng đá. Hiện tại, SBOBET đang hoạt động trên nhiều nền tảng trò chơi trực tuyến khắp thế giới.
Xem Chi Tiết »
Sảnh Thể Thao SABA
Saba Sports (SABA) thành lập từ năm 2008, tập trung vào nhiều hoạt động thể thao phổ biến để tạo ra nền tảng thể thao chuyên nghiệp và hoàn thiện. SABA được cấp phép IOM hợp pháp từ Anh và mang đến hơn 5.000 giải đấu thể thao đa dạng mỗi tháng.
Xem Chi Tiết »
Sảnh Thể Thao CMD368
CMD368 nổi bật với những ưu thế cạnh tranh, như cung cấp cho người chơi hơn 20.000 trận đấu hàng tháng, đến từ 50 môn thể thao khác nhau, đáp ứng nhu cầu của tất cả các fan hâm mộ thể thao, cũng như thoả mãn mọi sở thích của người chơi.
Xem Chi Tiết »
Sảnh Thể Thao PANDA SPORT
OB Sports đã chính thức đổi tên thành “Panda Sports”, một thương hiệu lớn với hơn 30 giải đấu bóng. Panda Sports đặc biệt chú trọng vào tính năng cá cược thể thao, như chức năng “đặt cược sớm và đặt cược trực tiếp tại livestream” độc quyền.
Xem Chi Tiết »
Sảnh Thể Thao WG
WG Sports tập trung vào những môn thể thao không quá được yêu thích, với tỷ lệ cược cao và xử lý đơn cược nhanh chóng. Đặc biệt, nhiều nhà cái hàng đầu trên thị trường cũng hợp tác với họ, trở thành là một trong những sảnh thể thao nổi tiếng trên toàn cầu.
Xem Chi Tiết »
https://zamkiexpress.ru/
Отправляйтесь в захватывающее путешествие по Калининграду и его окрестностям под руководством опытных гидов. Наши экскурсии позволят вам ощутить дух истории, проникнуться красотой природы и открыть для себя удивительные культурные достопримечательности. https://mykaliningradgid.ru/
neurontin drug: neurontin canada – neurontin price
nolvadex pharmacy
Euro
UEFA Euro 2024 Sân Chơi Bóng Đá Hấp Dẫn Nhất Của Châu Âu
Euro 2024 là sự kiện bóng đá lớn nhất của châu Âu, không chỉ là một giải đấu mà còn là một cơ hội để các quốc gia thể hiện tài năng, sự đoàn kết và tinh thần cạnh tranh.
Euro 2024 hứa hẹn sẽ mang lại những trận cầu đỉnh cao và kịch tính cho người hâm mộ trên khắp thế giới. Cùng tìm hiểu các thêm thông tin hấp dẫn về giải đấu này tại bài viết dưới đây, gồm:
Nước chủ nhà
Đội tuyển tham dự
Thể thức thi đấu
Thời gian diễn ra
Sân vận động
Euro 2024 sẽ được tổ chức tại Đức, một quốc gia có truyền thống vàng của bóng đá châu Âu.
Đức là một đất nước giàu có lịch sử bóng đá với nhiều thành công quốc tế và trong những năm gần đây, họ đã thể hiện sức mạnh của mình ở cả mặt trận quốc tế và câu lạc bộ.
Việc tổ chức Euro 2024 tại Đức không chỉ là một cơ hội để thể hiện năng lực tổ chức tuyệt vời mà còn là một dịp để giới thiệu văn hóa và sức mạnh thể thao của quốc gia này.
Đội tuyển tham dự giải đấu Euro 2024
Euro 2024 sẽ quy tụ 24 đội tuyển hàng đầu từ châu Âu. Các đội tuyển này sẽ là những đại diện cho sự đa dạng văn hóa và phong cách chơi bóng đá trên khắp châu lục.
Các đội tuyển hàng đầu như Đức, Pháp, Tây Ban Nha, Bỉ, Italy, Anh và Hà Lan sẽ là những ứng viên nặng ký cho chức vô địch.
Trong khi đó, các đội tuyển nhỏ hơn như Iceland, Wales hay Áo cũng sẽ mang đến những bất ngờ và thách thức cho các đối thủ.
Các đội tuyển tham dự được chia thành 6 bảng đấu, gồm:
Bảng A: Đức, Scotland, Hungary và Thuỵ Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý và Albania
Bảng C: Slovenia, Đan Mạch, Serbia và Anh
Bảng D: Ba Lan, Hà Lan, Áo và Pháp
Bảng E: Bỉ, Slovakia, Romania và Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha và Cộng hoà Séc
외국선물의 개시 골드리치와 동참하세요.
골드리치증권는 오랜기간 투자자분들과 함께 선물시장의 행로을 함께 여정을했습니다, 회원님들의 보장된 투자 및 건강한 수익성을 향해 항상 전력을 기울이고 있습니다.
어째서 20,000+인 이상이 골드리치와 함께할까요?
즉각적인 서비스: 쉽고 빠른 프로세스를 갖추어 어느누구라도 용이하게 사용할 수 있습니다.
안전 프로토콜: 국가기관에서 사용하는 상위 등급의 보안시스템을 채택하고 있습니다.
스마트 인가: 모든 거래데이터은 부호화 처리되어 본인 외에는 그 누구도 정보를 열람할 수 없습니다.
보장된 이익률 마련: 위험 요소를 감소시켜, 보다 더 보장된 수익률을 공개하며 그에 따른 리포트를 제공합니다.
24 / 7 지속적인 고객지원: 365일 24시간 신속한 상담을 통해 투자자분들을 모두 지원합니다.
함께하는 파트너사: 골드리치는 공기업은 물론 금융기관들 및 다양한 협력사와 함께 동행해오고.
외국선물이란?
다양한 정보를 확인하세요.
외국선물은 국외에서 거래되는 파생금융상품 중 하나로, 명시된 기초자산(예시: 주식, 화폐, 상품 등)을 바탕로 한 옵션계약 약정을 말합니다. 본질적으로 옵션은 명시된 기초자산을 향후의 어떤 시기에 일정 가격에 사거나 매도할 수 있는 자격을 제공합니다. 해외선물옵션은 이러한 옵션 계약이 국외 시장에서 거래되는 것을 의미합니다.
국외선물은 크게 콜 옵션과 풋 옵션으로 구분됩니다. 콜 옵션은 지정된 기초자산을 미래에 정해진 가격에 매수하는 권리를 허락하는 반면, 매도 옵션은 지정된 기초자산을 미래에 일정 가격에 매도할 수 있는 권리를 허락합니다.
옵션 계약에서는 미래의 명시된 일자에 (만기일이라 지칭되는) 일정 가격에 기초자산을 사거나 매도할 수 있는 권리를 보유하고 있습니다. 이러한 금액을 행사 가격이라고 하며, 종료일에는 해당 권리를 실행할지 여부를 결정할 수 있습니다. 따라서 옵션 계약은 거래자에게 미래의 가격 변화에 대한 안전장치나 이익 창출의 기회를 제공합니다.
해외선물은 시장 참가자들에게 다양한 투자 및 매매거래 기회를 제공, 환율, 상품, 주식 등 다양한 자산유형에 대한 옵션 계약을 망라할 수 있습니다. 거래자는 매도 옵션을 통해 기초자산의 낙폭에 대한 안전장치를 받을 수 있고, 콜 옵션을 통해 활황에서의 이익을 겨냥할 수 있습니다.
해외선물 거래의 원리
행사 금액(Exercise Price): 외국선물에서 실행 금액은 옵션 계약에 따라 특정한 가격으로 약정됩니다. 만기일에 이 금액을 기준으로 옵션을 실현할 수 있습니다.
만기일(Expiration Date): 옵션 계약의 만료일은 옵션의 실행이 허용되지않는 마지막 날짜를 의미합니다. 이 일자 다음에는 옵션 계약이 소멸되며, 더 이상 거래할 수 없습니다.
매도 옵션(Put Option)과 콜 옵션(Call Option): 매도 옵션은 기초자산을 지정된 금액에 팔 수 있는 권리를 허락하며, 콜 옵션은 기초자산을 명시된 금액에 매수하는 권리를 부여합니다.
프리미엄(Premium): 국외선물 거래에서는 옵션 계약에 대한 옵션료을 지불해야 합니다. 이는 옵션 계약에 대한 가격으로, 시장에서의 수요와 공급에 따라 변경됩니다.
행사 방안(Exercise Strategy): 거래자는 종료일에 옵션을 실행할지 여부를 판단할 수 있습니다. 이는 시장 상황 및 거래 플랜에 따라 차이가있으며, 옵션 계약의 수익을 최대화하거나 손실을 최소화하기 위해 선택됩니다.
시장 리스크(Market Risk): 외국선물 거래는 시장의 변화추이에 작용을 받습니다. 가격 변동이 예상치 못한 진로으로 일어날 경우 손해이 발생할 수 있으며, 이러한 마켓 리스크를 축소하기 위해 투자자는 계획을 수립하고 투자를 설계해야 합니다.
골드리치증권와 동반하는 외국선물은 안전하고 믿을만한 수 있는 운용을 위한 최적의 선택입니다. 투자자분들의 투자를 뒷받침하고 가이드하기 위해 우리는 최선을 다하고 있습니다. 함께 더 나은 미래를 향해 계속해나가세요.
buy cytotec Misoprostol 200 mg buy online Abortion pills online
Чугунные гири на girya-sportivnaya.ru – это безопасные снаряды, используемые в силовых программах для улучшения силы и выносливости. Способствуют повышению качества жизни. Имеют удобную ручку, позволяющую выполнять тяги, свинги, выпады, скручивания и другие упражнения в гиревом спорте.
В выпуске качественных отягощений применяется лучшая марка чугуна.
Большой набор продуктов дает возможность приобрести отягощения для эффективной программы занятий.
Завод из России реализует чугунные гири по приятным ценам.
http://lisinopril.club/# lisinopril 5 mg price in india
can i buy lisinopril over the counter in mexico lisinopril 20mg india price of lisinopril 5mg
cialis soft tabs online train – levitra soft pressure viagra oral jelly claw
http://propeciaf.online/# generic propecia without rx
UEFA Euro 2024 Sân Chơi Bóng Đá Hấp Dẫn Nhất Của Châu Âu
Euro 2024 là sự kiện bóng đá lớn nhất của châu Âu, không chỉ là một giải đấu mà còn là một cơ hội để các quốc gia thể hiện tài năng, sự đoàn kết và tinh thần cạnh tranh.
Euro 2024 hứa hẹn sẽ mang lại những trận cầu đỉnh cao và kịch tính cho người hâm mộ trên khắp thế giới. Cùng tìm hiểu các thêm thông tin hấp dẫn về giải đấu này tại bài viết dưới đây, gồm:
Nước chủ nhà
Đội tuyển tham dự
Thể thức thi đấu
Thời gian diễn ra
Sân vận động
Euro 2024 sẽ được tổ chức tại Đức, một quốc gia có truyền thống vàng của bóng đá châu Âu.
Đức là một đất nước giàu có lịch sử bóng đá với nhiều thành công quốc tế và trong những năm gần đây, họ đã thể hiện sức mạnh của mình ở cả mặt trận quốc tế và câu lạc bộ.
Việc tổ chức Euro 2024 tại Đức không chỉ là một cơ hội để thể hiện năng lực tổ chức tuyệt vời mà còn là một dịp để giới thiệu văn hóa và sức mạnh thể thao của quốc gia này.
Đội tuyển tham dự giải đấu Euro 2024
Euro 2024 sẽ quy tụ 24 đội tuyển hàng đầu từ châu Âu. Các đội tuyển này sẽ là những đại diện cho sự đa dạng văn hóa và phong cách chơi bóng đá trên khắp châu lục.
Các đội tuyển hàng đầu như Đức, Pháp, Tây Ban Nha, Bỉ, Italy, Anh và Hà Lan sẽ là những ứng viên nặng ký cho chức vô địch.
Trong khi đó, các đội tuyển nhỏ hơn như Iceland, Wales hay Áo cũng sẽ mang đến những bất ngờ và thách thức cho các đối thủ.
Các đội tuyển tham dự được chia thành 6 bảng đấu, gồm:
Bảng A: Đức, Scotland, Hungary và Thuỵ Sĩ
Bảng B: Tây Ban Nha, Croatia, Ý và Albania
Bảng C: Slovenia, Đan Mạch, Serbia và Anh
Bảng D: Ba Lan, Hà Lan, Áo và Pháp
Bảng E: Bỉ, Slovakia, Romania và Ukraina
Bảng F: Thổ Nhĩ Kỳ, Gruzia, Bồ Đào Nha và Cộng hoà Séc
k8 カジノ 本人確認 時間
この記事の実用性に感動しました。大変役立つ情報をありがとうございます。
buy cytotec over the counter: buy cytotec in usa – buy cytotec
can you get cheap clomid price: can i purchase generic clomid tablets – order generic clomid
allnewstoday365.com
Rikvip Club: Trung Tâm Giải Trí Trực Tuyến Hàng Đầu tại Việt Nam
Rikvip Club là một trong những nền tảng giải trí trực tuyến hàng đầu tại Việt Nam, cung cấp một loạt các trò chơi hấp dẫn và dịch vụ cho người dùng. Cho dù bạn là người dùng iPhone hay Android, Rikvip Club đều có một cái gì đó dành cho mọi người. Với sứ mạng và mục tiêu rõ ràng, Rikvip Club luôn cố gắng cung cấp những sản phẩm và dịch vụ tốt nhất cho khách hàng, tạo ra một trải nghiệm tiện lợi và thú vị cho người chơi.
Sứ Mạng và Mục Tiêu của Rikvip
Từ khi bắt đầu hoạt động, Rikvip Club đã có một kế hoạch kinh doanh rõ ràng, luôn nỗ lực để cung cấp cho khách hàng những sản phẩm và dịch vụ tốt nhất và tạo điều kiện thuận lợi nhất cho người chơi truy cập. Nhóm quản lý của Rikvip Club có những mục tiêu và ước muốn quyết liệt để biến Rikvip Club thành trung tâm giải trí hàng đầu trong lĩnh vực game đổi thưởng trực tuyến tại Việt Nam và trên toàn cầu.
Trải Nghiệm Live Casino
Rikvip Club không chỉ nổi bật với sự đa dạng của các trò chơi đổi thưởng mà còn với các phòng trò chơi casino trực tuyến thu hút tất cả người chơi. Môi trường này cam kết mang lại trải nghiệm chuyên nghiệp với tính xanh chín và sự uy tín không thể nghi ngờ. Đây là một sân chơi lý tưởng cho những người yêu thích thách thức bản thân và muốn tận hưởng niềm vui của chiến thắng. Với các sảnh cược phổ biến như Roulette, Sic Bo, Dragon Tiger, người chơi sẽ trải nghiệm những cảm xúc độc đáo và đặc biệt khi tham gia vào casino trực tuyến.
Phương Thức Thanh Toán Tiện Lợi
Rikvip Club đã được trang bị những công nghệ thanh toán tiên tiến ngay từ đầu, mang lại sự thuận tiện và linh hoạt cho người chơi trong việc sử dụng hệ thống thanh toán hàng ngày. Hơn nữa, Rikvip Club còn tích hợp nhiều phương thức giao dịch khác nhau để đáp ứng nhu cầu đa dạng của người chơi: Chuyển khoản Ngân hàng, Thẻ cào, Ví điện tử…
Kết Luận
Tóm lại, Rikvip Club không chỉ là một nền tảng trò chơi, mà còn là một cộng đồng nơi người chơi có thể tụ tập để tận hưởng niềm vui của trò chơi và cảm giác hồi hộp khi chiến thắng. Với cam kết cung cấp những sản phẩm và dịch vụ tốt nhất, Rikvip Club chắc chắn là điểm đến lý tưởng cho những người yêu thích trò chơi trực tuyến tại Việt Nam và cả thế giới.
lisinopril medication order lisinopril 20mg buy prinivil
repair of appliances
augmentin 500 uk
Among these, certain icons stand out for their ubiquitous presence and importance in our daily digital interactions. This article delves into a variety of such icons, including the email, safari (web browser), location, discord, settings, Christmas, messages, spotify, person, and home icons, exploring their significance and evolution christmas icon
tamoxifen 20 mg cost
buy ciprofloxacin online uk
механизированная штукатурка москва цена [url=www.mekhanizirovannaya-shtukaturka13.ru/]механизированная штукатурка москва цена[/url] .
선물옵션
국외선물의 시작 골드리치증권와 함께하세요.
골드리치는 길고긴기간 고객님들과 더불어 선물마켓의 행로을 공동으로 걸어왔으며, 고객분들의 보장된 자금운용 및 건강한 수익성을 지향하여 계속해서 전력을 다하고 있습니다.
왜 20,000+인 이상이 골드리치와 동참하나요?
빠른 서비스: 간단하며 빠른속도의 프로세스를 제공하여 누구나 간편하게 사용할 수 있습니다.
보안 프로토콜: 국가당국에서 채택한 최상의 등급의 보안시스템을 도입하고 있습니다.
스마트 인가: 모든 거래정보은 부호화 가공되어 본인 외에는 그 누구도 정보를 확인할 수 없습니다.
확실한 수익성 공급: 리스크 요소를 줄여, 더욱 한층 확실한 수익률을 제시하며 이에 따른 리포트를 발간합니다.
24 / 7 실시간 고객지원: 365일 24시간 신속한 서비스를 통해 투자자분들을 온전히 뒷받침합니다.
제휴한 파트너사: 골드리치증권는 공기업은 물론 금융권들 및 다수의 협력사와 함께 걸어오고.
외국선물이란?
다양한 정보를 참고하세요.
해외선물은 해외에서 거래되는 파생상품 중 하나로, 지정된 기초자산(예: 주식, 화폐, 상품 등)을 기초로 한 옵션계약 계약을 의미합니다. 본질적으로 옵션은 지정된 기초자산을 미래의 특정한 시기에 정해진 가격에 사거나 팔 수 있는 자격을 허락합니다. 해외선물옵션은 이러한 옵션 계약이 국외 시장에서 거래되는 것을 지칭합니다.
해외선물은 크게 매수 옵션과 매도 옵션으로 구분됩니다. 매수 옵션은 명시된 기초자산을 미래에 정해진 가격에 사는 권리를 허락하는 반면, 풋 옵션은 지정된 기초자산을 미래에 정해진 금액에 팔 수 있는 권리를 부여합니다.
옵션 계약에서는 미래의 명시된 일자에 (만기일이라 불리는) 일정 가격에 기초자산을 사거나 매도할 수 있는 권리를 가지고 있습니다. 이러한 금액을 행사 금액이라고 하며, 종료일에는 해당 권리를 행사할지 여부를 판단할 수 있습니다. 따라서 옵션 계약은 투자자에게 미래의 시세 변동에 대한 안전장치나 수익 실현의 기회를 부여합니다.
해외선물은 마켓 참가자들에게 다양한 운용 및 차익거래 기회를 마련, 외환, 상품, 주식 등 다양한 자산유형에 대한 옵션 계약을 포함할 수 있습니다. 투자자는 풋 옵션을 통해 기초자산의 하향에 대한 보호를 받을 수 있고, 콜 옵션을 통해 호황에서의 이익을 겨냥할 수 있습니다.
해외선물 거래의 원리
행사 금액(Exercise Price): 해외선물에서 실행 금액은 옵션 계약에 따라 지정된 가격으로 계약됩니다. 만료일에 이 가격을 기준으로 옵션을 실행할 수 있습니다.
종료일(Expiration Date): 옵션 계약의 만료일은 옵션의 행사가 불가능한 마지막 일자를 뜻합니다. 이 일자 다음에는 옵션 계약이 종료되며, 더 이상 거래할 수 없습니다.
풋 옵션(Put Option)과 매수 옵션(Call Option): 매도 옵션은 기초자산을 지정된 가격에 팔 수 있는 권리를 허락하며, 매수 옵션은 기초자산을 지정된 가격에 사는 권리를 부여합니다.
계약료(Premium): 외국선물 거래에서는 옵션 계약에 대한 옵션료을 지불해야 합니다. 이는 옵션 계약에 대한 비용으로, 시장에서의 수요와 공급에 따라 변경됩니다.
행사 전략(Exercise Strategy): 거래자는 만료일에 옵션을 행사할지 여부를 판단할 수 있습니다. 이는 마켓 상황 및 투자 플랜에 따라 차이가있으며, 옵션 계약의 수익을 최대화하거나 손실을 최소화하기 위해 판단됩니다.
마켓 위험요인(Market Risk): 해외선물 거래는 시장의 변화추이에 영향을 받습니다. 가격 변화이 기대치 못한 진로으로 발생할 경우 손해이 발생할 수 있으며, 이러한 마켓 위험요인를 감소하기 위해 투자자는 전략을 구축하고 투자를 계획해야 합니다.
골드리치증권와 동반하는 해외선물은 확실한 신뢰할 수 있는 투자를 위한 최상의 선택입니다. 회원님들의 투자를 지지하고 가이드하기 위해 우리는 최선을 기울이고 있습니다. 함께 더 나은 미래를 향해 전진하세요.
http://gabapentin.club/# neurontin capsules 600mg
служба по вскрытию замков [url=vskrytie-zamkov-moskva111.ru]vskrytie-zamkov-moskva111.ru[/url] .
apo-prednisone
geinoutime.com
Fang Jifan은 고개를 끄덕이고 눈물이 가득한 Fang Tianci를 바라 보았습니다.
https://mlgtesturamdtestv44.ru/
https://mlgtesturamdtestv44.ru/
Телесериал «911 служба спасения» про доблестных и храбрых спасателей, служба которых тяжелая и несет опасность с каждым вызовом. Герои службы 911 все смелые и храбрые в каждой серии сериала спасают жизни людям. Все персонажи сериала разные по характеру, но это не мешает им дружить и работать слаженной командой 911 служба спасения
Индексация ссылок на сайте vindexe.ru
azithromycin 500mg purchase
buy clomid india
https://cheapestindia.shop/# indianpharmacy com
торшер хрустальный [url=https://hrustalnye-torshery.ru/]https://hrustalnye-torshery.ru/[/url] .
canada cloud pharmacy: cheapest canada – northwest canadian pharmacy
https://cheapestandfast.shop/# online pharmacy canada no prescription
online pharmacy india world pharmacy india Online medicine home delivery
azithromycin 787
Индексация ссылок на сайте vindexe.ru
http://cheapestmexico.com/# mexico pharmacy
брусчатка [url=http://www.kirpich-bruschatka.ru]http://www.kirpich-bruschatka.ru[/url] .
https://cheapestindia.com/# indianpharmacy com
Наши козырьки и навесы над входом фото цены – это идеальное решение для вашего авто.
acyclovir online prescription
Удобство и функциональность – вот что предлагают наши навес под машину 9 на 8 из металлопрофиля.
http://cheapestindia.com/# reputable indian pharmacies
Привет всем!
Получите документы об образовании всех Вузов России с гарантированной доставкой по РФ без предоплаты.
Купите диплом ВУЗа по выгодной цене с доставкой в любой город России без предоплаты – надежно и выгодно!
http://www.dlplomanrussia.com
У нас вы найдете заказать навес над крыльцом частного дома фото на любой вкус и бюджет.
Мы предлагаем только сертифицированные навес для машины из профтрубы.
k8 カジノ バニーガール
この記事は心に響きました。とても感動的です。
Наши навесы к дому фото размеры и цены под ключ подойдут для любого дома и участка.
buy lyrica online from mexico
В эпоху цифровых технологий, когда виртуальная реальность становится все более неотъемлемой частью нашей повседневной жизни, мир развлечений и азарта находит свое отражение в многочисленных онлайн площадках, предлагающих азартные игры и возможность погрузиться в атмосферу адреналина и выигрышей http://suprememasterchinghai.net/bbs/board.php?bo_table=free&wr_id=2113022
уборка квартир в минске [url=http://www.parkmebeli.by]http://www.parkmebeli.by[/url] .
https://cheapestmexico.com/# buying prescription drugs in mexico online
https://cheapestindia.shop/# cheapest online pharmacy india
canada ed drugs maple leaf pharmacy in canada canadian pharmacy sarasota
Индексация ссылок на сайте vindexe.ru
lyrica generic usa
zanetvize.com
Fang Jifan의 평판은 약간 나쁩니다. 그녀는 깊은 궁전에 있지만 어떻게 그것을 모를 수 있습니까?
baclofen australia
https://cheapestcanada.com/# legitimate canadian mail order pharmacy
how to get accutane online
cenforce online cloth – tadalis online jane brand viagra online straight
https://cheapestmexico.com/# mexico pharmacies prescription drugs
интернет магазин 4 4 [url=https://www.vytyazhka-dlya-manikyura.ru]https://www.vytyazhka-dlya-manikyura.ru[/url] .
diflucan online purchase
albuterol 200 mcg
how much is provigil
Лизинг всех видов ИТ, телекоммуникационного оборудования и средств связи. средства слежения и видеонаблюдения; системы хранения данных лизинг торгового оборудования для магазина
Лизинг всех видов ИТ, телекоммуникационного оборудования и средств связи. средства слежения и видеонаблюдения; системы хранения данных оборудование для мойки самообслуживания в лизинг
https://eufarmacieonline.com/# Farmacie on line spedizione gratuita
Please let me know if you’re looking for a author for your weblog. You have some really great articles and I think I would be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine. Please blast me an e-mail if interested. Cheers!
nudify a picture
acquisto farmaci con ricetta: comprare farmaci online con ricetta – Farmacie on line spedizione gratuita
azithromycin tablets 250 mg
pharmacie en ligne livraison europe Pharmacie en ligne livraison Europe pharmacie en ligne france fiable
Личный тренер, групповые занятия, безлимитный доступ, тренажерный зал, шкафчик в раздевалке! Оплата только за месяц фитнес клуб официальный сайт
Личный тренер, групповые занятия, безлимитный доступ, тренажерный зал, шкафчик в раздевалке! Оплата только за месяц тренажерный зал профсоюзная
veganchoicecbd.com
망설이는 듯이 Xu Jing의 눈만 깜박였습니다.
журнал о красоте [url=https://zhurnal-o-krasote11.ru/]журнал о красоте[/url] .
https://eufarmacieonline.shop/# farmacie online autorizzate elenco
can i buy diflucan over the counter in canada
online apotheke deutschland: europa apotheke – apotheke online
acne treatment business – acne medication man acne treatment plastic
acheter mГ©dicament en ligne sans ordonnance: vente de mГ©dicament en ligne – vente de mГ©dicament en ligne
Кроме привычного фитнеса, мы устраиваем челленджи и соревнования среди сети, проводим открытые тренировки в центре и устраиваем сайкл-забеги в торговых центрах фитнес клуб москва
geinoutime.com
Hongzhi 황제는 “예, 어렵습니다!”
how much is a diflucan pill
tadacip 100
asthma medication shin – asthma medication cottage asthma medication steam
טלגראס
האפליקציה היא פלטפורמה מקובלת בישראל לרכישת מריחואנה בצורה מקוון. היא מעניקה ממשק נוח ומאובטח לקנייה ולקבלת משלוחים מ מוצרי קנאביס שונים. במאמר זו נבחן עם העיקרון שמאחורי טלגראס, כיצד היא עובדת ומה היתרונות של השימוש בזו.
מה זו טלגראס?
הפלטפורמה היא דרך לקנייה של קנאביס דרך האפליקציה טלגראם. היא נשענת מעל ערוצי תקשורת וקבוצות טלגרם ספציפיות הקרויות ״כיווני טלגראס״, שבהם ניתן להזמין מרחב פריטי צמח הקנאביס ולקבל אותם ישירות למשלוח. ערוצי התקשורת אלו מאורגנים לפי איזורים גאוגרפיים, כדי להקל על קבלתם של השילוחים.
כיצד זאת פועל?
התהליך קל למדי. ראשית, יש להצטרף לערוץ הטלגראס הנוגע לאזור המגורים. שם אפשר לצפות בתפריטי הפריטים המגוונים ולהרכיב את הפריטים המבוקשים. לאחר ביצוע ההרכבה וסגירת התשלום, השליח יגיע בכתובת שצוינה עם החבילה שהוזמן.
רוב ערוצי טלגראס מציעים טווח רחב מ פריטים – סוגי מריחואנה, ממתקים, משקאות ועוד. כמו כן, אפשר לראות ביקורות מ צרכנים שעברו לגבי רמת הפריטים והשירות.
מעלות השימוש בטלגראס
מעלה עיקרי של הפלטפורמה הינו הנוחות והדיסקרטיות. ההרכבה וההכנות מתבצעות מרחוק מכל מקום, ללא נחיצות בהתכנסות פנים אל פנים. בנוסף, האפליקציה מאובטחת היטב ומבטיחה חיסיון גבוהה.
נוסף על זאת, עלויות הפריטים בטלגראס נוטים לבוא תחרותיים, והמשלוחים מגיעים במהירות ובמסירות גבוהה. קיים גם מוקד תמיכה פתוח לכל שאלה או בעיה.
סיכום
הפלטפורמה מהווה דרך חדשנית ויעילה לרכוש פריטי מריחואנה במדינה. זו משלבת את הנוחיות הדיגיטלית מ האפליקציה הפופולרית, ועם המהירות והדיסקרטיות מ שיטת המשלוח הישירה. ככל שהדרישה לקנאביס גדלה, אפליקציות כמו זו צפויות להמשיך ולהתפתח.
farmacia online: farmacie online affidabili – migliori farmacie online 2024
pharmacie en ligne pas cher: п»їpharmacie en ligne france – pharmacie en ligne france livraison internationale
pharmacie en ligne fiable pharmacie en ligne pharmacie en ligne pas cher
Low-carb candies have emerged as a in-demand snack choice for persons adhering to a ketogenic or low-carbohydrate lifestyle. These chewy delicacies are formulated to be reduced in net carbs, making them a harmless pleasure for those striving to maintain a https://t.me/s/ketogummies state of ketonemia.
By utilizing plant-based sugar substitutes like stevia or erythritol sweetener, low-carb gummies provide a gratifying sugary taste without spiking glucose levels, a common worry with traditional confectionery.
Актуальные купоны на скидку iHerb совершенно бесплатно! … Вы находитесь на странице iHerb, который на данный момент не работает на первый заказ айхерб промокод
can you buy cipro over the counter in canada
diflucan pill cost
günstige online apotheke: ohne rezept apotheke – eu apotheke ohne rezept
medikament ohne rezept notfall beste online-apotheke ohne rezept gГјnstige online apotheke
выкуп машин в москве https://avtovikupmashin21.ru/
Топ 10 лучших онлайн-казино, которые заняли первые места в рейтинге игр на наличные деньги, доверия и других значимых критериев 2024 лучшие казино
Топ 10 лучших онлайн-казино, которые заняли первые места в рейтинге игр на наличные деньги, доверия и других значимых критериев 2024 онлайн казино
лучшие казино
Farmacie on line spedizione gratuita: farmacia online senza ricetta – acquistare farmaci senza ricetta
הפלטפורמה מהווה פלטפורמה רווחת בארץ לקנייה של צמח הקנאביס באופן אינטרנטי. היא מספקת ממשק פשוט לשימוש ובטוח לקנייה ולקבלת שילוחים מ מוצרי מריחואנה שונים. בסקירה זה נסקור את הרעיון שמאחורי הפלטפורמה, כיצד זו פועלת ומהם המעלות של השימוש בה.
מה זו האפליקציה?
האפליקציה הינה אמצעי לקנייה של קנאביס דרך האפליקציה טלגרם. היא נשענת על ערוצים וקהילות טלגרם ייעודיות הקרויות ״טלגראס כיוונים, שם אפשר להרכיב מגוון פריטי קנאביס ולקבלת אלו ישירות לשילוח. ערוצי התקשורת אלו מאורגנים לפי אזורים גאוגרפיים, כדי לשפר את קבלת המשלוחים.
איך זאת פועל?
התהליך קל למדי. ראשית, יש להצטרף לערוץ הטלגראס הנוגע לאזור המחיה. שם אפשר לעיין בתפריטי הפריטים המגוונים ולהרכיב עם המוצרים המבוקשים. לאחר השלמת ההרכבה וסיום התשלום, השליח יופיע בכתובת שנרשמה עם החבילה המוזמנת.
מרבית ערוצי טלגראס מציעים מגוון רחב של מוצרים – זנים של צמח הקנאביס, ממתקים, שתייה ועוד. כמו כן, אפשר לראות ביקורות של צרכנים שעברו לגבי רמת הפריטים והשירות.
יתרונות השימוש באפליקציה
יתרון מרכזי מ הפלטפורמה הוא הנוחות והפרטיות. ההזמנה והתהליך מתבצעות מרחוק מכל מיקום, בלי צורך במפגש פיזי. בנוסף, האפליקציה מוגנת ביסודיות ומבטיחה חיסיון גבוה.
נוסף אל זאת, מחירי המוצרים באפליקציה נוטות להיות תחרותיים, והשילוחים מגיעים במהירות ובמסירות רבה. יש גם מרכז תמיכה זמין לכל שאלה או בעיית.
סיכום
האפליקציה היא דרך חדשנית ויעילה לקנות פריטי קנאביס בארץ. זו משלבת את הנוחיות הטכנולוגית מ היישומון הפופולרית, לבין המהירות והפרטיות של שיטת השילוח הישירה. ככל שהדרישה לצמח הקנאביס גדלה, אפליקציות כמו זו צפויות להמשיך ולהתפתח.
Как охранять свои личные данные: остерегайтесь утечек информации в интернете. Сегодня сохранение информации становится всё значимее важной задачей. Одним из наиболее распространенных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и в каком объеме предохранить себя от их утечки? Что такое «сит фразы»? «Сит фразы» — это комбинации слов или фраз, которые постоянно используются для получения доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или иные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как защитить свои личные данные? Используйте непростые пароли. Избегайте использования легких паролей, которые просто угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для всего аккаунта. Не применяйте один и тот же пароль для разных сервисов. Используйте двухфакторную аутентификацию (2FA). Это привносит дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт путем другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы уберечь свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким подобно кража личной информации и финансовых потерь. Чтобы защитить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
medikamente rezeptfrei beste online-apotheke ohne rezept internet apotheke
Как защитить свои данные: избегайте утечек информации в интернете. Сегодня охрана личных данных становится всё более важной задачей. Одним из наиболее популярных способов утечки личной информации является слив «сит фраз» в интернете. Что такое сит фразы и как сберечься от их утечки? Что такое «сит фразы»? «Сит фразы» — это комбинации слов или фраз, которые постоянно используются для доступа к различным онлайн-аккаунтам. Эти фразы могут включать в себя имя пользователя, пароль или разные конфиденциальные данные. Киберпреступники могут пытаться получить доступ к вашим аккаунтам, при помощи этих сит фраз. Как обезопасить свои личные данные? Используйте непростые пароли. Избегайте использования простых паролей, которые мгновенно угадать. Лучше всего использовать комбинацию букв, цифр и символов. Используйте уникальные пароли для каждого из аккаунта. Не пользуйтесь один и тот же пароль для разных сервисов. Используйте двухступенчатую аутентификацию (2FA). Это прибавляет дополнительный уровень безопасности, требуя подтверждение входа на ваш аккаунт посредством другое устройство или метод. Будьте осторожны с онлайн-сервисами. Не доверяйте личную информацию ненадежным сайтам и сервисам. Обновляйте программное обеспечение. Установите обновления для вашего операционной системы и программ, чтобы сохранить свои данные от вредоносного ПО. Вывод Слив сит фраз в интернете может повлечь за собой серьезным последствиям, таким как кража личной информации и финансовых потерь. Чтобы обезопасить себя, следует принимать меры предосторожности и использовать надежные методы для хранения и управления своими личными данными в сети
generic viagra online 50mg
can you buy retin a cream over the counter
Оградите собственные USDT: Удостоверьтесь перевод TRC20 перед отправкой
Цифровые валюты, такие как USDT (Tether) на блокчейне TRON (TRC20), делаются все всё более распространенными в области области децентрализованных финансов. Но вместе со увеличением распространенности увеличивается также риск ошибок либо мошенничества при отправке средств. Как раз по этой причине необходимо удостоверяться операцию USDT TRC20 до ее отправлением.
Погрешность при вводе данных адреса получателя адресата или перевод на некорректный адрес может привести к невозможности безвозвратной потере твоих USDT. Жулики тоже могут пытаться обмануть вас, посылая поддельные адреса получателей на отправки. Потеря цифровой валюты из-за таких погрешностей сможет повлечь серьезными денежными потерями.
Впрочем, существуют специализированные сервисы, дающие возможность проверить операцию USDT TRC20 до её пересылкой. Некий из числа подобных служб дает опцию наблюдать а также изучать переводы на блокчейне TRON.
В этом сервисе вы сможете вводить адрес получателя получателя и получать детальную данные об адресе, включая историю транзакций, остаток а также статус аккаунта. Данное поможет выяснить, есть ли адрес подлинным и безопасным на отправки финансов.
Другие службы также предоставляют похожие возможности для контроля операций USDT TRC20. Некоторые кошельки по криптовалют обладают инкорпорированные возможности для контроля адресов и переводов.
Не пропускайте удостоверением транзакции USDT TRC20 перед её отсылкой. Небольшая предосторожность может сберечь вам много денег и не допустить утрату ваших дорогих крипто активов. Применяйте проверенные службы для гарантии защищенности твоих переводов а также сохранности твоих USDT на распределенном реестре TRON.
В процессе работе с виртуальной валютой USDT в распределенном реестре TRON (TRC20) крайне значимо не только удостоверять адрес получателя перед отправкой средств, а также тоже систематически контролировать остаток своего крипто-кошелька, плюс источники поступающих транзакций. Данное действие позволит своевременно идентифицировать всевозможные нежелательные транзакции и не допустить возможные убытки.
В первую очередь, необходимо удостовериться в точности демонстрируемого остатка USDT TRC20 на вашем кошельке для криптовалют. Предлагается сравнивать данные с сведениями общедоступных обозревателей блокчейна, с целью исключить возможность хакерской атаки либо взлома этого кошелька.
Но лишь наблюдения баланса не хватает. Чрезвычайно необходимо изучать журнал входящих транзакций и их происхождение. Если Вы найдете поступления USDT с анонимных или подозрительных реквизитов, немедленно остановите данные средства. Есть риск, что эти монеты были добыты незаконным способом и впоследствии изъяты регуляторами.
Наш сервис обеспечивает средства для всестороннего исследования входящих USDT TRC20 переводов касательно этой законности а также отсутствия соотношения с криминальной деятельностью. Мы поможем вам безопасно работать с этим популярным стейблкоином.
Дополнительно необходимо регулярно отправлять USDT TRC20 в надежные некастодиальные криптовалютные кошельки под собственным полным присмотром. Содержание монет на сторонних площадках неизменно связано с рисками взломов и потери денег из-за программных сбоев или банкротства сервиса.
Соблюдайте основные правила безопасности, будьте внимательны и оперативно отслеживайте баланс а также происхождение поступлений кошелька для USDT TRC20. Это дадут возможность оградить ваши электронные ценности от незаконного присвоения и возможных правовых последствий впоследствии.
Welcome to our website, your top online nave after African sports, music, and luminary updates. We swaddle everything from heady sports events like the Africa Cup of Nations to the latest trends in Afrobeats and usual music. Explore closed interviews and features on prominent personalities making waves across the continent and beyond.
At our website, we forearm convenient and likeable topic that celebrates the heterogeneity and vibrancy of African culture. Whether you’re a sports supporter, music lover, or curious far Africa’s substantial figures, go our community and stay connected concerning constantly highlights and in-depth stories showcasing the kindest of African ability and creativity https://nouvelles-histoires-africaines.africa/comment-couper-de-la-musique-mp3/.
Befall our website today and see the emphatic the human race of African sports, music, and well-known personalities. Involve yourself in the richness of Africa’s cultural section with us!
beste online-apotheke ohne rezept: online apotheke günstig – beste online-apotheke ohne rezept
buy fluconazole online
pharmacies en ligne certifiГ©es pharmacie en ligne livraison europe pharmacie en ligne avec ordonnance
Фотокниги с вашей историей. Закажите сегодня, и через несколько дней будете держать дорогие сердцу воспоминания в руках. Обложка arrow фотокнига с рождения
п»їfarmacia online espaГ±a: п»їfarmacia online espaГ±a – farmacias online seguras en espaГ±a
モンスターハンター(V2.2)
素敵な記事で、読んでいてとても楽しかったです。
Pharmacie Internationale en ligne: pharmacie en ligne avec ordonnance – pharmacie en ligne pas cher
pharmacie en ligne sans ordonnance: pharmacie en ligne france livraison belgique – pharmacie en ligne france pas cher
https://eumedicamentenligne.com/# Pharmacie en ligne livraison Europe
werankcities.com
Liu Wenshan은 “선생님, 이백 팔십만 냥”이라고 말했습니다.
uti treatment obscure – treatment for uti condition treatment for uti section
comprare farmaci online all’estero Farmacie on line spedizione gratuita farmacia online senza ricetta
1вин зеркало
1вин
pharmacie en ligne: pharmacie en ligne avec ordonnance – pharmacie en ligne pas cher
pills for treat prostatitis city – prostatitis pills decent prostatitis pills plenty
Онлайн-заказ на печать фотографий, фотосувениров и фотокниг, производство интерьерной и полиграфической продукции фото москва центр
where can i buy advair
ушп 8 на 12 цена
ciprofloxacin 700 mg
accutane cream price
top farmacia online: farmacie online sicure – Farmacia online miglior prezzo
Farmacie on line spedizione gratuita: comprare farmaci online con ricetta – comprare farmaci online all’estero
Один из лучших буков. Даже наши “легальные” конторы бывают не выплачивают деньги и специально урезают лимиты. 1вин не страдает этой херней, всегда четко выводит, говорю лично про себя! Надеюсь так и будет дальше 1вин
проверить адрес usdt trc20
Название: Непременно контролируйте адрес реципиента при транзакции USDT TRC20
При работе со цифровыми валютами, особенно с USDT на блокчейне TRON (TRC20), весьма необходимо демонстрировать осторожность и аккуратность. Одна из самых распространенных погрешностей, какую делают юзеры – отправка финансов по ошибочный адрес. Чтобы предотвратить потери своих USDT, требуется постоянно старательно контролировать адресе реципиента до посылкой операции.
Криптовалютные адреса кошельков являют собой протяженные наборы литер а также номеров, например, TRX9QahiFUYfHffieZThuzHbkndWvvfzThB8U. Даже незначительная опечатка иль ошибка при копирования адреса кошелька сможет привести к тому результату, что твои цифровые деньги будут невозвратно утрачены, так как они окажутся в неподконтрольный вами кошелек.
Имеются разные методы проверки адресов USDT TRC20:
1. Глазомерная ревизия. Внимательно соотнесите адрес кошелька в своём крипто-кошельке с адресом реципиента. При малейшем различии – не производите операцию.
2. Применение веб-инструментов контроля.
3. Дублирующая проверка со адресатом. Попросите адресату подтвердить точность адреса до передачей операции.
4. Тестовый перевод. При существенной величине транзакции, возможно вначале послать небольшое количество USDT для контроля адреса кошелька.
Также предлагается хранить крипто на личных кошельках, но не на биржах или посреднических службах, для того чтобы иметь всецелый управление по отношению к собственными средствами.
Не оставляйте без внимания проверкой адресов кошельков при осуществлении взаимодействии со USDT TRC20. Данная обычная процедура безопасности посодействует обезопасить твои средства против случайной утраты. Имейте в виду, что в области крипто транзакции неотменимы, а переданные цифровые деньги по неправильный адрес возвратить практически нереально. Будьте бдительны и тщательны, для того чтобы обезопасить свои капиталовложения.
pg slot
pharmacie en ligne fiable Levitra pharmacie en ligne pharmacies en ligne certifiГ©es
Осуществляем уборку квартир, домов, офисов, уборку после ремонта, генеральную и поддерживающую, а также мытье окон услуга уборки
Осуществляем уборку квартир, домов, офисов, уборку после ремонта, генеральную и поддерживающую, а также мытье окон уборка квартир
vente de mГ©dicament en ligne: Acheter Cialis – pharmacie en ligne livraison europe
Pharmacie Internationale en ligne: Acheter Cialis – п»їpharmacie en ligne france
azithromycin 9 pills
Сдаём квадроциклы в аренду от 1 часа и организуем маршруты на любой вкус. Катаем на новой технике. Забронировать поездку квадроцикл кататься в подмосковье
Сдаём квадроциклы в аренду от 1 часа и организуем маршруты на любой вкус. Катаем на новой технике. Забронировать поездку прокат на квадроциклах в подмосковье
tintucnamdinh24h.com
이제 Ma Wensheng은 물고기에 관심이 없으며 돈과 음식을 원합니다.
Achat mГ©dicament en ligne fiable: pharmacie en ligne sans ordonnance – pharmacie en ligne avec ordonnance
15 tretinoin
Подарочный сертификат на аренду квадроциклов станет незабываемым подарком для любителей активного отдыха прокат квадроциклов чехов
https://levitraenligne.com/# pharmacie en ligne france
Bản cài đặt B29 IOS – Giải pháp vượt trội cho các tín đồ iOS
Trong thế giới công nghệ đầy sôi động hiện nay, trải nghiệm người dùng luôn là yếu tố then chốt. Với sự ra đời của Bản cài đặt B29 IOS, người dùng sẽ được hưởng trọn vẹn những tính năng ưu việt, mang đến sự hài lòng tuyệt đối. Hãy cùng khám phá những ưu điểm vượt trội của bản cài đặt này!
Tính bảo mật tối đa
Bản cài đặt B29 IOS được thiết kế với mục tiêu đảm bảo an toàn dữ liệu tuyệt đối cho người dùng. Nhờ hệ thống mã hóa hiện đại, thông tin cá nhân và dữ liệu nhạy cảm của bạn luôn được bảo vệ an toàn khỏi những kẻ xâm nhập trái phép.
Trải nghiệm người dùng đỉnh cao
Giao diện thân thiện, đơn giản nhưng không kém phần hiện đại, B29 IOS mang đến cho người dùng trải nghiệm duyệt web, truy cập ứng dụng và sử dụng thiết bị một cách trôi chảy, mượt mà. Các tính năng thông minh được tối ưu hóa, giúp nâng cao hiệu suất và tiết kiệm pin đáng kể.
Tính tương thích rộng rãi
Bản cài đặt B29 IOS được phát triển với mục tiêu tương thích với mọi thiết bị iOS từ các dòng iPhone, iPad cho đến iPod Touch. Dù là người dùng mới hay lâu năm của hệ điều hành iOS, B29 đều mang đến sự hài lòng tuyệt đối.
Quá trình cài đặt đơn giản
Với những hướng dẫn chi tiết, việc cài đặt B29 IOS trở nên nhanh chóng và dễ dàng. Chỉ với vài thao tác đơn giản, bạn đã có thể trải nghiệm ngay tất cả những tính năng tuyệt vời mà bản cài đặt này mang lại.
Bản cài đặt B29 IOS không chỉ là một bản cài đặt đơn thuần, mà còn là giải pháp công nghệ hiện đại, nâng tầm trải nghiệm người dùng lên một tầm cao mới. Hãy trở thành một phần của cộng đồng sử dụng B29 IOS để khám phá những tiện ích tuyệt vời mà nó có thể mang lại!
Подарочный сертификат на аренду квадроциклов станет незабываемым подарком для любителей активного отдыха биглион квадроциклы
diflucan one
Viagra sans ordonnance 24h suisse: viagra sans ordonnance – Viagra gГ©nГ©rique pas cher livraison rapide
How to lose weight
?These words warmed his soul. A joyful smile spread across the man’s face, and his mustache crawled into his freckled nose. It’s so good when there is someone who can stand up for you and your family. Until the evening, Pavel remained in a happy mood, and went home inspired. A walk was planned for today, after work. Meeting with the family, they went to rest and strengthen their health:
— And I didn’t slip up at all today! The first month will be difficult, of course, but then we’ll get used to it. When I lose weight and fit into a swimsuit, we’ll go to the sea!
— Excellent! I also ate stew with buckwheat for lunch, with vegetables there. It’s not that bad at all. We will cope, for sure.
Masha walked with her parents hand in hand and didn’t understand the essence, but also smiled with them. The family is together, and she is happy. That’s the most important thing:
— I also made arrangements about your problem. It turns out that Mikhalych is Vika’s neighbor. He will have a talk with them, and she won’t bother you anymore.
— Really? You’re not joking?
Вы можете взять в аренду квадроцикл и насладиться преодолением бездорожья. Всё просто – выберете продолжительность тура взять квадроцикл
Achat mГ©dicament en ligne fiable: acheter kamagra site fiable – pharmacie en ligne avec ordonnance
Место, где можно заказать стильные кухонные раковины из камня по выгодным ценам.
Как похудеть
Взгляд ее наполнился печалью, голова сама опустилась из-за тяжести мыслей, терзающих ее внутри. Она ничего не говорила, да и расспрос в магазине мужчину не особого интересовал в данный момент. Им понадобилось буквально полчаса, что бы собрать нужную продуктовую корзину, «правильную». Она очень отличалась от их привычной: там не было сладостей и газировки, копченостей и выпечки. Особенным ударом ниже пояса для мужчины стал отказ в покупке майонеза:
—Боже мой, что это. «Хлеб диетический», ух ты…. И ты хочешь сказать, что за эти два пакета зелени мы заплатили три тысячи?
—Так ты посмотри, сколько мы набрали? Это же не ролтон, ими наесться на весь день можно. И еще похудеть в том числе.
представитель сильного пола совсем не предусматривал из уст собственной жены Тани. Внутри этой семье телосложение организма полностью была иной в противовес общепринятой а также распространённой – обладать предожирением непреложная правило.
Achat mГ©dicament en ligne fiable Cialis sans ordonnance 24h п»їpharmacie en ligne france
https://123win1.com
vente de mГ©dicament en ligne: pharmacie en ligne avec ordonnance – pharmacie en ligne avec ordonnance
Геракл24: Профессиональная Смена Фундамента, Венцов, Покрытий и Перенос Строений
Организация Gerakl24 специализируется на оказании полных услуг по замене фундамента, венцов, полов и передвижению строений в месте Красноярск и за его пределами. Наша группа квалифицированных специалистов обеспечивает высокое качество выполнения всех видов ремонтных работ, будь то деревянные, каркасные, кирпичные или из бетона строения.
Преимущества сотрудничества с Геракл24
Квалификация и стаж:
Каждая задача выполняются лишь высококвалифицированными экспертами, с обладанием долгий стаж в сфере создания и реставрации домов. Наши сотрудники профессионалы в своем деле и выполняют задачи с безупречной точностью и учетом всех деталей.
Комплексный подход:
Мы предоставляем полный спектр услуг по реставрации и реконструкции строений:
Смена основания: укрепление и замена старого фундамента, что обеспечивает долгий срок службы вашего строения и устранить проблемы, связанные с оседанием и деформацией строения.
Реставрация венцов: реставрация нижних венцов из дерева, которые наиболее часто подвергаются гниению и разрушению.
Замена полов: монтаж новых настилов, что существенно улучшает внешний облик и практическую полезность.
Перенос строений: безопасное и качественное передвижение домов на новые локации, что помогает сохранить здание и избегает дополнительных затрат на строительство нового.
Работа с любыми видами зданий:
Дома из дерева: восстановление и укрепление деревянных конструкций, защита от разрушения и вредителей.
Дома с каркасом: реставрация каркасов и реставрация поврежденных элементов.
Дома из кирпича: ремонт кирпичных стен и укрепление конструкций.
Бетонные дома: восстановление и укрепление бетонных структур, исправление трещин и разрушений.
Надежность и долговечность:
Мы работаем с только высококачественные материалы и новейшее оборудование, что гарантирует долгий срок службы и надежность всех работ. Все наши проекты подвергаются строгому контролю качества на каждом этапе выполнения.
Индивидуальный подход:
Каждому клиенту мы предлагаем персонализированные решения, с учетом всех особенностей и пожеланий. Мы стремимся к тому, чтобы результат нашей работы полностью соответствовал ваши ожидания и требования.
Почему выбирают Геракл24?
Сотрудничая с нами, вы найдете надежного партнера, который возьмет на себя все хлопоты по восстановлению и ремонту вашего здания. Мы обещаем выполнение всех работ в сроки, установленные договором и с соблюдением всех строительных норм и стандартов. Связавшись с Геракл24, вы можете быть спокойны, что ваше здание в надежных руках.
Мы готовы предоставить консультацию и ответить на ваши вопросы. Звоните нам, чтобы обсудить детали вашего проекта и узнать о наших сервисах. Мы обеспечим сохранение и улучшение вашего дома, сделав его уютным и безопасным для долгого проживания.
Геракл24 – ваш выбор для реставрации и ремонта домов в Красноярске и области.
купить аккаунты вк оптом [url=https://kupit-akkaunt-vk.ru]https://kupit-akkaunt-vk.ru[/url] .
1вин казино
geinoutime.com
지식이 있으면 당연히 의심이 생기기 때문에 다른 사람에게 조언을 구했습니다.
tvlore.com
Hongzhi 황제는 한숨을 쉬고 Fang Jifan에게 떠나라고 손을 흔들었습니다.
From Northwestern University Feinberg School of Medicine, Chicago, Ill M cialis on line If the case describes a patient with atypical squamus cells of undetermined significance ASCUS on the Pap smear and repeat pap smear result is again ASCUS, or HPV 16 and 18, what next
Отзывы на работу онлайн казино 1Win Casino (1Вин Казино) об игре на реальные деньги, скорости выплат и вывода средств, отдаче автоматов казино 1Вин
Квадроцикл дарит невероятную свободу передвижения по бездорожью. Впервые сев за руль человек получает невероятные эмоции от управления квадроцикл напрокат
lyrica 300 mg price uk
SildГ©nafil 100 mg sans ordonnance: Viagra generique en pharmacie – Quand une femme prend du Viagra homme
k8 カジノ 系列
興味深いトピックと素晴らしい分析で、大変勉強になりました。
loratadine medication upper – loratadine medication startle claritin pills flora
Квадроцикл дарит невероятную свободу передвижения по бездорожью. Впервые сев за руль человек получает невероятные эмоции от управления покататься на квадроциклах в щёлковском районе
dexamethasone 1 mg tablet
Hello!
This post was created with XRumer 23 StrongAI.
Good luck 🙂
lasix 1975
acheter mГ©dicament en ligne sans ordonnance: acheter mГ©dicament en ligne sans ordonnance – pharmacie en ligne livraison europe
blackpanther77
Букмекерская контора 1win отзывы клиентов, Отзывы о Букмекерская контора 1win. На сайте отвечает официальный представитель Букмекерская контора 1win 1win зеркало
trouver un mГ©dicament en pharmacie: pharmacie en ligne sans ordonnance – Pharmacie en ligne livraison Europe
purchase nolvadex online
Achat mГ©dicament en ligne fiable: kamagra gel – pharmacie en ligne fiable
ремонт сотовых телефонов в москве
Поддельный Диплом О Высшем Образовании
Поддельный Диплом О Высшем Образовании
Следующим признаком защиты являются небольшие волоски, красного или синего цвета на бланке и вкладыше. Мы гарантируем высокое образованье документов, полную конфиденциальность и оперативность выполнения заказа. Ответ на вопрос заголовка: по возможности необходимо пройти конкурс в знаменитый институт и университет России, но это преимущество не является необходимостью для кандидатов, скорее бонусом при трудоустройстве. Предприниматели, которые хотят достигнуть новых финансовых высот, прекрасно осознают, что образование, которое обретено в России имеет весомый поддельный диплом, и работник с таким дипломом даст большую пользу, что в итоге обернется в звонкую монету. Вы можете заказать дипломы бакалавра и бакалавра без отличия в нашей компании, заполнив форму заказа на этой странице. Поэтому о качестве образования говорить не будем, вот почему купить поддельный диплом О Высшем Образовании техникума или ВУЗа зачастую, намного выгоднее, чем тратить деньги и время на учебу. При приобретении документа старого образца следует обязательно обратить внимание на приложение к нему, бумага не должна иметь белый цвет, она должна быть старой, слегка пожелтевшей.
http://www.russkiy365-diploms-srednee.ru
Купить Диплом Образование Киеве
Если вам необходимы другие сроки изготовления документа мы выполняем работы в сжатые сроки. Каждому диплому присваивается индивидуальный номер, он вносится как в титул, так и в приложение к диплому. Винницкий медицинский институт аттестован и аккредитован по IV уровню аккредитации.
Диплом О Высшем Образовании Оценки
Безусловно, можно обучаться в онлайн поддельном дипломе О Высшем Образовании дистанционно, но не лучше ли заниматься легальным заработком денег, искать новые горизонты и повышать финансовое благополучие. Нужно зайти на сайт Минобразования и найти там все о порядке восстановления диплома и документах, подтверждающих факт обучения там. Но порой в силу определенных обстоятельств человеку нужно купить диплом о высшем образовании в считанные дни. Поступающие могли выбрать как очную, так и дистанционную или вечернюю форму обучения.
Pharmacie en ligne livraison Europe: Cialis sans ordonnance 24h – pharmacie en ligne france livraison belgique
tretinoin price canada
Проверить Диплом О Высшем Образовании Онлайн
Требования работодателя – сертификат о повышении квалификации фармацевту. Появление первых колледжей приходится на 90-е годы, когда распалась советская система образования. Обязательно найдите информацию о возможности доработок текста, создании дополнительных материалов (например, графиков и чертежей) и проверке уникальности. Такая специальность подойдет для тех, кто не терпит однотипности в своей жизни, кто постоянно стремится к чему-то новому. Полностью готовый к использованию диплом со всеми подписями и печатями. Главное, чтобы на нем стояла подпись и печать “государственного образца”.
russkiy365-diploms-srednee.ru
Купить Диплом В Одессе Недорого
Речь идет о неотъемлемой ценности современного человека – диплом о высшем образовании. Документ бывает необходим не только тем, кто окончил учебное заведение, но и тем, кто только начал свою трудовую деятельность. Чаще всего они выглядят как полоски желто-зеленого или оранжевого цвета.
Справка О Трудоустройстве Студента
Имеет большое значение понимать, что приобретение документа – это лишь единственная сторона медали, а продолжительный успех все равно исключительно зависит от персональных качеств и навыков. Важно следить за своим прогрессом и вовремя решать все учебные задачки. Прежде, чем обратиться за услугами, следует выбрать подходящую организацию, которая точно не относится к числу мошенников.
Наши изготовление ферм для навеса studialestnic подойдут для любого дома и участка.
retin-a gel
Диплом Сварщика
Диплом Сварщика
Каждый сварщик может просмотреть их, чтобы убедиться, что мы создаем дипломы Сварщика международного диплома. Последний даст больше уверенности при желании продолжить обучение в вузе. Мы можем предложить вам купить диплом специалиста, документ техникума и много других полезных вещей. Вы можете обратиться к нам по электронной почте и мы мгновенно с вами свяжемся и дадим исчерпывающую консультацию по вашей проблеме. Сегодня купить диплом университета предлагают многие известные фирмы, организации и подпольные конторы.
https://russkiy365-diploms-srednee.ru/
Диплом О Высшем Образовании Юриста
Одними из основных являются: с таким дипломом неохотно берут на работу. Профессиональная квалификация дипломированного диплома Сварщика гораздо выше, что обусловлено широтой и глубиной освоенной им учебной программы. Мы изготавливаем дипломы в строгом соответствии с требованиями, которые предъявляет к оформлению документов наша страна.
Какие Бывают Дипломы В Колледже
Мы уверены, что решив купить диплом ВУЗа государственного образца в нашей компании, вы останетесь довольны. Чаще всего такая услуга, как покупка диплома, востребована для тех, кто имеет среднее или средне-специальное образование и хочет устроиться на хорошую работу. Многие работают с покупными “бумагами” и занимают хорошие должности.
seo продвижение и оптимизация сайтов
pharmacie en ligne pas cher: kamagra pas cher – trouver un mГ©dicament en pharmacie
Доставка из Китая с таможенными услугами — это профессиональное решение для импорта товаров из Китая, включающее в себя организацию перевозки, таможенное оформление и сопутствующие услуги. Мы предоставляем полный спектр услуг, связанных
доставка в китае включая организацию международных перевозок, таможенное оформление, сертификацию и страхование грузов. Наши специалисты помогут вам выбрать оптимальный маршрут и вид транспорта, оформить необходимые документы и декларации, а также проконсультируют по вопросам налогообложения и таможенного законодательства.
Купить Диплом О Среднем Образовании В Красноярске
Важно найти должность, способную всегда приносить желаемую прибыль. К тому же, вам сперва будет выслан черновой вариант диплома для одобрения. Если подходить к выбору с легкостью и интересом, во время поиска можно очень даже весело провести время. Диплом о высшем образовании – один из самых востребованных документов среди работодателей. Форма обучения заочная, с применением дистанционных образовательных технологий, а по окончанию программ слушатель получает диплом, подтверждающий получение компетенции.
http://https://arusak-diploms-srednee.ru
Заказать Диплом Нижний Новгород
В проекте Knowledge Stream речь пойдёт о передовых биотехнологических разработках, таких как радикальное продление жизни, производство наноматериалов и наноинструментов, переработка отходов нефтепромысла. Первый закончить нужное учебное заведение, а второй приобрести диплом. Наши специалисты имеют огромный опыт в изготовлении документов, поэтому несоответствия, ошибки исключены.
Купить Свидетельство Браке Киев
Фармацевты, работающие в аптеке, не только продают выписанное по рецепту лекарство, но и помогают с его выбором. Только помните, что к выбору исполнителя нужно подходить максимально ответственно ведь от того, насколько квалифицированные и грамотные специалисты будут с вами работать, зависит и качество исполнения заказанного документа. Человек, имеющий высшее образование может достичь хороших результатов в любой из сфер производства, частном предпринимательстве, а при должном рвении построить хорошую карьеру на государственной службе.
Почему теневой плинтус – красивая и практичная деталь интерьера,
Советы по монтажу теневого плинтуса без дополнительной помощи,
Креативные способы использования теневого плинтуса в дизайне помещения,
Теневой плинтус: классический стиль в современном исполнении,
Гармония оттенков: выбор цвета теневого плинтуса для любого интерьера,
Безопасность и стиль: почему теневой плинтус – идеальное решение для дома,
Теневой плинтус с подсветкой: создаем эффектное освещение в интерьере,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Теневой плинтус: деталь, которая делает интерьер законченным и гармоничным
плинтуса для пола https://plintus-tenevoj-aljuminievyj-msk.ru/ .
Viagra prix pharmacie paris: Meilleur Viagra sans ordonnance 24h – Viagra pas cher livraison rapide france
nederlandse casinos online [url=https://bestegokautomaten.nl/]nederlandse casinos online[/url] .
pharmacie en ligne france fiable: levitra generique – Pharmacie Internationale en ligne
pharmacie en ligne avec ordonnance: Levitra 20mg prix en pharmacie – pharmacie en ligne france fiable
blackpanther77
dapoxetine agent – priligy research priligy polish
Виртуальный номер для подтверждения аккаунта можно использовать в течение разного времени. Просто выберите соответствующую услугу https://compsch.com/news/osobennosti-virtualnyx-nomerov-telefona.html
Виртуальный номер для подтверждения аккаунта можно использовать в течение разного времени. Просто выберите соответствующую услугу http://www.6vwb.cn/20240129/10928394.html
SildГ©nafil 100 mg sans ordonnance: Acheter du Viagra sans ordonnance – Viagra homme prix en pharmacie sans ordonnance
Hello.
This post was created with XRumer 23 StrongAI.
Good luck 🙂
loratadine medication temper – claritin pills guide loratadine medication decay
blackpanther77
blackpanther77
cost of baclofen 20 mg
pharmacie en ligne livraison europe: Levitra pharmacie en ligne – pharmacie en ligne sans ordonnance
buy accutane from canada
Join our community of beyond 2 million contented users who are parsimonious time and getting paid faster with our travelling invoice solutions. Our unstationary invoicing tools, including movable invoice apps, pander to to both iOS and Android users. Whether you have occasion for an invoice app for iPhone, an Android invoice app, or a broad animated billing software, we’ve got you covered.
https://www.genio.ac/mobile-invoices
baclofen 20 mg tablet price
ilogidis.com
이를 위해서는 황제와 궁정이 완전히 손을 떼야 합니다.
Уборка квартиры после смерти Москва https://prof-uborka-posle-smerti.ru/
Sign up with our community of outstanding 2 million light-hearted users who are redemptory time and getting paid faster with our transportable invoice solutions. Our unstationary invoicing tools, including non-stationary invoice apps, pander to to both iOS and Android users. Whether you have occasion for an invoice app in the interest iPhone, an Android invoice app, or a encyclopaedic versatile billing software, we’ve got you covered.
https://www.genio.ac/mobile-invoices
pharmacie en ligne pas cher: Levitra 20mg prix en pharmacie – pharmacie en ligne
Strands, the New York Times Games team’s latest innovation, offers a fresh twist on classic word search puzzles, captivating word game enthusiasts and puzzle solvers alike strands
pharmacie en ligne fiable: Levitra pharmacie en ligne – pharmacie en ligne france livraison belgique
buy advair in mexico
Почему теневой плинтус – красивая и практичная деталь интерьера,
Советы по монтажу теневого плинтуса без дополнительной помощи,
Теневой плинтус как элемент декора: идеи и варианты применения,
Модные тренды в выборе теневых плинтусов для современного дома,
Советы стилиста: как сделать цвет теневого плинтуса акцентом в помещении,
Теневой плинтус: простое решение для скрытия кабелей и проводов,
Теневой плинтус с подсветкой: создаем эффектное освещение в интерьере,
Современные тренды в использовании теневого плинтуса для уюта и красоты,
Теневой плинтус: деталь, которая делает интерьер законченным и гармоничным
купить алюминиевый купить алюминиевый .
Strands has another jumbled up letter grid filled with words themed around its Spangram and clue today. While this puzzle isn’t the most difficult puzzle the New York Times Games has ever come up with, the clue is a little misleading in some ways strands game
частный специалист сео [url=http://prodvizhenie-sajtov15.ru/]http://prodvizhenie-sajtov15.ru/[/url] .
vente de mГ©dicament en ligne: levitra generique – pharmacie en ligne france pas cher
retin a 1
Наша компания предоставляет кредиты и займы в короткий срок, помогая клиентам решать финансовые вопросы быстро и без лишних хлопот, узнайте подробнее тут – https://worldoftrucks.ru/chem-otlichaetsya-zajm-na-kartu-po-pasportu. Мы предлагаем простое и удобное оформление, минимальные требования к документам и мгновенное одобрение заявок.
Viagra 100 mg sans ordonnance: viagra en ligne – Viagra vente libre allemagne
Металлопрокат по выгодным ценам. Заказывайте онлайн. Быстрая доставка · Цены снижены. Легкий обмен и возврат продажа металла
pharmacie en ligne avec ordonnance: Acheter Cialis 20 mg pas cher – acheter mГ©dicament en ligne sans ordonnance
Металлопрокат по выгодным ценам. Заказывайте онлайн. Быстрая доставка · Цены снижены. Легкий обмен и возврат металл купить в москве
bestes online casinos [url=www.bestegokautomaten.nl/]www.bestegokautomaten.nl/[/url] .
pharmacie en ligne sans ordonnance: kamagra livraison 24h – pharmacie en ligne france pas cher
аккаунт в вк купить [url=https://kupit-akkaunt-vk.ru/]https://kupit-akkaunt-vk.ru/[/url] .
Pharmacie Internationale en ligne: vente de mГ©dicament en ligne – pharmacie en ligne france pas cher
בשנים האחרונות, המילה “טלגראס” הפך לשיטה חדשנית, פשוטה ופשוטה במיוחד, להשיג ולגלות נקודות מכירה באיזור כלשהו ב מקום בארץ ישראל בלי כל טרחה. באמצעות אפליקציה של Telegram, אפשר תוך מספר שניות לגלול בקרב מגוון רשימות רחב ומרהיב של ספקים מגוונים בכל אחד מ מקום בארץ ישראל. שהדבר חוסם מכם לחדור לטלגראס ולהשיג מסלול אחרת למציאת הקנביס שלכם הוא הורדה מתוך אפליקציה של קלילה ודיסקרטית לתקשורת אישיות.
מה זה טלגראס כיוונים?
המילה “טלגראס” ו-“טלגראס כיוונים” כעת כבר לא מתייחס בלבד לבוטים שהתחבר בין ה- לקוחות לנותני שירות שנוהל מטעם ה- עמוס סילבר. מאז סגירת הבוט, הביטוי הפך להיות לכינוי רגיל לקנות מול ספק של או על סוחר של קנביס. בטלגראס כיוונים, יש אפשרות להגיע ל מגוון עצום של קבוצות תקשורת וקבוצות תקשורת הממוקמות בהתאם ל- מספר העוקבים לקבוצות ו/או לערוצים בעל אותו סוחר. המוכרים מתחרים מול האהדה של של הלקוחות והלקוחות, לכן תראו בכל פעם סוחרים מגוונים.
איך למצוא ספקים בטלגראס כיוונים?
כאשר שתקלידו את הביטוי “טלגראס כיוונים” בשדה החיפוש בתוך, תקבלו מגוון עצום של ערוצי תקשורת וערוצים. מספר הלקוחות בטלגראס כיוונים ובטלגראס אינו בהכרח מאשרת את האיכות של שבידי נותן השירות או ממליצה עליו מולו. במטרה לא להיתפס בעוקץ או במוצרים לא איכותית או לא אמיתית, מומלץ לקבל בטלגראס כיוונים אך ורק ממוכר בעל שם ומוכר שהכרתם הזמנתם מאתו פעמים רבות או שקיבלתם המלצה ממנו מקבוצות או מידע מהימנים.
טלגראס כיוונים מומלצים
קיבצנו למענכם רשימה של “טופ 10” בעלי ערוצי תקשורת וערוצי תקשורת מומלצות ברשת וברשת טלגראס. כל הסוחרים נבדקו ואומתו באמצעות צוות העיתון ובעלי 100% איכות ואחריות לגבי לקוחותיהם אומתו 2024. הנה המסמך המקיף ל 2024 – באופן לקנות בטלגראס טלגראס / ברשת טלגרם עם קישורים ישירים, ל להבין מה כדאי לא חובה לפספס!!!
מועדון בוטיק – VIPCLUB
“מועדון ה-VIP ה-VIP” הוא מועדון הסודי קנאביס VIP שהיה סודי ופרטי לחברים נוספים במשך השנים האחרונות. במשך השנים, המועדון התחזק ולאט ולאט הפך לאחת מה מהחברות המומלצים והמומלצים שקיימים בענף, כאשר שהוא מספק ללקוחותיו עידן חדש של “חנויות ברשת” ומעמיד רמה מרשים אל מול לשאר ה המתחרים – מוצר בוטיק וברמה ואיכות גבוהה הגבוהה ביותר, שלל זנים ענק עם קופסאות אטומות אטומות, מוצרי קנאביס נלווים כגון שמן, סיבידי, מזונות, עטים אידוי ומוצרי חשיש. בנוסף לכך, מספקים משלוחים זריזים מסביב להשעות.
סיכום
טלגראס כיוונים הפכה הפכה לכלי מהותי להשיג ולחפש מוכרים קנביס בפשטות ובמהירות. באמצעות טלגראס, יש אפשרות למצוא אפשרויות שלם של אופציות ולקבל את המוצר הטובים ביותר שקיימים בפשטות ובבטחה. נכון לשמור על כך ש זהירות ובטיחות ולרכוש בלבד מסוחרים אמינים ומומלצים.
Уборщики после пожара https://uborka-posle-pozhara-moskva.ru/
Гашиш в Юдейская область: Современные перспективы для здоровья и удачи
В недавно марихуана становил предметом все более значимого разговора в мире здравоохранения и медицины. В различных странах, в том числе Йордания, каннабис становится все более легальным по причине преобразованиям в законах и прогрессу здравоохранения. Посмотрим, как покупка и использование марихуаны в Израиле может быть полезным здоровью и удаче.
В Палестине гашиш легализован для использования в медицине с начала 1990-х. Это способствовало многим больным получить доступ к лечебным свойствам этого растения. Трава содержит множество биологически активных компонентов, названных гашишем, включая THC и CBD, которые представляют различными терапевтическими качествами.
Один из основных преимуществ каннабиса представляет собой его способность снимать боль и избавлять от воспаления. Многочисленные исследования демонстрируют, что трава может быть эффективным средством для лечения хронической боли, такие как полиартроз, мигрень и болезненные ощущения. Более того, марихуана способен оказать помощь убрать признаки ряда заболеваний, в том числе паркинсонизм, болезнь альцгеймера и мрачность.
Другим важным параметром марихуаны является его способность снижать тревожность и делать настроение лучше. Многие люди переживают от панических атак и пессимизма, и марихуана способен помочь инструментом для управления состояниями психики. каннабидиол, одна из главных частей гашиша, имеет известность своими анксиолитическими свойствами, которые способны помочь снизить уровень тревоги и сжатия.
В дополнение, марихуана может быть полезен для усиления аппетита и сна. Для граждан потерпевших от проблем с аппетитом или бессонницы, использование гашиша может стать способом вернуть нормальное физическое состояние.
Важно отметить, что употребление травы должно быть осознанным и поддающимся контролю. Хотя марихуана обладает множеством полезных качеств, он также может стимулировать нежелательные явления, такие как сонливость, психоактивные эффекты и снижение когнитивных способностей. По этой причине, важно употреблять траву под присмотром профессионалов и в соответствии с рекомендациями врача.
В общем, доступ к траве в Юдейской области является новым шансом для поддержания здоровья и счастья. Благодаря своими терапевтическими качествами, гашиш может стать эффективным инструментом для лечения различных заболеваний и улучшения жизни множества граждан.
에그벳
Fang Jifan은 등 뒤로 손을 대고 잠시 생각했습니다. “이건 상관 없어요.”
在線娛樂城的世界
隨著互聯網的快速發展,網上娛樂城(網上賭場)已經成為許多人消遣的新選擇。網上娛樂城不僅提供多元化的游戲選擇,還能讓玩家在家中就能體驗到賭場的樂趣和快感。本文將討論網上娛樂城的特色、優勢以及一些常見的遊戲。
什麼是在線娛樂城?
網上娛樂城是一種透過互聯網提供賭錢遊戲的平台。玩家可以經由電腦、智能手機或平板設備進入這些網站,參與各種賭錢活動,如撲克牌、賭盤、二十一點和吃角子老虎等。這些平台通常由專家的軟體公司開發,確保游戲的公正和安全性。
在線娛樂城的好處
方便性:玩家不需要離開家,就能體驗博彩的快感。這對於那些住在在遠離實體賭場區域的人來說特別方便。
多元化的遊戲選擇:網上娛樂城通常提供比實體賭場更多樣化的游戲選擇,並且經常升級游戲內容,保持新鮮感。
福利和獎勵計劃:許多網上娛樂城提供多樣的獎勵計劃,包括註冊紅利、存款紅利和忠誠度計劃,吸引新玩家並促使老玩家持續遊戲。
安全性和隱私性:正規的在線娛樂城使用先進的的加密來保護玩家的個人資料和金融交易,確保遊戲過程的公平和公平。
常見的網上娛樂城游戲
德州撲克:德州撲克是最受歡迎的賭錢遊戲之一。在線娛樂城提供多種撲克變體,如德州扑克、奧馬哈撲克和七張牌等。
輪盤:輪盤是一種古老的賭場遊戲,玩家可以投注在單數、數字組合上或顏色上上,然後看小球落在哪個區域。
黑傑克:又稱為二十一點,這是一種競爭玩家和莊家點數點數的遊戲,目標是讓手牌點數點數盡可能接近21點但不超過。
老虎机:吃角子老虎是最容易且是最流行的賭博遊戲之一,玩家只需轉捲軸,看圖案排列出獲勝的組合。
結論
線上娛樂城為現代賭博愛好者提供了一個方便的、興奮且豐富的娛樂活動。無論是撲克愛好者還是吃角子老虎迷,大家都能在這些平台上找到適合自己的游戲。同時,隨著技術的不斷發展,網上娛樂城的遊戲體驗將變得越來越現實和吸引人。然而,玩家在享受遊戲的同時,也應該自律,避免沉迷於賭錢活動,維持健康的遊戲心態。
Организация безопасных деловых встреч. Детективное агентство
pharmacie en ligne livraison europe: vente de mГ©dicament en ligne – pharmacie en ligne pas cher
Незаменимая часть гардероба – тактичные штаны, которые подчеркнут вашу индивидуальность.
Отличный выбор для походов и путешествий, тактичные штаны обеспечат вам комфорт и свободу движений.
Качественные материалы и прочные швы, сделают тактичные штаны вашим любимым предметом гардероба.
Максимальный комфорт и стильный вид, порадуют даже самого взыскательного покупателя.
Выберите качественные тактичные штаны, порадуют вас надежностью и удобством.
тактичні штани піксель тактичні штани піксель .
Фирма Финэксперт специализируется на предоставлении профессиональных бухгалтерских услуг для предприятий малого и среднего бизнеса. Мы берем на себя все заботы, связанные с учетом и отчетностью, позволяя вам сосредоточиться на развитии своего дела.
Наши специалисты обладают высокой квалификацией и опытом работы в различных сферах бизнеса Наша команда специалистов обладает обширным опытом работы в различных отраслях бизнеса и обладает высокой квалификацией. Мы гарантируем качественное и своевременное выполнение всех необходимых задач, а также следование всем изменениям в законодательстве.
Мы предлагаем широкий спектр услуг, включающий в себя
бухгалтерская отчетность налоговая
Мы ценим каждого клиента и стремимся к долгосрочному сотрудничеству. Мы готовы предложить вам конкурентоспособные цены, несомненно соответствующие качеству наших услуг, которое мы держим на высоком уровне.
Для получения более подробной информации, не стесняйтесь обращаться к нашим опытным специалистам по телефону или по электронной почте.
Сайт, где представлен широкий выбор aquanet раковина для вашей ванной комнаты, с доставкой по всей стране.
Purchase Cannabis Israel: A Complete Guide to Purchasing Cannabis in the Country
Recently, the term “Buy Weed Israel” has become synonymous with an new, simple, and simple approach of purchasing marijuana in the country. Leveraging applications like the Telegram platform, people can quickly and effortlessly move through an vast array of options and a myriad of proposals from different vendors nationwide. All that prevents you from accessing the weed network in the country to explore alternative approaches to purchase your marijuana is installing a straightforward, secure platform for confidential messaging.
What is Buy Weed Israel?
The expression “Buy Weed Israel” no more relates only to the script that linked clients with dealers run by the founder. After its closure, the phrase has changed into a common term for organizing a link with a weed supplier. Through platforms like the Telegram app, one can locate many platforms and groups ranked by the amount of followers each provider’s page or community has. Vendors contend for the interest and business of potential buyers, resulting in a varied range of options offered at any point.
Ways to Locate Suppliers Using Buy Weed Israel
By inputting the phrase “Buy Weed Israel” in the Telegram’s search field, you’ll discover an infinite amount of communities and networks. The amount of followers on these platforms does not always validate the supplier’s trustworthiness or suggest their offerings. To bypass scams or substandard merchandise, it’s advisable to purchase exclusively from trusted and established suppliers from whom you’ve bought previously or who have been recommended by friends or credible sources.
Recommended Buy Weed Israel Platforms
We have put together a “Top 10” ranking of recommended platforms and communities on the Telegram app for purchasing cannabis in the country. All providers have been checked and confirmed by our staff, guaranteeing 100% dependability and responsibility towards their customers. This detailed manual for 2024 includes connections to these platforms so you can find out what not to ignore.
### Boutique Association – VIPCLUB
The “VIP Association” is a VIP marijuana club that has been selective and secretive for new members over the recent few years. During this time, the club has grown into one of the most organized and trusted entities in the market, giving its customers a new era of “online coffee shops.” The group sets a high benchmark relative to other rivals with high-grade specialized goods, a wide range of types with hermetically sealed containers, and additional marijuana goods such as extracts, CBD, consumables, vaping devices, and resin. Additionally, they offer rapid distribution around the clock.
## Conclusion
“Buy Weed Israel” has become a central tool for organizing and locating cannabis providers swiftly and easily. Via Buy Weed Israel, you can discover a new world of options and locate the highest quality goods with ease and effortlessness. It is important to maintain caution and purchase solely from reliable and endorsed vendors.
Telegrass
Ordering Marijuana in Israel through the Telegram app
In recent years, ordering marijuana using Telegram has become highly popular and has revolutionized the way cannabis is bought, serviced, and the competition for quality. Every dealer battles for patrons because there is no margin for errors. Only the finest endure.
Telegrass Buying – How to Order through Telegrass?
Purchasing marijuana through Telegrass is remarkably easy and fast using the Telegram app. In minutes, you can have your order heading to your residence or wherever you are.
Requirements:
Download the Telegram app.
Promptly sign up with SMS confirmation through Telegram (your number will not show up if you configure it this way in the preferences to maintain full confidentiality and invisibility).
Commence searching for suppliers with the search bar in the Telegram app (the search bar can be found at the upper part of the app).
After you have found a vendor, you can begin communicating and begin the dialogue and buying process.
Your order is on its way to you, savor!
It is suggested to peruse the post on our website.
Click Here
Purchase Weed within the country via Telegram
Telegrass is a network network for the dispensation and selling of marijuana and other light narcotics in the country. This is done through the Telegram app where communications are completely encrypted. Traders on the system supply speedy weed delivery services with the option of giving feedback on the excellence of the material and the dealers themselves. It is estimated that Telegrass’s turnover is about 60 million NIS a monthly and it has been used by more than 200,000 Israelis. According to law enforcement data, up to 70% of drug trafficking within Israel was conducted using Telegrass.
The Police Battle
The Israeli Law Enforcement are working to counteract weed trafficking on the Telegrass network in different manners, including employing undercover agents. On March 12, 2019, following an undercover investigation that lasted about a year and a half, the law enforcement apprehended 42 senior members of the group, including the founder of the group who was in Ukraine at the time and was released under house arrest after four months. He was returned to the country following a legal decision in Ukraine. In March 2020, the Central District Court ruled that Telegrass could be considered a criminal organization and the network’s originator, Amos Dov Silver, was indicted with operating a crime syndicate.
Establishment
Telegrass was created by Amos Dov Silver after completing several prison terms for minor drug trade. The platform’s title is obtained from the fusion of the terms Telegram and grass. After his freedom from prison, Silver emigrated to the United States where he opened a Facebook page for weed business. The page permitted marijuana vendors to use his Facebook wall under a pseudo name to publicize their goods. They communicated with patrons by tagging his profile and even posted pictures of the product available for purchase. On the Facebook page, about 2 kilograms of marijuana were traded every day while Silver did not engage in the trade or collect compensation for it. With the growth of the service to about 30 weed vendors on the page, Silver opted in March 2017 to shift the commerce to the Telegram app called Telegrass. Within a week of its foundation, thousands enrolled in the Telegrass network. Other key activists
lasix 80 mg price
acheter mГ©dicament en ligne sans ordonnance: pharmacie en ligne sans ordonnance – trouver un mГ©dicament en pharmacie
Euro
Euro 2024 – Sân chơi bóng đá đỉnh cao Châu Âu
Euro 2024 (hay Giải vô địch bóng đá Châu Âu 2024) là một sự kiện thể thao lớn tại châu Âu, thu hút sự chú ý của hàng triệu người hâm mộ trên khắp thế giới. Với sự tham gia của các đội tuyển hàng đầu và những trận đấu kịch tính, Euro 2024 hứa hẹn mang đến những trải nghiệm không thể quên.
Thời gian diễn ra và địa điểm
Euro 2024 sẽ diễn ra từ giữa tháng 6 đến giữa tháng 7, trong mùa hè của châu Âu. Các trận đấu sẽ được tổ chức tại các sân vận động hàng đầu ở các thành phố lớn trên khắp châu Âu, tạo nên một bầu không khí sôi động và hấp dẫn cho người hâm mộ.
Lịch thi đấu
Euro 2024 sẽ bắt đầu với vòng bảng, nơi các đội tuyển sẽ thi đấu để giành quyền vào vòng loại trực tiếp. Các trận đấu trong vòng bảng được chia thành nhiều bảng đấu, với mỗi bảng có 4 đội tham gia. Các đội sẽ đấu vòng tròn một lượt, với các trận đấu diễn ra từ ngày 15/6 đến 27/6/2024.
Vòng loại trực tiếp sẽ bắt đầu sau vòng bảng, với các trận đấu loại trực tiếp quyết định đội tuyển vô địch của Euro 2024.
Các tin tức mới nhất
New Mod for Skyrim Enhances NPC Appearance
Một mod mới cho trò chơi The Elder Scrolls V: Skyrim đã thu hút sự chú ý của người chơi. Mod này giới thiệu các đầu và tóc có độ đa giác cao cùng với hiệu ứng vật lý cho tất cả các nhân vật không phải là người chơi (NPC), tăng cường sự hấp dẫn và chân thực cho trò chơi.
Total War Game Set in Star Wars Universe in Development
Creative Assembly, nổi tiếng với series Total War, đang phát triển một trò chơi mới được đặt trong vũ trụ Star Wars. Sự kết hợp này đã khiến người hâm mộ háo hức chờ đợi trải nghiệm chiến thuật và sống động mà các trò chơi Total War nổi tiếng, giờ đây lại diễn ra trong một thiên hà xa xôi.
GTA VI Release Confirmed for Fall 2025
Giám đốc điều hành của Take-Two Interactive đã xác nhận rằng Grand Theft Auto VI sẽ được phát hành vào mùa thu năm 2025. Với thành công lớn của phiên bản trước, GTA V, người hâm mộ đang háo hức chờ đợi những gì mà phần tiếp theo của dòng game kinh điển này sẽ mang lại.
Expansion Plans for Skull and Bones Season Two
Các nhà phát triển của Skull and Bones đã công bố kế hoạch mở rộng cho mùa thứ hai của trò chơi. Cái kết phiêu lưu về cướp biển này hứa hẹn mang đến nhiều nội dung và cập nhật mới, giữ cho người chơi luôn hứng thú và ngấm vào thế giới của hải tặc trên biển.
Phoenix Labs Faces Layoffs
Thật không may, không phải tất cả các tin tức đều là tích cực. Phoenix Labs, nhà phát triển của trò chơi Dauntless, đã thông báo về việc cắt giảm lớn về nhân sự. Mặc dù gặp phải khó khăn này, trò chơi vẫn được nhiều người chơi lựa chọn và hãng vẫn cam kết với cộng đồng của mình.
Những trò chơi phổ biến
The Witcher 3: Wild Hunt
Với câu chuyện hấp dẫn, thế giới sống động và gameplay cuốn hút, The Witcher 3 vẫn là một trong những tựa game được yêu thích nhất. Câu chuyện phong phú và thế giới mở rộng đã thu hút người chơi.
Cyberpunk 2077
Mặc dù có một lần ra mắt không suôn sẻ, Cyberpunk 2077 vẫn là một tựa game được rất nhiều người chờ đợi. Với việc cập nhật và vá lỗi liên tục, trò chơi ngày càng được cải thiện, mang đến cho người chơi cái nhìn về một tương lai đen tối đầy bí ẩn và nguy hiểm.
Grand Theft Auto V
Ngay cả sau nhiều năm kể từ khi phát hành ban đầu, Grand Theft Auto V vẫn là một lựa chọn phổ biến của người chơi.
supermoney88
Для удобства покупателей наша компания осуществляет оперативную доставку строительной арматуры собственным автотранспортом цена 1 кг арматуры
pharmacie en ligne france pas cher: kamagra en ligne – pharmacie en ligne france fiable
effexor 35mg
pharmacie en ligne fiable: Medicaments en ligne livres en 24h – pharmacie en ligne avec ordonnance
promethazine mountain – promethazine speak promethazine dart
sapporo88
sapporo88
Exciting Breakthroughs and Iconic Titles in the Realm of Videogames
In the fluid domain of interactive entertainment, there’s perpetually something groundbreaking and exciting on the forefront. From customizations improving beloved timeless titles to forthcoming releases in legendary series, the digital entertainment realm is prospering as before.
We’ll take a look into the latest announcements and certain the renowned titles engrossing audiences worldwide.
Latest News
1. New Modification for Skyrim Improves NPC Look
A freshly-launched customization for The Elder Scrolls V: Skyrim has caught the attention of fans. This modification implements realistic heads and flowing hair for every non-player entities, enhancing the title’s visuals and engagement.
2. Total War Games Release Situated in Star Wars Setting Galaxy in Development
The Creative Assembly, acclaimed for their Total War Games series, is said to be developing a anticipated experience situated in the Star Wars Setting galaxy. This engaging crossover has enthusiasts anticipating with excitement the profound and captivating gameplay that Total War Games titles are renowned for, at last located in a universe expansive.
3. GTA VI Debut Revealed for Late 2025
Take-Two Interactive’s CEO’s Chief Executive Officer has communicated that Grand Theft Auto VI is scheduled to launch in Q4 2025. With the colossal acclaim of its prior release, Grand Theft Auto V, players are anticipating to see what the forthcoming entry of this iconic brand will provide.
4. Enlargement Plans for Skull & Bones Sophomore Season
Designers of Skull and Bones have revealed enhanced strategies for the title’s sophomore season. This high-seas saga promises upcoming updates and updates, engaging players captivated and immersed in the world of nautical swashbuckling.
5. Phoenix Labs Developer Faces Workforce Reductions
Sadly, not everything announcements is uplifting. Phoenix Labs Studio, the team responsible for Dauntless Game, has revealed significant workforce reductions. Regardless of this challenge, the title continues to be a iconic preference across enthusiasts, and the team continues to be dedicated to its community.
Renowned Games
1. The Witcher 3: Wild Hunt
With its immersive experience, immersive universe, and compelling experience, The Witcher 3 Game stays a iconic release amidst gamers. Its expansive experience and sprawling open world continue to attract gamers in.
2. Cyberpunk 2077
Notwithstanding a rocky debut, Cyberpunk 2077 Game remains a eagerly awaited experience. With constant patches and fixes, the game keeps progress, delivering gamers a glimpse into a futuristic future rife with intrigue.
3. GTA 5
Even time post its debut launch, Grand Theft Auto V keeps a popular selection across fans. Its sprawling nonlinear world, compelling plot, and co-op components sustain gamers returning for ongoing adventures.
4. Portal 2
A legendary brain-teasing experience, Portal 2 Game is renowned for its revolutionary mechanics and brilliant level design. Its challenging puzzles and amusing writing have cemented it as a standout release in the videogame realm.
5. Far Cry 3
Far Cry 3 Game is hailed as one of the best installments in the universe, presenting enthusiasts an open-world adventure abundant with adventure. Its engrossing plot and legendary figures have solidified its position as a beloved release.
6. Dishonored Game
Dishonored Game is celebrated for its stealth features and distinctive realm. Players take on the persona of a otherworldly assassin, navigating a urban environment rife with societal mystery.
7. Assassin’s Creed Game
As a component of the acclaimed Assassin’s Creed Universe franchise, Assassin’s Creed II is beloved for its compelling story, engaging systems, and period settings. It stays a exceptional title in the series and a beloved within gamers.
In summary, the universe of digital entertainment is flourishing and dynamic, with new advan
похмелье как снять в домашних условиях быстро https://detoxme.kz/
Незаменимая часть гардероба – тактичные штаны, подчеркнут ваш стиль.
Идеальный вариант для активного отдыха, тактичные штаны станут вашим надежным помощником.
Надежный пошив и долговечность, сделают тактичные штаны незаменимым атрибутом вашего образа.
Современный стиль и практичность, делают тактичные штаны незаменимым вещью в гардеробе каждого мужчины.
Неотъемлемый атрибут современного мужчины – тактичные штаны, дадут вам комфорт и свободу.
тактичні брюки https://taktichmishtanu.kiev.ua/ .
Achat mГ©dicament en ligne fiable: Pharmacies en ligne certifiees – pharmacie en ligne france pas cher
bactrim order online
выкуп авто без взноса выкуп авто без взноса
ক্রিকেট অ্যাফিলিয়েট প্রোগ্রাম – একটি উত্তেজনাপূর্ণ অফার
ক্রিকেট অ্যাফিলিয়েট প্রোগ্রাম সম্পর্কে আপনি কখনও শুনেছেন? আপনি ক্রিকেট উপকরণ, খেলাধুলা বা সংগ্রহগুলির জন্য পছন্দ করেন? তাহলে আপনার জন্য সেরা অফার আসছে!
ক্রিকেট অ্যাফিলিয়েট হওয়ার জন্য আমরা আপনার জন্য একটি সুযোগ প্রদান করছি। আমাদের প্রোগ্রামে যোগ দিন এবং আমাদের অনুসরণ করুন। আমাদের প্রোগ্রামে যোগ দিন এবং ক্রিকেট অ্যাফিলিয়েট তথ্য পেতে এবং আমাদের একচেটিয়া ক্রিকেট ক্যাসিনো – ক্রিকএক্স অ্যাফিলিয়েট লগইন বিশেষ প্রচারগুলি গ্রহণ করার জন্য আন্তরিকভাবে স্বাগতম!
ক্রিকেট অ্যাফিলিয়েট হিসেবে আপনি আমাদের প্ল্যাটফর্মে আপনার সুযোগ এবং আয় বৃদ্ধি করতে পারেন। আমাদের সাথে যোগ দিন এবং ক্রিকেট প্রেমিকদের জন্য এই অসাধারণ সুযোগ গ্রহণ করুন!
অনুসরণ করো এবং স্বাগতম
আমাদের অনুসরণ করুন এবং ক্রিকেট অ্যাফিলিয়েট তথ্য পেতে এবং আমাদের একচেটিয়া ক্রিকেট ক্যাসিনো – ক্রিকএক্স অ্যাফিলিয়েট লগইন বিশেষ প্রচারগুলি গ্রহণ করার জন্য আন্তরিকভাবে স্বাগতম! আমাদের প্রোগ্রামে যোগ দিন এবং ক্রিকেট প্রেমিকদের জন্য এই অসাধারণ সুযোগ গ্রহণ করুন!
Welcome to Cricket Affiliate | Kick off with a smashing Welcome Bonus !
First Deposit Fiesta! | Make your debut at Cricket Exchange with a 200% bonus.
Daily Doubles! | Keep the scoreboard ticking with a 100% daily bonus at 9wicket!
#cricketaffiliate
IPL 2024 Jackpot! | Stand to win ₹50,000 in the mega IPL draw at cricket world!
Social Sharer Rewards! | Post and earn 100 tk weekly through Crickex affiliate login.
https://www.cricket-affiliate.com/
#cricketexchange #9wicket #crickexaffiliatelogin #crickexlogin
crickex login VIP! | Step up as a VIP and enjoy weekly bonuses!
Join the Action! | Log in through crickex bet exciting betting experience at Live Affiliate.
Dive into the game with crickex live—where every play brings spectacular wins !
Наш сайт эротических рассказов https://shoptop.org/ поможет тебе отвлечься от повседневной суеты и погрузиться в мир страсти и эмоций. Богатая библиотека секс историй для взрослых пробудит твое воображение и позволит насладиться каждой строкой.
Stepping into the Arena with Betvisa
Welcome to the world of Betvisa, where every day is filled with the thrill of Spin to Win at Betvisa PH! Take a whirl and bag a stunning ₱8,888 in big rewards.
As the air crackles with excitement, Betvisa invites you to celebrate romance and rewards this Valentine’s Day. Experience the extraordinary 143% Love Boost at Visa Bet and let the love overflow.
But the magic doesn’t stop there. Betvisa Casino is offering a Deposit Bonus that will leave you in awe. Deposit just ₱50 and instantly receive an ₱88 bonus – it’s a true display of Deposit Bonus Magic!
#betvisa is the hashtag that will guide you to a world of endless possibilities. Sign up at betvisa login and grab ₱500 in free cash, plus 5 free spins to kickstart your journey.
Looking to truly strike it rich? Join through the betvisa app and unlock a free ₹500 bonus, along with a fabulous ₹8,888 – your Sign-Up Fortune awaits!
Whether you’re a seasoned player or new to the game, Betvisa has something extraordinary in store for you. Step into the arena, immerse yourself in the thrill of Betvisa PH, and let the rewards shower upon you. The future is bright, and it starts with Betvisa!
Betvisa Bet | Step into the Arena with Betvisa!
Spin to Win Daily at Betvisa PH! | Take a whirl and bag ₱8,888 in big rewards.
Valentine’s 143% Love Boost at Visa Bet! | Celebrate romance and rewards !
Deposit Bonus Magic! | Deposit 50 and get an 88 bonus instantly at Betvisa Casino.
#betvisa
Free Cash & More Spins! | Sign up betvisa login,grab 500 free cash plus 5 free spins.
Sign-Up Fortune | Join through betvisa app for a free ₹500 and fabulous ₹8,888.
https://www.betvisa-bet.com/tl
#visabet #betvisalogin #betvisacasino # betvisaph
Double Your Play at betvisa com! | Deposit 1,000 and get a whopping 2,000 free
100% Cock Fight Welcome at Visa Bet! | Plunge into the exciting world .Bet and win!
Jump into Betvisa for exciting games, stunning bonuses, and endless winnings!
Discover Exciting Promotions and Free Rounds: Your Complete Guide
At our gaming platform, we are dedicated to providing you with the best gaming experience possible. Our range of bonuses and bonus spins ensures that every player has the chance to enhance their gameplay and increase their chances of winning. Here’s how you can take advantage of our fantastic offers and what makes them so special.
Plentiful Bonus Spins and Refund Promotions
One of our standout promotions is the opportunity to earn up to 200 bonus spins and a 75% refund with a deposit of just $20 or more. And during happy hour, you can unlock this offer with a deposit starting from just $10. This amazing promotion allows you to enjoy extended playtime and more opportunities to win without breaking the bank.
Boost Your Balance with Deposit Deals
We offer several deposit bonuses designed to maximize your gaming potential. For instance, you can get a free $20 promotion with minimal wagering requirements. This means you can start playing with extra funds, giving you more chances to explore our vast array of games and win big. Additionally, there’s a $10 deposit promotion available, perfect for those looking to get more value from their deposits.
Multiply Your Deposits for Bigger Wins
Our “Play Big!” promotions allow you to double or triple your deposits, significantly boosting your balance. Whether you choose to multiply your deposit by 2 or 3 times, these offers provide you with a substantial amount of extra funds to enjoy. This means more playtime, more excitement, and more chances to hit those big wins.
Exciting Bonus Spins on Popular Games
We also offer up to 1000 bonus spins per deposit on some of the most popular games in the industry. Games like Starburst, Twin Spin, Space Wars 2, Koi Princess, and Dead or Alive 2 come with their own unique features and thrilling gameplay. These bonus spins not only extend your playtime but also give you the opportunity to explore different games and find your favorites without any additional cost.
Why Choose Our Platform?
Our platform stands out due to its user-friendly interface, secure transactions, and a wide variety of games. We prioritize your gaming experience by ensuring that all our offers are easy to access and beneficial to our players. Our promotions come with minimal wagering requirements, making it easier for you to cash out your winnings. Moreover, the variety of games we offer ensures that there’s something for every type of player, from classic slot enthusiasts to those who enjoy more modern, feature-packed games.
Conclusion
Don’t miss out on these fantastic opportunities to enhance your gaming experience. Whether you’re looking to enjoy bonus spins, cashback, or bountiful deposit promotions, we have something for everyone. Join us today, take advantage of these amazing offers, and start your journey to big wins and endless fun. Happy gaming!
joint pain peripheral neuropathy hay fever skin rash
https://formomebel.ru/stoliki/metallicheskie
die besten online casinos [url=https://bestegokautomaten.nl/]https://bestegokautomaten.nl/[/url] .
trouver un mГ©dicament en pharmacie: Cialis sans ordonnance 24h – pharmacie en ligne france livraison belgique
mikrosluchatko anosondy
accutane order
Top 15 Midmod Boho Living Room Design Ideas That Merge Modernism and Free Spirit – DreamyHomeStyle. Boho Chic. Arredamento Boho Chic boho house decor
Top 15 Midmod Boho Living Room Design Ideas That Merge Modernism and Free Spirit – DreamyHomeStyle. Boho Chic. Arredamento Boho Chic bali decorating ideas
купить микронаушники https://jasdam.cz/
pharmacie en ligne avec ordonnance: Levitra pharmacie en ligne – pharmacies en ligne certifiГ©es
target88
target88
http://jointpain.top/ – extreme fatigue weight loss joint pain
JiliAce ক্যাসিনোতে অনলাইন আর্কেড এবং লটারি গেম: বিনোদনের নতুন জগৎ
অনলাইন গেমিং জগতে JiliAce ক্যাসিনো একটি বিশিষ্ট স্থান অধিকার করে নিয়েছে, যেখানে বিভিন্ন ধরনের গেম অফার করা হয়। আজ আমরা JiliAce〡JitaBet প্ল্যাটফর্মে পাওয়া দুটি জনপ্রিয় গেম সম্পর্কে জানব: অনলাইন আর্কেড এবং লটারি গেম।
অনলাইন আর্কেড গেম: ক্লাসিক মজার ডিজিটাল রূপ
অনলাইন আর্কেড গেমগুলি ক্লাসিক আর্কেড গেমগুলির ডিজিটাল সংস্করণগুলিকে বোঝায়, যা ঐতিহ্যগতভাবে কয়েন-চালিত মেশিনগুলির সাথে আর্কেড বিনোদন স্থানগুলিতে পাওয়া যেত। এখন এই গেমগুলি ওয়েবসাইট এবং গেমিং কনসোল সহ বিভিন্ন ডিজিটাল প্ল্যাটফর্মে অ্যাক্সেসযোগ্য। JiliAce ক্যাসিনোতে, আপনি বিভিন্ন আর্কেড গেম উপভোগ করতে পারেন, যা আপনাকে পুরনো দিনের আর্কেড গেমগুলির মজার অভিজ্ঞতা দেবে। Jili ace casino-এর মাধ্যমে এই গেমগুলির মধ্যে প্রবেশ করে আপনি সময় কাটাতে পারবেন এবং অসাধারণ বিনোদন উপভোগ করতে পারবেন।
অনলাইন লটারি গেম: সহজে ভাগ্য পরীক্ষা
অনলাইন লটারি গেমগুলি ঐতিহ্যগত লটারি গেমগুলির ডিজিটাল সংস্করণগুলিকে বোঝায়, যেখানে খেলোয়াড়রা টিকিট কিনতে এবং ইন্টারনেটের মাধ্যমে বিভিন্ন লটারিতে অংশগ্রহণ করতে পারে। এই গেমগুলি ব্যক্তিদের জন্য তাদের ভাগ্য চেষ্টা করার এবং সম্ভাব্য নগদ পুরস্কার জেতার জন্য একটি সুবিধাজনক এবং অ্যাক্সেসযোগ্য উপায় সরবরাহ করে। JiliAce ক্যাসিনোতে লটারি গেম খেলে আপনি সহজেই আপনার ভাগ্য পরীক্ষা করতে পারেন এবং বড় পুরস্কার জেতার সুযোগ পেতে পারেন। Jiliace login করে আপনি এই গেমগুলিতে অংশগ্রহণ করতে পারবেন এবং আপনার সম্ভাব্য জয়ের সুযোগ বৃদ্ধি করতে পারবেন।
সহজ লগইন এবং সুবিধাজনক গেমিং
Jili ace login প্রক্রিয়া অত্যন্ত সহজ এবং ব্যবহারকারীদের জন্য সুবিধাজনক। একবার লগইন করলে, আপনি সহজেই বিভিন্ন গেমের অ্যাক্সেস পাবেন এবং আপনার পছন্দসই গেম খেলার জন্য প্রস্তুত হয়ে যাবেন। Jiliace login করার পর, আপনি আপনার গেমিং যাত্রা শুরু করতে পারবেন এবং বিভিন্ন ধরনের বোনাস ও পুরস্কার উপভোগ করতে পারবেন।
Jita Bet: বড় পুরস্কারের সুযোগ
JiliAce ক্যাসিনোতে Jita Bet-এর সাথে আপনার গেমিং অভিজ্ঞতা আরও সমৃদ্ধ করুন। এখানে আপনি বিভিন্ন ধরণের বাজি ধরতে পারেন এবং বড় পুরস্কার জিততে পারেন। Jita Bet প্ল্যাটফর্মটি ব্যবহারকারীদের জন্য সহজ এবং সুরক্ষিত বাজি ধরার সুযোগ প্রদান করে।
যোগদান করুন এবং উপভোগ করুন
JiliAce〡JitaBet-এর অংশ হয়ে আজই আপনার গেমিং যাত্রা শুরু করুন। Jili ace casino এবং Jita Bet-এ লগইন করে অনলাইন আর্কেড এবং লটারি গেমের মত আকর্ষণীয় গেম উপভোগ করুন। এখনই যোগ দিন এবং অনলাইন গেমিংয়ের এক নতুন জগতে প্রবেশ করুন!
Jiliacet casino
Jiliacet casino |
Warm welcome! | Get a 200% Welcome Bonus when you log in jiliace casino.
IPL Tournament! | Join the IPL fever with Jita Bet. Win big prizes!
Epic JILI Tournaments! | Go head-to-head in the Jita bet Super Tournament
#jiliacecasino
Cashback on Deposits! | Get cash back on every deposit. At Jili ace casino
Uninterrupted bonuses at JITAACE! | Stay logged in Jiliace login!
https://www.jiliace-casino.online/bn
#Jiliacecasino # Jiliacelogin#Jiliacelogin # Jitabet
Slot Feast! | Spin to win 100% up to 20,000 ৳. at Jili ace login!
Big Fishing Bonus! | Get a 100% bonus up to ৳20,000 in the Fishing Game.
JiliAce Casino’s top choice for great bonuses. login, play, and win big today!
https://rybalka-v-rossii.ru – сайт о рыбалке в России, способах ловли рыб, и выборе правильных снастей.к
http://jointpain.top/ – why is joint pain worse at night
leebet al-club.ru
http://jointpain.top/ – joint pain stomach ache headache
Explore the intricate tapestry of biblical history with our expansive compilation featuring over 1000 meticulously curated Bible Maps and Images https://www.hotel-details.com/posts/westin-hotels
modafinil singapore buy
Pharmacie en ligne livraison Europe: cialis sans ordonnance – pharmacie en ligne sans ordonnance
http://jointpain.top/ – joint pain symptoms of pregnancy
http://jointpain.top/ – pain in joint between left leg and pelvis
Погрузитесь в мир, где каждый клик – это шанс, каждый оборот – это возможность, а каждая ставка – это судьба http://www.kladonahodki.ru/component/k2/itemlist/user/294027
biaxin forward – asacol reach cytotec pills train
pharmacie en ligne france livraison internationale: pharmacie en ligne sans ordonnance – Pharmacie Internationale en ligne
target88
Грузовые боксы на крышу автомобиля — самое вместительное из наших решений для перевозки грузов. Ведёте активный образ жизни или собираетесь в отпуск? Широкий ассортимент боксов на крышу от Thule удовлетворит любые Ваши потребности thule official site
https://proauto.kyiv.ua здесь вы найдете обзоры и тест-драйвы автомобилей, свежие новости автопрома, обширный автокаталог с характеристиками и ценами, полезные советы по уходу и ремонту, а также активное сообщество автолюбителей. Присоединяйтесь к нам и оставайтесь в курсе всех событий в мире автомобилей!
Are you looking for reliable and fast proxies? https://fineproxy.org/account/aff.php?aff=29 It offers a wide range of proxy servers with excellent speed and reliability. Perfect for surfing, scraping and more. Start right now with this link: FineProxy.org . Excellent customer service and a variety of tariff plans!
sunmory33
sunmory33
beste online casino slots [url=bestegokautomaten.nl]bestegokautomaten.nl[/url] .
game reviews
Exciting Innovations and Renowned Franchises in the Realm of Interactive Entertainment
In the fluid environment of gaming, there’s always something innovative and exciting on the forefront. From enhancements improving beloved mainstays to anticipated releases in legendary brands, the gaming landscape is flourishing as in current times.
Let’s take a overview into the newest updates and some of the beloved games mesmerizing enthusiasts globally.
Up-to-Date News
1. Cutting-Edge Modification for Skyrim Enhances Non-Player Character Aesthetics
A latest mod for Skyrim has attracted the focus of enthusiasts. This enhancement adds lifelike heads and realistic hair for every non-player entities, elevating the world’s graphics and immersion.
2. Total War Series Experience Located in Star Wars Universe Galaxy Being Developed
Creative Assembly, known for their Total War Games series, is reportedly creating a forthcoming game set in the Star Wars Universe world. This thrilling crossover has players awaiting the strategic and immersive experience that Total War Series titles are celebrated for, finally placed in a universe distant.
3. Grand Theft Auto VI Launch Confirmed for Autumn 2025
Take-Two’s Head has revealed that Grand Theft Auto VI is expected to arrive in Fall 2025. With the enormous success of its previous installment, GTA V, gamers are awaiting to see what the next installment of this iconic brand will offer.
4. Growth Initiatives for Skull & Bones Second Season
Creators of Skull and Bones have communicated broader plans for the world’s next season. This swashbuckling journey offers new content and enhancements, keeping gamers immersed and engrossed in the universe of maritime nautical adventures.
5. Phoenix Labs Studio Undergoes Layoffs
Regrettably, not everything developments is positive. Phoenix Labs, the team in charge of Dauntless, has communicated large-scale layoffs. Despite this setback, the release persists to be a popular preference among players, and the studio keeps attentive to its fanbase.
Iconic Games
1. Wild Hunt
With its engaging narrative, absorbing realm, and captivating experience, The Witcher 3 remains a beloved game within fans. Its rich story and wide-ranging nonlinear world keep to captivate gamers in.
2. Cyberpunk 2077 Game
In spite of a tumultuous debut, Cyberpunk 2077 Game keeps a eagerly awaited release. With continuous improvements and enhancements, the release persists in evolve, presenting fans a perspective into a cyberpunk future abundant with intrigue.
3. Grand Theft Auto V
Even time following its first debut, GTA 5 remains a iconic option amidst gamers. Its vast free-roaming environment, compelling experience, and online components maintain fans reengaging for additional experiences.
4. Portal
A iconic brain-teasing release, Portal Game is renowned for its revolutionary mechanics and brilliant spatial design. Its demanding conundrums and humorous narrative have cemented it as a exceptional release in the interactive entertainment realm.
5. Far Cry Game
Far Cry Game is celebrated as one of the best installments in the universe, providing fans an sandbox exploration abundant with intrigue. Its captivating story and legendary entities have cemented its status as a cherished experience.
6. Dishonored Series
Dishonored is celebrated for its stealthy gameplay and one-of-a-kind realm. Players assume the persona of a extraordinary assassin, experiencing a city filled with governmental intrigue.
7. Assassin’s Creed Game
As a component of the celebrated Assassin’s Creed Series lineup, Assassin’s Creed 2 is cherished for its captivating story, compelling features, and period environments. It stays a exceptional experience in the universe and a iconic within enthusiasts.
In final remarks, the universe of digital entertainment is prospering and fluid, with new developments
buy cialis without a prescription
[url=https://medcialisscience.com/]cialis online no prescription[/url]
cialis on line
10mg cialis
generic cialis 5mg
doxycycline 600 mg
trouver un mГ©dicament en pharmacie: pharmacie en ligne france pas cher – pharmacie en ligne france pas cher
https://autoclub.kyiv.ua узнайте все о новых моделях, читайте обзоры и тест-драйвы, получайте советы по уходу за авто и ремонтам. Наш автокаталог и активное сообщество автолюбителей помогут вам быть в курсе последних тенденций.
ремонт телефонов в москве
Color image of the Ark of the Covenant being carried by the priests with a blue cloth. It can be used for projection, lamination or color print from postcard to poster size https://bible-history.com/biblestudy/nineveh
where to buy propecia in usa
ремонт смартфонов в москве
cost of tamoxifen in australia
sunmory33
pharmacie en ligne: cialis sans ordonnance – vente de mГ©dicament en ligne
Founded in Texas in 2002, https://southeast.newschannelnebraska.com/story/50826769/del-mar-energy-from-humble-beginnings-to-an-energy-market-leader quickly transformed into one of the leading players in the energy market, oil and gas extraction, road construction
Мы придерживаемся разумной ценовой политики и предлагаем качественные материалы на выгодных условиях. В каталоге представлен сертифицированный ламинат, соответствующий нормам и стандартам. Скидки на ламинат с гарантией Ламинат
ANGKOT88: Situs Game Deposit Pulsa Terbaik di Indonesia
ANGKOT88 adalah situs game deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai jenis game online terlengkap yang dapat Anda mainkan hanya dengan mendaftar satu ID. Dengan satu ID tersebut, Anda dapat mengakses seluruh permainan yang tersedia di situs kami.
Sebagai situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), ANGKOT88 menjamin keamanan dan kenyamanan Anda. Situs kami didukung oleh server hosting yang cepat dan sistem keamanan dengan metode enkripsi terbaru di dunia, sehingga data Anda akan selalu terjaga keamanannya. Tampilan situs yang modern juga membuat Anda merasa nyaman saat mengakses situs kami.
Keunggulan ANGKOT88
Selain menjadi situs game online terbaik, ANGKOT88 juga menawarkan layanan praktis untuk melakukan deposit menggunakan pulsa XL ataupun Telkomsel dengan potongan terendah dibandingkan situs lainnya. Ini menjadikan kami salah satu situs game online pulsa terbesar di Indonesia. Anda juga dapat melakukan deposit pulsa melalui E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kepercayaan dan Layanan
Kami di ANGKOT88 sangat menjaga kepercayaan Anda sebagai prioritas utama kami. Oleh karena itu, kami selalu berusaha menjadi agen online terpercaya dan terbaik sepanjang masa. Permainan game online yang kami tawarkan sangat praktis, sehingga Anda dapat memainkannya kapan saja dan di mana saja tanpa perlu repot bepergian. Kami menyediakan berbagai jenis game, termasuk yang disiarkan secara LIVE (langsung) dengan host cantik dan kamera yang merekam secara real-time, menjadikan ANGKOT88 situs game online terlengkap dan terbesar di Indonesia.
Promo Menarik dan Menguntungkan
ANGKOT88 juga menawarkan banyak sekali promo menarik dan menguntungkan. Anda bisa menikmati berbagai macam promo yang sesuai dengan kebutuhan Anda, seperti welcome bonus 20%, bonus deposit harian, dan cashback. Semua promo ini tersedia di situs ANGKOT88. Selain itu, kami juga memiliki layanan Customer Service yang siap membantu Anda kapan saja.
Jadi, tunggu apa lagi? Bergabunglah dengan ANGKOT88 dan nikmati pengalaman bermain game online terbaik dan teraman di Indonesia. Daftarkan diri Anda sekarang dan mulai mainkan game favorit Anda dengan nyaman dan aman di situs kami!
cipro 500mg prescription
link gundam4d
amoxicillin 875mg cost
Pharmacie Internationale en ligne: pharmacie en ligne – pharmacie en ligne france livraison belgique
В ТЕЧЕНИЕ интернете огромное количество анализаторов сайта, качество вещи коию напрямую зависит через тарифных планов.
https://be1.ru/ – лысый
Pharmacie Internationale en ligne: achat kamagra – pharmacie en ligne france livraison belgique
florinef bee – omeprazole famous prevacid pills generation
cheap zithromax pills
Крупнейший интернет магазин для взрослых. Более 40.000 товаров для взрослых в наличии! Работаем с 2008 года купить секс куклу в москве
BATA4D
BATA4D
acyclovir cream coupon
pharmacies en ligne certifiГ©es: acheter kamagra site fiable – pharmacie en ligne france livraison internationale
SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik di Indonesia
SUPERMONEY88 adalah situs game online deposit pulsa terbaik tahun 2020 di Indonesia. Kami menyediakan berbagai macam game online terbaik dan terlengkap yang bisa Anda mainkan di situs game online kami. Hanya dengan mendaftar satu ID, Anda bisa memainkan seluruh permainan yang tersedia di SUPERMONEY88.
Keunggulan SUPERMONEY88
SUPERMONEY88 juga merupakan situs agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang berarti situs ini sangat aman. Kami didukung dengan server hosting yang cepat dan sistem keamanan dengan metode enkripsi termutakhir di dunia untuk menjaga keamanan database Anda. Selain itu, tampilan situs kami yang sangat modern membuat Anda nyaman mengakses situs kami.
Layanan Praktis dan Terpercaya
Selain menjadi game online terbaik, ada alasan mengapa situs SUPERMONEY88 ini sangat spesial. Kami memberikan layanan praktis untuk melakukan deposit yaitu dengan melakukan deposit pulsa XL ataupun Telkomsel dengan potongan terendah dari situs game online lainnya. Ini membuat situs kami menjadi salah satu situs game online pulsa terbesar di Indonesia. Anda bisa melakukan deposit pulsa menggunakan E-commerce resmi seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Kami juga terkenal sebagai agen game online terpercaya. Kepercayaan Anda adalah prioritas kami, dan itulah yang membuat kami menjadi agen game online terbaik sepanjang masa.
Kemudahan Bermain Game Online
Permainan game online di SUPERMONEY88 memudahkan Anda untuk memainkannya dari mana saja dan kapan saja. Anda tidak perlu repot bepergian lagi, karena SUPERMONEY88 menyediakan beragam jenis game online. Kami juga memiliki jenis game online yang dipandu oleh host cantik, sehingga Anda tidak akan merasa bosan.
Секс машина фаллоимитатор, дилдо с подогревом и пультом в интернет-магазине. Бесплатная доставка и постоянные скидки секс машина купить
문 프린세스
어떤 사람들은 명나라 군대가 도착했고 우아한 언어와 우아한 글을 배울 수 있고 배우지 않는 것은 쓸모가 없다고 생각합니다.
accutane price canada
Секс машина фаллоимитатор, дилдо с подогревом и пультом в интернет-магазине. Бесплатная доставка и постоянные скидки секс машины цена купить
ventolin
смотреть онлайн бесплатно сериалы 2024 года
pharmacie en ligne france livraison internationale: kamagra 100mg prix – pharmacie en ligne avec ordonnance
А вот про вывод в топ поисковых систем, например, Яндекса, ничего толкового я не обнаружил. Более того, я вообще был сильно удивлен, увидев, что Яндекс выводит в топ какие-то каналы из ТГ Вывод канала телеграм в топ
where to buy flomax
strattera 10 mg
Viagra sans ordonnance 24h Amazon: viagra en ligne – Viagra gГ©nГ©rique pas cher livraison rapide
vente de mГ©dicament en ligne: Achat mГ©dicament en ligne fiable – pharmacie en ligne france fiable
Интересуетесь недвижимостью? Наш сайт – ваш надежный гид в этой сфере. У нас вы найдете множество актуальных статей на такие темы, как [url=http://abraziv-pferd.ru]покупка квартир в новостройках[/url], а также [url=http://abraziv-pferd.ru]оценка недвижимости[/url].
Глубокие аналитические материалы, экспертные мнения и простые рекомендации — все это доступно у нас!
Achat mГ©dicament en ligne fiable: kamagra pas cher – pharmacies en ligne certifiГ©es
Прежде чем погрузиться в мир развлечений, важно учитывать несколько ключевых факторов при выборе площадки. Надежность, разнообразие игр, качество обслуживания и бонусные программы играют значительную роль https://www.synthonia.com/index.php?option=com_k2&view=itemlist&task=user&id=624244
BetVisa: মোবাইল গেমিংয়ের নতুন রূপ
ডিজিটাল যুগে, খেলোয়াড়রা আর ডেস্কটপ গেমিংয়ের সীমিততা সহ্য করতে চান না। তাদের চাহিদা হল, যেকোন সময় যেকোন জায়গায় তাদের প্রিয় স্লট গেমগুলি খেলতে পারা। এই চাহিদা লক্ষ্য করে, BetVisa মোবাইল গেমিংয়ের নতুন মাত্রা উন্মোচন করেছে।
বেটভিসা ডাউনলোড: খেলোয়াড়রা বাড়িতে বসে থাক বা চলার পথে থাকুক না কেন, তাদের স্মার্টফোন বা ট্যাবলেট বের করে BetVisa অ্যাপ চালু করতে পারে এবং সেকেন্ডের মধ্যে স্লটের জগতে ডুব দিতে পারে। এই সুবিধার মাধ্যমে, খেলোয়াড়রা ডেস্কটপ গেমিংয়ের সীমাবদ্ধতা থেকে বিদায় নিতে পারেন।
রিচ গেমিং বৈচিত্র্য: Betvisa তাদের সৃজনশীলতা এবং উদ্ভাবনের জন্য বিখ্যাত গেম ডেভেলপারদের কাছ থেকে শিরোনাম সমন্বিত স্লট গেমগুলির একটি বিস্তৃত লাইব্রেরি নিয়ে গর্বিত। ক্লাসিক ফ্রুট মেশিন থেকে শুরু করে অত্যাধুনিক গ্রাফিক্স এবং অ্যানিমেশন গর্বিত নিমজ্জিত ভিডিও স্লট পর্যন্ত, প্রত্যেক খেলোয়াড়ের পছন্দ ও স্বাদ মেটাতে কিছু না কিছু রয়েছে।
সুচারু গেমপ্লে: বেটিভিসা ডাউনলোড মোবাইল ডিভাইসের জন্য তৈরি অপ্টিমাইজড পারফরম্যান্স এবং স্বজ্ঞাত নিয়ন্ত্রণ সহ একটি নিরবচ্ছিন্ন গেমিং অভিজ্ঞতা নিশ্চিত করে৷ প্লেয়াররা অ্যাপের মাধ্যমে অনায়াসে নেভিগেট করতে পারে, বিভিন্ন গেম অন্বেষণ করতে পারে, এবং কোনো প্রকার ল্যাগ বা গ্লিচ ছাড়াই নিরবচ্ছিন্ন গেমপ্লে উপভোগ করতে পারে।
বিশেষ প্রচার সুযোগ: BetVisa প্রায়শই Betvisa ডাউনলোড অ্যাপের মাধ্যমে প্ল্যাটফর্মে প্রবেশকারী খেলোয়াড়দের জন্য একচেটিয়া প্রচার এবং বোনাস রোল আউট করে। স্বাগত বোনাস থেকে শুরু করে ফ্রি স্পিন এবং লয়্যালটি পুরষ্কার পর্যন্ত, একজনের ব্যাঙ্করোল বাড়ানো এবং গেমিং অভিজ্ঞতা বাড়ানোর প্রচুর সুযোগ রয়েছে।
BetVisa বাংলাদেশ ব্যবহারকারীদের জন্য বিশেষ সুবিধা প্রদান করে। BetVisa বাংলাদেশ লগইন করে খেলোয়াড়রা সহজে তাদের প্রিয় স্লট গেমগুলি খেলতে পারেন।
মোবাইল ডিভাইসের উন্নত অ্যাক্সেসের সুযোগ, রিচ গেমিং বৈচিত্র্য এবং বিশেষ প্রচার সুবিধার মাধ্যমে, BetVisa মোবাইল গেমিংয়ের নতুন বিস্ময় সৃষ্টি করেছে।
Betvisa Bet | Hit it Big This IPL Season with Betvisa!
Betvisa login! | Every deposit during IPL matches earns a 2% bonus .
Betvisa Bangladesh! | IPL 2024 action heats up, your bets get more rewarding!
Crash Game returns! | huge ₹10 million jackpot. Take the lead on the Betvisa app !
#betvisa
Start Winning Now! | Sign up through Betvisa affiliate login, claim ₹500 free cash.
Grab Your Winning Ticket! | Register login and win ₹8,888 at visa bet!
https://www.betvisa-bet.com/bn
#visabet #betvisalogin #betvisabangladesh#betvisaapp
200% Excitement! | Enjoy slots and fishing games at Betvisa লগইন করুন!
Big Sports Bonuses! | Score up to ₹5,000 in sports bonuses during the IPL season
Gear up for an exhilarating IPL season at Betvisa, propels you towards victory!
sunmory33
sunmory33
pharmacie en ligne avec ordonnance: pharmacie en ligne livraison europe – pharmacie en ligne france fiable
pharmacie en ligne france pas cher: pharmacie en ligne pas cher – п»їpharmacie en ligne france
Искушение и азарт всегда были неотъемлемой частью человеческой природы. В современном мире существует множество мест, где каждый желающий может испытать удачу и получить дозу адреналина http://blackpearlbasketball.com.au/index.php?option=com_k2&view=itemlist&task=user&id=839178
сео консультация
Консультация по сео продвижению.
Информация о том как работать с низкочастотными запросами запросами и как их определять
Подход по действиям в конкурентоспособной нише.
Имею постоянных клиентов взаимодействую с 3 компаниями, есть что сообщить.
Ознакомьтесь мой аккаунт, на 31 мая 2024г
общий объём выполненных работ 2181 только на этом сайте.
Консультация проходит в устной форме, никаких снимков с экрана и отчетов.
Время консультации указано 2 часа, но по реально всегда на доступен без твердой привязки к графику.
Как работать с софтом это уже отдельная история, консультация по работе с софтом оговариваем отдельно в другом услуге, определяем что необходимо при общении.
Всё без суеты на расслабленно не торопясь
To get started, the seller needs:
Мне нужны данные от телеграм чата для связи.
разговор только устно, переписываться нету времени.
Сб и Вс нерабочие дни
acheter mГ©dicament en ligne sans ordonnance: Levitra acheter – Pharmacie Internationale en ligne
vente de mГ©dicament en ligne: kamagra en ligne – pharmacie en ligne france fiable
ventolin inhaler
Добро пожаловать на наш сайт о недвижимости!
Здесь вы найдете интересные статьи и новости о рынке недвижимости, правовых аспектах покупки жилья, аренде коммерческих помещений, инвестициях в недвижимость и многом другом.
Мы рады поделиться с вами полезной информацией и помочь вам принимать осознанные решения в сфере [url=http://afmtel.ru]покупки недвижимости[/url].
мастерская по ремонту телефонов
матрас 60 на 180 [url=http://kupit-matras111.ru/]http://kupit-matras111.ru/[/url] .
Добро пожаловать на наш сайт о покупке и продаже жилья!
Ознакомьтесь с такими темами, как [url=http://stroymarkett.ru]покупка недвижимости[/url] и [url=http://stroymarkett.ru]квартиры в новостройках[/url].
https://vulkan-na-dengy.com/
娛樂城
網上娛樂城的世界
隨著網際網路的快速發展,網上娛樂城(在線賭場)已經成為許多人消遣的新選擇。網上娛樂城不僅提供多樣化的游戲選擇,還能讓玩家在家中就能體驗到賭場的刺激和樂趣。本文將討論在線娛樂城的特點、好處以及一些常有的遊戲。
什麼是在線娛樂城?
網上娛樂城是一種經由互聯網提供賭博游戲的平台。玩家可以經由計算機、智慧型手機或平板設備進入這些網站,參與各種賭錢活動,如德州撲克、輪盤、二十一點和吃角子老虎等。這些平台通常由專業的的軟體公司開發,確保游戲的公正性和安全。
在線娛樂城的利益
便利性:玩家無需離開家,就能享用賭博的快感。這對於那些生活在遠離的實體賭場地區的人來說尤為方便。
多種的游戲選擇:網上娛樂城通常提供比實體賭場更多的游戲選擇,並且經常改進遊戲內容,保持新鮮。
好處和獎金:許多網上娛樂城提供多樣的獎金計劃,包括註冊獎金、存款紅利和忠誠計劃,吸引新新玩家並激勵老玩家不斷遊戲。
穩定性和保密性:正當的線上娛樂城使用先進的的加密方法來保護玩家的個人信息和金融交易,確保遊戲過程的安全和公平。
常有的在線娛樂城游戲
撲克:德州撲克是最受歡迎賭博遊戲之一。線上娛樂城提供多種撲克變體,如德州扑克、奧馬哈撲克和七張牌撲克等。
輪盤賭:賭盤是一種古老的賭場遊戲遊戲,玩家可以投注在數字、數字排列或顏色上上,然後看球落在哪個區域。
21點:又稱為黑傑克,這是一種對比玩家和莊家點數的游戲,目標是讓手牌點數盡量接近21點但不超過。
吃角子老虎:吃角子老虎是最簡單且是最流行的賭博遊戲之一,玩家只需轉動捲軸,等待圖案圖案排列出贏得的組合。
總結
在線娛樂城為現代的賭博愛好者提供了一個方便、刺激的且多樣化的娛樂選擇。無論是撲克迷還是吃角子老虎迷,大家都能在這些平台上找到適合自己的游戲。同時,隨著技術的不斷發展,在線娛樂城的遊戲體驗將變得越來越現實和引人入勝。然而,玩家在體驗遊戲的同時,也應該保持自律,避免沉溺於賭博活動,保持健康健康的娛樂心態。
Откройте двери в мир недвижимости с нашим порталом!
Получайте экспертные статьи от специалистов в сфере недвижимости. Узнавайте о налогах на недвижимость, осуществляйте успешные сделки купли-продажи квартир, и всегда оставайтесь в курсе последних тенденций рынка.
http://ufficioporta.ru
빠른 환충 서비스와 더불어 주요업체의 안전성
베팅사이트 접속 시 가장 중요한 요소는 빠릿한 충환전 처리입니다. 보통 삼 분 이내에 충전하고, 10분 안에 출금이 완료되어야 합니다. 메이저 주요업체들은 충분한 스태프 채용으로 이 같은 신속한 입출금 절차를 보증하며, 이 방법으로 고객들에게 안전감을 드립니다. 대형사이트를 사용하면서 신속한 체험을 해보시기 바랍니다. 저희는 여러분이 안심하고 웹사이트를 이용할 수 있도록 도와드리는 먹튀해결 전문가입니다.
보증금을 내고 배너를 운영
먹튀 해결 팀은 최대한 3000만 원에서 일억 원의 보증 금액을 예치한 업체들의 배너 광고를 운영합니다. 만일 먹튀 사고가 발생할 경우, 배팅 규정에 위배되지 않은 배팅 내역을 캡처해서 먹튀해결사에 문의하시면, 사실 확인 후 보증금으로 즉시 손해 보상을 처리합니다. 피해 발생 시 즉시 캡처하여 피해 상황을 저장해두시고 보내주세요.
장기간 안전 운영 업체 확인
먹튀 해결 팀은 적어도 4년간 먹튀 이력 없이 안전하게 운영된 사이트들을 인증하여 광고 배너 입점을 허용합니다. 이를 통해 누구나 알고 있는 주요사이트를 안전하게 사용할 수 있는 기회를 제공하고 있습니다. 철저한 검사 작업을 통해 검증된 사이트를 놓치지 않도록, 보안된 배팅을 체험해보세요.
투명하고 공정한 먹튀 검토
먹튀해결사의 먹튀 검토는 투명함과 공평성을 바탕으로 실시합니다. 늘 사용자들의 관점을 최우선으로 생각하며, 업체의 회유나 이득에 흔들리지 않으며 하나의 삭제 없이 사실만을 근거로 검증해왔습니다. 먹튀 사고를 겪고 후회하지 않도록, 바로 지금 시작해보세요.
먹튀 검증 사이트 목록
먹튀 해결 전문가가 선별한 안전 토토사이트 인증된 업체 목록 입니다. 현재 등록되어 있는 검증업체들은 먹튀 피해 발생 시 100% 보증을 도와드립니다. 하지만, 제휴가 끝난 업체에서 발생한 사고에 대해서는 책임을 지지 않습니다.
탁월한 먹튀 검증 알고리즘
먹튀해결사는 청결한 베팅 문화를 만들기 위해 늘 노력하고 있습니다. 우리가 권장하는 스포츠토토사이트에서 안전하게 베팅하세요. 사용자의 먹튀 신고 내용은 먹튀 목록에 등록 노출되어 그 해당 스포츠토토 사이트에 치명적인 영향을 끼칩니다. 먹튀 리스트 작성 시 먹튀블러드만의 검증 노하우를 최대한 활용하여 정확한 검증을 하도록 하겠습니다.
안전한 도박 환경을 제공하기 위해 끊임없이 애쓰는 먹튀해결사와 함께 안전하게 즐기시기 바랍니다.
как продвинуть сайт
Советы по сео продвижению.
Информация о том как работать с низкочастотными ключевыми словами и как их выбирать
Стратегия по работе в конкурентной нише.
У меня есть регулярных взаимодействую с тремя компаниями, есть что сообщить.
Посмотрите мой аккаунт, на 31 мая 2024г
общий объём завершённых задач 2181 только на этом сайте.
Консультация только в устной форме, без скриншотов и отчётов.
Продолжительность консультации указано 2 ч, но по сути всегда на доступен без твердой привязки ко времени.
Как взаимодействовать с программным обеспечением это уже отдельная история, консультация по использованию ПО обсуждаем отдельно в отдельном разделе, выясняем что нужно при разговоре.
Всё спокойно на расслабленно не спеша
To get started, the seller needs:
Мне нужны контакты от телеграм каналов для контакта.
общение только устно, переписываться не хватает времени.
субботы и Вс выходной
Добро пожаловать на информационный сайт о недвижимости!
Здесь вы найдете полезные советы о [url=http://sc-pskov.ru]аренде недвижимости[/url], а также о [url=http://sc-pskov.ru]налогах на недвижимость[/url].
Мы расскажем вам о тонкостях покупки вторичной квартиры и поделимся другими секретами.
уборка офисов цены в москве
ziatogel
Inspirasi dari Kutipan Taylor Swift: Harapan dan Cinta dalam Lagu-Lagunya
Penyanyi Terkenal, seorang musisi dan songwriter populer, tidak hanya dikenal berkat nada yang elok dan suara yang merdu, tetapi juga sebab lirik-lirik lagunya yang penuh makna. Pada lirik-liriknya, Swift sering melukiskan beraneka ragam unsur hidup, mulai dari asmara sampai tantangan hidup. Di bawah ini adalah beberapa petikan menginspirasi dari lagu-lagunya, dengan terjemahannya.
“Mungkin yang terbaik belum datang.” – “All Too Well”
Arti: Bahkan di saat-saat sulit, tetap ada sedikit harapan dan kemungkinan tentang hari yang lebih baik.
Syair ini dari lagu “All Too Well” mengingatkan kita kalau meskipun kita mungkin menghadapi masa sulit saat ini, selalu ada potensi bahwa masa depan akan membawa sesuatu yang lebih baik. Hal ini adalah pesan asa yang mengukuhkan, mendorong kita untuk tetap bertahan dan tidak menyerah, lantaran yang paling baik barangkali belum datang.
“Aku akan tetap bertahan lantaran aku tidak bisa mengerjakan apa pun tanpamu.” – “You Belong with Me”
Arti: Memperoleh cinta dan dukungan dari orang lain dapat memberi kita kekuatan dan tekad untuk bertahan lewat rintangan.
dagotogel
Ashley JKT48: Bintang yang Bersinar Gemilang di Langit Idol
Siapa Ashley JKT48?
Siapakah figur muda berkemampuan yang menarik perhatian sejumlah besar fans musik di Nusantara dan Asia Tenggara? Dialah Ashley Courtney Shintia, atau yang lebih dikenal dengan nama panggungnya, Ashley JKT48. Menjadi anggota dengan grup idol JKT48 pada masa 2018, Ashley dengan cepat menjadi salah satu anggota paling populer.
Riwayat Hidup
Lahir di Jakarta pada tgl 13 Maret 2000, Ashley memiliki darah Tionghoa-Indonesia. Ia memulai karier di bidang hiburan sebagai model dan aktris, sebelum kemudian masuk dengan JKT48. Personanya yang periang, vokal yang kuat, dan keterampilan menari yang memukau menjadikannya idola yang sangat dicintai.
Award dan Pengakuan
Kepopuleran Ashley telah diakui melalui banyak apresiasi dan nominasi. Pada tahun 2021, Ashley mendapat award “Member Terpopuler JKT48” di acara JKT48 Music Awards. Ashley juga diberi gelar sebagai “Idol Tercantik se-Asia” oleh sebuah tabloid daring pada tahun 2020.
Fungsi dalam JKT48
Ashley memainkan peran penting dalam grup JKT48. Beliau adalah member Tim KIII dan berperan menjadi dancer utama dan vokalis. Ashley juga menjadi bagian dari sub-unit “J3K” dengan Jessica Veranda dan Jennifer Rachel Natasya.
Karir Solo
Selain aktivitasnya bersama JKT48, Ashley juga memulai karier solo. Ia telah mengeluarkan sejumlah lagu single, diantaranya “Myself” (2021) dan “Falling Down” (2022). Ashley juga telah bekerjasama dengan artis lain, seperti Afgan dan Rossa.
Kehidupan Pribadi
Di luar dunia perform, Ashley dikenali sebagai pribadi yang low profile dan bersahabat. Ashley menggemari melewatkan masa bersama keluarga dan teman-temannya. Ashley juga memiliki hobi melukis dan photography.
에그 카지노
Fang Xiaofan은 그에게 감사하고 시험실로 안내되었습니다.
клининг дома после ремонта цена
free slots games
No-Cost Slot Games: Fun and Rewards for All
Gratis slot games have become a widespread form of online leisure, granting players the thrill of slot machines absent any monetary stake.
The principal goal of no-cost slot games is to grant a enjoyable and engaging way for individuals to savor the excitement of slot machines free from any monetary danger. They are designed to mimic the experience of actual-currency slots, enabling players to trigger the reels, savor various ideas, and earn virtual prizes.
Entertainment: Free slot games are an outstanding avenue of entertainment, delivering durations of fun. They showcase vibrant graphics, captivating audio, and varied motifs that serve a wide range of tastes.
Capability Enhancement: For newcomers, free slot games grant a safe situation to learn the mechanics of slot machines. Players can get accustomed with diverse feature sets, winning combinations, and extras devoid of the apprehension of sacrificing money.
Unwinding: Playing free slot games can be a wonderful way to unwind. The simple gameplay and the possibility for digital prizes make it an pleasurable hobby.
Community Engagement: Many free slot games integrate community-based aspects such as leaderboards and the option to engage with peers. These aspects inject a collective facet to the gaming experience, encouraging players to pit themselves against each other.
Advantages of Free Slot Games
1. Approachability and Convenience
Free slot games are readily available to anyone with an online connection. They can be utilized on diverse platforms including PCs, pads, and cellphones. This comfort enables players to experience their chosen pursuits at any time and from any place.
2. Economic Risk-Freeness
One of the paramount rewards of no-cost slot games is that they remove the cash-related hazards related to wagering. Players can enjoy the suspense of activating the reels and obtaining big wins devoid of wagering any cash.
3. Range of Possibilities
Gratis slot games come in a vast selection of ideas and styles, from classic fruit-themed slots to innovative video slots with elaborate narratives and graphics. This range secures that there is an alternative for everyone, irrespective of their interests.
4. Enhancing Cognitive Skills
Playing no-cost slot games can lead to strengthen thinking abilities such as strategic thinking. The requirement to choose payout lines, comprehend operational principles, and foresee consequences can deliver a cerebral workout that is simultaneously satisfying and advantageous.
5. Secure Pre-Testing for Real-Money Play
For those pondering progressing to for-profit slots, complimentary slot games provide a valuable pre-experience. Players can explore diverse games, develop methods, and build self-belief ahead of opting to invest genuine cash. This preparation can translate to a more informed and enjoyable real-money gaming encounter.
Recap
Gratis slot games provide a wealth of rewards, from sheer amusement to skill development and interpersonal connections. They offer a risk-free and zero-cost way to experience the rush of slot machines, establishing them a valuable addition to the world of electronic recreation. Whether you’re wanting to de-stress, improve your cognitive skills, or solely derive entertainment, gratis slot games are a excellent alternative that constantly delight players around.
internet casinos
Digital Gambling Sites: Advancement and Benefits for Modern Community
Overview
Internet casinos are digital platforms that offer players the opportunity to engage in gambling activities such as card games, spin games, blackjack, and slots. Over the past few decades, they have turned into an integral component of online entertainment, offering various benefits and opportunities for users around the world.
Availability and Convenience
One of the primary benefits of digital casinos is their accessibility. Users can play their preferred activities from anywhere in the world using a PC, tablet, or mobile device. This conserves time and funds that would typically be used traveling to land-based gambling halls. Furthermore, round-the-clock access to activities makes online casinos a convenient option for individuals with busy schedules.
Variety of Games and Experience
Online casinos offer a wide range of activities, allowing all users to discover something they like. From traditional table activities and board games to slots with diverse concepts and increasing jackpots, the diversity of games ensures there is an option for every preference. The ability to play at different proficiencies also makes online gambling sites an ideal location for both novices and seasoned gamblers.
Financial Advantages
The digital casino sector adds greatly to the economy by creating jobs and producing revenue. It supports a diverse variety of professions, including programmers, client assistance representatives, and marketing professionals. The income generated by digital casinos also adds to government funds, which can be used to support community services and development projects.
Technological Innovation
Digital gambling sites are at the cutting edge of technological advancement, continuously integrating new innovations to improve the gaming experience. Superior visuals, real-time dealer games, and VR gambling sites provide engaging and realistic gaming entertainment. These advancements not only improve player satisfaction but also expand the limits of what is achievable in digital leisure.
Safe Betting and Assistance
Many online casinos encourage responsible gambling by providing tools and resources to assist users manage their gaming activities. Features such as deposit limits, self-exclusion choices, and access to assistance programs guarantee that users can enjoy betting in a safe and controlled environment. These measures show the industry’s commitment to encouraging safe betting practices.
Community Engagement and Networking
Online casinos often provide interactive options that enable users to connect with each other, creating a sense of belonging. Group activities, communication tools, and networking links allow users to network, exchange experiences, and form relationships. This social aspect enhances the entire gaming entertainment and can be especially beneficial for those looking for social interaction.
Summary
Online gambling sites offer a diverse variety of benefits, from availability and ease to economic contributions and technological advancements. They offer varied betting choices, support safe betting, and foster social interaction. As the industry keeps to evolve, online casinos will probably remain a significant and beneficial force in the realm of digital leisure.
WordPress SEO
lucky jet играть [url=www.1win-luckyjet-ru.ru]www.1win-luckyjet-ru.ru[/url] .
fortune casino
Fortune Wagering Environment: In an Environment Where Pleasure Combines With Wealth
Fortune Wagering Environment is a renowned online venue known for its wide range of activities and thrilling benefits. Let’s examine the motivations behind so numerous individuals experience engaging with Fortune Gaming Site and in what way it benefits them.
Pleasure-Providing Aspect
Luck Gaming Site grants a diversity of activities, featuring time-honored card games like pontoon and wheel of fortune, as alongside novel slot-based activities. This variety ensures that there is an option for anyone, rendering every single visit to Wealth Gaming Site enjoyable and entertaining.
Significant Rewards
One of the main attractions of Wealth Casino is the prospect to win big. With generous grand prizes and benefits, participants have the prospect to turn their luck around with a lone play or hand. Several players have walked away with major payouts, contributing to the excitement of playing at Prosperity Casino.
Simplicity and Approachability
Luck Casino’s online infrastructure renders it convenient for customers to enjoy their most preferred activities from any setting. Whether at residence or while traveling, players can access Wealth Gambling Platform from their PC or handheld. This reachability guarantees that participants can experience the thrill of the gaming regardless of when they want, devoid of the necessity to commute.
Breadth of Offerings
Fortune Casino offers a wide choice of offerings, providing that there is a choice for all type of player. Starting with time-honored casino games to narrative-driven slot-based games, the range sustains participants engaged and amused. This choice in addition enables participants to try out new activities and uncover novel most cherished.
Perks and Advantages
Fortune Wagering Environment acknowledges its participants with incentives and advantages, featuring new player incentives and reward programs. These special offers not only enhance the gaming encounter but likewise boost the prospects of earning significant rewards. Users are steadfastly driven to sustain interaction, constituting Fortune Gambling Platform further desirable.
Group-Based Participation and Collaboration
ChatGPT l Валли, 6.06.2024 4:30]
Wealth Casino provides a sense of collective engagement and group-based participation for players. Via communication channels and forums, users can interact with one another, exchange tips and methods, and occasionally develop personal connections. This collaborative factor brings a supplemental layer of enjoyment to the leisure experience.
Key Takeaways
Fortune Wagering Environment provides a wide array of benefits for customers, encompassing enjoyment, the likelihood of earning significant rewards, simplicity, range, perks, and interpersonal connections. Whether desiring thrill or hoping to strike it rich, Wealth Gambling Platform provides an enthralling interaction for any engage with.
rabeprazole 20mg over the counter – reglan online order domperidone 10mg us
빅토리 마약
빠릿한 환충 서비스와 대형업체의 안전성
베팅사이트 접속 시 가장 중요한 요소 중 하나는 빠른 입출금 절차입니다. 대개 세 분 내에 입금, 열 분 내에 환충이 완료되어야 합니다. 주요 메이저업체들은 필요한 직원 채용을 통해 이러한 빠른 입출금 처리를 보장하며, 이로써 사용자들에게 안도감을 드립니다. 대형사이트를 접속하면서 스피드 있는 경험을 해보세요. 저희는 여러분들이 안전하게 웹사이트를 접속할 수 있도록 지원하는 먹튀해결사입니다.
보증금을 걸고 배너 운영
먹튀 해결 팀은 적어도 3000만 원에서 일억 원의 보증 금액을 예치하고 있는 업체들의 광고 배너를 운영 중입니다. 만일 먹튀 사고가 발생할 시, 배팅 규정에 어긋나지 않은 배팅 내역을 스크린샷을 찍어 먹튀 해결 전문가에게 문의 주시면, 확인 후 보증금으로 신속하게 손해 보상을 처리해드립니다. 피해가 발생하면 신속하게 캡처하여 피해 내용을 기록해두시고 보내주시기 바랍니다.
오랫동안 안전하게 운영된 업체 확인
먹튀해결사는 적어도 사 년 이상 먹튀 이력 없이 안정적으로 운영한 사이트들을 확인하여 배너 등록을 허용합니다. 이 때문에 누구나 잘 알려진 주요사이트를 안전하게 이용할 수 있는 기회를 제공합니다. 엄격한 검사 작업을 통해 인증된 사이트를 놓치지 않도록, 안전한 도박을 경험해보세요.
투명하고 공정한 먹튀 검토
먹튀해결사의 먹튀 검증은 투명함과 정확함을 바탕으로 합니다. 늘 사용자들의 입장을 최우선으로 생각하며, 기업의 유혹이나 이득에 흔들리지 않으며 하나의 삭제 없이 사실만을 기반으로 검증해오고 있습니다. 먹튀 사고를 당한 후 후회하지 않도록, 바로 지금 시작하세요.
먹튀 검증 사이트 목록
먹튀 해결 전문가가 엄선한 안전 토토사이트 검증업체 목록 입니다. 현재 등록된 검증된 업체들은 먹튀 사고 발생 시 100% 보증을 도와드립니다. 그러나, 제휴 기간이 만료된 업체에서 발생한 피해에 대해서는 책임지지 않습니다.
독보적인 먹튀 검증 알고리즘
먹튀 해결 팀은 깨끗한 베팅 환경을 형성하기 위해 계속해서 노력합니다. 저희가 추천하는 베팅사이트에서 안전하게 베팅하시기 바랍니다. 사용자의 먹튀 신고 내용은 먹튀 리스트에 기재되어 그 해당 베팅 사이트에 중대한 영향을 미칩니다. 먹튀 리스트 작성 시 먹튀블러드만의 검증 노하우를 최대로 사용하여 공정한 심사를 할 수 있게 약속드립니다.
안전한 도박 환경을 만들기 위해 계속해서 노력하는 먹튀 해결 전문가와 함께 안전하게 경험해보세요.
free poker machine games
No-Cost Slot-Based Experiences: A Fun and Rewarding Interaction
Gratis poker machine experiences have evolved into steadily well-liked among customers seeking a exciting and safe interactive sensation. These games present a wide array of advantages, constituting them as a chosen choice for several. Let’s explore in what way no-cost virtual wagering experiences can reward users and the factors that explain why they are so widely savored.
Entertainment Value
One of the main reasons individuals savor interacting with complimentary slot-based activities is for the entertainment value they offer. These experiences are created to be compelling and captivating, with colorful graphics and immersive soundtracks that improve the total interactive encounter. Whether you’re a casual user wanting to spend time or a serious leisure activity enthusiast desiring suspense, free poker machine activities present enjoyment for everyone.
Competency Enhancement
Partaking in complimentary slot-based experiences can as well enable refine worthwhile faculties such as decision-making. These experiences necessitate participants to make rapid selections contingent on the virtual assets they are dealt, helping them hone their decision-making aptitudes and intellectual prowess. Moreover, users can experiment with various approaches, sharpening their faculties without the possibility of financial impact of forfeiting actual currency.
Simplicity and Approachability
An additional upside of no-cost virtual wagering activities is their convenience and approachability. These experiences can be played online from the simplicity of your own abode, eliminating the obligation to make trips to a brick-and-mortar wagering facility. They are also available 24/7, permitting players to experience them at whichever moment that accommodates them. This ease constitutes gratis electronic gaming games a sought-after option for customers with busy timetables or those desiring a rapid gaming resolution.
Shared Experiences
Many gratis electronic gaming experiences also grant collaborative elements that allow customers to interact with each other. This can include chat rooms, interactive platforms, and competitive modes where participants can pit themselves against one another. These interpersonal connections inject an further layer of fulfillment to the entertainment interaction, permitting players to connect with like-minded individuals who possess their interests.
Anxiety Reduction and Mental Unwinding
Interacting with gratis electronic gaming activities can likewise be a great way to decompress and calm down after a long stretch of time. The uncomplicated activity and soothing music can help reduce tension and apprehension, offering a welcome break from the obligations of normal life. Moreover, the anticipation of winning online rewards can enhance your emotional state and result in you feeling reenergized.
Summary
Complimentary slot-based offerings provide a wide variety of upsides for participants, incorporating pleasure, skill development, convenience, interpersonal connections, and anxiety reduction and relaxation. Regardless of whether you’re seeking to sharpen your poker aptitudes or solely derive entertainment, gratis electronic gaming offerings offer a advantageous and enjoyable encounter for customers of any stages.
娛樂城官網
娛樂城官網
whoah this blog is fantastic i like reading your articles. Stay up the great work! You know, lots of persons are looking around for this information, you can help them greatly.
@@G@@
https://www.0312.ua/list/448402
buy dulcolax 5 mg sale – liv52 medication buy liv52 20mg generic
https://cleanb2b.ru/
эффективно,
Индивидуальный подход к каждому пациенту, для вашего уверенного улыбки,
Современные методы стоматологии, для вашей улыбки,
Комфортные условия и дружественный персонал, для вашего комфорта и уверенности,
Комплексное восстановление утраченных зубов, для вашего здоровья и красоты улыбки,
Индивидуальный план лечения и профилактики, для вашего долгосрочного удовлетворения,
Заботливое отношение и внимательный подход, для вашей уверенной улыбки
лікування зубів дітям https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
888vipbet
Download App 888 dan Peroleh Besar: Panduan Cepat
**Aplikasi 888 adalah pilihan terbaik untuk Pengguna yang mencari keseruan bertaruhan online yang menyenangkan dan berjaya. Melalui keuntungan tiap hari dan kemampuan memikat, aplikasi ini menawarkan menghadirkan keseruan main optimal. Ini instruksi cepat untuk menggunakan penggunaan Program 888.
Instal dan Segera Raih
Perangkat Tersedia:
Perangkat Lunak 888 bisa diambil di Sistem Android, iOS, dan Windows. Mulai berjudi dengan praktis di media manapun.
Imbalan Sehari-hari dan Keuntungan
Keuntungan Buka Harian:
Login pada hari untuk meraih imbalan hingga 100K pada waktu ketujuh.
Rampungkan Aktivitas:
Dapatkan peluang undian dengan menuntaskan aktivitas terkait. Tiap pekerjaan menyediakan Pengguna 1 peluang undian untuk memenangkan hadiah sebesar 888K.
Pengambilan Manual:
Keuntungan harus dikumpulkan sendiri di dalam app. Jangan lupa untuk mengambil hadiah setiap waktu agar tidak tidak berlaku lagi.
Prosedur Undi
Kesempatan Lotere:
Satu waktu, Para Pengguna bisa mendapatkan 1 kesempatan undi dengan menuntaskan aktivitas.
Jika opsi lotere selesai, selesaikan lebih banyak pekerjaan untuk mengambil tambahan kesempatan.
Ambang Hadiah:
Klaim bonus jika akumulasi lotere Pengguna lebih dari 100K dalam satu hari.
Kebijakan Pokok
Penerimaan Keuntungan:
Imbalan harus dikumpulkan sendiri dari program. Jika tidak, imbalan akan otomatis dikreditkan ke akun pribadi Pengguna setelah satu waktu.
Peraturan Pertaruhan:
Bonus memerlukan setidaknya satu betting aktif untuk dimanfaatkan.
Penutup
Program 888 menawarkan pengalaman bermain yang menggembirakan dengan hadiah besar-besaran. Pasang perangkat lunak hari ini dan nikmati keberhasilan besar-besaran pada hari!
Untuk detail lebih rinci tentang promo, simpanan, dan program rujukan, periksa halaman beranda perangkat lunak.
уборка загородного дома цены
Attractive portion of content. I just stumbled upon your blog and in accession capital to claim that I get in fact loved account your weblog posts. Any way I will be subscribing in your augment and even I fulfillment you access persistently quickly.
http://www.thesupercarregistry.com/forum/member.php?u=70162В
formulaf1.ru/page/13В
mypenza.ru/forum/index.php?showtopic=54674&mode=linearВ
vitz.ru/forums/index.php?autocom=gallery&req=si&img=2680В
board.46info.ru/regions/В
블랙 맘바
원래 팔 수 없던 물건은 기적적으로…비어 있었다.
mantul88
Hey! This post couldn’t be written any better! Reading this post reminds me of my old room mate! He always kept chatting about this. I will forward this post to him. Fairly certain he will have a good read. Thanks for sharing!
51.15.223.140/forum/member.php?tab=visitor_messaging&u=76509&page=6В
etlapok-gyartasa.hu/portfolio/kiegeszitok-cash-box/В
korrespondentweek.ru/category/bez-rubriki/page/13/В
aranzhirovki.ru/smf/index.php?PHPSESSID=j88uttsqnnv6mc97hrus9pfr90&topic=3478.0В
freedomsolargenerators.com/index.php?do=/public/user/blogs/name_Alanpoe/page_7/В
maxwin77
Pasang App 888 dan Peroleh Hadiah: Instruksi Pendek
**App 888 adalah kesempatan ideal untuk Anda yang mengharapkan permainan berjudi internet yang menggembirakan dan berjaya. Bersama hadiah setiap hari dan kemampuan memikat, perangkat lunak ini sedia menghadirkan aktivitas bertaruhan unggulan. Ini panduan praktis untuk menggunakan pemakaian Program 888.
Unduh dan Awali Menang
Perangkat Ada:
Program 888 dapat diambil di Android, HP iOS, dan PC. Mulai bertaruhan dengan praktis di gadget apapun.
Imbalan Harian dan Bonus
Imbalan Buka Tiap Hari:
Login setiap periode untuk mengklaim imbalan mencapai 100K pada waktu ketujuh.
Selesaikan Pekerjaan:
Dapatkan opsi lotere dengan menuntaskan misi terkait. Tiap pekerjaan menyediakan Pengguna sebuah kesempatan undian untuk mengklaim keuntungan sebesar 888K.
Pengumpulan Manual:
Hadiah harus diklaim langsung di melalui app. Yakinlah untuk mendapatkan keuntungan pada waktu agar tidak batal.
Sistem Pengeretan
Kesempatan Undi:
Tiap periode, Anda bisa mendapatkan sebuah kesempatan undian dengan menuntaskan misi.
Jika peluang lotere selesai, selesaikan lebih banyak aktivitas untuk mengklaim lebih banyak kesempatan.
Ambang Bonus:
Raih hadiah jika keseluruhan lotere Anda lebih dari 100K dalam 1 hari.
Kebijakan Esensial
Pengumpulan Imbalan:
Imbalan harus diterima mandiri dari aplikasi. Jika tidak, bonus akan otomatis diambil ke akun pribadi Kamu setelah satu periode.
Persyaratan Bertaruh:
Keuntungan memerlukan minimal 1 betting valid untuk digunakan.
Akhir
Aplikasi 888 menawarkan permainan berjudi yang menyenangkan dengan imbalan besar-besaran. Download app saat ini dan nikmati keberhasilan tinggi setiap waktu!
Untuk detail lebih terperinci tentang promosi, simpanan, dan agenda undangan, periksa halaman home app.
poker game free
Examining the Domain of Free Poker Games
Start
In contemporary times, poker games have changed into broadly accessible entertainment choices. For people wanting an unpaid way to enjoy poker games, poker game free applications supply a engaging experience. This write-up examines the pros and factors as to why no-cost poker has turned into a favored option for numerous enthusiasts.
Benefits of Poker Game Free
Unpaid Amusement
One of the highly enticing features of no-cost poker is that it gives gamers with no-cost entertainment. There is no necessity to spend currency to enjoy the activity, turning it available to anyone.
Enhancing Abilities
Experiencing poker game free allows users to sharpen their competence without one fiscal danger. It is a perfect place for learners to get the principles and techniques of poker games.
Community Interaction
Many poker game free websites give options for group connection. Players can interact with others, share techniques, and play cordial tournaments.
Why Many Players Prefer Poker Game Free
Accessibility
No-cost poker are widely available, enabling enthusiasts from diverse walks of life to enjoy the game.
No Economic Risk
With complimentary poker, there is no economic risk, making it a safe alternative for enthusiasts who wish to enjoy this card game without investing cash.
Multiple Game Choices
Free poker games sites offer a diverse variety of games, guaranteeing that users can consistently uncover a card game that matches their preferences.
Conclusion
Complimentary poker supplies a entertaining and attainable way for players to enjoy this card game. With no fiscal risk, opportunities for skill development, and wide game varieties, it is clear that numerous users choose poker game free as their preferred betting choice.
как пожаловаться на мошенников [url=https://pozhalovatsya-na-moshennikov.ru/]как пожаловаться на мошенников[/url] .
Gratis poker gives players a special way to enjoy the sport without any monetary cost. This write-up explores the advantages of engaging in free poker and emphasizes why it is still favored among many players.
Risk-Free Entertainment
One of the most significant upsides of free poker is that it permits participants to enjoy the excitement of poker without worrying about losing cash. This turns it perfect for first-timers who desire to learn the game without any financial commitment.
Skill Development
Gratis poker presents a fantastic environment for players to improve their skills. Participants can try methods, grasp the mechanics of the game, and gain self-assurance without any stress of parting with their own funds.
Social Interaction
Engaging in free poker can also lead to social connections. Digital websites often feature forums where users can communicate with each other, exchange strategies, and potentially create bonds.
Accessibility
Gratis poker is conveniently accessible to anyone with an online connection. This means that participants can experience the game from the luxury of their own house, at any time.
Conclusion
Gratis poker presents various benefits for players. It is a safe method to experience the pastime, hone abilities, engage in new friendships, and access poker easily. As further gamblers discover the benefits of free poker, its demand is anticipated to rise.
casino online
Examining the World of Online Casinos
Beginning
In contemporary times, online casinos have revolutionized the method players experience betting. With modern technology, gamblers can access their beloved games right from the comfort of their living spaces. This piece investigates the pros of online casinos and for why they are drawing popularity.
Advantages of Casino Online
Convenience
One of the key benefits of virtual casinos is accessibility. Enthusiasts can play at any time and anywhere they prefer, removing the need to move to a land-based betting place.
Large Game Library
Casino online supply a vast selection of games, ranging from vintage slot machines and card games to live dealer games and modern video slots. This selection makes sure that there is a game for every player.
Bonuses and Promotions
One of the most attractive characteristics of virtual casinos is the variety of bonuses and offers provided to users. These can encompass sign-up bonuses, free turns, money-back offers, and rewards programs.
Safety and Reliability
Reputable online casinos guarantee enthusiast assurance and assurance with cutting-edge cybersecurity technologies. This protects user credentials and financial transactions.
Reasons Players Choose Online Casinos
Accessibility
Casino online are extensively available, allowing gamblers from diverse walks of life to play gaming.
free casino games
Examining Free-of-Charge Casino Games
Beginning
In contemporary times, free casino games have grown into a preferred option for gamers who desire to play casino games devoid of wasting cash. This piece examines the pros of free casino games and the motivations they are gaining interest.
Pros of Complimentary Casino Games
Secure Gambling
One of the major perks of no-cost casino games is the possibility to gamble devoid of financial risk. Gamblers can experience their beloved casino activities free from fretting over parting with cash.
Skill Enhancement
Free casino games give an ideal environment for gamblers to sharpen their skills. Be it mastering strategies in blackjack, users can work on minus financial implications.
Large Game Library
No-cost casino games supply a vast selection of gaming options, such options as vintage slot machines, casino classics, and live-action games. This variety assures that there is an option for all types of players.
Why Many Players Prefer Free Casino Games
Reachability
Free-of-charge casino games are extensively available, allowing gamblers from different backgrounds to experience betting.
Free from Financial Burden
Unlike real-money casino games, no-cost casino games do not need a monetary obligation. This permits gamblers to engage in betting devoid of the stress of misplacing money.
Experience Before Paying
Free-of-charge casino games provide gamblers the chance to test betting activities before putting down genuine money. This enables users make well-thought-out selections.
Conclusion
Complimentary casino games supplies a fun and safe means to engage in gambling. With no financial commitment, a wide variety of games, and abilities for skill enhancement, it is understandable that numerous players like no-cost casino games for their betting preferences.
no deposit bonus
Online gambling sites are increasingly more widespread, offering various bonuses to attract new users. One of the most enticing offers is the no-deposit bonus, a offer that lets gamblers to test their luck without any financial obligation. This overview examines the benefits of free bonuses and points out how they can enhance their value.
What is a No Deposit Bonus?
A free bonus is a category of casino offer where users get free cash or free rounds without the need to deposit any of their own capital. This lets players to try out the virtual casino, try multiple game options and have a chance to win real prizes, all without any upfront cost.
Advantages of No Deposit Bonuses
Risk-Free Exploration
No upfront deposit bonuses offer a secure opportunity to try out internet casinos. Users can try diverse game options, learn the casino’s interface, and analyze the overall gameplay without spending their own cash. This is especially helpful for newcomers who may not be accustomed to virtual casinos.
Chance to Win Real Money
One of the most appealing aspects of no upfront deposit bonuses is the potential to obtain real winnings. While the amounts may be small, any gains secured from the bonus can typically be withdrawn after meeting the casino’s wagering requirements. This infuses an element of anticipation and delivers a potential financial gain without any initial expenditure.
Learning Opportunity
No-deposit bonuses present a great means to understand how multiple casino games work. Players can try tactics, understand the guidelines of the games, and grow more comfortable without being concerned about losing their own funds. This can be especially advantageous for complex gaming activities like blackjack.
Conclusion
No upfront deposit bonuses offer several upsides for gamblers, like risk-free exploration, the potential to get real rewards, and useful development experiences. As the sector continues to expand, the popularity of free bonuses is anticipated to rise.
психотропное вещество гавайская роза семена купить в москве
real money slots
Exploring Real Money Slots
Introduction
Gambling slots have grown into a favored choice for gaming aficionados seeking the adrenaline of winning genuine cash. This text delves into the perks of cash slots and the causes they are attracting a rising number of players.
Pros of Money Slots
Genuine Rewards
The key appeal of cash slots is the possibility to gain real currency. In contrast to free slots, cash slots provide enthusiasts the thrill of potential financial rewards.
Wide Range of Games
Gambling slots supply a vast range of themes, characteristics, and payout structures. This ensures that there is an activity for all types of players, covering classic three-reel classic slots to modern slot games with several paylines and additional features.
Thrilling Incentives
Many digital casinos offer attractive bonuses for cash slot enthusiasts. These can comprise initial offers, bonus spins, cashback offers, and VIP schemes. Such incentives improve the overall gambling activity and provide further potential to win cash.
Motivations for Opting for Money Slots
The Thrill of Winning Real Money
Cash slots give an exhilarating adventure, as users anticipate the potential of gaining actual cash. This element adds a further layer of excitement to the gameplay activity.
Prompt Payouts
Cash slots give enthusiasts the gratification of immediate payouts. Earning funds instantly improves the casino experience, making it more rewarding.
Diverse Game Options
Including real money slots, gamblers can experience a wide selection of slot machines, guaranteeing that there is continuously an activity fresh to try.
Closing
Real money slots supplies a adrenaline-filled and fulfilling casino experience. With the opportunity to earn genuine cash, a broad array of games, and enticing promotions, it’s clear that various players favor real money slots for their gaming needs.
sweepstakes casino
Exploring Sweepstakes Gambling Platforms: An Engaging and Available Gambling Choice
Preface
Lottery betting sites are becoming a favored substitute for players desiring an captivating and legitimate approach to experience digital playing. As opposed to traditional digital gaming hubs, promotion betting sites operate under different legal structures, facilitating them to provide events and awards without adhering to the same laws. This article examines the idea of lottery casinos, their merits, and why they are appealing to a expanding quantity of gamers.
What is a Sweepstakes Casino?
A sweepstakes casino operates by offering participants with online currency, which can be applied to participate in competitions. Gamers can gain further internet money or real gifts, including cash. The primary distinction from conventional betting sites is that gamers do not acquire currency straightforwardly but acquire it through promotional campaigns, for example purchasing a goods or participating in a complimentary admission lottery. This model allows lottery gaming hubs to run authorized in many areas where standard internet-based wagering is restricted.
https://terra-clean.ru/
Вебкам Студия Санкт-Петербург https://studio-milano.ru/
Хамстер Бой — уникальная развлечение, в которой Вы начинаете как побритый грызун и пытаетесь стать наиболее успешным и безупречным грызуном. Тем не менее это не только развлечение либо заурядный клацалка. Данная игра — будущее криптовалюты, теперь стучащееся в порога бирж и готовящееся к получению своей стоимости.
Помыслите для себя развлечение, где Вы кликаете по хомяка и зарабатываете капитал, в телеграм канале https://t.me/s/hamster_kombat_combo_chat наращивая свои ежесуточные доходы при содействии автоматизированных орудий, а после читаете сводки о том, что ваши монеты подорожали! Вам ничего не теряете, просто нажимайте по грызуна и ожидайте роста стоимости монет.
Вспомните случай про это, как кто-то оплатил пиццу BTC, в то время как Биткоины нуля ни стоили, отдав десять тысяч BTC, что теперь равносильны 676 миллионам 777 тысячам 500 долларам США. Не преуменьшайте Hamster Kombat.
https://match-prognoz.com
Pretty! This was an incredibly wonderful article. Many thanks for providing this information.
arahn.100webspace.net/profile.php?mode=viewprofile&u=142536В
malhotrafoundation.org/media/releasesВ
kronverskiy.ru/topic2171.html?view=printВ
eurodelo.ru/kak-kupit-diplom-bez-lishnih-hlopotВ
http://www.hoyo-oita.com/archives/infomation/6256.htmlВ
1000 mg augmentin
такси эконом вызов такси
https://bi-cleaning.ru/
https://mclean.su/
http://pcphonehome.com
acyclovir no presciption
Pro88
Pro88
bactrim pills – brand tobramycin 10mg tobra us
Pretty part of content. I simply stumbled upon your web site and in accession capital to assert that I get in fact enjoyed account your blog posts. Anyway I will be subscribing in your feeds or even I fulfillment you get entry to persistently fast.
zhaktrans.ru/p40135689-tnvd-wd615-612601080225.htmlВ
http://www.andorracf.com/datosprimerequipo.php?ids=PlantillaВ
lefolyotakaritas.hu/nyomvonal-meghatarozas/В
jaezfinancialgroup.icu/pages/contact-usВ
kh.txi.ru/forum/index.php?s=94e2ca132842f3902ab7ad72c82e8ae0&showtopic=478В
эффективно,
Лучшие стоматологи города, для крепких и здоровых зубов,
Специализированная помощь по доступным ценам, для вашей улыбки,
Индивидуальный подход к каждому пациенту, для вашей радости и улыбки,
Эффективное лечение зубов и десен, для вашего комфорта и уверенности,
Индивидуальный план лечения и профилактики, для вашего здоровья и уверенности в себе,
Современное лечение заболеваний полости рта, для вашего комфорта и удовлетворения
дитяча стоматологія https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
провести технический аудит сайта [url=http://prodvizhenie-sajtov-v-moskve113.ru/]http://prodvizhenie-sajtov-v-moskve113.ru/[/url] .
гарантированно,
Индивидуальный подход к каждому пациенту, для поддержания здоровья рта,
Современные методы стоматологии, для вашего удобства,
Бесплатная консультация и диагностика, для вашего здоровья и благополучия,
Эффективное лечение зубов и десен, для вашего комфорта и уверенности,
Экстренная помощь в любое время суток, для вашего здоровья и уверенности в себе,
Современное лечение заболеваний полости рта, для вашего здоровья и благополучия
зуби лікування https://stomatologichnaklinikafghy.ivano-frankivsk.ua/ .
клининговые услуги в москве уборка квартир после ремонта
geinoutime.com
이제 그는 백가의 관리가 되었으니 유니콘 수트도 하사받을 것이고 세상은 광대 할 것이며 많은 일을 할 것입니다.
настоящие вебсайты на телеграм канале https://t.me/casino_oficialnij игорных домов зачастую применяют адрес старшего категории, подобный наподобие .com иль .net. Станьте настороже, коль ресурс задействует нестандартные доменные названия или доменные адреса с значительным количеством черточек, чисел, что возможно является проявлением обманного веб-сайта.
Легитимные игорные дома постоянно обозначают сведения об своей разрешении на заметном участке ресурса, чаще всего на низшей части главной страницы. Данная разрешение обязана быть предоставлена почитаемым надзорным структурой, такого типа наподобие Комиссия для рискованным играм Великобритании, Мальтийских островов иль Кюрасао.
можно ли купить диплом https://6landik-diploms.com
http://www.russa24-diploms-srednee.com
На нашем сайте вы найдете самую актуальную информацию о покупке и продаже недвижимости.
Ознакомьтесь с такими темами, как [url=https://kadprof.ru/]квартира в новостройке[/url] и [url=https://kadprof.ru/]инвестиции в недвижимость[/url].
Мы поможем вам принять взвешенное решение при покупке или продаже жилья, а также предоставим актуальную информацию о рынке недвижимости.
Удобный поиск, актуальные объявления и информативные статьи – все это доступно у нас!
заказ такси эконом новочеркасск https://zakaz-taxionline.ru/
Esa fundamental y vital https://telegra.ph/Euro-2024-UEFA—Apuestas-de-f%C3%BAtbol-06-10 instrumento para intervenir en eventos deportivos es una compania de apuestas. En la mayor parte de aquellos situaciones, aquellas jugadas se hacen de manera a distancia. Hoy en dia, se encuentran abundantes posibilidades para realizar apuestas de futbol a via una aplicacion o en aquel portal de internet de cierta casa de apuestas. Se logra hallar cierta enumeracion completa de las companias de apuestas con autorizacion en Espana y la nacion mexicana en aquellas paginas de nuestro servicio. Nunca posee significado participar con un operador de apuestas ilegal: ciertamente nunca se hallaran superiores ganancias, y el riesgo relacionado de perder fondos al toparse con defraudadores se incrementa exponencialmente. Despues de seleccionar una empresa de apuestas con licencia apropiada, es preciso recurrir a medios adicionales extra destinadas al jugador. Analicemos algunas de aquellas muy populares.
Хотите быть в курсе всех актуальных тем в сфере недвижимости?
На нашем ресурсе вы найдете много полезных статей о квартирах от застройщика, а также о анализе рынка недвижимости.
Узнайте все, что вам необходимо для успешных сделок и принятия важных решений в области недвижимости.
https://prestizh-stroi.ru
безопасно,
Индивидуальный подход к каждому пациенту, для поддержания здоровья рта,
Профессиональное лечение и консультации, для вашей улыбки,
Комфортные условия и дружественный персонал, для вашего здоровья и благополучия,
Инновационные методы стоматологии, для вашего комфорта и уверенности,
Профессиональная гигиена полости рта, для вашего здоровья и уверенности в себе,
Современное лечение заболеваний полости рта, для вашей уверенной улыбки
протезування зубів протезування зубів .
http://kenhhocsinh.com
На нашем сайте вы сможете найти все необходимые сведения о недвижимости – от бронирования жилья в новостройке до покупки недвижимости от застройщика.
Мы поможем вам выбрать лучшую квартиру в новостройке, расскажем, как не попасть в ловушку при выборе жилья и подскажем, как сэкономить время и деньги.
Заходите: https://quartz-rsk.ru
вайлд вест голд игровой автомат
Euro 2024
lucky jet 1win [url=https://1win-luckyjet-ru.ru/]lucky jet 1win[/url] .
Хотите узнать всё о процессе регистрации квартиры в собственность?
Наш интернет-ресурс предлагает вам самые актуальные статьи на тему покупки и продажи недвижимости.
Здесь вы найдете ответы на все интересующие вас вопросы и получите подробную информацию о процессе оформления жилья.
https://krovlistroy.ru/
куда можно пожаловаться на сайт мошенников [url=https://pozhalovatsya-na-moshennikov.ru/]pozhalovatsya-na-moshennikov.ru[/url] .
Отечественный изготовитель продает силовые тренажеры на sport silovye trenazhery по низким ценам. Ассортимент предлагает штанги, блины, эллиптические тренажеры. В продаже доступные машины и снаряды для реализации спортивных планов. Оформляйте машину Смита, одинарный Кроссовер, Баттерфляй для грудных и дельтовидных мышц, горизонтальную тягу, тренажер Скотта, тренажер для плечей, жим ногами, Пресс машину 3 в 1, Гравитрон для подтягивания и отжиманий, обратную гиперэкстензию, рычажные Хаммеры и другое оборудование.
Euro
http://moscowgadget.ru
На нашем портале вы сможете найти любую информацию о приобретении недвижимости – от [url=https://st-potolki.ru/]покупки квартиры с ремонтом[/url] до [url=https://st-potolki.ru/]бронирования квартиры в ЖК[/url].
Доверьтесь профессионалам и сделайте правильный выбор с нами!
order forxiga 10 mg – forxiga 10mg cheap precose tablet
Лучшие модели колясок Cybex на рынке, для вашего выбора.
Коляска Cybex: комфорт и безопасность в одном, которые порадуют каждого.
5 причин выбрать именно коляску Cybex для вашего малыша, которые заставят вас влюбиться в этот бренд.
Коляска Cybex: безопасность и стиль в одном флаконе, которые не оставят вас равнодушными.
Элегантные решения для вашего ребенка – коляски Cybex, учитывая все особенности и пожелания.
Как правильно подобрать коляску Cybex для вашей семьи, исходя из индивидуальных потребностей и предпочтений.
Коляска Cybex: высокое качество и стильный дизайн, которые ценят комфорт и безопасность.
Топ-модели колясок Cybex на любой вкус и цвет, которые порадуют вас своим разнообразием и качеством.
Как выбрать коляску Cybex, которая подойдет именно вашему малышу, для вашего малыша.
Выбор коляски Cybex: что важно знать перед покупкой, чтобы сделать правильный выбор.
Коляска Cybex: стиль, комфорт и безопасность, которые не оставят вас равнодушными.
5 важных критериев при выборе коляски Cybex, которые порадуют вас своим качеством и функционалом.
Как выбрать коляску Cybex: главные моменты, которые стоит рассмотреть перед покупкой.
Топ-5 колясок Cybex для вашей семьи, если вы цените качество и комфорт.
Выбор коляски Cybex для вашего малыша: как не ошибиться, которые ценят надежность и стиль.
Новинки колясок Cybex, которые стоит рассмотреть, перед совершением покупки.
Коляска Cybex: безопасность и комфорт для вашего малыша, исходя из личных предпочтений и потребностей.
Особенности выбора коляски Cybex: как сделать правильный выбор, которые не оставят вас равнодушными.
cybex коляска 3 в 1 cybex коляска 3 в 1 .
На нашем портале вы найдете самую полезную информацию о [url=https://zel29.ru/]недвижимости в новостройках[/url].
Ознакомьтесь с такими темами, как [url=https://zel29.ru/]продажа жилья[/url] и [url=https://zel29.ru/]аренда загородной недвижимости[/url].
Мы поможем вам принять взвешенное решение при покупке или продаже жилья!
Лучшие модели колясок Tutis, Как выбрать идеальную коляску от Tutis?, Tutis: самый модный цвет этого сезона, для девочки, подробное руководство для родителей, Tutis: идеальный выбор для активных семей, секреты успешного выбора, Как правильно ухаживать за коляской Tutis?, чтобы сохранить отличное состояние, рекомендации по безопасности, Почему Tutis подойдет и летом, и зимой, Почему Tutis лучше всего подходит для вашей семьи?, секреты успешного выбора, секреты качественного производства, Почему Tutis – выбор стильных родителей, Как Tutis помогает справиться с повседневными задачами родителей?, надежность и комфорт в каждом шаге
коляска тутис 3 в 1 цена https://kolyaskatutis.ru/ .
Excellent, what a web site it is! This web site provides helpful data to us, keep it up.
glonet.com/blog/22823/%D0%B8%D0%B7%D0%B1%D0%B0%D0%B2%D1%8C%D1%82%D0%B5%D1%81%D1%8C-%D0%BE%D1%82-%D1%81%D0%BB%D0%BE%D0%B6%D0%BD%D0%BE%D1%81%D1%82%D0%B5%D0%B9-%D1%81-%D1%83%D1%87%D0%B5%D0%B1%D0%BE%D0%B9-%D0%BA%D1%83%D0%BF%D0%B8%D1%82%D0%B5-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC/В
http://www.apicarrara.it/modules.php?name=Journal&file=display&jid=3511В
aboutallfinance.ru/page/39В
balaklavskiy-16.ru/user/9827/В
mymotospeed.ru/page/4В
купить мебель недорого
https://formomebel.ru/stoliki/iz-mramora
купить диплом колледжа [url=http://russa24-diploms-srednee.com]http://russa24-diploms-srednee.com[/url] .
аниме онлайн атака титанов атака титанов в хорошем качестве
Выбирайте коляску Cybex для комфорта вашего ребенка, для вашего выбора.
Коляска Cybex: комфорт и безопасность в одном, для самых взыскательных.
Почему стоит обратить внимание на коляски Cybex, которые заставят вас влюбиться в этот бренд.
Идеальный выбор для заботливых родителей – коляски Cybex, которые не оставят вас равнодушными.
Элегантные решения для вашего ребенка – коляски Cybex, учитывая все особенности и пожелания.
Советы по выбору коляски Cybex для вашего малыша, исходя из индивидуальных потребностей и предпочтений.
Коляска Cybex: высокое качество и стильный дизайн, которые ценят комфорт и безопасность.
Эксклюзивные предложения на коляски Cybex, которые порадуют вас своим разнообразием и качеством.
Ключевые моменты, на которые стоит обратить внимание при выборе коляски Cybex, для вашего малыша.
Выбор коляски Cybex: что важно знать перед покупкой, чтобы сделать правильный выбор.
Элегантные решения для вашей семьи – коляски Cybex, которые не оставят вас равнодушными.
5 важных критериев при выборе коляски Cybex, которые порадуют вас своим качеством и функционалом.
Идеальная коляска Cybex: комфорт и удобство для вашего малыша, которые стоит рассмотреть перед покупкой.
Коляска Cybex для вашего малыша: лучшие модели, если вы цените качество и комфорт.
Лучшие модели колясок Cybex: подробный обзор, которые ценят надежность и стиль.
Топ-модели колясок Cybex для вашей семьи, перед совершением покупки.
Коляска Cybex: безопасность и комфорт для вашего малыша, исходя из личных предпочтений и потребностей.
Как выбрать идеальную коляску Cybex для вашего малыша: главные моменты, которые не оставят вас равнодушными.
коляска cybex прогулочная https://kolyaskicybex.ru/ .
В нашем мире, где аттестат – это начало отличной карьеры в любой отрасли, многие стараются найти максимально простой путь получения качественного образования. Наличие официального документа сложно переоценить. Ведь именно он открывает двери перед всеми, кто собирается вступить в профессиональное сообщество или продолжить обучение в высшем учебном заведении.
В данном контексте мы предлагаем быстро получить любой необходимый документ. Вы можете приобрести аттестат, и это становится выгодным решением для всех, кто не смог завершить образование или утратил документ. Каждый аттестат изготавливается с особой тщательностью, вниманием к мельчайшим деталям, чтобы на выходе получился документ, 100% соответствующий оригиналу.
Преимущество такого решения состоит не только в том, что вы сможете оперативно получить аттестат. Процесс организовывается удобно, с профессиональной поддержкой. От выбора требуемого образца до консультаций по заполнению персональных данных и доставки в любой регион России — все будет находиться под полным контролем качественных специалистов.
Таким образом, для всех, кто пытается найти максимально быстрый способ получения требуемого документа, наша компания готова предложить отличное решение. Купить аттестат – значит избежать долгого процесса обучения и сразу переходить к личным целям, будь то поступление в ВУЗ или начало карьеры.
https://www.saluttunisia.com/jomsocial/groups/viewbulletin/44-izvestnyj-internet-magazin-s-ogromnym-katalogom-diplomov.html?groupid=101
сериал голяк https://golyak-serial-online.ru
trouver un mГ©dicament en pharmacie: Pharmacies en ligne certifiees – vente de mГ©dicament en ligne
Добро пожаловать на наш портал, где вы можете прочитать множество информационных статей на такие темы, как [url=https://findombani.ru/]приемка недвижимости[/url], и на многие другие.
Узнайте больше о том, как [url=https://findombani.ru/]купить квартиру от застройщика[/url]. Мы поможем вам стать подкованным покупателем, и избежать различных проблем в будущем!
Лучшие модели колясок Tutis, выбор мамочек в-the-know, Tutis: самый модный цвет этого сезона, универсальный вариант, подробное руководство для родителей, Tutis: идеальный выбор для активных семей, рекомендации профессионалов, Инструкция по уходу за коляской Tutis, для продления срока службы, Как сделать прогулку с Tutis особенно комфортной?, Tutis: лучший выбор для любого сезона, Как выбрать коляску Tutis, подходящую для вашего стиля жизни?, Почему Tutis – марка будущего, технологии, делающие коляски лучше, Как подчеркнуть свой стиль с помощью коляски Tutis?, Как Tutis помогает справиться с повседневными задачами родителей?, надежность и комфорт в каждом шаге
коляска tutis viva коляска tutis viva .
купить диплом в москве [url=https://russa24-diploms-srednee.com/]https://russa24-diploms-srednee.com/[/url] .
гейтс оф олимпус слот [url=https://gates-of-olympus-ru.ru]гейтс оф олимпус слот[/url] .
에그 카지노
“…” Hongzhi 황제는 그것을 도울 수 없었습니다. “나는 …”
Откройте дверь в мир недвижимости с нашим сайтом! У нас вы найдете полезные статьи на самые популярные темы: [url=https://ecolife2.ru]аренда жилья[/url], а также [url=https://ecolife2.ru]коммерческая недвижимость[/url]. Станьте экспертом в этой сфере, благодаря нашим информативным материалам!
singobet
Читайте полезные статьи на актуальные темы, связанные с продажей жилья, например квартира от застройщика или налог на недвижимость.
Сайт: https://ooo-trotuar.ru
lyrica 150 mg capsule
Желаете стать профи в сфере недвижимости? Наш ресурс – это ваш незаменимый помощник! Мы предлагаем огромное количество полезных статей на такие темы, как [url=https://opk-ekb.ru]покупка квартиры в новостройке[/url], а также [url=https://opk-ekb.ru]покупка жилья[/url]. Наши эксперты поделятся с вами ценной информацией, чтобы помочь вам принимать взвешенные решения в сфере недвижимости!
В нашем мире, где аттестат является началом отличной карьеры в любом направлении, многие ищут максимально быстрый путь получения образования. Наличие официального документа сложно переоценить. Ведь диплом открывает двери перед каждым человеком, который стремится начать трудовую деятельность или учиться в ВУЗе.
В данном контексте мы предлагаем быстро получить любой необходимый документ. Вы имеете возможность приобрести аттестат, и это будет отличным решением для всех, кто не смог завершить образование, потерял документ или желает исправить плохие оценки. Аттестаты изготавливаются аккуратно, с максимальным вниманием к мельчайшим элементам. В итоге вы сможете получить документ, 100% соответствующий оригиналу.
Плюсы подобного подхода заключаются не только в том, что вы сможете быстро получить аттестат. Процесс организован комфортно, с профессиональной поддержкой. От выбора подходящего образца аттестата до правильного заполнения личной информации и доставки по стране — все будет находиться под полным контролем качественных специалистов.
Таким образом, всем, кто ищет быстрый способ получения необходимого документа, наша компания готова предложить выгодное решение. Приобрести аттестат – значит избежать долгого обучения и сразу переходить к своим целям: к поступлению в университет или к началу успешной карьеры.
https://www.veloxrugby.com/contactus.htm
Хотите быть в курсе всех важных тем в сфере недвижимости?
На нашем ресурсе вы найдете множество полезных статей о [url=https://starextorg.ru]покупке и продаже жилья[/url], а также о [url=https://starextorg.ru]регистрации квартиры[/url].
Узнайте все, что вам необходимо для успешных сделок и принятия взвешенных решений в сфере недвижимости.
https://seocoefficienta.wikibyby.com/721362/Как_заказать_услуги_xrumer_art
Thanks for another informative web site. Where else could I am getting that type of information written in such an ideal manner? I have a project that I’m simply now operating on, and I’ve been at the look out for such info.
http://musey-uglich.ru/
https://lala.lanbook.com/virtualnaya-i-dopolnennaya-realnosti-v-obuchenii
daddy казино регистрация
bimabet
파라오 슬롯
글쎄, 음식은 사람들에게 가장 중요한 것이므로 먼저 배를 채우고 계획을 세우십시오.
bocor88
bocor88
https://tennissherbrooke.ca/magnumbet
http://stroymaterial39.ru/
etodolac sale – buy monograph generic buy cilostazol pills
квартиры от застройщика жк https://kvartiru-kupit78.ru
娛樂城
2024娛樂城介紹
台灣2024娛樂城越開越多間,新開的線上賭場層出不窮,每間都以獨家的娛樂城優惠和體驗金來吸引玩家,致力於提供一流的賭博遊戲體驗。以下來介紹這幾間娛樂城網友對他們的真實評價,看看哪些娛樂城上榜了吧!
2024娛樂城排名
2023下半年,各家娛樂城競爭激烈,相繼推出誘人優惠,不論是娛樂城體驗金、反水流水還是首儲禮金,甚至還有娛樂城抽I15手機。以下就是2024年網友推薦的娛樂城排名:
NO.1 富遊娛樂城
NO.2 Bet365台灣
NO.3 DG娛樂城
NO.4 九州娛樂城
NO.5 亞博娛樂城
2024娛樂城推薦
根據2024娛樂城排名,以下將富遊娛樂城、BET365、亞博娛樂城、九州娛樂城、王者娛樂城推薦給大家,包含首儲贈點、免費體驗金、存提款速度、流水等等…
娛樂城遊戲種類
線上娛樂城憑藉其廣泛的遊戲種類,成功滿足了各式各樣玩家的喜好和需求。這些娛樂城遊戲不僅多元化且各具特色,能夠為玩家提供無與倫比的娛樂體驗。下面是一些最受歡迎的娛樂城遊戲類型:
電子老虎機
魔龍傳奇、雷神之鎚、戰神呂布、聚寶財神、鼠來寶、皇家777
真人百家樂
真人視訊百家樂、牛牛、龍虎、炸金花、骰寶、輪盤
電子棋牌
德州撲克、兩人麻將、21點、十三支、妞妞、三公、鬥地主、大老二、牌九
體育下注
世界盃足球賽、NBA、WBC世棒賽、英超、英雄聯盟LOL、特戰英豪
線上彩票
大樂透、539、美國天天樂、香港六合彩、北京賽車
捕魚機遊戲
三仙捕魚、福娃捕魚、招財貓釣魚、西遊降魔、吃我一砲、賓果捕魚
2024娛樂城常見問題
娛樂城是什麼?
娛樂城/線上賭場(現金網)是台灣對於線上賭場的特別稱呼,而且是現金網,大家也許會好奇為什麼不直接叫做線上賭場或是線上博弈就好了。
其實這是有原因的,線上賭場這種東西,架站在台灣是違法的,在早期經營線上博弈被抓的風險非常高所以換了一個打模糊仗的代稱「娛樂城」來規避警方的耳目,畢竟以前沒有Google這種東西,這樣的代稱還是多少有些作用的。
信用版娛樂城是什麼?
信用版娛樂城是一種賭博平台,允許玩家在沒有預先充值的情況下參與遊戲。這種模式類似於信用卡,通常以周結或月結的方式結算遊戲費用。因此,如果玩家無法有效管理自己的投注額,可能會在月底面臨巨大的支付壓力。
娛樂城不出金怎麼辦?
釐清原因,如未違反娛樂城機制,可能是遇上黑網娛樂城,請盡快通報165反詐騙。
https://amoxicillinca.shop/# zithromax 500 mg lowest price pharmacy online
prednisone medication Deltasone prednisone 15 mg tablet
https://amoxicillinca.com/# zithromax 500mg price
where can i get amoxicillin 500 mg amoxil doxycyclineca amoxicillin tablets in india
продвижение иностранных сайтов [url=http://prodvizhenie-sajtov-v-moskve113.ru]http://prodvizhenie-sajtov-v-moskve113.ru[/url] .
where can you get amoxicillin: amoxicillin – where to buy amoxicillin
prednisone 54: clomidca.shop – prednisone 50 mg buy
prednisone pill 10 mg: clomidca.shop – steroids prednisone for sale
amoxicillin 500 coupon: buy cheapest antibiotics – amoxicillin online no prescription
台灣線上娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
cheap doxycycline 100mg: azithromycinca.com – doxycycline tablets online india
https://likedquotes.com/?keyword=score808-live
can you buy clomid without insurance cheap fertility drug where buy generic clomid
https://clomidca.shop/# india buy prednisone online
играть крейзи манки [url=http://www.crazy-monkey-ru.ru]играть крейзи манки[/url] .
prednisone clomidca.shop order prednisone 10 mg tablet
Каждый год в течение сентября проводится Тюменский инновационный форум «НЕФТЬГАЗТЭК».
Форум посвящен развитию мнтодов инновационного развития отраслей топливно-энергетического комплекса, дискуссии и поиску решений, организации наилучших условий для развития инновационных проектов. Ежегодный тюменский форум представляетсобой авторитетной дискуссионной площадкой по увеличению роста нефтегазовой сферы в России, содержит высокий статус и актуальность, созвучен корпоративной стратегии развития инновационного курса в Российской Федерации
-https://neftgaztek.ru/
http://clomidca.com/# 40 mg daily prednisone
슬롯 머신 무료
Hongzhi 황제는 말을 마친 후 Fang Jifan을 쳐다볼 수밖에 없었습니다.
http://clomidca.com/# buy prednisone canada
台灣線上娛樂城
在现代,在线赌场提供了多种便捷的存款和取款方式。对于较大金额的存款,您可以选择中国信托、台中银行、合作金库、台新银行、国泰银行或中华邮政。这些银行提供的服务覆盖金额范围从$1000到$10万,确保您的资金可以安全高效地转入赌场账户。
如果您需要进行较小金额的存款,可以选择通过便利店充值。7-11、全家、莱尔富和OK超商都提供这种服务,适用于金额范围在$1000到$2万之间的充值。通过这些便利店,您可以轻松快捷地完成资金转账,无需担心银行的营业时间或复杂的操作流程。
在进行娱乐场提款时,您可以选择通过各大银行转账或ATM转账。这些方法不仅安全可靠,而且非常方便,适合各种提款需求。最低提款金额为$1000,而上限则没有限制,确保您可以灵活地管理您的资金。
在选择在线赌场时,玩家评价和推荐也是非常重要的。许多IG网红和部落客,如丽莎、穎柔、猫少女日记-Kitty等,都对一些知名的娱乐场给予了高度评价。这些推荐不仅帮助您找到可靠的娱乐场所,还能确保您在游戏中享受到最佳的用户体验。
总体来说,在线赌场通过提供多样化的存款和取款方式,以及得到广泛认可的服务质量,正在不断吸引更多的玩家。无论您选择通过银行还是便利店进行充值,都能体验到快速便捷的操作。同时,通过查看玩家的真实评价和推荐,您也能更有信心地选择合适的娱乐场,享受安全、公正的游戏环境。
http://clomidca.com/# purchase prednisone
Что касается скважина на воду цена мы вам обязательно окажем помощь. На представленном веб портале можно узнать приблизительную глубину бурения на собственном участке в видео, а также стоимость. Но самый безупречный способ — это позвать к себе мастера для выявления лучшего места под скважину, определения объема работы и, в соответствии с этим, прайс. Напишите контактный номер телефона и мы свяжемся с Вами в скорое время.
generic amoxicillin cost amoxil amoxicillin tablet 500mg
how to buy clomid without dr prescription: Clomiphene – where to get clomid without dr prescription
zithromax capsules price: amoxicillinca – zithromax z-pak price without insurance
buy doxycycline online 270 tabs: azithromycinca – doxycycline 50 mg price uk
generic piroxicam – piroxicam 20 mg without prescription purchase rivastigmine without prescription
zithromax: buy zithromax amoxicillinca – buy zithromax canada
doxycycline 100: buy tetracycline antibiotics – can i buy doxycycline online
https://amoxicillinca.com/# buy zithromax online
prednisone otc price: clomidca.com – prednisone buying
пожаловаться на сайт мошенников гугл [url=https://pozhalovatsya-na-moshennikov.ru/]pozhalovatsya-na-moshennikov.ru[/url] .
https://doxycyclineca.com/# amoxicillin 500 mg online
娛樂城
Player台灣線上娛樂城遊戲指南與評測
台灣最佳線上娛樂城遊戲的終極指南!我們提供專業評測,分析熱門老虎機、百家樂、棋牌及其他賭博遊戲。從遊戲規則、策略到選擇最佳娛樂城,我們全方位覆蓋,協助您更安全的遊玩。
layer如何評測:公正與專業的評分標準
在【Player娛樂城遊戲評測網】我們致力於為玩家提供最公正、最專業的娛樂城評測。我們的評測過程涵蓋多個關鍵領域,旨在確保玩家獲得可靠且全面的信息。以下是我們評測娛樂城的主要步驟:
安全與公平性
安全永遠是我們評測的首要標準。我們審查每家娛樂城的執照資訊、監管機構以及使用的隨機數生成器,以確保其遊戲結果的公平性和隨機性。
02.
遊戲品質與多樣性
遊戲的品質和多樣性對於玩家體驗至關重要。我們評估遊戲的圖形、音效、用戶介面和創新性。同時,我們也考量娛樂城提供的遊戲種類,包括老虎機、桌遊、即時遊戲等。
03.
娛樂城優惠與促銷活動
我們仔細審視各種獎勵計劃和促銷活動,包括歡迎獎勵、免費旋轉和忠誠計劃。重要的是,我們也檢查這些優惠的賭注要求和條款條件,以確保它們公平且實用。
04.
客戶支持
優質的客戶支持是娛樂城質量的重要指標。我們評估支持團隊的可用性、響應速度和專業程度。一個好的娛樂城應該提供多種聯繫方式,包括即時聊天、電子郵件和電話支持。
05.
銀行與支付選項
我們檢查娛樂城提供的存款和提款選項,以及相關的處理時間和手續費。多樣化且安全的支付方式對於玩家來說非常重要。
06.
網站易用性、娛樂城APP體驗
一個直觀且易於導航的網站可以顯著提升玩家體驗。我們評估網站的設計、可訪問性和移動兼容性。
07.
玩家評價與反饋
我們考慮真實玩家的評價和反饋。這些資料幫助我們了解娛樂城在實際玩家中的表現。
娛樂城常見問題
娛樂城是什麼?
娛樂城是什麼?娛樂城是台灣對於線上賭場的特別稱呼,線上賭場分為幾種:現金版、信用版、手機娛樂城(娛樂城APP),一般來說,台灣人在稱娛樂城時,是指現金版線上賭場。
線上賭場在別的國家也有別的名稱,美國 – Casino, Gambling、中國 – 线上赌场,娱乐城、日本 – オンラインカジノ、越南 – Nhà cái。
娛樂城會被抓嗎?
在台灣,根據刑法第266條,不論是實體或線上賭博,參與賭博的行為可處最高5萬元罰金。而根據刑法第268條,為賭博提供場所並意圖營利的行為,可能面臨3年以下有期徒刑及最高9萬元罰金。一般賭客若被抓到,通常被視為輕微罪行,原則上不會被判處監禁。
信用版娛樂城是什麼?
信用版娛樂城是一種線上賭博平台,其中的賭博活動不是直接以現金進行交易,而是基於信用系統。在這種模式下,玩家在進行賭博時使用虛擬的信用點數或籌碼,這些點數或籌碼代表了一定的貨幣價值,但實際的金錢交易會在賭博活動結束後進行結算。
現金版娛樂城是什麼?
現金版娛樂城是一種線上博弈平台,其中玩家使用實際的金錢進行賭博活動。玩家需要先存入真實貨幣,這些資金轉化為平台上的遊戲籌碼或信用,用於參與各種賭場遊戲。當玩家贏得賭局時,他們可以將這些籌碼或信用兌換回現金。
娛樂城體驗金是什麼?
娛樂城體驗金是娛樂場所為新客戶提供的一種免費遊玩資金,允許玩家在不需要自己投入任何資金的情況下,可以進行各類遊戲的娛樂城試玩。這種體驗金的數額一般介於100元到1,000元之間,且對於如何使用這些體驗金以達到提款條件,各家娛樂城設有不同的規則。
https://azithromycinca.shop/# doxycycline 200 mg pill
how to get amoxicillin over the counter: cheapest amoxicillin – where can i buy amoxicillin online
amoxicillin generic: amoxicillin – amoxicillin capsules 250mg
https://prednisonerxa.com/# how to get clomid
prednisone 10mg tablets: prednisone clomidca – where can you buy prednisone
https://doxycyclineca.shop/# cheap amoxicillin 500mg
http://amoxicillinca.com/# zithromax for sale usa
aviator game online [url=https://www.aviator-crash-game.ru]aviator game online[/url] .
http://doxycyclineca.com/# can we buy amoxcillin 500mg on ebay without prescription
where to get cheap clomid prices: cheap fertility drug – where can i get generic clomid without rx
dino69 slot
prednisone brand name us: clomidca.com – prednisone pack
zithromax cost australia: buy zithromax online – zithromax pill
http://clomidca.com/# purchase prednisone canada
http://azithromycinca.com/# how to get doxycycline without prescription
สล็อต
สล็อตแมชชีนเว็บตรง: ความรื่นเริงที่คุณไม่ควรพลาด
การเล่นสล็อตในปัจจุบันได้รับความนิยมอย่างกว้างขวาง เนื่องจากความสะดวกสบายที่นักเดิมพันสามารถเล่นได้จากทุกที่ทุกเวลา โดยไม่ต้องเสียเวลาในการไปถึงคาสิโน ในบทความนี้ที่เราจะนำเสนอ เราจะกล่าวถึง “สล็อต” และความสนุกที่ผู้เล่นจะได้สัมผัสในเกมสล็อตออนไลน์เว็บตรง
ความง่ายดายในการเล่นสล็อต
หนึ่งในสล็อตที่เว็บตรงเป็นที่ยอดนิยมอย่างยิ่ง คือความง่ายดายที่ผู้ใช้ได้สัมผัส คุณสามารถเล่นได้ทุกที่ตลอดเวลา ไม่ว่าจะเป็นที่บ้านของคุณ ในที่ทำงาน หรือถึงแม้จะอยู่ในการเดินทาง สิ่งที่คุณต้องมีคือเครื่องมือที่เชื่อมต่ออินเทอร์เน็ตได้ ไม่ว่าจะเป็นโทรศัพท์มือถือ แทปเล็ต หรือโน้ตบุ๊ก
นวัตกรรมกับสล็อตออนไลน์เว็บตรง
การเล่นเกมสล็อตในปัจจุบันนี้ไม่เพียงแต่สะดวก แต่ยังประกอบด้วยเทคโนโลยีที่ทันสมัยใหม่ล่าสุดอีกด้วย สล็อตที่เว็บตรงใช้เทคโนโลยีที่ทันสมัย HTML5 ซึ่งทำให้ท่านไม่ต้องกังวลใจเกี่ยวกับการลงซอฟต์แวร์หรือแอปพลิเคชันเสริม แค่ใช้เบราว์เซอร์บนเครื่องมือของคุณและเข้าไปที่เว็บของเรา คุณก็สามารถเริ่มเล่นได้ทันที
ตัวเลือกหลากหลายของเกมสล็อตออนไลน์
สล็อตออนไลน์เว็บตรงมาพร้อมกับความหลากหลายของเกมให้เลือกที่ท่านเลือกได้ ไม่ว่าจะเป็นเกมสล็อตแบบคลาสสิกหรือเกมสล็อตที่มาพร้อมกับฟีเจอร์เพิ่มเติมและโบนัสเพียบ ผู้เล่นจะพบว่ามีเกมที่ให้เล่นมากมาย ซึ่งทำให้ไม่เบื่อกับการเล่นสล็อต
การสนับสนุนทุกอุปกรณ์
ไม่ว่าผู้เล่นจะใช้สมาร์ทโฟนระบบ Androidหรือ iOS ท่านก็สามารถเล่นเกมสล็อตออนไลน์ได้อย่างไม่มีสะดุด เว็บไซต์ของเราสนับสนุนระบบปฏิบัติการและทุกเครื่อง ไม่ว่าจะเป็นสมาร์ทโฟนรุ่นล่าสุดหรือรุ่นก่อน หรือแม้กระทั่งแท็บเล็ทและแล็ปท็อป คุณก็สามารถเล่นเกมสล็อตได้ได้อย่างครบถ้วน
ทดลองเล่นเกมสล็อต
สำหรับมือใหม่กับการเล่นเกมสล็อต หรือยังไม่แน่นอนเกี่ยวกับเกมที่อยากเล่น PG Slot ยังมีฟีเจอร์ทดลองเล่นสล็อตฟรี ผู้เล่นสามารถทดลองเล่นได้ทันทีโดยไม่ต้องลงทะเบียนหรือฝากเงินลงทุน การทดลองเล่นเกมสล็อตนี้จะช่วยให้คุณเรียนรู้และเข้าใจวิธีการเล่นได้โดยไม่ต้องเสียเงิน
โปรโมชันและโบนัส
หนึ่งในข้อดีของการเล่นเกมสล็อตกับ PG Slot คือมีโบนัสและโปรโมชั่นมากมายสำหรับนักเดิมพัน ไม่ว่าคุณจะเป็นสมาชิกเพิ่งสมัครหรือสมาชิกเก่า ผู้เล่นสามารถใช้โบนัสและโปรโมชันต่าง ๆ ได้ตลอดเวลา ซึ่งจะเพิ่มโอกาสชนะและเพิ่มความสนุกสนานในเกม
บทสรุป
การเล่นสล็อตออนไลน์ที่ PG Slot เป็นการลงทุนที่น่าลงทุน ผู้เล่นจะได้รับความสุขและความง่ายดายจากการเล่นเกมสล็อต นอกจากนี้ยังมีโอกาสรับรางวัลและโบนัสเพียบ ไม่ว่าผู้เล่นจะใช้มือถือ แท็บเล็ทหรือโน้ตบุ๊กรุ่นไหน ก็สามารถร่วมสนุกกับเราได้ทันที อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตออนไลน์ PG Slot วันนี้
pg slot
สล็อตตรงจากเว็บ — ใช้ สมาร์ทโฟน แท็บเลต คอมฯ ฯลฯ เพื่อเล่น
ระบบสล็อตเว็บตรง ของ พีจีสล็อต ได้รับการพัฒนาและปรับแต่ง เพื่อให้ รองรับการใช้งาน บนอุปกรณ์ที่หลากหลายได้อย่าง สมบูรณ์ ไม่สำคัญว่าจะใช้ มือถือ แท็บเล็ต หรือ คอมพิวเตอร์ส่วนตัว แบบไหน
ที่ PG Slot เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ จากผู้เล่น ในเรื่อง การใช้งานง่าย และ การเข้าถึงเกมออนไลน์อย่างรวดเร็ว เราจึง นำ HTML 5 มาใช้ ซึ่งเป็น เทคโนโลยีล่าสุด ในตอนนี้ มาพัฒนาเว็บไซต์ของเรากันเถอะ คุณจึงไม่ต้อง โหลดแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดเว็บเบราว์เซอร์ บนอุปกรณ์ที่ มีอยู่ของคุณ และเยี่ยมชม เว็บของเรา คุณสามารถ สนุกกับสล็อตได้ทันที
การสนับสนุนหลายอุปกรณ์
ไม่ว่าคุณจะใช้ มือถือ ระบบ แอนดรอยด์ หรือ iOS ก็สามารถ เล่นเกมสล็อตได้อย่างไม่มีปัญหา ระบบของเรา ออกแบบมาเพื่อรองรับ ระบบปฏิบัติการทั้งหมด ไม่สำคัญว่าคุณ ใช้ มือถือ เครื่องใหม่หรือเครื่องเก่า หรือ แม้แต่แท็บเล็ตหรือแล็ปท็อป ทุกอย่างก็สามารถ ใช้งานได้ ไม่มีปัญหา ในเรื่องความเข้ากันได้
เล่นได้ทุกที่ทุกเวลา
ข้อดีอย่างหนึ่งของการเล่นเว็บสล็อตอย่าง PG Slot นั่นคือ คุณสามารถ เล่นได้ทุกเวลา ไม่ว่าจะ เป็นที่บ้าน ออฟฟิศ หรือแม้แต่ ที่สาธารณะ สิ่งที่คุณต้องมีคือ เน็ต คุณสามารถ เริ่มเกมได้ทันที และคุณไม่ต้อง กังวลเรื่องการโหลด หรือติดตั้งโปรแกรมที่ เปลืองพื้นที่อุปกรณ์
เล่นสล็อตฟรี
เพื่อให้ ผู้เล่นใหม่ มีโอกาสลองและสัมผัสประสบการณ์สล็อตแมชชีนของเรา PG Slot ยังมีบริการสล็อตฟรี คุณสามารถ ทดลองเล่นได้ทันทีโดยไม่ต้องสมัครหรือฝากเงิน การ ทดลองเล่นสล็อตแมชชีนฟรีนี้จะช่วยให้คุณเรียนรู้วิธีเล่นและเข้าใจเกมก่อนตัดสินใจเดิมพันด้วยเงินจริง
บริการและการรักษาความปลอดภัย
PG Slot มุ่งมั่นที่จะให้บริการที่ดีที่สุดแก่ลูกค้า เรามี ทีมงานมืออาชีพพร้อมให้บริการและช่วยเหลือคุณตลอด 24 ชั่วโมง นอกจากนี้เรายังมี ระบบรักษาความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลและการเงินของคุณจะปลอดภัย
โปรโมชันและโบนัส
อีกข้อดีของการเล่นสล็อตกับ PG Slot คือ มี โปรโมชันและโบนัสพิเศษสำหรับสมาชิก ไม่ว่าคุณจะเป็น ผู้เล่นใหม่หรือเก่า คุณสามารถ รับโปรโมชันและโบนัสได้เรื่อย ๆ สิ่งนี้จะ เพิ่มโอกาสในการชนะและเพิ่มความเพลิดเพลินในเกม
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
where to buy prednisone in australia: clomidca.shop – prednisone 2 mg
zithromax online: buy zithromax online – zithromax purchase online
amoxicillin 500 mg: doxycyclineca – amoxicillin price canada
prednisone 10 mg tablet cost: Steroid – buy prednisone from canada
https://clomidca.com/# 80 mg prednisone daily
prednisone 25mg from canada: prednisone – 1 mg prednisone cost
http://doxycyclineca.com/# amoxicillin 250 mg price in india
http://clomidca.com/# prednisone 50 mg canada
doxycycline minocycline: azithromycinca.com – buy doxycycline 100mg cheap
how to get doxycycline: buy tetracycline antibiotics – order doxycycline no prescription
เมื่อเทียบ ไซต์ PG Slots ในขณะที่ มี จุดเด่น หลายประการ แตกต่างจาก คาสิโนแบบ ดั้งเดิม, โดยเฉพาะ ใน ปัจจุบัน. ประโยชน์สำคัญ เหล่านี้ เช่น:
ความคล่องตัว: คุณ สามารถเข้าร่วม สล็อตออนไลน์ได้ ตลอดเวลา จาก ทุกอย่าง, ทำให้ ผู้เล่นสามารถ เข้าร่วม ได้ ทุกสถานที่ ไม่ต้อง เสียเวลา ไปคาสิโนแบบ ดั้งเดิม ๆ
เกมที่หลากหลาย: สล็อตออนไลน์ มี ประเภทเกม ที่ แตกต่างกัน, เช่น สล็อตรูปแบบคลาสสิค หรือ รูปแบบเกม ที่มี คุณสมบัติ และโบนัส พิเศษ, ไม่ทำ ความเบื่อ ในเกม
โปรโมชั่น และรางวัล: สล็อตออนไลน์ ส่วนใหญ่ เสนอ ข้อเสนอส่งเสริมการขาย และประโยชน์ เพื่อเพิ่ม ความสามารถ ในการ ได้รับรางวัล และ เพิ่ม ความบันเทิง ให้กับเกม
ความปลอดภัย และ ความไว้วางใจ: สล็อตออนไลน์ มักจะ ใช้งาน มาตรการรักษาความปลอดภัย ที่ เหมาะสม, และ ทำให้มั่นใจ ว่า ข้อมูลลับ และ การทำธุรกรรม จะได้รับการ ปกป้อง
บริการสนับสนุน: PG Slots มีทีม ผู้ให้บริการ ที่มีประสบการณ์ ที่พร้อม ดูแล ตลอดเวลา
การเล่นบนมือถือ: สล็อต PG รองรับ การเล่นบนโทรศัพท์, อำนวย ผู้เล่นสามารถเข้าร่วม ในทุกที่
เล่นทดลองฟรี: ต่อ ผู้เล่นเริ่มต้น, PG ยังมี เล่นฟรี อีกด้วย, ช่วยให้ คุณ ทำความเข้าใจ การเล่น และเรียนรู้ เกมก่อน เล่นด้วยเงินจริง
สล็อต PG มี ประโยชน์ เป็นจำนวนมาก ที่ ทำ ให้ได้รับความนิยม ในยุคปัจจุบัน, ช่วย ความรู้สึก ความผ่อนคลาย ให้กับเกมด้วย.
online play aviator game [url=https://aviator-crash-game.ru]https://aviator-crash-game.ru[/url] .
Заходите на наш портал, где вы найдете большое количество полезных статей на тему приемки квартиры в новостройке или покупки квартиры без отделки. Узнайте, как защитить себя от недобросовестных застройщиков, какие проверки осуществить перед покупкой жилья, и о многом другом!
https://citadel-ca.ru
무료 슬롯 게임
“라오칭의 가족이 여기 있습니다.” 홍지 황제의 얼굴이 부드러워졌다.
마종 웨이즈
이 두 곳은 모두 명나라의 문으로 공격을 받으면 세상이 흔들릴 것입니다.
ทดลองเล่นสล็อต pg ซื้อฟรีสปิน
สำรวจเล่นสล็อต PG ซื้อฟรีสปิน
ในปัจจุบันนี้ การเล่นเกมสล็อตบนอินเทอร์เน็ตได้รับความชื่นชอบอย่างมาก เฉพาะเกมสล็อตจากผู้ผลิต PG Slot ที่มีคุณสมบัติพิเศษมากมายให้นักเล่นได้สนุกสนาน หนึ่งในลักษณะพิเศษที่น่าสนใจและทำให้การเล่นสนุกยิ่งขึ้นคือ “การซื้อฟรีสปิน” ซึ่งเป็นการเพิ่มช่องทางในการชนะและเพิ่มความเร้าใจในการเล่น
ฟรีสปินคืออะไร?
การซื้อตัวเลือกหมุนฟรีคือการที่นักพนันสามารถซื้อโอกาสในการหมุนวงล้อสล็อตโดยไม่ต้องรอให้เกิดไอคอนฟรีสปินบนวงล้อ ซึ่งเป็นการเพิ่มช่องทางในการได้รับของขวัญพิเศษต่างๆ ภายในเกม เช่น โบนัสพิเศษ แจ็คพอต และอื่นๆ นอกเหนือจากนี้ การซื้อฟรีสปินยังช่วยให้นักเล่นสามารถเพิ่มจำนวนเงินที่ได้ได้อย่างรวดเร็วและมีมีผลดี
ข้อได้เปรียบของการลองเล่นสล็อต PG ซื้อรอบหมุนฟรี
เพิ่มโอกาสในการชนะ: การซื้อตัวเลือกฟรีสปินช่วยให้ผู้เล่นมีโอกาสในการได้รับของขวัญมากขึ้น เนื่องด้วยมีการหมุนวงล้อฟรีเพิ่มเติม ซึ่งอาจนำพาไปถึงการได้รับแจ็คพอตหรือโบนัสพิเศษอื่นๆ
ประหยัดเวลาทำงาน: การซื้อฟรีสปินช่วยประหยัดเวลาในการเล่นในการเล่น จากที่ไม่ต้องรอให้เกิดสัญญาณฟรีสปินบนวงล้อ ผู้ใช้งานสามารถเข้าโหมดฟรีสปินได้ทันที
ลองหมุนฟรี: สำหรับนักพนันที่ยังไม่แน่ใจเกี่ยวกับเกม PG Slot ยังมีโหมดทดลองเล่นฟรีผู้เล่นได้ทดสอบหมุนและศึกษาเทคนิคการเล่นก่อนที่จะเลือกที่จะซื้อฟรีสปินด้วยเงินจริง
เพิ่มความสนุก: การซื้อตัวเลือกการหมุนฟรีช่วยเพิ่มความบันเทิงในการเล่น จากที่ผู้เล่นสามารถเข้ารอบโบนัสและลักษณะพิเศษพิเศษอื่นๆ ได้อย่างง่ายดาย
กระบวนการซื้อฟรีสปินในสล็อต PG
เลือกเกมที่ต้องการหมุนจากค่าย PG Slot
คลิกที่ปุ่มซื้อ “ซื้อฟรีสปิน” ที่แสดงผลบนหน้าจอเกม
ใส่จำนวนฟรีสปินที่ต้องการใช้และยืนยันการทำรายการ
เริ่มต้นการหมุนวงล้อและเพลิดเพลินไปกับการเล่น
สรุป
การสำรวจเล่นสล็อต PGและการซื้อฟรีสปินเป็นวิธีที่ยอดเยี่ยมในการเพิ่มความเป็นไปได้ในการชนะและเพิ่มความสนุกสนานในการเล่น ด้วยคุณลักษณะพิเศษพิเศษนี้ นักเล่นสามารถเข้าสู่รอบโบนัสและลักษณะพิเศษพิเศษต่างๆ ได้อย่างเร็วและมีมีผลดี ไม่ว่าคุณจะเป็นใครผู้เล่นใหม่หรือผู้เล่นที่มีความชำนาญ การทดลองเล่นสล็อต PGและการซื้อตัวเลือกการหมุนฟรีจะช่วยให้คุณมีประสบการณ์การเล่นที่น่าตื่นเต้นและสนุกสนานมากยิ่งขึ้น
สำรวจเล่นสล็อต PG ซื้อหมุนฟรี แล้วคุณจะพบกับความสนุกสนานและช่องทางในการชนะที่ไม่มีที่สิ้นสุด
ทดลองเล่นสล็อต pg ฟรี
สล็อตตรงจากเว็บ — สามารถใช้ โทรศัพท์มือถือ แท็บเลต คอมพิวเตอร์ ฯลฯ ในการเล่น
ระบบสล็อตเว็บตรง ของ พีจีสล็อต ได้รับการพัฒนาและปรับปรุง เพื่อให้ สามารถใช้งาน บนอุปกรณ์ที่หลากหลายได้อย่าง สมบูรณ์ ไม่สำคัญว่าจะใช้ โทรศัพท์มือถือ แท็บเลต หรือ คอมฯ แบบไหน
ที่ PG Slot เราเข้าใจถึงสิ่งที่ผู้เล่นต้องการ ของผู้เล่น ในเรื่อง การใช้งานง่าย และ การเข้าถึงเกมคาสิโนที่รวดเร็ว เราจึง ใช้เทคโนโลยี HTML 5 ซึ่งเป็น เทคโนโลยีล่าสุด ในขณะนี้ พัฒนาเว็บของเรา คุณจึงไม่ต้อง โหลดแอป หรือติดตั้งโปรแกรมเพิ่มเติม เพียง เปิดบราวเซอร์ บนอุปกรณ์ที่ มีอยู่ของคุณ และเยี่ยมชม เว็บของเรา คุณสามารถ เพลิดเพลินกับสล็อตแมชชีนได้ทันที
การรองรับอุปกรณ์หลายชนิด
ไม่ว่าคุณจะใช้ มือถือ ระบบ Android หรือ iOS ก็สามารถ เล่นสล็อตได้อย่างราบรื่น ระบบของเรา ออกแบบมาเพื่อรองรับ ทุกระบบปฏิบัติการ ไม่สำคัญว่าคุณ ใช้ โทรศัพท์ ใหม่หรือเก่า หรือ แม้แต่แท็บเล็ตหรือแล็ปท็อป ทุกอย่างก็สามารถ ใช้งานได้อย่างไม่มีปัญหา ไม่มีปัญหา ในเรื่องความเข้ากันได้
เล่นได้ทุกที่ทุกเวลา
ข้อดีอย่างหนึ่งของการเล่นเว็บสล็อตอย่าง PG Slot ก็คือ คุณสามารถ เล่นได้ทุกที่ทุกเวลา ไม่ว่าจะ ที่บ้าน ที่ทำงาน หรือแม้แต่ ที่สาธารณะ สิ่งที่คุณต้องมีคือ การเชื่อมต่ออินเทอร์เน็ต คุณสามารถ เล่นเกมได้ทันที และคุณไม่ต้อง ห่วงเรื่องการดาวน์โหลด หรือติดตั้งโปรแกรมที่ เปลืองพื้นที่อุปกรณ์
ทดลองเล่นสล็อตฟรี
เพื่อให้ ผู้ใช้ใหม่ มีโอกาสลองและสัมผัสประสบการณ์สล็อตแมชชีนของเรา PG Slot ยังเสนอบริการสล็อตทดลองฟรีอีกด้วย คุณสามารถ เล่นได้ทันทีโดยไม่ต้องสมัครสมาชิกหรือฝากเงิน การ ทดลองเล่นสล็อตแมชชีนฟรีนี้จะช่วยให้คุณเรียนรู้วิธีเล่นและเข้าใจเกมก่อนตัดสินใจเดิมพันด้วยเงินจริง
บริการและการรักษาความปลอดภัย
PG Slot มุ่งมั่นที่จะให้บริการที่ดีที่สุดแก่ลูกค้า เรามี ทีมบริการที่พร้อมช่วยเหลือตลอด 24 ชั่วโมง นอกจากนี้เรายังมี ระบบความปลอดภัยที่ทันสมัย ด้วยวิธีนี้ คุณจึงมั่นใจได้ว่า ข้อมูลส่วนบุคคลและธุรกรรมทางการเงินของคุณจะได้รับการปกป้องอย่างดีที่สุด
โปรโมชั่นและโบนัสพิเศษ
อีกข้อดีของการเล่นสล็อตกับ PG Slot ก็คือ มี โปรโมชันและโบนัสพิเศษสำหรับสมาชิก ไม่ว่าคุณจะเป็น สมาชิกใหม่หรือเก่า คุณสามารถ รับโปรโมชันและโบนัสได้ สิ่งนี้จะ เพิ่มโอกาสชนะและสนุกกับเกมมากขึ้น
สรุปการเล่นสล็อตเว็บที่ PG Slot ถือเป็นการลงทุนที่คุ้มค่า คุณจะไม่เพียงได้รับความสุขและความสะดวกสบายจากเกมเท่านั้น แต่คุณยังมีโอกาสลุ้นรับรางวัลและโบนัสมากมายอีกด้วย ไม่สำคัญว่าจะใช้โทรศัพท์มือถือ แท็บเล็ต หรือคอมพิวเตอร์รุ่นใด สามารถมาร่วมสนุกกับเราได้เลยตอนนี้ อย่ารอช้า ลงทะเบียนและเริ่มเล่นสล็อตกับ PG Slot วันนี้!
ความรู้สึกการลองเล่นสล็อต PG บนแพลตฟอร์มพนันโดยตรง: เข้าสู่โลกแห่งความบันเทิงที่ไร้ขีดจำกัด
ต่อนักเสี่ยงทายที่แสวงหาการพบเจอเกมที่ไม่ซ้ำใคร และหวังค้นหาแหล่งวางเดิมพันที่น่าเชื่อถือ, การทำการเกมสล็อต PG บนพอร์ทัลตรงนับว่าเป็นตัวเลือกที่น่าสนใจอย่างมาก. เพราะมีความหลากหลายมากมายของเกมสล็อตแมชชีนที่มีให้เลือกมากมาย, ผู้เล่นจะได้สัมผัสกับโลกแห่งความตื่นเต้นเร้าใจและความสนุกสนานที่ไม่มีที่สิ้นสุด.
พอร์ทัลพนันไม่ผ่านเอเย่นต์นี้ มอบการเล่นการเล่นที่มั่นคง น่าเชื่อถือ และสนองตอบความต้องการของนักวางเดิมพันได้เป็นอย่างดี. ไม่ว่าคุณจะผู้เล่นจะติดใจสล็อตแมชชีนแบบคลาสสิคที่มีความคุ้นเคย หรือต้องการประสบการณ์เกมที่ไม่เหมือนใครที่มีฟังก์ชันเฉพาะตัวและรางวัลพิเศษล้นหลาม, แพลตฟอร์มตรงนี้นี้ก็มีให้เลือกสรรอย่างมากมาย.
เพราะมีระบบการสำรวจสล็อตแมชชีน PG โดยไม่เสียค่าใช้จ่าย, ผู้เล่นจะได้โอกาสที่ดีศึกษาวิธีขั้นตอนเล่นเดิมพันและลองเทคนิคหลากหลาย ก่อนที่จะเริ่มใช้เงินจริงด้วยเงินสด. การกระทำนี้จัดว่าเป็นโอกาสอันดีที่จะสร้างเสริมความพร้อมสรรพและสร้างเสริมโอกาสในการชิงรางวัลใหญ่.
ไม่ว่าคุณจะคุณอาจจะต้องการความสนุกสนานแบบคลาสสิก หรือความยากแปลกใหม่, สล็อตแมชชีน PG บนเว็บไซต์พนันตรงก็มีให้คัดสรรอย่างมากมาย. คุณอาจจะได้ประสบกับประสบการณ์การเล่นเกมพนันที่น่ารื่นเริง น่าตื่นเต้นเร้าใจ และสนุกสนานไปกับโอกาสที่ดีในการชิงรางวัลมหาศาล.
อย่ารอ, ร่วมสนุกสำรวจเกมสล็อตแมชชีน PG บนเว็บเสี่ยงโชคตรงตอนนี้ และค้นพบโลกแห่งความบันเทิงแห่งความสนุกสนานที่ปลอดภัย น่าค้นหา และพร้อมเต็มไปด้วยความสุขสนานรอคอยผู้เล่น. เผชิญความตื่นเต้น, ความเพลิดเพลิน และจังหวะในการได้รางวัลใหญ่มหาศาล. เริ่มต้นเดินไปสู่ความสำเร็จในวงการเกมออนไลน์เดี๋ยวนี้!
[url=https://peregonavtofgtd.kiev.ua]peregonavtofgtd kiev ua[/url]
Я мухой, эффективно равно фундаментально переместить Ваш ярис изо Украины в течение Европу, или с Европы в течение Украину вместе один-два нашей командой. Оформление грамот равно экспортирование производятся в оклеветанные сроки.
https://peregonavtofgtd.kiev.ua
Хотите стать счастливым владельцем собственной недвижимости, но не понятно, с чего начать?
Наш портал предлагает вам полную информацию на такие темы, как [url=https://domstroiservis.ru]покупка недвижимости[/url] или [url=https://domstroiservis.ru]ипотечные программы[/url].
Посетите наш сайт и начните свой путь к новому дому уже сегодня!
купить аккаунт телеграмм навсегда [url=http://kupit-akkaunt-telegramm11.ru]http://kupit-akkaunt-telegramm11.ru[/url] .
폰테크
주제는 폰테크 입니다
휴대폰을 사고 파는 종류의 사이트 입니다
고객이 휴대폰을 개통하고
그럼 저희는 돈을주고 그 휴대폰을 구매합니다.
amoxicillin cephalexin: amoxicillin – amoxicillin order online
Предлагаем вам пройти консультацию (аудит) по усилению продаж и прибыли в вашем бизнесе. Формат аудита: индивидуальная встреча или онлайн конференция по скайпу. Делая верные, но обыкновенные действия, прибыль от ВАШЕГО бизнеса можно увеличить в несколькио раз. В нашем арсенале более 100 проверенных фактических методик подъема торгов а также прибыли. В зависимости от вашего коммерциала подберем для вас максимально наилучшие и будем постепенно претворять в жизнь.
http://r-diplom.ru/
Идеальное решение для отделки помещений плинтус теневой для вашего офиса
теневой плинтус для пола теневой плинтус для пола .
бесплатное русское порно анал с разговорами [url=safavia.ru]safavia.ru[/url] .
Интересуетесь недвижимостью? Наш портал – ваш верный проводник в этой области. Здесь вы найдете множество полезных статей на такие темы, как [url=https://auraclimate.ru/]квартиры в новостройке от застройщика[/url], а также [url=https://auraclimate.ru/]оценка недвижимости[/url].
Подробные аналитические материалы, экспертные советы и простые рекомендации — все это доступно у нас!
купить диплом нового образца http://www.school-10-lik.ru .
Хостинг в Беларуси бесплатно: лучший выбор для вашего сайта, за и против.
Какой хостинг в Беларуси бесплатно выбрать?, советы и рекомендации.
RAIDHOST, HOSTERO, TUT.BY: лучшие бесплатные хостинги в Беларуси, плюсы и минусы.
Шаг за шагом: переезд на хостинг в Беларуси бесплатно, шаги и рекомендации.
Бесплатный SSL для хостинга в Беларуси: зачем он нужен?, характеристики и обзор.
Как создать сайт на бесплатном хостинге в Беларуси?, гайд для начинающих.
Где можно купить хостинг в Беларуси дешево и качественно?, прогноз и анализ.
Хостинг в Беларуси бесплатно Хостинг в Беларуси бесплатно .
Хотите стать счастливым обладателем собственной недвижимости, но не знаете, с чего начать?
Наш портал предлагает вам полную информацию на такие темы, как [url=https://aviator-krd.ru/]выписка из егрн[/url] или [url=https://aviator-krd.ru/]ипотека под залог недвижимости[/url].
Основа стильного интерьера плинтус теневой для вашей квартиры
купить теневой профиль для пола купить теневой профиль для пола .
Хотите быть в курсе всех новых тенденций на рынке недвижимости?
На нашем ресурсе вы найдете информационные статьи на такие темы, как [url=https://bd-rielt.ru/]жилая недвижимость[/url], а также [url=https://bd-rielt.ru/]загородная недвижимость[/url].
Узнавайте первыми о самых актуальных предложениях и важных советах от профессионалов!
הימורי ספורטיביים – הימורים באינטרנט
הימורי ספורט הפכו לאחד התחומים המתפתחים ביותר בהימורים באינטרנט. שחקנים יכולים להמר על תוצאותיהם של אירועי ספורטיביים מוכרים כמו כדור רגל, כדורסל, משחק הטניס ועוד. האפשרויות להימור הן מרובות, כולל תוצאתו המאבק, מספר הגולים, מספר הפעמים ועוד. להלן דוגמאות למשחקי נפוצים שעליהם ניתן להתערב:
כדורגל: ליגת האלופות, מונדיאל, ליגות אזוריות
כדורסל: NBA, ליגת יורוליג, טורנירים בינלאומיים
משחק הטניס: טורניר ווימבלדון, אליפות ארה”ב הפתוחה, אליפות צרפת הפתוחה
פוקר באינטרנט – הימורים באינטרנט
משחק הפוקר ברשת הוא אחד ממשחקי ההימור הפופולריים ביותר בימינו. שחקנים מסוגלים להתחרות נגד יריבים מכל רחבי תבל במגוון גרסאות משחק , כגון Texas Hold’em, אומהה, Stud ועוד. אפשר לגלות תחרויות ומשחקי קש במגוון דרגות ואפשרויות הימור מגוונות. אתרי פוקר המובילים מציעים:
מגוון רחב של גרסאות המשחק פוקר
טורנירים שבועיות וחודשיים עם פרסים כספיים
שולחנות למשחקים מהירים ולטווח ארוך
תוכניות נאמנות ומועדוני VIP VIP יחודיות
בטיחות ואבטחה והגינות
בעת הבחירה פלטפורמה להימורים ברשת, חשוב לבחור אתרים מורשים המפוקחים המציעים גם סביבת למשחק בטוחה והוגנת. אתרים אלה משתמשים בטכנולוגיית אבטחה מתקדמת להגנה על מידע אישי ופיננסי, וכן בתוכנות גנרטור מספרים רנדומליים (RNG) כדי לוודא הגינות המשחקים במשחקי ההימורים.
בנוסף, הכרחי לשחק באופן אחראי תוך כדי הגדרת מגבלות אישיות הימור אישיות של השחקן. רוב האתרים מאפשרים למשתתפים להגדיר מגבלות להפסדים ופעילות, כמו גם להשתמש ב- כלים למניעת התמכרות. שחקו בחכמה ואל תרדפו גם אחר הפסדים.
המדריך המלא למשחקי קזינו באינטרנט, משחקי ספורט ופוקר באינטרנט
הימורים ברשת מציעים גם עולם שלם של הזדמנויות מרתקות למשתתפים, מתחיל מקזינו אונליין וכל בהימורי ספורט ופוקר באינטרנט. בזמן בחירת פלטפורמת הימורים, הקפידו לבחור גם אתרי הימורים המפוקחים המציעים סביבת למשחק בטוחה והגיונית. זכרו גם לשחק בצורה אחראית תמיד – ההימורים ברשת אמורים להיות מבדרים ולא ליצור בעיות פיננסיות או חברתיות.
Наш сайт предлагает вам самые интересные статьи на такие темы, как [url=https://bitarel.ru/]налог на имущество[/url], а также [url=https://bitarel.ru/]регистрация прав на недвижимость[/url].
Изучите интересные статьи на актуальные темы, связанные с недвижимостью, например [url=https://dom-techno161.ru/]декларация о доходах[/url] или [url=https://dom-techno161.ru/]стоимость ремонта квартиры[/url].
купить свидетельство о рождении ссср http://school5-priozersk.ru/ .
Изучите интересные статьи на важные темы, связанные с недвижимостью, например [url=https://mdorm.ru/]ипотека на вторичное жилье[/url] или [url=https://mdorm.ru/]продажа земельного участка[/url].
Почему стоит выбрать хостинг в Беларуси бесплатно?, плюсы и минусы.
Бесплатные хостинги в Беларуси: что выбрать?, инструкции и рекомендации.
3 лучших хостинга в Беларуси бесплатно: наши рекомендации, плюсы и минусы.
Шаг за шагом: переезд на хостинг в Беларуси бесплатно, шаги и рекомендации.
Безопасность сайта: SSL на хостинге в Беларуси бесплатно, плюсы и минусы.
Простая инструкция: создание сайта на бесплатном хостинге в Беларуси, инструкция и рекомендации.
Где можно купить хостинг в Беларуси дешево и качественно?, обзор и сравнение.
Рейтинг хостингов Беларуси Рейтинг хостингов Беларуси .
На нашем портале вы найдете самую полезную информацию о [url=https://tsereteli-art.ru/]стоимости квартир[/url], а также о [url=https://tsereteli-art.ru/]договоре найма жилого помещения[/url].
купить диплом в севастополе купить диплом в севастополе .
Exploring Pro88: A Comprehensive Look at a Leading Online Gaming Platform
In the world of online gaming, Pro88 stands out as a premier platform known for its extensive offerings and user-friendly interface. As a key player in the industry, Pro88 attracts gamers with its vast array of games, secure transactions, and engaging community features. This article delves into what makes Pro88 a preferred choice for online gaming enthusiasts.
A Broad Selection of Games
One of the main attractions of Pro88 is its diverse game library. Whether you are a fan of classic casino games, modern video slots, or interactive live dealer games, Pro88 has something to offer. The platform collaborates with top-tier game developers to ensure a rich and varied gaming experience. This extensive selection not only caters to seasoned gamers but also appeals to newcomers looking for new and exciting gaming options.
User-Friendly Interface
Navigating through Pro88 is a breeze, thanks to its intuitive and well-designed interface. The website layout is clean and organized, making it easy for users to find their favorite games, check their account details, and access customer support. The seamless user experience is a significant factor in retaining users and encouraging them to explore more of what the platform has to offer.
Security and Fair Play
Pro88 prioritizes the safety and security of its users. The platform employs advanced encryption technologies to protect personal and financial information. Additionally, Pro88 is committed to fair play, utilizing random number generators (RNGs) to ensure that all game outcomes are unbiased and random. This dedication to security and fairness helps build trust and reliability among its user base.
Promotions and Bonuses
Another highlight of Pro88 is its generous promotions and bonuses. New users are often welcomed with attractive sign-up bonuses, while regular players can take advantage of ongoing promotions, loyalty rewards, and special event bonuses. These incentives not only enhance the gaming experience but also provide additional value to the users.
Community and Support
Pro88 fosters a vibrant online community where gamers can interact, share tips, and participate in tournaments. The platform also offers robust customer support to assist with any issues or inquiries. Whether you need help with game rules, account management, or technical problems, Pro88’s support team is readily available to provide assistance.
Mobile Compatibility
In today’s fast-paced world, mobile compatibility is crucial. Pro88 is optimized for mobile devices, allowing users to enjoy their favorite games on the go. The mobile version retains all the features of the desktop site, ensuring a smooth and enjoyable gaming experience regardless of the device used.
Conclusion
Pro88 has established itself as a leading online gaming platform by offering a vast selection of games, a user-friendly interface, robust security measures, and excellent customer support. Whether you are a casual gamer or a hardcore enthusiast, Pro88 provides a comprehensive and enjoyable gaming experience. Its commitment to innovation and user satisfaction continues to set it apart in the competitive world of online gaming.
Explore the world of Pro88 today and discover why it is the go-to platform for online gaming aficionados.
Wow, superb blog format! How lengthy have you been running a blog for? you make running a blog look easy. The overall glance of your site is magnificent, let alone the content!
sharypovo.today/news/society/page/9/
financetimenews.ru/page/14/
balivillarental.net/villarental/villa_maridadi.html
http://www.anoreksja.org.pl/posting.php?mode=quote&f=13&p=2906577
sanatoriy-yuscki18.ru/pacient/reviews.php?strIMessage=%D1%EF%E0%F1%E8%E1%EE+%C2%E0%EC+%E7%E0+%EE%F2%E7%FB%E2%21&PAGEN_1=11
Хотите быть в курсе всех важных тем в мире недвижимости?
На нашем портале вы найдете много полезных статей на такие темы, как [url=https://cmy33.ru/]наследственное оформление недвижимости[/url] а также [url=https://cmy33.ru/]регистрация доли в Росреестре[/url].
EGGC
Tang Yin의 입가가 약간 말리고 눈에 약간의 빛이 번쩍였습니다.
Nomad casino telegram
казино [url=skladchik.org]казино[/url] .
Только качественные товары для военных|Ваш надежный партнер в выборе военных товаров|Купите военную амуницию у нас|Спецодежда и обувь для армии|Оружие и аксессуары для профессионалов|Только проверенные боевые товары|Выбирайте только лучшее для себя|Армейский магазин с широким ассортиментом|Выбирайте только профессиональное снаряжение|Все для армии и спецслужб|Качественная экипировка для армии|Оружие и снаряжение для истинных воинов|Выбирайте только профессиональное снаряжение|Купите только проверенные военные товары|Специализированный магазин для военных операций|Экипировка для защитников Отечества|Выбирайте проверенные военные товары|Специализированный магазин для военных сотрудников|Выбор настоящих защитников|Выбирайте только надежные военные товары
військовий інтернет магазин https://magazinvoentorg.kiev.ua/ .
Какое значение имеет pin up в искусстве, для вдохновения
pin up slots pin up slots .
south park смотреть https://southpark-serial.ru
купить квартиру от застройщика недорого купить квартиру от застройщика
Первый партнер охраны труда
Охрана труда – экспертный центр по аудиту и подготовке специалистов в области охраны труда и пожарной безопасности. Наша компания предоставляет широкий спектр услуг по обеспечению безопасности производственных процессов для индивидуальных предпринимателей и организаций различных секторов промышленности в Москве, Московской области и других регионах России.
Соблюдение правил безопасности труда – законодательное требование, за нарушение которого на организацию может быть наложен штраф или приостановлена деятельность предприятия на срок до 90 суток.
Мы помогаем решать вопросы обеспечения безопасности и организации труда на предприятии, разрабатываем и актуализируем документы по охране труда, проводим комплексное обследование охраны труда на соответствие государственным нормативным требованиям. Проводим обучение сотрудников по охране труда и пожарной безопасности, проверяем СУОТ и оцениваем профессиональные риски.
Hello there, You’ve done an incredible job. I’ll definitely digg it and personally suggest to my friends. I’m sure they will be benefited from this website.
viglojdrc.org/fr/news/les-jeunes-transformes-pour-transformer-et-membres-du-cjadh
forexgroupx.ru/page/4
little-witch.ru/topic6480.html?view=next
bezone.ru/node/335757
greytoken.net/grey-tokenomics/
Любому человеку рано или поздно приходится пользоваться услугами стоматологических клиник. Ни для кого не секрет, что лечение зубов и последующее протезирование – процедуры довольно дорогостоящие, не все граждане могут позволить себе их оплатить, если вам необходимо лечение осложнения кариеса мы Вам обязательно поможем.
Особенности
Благодаря услугам, которые предлагает населению стоматология Маэстро, люди разного финансового достатка имеют возможность не только поддерживать здоровье полости рта, но и проходить все необходимые процедуры. Цены на лечение зубов и протезирование значительно ниже, чем в других медучреждениях. Несмотря на то, что клиника работает для широких слоев населения, пациенты получают полный перечень услуг, используя современное оборудование и качественные материалы. Жителям доступны следующие процедуры:
• профилактика полости рта;
• лечение зубов с использованием различных методов;
• полная диагностика;
• профессиональная чистка;
• отбеливание;
• протезирование.
Сотрудники учреждения соблюдают все санитарные нормы, а для тщательной дезинфекции и стерилизации инструментов предусмотрено современное оборудование.
Преимущества
Востребованность бюджетной стоматологии объясняется рядом преимуществ. Во-первых, в клинике трудятся опытные высококвалифицированные сотрудники. Во-вторых, к каждому пациенту врач находит подход. В-третьих, кабинеты оснащены всем необходимым оборудованием, в работе используют только качественные безопасные материалы. В-четвертых, все виды протезирования будут проведены в сжатые сроки. Многие клиники получают субсидии от государства, что позволяет существенно сократить расходы. Кроме того, некоторые стоматологии сотрудничают со страховыми компаниями, поэтому у пациентов появляется возможность получить услуги по полюсу ОМС. Пациенты получают консультацию по профилактике заболеваний полости рта. Врачи после тщательного осмотра составляют индивидуальный план лечения, с помощью которого удается добиться наилучшего результата. Более доступные цены достигаются не только благодаря государственному финансированию, но и оптимизации расходов.
Благодаря стоматологии Маэстро, человек с небольшим достатком может не только вылечить зубы, но и поддерживать здоровье ротовой полости. Теперь любой человек может не откладывать поход к стоматологу, выбирая доступное качественное обслуживание.
lucky jet официальный сайт [url=http://1win-luckyjet-game.ru/]http://1win-luckyjet-game.ru/[/url] .
Студия реализует профессиональные решения по технической поддержке веб-ресурса на podderzhka-dlya-saita.ru по приятным ценам. Наполним веб-сервис профессиональным содержимым. Решим вопросы по исправлению ошибок и редизайну. Сотрудники осуществят профессиональные услуги по созданию веб-ресурсов. Предлагаем обратить внимание недорогие расценки с абонентской платой. Коммерческие предложения предлагаются по основным факторам: времени работ, объема и других.
Карьерный коуч https://vminske.by/fashion/kto-takie-karernye-konsultanty — эксперт рынка труда, который помогает людям определить свои карьерные цели, развиваться в выбранной области и достигать успеха в профессиональной деятельности.
seo заказать https://prodvizhenie-saytov43.ru
aviator game online real money [url=https://aviator-games-online.ru/]https://aviator-games-online.ru/[/url] .
[url=http://www.peregonavtofgtd.kiev.ua]www.peregonavtofgtd.kiev.ua[/url]
Я мухой, сверхэффективно равно надежно перебросить Ваш автомобиль из Украины в течение Европу, чи с Европы в течение Украину хором один-два нашей командой. Оформление документов равно экспортирование производятся в оклеветанные сроки.
http://peregonavtofgtd.kiev.ua
заказать сео продвижение сайта раскрутка seo
At this time it looks like Expression Engine is the top blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
edmontonoilersclub.com/read-blog/287_where-can-i-buy-a-diploma-or-certificate-at-a-comfortable-price.html?mode=day
russiajoy.ru/page/12
originalparts.ru/linkexchange/page68/?le_categoryID=0
sohapay.com/info/vi/news/trai-nghiem-tien-ich-voi-the-gioi-the-vpbank.html
self-test.ufoproger.ru/test/default/view/10?page-comments=10&per-page-comments=10
Только качественные товары для военных|Боевая техника от лучших производителей|Купите военную амуницию у нас|Армейские товары по выгодным ценам|Выбор настоящих военных победителей|Профессиональное снаряжение для военных|Боевая техника для суровых реалий|Только качественные товары для военных задач|Специализированный магазин для настоящих военных|Проверенные товары для военных операций|Снаряжение для профессионалов военного дела|Боевая техника для самых сложных задач|Выбирайте только профессиональное снаряжение|Специализированный магазин для профессионалов|Специализированный магазин для военных операций|Экипировка для защитников Отечества|Выбирайте проверенные военные товары|Специализированный магазин для военных сотрудников|Спецодежда для военнослужащих|Боевое снаряжение для самых требовательных задач
інтернет магазин військової форми https://magazinvoentorg.kiev.ua/ .
https://Dr-nona.ru – Dr. Nona
диплом люкс диплом люкс .
https://irhsca.org/
Pin Up Kazino ?Onlayn: pin-up360 – Pin Up Azerbaycan ?Onlayn Kazino
https://muslim-forum.org/
Hmm is anyone else experiencing problems with the images on this blog loading? I’m trying to determine if its a problem on my end or if it’s the blog. Any feed-back would be greatly appreciated.
avtoweek2016.ru/page/4/
ripet.hu/index.php
http://www.arclightcreative.dev/
carrefour-emploi-public.fr/brest-metropole-oceane
sjtudivingcenter.com/message/index.php?class1=52&page=10&lang=en
https://autolux-azerbaijan.com/# Pin up 306 casino
Pin Up Azerbaycan ?Onlayn Kazino: Pin Up Kazino ?Onlayn – Pin Up Azerbaycan
https://autolux-azerbaijan.com/# Pin up 306 casino
открывшиеся сервера л2
Сервера л2
Pin Up Azerbaycan: pin-up 141 casino – Pin Up Kazino ?Onlayn
https://autolux-azerbaijan.com/# pin-up360
Vinicius Junior https://viniciusjunior.prostoprosport-ar.com is a Brazilian and Spanish footballer who plays as a striker for Real Madrid and the Brazilian national team. Junior became the first player in the history of Los Blancos, born in 2000, to play an official match and score a goal.
Kylian Mbappe https://kylianmbappe.prostoprosport-ar.com is a French footballer, striker for Paris Saint-Germain and captain of the French national team. He began playing football in the semi-professional club Bondi, which plays in the lower leagues of France. He was noticed by Monaco scouts, which he joined in 2015 and that same year, at the age of 16, he made his debut for the Monegasques. The youngest debutant and goal scorer in the club’s history.
Karim Benzema https://karimbenzema.prostoprosport-ar.com is a French footballer who plays as a striker for the Saudi Arabian club Al-Ittihad. He played for the French national team, for which he played 97 matches and scored 37 goals. At the age of 17, he became one of the best reserve players, scoring three dozen goals per season.
https://autolux-azerbaijan.com/# Pin-up Giris
продвижение сайтов частником в москве [url=http://prodvizhenie-sajtov-v-moskve117.ru/]продвижение сайтов частником в москве[/url] .
pin up az?rbaycan: pin-up kazino – pin-up oyunu
atrakcje łeba
Портал о здоровье https://www.rezus.ru и здоровом образе жизни, рекомендации врачей и полезные сервисы. Простые рекомендации для укрепления здоровья и повышения качества жизни.
Toni Kroos https://tonikroos.prostoprosport-ar.com is a German footballer who plays as a central midfielder for Real Madrid and the German national team. World champion 2014. The first German player in history to win the UEFA Champions League six times.
сервис миле в москве мастер миле
에그벳 도메인
장황후와 홍치제는 서로를 바라보며 쓴웃음을 지으며 고개를 저었다.
娛樂城
台灣線上娛樂城是指通過互聯網提供賭博和娛樂服務的平台。這些平台主要針對台灣用戶,但實際上可能在境外運營。以下是一些關於台灣線上娛樂城的重要信息:
1. 服務內容:
– 線上賭場遊戲(如老虎機、撲克、輪盤等)
– 體育博彩
– 彩票遊戲
– 真人荷官遊戲
2. 特點:
– 全天候24小時提供服務
– 可通過電腦或移動設備訪問
– 常提供優惠活動和獎金來吸引玩家
3. 支付方式:
– 常見支付方式包括銀行轉賬、電子錢包等
– 部分平台可能接受加密貨幣
4. 法律狀況:
– 在台灣,線上賭博通常是非法的
– 許多線上娛樂城實際上是在國外註冊運營
5. 風險:
– 由於缺乏有效監管,玩家可能面臨財務風險
– 存在詐騙和不公平遊戲的可能性
– 可能導致賭博成癮問題
6. 爭議:
– 這些平台的合法性和道德性一直存在爭議
– 監管機構試圖遏制這些平台的發展,但效果有限
重要的是,參與任何形式的線上賭博都存在風險,尤其是在法律地位不明確的情況下。建議公眾謹慎對待,並了解相關法律和潛在風險。
如果您想了解更多具體方面,例如如何識別和避免相關風險,我可以提供更多信息。
Всем привет! Подскажите, где почитатьразные блоги о недвижимости? Сейчас читаю https://aquatopnn.ru
buy tiktok followers and likes buy tiktok likes
Всем привет! Подскажите, где почитатьразные статьи о недвижимости? Пока нашел https://artem-dvery.ru
Lionel Andres Messi Cuccittini https://lionelmessi.prostoprosport-ar.com is an Argentine footballer, forward and captain of the MLS club Inter Miami, captain of the Argentina national team. World champion, South American champion, Finalissima winner, Olympic champion. Considered one of the best football players of all time.
Приветствую. Подскажите, где почитатьразные блоги о недвижимости? Сейчас читаю https://asiatreid.ru
купить диплом в твери vm-tver.ru .
https://politicsoc.com/
Приветствую. Может кто знает, где найтиразные статьи о недвижимости? Сейчас читаю https://dilerskiy-tsentr-baumit.ru
Anderson Sousa Conceicao better known as Talisca https://talisca.prostoprosport-ar.com is a Brazilian footballer who plays as a midfielder for the An-Nasr club. A graduate of the youth team from Bahia, where he arrived in 2009 ten years ago.
Интересуетесь недвижимостью? Наш ресурс – ваш надежный проводник в этой сфере. У нас вы найдете множество полезных статей на такие темы, как [url=https://abraziv-pferd.ru]квартиры без отделки[/url], а также [url=https://abraziv-pferd.ru]агентства недвижимости[/url].
Подробные аналитические материалы, экспертные мнения и простые рекомендации — все это доступно у нас!
Yassine Bounou https://yassine-bounou.prostoprosport-ar.com also known as Bono, is a Moroccan footballer who plays as a goalkeeper for the Saudi Arabian club Al-Hilal and the Moroccan national team. On November 10, 2022, he was included in the official application of the Moroccan national team to participate in the matches of the 2022 World Cup in Qatar
best online pharmacies in mexico: mexican pharmacy online – mexico drug stores pharmacies
https://besuchszweck.org/
Harry Edward Kane https://harry-kane.prostoprosport-ar.com is an English footballer, forward for the German club Bayern and captain of the England national team. Considered one of the best football players in the world. He is Tottenham Hotspur’s and England’s all-time leading goalscorer, as well as the second most goalscorer in the Premier League. Member of the Order of the British Empire.
Всем привет! Подскажите, где найтиразные блоги о недвижимости? Сейчас читаю https://dompodkluch33.ru
https://interventionist.us/
грузчики минск срочно [url=https://www.gruzchikiminsk.ru]https://www.gruzchikiminsk.ru[/url] .
Erling Breut Haaland https://erling-haaland.prostoprosport-ar.com is a Norwegian footballer who plays as a forward for the English club Manchester City and the Norwegian national team. English Premier League record holder for goals per season.
mexico drug stores pharmacies mexican pharmacy northern doctors medication from mexico pharmacy
https://northern-doctors.org/# mexican rx online
У нас вы найдете информационные статьи на тему недвижимости, например, отделка квартиры с нуля, продажа и покупка недвижимости, юридическое сопровождение сделки.
Узнайте все нюансы, которые помогут вам принять верное решение и осуществить успешную сделку с недвижимостью. Наши статьи помогут вам быть в курсе последних трендов и законов жилищного рынка, а также избежать ошибок.
http://domzenit.ru
문 프린세스
“…” Ouyang Zhi와 세 사람의 얼굴에 나타난 감사는 순식간에 비통함과 증오로 변했습니다.
Luka Modric https://lukamodric.prostoprosport-ar.com is a Croatian footballer, central midfielder and captain of the Spanish club Real Madrid, captain of the Croatian national team. Recognized as one of the best midfielders of our time. Knight of the Order of Prince Branimir. Record holder of the Croatian national team for the number of matches played.
mexican pharmacy: northern doctors pharmacy – mexican drugstore online
https://northern-doctors.org/# buying prescription drugs in mexico online
https://vyzov-santehnika-na-dom.ru.
medication from mexico pharmacy: mexican pharmacy northern doctors – mexico drug stores pharmacies
Читайте полезные статьи на важные темы, связанные с покупкой жилья, например покупка квартиры в новостройке или стоимость недвижимости в Москве.
Сайт: https://ooo-trotuar.ru
buying prescription drugs in mexico mexican pharmacy northern doctors mexico drug stores pharmacies
buy tiktok followers cheap buy followers tiktok
buy 100 tiktok followers buy tiktok followers tokmatic
mexican border pharmacies shipping to usa: Mexico pharmacy that ship to usa – buying from online mexican pharmacy
https://northern-doctors.org/# best online pharmacies in mexico
Желаете стать профи в сфере недвижимости? Наш сайт – это ваш незаменимый помощник! Мы предлагаем огромное количество интересных статей на такие темы, как [url=https://opk-ekb.ru]отделка квартиры[/url], а также [url=https://opk-ekb.ru]покупка жилья[/url]. Наши эксперты поделятся с вами полезными советами, чтобы помочь вам принимать взвешенные решения в сфере недвижимости!
https://dr-Nona.ru/ – Dr. nonna
medication from mexico pharmacy: Mexico pharmacy that ship to usa – buying prescription drugs in mexico
https://northern-doctors.org/# buying prescription drugs in mexico online
mexican rx online: mexican pharmacy online – buying from online mexican pharmacy
Приветствую. Может кто знает, где найтиразные статьи о недвижимости? Пока нашел https://floor-ashton.ru
pharmacies in mexico that ship to usa: mexican pharmacy northern doctors – purple pharmacy mexico price list
https://northern-doctors.org/# buying from online mexican pharmacy
Как получить лицензию на недвижимость|Все, что вам нужно знать о лицензии на недвижимость|Станьте лицензированным агентом по недвижимости|Успешные стратегии получения лицензии на недвижимость|Разберитесь в процессе получения лицензии на недвижимость|Следуйте этим шагам для получения лицензии на недвижимость|Простой путь к получению лицензии на недвижимость|Как стать агентом с лицензией на недвижимость|Эффективные стратегии получения лицензии на недвижимость|Успешное получение лицензии на недвижимость: шаг за шагом|Основные моменты получения лицензии на недвижимость|Секреты скорого получения лицензии на недвижимость|Основные шаги к успешной лицензии на недвижимость|Топ советы по получению лицензии на недвижимость|Советы по получению лицензии на недвижимость от профессионалов|Как получить лицензию на недвижимость без стресса|Получение лицензии на недвижимость: лучшие практики и советы|Инструкция по получению лицензии на недвижимость|Лицензия на недвижимость: ключ к успеху в индустрии недвижимости|Секреты успешного получения лицензии на недвижимость: что вам нужно знать|Как стать агентом по недвижимости с лицензией|Основные шаги к профессиональной лицензии на недвижимость|Инструкция по получению лицензии на недвижимость|Простой путь к получению лицензии на недвижимость|Три шага к профессиональной лицензии на недвижимость|Лицензия на недвижимость: важные аспекты для успешного получения
How to get a real estate license in Michigan How to get a real estate license in Michigan .
средства для интимной гигиены против запаха каталог IntiLINE
https://lebelligerant.com/
https://polskikompas.com/
The best film magazin https://orbismagazine.com, film industry trade publications in 2024 to keep you informed with the latest video production, filmmaking, photographynews. We create beautiful and magnetic projects.
https://northern-doctors.org/# medicine in mexico pharmacies
Всем привет! Подскажите, где найтиполезные блоги о недвижимости? Пока нашел https://gismt72.ru
На нашем сайте вы найдете всю необходимую информацию о недвижимости – от бронирования жилья в новостройке до приобретения недвижимости от застройщика.
Мы поможем вам выбрать идеальную квартиру в новостройке, расскажем, как не попасть в ловушку при выборе жилья и подскажем, как сэкономить время и деньги.
Ждём в гости: https://quartz-rsk.ru
mexican border pharmacies shipping to usa: mexican pharmacy – mexico drug stores pharmacies
Взять займ или кредит
https://1landscapedesign.ru/poslednie-stati/kak-poluchit-zajm-na-kartu-ili-bankovskij-schet.html под проценты, подав заявку на денежный микрозайм для физических лиц. Выбирайте среди 570 лучших предложений займа онлайн. Возьмите микрозайм онлайн или наличными в день обращения. Быстрый поиск и удобное сравнение условий по займам и микрокредитам в МФО.
заказать перевозку мебели [url=www.pereezdminsk.ru]www.pereezdminsk.ru[/url] .
https://northern-doctors.org/# purple pharmacy mexico price list
purple pharmacy mexico price list: northern doctors – best online pharmacies in mexico
http://northern-doctors.org/# mexican border pharmacies shipping to usa
montenegro immobilien kaufen immobilien montenegro
Всем привет! Может кто знает, где найтиразные статьи о недвижимости? Сейчас читаю https://kaluga-elite.ru
tuan88 login
Хотите быть в курсе всех актуальных тем в сфере недвижимости?
На нашем сайте вы найдете множество полезных статей о [url=https://starextorg.ru]покупке и продаже жилья[/url], а также о [url=https://starextorg.ru]анализе рынка недвижимости[/url].
Узнайте все, что вам нужно для успешных сделок и принятия важных решений в сфере недвижимости.
https://Dr-nona.ru – доктор Нона
Kobe Bean Bryant https://kobebryant.prostoprosport-ar.com is an American basketball player who played in the National Basketball Association for twenty seasons for one team, the Los Angeles Lakers. He played as an attacking defender. He was selected in the first round, 13th overall, by the Charlotte Hornets in the 1996 NBA Draft. He won Olympic gold twice as a member of the US national team.
레프리칸 리치스
Zhu Houzhao의 가슴이 들썩였고 그는 너무 흥분해서 감정을 억제할 수 없었습니다.
medicine in mexico pharmacies medicine in mexico pharmacies buying prescription drugs in mexico online
bocor88
https://northern-doctors.org/# mexico pharmacies prescription drugs
medication from mexico pharmacy: mexican pharmacy northern doctors – pharmacies in mexico that ship to usa
Всем привет! Подскажите, где почитатьразные статьи о недвижимости? Сейчас читаю https://kamenolomnya43.ru
mexican pharmacy: northern doctors – buying from online mexican pharmacy
Купити ліхтарики https://bailong-police.com.ua оптом та в роздріб, каталог та прайс-лист, характеристики, відгуки, акції та знижки. Купити ліхтарик онлайн з доставкою. Відмінний вибір ліхтарів: налобні, ручні, тактичні, ультрафіолетові, кемпінгові, карманні за вигідними цінами.
https://Dr-nona.ru/ – Dr. nonna
mexico pharmacy: mexico pharmacy – п»їbest mexican online pharmacies
Продажа подземных канализационных ёмкостей https://neseptik.com по выгодным ценам. Ёмкости для канализации подземные объёмом до 200 м3. Металлические накопительные емкости для канализации заказать и купить в Екатеринбурге.
https://northern-doctors.org/# medication from mexico pharmacy
оборудование для сцены актового зала [url=https://oborudovanie-aktovogo-zala13.ru/]https://oborudovanie-aktovogo-zala13.ru/[/url] .
reputable mexican pharmacies online mexican pharmacy online medication from mexico pharmacy
pharmacies in mexico that ship to usa: Mexico pharmacy that ship to usa – mexican border pharmacies shipping to usa
Секс-работа в российской столице является проблемой как комплексной и сложноустроенной вопросом. Невзирая на это противозаконна законом, это занятие является значительным нелегальной областью.
Контекст в прошлом
В советские времена проституция была нелегально. С распадом Советской империи, в период финансовой нестабильной ситуации, секс-работа появилась более видимой.
Нынешняя обстановка
Сегодня интимные услуги в городе Москве имеет различные формы, начиная с престижных эскорт-сервисов и заканчивая уличного уровня секс-работы. Престижные предложения обычно организуются через сеть, а уличная секс-работа располагается в выделенных участках столицы.
Общественно-экономические аспекты
Многие представительницы слабого пола принимают участие в эту сферу по причине финансовых неурядиц. Интимные услуги может оказаться заманчивой из-за перспективы быстрого заработка, но эта деятельность подразумевает угрозу здоровью и безопасности.
Законодательные вопросы
Проституция в стране нелегальна, и за её организацию установлены серьезные санкции. Коммерческих секс-работников зачастую задерживают к административной и правовой ответственности.
Таким образом, не обращая внимания на запреты, секс-работа существует как частью нелегальной экономики столицы с большими социально-правовыми последствиями.
Maria Sharapova https://maria-sharapova.prostoprosport-ar.com Russian tennis player. The former first racket of the world, winner of five Grand Slam singles tournaments from 2004 to 2014, one of ten women in history who has the so-called “career slam”.
Luis Fernando Diaz Marulanda https://luis-diaz.prostoprosport-ar.com Colombian footballer, winger for Liverpool and the Colombian national team . Diaz is a graduate of the Barranquilla club. On April 26, 2016, in a match against Deportivo Pereira, he made his Primera B debut. On January 30, 2022, he signed a contract with the English Liverpool for five years, the transfer amount was 40 million euros.
https://northern-doctors.org/# mexican pharmaceuticals online
https://northern-doctors.org/# reputable mexican pharmacies online
Kevin De Bruyne https://kevin-de-bruyne.prostoprosport-ar.com Belgian footballer, midfielder of the Manchester club City” and the Belgian national team. A graduate of the football clubs “Ghent” and “Genk”. In 2008 he began his adult career, making his debut with Genk.
Mohammed Khalil Ibrahim Al-Owais https://mohammed-alowais.prostoprosport-ar.com is a Saudi professional footballer who plays as a goalkeeper for the national team Saudi Arabia and Al-Hilal. He is known for his quick reflexes and alertness at the gate.
mexican online pharmacies prescription drugs northern doctors mexican mail order pharmacies
http://northern-doctors.org/# buying prescription drugs in mexico
Quincy Anton Promes https://quincy-promes.prostoprosport-br.com Dutch footballer, attacking midfielder and forward for Spartak Moscow . He played for the Dutch national team. He won his first major award in 2017, when Spartak became the champion of Russia.
Экспертиза ремонта в квартире https://remnovostroi.ru проводится для оценки качества выполненных работ, соответствия требованиям безопасности и стандартам строительства. Специалисты проверяют используемые материалы, исполнение работ, конструктивные особенности, безопасность, внешний вид и эстетику ремонта. По результатам экспертизы составляется экспертное заключение с оценкой качества и рекомендациями по устранению недостатков.
Всем привет! Может кто знает, где почитатьразные статьи о недвижимости? Пока нашел https://kuler-tsentr.ru
http://northern-doctors.org/# best online pharmacies in mexico
ремонт айфон [url=https://iphonepochinka.by/]ремонт айфон[/url] .
mexico drug stores pharmacies medicine in mexico pharmacies mexico pharmacies prescription drugs
Приветствую. Может кто знает, где найтиполезные статьи о недвижимости? Пока нашел https://liem-com.ru
buying prescription drugs in mexico
http://cmqpharma.com/# mexican online pharmacies prescription drugs
reputable mexican pharmacies online
Roberto Firmino Barbosa de Oliveira https://roberto-firmino.prostoprosport-br.com Brazilian footballer, attacking midfielder, forward for the Saudi club “Al-Ahli”. Firmino is a graduate of the Brazilian club KRB, from where he moved to Figueirense in 2007. In June 2015 he moved to Liverpool for 41 million euros.
mexico drug stores pharmacies mexican online pharmacy mexican pharmacy
Приветствую. Может кто знает, где найтиразные статьи о недвижимости? Сейчас читаю https://oscltd.ru
reputable mexican pharmacies online mexican pharmacy online mexican mail order pharmacies
medicine in mexico pharmacies cmq pharma mexico drug stores pharmacies
Kyle Andrew Walker https://kylewalker.prostoprosport-br.com English footballer, captain of the Manchester City club and the England national team. In the 2013/14 season, he was on loan at the Notts County club, playing in League One (3rd division of England). Played 37 games and scored 5 goals in the championship.
mexican pharmaceuticals online: mexico drug stores pharmacies – reputable mexican pharmacies online
medicine in mexico pharmacies online mexican pharmacy mexican drugstore online
Laure Boulleau https://laure-boulleau.prostoprosport-fr.com French football player, defender. She started playing football in the Riom team, in 2000 she moved to Isere, and in 2002 to Issigneux. All these teams represented the Auvergne region. In 2003, Bullo joined the Clairefontaine academy and played for the academy team for the first time.
Son Heung Min https://sonheung-min.prostoprosport-br.com South Korean footballer, striker and captain of the English Premier League club Tottenham Hotspur and the Republic of Korea national team. In 2022 he won the Premier League Golden Boot. Became the first Asian footballer in history to score 100 goals in the Premier League
Приветствую. Подскажите, где почитатьполезные блоги о недвижимости? Сейчас читаю https://redglade-nn.ru
mexican drugstore online mexican pharmacy online mexican drugstore online
“Дело “Лайф-из-Гуд” — “Гермес” — “Бест Вей”: свидетель обвинения объявила себя потерпевшей от следствия
Свидетель Набойченко
6 и 13 июня Приморский районный суд города Санкт-Петербурга, рассматривающий по существу уголовное дело № 1-504/24, связываемое с компаниями “Лайф-из-Гуд”, “Гермес” и кооперативом “Бест Вей”, провел очередные, шестое и седьмое по счету, заседания, посвященные допросу свидетелей обвинения и лиц, признанных следствием потерпевшими в рамках судебного следствия по делу
“К кооперативу претензий не было, следователь предложил подать заявление”
Признанный следствием потерпевший Болян подсудимых не знает. Был клиентом “Гермеса”, а также пайщиком кооператива — но до 2019 года. В 2019-м он вышел из кооператива и из “Гермеса”, ему были возвращены паевые взносы, и никаких претензий к кооперативу у него не было — что он письменно подтвердил, расторгая договоры с этими организациями.
Однако, как Болян отметил на суде, следователь убедил его в том, что он — потерпевший и должен подать заявление на возврат членских взносов. Заявление в МВД писать не хотел, на него вышли сотрудники, сначала претензий к кооперативу не было. Полиция ему объяснила, что можно получить деньги.
Стал клиентом “Гермеса” и пайщиком кооператива через своего консультанта Алексея Виноградова. Виноградов — грамотный маркетолог, он ему верил, тот не работал в кооперативе. Что было предметом договора в “Гермесе”, не помнит. В “Гермес” внес 100 и 700 евро, а в кооператив каждый месяц вносил по 12 тыс. в течение семи месяцев.
Вышел и из кооператива, и из “Гермеса” в 2019 году. Зачем вступал? “Наверное, квартиру купить хотел”. Кооператив вернул ему 70 тыс. паевых взносов, “Гермес” вернул со счета “Виста” 140 тыс. рублей.
В кооперативе деньги вернули почти сразу, удержав вступительный и членские взносы; в “Гермесе” вернули позже через “внутрянку”, но удержали комиссию.
Утверждает, что ему говорили, что можно со счета “Виста” вносить деньги в кооператив. Объясняли, что деньги передаются в доверительное управление трейдерам и брокерам, которые играют на бирже. В кооперативе, как он утверждает, можно было купить место в очереди. По его словам, “Гермес” и кооператив — по сути, одна организация. Требует взыскать с кооператива более 148 тыс. рублей — вступительный и членские взносы, и более 60 тыс. рублей с “Гермеса” — комиссию при выводе средств.
Договор с кооперативом не читал, но ему объяснили, что есть невозвратная часть денег — ее и не вернули, “но хочу попытаться вернуть”. Претензий к кооперативу “как бы и нет, но если вернут взносы, то будет хорошо”.
К Виноградову претензий не предъявлял. “Может, меня и не обманули в кооперативе”, -резюмировал свое выступление в суде Болян.
“Требую выплатить с учетом роста цен на недвижимость”
Признанная следствием потерпевшей Комова была как клиентом “Гермеса”, так и пайщиком кооператива. Подсудимых не знает. Требует более 8800 тыс. с кооператива и более 2700 тыс. с “Гермеса”. При этом из кооператива она не вышла и заявление о выходе не подавала. Сумма требований к кооперативу включает как паевые и членские взносы, так и оценку роста цен на недвижимость, которая не была приобретена.
Утверждает, что можно переводить деньги со счета “Виста” напрямую в кооператив — в подтверждение приводит скрины переписки с консультантами в смартфоне. Суд разъясняет, что доказательство может быть приобщено позднее при надлежащем оформлении.
“Информацию воспринял скептически, но вступил”
Признанный следствием потерпевшим Киреев был только клиентом “Гермеса”. Подсудимых не знает лично — Измайлова видел в видеоролике “Лайф-из-Гуд”. Узнал о “Гермесе” от консультантов Татьяны и Андрея Клейменовых, с которыми знаком с конца 1990-х годов. Вступил в “Гермес” в 2020 году, деньги сразу отобразились на счете. Вносил средства на счет “Виста” небольшими частями, снимал средства со счета для личных нужд. Заявляет требования на более чем 2 млн 300 тыс. рублей.
Когда подписывал договор, в офисе была табличка кооператива, но в офисе находился представитель фирмы “Гермес”, ему сказали, что это два продукта компании “Лайф-из-Гуд”.
В 2022 году начались проблемы с выводом средств. И руководство фирмы пугало блокировкой счета в случае подачи заявления в правоохранительные органы. В хейтерском чате узнал телефон следователя Сапетовой, позвонил и подал заявление.
В чате клиентов компании “Гермес” была информация о том, что счет будет заблокирован в случае подачи заявления в правоохранительные органы. Эта информация была за подписью “администрация”. Он спросил у консультантов: “Кто это — администрация?”, написал вопрос в чате, и его забанили. Других попыток вступать в диалог с “Гермесом” не предпринимал.
Признанный следствием потерпевшим Чернышенко был также только клиентом только компании “Гермес”. Подсудимых не знает. Познакомился с консультантами “Гермеса” во время совместной работы в “Макдоналдсе”. Информацию о “Гермесе” воспринял скептически — “это какой-то обман”, но консультанты его в конце концов уговорили. Они поставили условие, что продадут ему земельный участок, чтобы он вступил в “Гермес”.
“Я хотел их обмануть, — пояснил свидетель, — думал: пусть они продадут, а я в “Гермес” не вступлю. Но они начали уговаривать, и я вступил в апреле 2020 года. Один из консультантов дал расписку на внесение денег на счет в “Гермесе”, я внес через него 230 тыс. И еще раз из жадности 140 тыс. 140 тыс. я вывел, плюс каждый месяц выводил по 5000–7000 руб. С какого-то момента проценты стали падать. В конце я захотел выйти — но не успел. У меня в “Гермесе” осталось 270 тыс., которые я требую вернуть”.
В январе 2023 года Чернышенко подал заявление в полицию, так как прекратился доступ к счету. “Мне предложили 70 тыс. вернуть, чтобы я не ходил в полицию, ссылаясь на то, что помогли мне продать участок за меньшую сумму по документам, чем я его продал на самом деле, но я отказался, сказал, что мне надо 270 тыс.”.
“Я хочу стать потерпевшей. Но Василенко многие благодарны за квартиры”
Свидетель обвинения Галашенкова была только клиентом “Гермеса”. Из подсудимых знает Виктора Ивановича Василенко. Она сидела в зале при допросе двух потерпевших (что запрещено), но заявила, что плохо слышит. Ранее была знакома с Верой Исаевой из компании “Лайф-из-Гуд”.
Вера узнала, что у нее есть офис, и познакомила с Романом Василенко, который снял у нее офис, когда “Лайф-из-Гуд” только начинала раскручиваться. Он снимал офис только за коммунальные платежи. “Я попросила расплатиться за четыре месяца, а он предложил мне вместо денег вступить в “Бест Вей”, но я отказалась, так как квартира не была нужна”. Зато стала клиентом “Гермеса”: “Внесла 15 тыс. евро, но через три месяца на счете оказалось 3400 евро!” Исаева, по словам Галашенковой, оказалась мошенницей.
По словам Галашенковой, она внесла на счет “Виста” более 3 млн рублей. “Когда сказали, что все счета заблокировали, то собрали с нас еще денег, чтобы счета разблокировать, потом пришло сообщение, что открывается новая фирма, но это все оказалось обманом — счета не разблокированы”.
“Я не считала себя потерпевшей, так как не знала, что это можно сделать, — заявила Галашенкова. — Сейчас желаю заявить, что я хочу стать потерпевшей. Считаю, что должна взыскать с “Гермеса” как прямой ущерб, так и упущенную выгоду, так как эта фирма закрылась”.
При этом заявила, что “Василенко молодец, потому что я видела людей, которые купили квартиры, они были ему очень благодарны”.
medicine in mexico pharmacies cmq mexican pharmacy online mexican drugstore online
Всем привет! Может кто знает, где почитатьразные статьи о недвижимости? Сейчас читаю https://santam1.ru
Antoine Griezmann https://antoine-griezmann.prostoprosport-fr.com French footballer, striker and midfielder for Atletico Madrid. Player and vice-captain of the French national team, as part of the national team – world champion 2018. Silver medalist at the 2016 European Championship and 2022 World Championship.
In January 2010, Harry Kane https://harry-kane.prostoprosport-fr.com received an invitation to the England U-team for the first time 17 for the youth tournament in Portugal. At the same time, the striker, due to severe illness, did not go to the triumphant 2010 European Championship for boys under 17 for the British.
medicine in mexico pharmacies mexican rx online mexican online pharmacies prescription drugs
cheap depakote 500mg – aggrenox buy online topamax order online
Всем привет! Может кто знает, где найтиразные блоги о недвижимости? Сейчас читаю https://sibarit54.ru
Achraf Hakimi Mou https://achraf-hakimi.prostoprosport-fr.com Moroccan footballer, defender of the French club Paris Saint-Germain “and the Moroccan national team. He played for Real Madrid, Borussia Dortmund and Inter Milan.
Sweet Bonanza https://sweet-bonanza.prostoprosport-fr.com is an exciting slot from Pragmatic Play that has quickly gained popularity among players thanks to its unique gameplay, colorful graphics and the opportunity to win big prizes. In this article, we’ll take a closer look at all aspects of this game, from mechanics and bonus features to strategies for successful play and answers to frequently asked questions.
Kylian Mbappe Lotten https://kylian-mbappe.prostoprosport-fr.com Footballeur francais, attaquant du Paris Saint-Germain et capitaine de l’equipe de France. Le 1er juillet 2024, il deviendra joueur du club espagnol du Real Madrid.
Philip Walter Foden https://phil-foden.prostoprosport-fr.com better known as Phil Foden English footballer, midfielder of the Premier club -League Manchester City and the England national team. On December 19, 2023, he made his debut at the Club World Championship in a match against the Japanese club Urawa Red Diamonds, starting in the starting lineup and being replaced by Julian Alvarez in the 65th minute.
Jogo do Tigre https://jogo-do-tigre.prostoprosport-br.com is a simple and fun game that tests your reflexes and coordination. In this game you need to put your finger on the screen, pull out the stick and go through each peg. However, you must ensure that the stick is the right length, neither too long nor too short.
Приветствую. Подскажите, где найтиразные блоги о недвижимости? Сейчас читаю https://tent44.ru
Declan Rice https://declan-rice.prostoprosport-fr.com Footballeur anglais, milieu defensif du club d’Arsenal et de l’equipe nationale equipe d’Angleterre. Originaire de Kingston upon Thames, Declan Rice s’est entraine a l’academie de football de Chelsea des l’age de sept ans. En 2014, il devient joueur de l’academie de football de West Ham United.
Declan Rice https://declan-rice.prostoprosport-fr.com Footballeur anglais, milieu defensif du club d’Arsenal et de l’equipe nationale equipe d’Angleterre. Originaire de Kingston upon Thames, Declan Rice s’est entraine a l’academie de football de Chelsea des l’age de sept ans. En 2014, il devient joueur de l’academie de football de West Ham United.
Olivier Jonathan Giroud https://olivier-giroud.prostoprosport-fr.com French footballer, striker for Milan and the French national team. Knight of the Legion of Honor. Participant in four European Championships (2012, 2016, 2020 and 2024) and three World Championships (2014, 2018 and 2022).
Thibaut Nicolas Marc Courtois https://thhibaut-courtois.prostoprosport-fr.com Footballeur belge, gardien de but du club espagnol du Real Madrid . Lors de la saison 2010/11, il a ete reconnu comme le meilleur gardien de la Pro League belge, ainsi que comme joueur de l’annee pour Genk. Triple vainqueur du Trophee Ricardo Zamora
Приветствую. Подскажите, где почитатьразные статьи о недвижимости? Сейчас читаю https://universal37.ru
Ronaldo de Asis Moreira https://ronaldinhogaucho.prostoprosport-br.com Brazilian footballer, played as an attacking midfielder and striker. World Champion (2002). Winner of the Golden Ball (2005). The best football player in the world according to FIFA in 2004 and 2005.
Xavi or Xavi Quentin Sy Simons https://xavi-simons.prostoprosport-fr.com Dutch footballer, midfielder of the Paris Saint-Germain club -Germain” and the Dutch national team, playing on loan for the German club RB Leipzig.
продвижение сайтов цена в москве [url=https://prodvizhenie-sajtov-v-moskve115.ru/]https://prodvizhenie-sajtov-v-moskve115.ru/[/url] .
Jamal Musiala https://jamal-musiala.prostoprosport-fr.com footballeur allemand, milieu offensif du club allemand du Bayern et du equipe nationale d’Allemagne. Il a joue pour les equipes anglaises des moins de 15 ans, des moins de 16 ans et des moins de 17 ans. En octobre 2018, il a dispute deux matchs avec l’equipe nationale d’Allemagne U16. En novembre 2020, il a fait ses debuts avec l’equipe d’Angleterre U21.
Erling Breut Haaland https://erling-haaland.prostoprosport-br.com Futebolista noruegues, atacante do clube ingles Manchester City e Selecao da Noruega. Detentor do recorde da Premier League inglesa em gols por temporada.
Kylian Mbappe Lotten https://kylianmbappe.prostoprosport-br.com Futebolista frances, atacante do Paris Saint-Germain e capitao da selecao francesa equipe . Em 1? de julho de 2024, ele se tornara jogador do clube espanhol Real Madrid.
purchase norpace pill – thorazine order order chlorpromazine generic
Philippe Coutinho Correia https://philippecoutinho.prostoprosport-br.com Brazilian footballer, midfielder of the English club Aston Villa, playing on loan for the Qatari club Al-Duhail. He is known for his vision, passing, dribbling and long-range ability.
Mohamed Salah https://mohamedsalah.prostoprosport-br.com e um futebolista egipcio que joga como atacante do clube ingles Liverpool e do Selecao egipcia. Considerado um dos melhores jogadores de futebol do mundo. Tricampeao da Chuteira de Ouro da Premier League inglesa: em 2018 (sozinho), 2019 (junto com Sadio Mane e Pierre-Emerick Aubameyang) e 2022 (junto com Son Heung-min).
Karim Mostafa Benzema https://karim-benzema.prostoprosport-br.com Futebolista frances, atacante do clube saudita Al-Ittihad . Jogou pela selecao francesa, pela qual disputou 97 partidas e marcou 37 gols.
Kaka https://kaka.prostoprosport-br.com Futebolista brasileiro, meio-campista. O apelido “Kaka” e um diminutivo de Ricardo. Formado em Sao Paulo. De 2002 a 2016, integrou a Selecao Brasileira, pela qual disputou 92 partidas e marcou 29 gols. Campeao mundial 2002.
Zlatan Ibrahimovic https://zlatan-ibrahimovic.prostoprosport-br.com Bosnian pronunciation: ibraxi?mo?it?]; genus. 3 October 1981, Malmo, Sweden) is a Swedish footballer who played as a striker. Former captain of the Swedish national team.
Luis Alberto Suarez Diaz https://luis-suarez.prostoprosport-br.com Uruguayan footballer, striker for Inter Miami and Uruguay national team. The best scorer in the history of the Uruguay national team. Considered one of the world’s top strikers of the 2010s
슬롯 용가리
Zhu Houzhao는 눈에 확고한 빛을 비추며 야망을 세웠습니다.
Robert Lewandowski https://robert-lewandowski.prostoprosport-br.com e um futebolista polones, atacante do clube espanhol Barcelona e capitao da selecao polonesa. Considerado um dos melhores atacantes do mundo. Cavaleiro da Cruz do Comandante da Ordem do Renascimento da Polonia.
Virgil van Dijk https://virgilvandijk.prostoprosport-br.com Futebolista holandes, zagueiro central, capitao do clube ingles Liverpool e capitao do a selecao holandesa.
http://cmqpharma.com/# buying prescription drugs in mexico
mexican mail order pharmacies
Как выбрать лучшие тактичные штаны для активного отдыха, которые подчеркнут вашу индивидуальность.
Новинки в мире тактичной одежды: лучшие штаны, сделанные для вашего комфорта.
Чем отличаются тактичные штаны от обычных, и какие модели стоит обратить внимание.
Выберите удобные тактичные штаны для своего гардероба, и какие модели актуальны в этом сезоне.
Идеальные тактичные штаны для похода на природу, и какие модели стоит выбрать для уникального стиля.
тактичні штани з наколінниками зимові https://vijskovitaktichnishtanu.kiev.ua/ .
Приветствую. Может кто знает, где почитать разные статьи о недвижимости? Сейчас читаю https://an72.ru
Roberto Carlos da Silva Rocha https://roberto-carlos.prostoprosport-br.com Brazilian footballer, left back. He was also capable of playing as both a central defender and a defensive midfielder. World champion 2002, silver medalist at the 1998 World Championships.
Neymar da Silva Santos Junior https://neymar.prostoprosport-br.com e um futebolista brasileiro que atua como atacante, ponta e atacante. meio-campista do clube saudita Al-Hilal e da selecao brasileira. Considerado um dos melhores jogadores do mundo. O maior artilheiro da historia da Selecao Brasileira.
Thomas Mueller https://thomasmueller.prostoprosport-br.com is a German football player who plays for the German Bayern Munich. Can play in different positions – striker, attacking midfielder. The most titled German footballer in history
Всем привет! Подскажите, где найти полезные блоги о недвижимости? Сейчас читаю https://armid44.ru
Kylian Mbappe Lotten https://kylian-mbappe.prostoprosport-cz.org Francouzsky fotbalista, utocnik Paris Saint-Germain a kapitan tymu francouzskeho tymu. 1. cervence 2024 se stane hracem spanelskeho klubu Real Madrid.
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://azimut-irkutsk.ru
스핀 슬롯
이 문학과 역사 박물관에는 모두가 일찍 왔고 공식적인 사업은 아직 시작되지 않았습니다.
Kevin De Bruyne https://kevin-de-bruyne.prostoprosport-cz.org Belgicky fotbalista, zaloznik Manchesteru klub City” a belgicky narodni tym. Absolvent fotbalovych klubu „Ghent” a „Genk”. V roce 2008 zahajil svou karieru dospelych, debutoval v Genku.
русское порно анал русское порно анал .
Приветствую. Подскажите, где почитать полезные статьи о недвижимости? Пока нашел https://ecn-novodom.ru
Lionel Messi https://lionel-messi.prostoprosport-cz.org je argentinsky fotbalista, utocnik a kapitan klubu MLS Inter Miami. , kapitan argentinske reprezentace. Mistr sveta, vitez Jizni Ameriky, vitez finale, olympijsky vitez. Povazovan za jednoho z nejlepsich fotbalistu vsech dob.
Bernardo Silva https://bernardo-silva.prostoprosport-cz.org Portugalsky fotbalista, zaloznik. Narozen 10. srpna 1994 v Lisabonu. Silva je povazovan za jednoho z nejlepsich utocnych zalozniku na svete. Fotbalista je povestny svou vytrvalosti a vykonem.
Antoine Griezmann https://antoine-griezmann.prostoprosport-cz.org Francouzsky fotbalista, utocnik a zaloznik za Atletico de Madrid. Hrac a vicekapitan francouzskeho narodniho tymu, clen tymu – mistr sveta 2018 Stribrny medailista z mistrovstvi Evropy 2016 a mistrovstvi sveta 2022.
Robert Lewandowski https://robert-lewandowski.prostoprosport-cz.org je polsky fotbalista, utocnik spanelskeho klubu Barcelona a kapitan polskeho narodniho tymu. Povazovan za jednoho z nejlepsich utocniku na svete. Rytir krize velitele polskeho renesancniho radu.
Следственная группа по делу «Бест Вей»: следователи или оборотни в погонах?
ОПГ Колокольцева
Следственная группа по делу кооператива «Бест Вей» во главе со следователями ГСУ ГУ МВД по Санкт-Петербургу и Ленобласти майором юстиции Екатериной Сапетовой и подполковником юстиции Константином Иудичевым играет собственную партию либо для того, чтобы выслужиться перед непосредственным начальством, либо из-за прямой заинтересованности в уничтожении кооператива со стороны конкурентов и/или банков.
Следствие по делу кооператива «Бест Вей» вступило в активную фазу ровно год назад. За это время арестованы четверо технических сотрудников, и уже год они томятся в СИЗО, пятеро граждан объявлены в розыск.
Офис кооператива буквально разгромлен двумя обысками, документация изъята, и следствие запрещает ее копировать, счета и недвижимость арестованы. Под арестом — активы на более чем 15 млрд рублей, хотя ущерб для так называемых потерпевших, пул которых следователи год собирали под разными предлогами, не превышает 115 млн рублей. Это спустя почти полтора года с момента возбуждения уголовного дела, не считая периода длительного проведения оперативно-разыскных мероприятий. Гора родила мышь.
При этом значительная часть этих потерпевших, например, бывшие пайщики, которые внесли невозвратный вступительный взнос, но затем не смогли копить на квартиру и сами вышли из кооператива, а теперь по наущению следствия подали заявление о том, что кооператив им не вернул то, что и не должен был вернуть. Потерпевших 100 с лишним человек, притом что в кооперативе — более 19 тыс. пайщиков, то есть капля в море, да и эти 100 не имеют юридически обоснованных претензий к кооперативу. Среди представленных следствием потерпевших есть и конкуренты — бывшие пайщики, которые еще несколько лет назад вышли из «Бест Вей» и создали «альтернативный» кооператив «Вера».
Следователи обосновывают арест счетов тем, что «деньги могут украсть», хотя они же сами как минимум участвуют во вполне криминальном использовании чужих денег, уже год не давая пайщикам ни приобрести квартиру за счет средств, которые они скопили на счете в кооперативе, ни забрать деньги, при этом предоставляя возможность банкам. Следователи уже год дают возможность банкам пользоваться счетами почти на 4 млрд рублей, притом постоянно пополняющимися, так как большинство пайщиков продолжает вносить паевые и членские взносы.
Парадокс в том, что новая история обиженных дольщиков (в данном случае пайщиков) всероссийского масштаба возникла не из-за того, что у организации не оказалось средств для выполнения обязательств, а из-за того, что следственная группа лишила ее возможности пользования средствами и прямо блокирует выполнение обязательств перед пайщиками.
Адвокатам кооператива несколько раз удавалось добиться снятия арестов с активов кооператива, однако следователи и банки просто игнорируют решения судов. Потом, пользуясь высоким статусом следователей главка, заходят с новым ходатайством об аресте через кабинет судьи и без участия представителей кооператива, и активы снова арестовываются — до следующей успешной апелляции адвокатов, после которой в дело вступают банки, по договоренности со следствием блокирующие счета в рамках процедур комплаенс, игнорируя решения судов.
Должностное преступление
Действия следственной группы не могут квалифицироваться иначе, как должностное преступление, так как в них прослеживается заинтересованность в уничтожении кооператива. Фактически они сами организуют преступление, которое якобы расследуют, целенаправленно разрушают кооператив, а не спасают пайщиков, не нуждающихся в их спасении и 15 февраля проводящих всероссийскую акцию в защиту своего кооператива от следственной группы.
Адвокаты подавали в Следственный комитет заявление о преступлении, но оно было положено под сукно.
К службе не годны
Отдельная тема — вопиющая профнепригодность следственной группы. Иудичев в своих ответах на запросы ничтоже сумняшеся пишет, что Центральный банк признал кооператив финансовой пирамидой, хотя ЦБ, во-первых, не суд, чтобы делать такие «признания», во-вторых, такого признания просто не было: утверждение не соответствует действительности.
ЦБ внес кооператив в так называемый предупредительный список, являющийся инструментом информирования потребителей финансовых услуг об организациях, работа с которыми чревата для граждан рисками, и решение о включении в этот список состоялось после возбуждения уголовного дела, скорее всего, как раз на основе информации о его возбуждении.
Любимая тема следственной группы — якобы незаконность переименования кооператива из жилищного в потребительский: они не могут даже прочитать Жилищный кодекс, где черным по белому написано, что жилищный кооператив — один из видов жилищного. И подобных примеров некомпетентности и выдумок в деятельности следователей масса.
В итоге мы имеем шитое белыми нитками дело, наносящее колоссальный ущерб тысячам пайщиков кооператива, среди которых преобладают малообеспеченные люди.
Возникают вопросы: не пора ли министру Колокольцеву разобраться со своими сотрудниками, не пора ли главе Следкома Бастрыкину обратить внимание на должностные преступления в «соседнем» ведомстве?
Что нужно знать перед походом к стоматологу, предлагаем.
Что такое эндодонтия, качественный уход за зубами.
Как избежать боли при лечении зубов, предлагаем.
Мифы о стоматологии, в которые верят все, качественные советы стоматолога.
Как избежать проблем с зубами, предлагаем.
Как выбрать хорошего стоматолога, эффективные методики стоматологии.
Что делать при кровоточащих деснах, ознакомиться.
стоматологія спектр https://klinikasuchasnoistomatologii.vn.ua/ .
видеостена https://kupit-videostenu.ru/ .
Всем привет! Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://germes-alania.ru
toto togel komengtoto
Выберите стильные тактичные штаны для повседневной носки, для идеального комфорта и функциональности.
Новинки в мире тактичной одежды: лучшие штаны, сделанные для вашего комфорта.
Советы по выбору тактичных штанов, и какие модели стоит обратить внимание.
Тактичные штаны: идеальное сочетание стиля и практичности, сделанные для динамичного образа жизни.
Тактичные штаны: выбор современного мужчины, для максимального комфорта в походе.
тактичні штани жіночі https://vijskovitaktichnishtanu.kiev.ua/ .
Pablo Martin Paez Gavira https://gavi.prostoprosport-cz.org Spanelsky fotbalista, zaloznik barcelonskeho klubu a spanelske reprezentace. Povazovan za jednoho z nejtalentovanejsich hracu sve generace. Ucastnik mistrovstvi sveta 2022. Vitez Ligy narodu UEFA 2022/23
Luka Modric https://luka-modric.prostoprosport-cz.org je chorvatsky fotbalista, stredni zaloznik a kapitan spanelskeho tymu. klub Real Madrid, kapitan chorvatskeho narodniho tymu. Uznavan jako jeden z nejlepsich zalozniku nasi doby. Rytir Radu prince Branimira. Rekordman chorvatske reprezentace v poctu odehranych zapasu.
Pedro Gonzalez Lopez https://pedri.prostoprosport-cz.org lepe znamy jako Pedri, je spanelsky fotbalista, ktery hraje jako utocny zaloznik. za Barcelonu a spanelskou reprezentaci. Bronzovy medailista z mistrovstvi Evropy 2020 a zaroven nejlepsi mlady hrac tohoto turnaje.
Alison Ramses Becker https://alisson-becker.prostoprosport-cz.org Brazilsky fotbalista nemeckeho puvodu, brankar klubu Liverpool a brazilsky narodni tym. Je povazovan za jednoho z nejlepsich brankaru sve generace a je znamy svymi vynikajicimi zakroky, presnosti prihravek a schopnosti jeden na jednoho.
Karim Benzema https://karim-benzema.prostoprosport-cz.org je francouzsky fotbalista, ktery hraje jako utocnik za Saudskou Arabii. Arabsky klub Al-Ittihad. Hral za francouzsky narodni tym, za ktery odehral 97 zapasu a vstrelil 37 branek. V 17 letech se stal jednim z nejlepsich hracu rezervy, nastrilel tri desitky golu za sezonu.
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Сейчас читаю https://ilinka2.ru
Rodrigo Silva de Goiz https://rodrygo.prostoprosport-cz.org Brazilsky fotbalista, utocnik Realu Madrid a brazilskeho narodniho tymu. V breznu 2017 byl Rodrigo povolan do narodniho tymu Brazilie U17 na zapasy Montague Tournament.
buy aldactone 25mg online – aldactone 100mg oral revia 50 mg oral
Thibaut Nicolas Marc Courtois https://thibaut-courtois.prostoprosport-cz.org Belgicky fotbalista, brankar spanelskeho klubu Real Madrid . V sezone 2010/11 byl uznan jako nejlepsi brankar v belgicke Pro League a take hrac roku pro Genk. Trojnasobny vitez Ricardo Zamora Trophy
Toni Kroos https://toni-kroos.prostoprosport-cz.org je nemecky fotbalista, ktery hraje jako stredni zaloznik za Real Madrid a nemecky narodni tym. Mistr sveta 2014. Prvni nemecky hrac v historii, ktery sestkrat vyhral Ligu mistru UEFA.
Romelu Menama Lukaku Bolingoli https://romelu-lukaku.prostoprosport-cz.org Belgicky fotbalista, utocnik anglickeho klubu Chelsea a Belgican vyber. Na hostovani hraje za italsky klub Roma.
how to buy tiktok followers buy real tiktok followers
смотреть бесплатно в хорошем качестве отчаянные домохозяйки сериал отчаянные домохозяйки смотреть
businka74.ru регистрация рио бет казино
슬롯 게임 추천
Fang Jifan의 눈이 빛나고 흑단을 비축하는 아이디어가 떠 올랐습니다.
Slot machines on the official website and mirrors of the Pin Up online casino https://pin-up.tr-kazakhstan.kz are available for free mode, and after registering at Pin Up Casino Ru you can play for money.
Sports in Azerbaijan https://idman-xeberleri.com.az development and popular sports Azerbaijan is a country with rich sports traditions and outstanding achievements on the international stage.
blackpanther77
купить спортивные комплексы и площадки купить спортивные комплексы и площадки .
World of Games https://onlayn-oyunlar.com.az provides the latest news about online games, game reviews, gameplay and ideas, game tactics and tips. The most popular and spectacular
NHL (National Hockey League) News https://nhl.com.az the latest and greatest NHL news for today. Sports news – latest NHL news, standings, match results, online broadcasts.
Привет, друзья!
Приобрести диплом о высшем образовании.
Стоимость значительно ниже нежели понадобилось бы платить на очном обучении в университете
Где приобрести диплом специалиста?
http://istinastroitelstva.xyz/index.php?subaction=userinfo&user=eziwolo
Удачи!
ремонт стиральных машин на дому https://centr-remonta-stiralnyh-mashin.ru .
Узнайте всю правду о берцах зсу, Почему берці зсу так важны для культуры?, Какова история появления берців зсу?, углубитесь в, Берці зсу: связь с предками, Берці зсу: символ силы, исследуйте, магией, Берці зсу: древние тайны, Спробуйте на власній шкірі бути Берцем зсу, дізнайтесь, зрозумійте
літні берці зсу купити https://bercitaktichnizsu.vn.ua/ .
하이퍼노바 인피니티 릴스
이 기복, 모두가 이해하는 세상의 쓰레기…
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://officesaratov.ru
Погрузитесь в мир берців зсу, исследуйте, Зачем люди носят берці зсу?, Легенды и предания о берцах зсу, раскройте, проникнитесь, смысл, мощью, традициями, в мир, освійте, силу
купити літні берці зсу https://bercitaktichnizsu.vn.ua/ .
продвижение сайтов в москве цены https://prodvizhenie-sajtov-v-moskve115.ru/ .
buy generic flexeril for sale – prasugrel generic cost enalapril
продвижение сайтов в москве в яндекс и гугл https://prodvizhenie-sajtov-v-moskve115.ru .
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://sintes21.ru
продвижение сайтов в москве в яндекс и гугл http://www.prodvizhenie-sajtov-v-moskve115.ru .
оригинални дисплеи за телефони
Защо да избирате при нашият онлайн магазин?
Огромен разнообразие
Ние разполагаме с внушителен избор от сменяеми части и аксесоари за смартфони.
Атрактивни ставки
Прайс-листът ни са изключително привлекателни на индустрията. Ние полагаме усилия да предоставяме отлични услуги на най-ниските ставки, за да придобиете най-добра възвръщаемост за инвестицията.
Незабавна логистично обслужване
Всички направени заявки направени до 16:00 часа се обработват и изпращат светкавично. Така гарантираме, че ще придобиете желаните принадлежности максимално скоро.
Интуитивно търсене
Нашият онлайн магазин е изграден да бъде удобен за търсене. Вие можете да разглеждате стоки по модел, което прецизира намирането на подходящия аксесоар за вашите изисквания.
Обслужване на високо ниво
Нашият персонал от експерти постоянно на услуга, за да помогнат на потребителските нужди и да съдействат да подберете необходимите продукти за вашите нужди. Ние работим упорито да постигнем непрекъснато грижа, за да сте удовлетворени от взаимодействието си с нас.
Водещи артикули:
Оригинални дисплеи за смартфони: Първокласни дисплеи, които осигуряват безупречно визуализация.
Сменяеми компоненти за телефони: От захранващи източници до други компоненти – необходимите за възстановяването на вашето устройство.
Мобилен ремонт: Професионални сервизни услуги за ремонт на вашата техника.
Допълнителни принадлежности за мобилни устройства: Многообразие от зарядни устройства.
Елементи за електронни комуникации: Всичко необходимо принадлежности за поддръжка на Ваши телефони.
Доверете се към нас за Необходимите изисквания от резервни части за таблети, и се насладете на качествени услуги, отлични ценови равнища и безупречно грижа.
Студия Подкастов в Москве, Запись подкастов в Москве.
http://video-podcast.ru/
레거시 오브 데드
그 유전적인 황실 의사들은 정말 설득력이 있습니다.
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://ste96.ru
В чёрный список пирамид и лохотронов 31 августа 2022 года внесены следующие организации, обладающие признаками финансовой пирамиды или признаками мошенничества.
гей член
Etihad Rail (etihadrail-ae.com)
Club Unite To Live, Life Is Good, Unite To Live (uniteto.live). Новый домен пирамиды находящегося в розыске Романа Василенко.
TopBoom, «платформа хедж-фонда, специализирующегося на сделках с обратным исходом спортивного события» (topboom.vip, t.me/TopBoom001)
Change Team, мошенники указывают реквизиты чужого юрлица ООО «АТТИС ГРУПП» (ОРГН 1207700314128, ИНН 9702022065), телеграм-канал «Change Team: Главный Канал» (change-team.ru). Фальшивый обменник раньше назывался C Exchange.
Ещё лохотроны:
Scam! Чёрный список пирамид и лохотронов и отзывы
В чёрный список пирамид и лохотронов включены организации, имеющие признаки финансовой пирамиды по классификации Центрального банка; организации, обладающие признаками матричной пирамиды (массовый привод друзей, «столы»); сборы денег с пенсионеров и прочих незащищённых слоёв населения; хайпы; организации, имеющие негативные отзывы; структуры, оказывающие финансовые услуги без лицензии и прочие лохотроны за исключением псевдоброкеров, кооперативов (с ними тоже не рекомендуем связываться) и некоторых других категорий.
purchase zofran generic – buy selegiline sale requip canada
Международное бронирование гостиниц
Предварително заявете перфектен хижа незакъснително днес
Идеальное место для отдыха с атрактивна такса
Бронируйте най-добри оферти отелей и размещений веднага със сигурност на наша система резервиране. Откройте за ваше удоволствие уникальные варианти и ексклузивни намаления за заемане отелей из цял глобус. Независимо желаете предприемате почивка до плаж, деловую поездку или романтический уикенд, в нашия магазин ще намерите идеальное дестинация для проживания.
Автентични снимки, оценки и отзывы
Преглеждайте подлинные снимки, обстойни отзиви и правдиви препоръки за хотелите. Осигуряваме разнообразен асортимент алтернативи отсядане, за да можете выбрать оня, который най-добре удовлетворява вашия бюджет и стилю путешествий. Нашата услуга гарантира достъпно и доверие, давайки Ви изискваната информацию для принятия най-добро решение.
Простота и надеждност
Забудьте за отнемащите разглеждания – оформете незабавно безпроблемно и сигурно у нас, с возможностью разплащане в настаняването. Наш процесс бронирования безпроблемен и безопасен, что позволяет вам да се фокусирате върху планирането на вашата дейност, вместо по детайли.
Главные обекти земното кълбо для посещения
Найдите перфектното място за престой: места за подслон, гостевые дома, общежития – все под рукой. Над 2М опции на ваш выбор. Начните Вашето пътуване: резервирайте места за отсядане и исследуйте топ направления на територията на миру! Наш сайт осигурява качествените оферти за престой и широк выбор места за всеки уровня бюджет.
Опознайте отблизо Европейския континент
Изучайте города Европа за откриване на варианти за престой. Изследвайте обстойно места размещения на Европейския континент, от курортов на Средиземно море до алпийски прибежища в Алпийските планини. Наши указания ще ви доведат к лучшим оферти размещения в континентален свят. Лесно нажмите препратките отдолу, за находяне на отель във Вашата предпочитана европейска държава и стартирайте Вашето европейско опознаване
Заключение
Заявете превъзходно место за туризъм с конкурентна ставка веднага
русское порно анал бесплатно русское порно анал бесплатно .
Бронирование отелей
Зарезервируйте идеальный отель уже незабавно
Отлично пункт за туризъм по выгодной цене
Бронируйте лучшие възможности подслон и квартири незабавно с гарантией на нашия сервиса заемане. Разгледайте для себя неповторими варианти и специални намаления за заявяване отелей из цял глобус. Независимо от желаете организирате пътуване до море, деловую поездку или семеен уикенд, при нас ще откриете перфектно дестинация за настаняване.
Подлинные снимки, рейтинги и отзывы
Преглеждайте оригинални изображения, детайлни ревюта и правдиви препоръки об отелях. Предоставяме голям номенклатура вариантов настаняване, за да сте в състояние изберете тот, который най-пълно отговаря вашему средства и стилю пътуване. Нашата услуга предоставя достъпно и сигурност, давайки Ви всю необходимую информацию для принятия правилен избор.
Удобство и безопасность
Пренебрегнете за продължителните издирвания – забронируйте сейчас просто и безопасно в нашата компания, с опция плащане при пристигане. Наш процесс бронирования интуитивен и гарантиран, что позволяет вам да се концентрирате на планировании вашего путешествия, а не в подробностите.
Главные достопримечательности глобуса за туристически интерес
Найдите отличното място за нощуване: отели, гостевые дома, общностни ресурси – всичко наблизо. Около 2 миллионов оферти за Ваше решение. Започнете Вашето изследване: забронируйте отели и опознавайте лучшие направления във всички света! Нашето предложение осигурява най-добрите възможности за подслон и богат асортимент места за всеки степен финансов ресурс.
Опознайте отблизо Европейския континент
Разследвайте локациите Европы за откриване на отелей. Изследвайте для себя варианти за настаняване на Европейския континент, от крайбрежни в средиземноморския регион до планински убежища в Алпийския регион. Нашите препоръки приведут вас към водещите опции подслон в континентален континенте. Незабавно нажмите на ссылки по-долу, чтобы найти място за настаняване във Вашата желана европейска дестинация и инициирайте Вашето континентално преживяване
Обобщение
Забронируйте превъзходно место за туризъм по выгодной такса веднага
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://mart-posters.ru
Всем привет! Подскажите, где найти полезные блоги о недвижимости? Сейчас читаю https://metrazhi-omsk.ru
Всем привет! Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://tochkacn.ru
무료 프라그마틱
어젯밤의 모든 손님은 이것에 익숙하다고 느꼈습니다.
Всем привет! Подскажите, где почитать полезные статьи о недвижимости? Сейчас читаю https://mzhk-stroy.ru
buy ascorbic acid 500mg pill – order generic ciprodex ophthalmic solution buy compro sale
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Пока нашел https://potolkinomer1.ru
амл проверка
Противоотмывочная верификация: Как избежать замораживание активов в криптосфере
С какой целью важна AML-проверка?
Процедура противодействия отмыванию денег (Борьба с отмыванием денег) – включает в себя совокупность действий, нацеленных на борьбу отбеливания ресурсов. Подобная оценка обеспечивает охранять виртуальные фонды пользователей и предотвращать использование сервисов криминальных операций. Процедура противодействия отмыванию денег требуется в интересах обеспечения неприкосновенности своих средств вместе с соблюдением юридических стандартов.
Главные способы верификации
Платформы обмена криптовалют помимо прочего платежные решения задействуют разные главных методов с целью проверки участников:
“Знай своего клиента”: Эта методика включает базовые процедуры для идентификации данных владельца, такие как проверка документов регистрации. Идентификация личности помогает убедиться, что участник представляет собой доверенным.
CFT: Сосредоточена для предотвращения поддержки терроризма. Механизм мониторит сомнительные операции и при необходимости блокирует аккаунты для проведения внутрикорпоративного расследования.
Полезные стороны процедуры противодействия отмыванию денег
Проверка по борьбе с отмыванием денег обеспечивает участникам криптосферы:
Придерживаться мировые вместе с национальными законодательные стандарты.
Защищать клиентов незаконных операций.
Укреплять мера репутации со стороны пользователей госорганов.
Каким способом минимизировать риски свои средства во время операций с криптовалютой
Чтобы ограничить риски ограничения активов, следуйте перечисленным указаниям:
Работайте с заслуживающие доверие биржи: Используйте только к обменникам надежной оценкой наряду с высоким мерой надежности.
Проверяйте контрагентов: Используйте решения для верификации посредством проверки цифровых кошельков участников непосредственно перед осуществлением сделок.
Периодически обновляйте виртуальные счета: Данное действие позволит снизить гипотетических ограничений, в ситуации когда Ваши партнеры получатели попадут в серых списках.
Обеспечивайте подтверждения переводов: При необходимости получите возможность верифицировать чистоту полученных фондов.
Резюме
AML-проверка – является важный средство для обеспечения неприкосновенности активностей на криптовалютном рынке. Эта практика помогает минимизировать сокрытие активов, обеспечение терроризма а также иные криминальные мероприятия. Применяя советам по безопасности и выбирая безопасные биржи, будете в состоянии минимизировать вероятности блокировки ресурсов взаимодействовать надежной деятельностью в криптосфере.
Наш портал предлагает вам подробную информацию на такие темы, как [url=https://xn—-stbkav.xn--p1ai/]агентство недвижимости[/url] или [url=https://xn—-stbkav.xn--p1ai/]новостройки Москвы и Подмосковья[/url].
Посетите наш сайт и начните свой путь к собственному жилью уже сегодня!
sapporo88 login
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://promresmag.ru
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://schuconvr.ru
Всем привет! Подскажите, где найти разные блоги о недвижимости? Пока нашел https://simposad.ru
온라인 슬롯 머신 게임
Hongzhi 황제의 얼굴 전체가 심각해졌습니다. “지금 몇 개를 확인 했습니까?”
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://smgarant.ru
best online pharmacies in mexico
https://cmqpharma.com/# purple pharmacy mexico price list
buying prescription drugs in mexico
Приветствую. Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://tc-all.ru
外送茶
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://teplohod-denisdavidov.ru
Приветствую. Может кто знает, где почитать разные статьи о недвижимости? Пока нашел https://titovloft.ru
order durex gel – buy durex gel online cheap buy xalatan generic
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://toadmarket.ru
купить диплом брянск ast-diplom.com .
world of warcraft raid carry
Всем привет! Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://utc96.ru
Здравствуйте!
Где заказать диплом специалиста?
Купить диплом ВУЗа.
http://av.flyboard.ru/viewtopic.php?f=9&t=1339&sid=c2e56033b33c034add261ae4b8a039a0
Удачи!
슬롯 안전한 사이트
이것이 Fang Jifan이 이 세상에 왔을 때 배운 것입니다.
купить диплом мгу в нижнем тагиле ast-diplom.com .
Всем привет! Подскажите, где почитать разные статьи о недвижимости? Сейчас читаю https://vortex-los.ru
1 win ios [url=http://www.1win.tr-kazakhstan.kz]http://www.1win.tr-kazakhstan.kz[/url] как использовать бонус спорт в 1win https://www.1win.tr-kazakhstan.kz
sunmory33 login
Приветствую. Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://yah-bomag.ru
Приветствую. Может кто знает, где найти разные блоги о недвижимости? Пока нашел https://yaoknaa.ru
娛樂城
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://zt365.ru
外送茶
外送茶是什麼?禁忌、價格、茶妹等級、術語等..老司機告訴你!
外送茶是什麼?
外送茶、外約、叫小姐是一樣的東西。簡單來說就是在通訊軟體與茶莊聯絡,選好自己喜歡的妹子後,茶莊會像送飲料這樣把妹子派送到您指定的汽車旅館、酒店、飯店等交易地點。您只需要在您指定的地點等待,妹妹到達後,就可以開心的開始一場美麗的約會。
外送茶種類
學生兼職的稱為清新書香茶
日本女孩稱為清涼綠茶
俄羅斯女孩被稱為金酥麻茶
韓國女孩稱為超細滑人參茶
外送茶價格
外送茶的客戶相當廣泛,包括中小企業主、自營商、醫生和各行業的精英,像是工程師等等。在台北和新北地區,他們的消費指數大約在 7000 到 10000 元之間,而在中南部則通常在 4000 到 8000 元之間。
對於一般上班族和藍領階層的客人來說,建議可以考慮稍微低消一點,比如在北部約 6000 元左右,中南部約 4000 元左右。這個價位的茶妹大多是新手兼職,但有潛力。
不同地區的客人可以根據自己的經濟能力和喜好選擇適合自己的價位範圍,以免感到不滿意。物價上漲是一個普遍現象,受到地區和經濟情況等因素的影響,茶莊的成本也在上升,因此價格調整是合理的。
外送茶外約流程
加入LINE:加入外送茶官方LINE,客服隨時為你服務。茶莊一般在中午 12 點到凌晨 3 點營業。
告知所在地區:聯絡客服後,告訴他們約會地點,他們會幫你快速找到附近的茶妹。
溝通閒聊:有任何約妹問題或需要查看妹妹資訊,都能得到詳盡的幫助。
提供預算:告訴客服你的預算,他們會找到最適合你的茶妹。
提早預約:提早預約比較好配合你的空檔時間,也不用怕到時候約不到你想要的茶妹。
外送茶術語
喝茶術語就像是進入茶道的第一步,就像是蓋房子打地基一樣。在這裡,我們將這些外送茶入門術語分類,讓大家能夠清楚地理解,讓喝茶變得更加容易上手。
魚:指的自行接客的小姐,不屬於任何茶莊。
茶:就是指「小姐」的意思,由茶莊安排接客。
定點茶:指由茶莊提供地點,客人再前往指定地點與小姐交易。
外送茶:指的是到小姐到客人指定地點接客。
個工:指的是有專屬工作室自己接客的小姐。
GTO:指雞頭也就是飯店大姊三七茶莊的意思。
摳客妹:只負責找客人請茶莊或代調找美眉。
內機:盤商應召站提供茶園的人。
經紀人:幫內機找美眉的人。
馬伕:外送茶司機又稱教練。
代調:收取固定代調費用的人(只針對同業)。
阿六茶:中國籍女子,賣春的大陸妹。
熱茶、熟茶:年齡比較大、年長、熟女級賣春者(或稱阿姨)。
燙口 / 高溫茶:賣春者年齡過高。
台茶:從事此職業的台灣小姐。
本妹:從事此職業的日本籍小姐。
金絲貓:西方國家的小姐(歐美的、金髮碧眼的那種)。
青茶、青魚:20 歲以下的賣春者。
乳牛:胸部很大的小姐(D 罩杯以上)。
龍、小叮噹、小叮鈴:體型比較肥、胖、臃腫、大隻的小姐。
Привет, друзья!
Где купить диплом специалиста?
Купить диплом университета.
http://karkadan.ru/users/77829
Успешной учебы!
Всем привет! Может кто знает, где почитать разные статьи о недвижимости? Пока нашел https://astali.ru
поисковая раскрутка сайтов москва
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Сейчас читаю https://batstroimat24.ru
Приветствую. Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://bdrsu-2.ru
Привет, друзья!
Где заказать диплом по нужной специальности?
Приобрести диплом ВУЗа.
http://pirat.iboards.ru/viewtopic.php?f=20&t=20746
Хорошей учебы!
Привет!
Приобрести диплом о высшем образовании
Наши специалисты предлагают выгодно купить диплом, который выполнен на оригинальной бумаге и заверен печатями, водяными знаками, подписями официальных лиц. Документ пройдет лубую проверку, даже с использованием профессиональных приборов. Достигайте своих целей быстро с нашими дипломами.
Где приобрести диплом специалиста?
https://ironway.ru/forum/viewtopic.php?f=5&t=21078
Рады оказаться полезными!.
Всем привет! Может кто знает, где почитать разные блоги о недвижимости? Сейчас читаю https://centro-kraska.ru
wow mythic raid carry wow mythic raid carry .
Gerakl24: Опытная Смена Основания, Венцов, Полов и Перенос Домов
Фирма Gerakl24 специализируется на предоставлении полных сервисов по замене основания, венцов, покрытий и перемещению зданий в городе Красноярском регионе и за его пределами. Наш коллектив профессиональных экспертов обещает отличное качество реализации различных типов восстановительных работ, будь то деревянные, каркасные, из кирпича или из бетона дома.
Достоинства услуг Gerakl24
Профессионализм и опыт:
Все работы выполняются исключительно высококвалифицированными специалистами, с многолетним многолетний стаж в направлении создания и реставрации домов. Наши мастера профессионалы в своем деле и осуществляют задачи с максимальной точностью и вниманием к мелочам.
Комплексный подход:
Мы осуществляем все виды работ по реставрации и ремонту домов:
Реставрация фундамента: усиление и реставрация старого основания, что обеспечивает долгий срок службы вашего здания и устранить проблемы, связанные с оседанием и деформацией строения.
Реставрация венцов: восстановление нижних венцов деревянных зданий, которые чаще всего подвергаются гниению и разрушению.
Смена настилов: монтаж новых настилов, что значительно улучшает внешний облик и функциональные характеристики.
Перемещение зданий: безопасное и надежное перемещение зданий на другие участки, что обеспечивает сохранение строения и избегает дополнительных затрат на возведение нового.
Работа с любыми видами зданий:
Деревянные дома: восстановление и укрепление деревянных конструкций, обработка от гниения и насекомых.
Дома с каркасом: усиление каркасных конструкций и реставрация поврежденных элементов.
Кирпичные строения: реставрация кирпичной кладки и укрепление конструкций.
Бетонные строения: реставрация и усиление бетонных элементов, исправление трещин и разрушений.
Надежность и долговечность:
Мы используем только высококачественные материалы и современное оборудование, что обеспечивает долгий срок службы и надежность всех работ. Все проекты проходят строгий контроль качества на каждом этапе выполнения.
Индивидуальный подход:
Для каждого клиента мы предлагаем подходящие решения, с учетом всех особенностей и пожеланий. Наша цель – чтобы результат нашей работы полностью соответствовал вашим запросам и желаниям.
Зачем обращаться в Геракл24?
Обратившись к нам, вы приобретете надежного партнера, который возьмет на себя все заботы по ремонту и реставрации вашего дома. Мы гарантируем выполнение всех работ в сроки, оговоренные заранее и с соблюдением всех правил и норм. Обратившись в Геракл24, вы можете не сомневаться, что ваше строение в надежных руках.
Мы готовы предоставить консультацию и ответить на ваши вопросы. Звоните нам, чтобы обсудить детали и узнать больше о наших услугах. Мы обеспечим сохранение и улучшение вашего дома, обеспечив его безопасность и комфорт на долгие годы.
Gerakl24 – ваш надежный партнер в реставрации и ремонте домов в Красноярске и за его пределами.
Всем привет! Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://deon-stroy.ru
Приветствую. Подскажите, где почитать разные статьи о недвижимости? Пока нашел https://dom-vasilevo.ru
Обязательно попробуйте обратиться к Mihaylov digital, их специализация это продвижение сайтов в гугл и яндекс, а еще разработка сайтов.
娛樂城
order minoxidil online cheap – cost rogaine proscar 1mg generic
nettruyen
NetTruyen ZZZ: Nền tảng đọc truyện tranh trực tuyến dành cho mọi lứa tuổi
NetTruyen ZZZ là nền tảng đọc truyện tranh trực tuyến miễn phí với số lượng truyện tranh lên đến hơn 30.000 đầu truyện với chất lượng hình ảnh và tốc độ tải cao. Nền tảng được xây dựng với mục tiêu mang đến cho người đọc những trải nghiệm đọc truyện tranh tốt nhất, đồng thời tạo dựng cộng đồng yêu thích truyện tranh sôi động và gắn kết với hơn 11 triệu thành viên (tính đến tháng 7 năm 2024).
NetTruyen ZZZ – Kho tàng truyện tranh phong phú:
NetTruyen ZZZ sở hữu kho tàng truyện tranh khổng lồ với hơn 30.000 đầu truyện thuộc nhiều thể loại khác nhau như:
● Manga: Những bộ truyện tranh Nhật Bản với nhiều thể loại phong phú như lãng mạn, hành động, hài hước, v.v.
● NetTruyen anime: Hàng ngàn bộ truyện tranh anime chọn lọc được đăng tải đều đặn trên NetTruyen ZZZ được chuyển thể từ phim hoạt hình Nhật Bản với nội dung hấp dẫn và hình ảnh đẹp mắt.
● Truyện manga: Hơn 10.000 bộ truyện tranh manga hay nhất được đăng tải đầy đủ trên NetTruyen ZZZ.
● Truyện manhua: Hơn 5000 bộ truyện tranh manhua được đăng tải trọn bộ đầy đủ trên NetTruyen ZZZ.
● Truyện manhwa: Những bộ truyện tranh manhwa Hàn Quốc được yêu thích nhất có đầy đủ trên NetTruyen với cốt truyện lôi cuốn và hình ảnh bắt mắt cùng với nét vẽ độc đáo và nội dung đa dạng.
● Truyện ngôn tình: Những câu chuyện tình yêu lãng mạn, ngọt ngào và đầy cảm xúc.
● Truyện trinh thám: Những câu chuyện ly kỳ, bí ẩn và đầy lôi cuốn xoay quanh các vụ án và quá trình phá án.
● Truyện tranh xuyên không: Những câu chuyện về những nhân vật du hành thời gian hoặc không gian đến một thế giới khác.
NetTruyen ZZZ không ngừng cập nhật những bộ truyện tranh mới nhất và hot nhất trên thị trường, đảm bảo mang đến cho bạn đọc những trải nghiệm đọc truyện mới mẻ và thú vị nhất.
Chất lượng hình ảnh và nội dung đỉnh cao tại NetTruyenZZZ:
Với hơn 30 triệu lượt truy cập hằng tháng, NetTruyen ZZZ luôn chú trọng vào chất lượng hình ảnh và nội dung của các bộ truyện tranh được đăng tải trên nền tảng. Hình ảnh được hiển thị sắc nét, rõ ràng, không bị mờ hay vỡ ảnh. Nội dung được dịch thuật chính xác, dễ hiểu và giữ nguyên vẹn ý nghĩa của tác phẩm gốc.
NetTruyen ZZZ hợp tác với đội ngũ dịch giả và biên tập viên chuyên nghiệp, giàu kinh nghiệm để đảm bảo chất lượng bản dịch tốt nhất. Nền tảng cũng có hệ thống kiểm duyệt nội dung nghiêm ngặt để đảm bảo nội dung lành mạnh, phù hợp với mọi lứa tuổi.
Trải nghiệm đọc truyện mượt mà, tiện lợi:
NetTruyen ZZZ được thiết kế với giao diện đẹp mắt, thân thiện với người dùng và dễ dàng sử dụng. Bạn đọc có thể đọc truyện tranh trên mọi thiết bị, từ máy tính, điện thoại thông minh đến máy tính bảng. Nền tảng cũng cung cấp nhiều tính năng tiện lợi như:
● Tìm kiếm truyện tranh theo tên, tác giả, thể loại, v.v.
● Lưu truyện tranh yêu thích để đọc sau.
● Đánh dấu trang để dễ dàng quay lại vị trí đang đọc.
● Chia sẻ truyện tranh với bạn bè.
● Tham gia bình luận và thảo luận về truyện tranh.
NetTruyen ZZZ luôn nỗ lực để mang đến cho bạn đọc những trải nghiệm đọc truyện mượt mà, tiện lợi và thú vị nhất.
Định hướng phát triển:
NetTruyen ZZZ cam kết không ngừng phát triển và hoàn thiện để trở thành nền tảng đọc truyện tranh trực tuyến tốt nhất dành cho bạn đọc tại Việt Nam. Nền tảng sẽ tiếp tục cập nhật những bộ truyện tranh mới nhất và hot nhất trên thị trường thế giới, đồng thời nâng cao chất lượng hình ảnh và nội dung. NetTruyen ZZZ cũng sẽ phát triển thêm nhiều tính năng mới để mang đến cho bạn đọc những trải nghiệm đọc truyện tốt nhất.
NetTruyen ZZZ luôn đặt lợi ích của bạn đọc lên hàng đầu. Nền tảng cam kết:
● Cung cấp kho tàng truyện tranh khổng lồ và đa dạng với chất lượng hình ảnh và nội dung đỉnh cao.
● Mang đến cho bạn đọc những trải nghiệm đọc truyện mượt mà, tiện lợi và thú vị nhất.
● Luôn lắng nghe ý kiến phản hồi của bạn đọc và không ngừng cải thiện để mang đến dịch vụ tốt nhất.
NetTruyen ZZZ hy vọng sẽ trở thành người bạn đồng hành không thể thiếu của bạn trong hành trình khám phá thế giới truyện tranh đầy màu sắc.
Kết nối với NetTruyen ZZZ ngay hôm nay để tận hưởng những trải nghiệm đọc truyện tuyệt vời.
купить диплом второй asxdiplomik24.ru .
Tributes flood in for BBC sport commentator whose wife and daughters were killed in suspected crossbow attack
гей онлайн
Figures from across the United Kingdom have offered their condolences to a BBC sport commentator, after his wife and two daughters were killed by an alleged crossbow attacker, in deaths that again drew attention to the epidemic of violence against women.
Carol Hunt, 61, wife of BBC horse racing commentator, John Hunt, and their daughters, Hannah Hunt, 28, and Louise Hunt, 25, died from injuries sustained in an attack in Bushey, just northwest of London, on Tuesday, according to police and Britain’s public broadcaster.
A 26-year-old suspect wanted in connection with the killings, and named as Kyle Clifford, was found by British police in Enfield, north London, on Wednesday, following a sprawling manhunt. There were no previous reports to the force over Clifford, who is in serious condition in hospital and is yet to speak with officers, Hertfordshire Police said in a statement.
A crossbow was recovered as part of the investigation, which police believe was used in a “targeted incident.”
Epidemic of violence against women
The killings of the three women rocked Britain, where mass murders are infrequent but violence against women and girls has been officially labeled as a national threat.
A woman is killed by a man every three days in the UK and one in four women will experience domestic violence in her lifetime, the United Nations’ special rapporteur on violence against women and girls, Reem Alsalem, said earlier this year.
Charities and human rights organizations have subsequently reiterated urgent demands to tackle femicide in the UK.
Tributes flood in for BBC sport commentator whose wife and daughters were killed in suspected crossbow attack
красивый анальный секс
Figures from across the United Kingdom have offered their condolences to a BBC sport commentator, after his wife and two daughters were killed by an alleged crossbow attacker, in deaths that again drew attention to the epidemic of violence against women.
Carol Hunt, 61, wife of BBC horse racing commentator, John Hunt, and their daughters, Hannah Hunt, 28, and Louise Hunt, 25, died from injuries sustained in an attack in Bushey, just northwest of London, on Tuesday, according to police and Britain’s public broadcaster.
A 26-year-old suspect wanted in connection with the killings, and named as Kyle Clifford, was found by British police in Enfield, north London, on Wednesday, following a sprawling manhunt. There were no previous reports to the force over Clifford, who is in serious condition in hospital and is yet to speak with officers, Hertfordshire Police said in a statement.
A crossbow was recovered as part of the investigation, which police believe was used in a “targeted incident.”
Epidemic of violence against women
The killings of the three women rocked Britain, where mass murders are infrequent but violence against women and girls has been officially labeled as a national threat.
A woman is killed by a man every three days in the UK and one in four women will experience domestic violence in her lifetime, the United Nations’ special rapporteur on violence against women and girls, Reem Alsalem, said earlier this year.
Charities and human rights organizations have subsequently reiterated urgent demands to tackle femicide in the UK.
NetTruyen ZZZ – nền tảng được 11 triệu người yêu truyện tranh chọn đọc
NetTruyen ZZZ là nền tảng đọc truyện tranh trực tuyến miễn phí với số lượng truyện tranh lên đến hơn 30.000 đầu truyện với chất lượng hình ảnh và tốc độ tải cao. Nền tảng được xây dựng với mục tiêu mang đến cho người đọc những trải nghiệm đọc truyện tranh tốt nhất, đồng thời tạo dựng cộng đồng yêu thích truyện tranh sôi động và gắn kết với hơn 11 triệu thành viên (tính đến tháng 7 năm 2024).
Là một người sáng lập NetTruyen ZZZ, cũng là một “mọt truyện” chính hiệu, tôi hiểu rõ niềm đam mê mãnh liệt và tình yêu vô bờ bến dành cho những trang truyện đầy màu sắc. Hành trình khám phá thế giới truyện tranh đã nuôi dưỡng tâm hồn tôi, khơi gợi trí tưởng tượng và truyền cảm hứng cho tôi trong suốt quãng đường trưởng thành.
NetTruyen ZZZ ra đời từ chính niềm đam mê ấy. Với sứ mệnh “Kết nối cộng đồng yêu truyện tranh và mang đến những trải nghiệm đọc truyện tốt nhất”, chúng tôi đã nỗ lực không ngừng để xây dựng một nền tảng đọc truyện tranh trực tuyến hoàn hảo, dành cho tất cả mọi người.
Tại NetTruyen ZZZ, bạn sẽ tìm thấy:
● Kho tàng truyện tranh khổng lồ và đa dạng: Hơn 30.000 đầu truyện thuộc mọi thể loại, từ anime, manga, manhua, manhwa đến truyện tranh Việt Nam, truyện ngôn tình, trinh thám, xuyên không,… đáp ứng mọi sở thích và nhu cầu của bạn.
● Chất lượng hình ảnh và nội dung đỉnh cao: Hình ảnh sắc nét, rõ ràng, không bị mờ hay vỡ ảnh. Nội dung được dịch thuật chính xác, dễ hiểu và giữ nguyên vẹn ý nghĩa của tác phẩm gốc.
● Trải nghiệm đọc truyện mượt mà, tiện lợi: Giao diện đẹp mắt, thân thiện với người dùng, dễ dàng sử dụng trên mọi thiết bị. Nhiều tính năng tiện lợi như: tìm kiếm truyện tranh, lưu truyện tranh yêu thích, đánh dấu trang, chia sẻ truyện tranh, bình luận và thảo luận về truyện tranh.
● Cộng đồng yêu truyện tranh sôi động và gắn kết: Tham gia cộng đồng NetTruyen ZZZ để kết nối với những người cùng sở thích, chia sẻ cảm xúc về các bộ truyện tranh yêu thích, thảo luận về những chủ đề liên quan đến truyện tranh và cùng nhau khám phá thế giới truyện tranh đầy màu sắc.
● Sự tận tâm và cam kết: NetTruyen ZZZ luôn lắng nghe ý kiến phản hồi của bạn đọc và không ngừng cải thiện để mang đến dịch vụ tốt nhất. Chúng tôi luôn đặt lợi ích của người dùng lên hàng đầu và cam kết mang đến cho bạn những trải nghiệm đọc truyện tuyệt vời nhất.
Là một người yêu truyện tranh, tôi hiểu được:
● Niềm vui được đắm chìm trong những câu chuyện đầy hấp dẫn.
● Sự phấn khích khi khám phá những thế giới mới mẻ.
● Cảm giác đồng cảm với những nhân vật trong truyện.
● Bài học quý giá mà mỗi bộ truyện mang lại.
Chính vì vậy, NetTruyen ZZZ không chỉ là một nền tảng đọc truyện tranh đơn thuần, mà còn là nơi để bạn:
● Thư giãn và giải trí sau những giờ học tập và làm việc căng thẳng.
● Khơi gợi trí tưởng tượng và sáng tạo.
● Rèn luyện khả năng ngôn ngữ và tư duy logic.
● Kết nối với bạn bè và chia sẻ niềm đam mê truyện tranh.
NetTruyen ZZZ sẽ là người bạn đồng hành lý tưởng cho hành trình khám phá thế giới truyện tranh của bạn.
Hãy cùng NetTruyen ZZZ nuôi dưỡng tâm hồn yêu truyện tranh và lan tỏa niềm đam mê này đến với mọi người. Kết nối với NetTruyen ZZZ ngay hôm nay để tận hưởng những trải nghiệm đọc truyện tuyệt vời.
Воины-пайщики оказались без защиты в тылу
Пайщики «Бест Вей» — участники СВО готовы защищать свой кооператив
Арест счетов Бест вей
Многие пайщики кооператива «Бест Вей» и те, в чьих интересах приобретаются квартиры в кооперативе, — участники СВО. И они сами, и их родственники возмущены событиями, происходящими вокруг кооператива. Ведь защищая интересы страны на фронте, в тылу они не защищены от того, что не могут приобрести недвижимость из-за того, что счета кооператива с почти 4 млрд рублей уже более двух лет находятся под арестом — притом, что сумма ущерба по уголовному делу, рассматриваемому Приморским районным судом Санкт-Петербурга, согласно обвинительному заключению, составляет 282 млн рублей.
«Надеемся, новое руководство Министерства обороны поможет урегулировать ситуацию»
Наталья Пригаро, мать пайщика кооператива — участника СВО из Нефтеюганска Даниила Пригаро:
— Сын расплатился за однокомнатную квартиру, приобретенную с помощью кооператива, еще два года назад, подал пакет документов на оформление квартиры в собственность в Росреестр в начале сентября 2022 года — и все это время не может зарегистрировать собственность на нее из-за того, что в Росреестре она значится как арестованная. В конце сентября 2022 года он был мобилизован. Сын брал кредит, чтобы расплатиться за квартиру с кооперативом. Планировал продать эту квартиру и взять квартиру побольше в ипотеку. Однако неоднократно накладывался арест на недвижимость кооператива, несмотря на то что сейчас ареста нет — последний арест, накладывавшийся осенью 2023 года, 19 февраля истек, ходатайства о новом аресте дважды отклонены судом, по Росреестру арест с квартиры до сих пор не снят. В результате кредит приходится платить, квартира в собственность до сих пор не оформлена.
У сына нет никакой физической и финансовой возможности выяснять отношения с Росреестром — в административном или судебном порядке, он приезжает в отпуска на неделю-полторы, ему не до сутяжничества. Я нахожусь в Анапе, приобрела квартиру с помощью кооператива — сын не имеет возможности сделать на меня генеральную доверенность, а я не могу из Анапы приехать в Нефтеюганск и решать вопросы в Росреестре — кроме поезда, сейчас, сами понимаете, ничего не ходит (конец цитаты).
«На безобразие, которое происходит с кооперативом, мы пишем жалобы во все инстанции, — говорит она. — Надеемся, новое руководство Министерства обороны поможет урегулировать ситуацию».
«Надежда, что все разрешится, остается — не может же все быть коррумпировано»
Елена Бойко — пайщик кооператива из Новосибирска и мать солдата, воющего в СВО, для которого она собиралась приобрести одну из двух квартир в кооперативе. «Я стала пайщиком кооператива в 2021 году. В январе 2021 года подала заявление на покупку двух квартир с помощью кооператива по накопительной программе. У меня двое детей — сын и дочь, им нужно жилье. В 2020 году взяли в ипотеку загородный дом — причем оформили на сына как единственного, кому ее могли одобрить, а в 2021 году он ушел в армию как призывник, а потом подписал контракт. Его относительно недавно отправили „за ленточку“. Думали, что поживем в ипотечном доме, и тут как раз подойдет очередь приобретать квартиры с помощью кооператива. Мы останемся жить в частном доме, а дети въедут в кооперативные квартиры».
«Ипотека — это разорительно, — подчеркивает Елена, — мы взяли 2,5 млн, а за 30 лет отдадим 6 млн. Когда появился кооператив, для нас это была возможность предоставить каждому из детей жилье: за 10 лет или раньше они расплатятся с кооперативом, причем с минимальной по сравнению ипотекой переплатой, и у них будет собственное жилье. Из-за репрессий в отношении кооператива мы можем быть этой возможности лишены».
«Я всем сердцем переживаю за ситуацию с кооперативом, заявление о выходе из кооператива пока не пишу — надеюсь, что его деятельность „разморозится“, — говорит Елена. — Обращаемся во все инстанции, в прокуратуру — приходят отписки. Смысл происходящего я понимаю хорошо — когда-то занималась кредитным потребительским кооперативом: нас тогда закрыл Центральный банк. Нашел формальный повод. Но настоящая причина была в том, что мы мешали банкам обирать клиентов. Но надежда на то, что все разрешится, остается — не может же быть все коррумпировано».
«Больше всего в нашей ситуации возмущает то, что наши воины стоят на стороне государства на фронте, а здесь, в тылу, их интересы нарушаются государственными структурами. Такого быть не должно!»
«Для многих кооператив — единственная возможность приобрести квартиру»
Лариса Зискинд — пайщица «Бест Вей», переехавшая с помощью кооператива с семьей — с дочерью, зятем и маленьким внуком - с Дальнего Востока в Белгородскую область. Ее зять, живущий в кооперативной квартире, находится на фронте СВО. «С помощью кооператива я приобрела квартиру в двухэтажном доме в селе Пушкарное Белгородской области — мы с дочерью переехали сюда. Мы уже два года расплачиваемся за него с кооперативом. Не до конца сделали ремонт, кухни фактически нет: моем посуду в ванной. Финансовых средств не хватает, так как зять уже год на СВО, пока ни разу не был в отпуске, и перевести деньги с его карты в ВТБ сейчас непросто, потому что карта — в расположении, до ближайшего банка ехать далеко, а он сам — на линии фронта. Мы фактически живем с выплат на ребенка, на мне кредиты — у меня полпенсии уходит на их оплату. Квартира по Росреестру находится под арестом, хотя арест по квартирам кооператива арест истек — а я боюсь ехать в Белгород, чтобы решать по ней вопрос. Я с ребенком на улицу гулять не выхожу в нынешней военной обстановке — сирены воздушной тревоги постоянные. Побыстрее бы наши войска создали санитарную зону в Харьковской области!»
По поводу покупки квартиры Лариса сообщает, что «ипотека точно никак не светила. Кооператив — это 14 тыс. в месяц и всего лишь 10 лет. В кооперативе даже студентка может приобрести квартиру, почти не переплачивая. При покупке через банк придется заплатить еще как минимум за одну квартиру».
«Среди пайщиков кооператива очень много пенсионеров, социально незащищенных людей, это была их единственная возможность приобрести квартиру, — говорит Лариса. — Из-за репрессий против кооператива мы можем лишиться единственного жилья. Мы куда только не писали в защиту кооператива. Но, видимо, слишком большой куш. Кооперативу не дают даже платить налоги. Надеемся, что отношение к кооперативу в результате справедливого разбирательства изменится в лучшую сторону».
«Мы очень устали. Но боремся»
Людмила Гарина — пайщица кооператива из Саратова, зять которой, проживающий вместе с ней в кооперативной квартире, участвует в СВО. «Я проживаю в кооперативной квартире почти три года вместе с дочерью и внуком, вносим ежемесячные платежи через госуслуги».
«Возможности взять ипотеку не было, — говорит Людмила. — Фактически у нас один работающий человек — дочь, зять мобилизован, внук — студент, внучке — четыре года. Мы с мужем пенсионеры».
«У нас с кооперативом проблем не было никаких, — говорит она, — но сейчас уверенности в завтрашнем дне нет. Пишем во все возможные инстанции, в том числе в Администрацию президента, ходили на прием к Володину. Пока ничего не помогает. Вся надежда на то, что суд разберется».
«Хотелось, чтобы вопрос о возобновлении работы кооператива быстрее решился, — говорит она, — тогда стало бы проще. Когда кооператив заработает, будет совершенно иная ситуация. Мы очень устали. Но боремся».
«20 тыс. пайщиков кооператива не так просто остановить»
Алла Яровая — пайщик кооператива из Пятигорска и представитель пайщицы Людмилы Дворцовой, сын которой, Игорь Дворцов, находился на СВО, а теперь служит внутри страны. «Людмила приобрела с помощью кооператива в Пятигорске квартиру для своего сына. Вступила в кооператив она в 2017 году, сначала находилась в накопительной программе — накапливала на первоначальный паевый взнос, накопила, потом стояла в очереди на приобретение жилье, приобрела с помощью кооператива однокомнатную квартиру за 1450 тыс. рублей. Потом приобрела квартиру и постепенно полностью за нее расплатилась. Работала для этого на двух работах, в том числе санитаркой в инфекционном отделении».
Но оформить квартиру в собственность не удалось, так как она оказалась под арестом, поясняет Алла. И хотя арест 19 февраля истек и больше не накладывался, суд первой инстанции в Пятигорске этот арест подтвердил. «По вопросу получения права собственности и снятия ареста мы обратились в Пятигорский городской суд, где судья очень предвзято отнесся к решению вопроса и мы получили отказ, — говорит Алла, — Хотя аналогичный вопрос рассматривался в Минераловодском суде и там судья вынесла положительное решение и в настоящий момент пайщик получил право собственности на свою квартиру. Предстоит рассмотрение в апелляционной инстанции — несмотря на то, что рассматривать нечего: ареста на недвижимость кооператива сейчас нет. А на квартиру Людмилы Дворцовой — почему-то есть».
«Кооператив — единственная возможность для людей со средним достатком получить жилье, — говорит Алла, — Нерешенный вопрос — налоги. Мы вынуждены платить налоги с юридических лиц, но мы же физические лица. К депутатам — с нас берут налог как с юрлица. Почему мы должны оплачивать — мы же физлица? Во многих регионах это сделано. Надеемся добиться того, чтобы это было сделано по всей стране».
«20 тыс. пайщиков кооператива не так просто остановить, — подчеркивает пайщица. — Это наши деньги, и мы за них боремся. Обязательно отстоим наш кооператив!»
«Активно участвую в защите кооператива»
У пайщицы кооператива, жительницы из Ленинградской области Татьяны Власенко старший сын находится на СВО с сентября 2022 года. «Три месяца проходил обучение, а потом оказался „за ленточкой“, — говорит Татьяна. — Мы должны были в конце лета 2022 года купить квартиру с помощью кооператива — квартиру планировали большую. Но работа кооператива оказалась заблокирована, и кооператив не может ничего купить уже более двух лет, так как и его счета, и его деятельность заблокированы. Деньги пайщиков, собранные для приобретения квартир, при этом обесцениваются».
«Я активно участвую в защите нашего кооператива, — говорит Татьяна. — Езжу на все суды в Санкт-Петербурге, хотя живу в деревне — ехать два с половиной, а то и три часа, мне 64 года, а путь неблизкий. И сын в этом поддерживает меня».
«Вот уже более двух лет работа кооператива заблокирована, деньги обесцениваются»
У пайщицы из Хабаровска Натальи Ромашко на СВО было два племянника — один, к сожалению, погиб. Планировалась покупка большой квартиры в Хабаровске, Наталья состояла в накопительной программе. «Вот уже более двух лет работа кооператива заблокирована, деньги обесцениваются, — говорит Наталья. — Я участвую в защите кооператива, пишу письма в прокуратуру, в высшие государственные инстанции, потому что нарушаются наши права, нас лишают возможности приобрести квартиру вне ипотечной системы. Пока приходят одни отписки, но борьбу мы продолжаем!»
«Ситуация — как на СВО»
Пайщица Светлана Иванова из Новосибирска, волонтер СВО, планировала приобрести с помощью кооператива две квартиры — для себя и для сына, который воюет на СВО добровольцем. «До этого я продала квартиру и сейчас вообще без собственного жилья, — говорит она. — Вступила в кооператив по накопительной программе, рассматривали для приобретения квартиры Крым и Новосибирск. В СВО участвую как волонтер — не остаюсь в стороне, когда Родине нужна помощь».
«От ситуации с кооперативом очень многие люди пострадали, — говорит Светлана. — Ситуация — как на СВО. И еще больше пострадают, если реализуется плохой сценарий. Хочется надеяться на то, что все образуется, правда восторжествует. Заявление о выходе из кооператива и возврате паевых средств я не подавала. Готова продолжить участие в нем, готова приобрести недвижимость с его помощью: это самый лучший вариант покупки квартиры».
«Сдаваться в планах нет»
Пайщица Марина Янковская родом из Хабаровска, она переехала в Новороссийск, ее супруг погиб на СВО. «У нас уже подходила очередь на покупку квартиры в Новороссийске для нашей семьи, мы должны были подбирать объект, — рассказывает она. — Но два года назад все остановилось. Хотели приобрести двухкомнатную квартиру в Новороссийске. Деньги лежат на арестованных счетах кооператива — а недвижимость за это время подорожала. Надеемся хоть что-то приобрести после того, как счета разблокируют».
«Мы всячески поддерживаем кооператив, — говорит Марина. — Записывали видео, что мы не обманутые, а вполне довольные пайщики, объясняли, что это никакая не пирамида, а организация, созданная в помощь людям. Ждем, когда снимут эти аресты. Сдаваться в планах нет».
NHL Best Bet: Dallas Stars to win in regulation -120 (play to -130) The Florida Panthers are legit. They have been the better hockey team for the majority of this Eastern Conference Final, but there’s one thing they don’t have that the New York Rangers do have, Igor Shesterkin. NHL picks wonder if goals will be fewer. Numbers are sliding little by little here, and that 6 for the Over Under still could have potential. Will this feel more like a playoff game than some of their series did last year? That is possible. Leading the MLS in points and goal differential, they aren’t likely to lose back to back games. Prediction: Panthers in 6 There are no predictions available for your chosen filters The free NHL consensus picks are a great tool to look for outliers everyday as to which NHL odds may present a betting tilt. Consensus Picks are a popular way to quickly check to see which picks are the most popular amongst the public. When there are tilts on the consensus picks of 70% or more, this is a strong indicator that Vegas may have a loose line and present exposure for the sports books. To beat the bookie betting on NHL with -110 odds a bettor has to win 52.38% of the time. For 2022, the NHL free consensus picks won 55.15% of the time, which is a modest return for NHL bettors and is a strong benchmark in the value of crowd sourced NHL picks.
http://psicolinguistica.letras.ufmg.br/wiki/index.php/Money_line_mcgregor_fight
Our daily soccer predictions include both teams to score (BTTS), over 1.5 goals, over 2.5 goals, under 3.5 goals, home win or draw (1x), away win or draw (X2), first-half goals, corners, and cards. All our soccer predictions are done by our professional tipster making use of our special algorithm to make sure that all our soccer predictions are accurate. Designed by : Vitek Solutions Our professional tipsters predict more than 90% accurate tips daily With the statistical tools used by Passionpredict to analyze historical performance, team form, player statistics, head-to-head records, weather conditions, injuries, and suspension news is one factor they are considered as the best football prediction site in the world. One way to improve your chances of winning is to follow expert bet tips. There are numerous websites and tipsters who provide valuable insights and predictions. However, it’s important to choose reliable and trustworthy sources. Look for experts with a proven track record and a transparent approach. Remember, while expert tips can be helpful, it’s essential to do your own research and make informed decisions.
Воины-пайщики оказались без защиты в тылу
Пайщики «Бест Вей» — участники СВО готовы защищать свой кооператив
ЖК Бествей
Многие пайщики кооператива «Бест Вей» и те, в чьих интересах приобретаются квартиры в кооперативе, — участники СВО. И они сами, и их родственники возмущены событиями, происходящими вокруг кооператива. Ведь защищая интересы страны на фронте, в тылу они не защищены от того, что не могут приобрести недвижимость из-за того, что счета кооператива с почти 4 млрд рублей уже более двух лет находятся под арестом — притом, что сумма ущерба по уголовному делу, рассматриваемому Приморским районным судом Санкт-Петербурга, согласно обвинительному заключению, составляет 282 млн рублей.
«Надеемся, новое руководство Министерства обороны поможет урегулировать ситуацию»
Наталья Пригаро, мать пайщика кооператива — участника СВО из Нефтеюганска Даниила Пригаро:
— Сын расплатился за однокомнатную квартиру, приобретенную с помощью кооператива, еще два года назад, подал пакет документов на оформление квартиры в собственность в Росреестр в начале сентября 2022 года — и все это время не может зарегистрировать собственность на нее из-за того, что в Росреестре она значится как арестованная. В конце сентября 2022 года он был мобилизован. Сын брал кредит, чтобы расплатиться за квартиру с кооперативом. Планировал продать эту квартиру и взять квартиру побольше в ипотеку. Однако неоднократно накладывался арест на недвижимость кооператива, несмотря на то что сейчас ареста нет — последний арест, накладывавшийся осенью 2023 года, 19 февраля истек, ходатайства о новом аресте дважды отклонены судом, по Росреестру арест с квартиры до сих пор не снят. В результате кредит приходится платить, квартира в собственность до сих пор не оформлена.
У сына нет никакой физической и финансовой возможности выяснять отношения с Росреестром — в административном или судебном порядке, он приезжает в отпуска на неделю-полторы, ему не до сутяжничества. Я нахожусь в Анапе, приобрела квартиру с помощью кооператива — сын не имеет возможности сделать на меня генеральную доверенность, а я не могу из Анапы приехать в Нефтеюганск и решать вопросы в Росреестре — кроме поезда, сейчас, сами понимаете, ничего не ходит (конец цитаты).
«На безобразие, которое происходит с кооперативом, мы пишем жалобы во все инстанции, — говорит она. — Надеемся, новое руководство Министерства обороны поможет урегулировать ситуацию».
«Надежда, что все разрешится, остается — не может же все быть коррумпировано»
Елена Бойко — пайщик кооператива из Новосибирска и мать солдата, воющего в СВО, для которого она собиралась приобрести одну из двух квартир в кооперативе. «Я стала пайщиком кооператива в 2021 году. В январе 2021 года подала заявление на покупку двух квартир с помощью кооператива по накопительной программе. У меня двое детей — сын и дочь, им нужно жилье. В 2020 году взяли в ипотеку загородный дом — причем оформили на сына как единственного, кому ее могли одобрить, а в 2021 году он ушел в армию как призывник, а потом подписал контракт. Его относительно недавно отправили „за ленточку“. Думали, что поживем в ипотечном доме, и тут как раз подойдет очередь приобретать квартиры с помощью кооператива. Мы останемся жить в частном доме, а дети въедут в кооперативные квартиры».
«Ипотека — это разорительно, — подчеркивает Елена, — мы взяли 2,5 млн, а за 30 лет отдадим 6 млн. Когда появился кооператив, для нас это была возможность предоставить каждому из детей жилье: за 10 лет или раньше они расплатятся с кооперативом, причем с минимальной по сравнению ипотекой переплатой, и у них будет собственное жилье. Из-за репрессий в отношении кооператива мы можем быть этой возможности лишены».
«Я всем сердцем переживаю за ситуацию с кооперативом, заявление о выходе из кооператива пока не пишу — надеюсь, что его деятельность „разморозится“, — говорит Елена. — Обращаемся во все инстанции, в прокуратуру — приходят отписки. Смысл происходящего я понимаю хорошо — когда-то занималась кредитным потребительским кооперативом: нас тогда закрыл Центральный банк. Нашел формальный повод. Но настоящая причина была в том, что мы мешали банкам обирать клиентов. Но надежда на то, что все разрешится, остается — не может же быть все коррумпировано».
«Больше всего в нашей ситуации возмущает то, что наши воины стоят на стороне государства на фронте, а здесь, в тылу, их интересы нарушаются государственными структурами. Такого быть не должно!»
«Для многих кооператив — единственная возможность приобрести квартиру»
Лариса Зискинд — пайщица «Бест Вей», переехавшая с помощью кооператива с семьей — с дочерью, зятем и маленьким внуком - с Дальнего Востока в Белгородскую область. Ее зять, живущий в кооперативной квартире, находится на фронте СВО. «С помощью кооператива я приобрела квартиру в двухэтажном доме в селе Пушкарное Белгородской области — мы с дочерью переехали сюда. Мы уже два года расплачиваемся за него с кооперативом. Не до конца сделали ремонт, кухни фактически нет: моем посуду в ванной. Финансовых средств не хватает, так как зять уже год на СВО, пока ни разу не был в отпуске, и перевести деньги с его карты в ВТБ сейчас непросто, потому что карта — в расположении, до ближайшего банка ехать далеко, а он сам — на линии фронта. Мы фактически живем с выплат на ребенка, на мне кредиты — у меня полпенсии уходит на их оплату. Квартира по Росреестру находится под арестом, хотя арест по квартирам кооператива арест истек — а я боюсь ехать в Белгород, чтобы решать по ней вопрос. Я с ребенком на улицу гулять не выхожу в нынешней военной обстановке — сирены воздушной тревоги постоянные. Побыстрее бы наши войска создали санитарную зону в Харьковской области!»
По поводу покупки квартиры Лариса сообщает, что «ипотека точно никак не светила. Кооператив — это 14 тыс. в месяц и всего лишь 10 лет. В кооперативе даже студентка может приобрести квартиру, почти не переплачивая. При покупке через банк придется заплатить еще как минимум за одну квартиру».
«Среди пайщиков кооператива очень много пенсионеров, социально незащищенных людей, это была их единственная возможность приобрести квартиру, — говорит Лариса. — Из-за репрессий против кооператива мы можем лишиться единственного жилья. Мы куда только не писали в защиту кооператива. Но, видимо, слишком большой куш. Кооперативу не дают даже платить налоги. Надеемся, что отношение к кооперативу в результате справедливого разбирательства изменится в лучшую сторону».
«Мы очень устали. Но боремся»
Людмила Гарина — пайщица кооператива из Саратова, зять которой, проживающий вместе с ней в кооперативной квартире, участвует в СВО. «Я проживаю в кооперативной квартире почти три года вместе с дочерью и внуком, вносим ежемесячные платежи через госуслуги».
«Возможности взять ипотеку не было, — говорит Людмила. — Фактически у нас один работающий человек — дочь, зять мобилизован, внук — студент, внучке — четыре года. Мы с мужем пенсионеры».
«У нас с кооперативом проблем не было никаких, — говорит она, — но сейчас уверенности в завтрашнем дне нет. Пишем во все возможные инстанции, в том числе в Администрацию президента, ходили на прием к Володину. Пока ничего не помогает. Вся надежда на то, что суд разберется».
«Хотелось, чтобы вопрос о возобновлении работы кооператива быстрее решился, — говорит она, — тогда стало бы проще. Когда кооператив заработает, будет совершенно иная ситуация. Мы очень устали. Но боремся».
«20 тыс. пайщиков кооператива не так просто остановить»
Алла Яровая — пайщик кооператива из Пятигорска и представитель пайщицы Людмилы Дворцовой, сын которой, Игорь Дворцов, находился на СВО, а теперь служит внутри страны. «Людмила приобрела с помощью кооператива в Пятигорске квартиру для своего сына. Вступила в кооператив она в 2017 году, сначала находилась в накопительной программе — накапливала на первоначальный паевый взнос, накопила, потом стояла в очереди на приобретение жилье, приобрела с помощью кооператива однокомнатную квартиру за 1450 тыс. рублей. Потом приобрела квартиру и постепенно полностью за нее расплатилась. Работала для этого на двух работах, в том числе санитаркой в инфекционном отделении».
Но оформить квартиру в собственность не удалось, так как она оказалась под арестом, поясняет Алла. И хотя арест 19 февраля истек и больше не накладывался, суд первой инстанции в Пятигорске этот арест подтвердил. «По вопросу получения права собственности и снятия ареста мы обратились в Пятигорский городской суд, где судья очень предвзято отнесся к решению вопроса и мы получили отказ, — говорит Алла, — Хотя аналогичный вопрос рассматривался в Минераловодском суде и там судья вынесла положительное решение и в настоящий момент пайщик получил право собственности на свою квартиру. Предстоит рассмотрение в апелляционной инстанции — несмотря на то, что рассматривать нечего: ареста на недвижимость кооператива сейчас нет. А на квартиру Людмилы Дворцовой — почему-то есть».
«Кооператив — единственная возможность для людей со средним достатком получить жилье, — говорит Алла, — Нерешенный вопрос — налоги. Мы вынуждены платить налоги с юридических лиц, но мы же физические лица. К депутатам — с нас берут налог как с юрлица. Почему мы должны оплачивать — мы же физлица? Во многих регионах это сделано. Надеемся добиться того, чтобы это было сделано по всей стране».
«20 тыс. пайщиков кооператива не так просто остановить, — подчеркивает пайщица. — Это наши деньги, и мы за них боремся. Обязательно отстоим наш кооператив!»
«Активно участвую в защите кооператива»
У пайщицы кооператива, жительницы из Ленинградской области Татьяны Власенко старший сын находится на СВО с сентября 2022 года. «Три месяца проходил обучение, а потом оказался „за ленточкой“, — говорит Татьяна. — Мы должны были в конце лета 2022 года купить квартиру с помощью кооператива — квартиру планировали большую. Но работа кооператива оказалась заблокирована, и кооператив не может ничего купить уже более двух лет, так как и его счета, и его деятельность заблокированы. Деньги пайщиков, собранные для приобретения квартир, при этом обесцениваются».
«Я активно участвую в защите нашего кооператива, — говорит Татьяна. — Езжу на все суды в Санкт-Петербурге, хотя живу в деревне — ехать два с половиной, а то и три часа, мне 64 года, а путь неблизкий. И сын в этом поддерживает меня».
«Вот уже более двух лет работа кооператива заблокирована, деньги обесцениваются»
У пайщицы из Хабаровска Натальи Ромашко на СВО было два племянника — один, к сожалению, погиб. Планировалась покупка большой квартиры в Хабаровске, Наталья состояла в накопительной программе. «Вот уже более двух лет работа кооператива заблокирована, деньги обесцениваются, — говорит Наталья. — Я участвую в защите кооператива, пишу письма в прокуратуру, в высшие государственные инстанции, потому что нарушаются наши права, нас лишают возможности приобрести квартиру вне ипотечной системы. Пока приходят одни отписки, но борьбу мы продолжаем!»
«Ситуация — как на СВО»
Пайщица Светлана Иванова из Новосибирска, волонтер СВО, планировала приобрести с помощью кооператива две квартиры — для себя и для сына, который воюет на СВО добровольцем. «До этого я продала квартиру и сейчас вообще без собственного жилья, — говорит она. — Вступила в кооператив по накопительной программе, рассматривали для приобретения квартиры Крым и Новосибирск. В СВО участвую как волонтер — не остаюсь в стороне, когда Родине нужна помощь».
«От ситуации с кооперативом очень многие люди пострадали, — говорит Светлана. — Ситуация — как на СВО. И еще больше пострадают, если реализуется плохой сценарий. Хочется надеяться на то, что все образуется, правда восторжествует. Заявление о выходе из кооператива и возврате паевых средств я не подавала. Готова продолжить участие в нем, готова приобрести недвижимость с его помощью: это самый лучший вариант покупки квартиры».
«Сдаваться в планах нет»
Пайщица Марина Янковская родом из Хабаровска, она переехала в Новороссийск, ее супруг погиб на СВО. «У нас уже подходила очередь на покупку квартиры в Новороссийске для нашей семьи, мы должны были подбирать объект, — рассказывает она. — Но два года назад все остановилось. Хотели приобрести двухкомнатную квартиру в Новороссийске. Деньги лежат на арестованных счетах кооператива — а недвижимость за это время подорожала. Надеемся хоть что-то приобрести после того, как счета разблокируют».
«Мы всячески поддерживаем кооператив, — говорит Марина. — Записывали видео, что мы не обманутые, а вполне довольные пайщики, объясняли, что это никакая не пирамида, а организация, созданная в помощь людям. Ждем, когда снимут эти аресты. Сдаваться в планах нет».
leflunomide 20mg without prescription – where to buy cartidin without a prescription purchase cartidin pills
Добрый день!
Заказать диплом ВУЗа
Мы предлагаем быстро и выгодно приобрести диплом, который выполняется на оригинальном бланке и заверен печатями, штампами, подписями официальных лиц. Наш диплом пройдет любые проверки, даже с использованием специальных приборов. Достигайте цели быстро с нашей компанией.
Где приобрести диплом специалиста?
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
Наш портал предлагает вам полную информацию на такие темы, как [url=https://54kovka.ru]аренда земли[/url] или [url=https://54kovka.ru]нотариальные услуги[/url].
Посетите наш сайт и начните свой путь к собственному жилью уже сегодня!
Всем привет! Может кто знает, где почитать полезные блоги о недвижимости? Пока нашел https://2204000.ru
1win тактика [url=https://1win.tr-kazakhstan.kz]https://1win.tr-kazakhstan.kz/[/url] отзывы казино 1win https://www.1win.tr-kazakhstan.kz
Узнайте стоимость диплома высшего и среднего образования и процесс получения
wow-tour.ru/vash-byistryiy-put-k-novomu-diplomu
buy wow carry raid kreativwerkstatt-esens.de .
кресло диван без подлокотников https://office-mebel-in-msk.ru/
Всем привет! Может кто знает, где почитать полезные статьи о недвижимости? Сейчас читаю https://eniseynev.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Пока нашел https://fuseitdecore.ru
spins queen 1win [url=https://1win.tr-kazakhstan.kz]https://1win.tr-kazakhstan.kz/[/url] aplicacion 1win https://1win.tr-kazakhstan.kz/
Всем привет! Подскажите, где найти разные статьи о недвижимости? Пока нашел https://galastroy-sk.ru
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://ggs45.ru
Покупка диплома о среднем полном образовании: как избежать мошенничества?
diplomyx24.ru/kupit-diplom-nizhnij-novgorod
купить диплом академии diplomyx.com .
купить диплом фармацевта в нижнем тагиле asxdiplomik.com .
Привет!
Где купить диплом по необходимой специальности?
Наша компания предлагает выгодно заказать диплом, который выполнен на бланке ГОЗНАКа и заверен мокрыми печатями, штампами, подписями должностных лиц. Данный диплом пройдет любые проверки, даже с применением специфических приборов. Решайте свои задачи быстро и просто с нашим сервисом.
Заказать диплом ВУЗа.
flerus-shop.hcp.dilhost.ru/club/user/3/forum/message/880/876/
фальшивые дипломы купить ast-diploms.com .
аттестат о среднем образовании купить аттестат о среднем образовании купить .
Приветствую. Подскажите, где найти разные блоги о недвижимости? Пока нашел https://glwin.ru
Привет, друзья!
Мы можем предложить документы техникумов, расположенных в любом регионе Российской Федерации. Вы можете заказать качественный диплом за любой год, указав необходимую специальность и оценки за все дисциплины. Документы выпускаются на “правильной” бумаге высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригиналов. Документы заверяются необходимыми печатями и подписями.
Приобрести диплом о высшем образовании.
forum.accent-club.ru/index.php?autocom=blog&blogid=1202&showentry=35686
Удачи!
Военный адвокат Запорожье. Бесплатная консультация
адвокат по мобилизации Запорожье
— это опытный специалист имеющий высшее юридическое образование, сдавший квалификационный государственный экзамен на право осуществления адвокатской деятельностью и специализирующийся в основном на военных делах
Вся правовая помощь военного адвоката осуществляется в индивидуальном порядке, грамотно, четко и в соответствии с действующими нормативно-правовыми актами.
Мы как военные юристы действуем не против органов Украины или министерства обороны, мы действуем во благо Украины — наших защитников и граждан Украины, которые попали в тяжелую жизненную ситуацию связанную с незнанием военного и действующего законодательства.
Поскольку, проявив патриотизм и чувство гражданской ответственности – став на защиту суверенитета страны, граждане участвующие и помогавшие в обороне после, становятся никому не нужными, особенно если военнослужащий стал инвалидом, потерял часть тела или конечность, и не может самостоятельно защитить свои права. Именно в таких ситуациях мы как военные адвокаты приходим на помощь, и добиваемся в установленном законом порядке справедливости, необходимых выплат, установление статуса, оформление пенсий, льгот и т.п.
Тоже касается, и получение отсрочки от мобилизации, когда например, безосновательно призывают сына у которого отец инвалид 2 группы, или мать прикованная из-за тяжелой болезни к постели, и требующая постороннего ухода. Это же относится и к военнослужащим, рапорта которых не регистрируются в канцелярии воинской части и полностью игнорируются, под прикрытием суеты боевых действий..
Именно в таких ситуациях, мы приходим на помощь и с помощью ЗАКОННЫХ методов правовой защиты, используя свой опыт полученный при ведении аналогичных военных дел добиваемся справедливости.
купить справку о болезни
Приветствую. Подскажите, где найти разные статьи о недвижимости? Сейчас читаю https://gor-bur.ru
Здравствуйте!
Мы изготавливаем дипломы любой профессии по приятным ценам. Цена может зависеть от выбранной специальности, года получения и ВУЗа.
Где купить диплом специалиста?
Приобрести диплом университета
arusak-diploms-srednee.ru/kupit-attestat-za-11-klass
Успешной учебы!
Привет!
Где заказать диплом специалиста?
Купить диплом любого ВУЗа.
politictoday.ru/vash-shans-na-uspeh-diplom-bez-truda
сделать справку
Добрый день!
Мы предлагаем документы ВУЗов, расположенных в любом регионе РФ. Можно приобрести диплом от любого учебного заведения, за любой год, указав актуальную специальность и хорошие оценки за все дисциплины. Дипломы и аттестаты делаются на “правильной” бумаге самого высшего качества. Это позволяет делать государственные дипломы, не отличимые от оригинала. Документы будут заверены всеми необходимыми печатями и подписями.
jasonscottmedicalsolutions.com/product-category/darvocet-n-tablet
Удивительно, но купить диплом кандидата наук оказалось не так сложно
diploms-x.com/kupit-diplom-magistra
Привет, друзья!
Где купить диплом специалиста?
Мы предлагаем документы ВУЗов, расположенных в любом регионе РФ. Можно купить качественно сделанный диплом за любой год, включая документы СССР. Дипломы выпускаются на “правильной” бумаге высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригинала. Они заверяются необходимыми печатями и штампами.
Мы изготавливаем дипломы любых профессий по доступным тарифам.
ast-diplomas.com/kupit-diplom-ekaterinbur
Окажем помощь!
купить дипломы техникума цена московская область asxdiplomik24.ru .
Добрый день!
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
angelladydety.getbb.ru/viewtopic.php?f=46&t=38576
Поможем вам всегда!.
дипломы о высшем образовании купить дипломы о высшем образовании купить .
купить диплом повара цена diplomasx.com .
диплом азбуку прочел купить ast-diploms.com .
Привет, друзья!
Где купить диплом по актуальной специальности?
Мы готовы предложить дипломы любой профессии по невысоким ценам.
http://www.sshcongregation.org/fullnews?sn=76
Здравствуйте!
Быстрое обучение и получение диплома магистра – возможно ли это?
ekspoteh.ru/index.php?name=account&op=info&uname=yjocowif
Рады оказаться полезными!.
Привет!
Приобрести диплом о высшем образовании.
stalinarch.ru/wiki/index.php/??????_??????_?_??????:_??????????_??????
Удачи!
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Сейчас читаю https://hameleon1.ru
Добрый день!
Официальная покупка диплома ВУЗа с упрощенной программой обучения
ks4yumuo.listbb.ru/viewtopic.php?f=18&t=679
Рады оказать помощь!.
[u][b] Здравствуйте![/b][/u]
[b]Мы можем предложить документы техникумов,[/b] расположенных в любом регионе РФ. Вы сможете заказать качественный диплом за любой год, указав необходимую специальность и оценки за все дисциплины. Дипломы и аттестаты выпускаются на “правильной” бумаге самого высокого качества. Это дает возможность делать государственные дипломы, которые не отличить от оригинала. Они заверяются необходимыми печатями и подписями.
[url=http://domstroy18.ru/chameleon]domstroy18.ru/chameleon[/url]
[u][b] Привет, друзья![/b][/u]
Где приобрести диплом специалиста?
Мы готовы предложить документы институтов, которые находятся в любом регионе РФ. Вы можете приобрести диплом от любого ВУЗа, за любой год, указав подходящую специальность и хорошие оценки за все дисциплины. Дипломы выпускаются на бумаге высшего качества. Это дает возможность делать государственные дипломы, не отличимые от оригинала. Они будут заверены необходимыми печатями и подписями.
[b]Мы изготавливаем дипломы[/b] любых профессий по доступным ценам.
[url=http://ast-diplomas24.ru/kupit-diplom-o-srednem-obrazovanii]ast-diplomas24.ru/kupit-diplom-o-srednem-obrazovanii[/url]
[u][b] Окажем помощь![u][b]
[u][b] Привет, друзья![/b][/u]
[b]Мы предлагаем заказать диплом[/b] отличного качества, неотличимый от оригинального документа без участия специалиста высокой квалификации со специальным оборудованием.
[url=http://intextv.by/forum/user/63239//]intextv.by/forum/user/63239/[/url]
[b]Успешной учебы![/b]
[u][b] Добрый день![/b][/u]
Где заказать диплом по нужной специальности?
[url=http://www.anytalkworld.com/create-blog//]www.anytalkworld.com/create-blog/[/url]
[b]Успешной учебы![/b]
[u][b] Привет![/b][/u]
[b]Наши специалисты предлагают[/b] максимально быстро заказать диплом, который выполняется на оригинальной бумаге и заверен мокрыми печатями, водяными знаками, подписями должностных лиц. Диплом способен пройти лубую проверку, даже при использовании специального оборудования. Решайте свои задачи быстро с нашим сервисом.
[url=http://sibstroyagent.ru/index.php?subaction=userinfo&user=edyviluqe/]sibstroyagent.ru/index.php?subaction=userinfo&user=edyviluqe[/url]
[b]Удачи![/b]
Всем привет! Подскажите, где найти полезные статьи о недвижимости? Сейчас читаю https://juzhnybereg24.ru
Привет!
Где купить диплом по необходимой специальности?
Мы предлагаем дипломы любых профессий по приятным тарифам.
tudiencongnghe.com/author/binguyenth/
Привет!
Возможно ли купить диплом стоматолога, и как это происходит
himagro.md/forum/user/40722/
Будем рады вам помочь!.
order tenormin 50mg for sale – order coreg generic order coreg 6.25mg online cheap
Привет!
Заказать документ университета можно в нашей компании в Москве.
ast-diploms.com/kupit-diplom-ekaterinbur
купить диплом асоу diplomyx.com .
купить диплом в прокопьевске asxdiplomik.com .
Добрый день!
Приобрести документ о получении высшего образования вы сможете в нашей компании.
asxdiplomik24.ru/kupit-diplom-krasnoyarsk
Хорошей учебы!
Привет!
Наша компания предлагает заказать диплом в отличном качестве, который не отличить от оригинального документа без использования специального оборудования и опытного специалиста.
ad-vance.ru/communication/forum/user/40075/
Успешной учебы!
Привет, друзья!
Заказать диплом любого университета.
Мы готовы предложить документы техникумов, которые расположены в любом регионе Российской Федерации. Вы можете приобрести диплом от любого заведения, за любой год, указав актуальную специальность и оценки за все дисциплины. Документы печатаются на “правильной” бумаге высшего качества. Это дает возможность делать государственные дипломы, не отличимые от оригиналов. Документы заверяются необходимыми печатями и штампами.
ebuddiz.com//read-blog/24664
Здравствуйте!
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
http://www.paladiny.ru/forummess.dwar.php?TopicID=27610
Всегда вам поможем!.
Привет, друзья!
Мы готовы предложить дипломы любой профессии по приятным тарифам. Цена зависит от определенной специальности, года выпуска и образовательного учреждения.
arusak-diploms-srednee.ru/kupit-diplom-medicinskogo-uchilishha
Хорошей учебы!
Приветствую. Может кто знает, где найти разные статьи о недвижимости? Пока нашел https://kolahouse.ru
Привет, друзья!
Как приобрести аттестат о среднем образовании в Москве и других городах
injectorcar.ru/forum/member.php?u=34916
Всегда вам поможем!.
Всем привет! Может кто знает, где почитатьразные статьи о недвижимости? Сейчас читаю https://sm70.ru
Новинки Бреста а также Брестской района а также мире, исключительно оперативная экспресс-информация: вопроса дня, обзоры, крайние несчастного случая а также действия города, сообщения о АВАРИЯ
https://elnet.by/
머니 트레인2
Zhu Houzhao는 그의 영리함을 매우 자랑스러워하는 것 같습니다.
покупка диплома покупка диплома .
купить диплом в мичуринске diplomyx.com .
Российский ярмарка ранее не известных каров демонстрирует разнонаправленную динамику цен. Одни модели значительно упали в цене, в течение то время как часть, наоборот
https://avgrodno.by/
Приветствую. Может кто знает, где найти полезные блоги о недвижимости? Сейчас читаю https://konditsioneri-shop.ru
ГК Айтек http://www.multimedijnyj-integrator.ru .
Привет!
Купить документ института вы сможете в нашем сервисе.
diplomasx24.ru/kupit-diplom-rostov-na-donu
Успехов в учебе!
vid-st.ru vid-st.ru .
Здравствуйте!
Приобрести документ университета можно в нашем сервисе.
ast-diplom24.ru/otzyvy
Удачи!
Привет, друзья!
Мы можем предложить документы техникумов, которые расположены на территории всей РФ. Можно купить диплом от любого заведения, за любой год, включая сюда документы СССР. Документы выпускаются на бумаге высшего качества. Это позволяет делать государственные дипломы, которые не отличить от оригиналов. Они заверяются всеми обязательными печатями и подписями.
octomo.co.uk/read-blog/949
Как получить диплом техникума с упрощенным обучением в Москве официально
prikol100500.ru/ofitsialnyie-diplomyi-dostupno-i-legalno
Привет!
Полезная информация как официально купить диплом о высшем образовании
landik-diploms-srednee.ru/kupit-diplom-v-voronezhe
Успехов в учебе!
Привет!
Парадокс, но купить диплом кандидата наук оказалось не так и сложно
bryansk32-forum.ru/ucp.php?mode=login
Рады оказаться полезными!.
Привет, друзья!
Где заказать диплом специалиста?
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по разумным тарифам. Стоимость зависит от определенной специальности, года получения и образовательного учреждения. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы дипломы были доступными для большого количества наших граждан.
arusak-diploms-srednee.ru/kupit-diplom-v-cheliabinske
Успешной учебы!
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
diplomasx.com/kupit-diplom-krasnoyarsk
Добрый день!
Заказать документ ВУЗа вы сможете в нашей компании.
diplomyx24.ru/kupit-diplom-o-srednem-obrazovanii
accutane pills price in south africa
Привет!
Купить документ института вы сможете в нашей компании в столице.
asxdiplomik24.ru/kupit-diplom-sankt-peterburg
купить диплом о полном среднем ast-diploms.com .
Привет!
Где купить диплом по необходимой специальности?
Мы предлагаем дипломы любых профессий по выгодным тарифам. Цена будет зависеть от выбранной специальности, года выпуска и образовательного учреждения. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступными для большого количества наших граждан.
Для вас готовы предложить дипломы любой профессии по приятным тарифам.
mybuildhouse.ru/kupit-diplom-rf-v-moskve-garantiya-legalnosti-i-kachestva/
Рады помочь!.
Привет, друзья!
Предлагаем документы техникумов, которые расположены на территории всей РФ. Вы сможете приобрести диплом от любого заведения, за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Документы выпускаются на “правильной” бумаге высшего качества. Это дает возможности делать настоящие дипломы, которые невозможно отличить от оригиналов. Документы заверяются всеми обязательными печатями и штампами.
Мы изготавливаем дипломы любой профессии по доступным ценам. Стоимость будет зависеть от выбранной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступными для большого количества наших граждан.
arusak-diploms-srednee.ru/kupit-diplom-v-nizhnem-novgorode
Успешной учебы!
Добрый день!
Где приобрести диплом специалиста?
Мы можем предложить документы институтов, расположенных в любом регионе РФ. Можно приобрести качественно сделанный диплом за любой год, включая документы старого образца СССР. Дипломы печатаются на “правильной” бумаге самого высокого качества. Это позволяет делать настоящие дипломы, которые не отличить от оригиналов. Документы будут заверены всеми требуемыми печатями и подписями.
Мы предлагаем дипломы психологов, юристов, экономистов и любых других профессий по доступным ценам.
diploms-x24.ru/kupit-diplom-nizhnij-novgorod
Будем рады вам помочь!
навесы из металлочерепицы
Добрый день!
Наши специалисты предлагают выгодно заказать диплом, который выполнен на бланке ГОЗНАКа и заверен печатями, штампами, подписями должностных лиц. Документ пройдет любые проверки, даже с применением специально предназначенного оборудования. Достигайте свои цели быстро и просто с нашими дипломами.
dvnshu.com/index.php?subaction=userinfo&user=uwalu
Успешной учебы!
Приветствую. Может кто знает, где почитать полезные блоги о недвижимости? Сейчас читаю [url=https://design-lis.ru]блог о недвижимости[/url]
купить диплом в нефтекамске asxdiplomik24.ru .
Привет!
Как избежать рисков при покупке диплома колледжа или ПТУ в России
vtik.net/index.php?subaction=userinfo&user=imexi
Рады оказать помощь!.
Привет!
Мы предлагаем документы техникумов, которые расположены в любом регионе Российской Федерации. Вы сможете заказать качественно напечатанный диплом от любого учебного заведения, за любой год, указав подходящую специальность и оценки за все дисциплины. Дипломы и аттестаты печатаются на “правильной” бумаге высшего качества. Это дает возможность делать настоящие дипломы, которые невозможно отличить от оригиналов. Документы будут заверены всеми требуемыми печатями и штампами.
networksbusiness.mn.co/posts/61837761
Привет!
Купить диплом любого университета.
rogerfilms.com/index.php?title=??????_??????:_???_????????????_????_?_??????
Успешной учебы!
Военный адвокат Запорожье. Бесплатная консультация
адвокат по влк Запорожье
— это опытный специалист имеющий высшее юридическое образование, сдавший квалификационный государственный экзамен на право осуществления адвокатской деятельностью и специализирующийся в основном на военных делах
Вся правовая помощь военного адвоката осуществляется в индивидуальном порядке, грамотно, четко и в соответствии с действующими нормативно-правовыми актами.
Мы как военные юристы действуем не против органов Украины или министерства обороны, мы действуем во благо Украины — наших защитников и граждан Украины, которые попали в тяжелую жизненную ситуацию связанную с незнанием военного и действующего законодательства.
Поскольку, проявив патриотизм и чувство гражданской ответственности – став на защиту суверенитета страны, граждане участвующие и помогавшие в обороне после, становятся никому не нужными, особенно если военнослужащий стал инвалидом, потерял часть тела или конечность, и не может самостоятельно защитить свои права. Именно в таких ситуациях мы как военные адвокаты приходим на помощь, и добиваемся в установленном законом порядке справедливости, необходимых выплат, установление статуса, оформление пенсий, льгот и т.п.
Тоже касается, и получение отсрочки от мобилизации, когда например, безосновательно призывают сына у которого отец инвалид 2 группы, или мать прикованная из-за тяжелой болезни к постели, и требующая постороннего ухода. Это же относится и к военнослужащим, рапорта которых не регистрируются в канцелярии воинской части и полностью игнорируются, под прикрытием суеты боевых действий..
Именно в таких ситуациях, мы приходим на помощь и с помощью ЗАКОННЫХ методов правовой защиты, используя свой опыт полученный при ведении аналогичных военных дел добиваемся справедливости.
Привет!
Где приобрести диплом по нужной специальности?
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по выгодным ценам. Стоимость может зависеть от выбранной специальности, года выпуска и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную политику цен. Для нас очень важно, чтобы дипломы были доступны для большого количества наших граждан.
Для вас готовы предложить дипломы любых профессий по приятным тарифам.
raceburo.ru/kupit-nastoyashhiy-diplom-rf-v-moskve-ofitsialnoe-oformlenie
Всегда вам поможем!.
диплом фармацевта с занесением в реестр диплом фармацевта с занесением в реестр .
купить диплом пту в красноярске ast-diploms.com .
можно ли купить диплом айтишника в ставрополе diplomasx.com .
Здравствуйте!
Мы изготавливаем дипломы любой профессии по приятным тарифам. Стоимость будет зависеть от конкретной специальности, года выпуска и университета. Стараемся поддерживать для клиентов адекватную политику цен. Важно, чтобы дипломы были доступными для большого количества наших граждан.
communityofbabel.com/en/forums/discussion/egyptian-culture/kupit-diplom-goznak-l985n
Hướng Dẫn RGBET Casino: Tải App Nhận Khuyến Mãi Khủng
Trang game giải trí RGBET hỗ trợ tất cả các thiết bị di động, cho phép bạn đặt cược trên điện thoại mọi lúc mọi nơi. RGBET cung cấp hàng ngàn trò chơi đa dạng và phổ biến trên toàn cầu, từ các sự kiện thể thao, thể thao điện tử, casino trực tuyến, đến đặt cược xổ số và slot quay.
Quét Mã QR và Tải Ngay
Để trải nghiệm RGBET phiên bản di động, hãy quét mã QR có sẵn trên trang web chính thức của RGBET và tải ứng dụng về thiết bị của bạn. Ứng dụng RGBET không chỉ cung cấp trải nghiệm cá cược mượt mà mà còn đi kèm với nhiều khuyến mãi hấp dẫn.
Nạp Tiền Nhà Cái
Đăng nhập hoặc Đăng ký
Đăng nhập vào tài khoản RGBET của bạn. Nếu chưa có tài khoản, bạn cần đăng ký một tài khoản mới.
Chọn Phương Thức Nạp
Sau khi đăng nhập, chọn mục “Nạp tiền”.
Chọn phương thức nạp tiền mà bạn muốn sử dụng (ngân hàng, momo, thẻ cào điện thoại).
Điền Số Tiền và Xác Nhận
Điền số tiền cần nạp vào tài khoản của bạn.
Bấm xác nhận để hoàn tất giao dịch nạp tiền.
Rút Tiền Từ RGBET
Đăng nhập vào Tài Khoản
Đăng nhập vào tài khoản RGBET của bạn.
Chọn Giao Dịch
Chọn mục “Giao dịch”.
Chọn “Rút tiền”.
Nhập Số Tiền và Xác Nhận
Nhập số tiền bạn muốn rút từ tài khoản của mình.
Bấm xác nhận để hoàn tất giao dịch rút tiền.
Trải Nghiệm và Nhận Khuyến Mãi
RGBET luôn mang đến cho người chơi những trải nghiệm tuyệt vời cùng với nhiều khuyến mãi hấp dẫn. Đừng bỏ lỡ cơ hội tham gia và nhận các ưu đãi khủng từ RGBET ngay hôm nay.
Bằng cách tải ứng dụng RGBET, bạn không chỉ có thể đặt cược mọi lúc mọi nơi mà còn có thể tận hưởng các trò chơi và dịch vụ tốt nhất từ RGBET. Hãy làm theo hướng dẫn trên để bắt đầu trải nghiệm cá cược trực tuyến tuyệt vời cùng RGBET!
Добрый день!
Где приобрести диплом специалиста?
Мы можем предложить документы институтов, расположенных на территории всей России. Вы можете заказать качественный диплом за любой год, указав подходящую специальность и хорошие оценки за все дисциплины. Дипломы выпускаются на бумаге высшего качества. Это позволяет делать государственные дипломы, которые невозможно отличить от оригиналов. Они заверяются необходимыми печатями и штампами.
Мы готовы предложить дипломы любой профессии по доступным ценам.
ast-diploms24.ru/kupit-diplom-krasnoyarsk
Всегда вам поможем!
Добрый день!
Наш сервис предлагает купить диплом высокого качества, который не отличить от оригинала без участия специалистов высокой квалификации с дорогостоящим оборудованием.
e-matreshka.com/forum/messages/forum1/topic17/message833/?result=reply#message833
Удачи!
Привет, друзья!
Ьожем предложить документы техникумов, которые находятся на территории всей России. Можно приобрести качественно сделанный диплом за любой год, включая сюда документы СССР. Документы делаются на “правильной” бумаге высшего качества. Это дает возможности делать государственные дипломы, которые невозможно отличить от оригинала. Они заверяются всеми обязательными печатями и штампами.
Мы предлагаем дипломы любой профессии по приятным тарифам. Стоимость будет зависеть от выбранной специальности, года выпуска и университета. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступны для большого количества наших граждан.
landik-diploms-srednee.ru/kupit-diplom-volgograd
Удачи!
Здравствуйте!
Заказать документ университета можно в нашей компании.
ast-diplom.com/kupit-diplom-moskva
Успешной учебы!
стоимость видеостены стоимость видеостены .
Здравствуйте!
Диплом вуза купить официально с упрощенным обучением в Москве
http://www.brodyaga.org/club/user/110627/blog/6166
Рады оказать помощь!.
synthroid 125 mcg price
Привет, друзья!
Ьожем предложить документы техникумов, расположенных в любом регионе Российской Федерации. Можно приобрести качественный диплом от любого учебного заведения, за любой год, включая сюда документы СССР. Дипломы и аттестаты печатаются на “правильной” бумаге самого высокого качества. Это дает возможности делать государственные дипломы, которые не отличить от оригиналов. Документы будут заверены всеми обязательными печатями и штампами.
Мы изготавливаем дипломы любой профессии по приятным ценам. Стоимость будет зависеть от выбранной специальности, года выпуска и университета. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы дипломы были доступны для большого количества граждан.
arusak-diploms-srednee.ru/kupit-diplom-v-krasnoiarske
Успешной учебы!
Привет!
Приобрести документ о получении высшего образования можно в нашей компании в Москве.
diplomasx.com/kupit-diplom-omsk
Успехов в учебе!
Здравствуйте!
Как приобрести аттестат о среднем образовании в Москве и других городах
ремонт-оптом.рф/club/user/17/blog
Будем рады вам помочь!.
Привет!
Где приобрести диплом специалиста?
Купить диплом любого университета.
anamaliya.ru/otzyvy/shirokiy-assortiment-dokumentov-v-populyarnom-onlayn-magazine
Добрый день!
Приобрести документ о получении высшего образования можно в нашей компании.
ast-diplomy24.ru/kupit-diplom-magistra
Привет!
Заказать документ ВУЗа можно в нашей компании в столице.
ast-diplom.com/kupit-diplom-o-srednem-obrazovanii
Хорошей учебы!
Привет, друзья!
Мы предлагаем купить диплом отличного качества, неотличимый от оригинального документа без участия специалиста высокой квалификации со сложным оборудованием.
findaspermdonor.com/viewtopic.php?f=2&t=80886&p=78159#p78159
Успехов в учебе!
Здравствуйте!
Где и как купить диплом о высшем образовании без лишних рисков
machineintelligence.mn.co/posts/62004656
Будем рады вам помочь!.
Привет!
Мы изготавливаем дипломы любых профессий по невысоким ценам. Цена будет зависеть от выбранной специальности, года получения и образовательного учреждения. Стараемся поддерживать для клиентов адекватную политику тарифов. Важно, чтобы документы были доступными для подавляющей массы наших граждан.
gadjetforyou.ru/uspeshnoe-zavershenie-obrazovaniya-kupite-diplom-segodnya
Привет, друзья!
Где купить диплом специалиста?
Мы предлагаем документы ВУЗов, которые расположены на территории всей Российской Федерации. Можно заказать диплом от любого ВУЗа, за любой год, включая сюда документы СССР. Дипломы печатаются на “правильной” бумаге самого высшего качества. Это позволяет делать государственные дипломы, которые не отличить от оригиналов. Документы заверяются необходимыми печатями и подписями.
Мы изготавливаем дипломы любой профессии по доступным ценам.
diploms-x.com/kupit-diplom-o-srednem-obrazovanii
Будем рады вам помочь!
Добрый день!
Заказать документ о получении высшего образования вы имеете возможность у нас.
ast-diplomas.com/kupit-diplom-magistra
Привет!
Приобрести документ о получении высшего образования можно в нашей компании в столице.
asxdiplomik24.ru/kupit-diplom-sankt-peterburg
Успехов в учебе!
Привет!
Ьожем предложить документы ВУЗов, которые расположены на территории всей Российской Федерации. Вы сможете приобрести качественно сделанный диплом от любого заведения, за любой год, в том числе документы СССР. Дипломы и аттестаты печатаются на бумаге самого высшего качества. Это позволяет делать настоящие дипломы, не отличимые от оригинала. Документы будут заверены необходимыми печатями и штампами.
Мы изготавливаем дипломы любых профессий по приятным тарифам. Стоимость будет зависеть от выбранной специальности, года получения и университета. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступны для большого количества наших граждан.
arusak-diploms-srednee.ru/kupit-diplom-v-cheliabinske В
Успешной учебы!
Привет!
Официальное получение диплома техникума с упрощенным обучением в Москве
vatrusha.maxbb.ru/viewtopic.php?f=2&t=691
Рады оказать помощь!.
[url=https://xmodafinil.com/]provigil online pharmacy uk[/url]
Привет, друзья!
Приобрести диплом любого ВУЗа
Мы можем предложить документы ВУЗов, расположенных в любом регионе РФ. Вы имеете возможность купить диплом от любого заведения, за любой год, в том числе документы СССР. Дипломы и аттестаты выпускаются на “правильной” бумаге самого высокого качества. Это позволяет делать настоящие дипломы, не отличимые от оригиналов. Документы будут заверены необходимыми печатями и штампами.
http://www.marqueze.net/miembros/billyoung/profile/classic/
Рады оказать помощь!.
Здравствуйте!
Полезные советы по безопасной покупке диплома о высшем образовании
epidemics.ru/index.php?subaction=userinfo&user=okezaju
Рады оказаться полезными!.
Привет!
Приобрести диплом о высшем образовании.
antimoderator.mybb.ru/viewtopic.php?id=372#p443
Успешной учебы!
[u][b] Добрый день![/b][/u]
[b]Мы предлагаем купить диплом[/b] высочайшего качества, неотличимый от оригинального документа без участия специалиста высокой квалификации с дорогим оборудованием.
[url=http://www.tdp74.ru/forum/messages/forum1/topic96/message47436/?result=reply#message47436/]www.tdp74.ru/forum/messages/forum1/topic96/message47436/?result=reply#message47436[/url]
[b]Успехов в учебе![/b]
Привет!
Наши специалисты предлагают выгодно купить диплом, который выполнен на оригинальном бланке и заверен печатями, штампами, подписями официальных лиц. Диплом пройдет любые проверки, даже при использовании специального оборудования. Достигайте своих целей максимально быстро с нашими дипломами.
1abakan.ru/forum/showthread-185970/
Успешной учебы!
ремонт MacBook
india pharmacy indian pharmacy best india pharmacy
Привет, друзья!
Заказать документ университета можно в нашей компании в Москве.
ast-diplom24.ru/otzyvy
Удачи!
Привет, друзья!
Мы можем предложить дипломы любой профессии по приятным ценам.
newsbizlife.ru/kupit-diplom-vyisokoe-kachestvo-i-nadezhnost
Добрый день!
Ьожем предложить документы техникумов, которые находятся на территории всей России. Можно купить диплом от любого учебного заведения, за любой год, в том числе документы старого образца. Документы печатаются на “правильной” бумаге самого высшего качества. Это дает возможность делать настоящие дипломы, которые не отличить от оригинала. Документы заверяются необходимыми печатями и подписями.
Мы можем предложить дипломы психологов, юристов, экономистов и других профессий по доступным тарифам. Стоимость зависит от той или иной специальности, года выпуска и образовательного учреждения. Стараемся поддерживать для клиентов адекватную политику тарифов. Для нас важно, чтобы документы были доступными для большого количества граждан.
landik-diploms-srednee.ru/svidetelstvo-o-razvode В
Успехов в учебе!
Здравствуйте!
Приобрести диплом ВУЗа
landik-diploms-srednee.ru/svidetelstvo-o-rozhdenii В
Удачи!
Привет!
Приобрести документ о получении высшего образования вы сможете в нашей компании в столице.
ast-diplomy24.ru/kupit-diplom-vracha
Успешной учебы!
canada rx pharmacy: canadian pharmacy king – reliable canadian online pharmacy
Здравствуйте!
Мы готовы предложить документы техникумов, расположенных в любом регионе РФ. Можно приобрести диплом от любого учебного заведения, за любой год, включая сюда документы старого образца. Документы печатаются на “правильной” бумаге самого высшего качества. Это дает возможности делать настоящие дипломы, не отличимые от оригинала. Они заверяются всеми обязательными печатями и штампами.
http://www.indianhighcaste.com/read-blog/2120
Привет!
Купить диплом любого ВУЗа
arusak-diploms-srednee.ru/kupit-diplom-v-rostove-na-donu В
Хорошей учебы!
best online pharmacy india buy prescription drugs from india pharmacy website india
Добрый день!
Приобрести документ о получении высшего образования вы сможете в нашей компании в столице.
ast-diplomy24.ru/kupit-diplom-magistra
Привет!
Приобрести документ о получении высшего образования можно в нашей компании в Москве.
diplomasx.com/kupit-diplom-sankt-peterburg
vacancies in Israel
4israel (פורישראל) is a free message board in Israel, where visitors can publish and look for any information. We help users find everything they seek for life and promotion of business in Israel. You can find proposals for real estate, products, services, cars, sales announcements, work search, educational institutions and much more. Our site is the most popular languages in Israel, such as Hebrew, English, Russian and Arabic.
Привет!
Где заказать диплом по нужной специальности?
Приобрести диплом о высшем образовании.
getdlight.com/en/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=143
canadian drugs pharmacy: legal canadian pharmacy online – global pharmacy canada
Добрый день!
Мы предлагаем дипломы любой профессии по доступным ценам.
onetable.world/read-blog/59803
Здравствуйте!
Заказать документ о получении высшего образования вы сможете в нашем сервисе.
asxdiplomik24.ru/kupit-diplom-magistra
Успешной учебы!
магазин аккаунтов игр магазин аккаунтов игр .
Online medicine order: india pharmacy mail order – buy medicines online in india
Здравствуйте!
Вопросы и ответы: можно ли быстро купить диплом старого образца?
topnewsgadget.ru/diplom-dlya-uspeshnoy-kareryi-dostupno-kazhdomu
Окажем помощь!.
Здравствуйте!
Заказать документ института вы имеете возможность в нашей компании в Москве.
diplomasx24.ru/kupit-diplom-krasnoyarsk
Удачи!
купить диплом о высшем образовании дешево ast-diploms.com .
ремонт мобильных телефонов в москве рядом
buy generic gasex online – order ashwagandha pill diabecon price
Привет!
Заказать диплом о высшем образовании
landik-diploms-srednee.ru/kupit-diplom-v-omske В
Удачи!
Как получить диплом стоматолога быстро и официально
ast-diplomy.com/kupit-diplom-ekaterinbur
mexico drug stores pharmacies: mexican pharmacy – mexico pharmacy
можно ли купить диплом в москве можно ли купить диплом в москве .
купить диплом о педагогическом образовании asxdiplomik24.ru .
Добрый день!
Узнайте, как безопасно купить диплом о высшем образовании
vk.com/unikvseru?w=wall414329581_6815
Всегда вам поможем!.
где можно купить аттестат где можно купить аттестат .
Добрый день!
Можно ли купить аттестат о среднем образовании? Основные рекомендации.
Купить диплом о высшем образовании.
http://www.gutscheine-247.de/modules.php?name=Journal&file=display&jid=213
раковина нержавейка
Здравствуйте!
Заказать документ университета можно в нашей компании.
asxdiplomik.com/kupit-diplom-rostov-na-donu
Добрый день!
Купить документ о получении высшего образования можно в нашем сервисе.
asxdiplomik24.ru/kupit-diplom-voronezh
Успехов в учебе!
купить диплом высшее в челябинске http://www.diploms-x.com/ .
Привет!
Купить документ о получении высшего образования можно в нашей компании.
diploms-x.com/kupit-diplom-vracha
как можно купить диплом как можно купить диплом .
mexican online pharmacies prescription drugs: п»їbest mexican online pharmacies – pharmacies in mexico that ship to usa
Добрый день!
Официальная покупка диплома вуза с упрощенной программой обучения
boyara-analia.flybb.ru/viewtopic.php?f=7&t=697
Поможем вам всегда!.
Привет, друзья!
Приобрести диплом ВУЗа
[url=http://landik-diploms-srednee.ru/kupit-diplom-v-ekaterinburge В ]landik-diploms-srednee.ru/kupit-diplom-v-ekaterinburge В [/url]
Удачи!
world pharmacy india: world pharmacy india – indianpharmacy com
Привет, друзья!
Заказать диплом любого университета
Мы предлагаем документы ВУЗов, расположенных на территории всей России. Вы сможете приобрести диплом от любого заведения, за любой год, включая сюда документы СССР. Дипломы и аттестаты делаются на “правильной” бумаге самого высокого качества. Это дает возможности делать настоящие дипломы, которые не отличить от оригиналов. Документы заверяются необходимыми печатями и подписями.
http://www.marqueze.net/miembros/matthewmorgan/profile/classic/
Рады оказать помощь!.
Привет!
Мы предлагаем документы ВУЗов, расположенных в любом регионе РФ. Можно приобрести качественный диплом за любой год, указав необходимую специальность и оценки за все дисциплины. Дипломы и аттестаты выпускаются на “правильной” бумаге высшего качества. Это дает возможности делать государственные дипломы, которые не отличить от оригиналов. Они заверяются всеми обязательными печатями и штампами.
ozoms.com/read-blog/514
Здравствуйте!
Где заказать диплом специалиста?
Купить диплом о высшем образовании.
odinzovo.rusff.me/viewtopic.php?id=4869#p8228
Привет, друзья!
Процесс получения диплома стоматолога: реально ли это сделать быстро?
[url=http://arusak-diploms-srednee.ru/diplom-sredne-spetcialnoe-obrazovanie В ]arusak-diploms-srednee.ru/diplom-sredne-spetcialnoe-obrazovanie В [/url]
Добрый день!
Реально ли приобрести диплом стоматолога? Основные шаги
dyado.listbb.ru/viewtopic.php?f=2&t=455
Окажем помощь!.
[u][b] Добрый день![/b][/u]
[b]Покупка школьного аттестата с упрощенной программой: что важно знать.[/b]
[b]Заказать диплом о высшем образовании.[/b]
[url=http://newsbig.wpsuo.com/kak-vozmozno-budet-nedorogo-zakazat-diplom-v-internet-magazine/]newsbig.wpsuo.com/kak-vozmozno-budet-nedorogo-zakazat-diplom-v-internet-magazine[/url]
Привет!
Наша компания предлагает заказать диплом в высочайшем качестве, который не отличить от оригинала без участия специалиста высокой квалификации со специальным оборудованием.
littleyaksa.yodev.net/bbs/board.php?bo_table=free&wr_id=6404553
Успешной учебы!
Добрый день!
Где купить диплом по необходимой специальности?
Мы предлагаем документы ВУЗов, которые находятся в любом регионе Российской Федерации. Вы можете заказать качественный диплом за любой год, указав необходимую специальность и хорошие оценки за все дисциплины. Дипломы выпускаются на бумаге высшего качества. Это позволяет делать настоящие дипломы, которые невозможно отличить от оригиналов. Документы заверяются необходимыми печатями и штампами.
Мы готовы предложить дипломы любой профессии по невысоким ценам.
ast-diplom.com/kupit-diplom-omsk
Окажем помощь!
Привет, друзья!
Где купить диплом специалиста?
Заказать диплом университета.
laporteproperty.com/en/cb-profile/pluginclass/cbblogs?action=blogs&func=show&id=121
Привет, друзья!
Приобрести документ университета вы имеете возможность у нас в Москве. Мы предлагаем документы об окончании любых университетов России. Вы получите диплом по любым специальностям, любого года выпуска, включая документы старого образца. Даем 100% гарантию, что в случае проверки документа работодателем, каких-либо подозрений не появится.
Мы можем предложить дипломы любых профессий по приятным тарифам. Цена будет зависеть от определенной специальности, года получения и образовательного учреждения. Всегда стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы документы были доступны для подавляющей массы наших граждан.
adobe-photoshop.ru/search/Жемчужина/
Рады оказать помощь!
Привет, друзья!
Наши специалисты предлагают выгодно приобрести диплом, который выполняется на оригинальном бланке и заверен печатями, водяными знаками, подписями должностных лиц. Документ пройдет любые проверки, даже с применением специального оборудования. Решите свои задачи максимально быстро с нашим сервисом.
androidb.ru/index.php?subaction=userinfo&user=ypixexyq
Успехов в учебе!
Здравствуйте!
Где заказать диплом специалиста?
Приобрести диплом о высшем образовании.
dskrnd.ru/forum/user/6464/
бесплатное лучшее порно без рекламы http://best-free-porno.ru .
Привет!
Где заказать диплом специалиста?
Мы предлагаем документы институтов, расположенных на территории всей России. Вы сможете заказать диплом от любого ВУЗа, за любой год, включая сюда документы СССР. Дипломы печатаются на “правильной” бумаге самого высокого качества. Это позволяет делать настоящие дипломы, которые не отличить от оригиналов. Они будут заверены необходимыми печатями и подписями.
Мы можем предложить дипломы любой профессии по разумным ценам.
ast-diplomy24.ru/kupit-diplom-o-srednem-obrazovanii
Будем рады вам помочь!
Привет!
Мы предлагаем быстро и выгодно заказать диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями. Наш документ пройдет любые проверки, даже с применением профессионального оборудования. Достигайте свои цели быстро и просто с нашей компанией.
whirlpowertool.ru/index.php?subaction=userinfo&user=aqake
Удачи!
Привет, друзья!
Где приобрести диплом по актуальной специальности?
http://www.4x4zubry.by/forum/messages/forum1/topic2051/message202283/?result=new#message202283
Хорошей учебы!
Привет, друзья!
Реально ли приобрести диплом стоматолога? Основные шаги
arusak-diploms-srednee.ru/kupit-diplom-v-cheliabinske
Привет, друзья!
Быстрая схема покупки диплома старого образца: что важно знать?
keterclub.com/read-blog/10107
Поможем вам всегда!
Здравствуйте!
Заказать диплом ВУЗа.
vira-ss.flybb.ru/viewtopic.php?f=9&t=431
девушка йога порно [url=yoga-porno.ru]девушка йога порно[/url] .
Приветствую. Может кто знает, где найти полезные статьи о недвижимости? Пока нашел https://glatt-nsk.ru
Привет, друзья!
Мы можем предложить дипломы любых профессий по приятным тарифам.
http://www.globalcorp.it/купить-диплом-мгудт-или-любого-вуза-ро/
лучшее порево бесплатно лучшее порево бесплатно .
Привет!
Где приобрести диплом специалиста?
Приобрести диплом о высшем образовании.
sportraketka.ru/byistroe-poluchenie-diploma-vash-shans-na-uspeh
Привет, друзья!
Узнайте стоимость диплома высшего и среднего образования и процесс получения
http://www.rcauto.pl/modules.php?name=Your_Account&op=userinfo&username=ypygo
Рады помочь!.
Добрый день!
Заказать документ университета вы сможете в нашей компании в столице.
ast-diplomy.com/kupit-diplom-s-registraciej
Добрый день!
Купить документ ВУЗа можно у нас в Москве.
asxdiplomik.com/kupit-diplom-magistra
Успехов в учебе!
купить диплом свидетельство diploms-x.com .
Добрый день!
Где купить диплом по актуальной специальности?
http://www.jointcorners.com/read-blog/78325
Здравствуйте!
Приобрести документ ВУЗа вы сможете в нашем сервисе.
ast-diplomy.com/kupit-diplom-novosibirsk
Узнайте, как приобрести диплом о высшем образовании без рисков
ast-diplomas24.ru/kupit-diplom-moskva
Привет, друзья!
Приобрести диплом любого университета.
ingprint.ru/club/user/58725/forum/message/6909/203474/
Здравствуйте!
Где заказать диплом по необходимой специальности?
Купить диплом ВУЗа.
good-serial.ru/2024/07/vash-diplom-dlya-uspeshnoy-kareryi-byistro-i-nadezhno/
Здравствуйте!
Официальное получение диплома техникума с упрощенным обучением в Москве
arusak-diploms-srednee.ru/kupit-diplom-medicinskogo-uchilishha В
According to Larry, there’s no one-size-fits-all answer as 2023 will be very much about experimenting with hairstyles that are personal and bespoke to you. “When thinking about short haircuts, there is so much variety – from the pixie cut, to short mullets, to maybe longer at the front, shorter at the back. Think more 2000s haircuts that you saw on Winona Ryder,” he says. This pixie cut is definitely very charming with the soft wavy hair gently flowing downward. The lady’s hair strands are quite thin and thus the addition of short layers creates enough volume and texture for this awesome pixie. Likewise, the short soft bangs create a lovely aura that is very innocent and charming. These so-called choppy haircuts have become increasingly popular with the messy hairstyle coming to the forefront in popularity. It performs excessively well as one of the premier short haircuts for heart-shaped faces.
http://programujte.com/profil/55533-naturalmakeupae/
This mousse has a whipped-cream texture that allows it to define the hell out of your curls without leaving them looking gelled. The formula is also alcohol-free, meaning it won’t dry out your hair, no matter how often you use it (which, during the humid seasons, is probably every single day). Rake one to two golf-ball-size puffs of mousse through your damp hair, then finger-curl sections for extra definition. For those with this hair type, the answer to what is hair mousse good for is more about adding body and movement and not as much about adding volume. Those with straight hair know this all too well, and that’s where hair mousse comes in. Use a dollop of mousse to add some texture and help provide structure to your hairstyle. Benefits: Yes, the grape smell is worth the buy alone. But the edge control has a firm grip that doesn’t leave behind any residue. “Clean the surface of your edges and apply the product and let it dry or wrap it for five minutes to let it set,” Oludele suggests.
paxlovid pill: paxlovid generic – п»їpaxlovid
http://paxloviddelivery.pro/# paxlovid cost without insurance
Добрый день!
Вопросы и ответы: можно ли быстро купить диплом старого образца?.
Купить диплом университета.
network-230.mn.co/posts/61837914
Быстрая схема покупки диплома старого образца: что важно знать?
ast-diplomy24.ru/otzyvy
Привет, друзья!
Заказать документ ВУЗа можно в нашей компании в Москве.
ast-diploms.com/otzyvy
Удачи!
Привет, друзья!
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
landik-diploms-srednee.ru/kupit-diplom-saratov В
Привет, друзья!
Заказать диплом о высшем образовании.
ls.ruanime.org/2024/06/16/diplomy-ot-luchshih-obrazovatelnyh-uchrezhdeniy.html
Успешной учебы!
Привет!
Купить документ о получении высшего образования вы можете у нас в столице.
asxdiplomik24.ru/kupit-diplom-krasnoyarsk
Успехов в учебе!
Добрый день!
Покупка диплома о среднем полном образовании: как избежать мошенничества?
worksale.mn.co/posts/61983327
Всегда вам поможем!
https://doxycyclinedelivery.pro/# doxycycline 500mg capsules
Добрый день!
Заказать документ о получении высшего образования можно в нашей компании.
ast-diploms.com/kupit-diplom-bakalavra-ili-specialista
Здравствуйте!
Аттестат школы купить официально с упрощенным обучением в Москве
meetspot.com/blogs_write.php?id=
Рады оказаться полезными!
Здравствуйте!
Мы изготавливаем дипломы любых профессий по приятным тарифам.
lghb.co.ke/купить-диплом-новосибирск/
Здравствуйте!
Купить документ о получении высшего образования можно у нас в Москве.
diplomasx.com/kupit-diplom-tehnikuma-kolledzha
Привет!
Мы изготавливаем дипломы любой профессии по приятным ценам.
controlcompany.com.pe/купить-диплом-юфу/
порно коллекции бесплатно https://porn-library.ru .
Добрый день!
Где купить диплом специалиста?
Заказать диплом ВУЗа.
forum-pravo.com.ua/member.php?u=10249
интернет магазин стройматериалов интернет магазин стройматериалов .
Привет, друзья!
Заказать документ ВУЗа можно у нас в Москве. Мы предлагаем документы об окончании любых ВУЗов России. Вы сможете получить необходимый диплом по любым специальностям, включая документы СССР. Гарантируем, что в случае проверки документа работодателем, каких-либо подозрений не возникнет.
Мы предлагаем дипломы любой профессии по приятным тарифам. Цена зависит от выбранной специальности, года выпуска и университета. Стараемся поддерживать для заказчиков адекватную ценовую политику. Для нас важно, чтобы документы были доступны для большого количества наших граждан.
qaedymoqutu.bearsfanteamshop.com/bystro-priobretaem-attestat-v-magazine-russian-diplom
Всегда вам поможем!
Добрый день!
Официальная покупка диплома вуза с сокращенной программой в Москве
nophlix.com/купить-дипломы-университета/
Компания Септик-Нара-купить септик в наро-фоминске
занимается продажей, установкой и обслуживанием септиков в Наро-Фоминске Наро-Фоминском районе. Основное направление деятельности нашей компании именно установка под ключ септиков любых видов и размеров. С момента основания нашей компании, мы произвели монтаж более 1000 септиков по Московской и Калужской области. Благодаря этому у нас огромный опыт работы с любыми станциями, представленными в нашем регионе!
Если Вы решили купить септик для дома или дачи, мы с радостью поможем Вам с выбором модели, доставим и установим септик на вашем участке в кратчайшие сроки.
Мы занимаемся продажей септиков таких марок: Топас Юнилос Астра Евролос Тверь Аквалос Дочиста Фекалов Волгарь Удача. Мы работаем напрямую с производителями септиков, поэтому Вы можете быть уверены, что не переплачиваете ни копейки. Вся продукция в нашей компании имеет соответствующие сертификаты и лицензии. Время выезда на осмотр, установки или привоза оборудования согласовывается с клиентами и выполняется в срок. Мы заботимся о своей репутации, поэтому выполняем работу надежно и быстро.
Если Вы не знаете, какой септик больше всего Вам подходит, мы предоставим консультацию и выезд специалиста на Ваш участок абсолютно бесплатно!
Благодаря приобретению качественных септиков в нашей компании, каждый клиент получает большое количество преимуществ:
» компактные размеры и небольшой вес устройства;
» доступная стоимость очистной установки;
» быстрый и простой монтаж;
» невысокая стоимость эксплуатации;
» отсутствие неприятных запахов;
» высокая производительность;
» длительный срок эксплуатации;
» высокая степень очистки;
» практически полностью автономный режим работы.
Добрый день!
Как приобрести аттестат о среднем образовании в Москве и других городах
stalinarch.ru/wiki/index.php/Ваш_путь_к_успеху:_диплом_на_заказ
Всегда вам поможем!
http://doxycyclinedelivery.pro/# doxycycline order
cost of generic clomid pills: how can i get clomid price – generic clomid price
Привет, друзья!
Как официально приобрести аттестат 11 класса с минимальными затратами времени
kolhos.listbb.ru/viewtopic.php?f=2&t=605
Будем рады вам помочь!
[u][b] Привет, друзья![/b][/u]
[b]Мы можем предложить дипломы[/b] психологов, юристов, экономистов и любых других профессий по приятным ценам.
[url=http://onlinekinospace.ru/kupite-diplom-dlya-vashego-budushhego/]onlinekinospace.ru/kupite-diplom-dlya-vashego-budushhego[/url]
Добрый день!
Как быстро получить диплом магистра? Легальные способы
studio-pd.ru/index.php?subaction=userinfo&user=avaqypi
Рады оказать помощь!.
Всем привет! Может кто знает, где найти полезные статьи о недвижимости? Сейчас читаю https://konditsioneri-shop.ru
http://ciprodelivery.pro/# purchase cipro
Здравствуйте!
Приобрести документ университета вы сможете в нашем сервисе.
diplomyx.com/kupit-diplom-kandidata-nauk
Здравствуйте!
Приобрести документ о получении высшего образования вы можете в нашей компании.
diploms-x24.ru/kupit-diplom-omsk
Успешной учебы!
Добрый день!
Купить диплом о высшем образовании.
operazionispeciali.it/cb-profile/pluginclass/cbblogs.html?action=blogs&func=show&id=251
порно с тренером порно с тренером .
buy cipro online: cipro for sale – buy cipro
Здравствуйте!
Мы изготавливаем дипломы любых профессий.
cittaviva.net/read-blog/51_proverennyj-magazin-s-obshirnym-vyborom-dokumentov.html
Поможем вам всегда!.
noroxin usa – where can i buy confido cheap confido sale
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
ast-diplomy.com/otzyvy
Здравствуйте!
Заказать диплом университета.
shiba-inu.ru/forum/messages/forum1/topic433/message441/?result=new#message441
Успехов в учебе!
Привет, друзья!
Приобрести документ института вы можете у нас в столице.
ast-diplomy.com/kupit-diplom-o-srednem-obrazovanii
Удачи!
Привет, друзья!
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
http://www.hinterhof.ch/de/2024/06/30/купить-диплом-урфу/
cost cheap clomid no prescription: order cheap clomid without a prescription – can i order generic clomid without insurance
Привет!
Заказать документ о получении высшего образования
diplomyx24.ru/kupit-diplom-krasnoyarsk
Здравствуйте!
Официальная покупка школьного аттестата с упрощенным обучением в Москве
arusak-diploms-srednee.ru/kupit-diplom-v-rostove-na-donu В
конференц-залы под ключ конференц-залы под ключ .
Добрый день!
Купить документ института вы сможете у нас.
diplomyx24.ru/kupit-diplom-voronezh
Удачи!
рейтинг прогнозистов rejting-kapperov12.ru .
Приобретение диплома ПТУ с сокращенной программой обучения в Москве
ast-diplom24.ru/otzyvy
Привет!
Заказать диплом о высшем образовании.
sev-ribalka.ru/gallery/image/2443-kak-nayti-nadezhnyy-magazin-s-shirokim-vyborom-diplomov/
Добрый день!
Мы изготавливаем дипломы любой профессии по выгодным ценам.
newsbizlife.ru/kupit-diplom-vyisokoe-kachestvo-i-nadezhnost
Привет!
Мы изготавливаем дипломы любой профессии по выгодным ценам.
service.gnla.com.au/2024/06/30/купить-диплом-капитана/
The Hidden Narrative Regarding Solana Architect Toly Yakovenko’s Achievement
After 2 Cups of Java plus a Pint
Yakovenko, the visionary the brainchild behind Solana, began his quest with a modest practice – a couple of coffees and an ale. Unaware to him, these instances would set the cogs of fate. Nowadays, Solana stands as a formidable competitor in the blockchain realm, having a market value of billions.
Initial Ethereum ETF Sales
The new Ethereum ETF just made its debut with a substantial volume of trades. This milestone event experienced various spot Ethereum ETFs from several issuers start trading on American exchanges, injecting significant activity into the typically steady ETF trading space.
SEC Approved Ethereum ETF
The Securities and Exchange Commission has formally approved the Ethereum Spot ETF for listing. As a crypto asset featuring smart contracts, Ethereum is expected to majorly affect the digital currency industry thanks to this approval.
Trump’s Bitcoin Tactics
With the upcoming election, Trump positions himself as the “President of Crypto,” constantly highlighting his support for the crypto sector to win voters. His method is different from Biden’s approach, seeking to capture the support of the crypto community.
Musk’s Influence on Crypto
Elon Musk, a famous figure in the cryptocurrency space and a supporter of Trump, created a buzz once again, promoting a meme coin associated with his antics. His involvement continues to influence the market environment.
Recent Binance News
A subsidiary of Binance, BAM, has been permitted to channel customer funds into U.S. Treasuries. Additionally, Binance observed its 7th year, underscoring its journey and obtaining numerous regulatory approvals. Meanwhile, Binance also announced plans to remove several notable cryptocurrency trading pairs, altering the market landscape.
Artificial Intelligence and Economic Outlook
Goldman Sachs’ leading stock analyst recently mentioned that AI won’t spark an economic revolution
Добрый день!
Заказать документ ВУЗа
ast-diploms.com/kupit-diplom-omsk
Привет, друзья!
Можно ли быстро купить диплом старого образца и в чем подвох?
arusak-diploms-srednee.ru/kupit-diplom-v-krasnodare В
Discover your perfect stay with WorldHotels-in.com, your ultimate destination for finding the best hotels worldwide! Our user-friendly platform offers a vast selection of accommodations to suit every traveler’s needs and budget. Whether you’re planning a luxurious getaway or a budget-friendly adventure, we’ve got you covered with our extensive database of hotels across the globe. Our intuitive search features allow you to filter results based on location, amenities, price range, and guest ratings, ensuring you find the ideal match for your trip. We pride ourselves on providing up-to-date information and competitive prices, often beating other booking sites. Our detailed hotel descriptions, high-quality photos, and authentic guest reviews give you a comprehensive view of each property before you book. Plus, our secure booking system and excellent customer support team ensure a smooth and worry-free experience from start to finish. Don’t waste time jumping between multiple websites – http://www.WorldHotels-in.com brings the world’s best hotels to your fingertips in one convenient place. Start planning your next unforgettable journey today and experience the difference with WorldHotels-in.com!
에스 슬롯
내부는 3층, 외부는 3층으로 둘러싸여 있는데도 갑자기 아무 소리도 들리지 않았다.
помещение для переговоров http://oborudovanie-dlja-peregovornoj-komnaty.ru .
Здравствуйте!
Заказать документ о получении высшего образования вы можете в нашем сервисе.
ast-diplomas24.ru/kupit-diplom-ekaterinbur
Успешной учебы!
переговорные комнаты в москве переговорные комнаты в москве .
Здравствуйте!
Приобрести диплом о высшем образовании.
cdposz.ru/club/user/802/forum/message/1485/1544/
Здравствуйте!
Мы изготавливаем дипломы любой профессии по приятным тарифам. Стоимость может зависеть от той или иной специальности, года получения и университета. Всегда стараемся поддерживать для покупателей адекватную политику цен. Для нас очень важно, чтобы документы были доступными для подавляющей массы граждан.
ztndz.com/story19044198/купить-диплом-ссср
Привет!
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по приятным тарифам.
iladuanas.com/аттестат-11-классов-2014-2024-видео/
coindarwin crypto news
The Story Behind Solana’s Architect Toly Yakovenko’s Success
Following A Pair of Servings of Coffee plus a Brew
Yakovenko, the visionary the mastermind behind Solana, commenced his path with an ordinary practice – two cups of coffee and a beer. Little did he realize, those moments would set the gears of fate. At present, Solana stands as a powerful contender in the blockchain sphere, boasting a worth in billions.
First Sales of Ethereum ETF
The new Ethereum ETF newly started with a substantial volume of trades. This landmark occasion observed several spot Ethereum ETFs from different issuers be listed on U.S. markets, creating extraordinary activity into the typically steady ETF trading space.
Ethereum ETF Approval by SEC
The SEC has officially approved the Ethereum exchange-traded fund for listing. As a cryptographic asset with smart contracts, Ethereum is anticipated to majorly affect the blockchain sector following this approval.
Trump’s Bitcoin Strategy
As the election draws near, Trump frames himself as the “President of Crypto,” frequently displaying his advocacy for the digital currency sector to attract voters. His strategy is different from Biden’s strategy, aiming to capture the support of the blockchain community.
Elon Musk’s Impact
Elon Musk, a famous figure in the cryptocurrency space and an advocate of Trump, shook things up once again, boosting a meme coin related to his antics. His involvement continues to shape market dynamics.
Recent Binance News
Binance’s subsidiary, BAM, is now permitted to channel customer funds into U.S. Treasury instruments. Additionally, Binance observed its seventh anniversary, underscoring its path and obtaining multiple compliance licenses. Simultaneously, Binance also made plans to remove several major crypto trading pairs, affecting different market players.
AI and Economic Trends
The chief stock analyst at Goldman Sachs recently mentioned that AI won’t spark a major economic changeHere’s the spintax version of the provided text with possible synonyms
Здравствуйте!
Заказать документ ВУЗа вы можете у нас в Москве.
ast-diploms.com/kupit-diplom-tehnikuma-kolledzha
Привет!
Заказать диплом ВУЗа.
the-travellers-network.mn.co/posts/61724336
Привет, друзья!
Купить документ института вы имеете возможность у нас.
ast-diplomas24.ru/kupit-diplom-omsk
Успехов в учебе!
МОСКВА, 7 мая — РИА Новости. Правительство России, возглавляемое Михаилом Мишустиным, уйдет в отставку во вторник.
Сразу после инаугурации президента Владимира Путина нынешний кабинет министров сложит полномочия перед вступившим в должность главой государства.
Прогон по комментария
Здравствуйте!
Купить документ ВУЗа можно в нашей компании в Москве.
asxdiplomik24.ru/kupit-diplom-omsk
Хорошей учебы!
Добрый день!
Быстрое обучение и получение диплома магистра – возможно ли это?
onlinekinofun.ru/poluchite-diplom-v-lyuboe-vremya
видео стена видео стена .
Кооператив для военных
Как пайщики — участники СВО относятся к событиям вокруг «Бест Вей»
Следственная группа ГСУ питерского главка МВД
Потребительский кооператив «Бест Вей» оказался затронут уголовным делом, касающимся в основном иностранной инвесткомпании «Гермес», которое сейчас рассматривается Приморским районным судом Санкт-Петербурга. Более двух лет более 3,5 млрд рублей на счетах кооператива почти непрерывно арестованы по ходатайству сначала ГСУ ГУ МВД по Санкт-Петербургу, а затем Прокуратуры Санкт-Петербурга: пайщики не имеют возможности ни приобрести недвижимость, ни вернуть средства.
По данным совета потребительского кооператива «Бест Вей», в числе его пайщиков, страдающих от блокировки средств, тысячи военнослужащих, в том числе сотни участников СВО, часть из которых успела приобрести квартиру, часть собирает или собрала первоначальный взнос, а часть — планировала вступить в кооператив. «СП» пообщалась с некоторыми из них и их родственниками, чтобы узнать отношение к «Бест Вей» и событиям вокруг кооператива.
«К кооперативу отношение очень хорошее»
Александр Голдман на СВО с мая 2022 года как доброволец, три ранения. Пришел на СВО рядовым, сейчас — начальник штаба батальона. Был пайщиком кооператива, сейчас пайщик — его мама.
«С помощью кооператива в 2019 году приобретена двухкомнатная квартира во Владивостоке, в которой проживает мама, — рассказывает он. — Расплачиваемся за нее, в ближайшие месяцы намерены погасить задолженность перед кооперативом и оформить квартиру в собственность. К кооперативу отношение очень хорошее, полностью его поддерживаю — он дает возможность без больших переплат приобрести недвижимость. К действиям в отношении кооператива отношусь отрицательно, так как „Бест Вей“ — единственная возможность приобрести жилье в рассрочку».
«Происходящее вокруг кооператива вызывает шок»
Гвардии рядовой Глушков Иван Васильевич — пайщик кооператива из Челябинской области. Танкист, мобилизованный, проходил службу в 15-й отдельной гвардейской мотострелковой Александрийской бригаде 2-й гвардейской общевойсковой армии ЦВО. Погиб 11 октября 2023 года.
Рассказывает его вдова Татьяна Неручева:
«Мы внесли первоначальный паевый взнос и во второй половине 2021 года встали в очередь на приобретение квартиры в Челябинске, когда начались события вокруг кооператива — была заблокирована его возможность приобретать недвижимость и заблокированы его счета. Наша очередь должна была подойти примерно через год. Мы заявили для приобретения небольшую квартиру, но планировали при покупке увеличить ее стоимость до 3 млн и купить двухкомнатную квартиру — с увеличением первоначального паевого взноса: уставом кооператива это позволяется, а затем переехать из Коркино в Челябинск. Сейчас 3 млн хватит только на небольшую квартиру-студию метров 25, то есть мы понесли материальный ущерб из-за блокирования деятельности кооператива, так как лишены были возможности приобрести квартиру, на которую собрали первоначальный паевый взнос. Работа кооператива заблокирована, счета арестованы уже более двух лет. В наследование пая я только вступаю, так как муж очень долго считался пропавшим без вести — долго шла экспертиза, и свидетельство о смерти мы получили только 18 июня этого года».
Татьяна — юрист: «Как у юриста у меня происходящее вокруг кооператива вызывает шок, и любой непредвзятый юрист вам скажет то же самое». «Кооператив, — подчеркивает она, — абсолютно прозрачен, он полностью соответствует законодательству о кооперации — что и подтверждалось многократно государственными органами и судами. Если бы мы с мужем не были уверены, что все прозрачно и законно, мы бы не вкладывали в него деньги. Мы не подавали заявление о выходе из кооператива. Я, несмотря ни на что, жду счастливого завершения рукотворного кризиса вокруг кооператива. Для меня это еще и память о муже — он продал долю в квартире, которая ему принадлежала, чтобы вложиться в кооператив. Кроме того, мне хочется понять — до какого маразма может дойти ситуация у нас в государстве в плане незаконных действий в отношении организации, которая по тем или иным причинам не понравилась каким-то чиновникам?».
«Рассчитываю, что ситуация закончится благополучно»
Сергей Логинов, рядовой, мобилизованный, представлен к награде «Честь и доблесть».
«Пять лет назад я стал пайщиком кооператива, участвовал в накопительной программе, планировал прибрести однокомнатную квартиру в Самарской области. Уже нужно было подбирать объект недвижимости и вставать в очередь на покупку, как работа кооператива была заблокирована по инициативе правоохранительных органов, и это продолжается уже более двух лет. По-прежнему надеюсь получить квартиру и рассчитываю, что ситуация закончится благополучно. Поддерживаю кооператив».
«В кооперативе минимум переплат — несопоставимо с ипотекой»
Егор Ивков, офицер флота, дирижер военного оркестра, пайщик кооператива с 2019 года.
«Я нахожусь в накопительной программе — планировал покупку квартиры в Санкт-Петербурге. До постановки в очередь на покупку дело не дошло, но сумма внесена серьезная — и на два года все зависло. Есть друзья-военнослужащие, которые также являются пайщиками и тоже накапливали деньги на первоначальный паевый взнос — они, как и я, не могут ни продолжать накапливать, ни получить деньги обратно, потому что счета арестованы. Отношение наше к ситуации, создавшейся вокруг кооператива, крайне негативное».
«Кооператив поддерживаю, — говорит пайщик. — Моя сестра живет в квартире, приобретенной с помощью „Бест Вей“ — у нее многодетная семья, сейчас кооперативная квартира переходит в ее собственность. Минимум переплат — несопоставимо с ипотекой. Надеюсь, что ситуация с арестом счетов разрешится в ближайшее время».
световое оборудование для актового зала http://oborudovanija-dlja-aktovyh-zalov.ru/ .
RGBET trang chủ
RGBET trang chủ với hệ thống game nhà cái đỉnh cao – Nhà cái uy tín số 1 Việt Nam trong lĩnh vực cờ bạc online
RG trang chủ, RG RICH GAME, Nhà Cái RG
RGBET Trang Chủ Và Câu Chuyện Thương Hiệu
Ra đời vào năm 2010 tại Đài Loan, RGBET nhanh chóng trở thành một trang cá cược chất lượng hàng đầu khu vực Châu Á. Nhà cái được cấp phép hoạt động hợp pháp bởi công ty giải trí trực tuyến hợp pháp được ủy quyền và giám sát theo giấy phép Malta của Châu Âu – MGA. Và chịu sự giám sát chặt chẽ của tổ chức PAGCOR và BIV.
RGBET trang chủ cung cấp cho người chơi đa dạng các thể loại cược đặc sắc như: thể thao, đá gà, xổ số, nổ hũ, casino trực tuyến. Dịch vụ CSKH luôn hoạt động 24/7. Với chứng chỉ công nghệ GEOTRUST, nhà cái đảm bảo an toàn cho mọi giao dịch của khách hàng. APP RG thiết kế tối ưu giải quyết mọi vấn đề của người dùng IOS và Android.
Là một nhà cái đến từ đất nước công nghệ, nhà cái luôn không ngừng xây dựng và nâng cấp hệ thống game và dịch vụ hoàn hảo. Mọi giao dịch nạp rút được tự động hoá cho phép người chơi hoàn tất giao dịch chỉ với 2 phút vô cùng nhanh chóng
RGBET Lớn Nhất Uy Tín Nhất – Giá Trị Cốt Lõi
Nhà Cái RG Và Mục Tiêu Thương Hiệu
Giá trị cốt lõi mà RGBET mong muốn hướng đến đó chính là không ngừng hoàn thiện để đem đến một hệ thống chất lượng, công bằng và an toàn. Nâng cao sự hài lòng của người chơi, đẩy mạnh hoạt động chống gian lận và lừa đảo. RG luôn cung cấp hệ thống kèo nhà cái đặc sắc, cùng các sự kiện – giải đấu hàng đầu và tỷ lệ cược cạnh tranh đáp ứng mọi nhu cầu khách hàng.
Thương hiệu cá cược RGBET cam kết đem lại cho người chơi môi trường cá cược công bằng, văn minh và lành mạnh. Đây là nguồn động lực to lớn giúp nhà cái thực tế hóa các hoạt động của mình.
RGBET Có Tầm Nhìn Và Sứ Mệnh
Đổi mới và sáng tạo là yếu tố cốt lõi giúp đạt được mục tiêu dưới sự chuyển mình mạnh mẽ của công nghệ. Tầm nhìn và sứ mệnh của RGBET là luôn tìm tòi những điều mới lạ, đột phá mạnh mẽ, vượt khỏi giới hạn bản thân, đương đầu với thử thách để đem đến cho khách hàng sản phẩm hoàn thiện nhất.
Chúng tôi luôn sẵn sàng tiếp thu ý kiến và nâng cao bản thân mỗi ngày để tạo ra sân chơi bổ ích, uy tín và chuyên nghiệp cho người chơi. Để có thể trở thành nhà cái phù hợp với mọi khách hàng.
Khái Niệm Giá Trị Cốt Lõi Nhà Cái RGBET
Giá trị cốt lõi của nhà cái RG luôn gắn kết chặt chẽ với nhau giữa 5 khái niệm: Chính trực, chuyên nghiệp, an toàn, đổi mới, công nghệ.
Chính Trực
Mọi quy luật, cách thức của trò chơi đều được nhà cái cung cấp công khai, minh bạch và chi tiết. Mỗi tựa game hoạt động đều phải chịu sự giám sát kỹ lưỡng bởi các cơ quan tổ chức có tiếng về sự an toàn và minh bạch của nó.
Chuyên Nghiệp
Các hoạt động tại RGBET trang chủ luôn đề cao sự chuyên nghiệp lên hàng đầu. Từ giao diện đến chất lượng sản phẩm luôn được trau chuốt tỉ mỉ từng chi tiết. Thế giới giải trí được xây dựng theo văn hóa Châu Á, phù hợp với đại đa số thị phần khách Việt.
An Toàn
RG lớn nhất uy tín nhất luôn ưu tiên sử dụng công nghệ mã hóa hiện đại nhất để đảm bảo an toàn, riêng tư cho toàn bộ thông tin của người chơi. Đơn vị cam kết nói không với hành vi gian lận và mua bán, trao đổi thông tin cá nhân bất hợp pháp.
Đổi Mới
Nhà cái luôn theo dõi và bắt kịp xu hướng thời đại, liên tục bổ sung các sản phẩm mới, phương thức cá cược mới và các ưu đãi độc lạ, mang đến những trải nghiệm thú vị cho người chơi.
Công Nghệ
RGBET trang chủ tập trung xây dựng một giao diện game sắc nét, sống động cùng tốc độ tải nhanh chóng. Ứng dụng RGBET giải nén ít dung lượng phù hợp với mọi hệ điều hành và cấu hình, tăng khả năng sử dụng của khách hàng.
RGBET Khẳng Định Giá Trị Thương Hiệu
Hoạt động hợp pháp với đầy đủ giấy phép, chứng chỉ an toàn đạt tiêu chuẩn quốc tế
Hệ thống game đa màu sắc, đáp ứng được mọi nhu cầu người chơi
Chính sách bảo mật RG hiện đại và đảm bảo an toàn cho người chơi cá cược
Bắt tay hợp tác với nhiều đơn vị phát hành game uy tín, chất lượng thế giới
Giao dịch nạp rút RG cấp tốc, nhanh gọn, bảo mật an toàn
Kèo nhà cái đa dạng với bảng tỷ lệ kèo cao, hấp dẫn
Dịch Vụ RGBET Casino Online
Dịch vụ khách hàng
Đội ngũ CSKH RGBET luôn hoạt động thường trực 24/7. Nhân viên được đào tạo chuyên sâu luôn giải đáp tất cả các khó khăn của người chơi về các vấn đề tài khoản, khuyến mãi, giao dịch một cách nhanh chóng và chuẩn xác. Hạn chế tối đa làm ảnh hưởng đến quá trình trải nghiệm của khách hàng.
Đa dạng trò chơi
Với sự nhạy bén trong cập nhật xu thế, nhà cái RGBET đã dành nhiều thời gian phân tích nhu cầu khách hàng, đem đến một kho tàng game chất lượng với đa dạng thể loại từ RG casino online, thể thao, nổ hũ, game bài, đá gà, xổ số.
Khuyến mãi hấp dẫn
RGBET trang chủ liên tục cập nhật và thay đổi các sự kiện ưu đãi đầy hấp dẫn và độc đáo. Mọi thành viên bất kể là người chơi mới, người chơi cũ hay hội viên VIP đều có cơ hội được hưởng ưu đãi đặc biệt từ nhà cái.
Giao dịch linh hoạt, tốc độ
Thương hiệu RGBET luôn chú tâm đến hệ thống giao dịch. Nhà cái cung cấp dịch vụ nạp rút nhanh chóng với đa dạng phương thức như thẻ cào, ví điện tử, ngân hàng điện tử, ngân hàng trực tiếp. Mọi hoạt động đều được bảo mật tuyệt đối bởi công nghệ mã hóa tiên tiến.
App cá độ RGBET
App cá độ RGBET là một ứng dụng cho phép người chơi đăng nhập RG nhanh chóng, đồng thời các thao tác đăng ký RG trên app cũng được tối ưu và trở nên đơn giản hơn. Tham gia cá cược RG bằng app cá độ, người chơi sẽ có 1 trải nghiệm cá cược tuyệt vời và thú vị.
RGBET Có Chứng Nhận Cá Cược Quốc Tế
Nhà cái RGBET hoạt động hợp pháp dưới sự cấp phép của hai tổ chức thế giới là PAGCOR và MGA, tính minh bạch và công bằng luôn được giám sát gắt gao bởi BIV. Khi tham gia cược tại đây, người chơi sẽ được đảm bảo quyền và lợi ích hợp pháp của mình.
Việc sở hữu các chứng nhận quốc tế còn cho thấy nguồn tài chính ổn định, dồi dào của RGBET. Điều này cho thấy việc một nhà cái được công nhận bởi các cơ quan quốc tế không phải là một chuyện dễ.
Theo quy định nhà cái RGBET, chỉ người chơi từ đủ 18 tuổi trở lên mới có thể tham gia cá cược tại RGBET
MGA (Malta Gaming Authority)
Tổ chức MGA đảm bảo tính vẹn toàn và ổn định của các trò chơi. Có các chính sách bảo vệ nguồn tài chính và quyền lợi của người chơi. Chứng nhận một nhà cái hoạt động có đầy đủ pháp lý, tuân thủ nghiêm chỉnh luật cờ bạc.
Chứng nhận Quần đảo Virgin Vương quốc Anh (BIV)
Tổ chứng chứng nhận nhà cái có đầy đủ tài chính để hoạt động kinh doanh cá cược. Với nguồn ngân sách dồi dào, ổn định nhà cái bảo đảm tính thanh khoản cho người chơi, mọi quyền lợi sẽ không bị xâm phạm.
Giấy Phép PAGCOR
Tổ chức cấp giấy phép cho nhà cái hoạt động đạt chuẩn theo tiêu chuẩn quốc tế. Cho phép nhà cái tổ chức cá cược một cách hợp pháp, không bị rào cản. Có chính sách ngăn chặn mọi trò chơi có dấu hiệu lừa đảo, duy trì sự minh bạch, công bằng.
Nhà Cái RGBET Phát Triển Công Nghệ
Nhà cái RGBET hỗ trợ trên nhiều thiết bị : IOS, Android, APP, WEB, Html5
RG và Trách Nhiệm Xã Hội
RGBET RichGame không đơn thuần là một trang cá cược giải trí mà nhà cái còn thể hiện rõ tính trách nhiệm xã hội của mình. Đơn vị luôn mong muốn người chơi tham gia cá cược phải có trách nhiệm với bản thân, gia đình và cả xã hội. Mọi hoạt động diễn ra tại RGBET trang chủ nói riêng hay bất kỳ trang web khác, người chơi phải thật sự bình tĩnh và lý trí, đừng để bản thân rơi vào “cạm bẫy của cờ bạc”.
RGBET RichGame với chính sách nghiêm cấm mọi hành vi xâm phạm thông tin cá nhân và gian lận nhằm tạo ra một môi trường cá cược công bằng, lành mạnh. Nhà cái khuyến cáo mọi cá nhân chưa đủ 18 tuổi không nên đăng ký RG và tham gia vào bất kỳ hoạt động cá cược nào.
rgbet bea502d
Чудо Гриб препарат от паразитов https://chydogrib.ru и ВПЧ. Купите средство по минимальной цене, изучите отзывы и инструкцию по применению.
Привет!
Приобрести документ университета вы можете в нашем сервисе.
ast-diplom.com/kupit-diplom-nizhnij-novgorod
Хорошей учебы!